一种数据模型训练方法及训练设备与流程
本发明涉及智慧医疗技术领域,尤其涉及一种数据模型训练方法及训练设备。
背景技术:
随着社会经济的高速发展,人类对生命健康的认知不断提高,对医疗卫生事业有着极大的期盼。冠脉疾病的医疗水平和预防技术也是其中较为关注的话题,这两方面的研究都离不开冠脉建模。因此,自动化冠脉重建具有重要的临床价值和实际意义。
在现有技术中,技术人员或医务人员都侧重在冠脉建模、冠脉分割和分割算法等方面的研究。在冠脉建模过程中,有一个模型自动化训练的分支,该分支旨在分析自动冠脉分割的模型,选出最优方案,以便对患者们的原始电子计算机扫描(ct)数据做出更好的预测,辅助医务人员完成诊断工作或自主完成其中的一部分诊断工作。
然而后续的数据训练的整理与分析并没有形成有效合力,这部分工作只能交给资深的医务人员来处理,使得就医成本大幅增加,医疗效率大打折扣。同时,这种医疗效果的最终准确度也不好把控,难以满足当今社会的需求。
技术实现要素:
本发明为了解决现有技术中一般冠脉分割技术无法实现自动化训练以及在训练过程中选出最优模型的问题,提供一种有关冠脉分割的数据模型训练方法及训练设备。
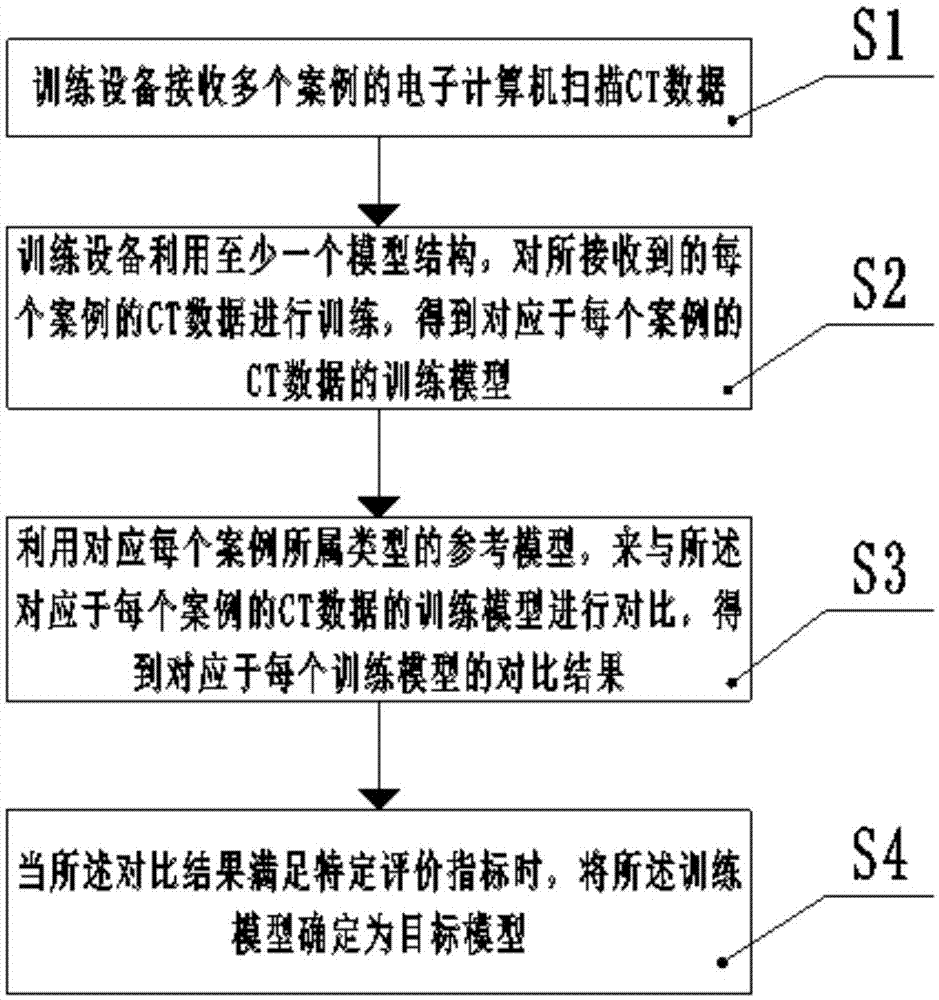
为了实现上述目的,本发明采取下述技术方案:一种数据模型训练方法,所述方法应用于一训练设备,所述方法包括:所述训练设备接收多个案例(case)的ct数据;所述训练设备利用至少一个模型结构,对所接收到的每个案例的ct数据进行训练,得到对应于每个案例的ct数据的训练模型;所述训练设备利用对应每个案例所属类型的参考模型,来与所述对应于每个案例的ct数据的训练模型进行对比,得到对应于每个训练模型的对比结果;当所述对比结果满足特定评价指标时,将所述训练模型确定为目标模型。
根据本发明一实施方式,当所述训练设备接收多个案例的ct数据时,所述训练设备对每个案例进行结果预测,得到对应于每个案例的预测结果;所述训练设备根据所得到的对应于每个案例的预测结果来对每个案例进行合格性标记。
根据本发明一实施方式,在所述训练设备根据所得到的对应于每个案例的预测结果来对每个案例进行合格性标记之后,所述方法还包括:所述训练设备分别对相邻两次训练的案例的总量、不合格案例的总量、各类不合格的案例的数量进行统计,得到统计结果。
根据本发明一实施方式,所述方法还包括:所述训练设备根据所得到的统计结果进行案例配比的微调。
根据本发明一实施方式,在所述训练设备利用至少一个模型结构,对所接收到的每个案例的ct数据进行训练,得到对应于每个案例的ct数据的训练模型之前,所述方法还包括:所述训练设备利用预置的超参数、训练数据和模拟结构三者进行排列组合,以形成所述模型结构。
根据本发明一实施方式,在当所述对比结果满足特定评价指标时,将所述训练模型确定为目标模型之后,所述方法还包括:从所得到目标模型中选取评价指标最高的模型,作为最终输出模型。
应用上述训练方法的一种训练设备,所述训练设备包括:配置数据单元,用于接收多个案例的ct数据;配置训练单元,用于利用至少一个模型结构,对所接收到的每个案例的ct进行训练,得到对应于每个案例的ct数据的训练模型;对比单元,用于利用对应每个案例所属类型的参考模型,来与所述对应于每个案例的ct数据的训练模型进行对比,得到对应于每个训练模型的对比结果;确定单元,用于当所述对比结果满足特定评价指标时,将所述训练模型确定为目标模型。
在计算机中设置配置数据单元,可自动配置数据,用于采集多个case的ct数据,实现其自动导入;配置训练单元利用模型对ct数据的训练,输出对应的训练模型,实现了计算机对冠脉健康情况的自动诊断,大幅减少了医务人员的工作量,甚至无需资深的医疗专家进行分析,提高医疗效率,大幅降低人们的医疗成本;依据不合格case的遗漏、噪声和断裂等因素,筛选单元设置与之相对应的参考模型;当训练模型落满足特定评价指标时,则表示该训练模型具有成为优选模型的可能,标为目标模型。
根据本发明一实施方式,所述配置数据单元还用于,当接收多个案例的ct数据时,对每个案例进行结果预测,得到对应于每个案例的预测结果;根据所得到的对应于每个案例的预测结果来对每个案例进行合格性标记。
根据本发明一实施方式,所述配置数据单元还用于,在根据所得到的对应于每个案例的预测结果来对每个案例进行合格性标记之后,分别对相邻两次训练的案例的总量、不合格案例的总量、各类不合格的案例的数量进行统计,得到统计结果。
根据本发明一实施方式,所述配置数据单元还用于,根据所得到的统计结果进行案例配比的微调。
根据本发明一实施方式,所述配置训练单元还用于,在利用至少一个模型结构,对所接收到的每个案例的ct数据进行训练,得到对应于每个案例的ct数据的训练模型之前,利用预置的超参数、训练数据和模拟结构三者进行排列组合,以形成所述模型结构。
根据本发明一实施方式,所述确定单元还用于,在当将所述训练模型确定为目标模型之后,从所得到目标模型中选取评价指标最高的模型,作为最终输出模型。
本发明通过上述方法求得的目标模型,即优选模型,再配合后期的分析与研究,最终筛选出冠脉疾病训练的最终输出模型,即常规最优模型,从而实现冠脉疾病训练及自动诊断的常规化。这样,优选模型以可替代的方式存储在计算机中,使得前后两次筛选出来的优选模型具有可比性,在计算机中设置相对应的处理模块,通过进一步的分析,从两个优选模型中再筛选,得出最终的最优模型,进一步提高准确性,为科学分析、研究和诊断冠脉疾病提供重要的参考。
需要理解的是,本发明的教导并不需要实现上面所述的全部有益效果,而是特定的技术方案可以实现特定的技术效果,并且本发明的其他实施方式还能够实现上面未提到的有益效果。
附图说明
通过参考附图阅读下文的详细描述,本发明示例性实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本发明的若干实施方式,其中:
在附图中,相同或对应的标号表示相同或对应的部分。
图1出示了本发明的数据模型训练方法的实现流程示意图;
图2出示了本发明的数据模型训练设备的组成结构示意图。
具体实施方式
为使本发明的目的、特征、优点能够更加的明显和易懂,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而非全部实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
下面将参考若干示例性实施方式来描述本发明的原理和精神。应当理解,给出这些实施方式仅仅是为了使本领域技术人员能够更好地理解进而实现本发明,而并非以任何方式限制本发明的范围。相反,提供这些实施方式是为了使本发明更加透彻和完整,并且能够将本发明的范围完整地传达给本领域的技术人员。
下面结合附图和具体实施例对本发明的技术方案进一步详细阐述。
结合附图1,本发明提供一种数据模型训练方法,所述方法应用于至少一训练设备,包括:
s1、所述训练设备接收多个案例的ct数据;
s2、所述训练设备利用至少一个模型结构,对所接收到的每个案例的ct数据进行训练,得到对应于每个案例的ct数据的训练模型;
s3、所述训练设备利用对应每个案例所属类型的参考模型,来与所述对应于每个案例的ct数据的训练模型进行对比,得到对应于每个训练模型的对比结果;
s4、当所述对比结果满足特定评价指标时,将所述训练模型确定为目标模型。
在这里,其中的参考模型一般是指健康人体的冠脉模型;同时,为了增强对比性,一般设定训练设备接收一组case的ct数据的时间(t0)是不变的,且t0是可以手动调节的;在传输速度不变的条件下,训练设备一次性接收数据的总容量(g0)不变;而一旦导入训练设备,这个case的容量(g0)是可知的。
本发明通过上述方法求得的目标模型,即优选模型,再配合后期的分析与研究,最终筛选出冠脉疾病训练的最终输出模型,即常规最优模型,从而实现冠脉疾病训练及自动诊断的常规化。这样,优选模型以可替代的方式存储在计算机中,使得前后两次筛选出来的优选模型具有可比性,在计算机中设置相对应的处理模块,通过进一步的分析,从两个优选模型中再筛选,得出最终的最优模型,进一步提高准确性,为科学分析、研究和诊断冠脉疾病提供重要的参考。
在一种可能的实施方式中,在s1之后,所述训练设备对每个案例进行结果预测,得到对应于每个案例的预测结果;所述训练设备根据所得到的对应于每个案例的预测结果来对每个案例进行合格性标记;若标记为合格,则记录本次case的数量加1;若标记为不合格,则记录本次badcase的数量加1,且预测不合格的原因(如遗漏、噪声和断裂等)。
在进一步的实施方式中,在所述训练设备根据所得到的对应于每个案例的预测结果来对每个案例进行合格性标记之后,所述方法还包括:所述训练设备分别对相邻两次训练的案例的总量、不合格案例的总量、各类不合格的案例的数量进行统计,得到统计结果。
在这里,训练设备分别对本次训练的case总量(an)、不合格案例(badcase)总量(bn)、badcase的类别(an、bn、cn……zn)进行统计,该统计的结果与前次的结果进行对比,并在下次接收ct数据时执行case类别配比的微调,其中an为第n次训练的case总量,bn为第n次训练的badcase总量,an、bn、cn……zn分别为不同的badcase在第n次训练时的数量。
在进一步的实施方式中,所述训练设备根据所得到的统计结果进行案例配比的微调。
在执行微调时,当此次训练case的总量少于前一次时,则训练设备执行case总量增加的指令;当此次训练的不合格的case总量大于前一次时,则训练设备执行不合格的case总量减少的指令;当某一种类型的不合格的case的数量小于前一次时,则训练设备执行该case数量增加的指令。
即,当an<an-1时,则an会增加;当bn>bn-1时,则bn会减少;当an<an-1时,则an会增加;当bn>bn-1时,则bn会减少;以此类推,直至所有类别的case都完成配比微调。
当任意一种类别的case在第n-1次和第n次的训练数量相同时,则在第n次训练时均不需要增加或减少对应case的数量。
在一种可能的实施方式中,在s2之前,所述方法还包括:所述训练设备利用预置的超参数、训练数据和模拟结构三者进行排列组合,以形成所述模型结构。
在一种可能的实施方式中,在s3之后,所述方法还包括:从所得到目标模型中选取评价指标最高的模型,作为最终输出模型。
在这里,参考模型与训练模型进行的对比,其中的评价指标可以包括检测的准确率(iou)、精确度、召回率、误报率或相似度等参数,根据评价指标来评价训练模型,其中评价指标最高的训练模型会被筛选出来。
下面结合一应用实例来对本发明数据模型训练方法进行详细阐述。
首先,所述训练设备接收20个案例的ct数据;对20个案例进行结果预测,得到对应于每个案例的预测结果;再根据所得到的对应于每个案例的预测结果来对每个案例进行合格性标记;所述训练设备分别对相邻两次训练的案例的总量、不合格案例的总量、各类不合格的案例的数量进行统计,得到统计结果。
比如,上一次共有20个case,其中12个合格case,6个case因发生断裂不合格,2个case因噪声干扰不合格;此次的统计结果也是如此,共有20个case,其中12个合格case,6个case因发生断裂不合格,2个case因噪声干扰不合格。
进一步地,所述训练设备根据所得到的统计结果进行案例配比的微调,根据g0、an、bn、an、bn、cn……zn等的关联性及数字关系,当配置数据单元201再一次接收case时,需增加10个case,不合格、合格各为5个,不合格的因发生断裂的4个,因噪声1个。故此次真实训练的统计结果:接收30个case,不合格的case为13个,因发生断裂的10个,因噪声3个。
其次,所述训练设备利用预置的2个超参数、2个训练数据和2个模拟结构,三者进行排列组合,以形成2*2*2=8种模型结构;利用这8种模型结构,对所述30个案例的ct数据进行训练,得到对应于每个案例的ct数据的8*30=240种训练模型。
再次,所述训练设备利用对应这30个案例所属类型的参考模型,来与所述对应于每个案例的ct数据的240种训练模型进行对比,得到对比结果;
最后,当所述对比结果满足特定评价指标时,将所述训练模型确定为目标模型;从所得到目标模型中选取评价指标最高的模型,作为最终输出模型。在这个过程中,为了提高准确性,可以通过数学建模、数学函数、模型图像等方面进行分析、对比和研究。
结合附图2,本发明还提供一种数据模型训练设备,所述训练设备包括:
配置数据单元201,用于接收多个案例的ct数据;配置训练单元202,用于利用至少一个模型结构,对所接收到的每个案例的ct进行训练,得到对应于每个案例的ct数据的训练模型;对比单元203,用于利用对应每个案例所属类型的参考模型,来与所述对应于每个案例的ct数据的训练模型进行对比,得到对比结果;确定单元204,用于当所述对比结果满足特定评价指标时,将所述训练模型确定为目标模型。
为了解决上述问题,根据本发明一实施方式,所述配置数据单元201还用于,当操作s1时,对每个案例进行结果预测,得到对应于每个案例的预测结果;根据所得到的对应于每个案例的预测结果来对每个案例进行合格性标记。
根据本发明一实施方式,所述配置数据单元201还用于,在根据所得到的对应于每个案例的预测结果来对每个案例进行合格性标记之后,分别对相邻两次训练的案例的总量、不合格案例的总量、各类不合格的案例的数量进行统计,得到统计结果。
根据本发明一实施方式,所述配置数据单元201还用于,根据所得到的统计结果进行案例配比的微调。
根据本发明一实施方式,所述配置训练单元202还用于,在操作s2之前,利用预置的超参数、训练数据和模拟结构三者进行排列组合,以形成所述模型结构。
根据本发明一实施方式,所述确定单元204还用于,在操作s1之后,从所得到目标模型中选取评价指标最高的模型,作为最终输出模型。
这里需要指出的是:以上实施例的描述,与前述方法实施例的描述是类似的,具有同方法实施例相似的有益效果,因此不做赘述。对于本发明实施例中未披露的技术细节,请参照本发明方法实施例的描述而理解,为节约篇幅,因此不再赘述。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括多要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!