一种circbank数据库系统及其应用的制作方法
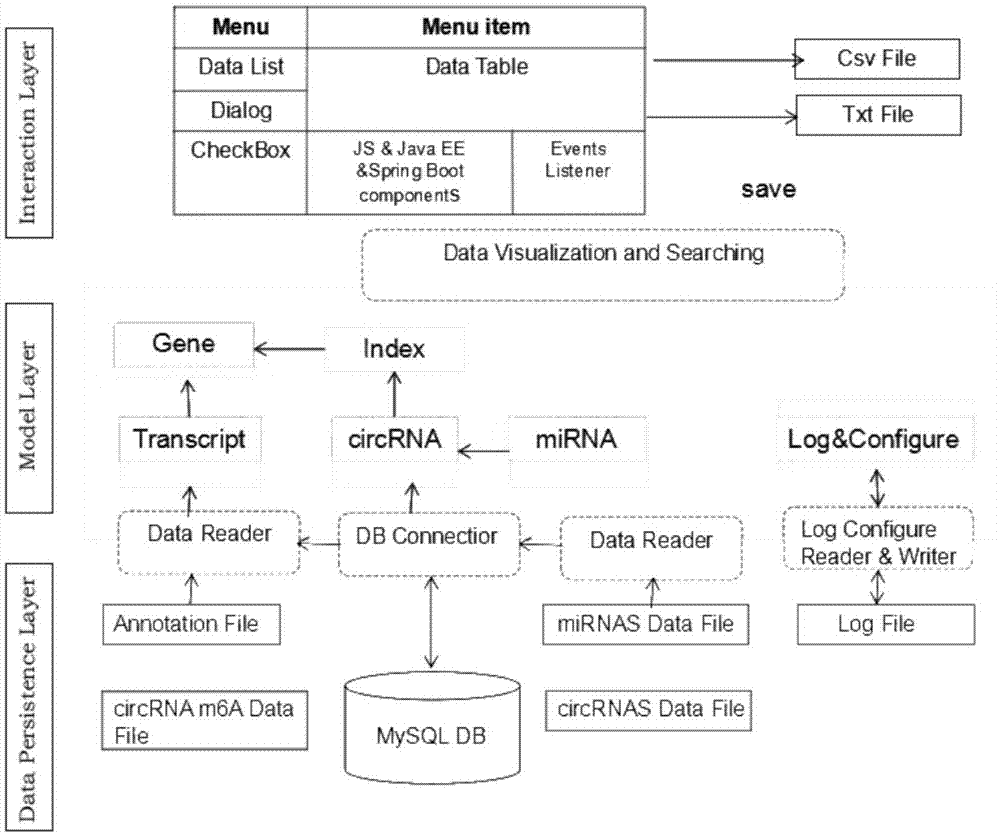
本发明属于基因数据库的
技术领域:
,具体涉及一种circbank数据库系统、该数据系统的构建方法以及该数据系统的应用。
背景技术:
:circrna(环形rna)由rna前体可变剪接产生,比线性rna稳定性更强,数量众多,现已查明人类circrna数量多达14万多种,是近几年rna研究领域的热点。越来越多的证据表明circrna与多种疾病的发生发展密切相关,可通过调控mirna、蛋白及其亲本基因和编码蛋白,从而发挥特定的生物学功能。尤其在癌症研究领域,circrna在肿瘤的生长、转移和耐药性方面发挥重要分子功能,相当一部分circrna可作为癌症诊断和治疗分子靶标。circrna数量众多,人类现已发现的circrna数量达到14万多种,如何组织管理这么多的circrna信息,迫切需要一个科学的管理系统。circrna命名方面尚未有统一规范实用的体系,目前已发布的其他系统,要么直接以阿拉伯数字命名(比如circbase数据库:hsa_circ_0007534)虽然可以解决circrna数量多而名字不重叠的问题,但给理解circrna分子带来了困难。此外,circrna分子在人体中大量存在,且功能强大,已有研究报道发现,circrna在人类疾病,如肿瘤、老年痴呆和心血管疾病等都存在密切关联。如何阐释circrna在这些疾病中的分子功能和分子机制,为上述疾病的诊断和治疗将带来重要突破。目前已有circrna数据库都功能单一,只针对其中某个方向或其中一部分,很难为全面理解circrna分子特性和功能带来益处。目前国内外尚未出现类似的大型综合circrna数据库系统,有些数据库信息老旧,实用意义大打折扣。如circbase数据库只提供circrna的序列信息,circrnadb数据库主要提供蛋白翻译预测功能,circnet主要提供circrna结合mirna预测功能等。技术实现要素:本发明综合生物医学和计算机信息技术,构建了circrna相关基因信息的综合分析预测系统circbank数据库系统,通过circbank数据库系统,可以方便、快捷、全面地分析circrna相关特征和功能预测,加速circrna科学研究进展。本发明所述的circbank数据库系统是一套利用计算机信息技术构建的生物医药领域circrna基因大型数据系统。一种circbank数据库系统,所述数据系统运行架构由数据持久层、数据模型层和人机交互层组成。其中所述数据持久层位于最底层,其在磁盘上保存了记录文件;所述数据模型层位于中间层,用于提供与数据库连接及数据处理接口,完成来自上层的业务请求,实现对业务逻辑的处理;所述人机交互层位于最上层,其用于为用户提供各种数据接口,包括各级菜单和各种图形界面组件,交互层接受用户请求,对请求进行分析和分发,最后对处理结果进行展示或保存为对应格式的文件。进一步,所述记录文件选自生物信息记录、数据文件及系统日志文件中的一种或多种。进一步,所述记录文件选自circrnasdatafile、mirnasdatafile、logfile中的一种或多种。进一步,所述circbank数据库系统包括六大模块:circrna科学命名模块、circrna-mirna结合预测分析模块、circrna保守性分析模块、circrna的m6a修饰信息模块、circrna突变分析模块、circrna蛋白翻译潜能分析模块。进一步,所述circrna科学命名模块采用如下命名规则:(1)命名基本格式:物种_circ基因名_三位阿拉伯数字;(2)一个基因名只对应一个circrna时,则命名为:物种_circ基因名_001;(3)同一基因名对应多个circrna时,三位阿拉伯数字的规则,主要依据转录其实和终止靠前的原则来排列,谁先转录谁排前,同时转录看谁先终止;(4)针对正链来源的circrna,依据circrna坐标起点数值从左到右、从小到大排列顺序,排在最前面的命名为001,后续依次排列;(5)针对负链来源的circrna,依据circrna坐标起点数值从右到左、从大到小排列顺序,排在最前面的命名为001,后续依次排列;(6)遇到转录起始终止坐标完全一致但序列长度不一致的circrna时,三位阿拉伯数字前加大写v,依据序列从长到短,从v001往后依次排列;(7)同一基因名对应既有正链又有负链来源的circrna时,按以上规则先命名正链的circrna,再命名负链的circrna;(8)如果circrna没有对应的基因名,则按对应的染色体来命名,数字按5位阿拉伯数字计数,由00001起始;进一步,所述circrna蛋白翻译潜能分析模块通过蛋白翻译预测算法工具cpat:coding-potentialassementtool预测circrna的编码潜能。所述cpat(codingpotentialassessmenttool)可快速区分新转录本是蛋白质编码还是非编码。cpat使用了4种序列特征(开放阅读框大小,开放阅读框覆盖,ficketttestcode统计和六联体使用偏倚)构建逻辑回归模型。cpat在区分rna编码能力方面表现优秀,其检测灵敏度可到0.96,特异性可达0.97,能够在数秒钟内处理数以千计的转录本。比coding-potentialcalculator和phylocodonsubstitutionfrequencies快约4个数量级,且cpat可接受fasta或bed格式文件作为输入序列;进一步,所述circrna-mirna结合预测分析模块采用miranda和targetscan两种算法对所有人类circrna进行了mirna结合位点预测,通过该circbank数据库系统可检索每个人circrna结合mirna的情况。所述miranda是最早的一个利用生物信息学对mirna靶基因进行预测的软件,由enright等人于2003年设计开发。作为最早的mirna靶基因预测软件,miranda对3′utr的筛选依据主要是从序列匹配、mirna与mrna双链的热稳定性以及靶位点的保守性三个方面进行分析。其算法具体运行代码及参数如下:mirandahg19_mirna_seq.facircrnaseq.fa-sc140>miranda_circ_prediction_output.txt;所述targetscan是lewis等人在2003年开发的一款用于预测哺乳动物mirna靶基因的软件,该软件将rna间相互作用的热力学模型与序列比对分析相结合,预测不同物种间保守的mirna结合位点。其算法具体运行代码及参数如下:targetscan_70.plhuman_mirna_seed.fahsa_circrna_seq.fatargetscan_circ_output.txt;进一步,所述circrna保守性分析模块通过序列对比分析,提供人circrna对应保守的小鼠circrna序列。进一步,所述circrna突变分析模块包含了circrna基因位置上包含的人类疾病相关基因突变位点信息,其通过circrna基因区域包含的基因突变位点id号、突变位点在基因组上坐标信息、染色体正负链和参考文献的pubmedid号进行展示。本发明还提供了采用上述circbank数据库系统在人类circrna基因库的综合检索应用,对circrna基因库构建全新命名体系,综合运用circrna基因序列、基因注释信息、mirna结合预测、翻译蛋白潜能、序列保守性、序列突变信息和circrna转录后修饰信息,为circrna在生物医学科研中的研究提供检索和预测。本发明circbank数据系统主要包含以下几方面主要功能:(1)对14万中人的circrna基因进行了全新的科学命名,有利于circrna研究规范和传承;(2)提供circrna基因基本特征注释信息;(3)提供circrna序列检索提取功能;(4)提供预测了circrna结合mirna的信息;(5)提供circrna翻译蛋白潜能的预测评估;(6)提供circrna基因序列保守性分析结果;(7)提供circrna转录后修饰信息。本发明的circbank数据库系统引入circrna来源基因的信息并结合转录起始信息,可直观的从circrna名称上了理解更多circrna的信息,如上面的hsa_circ_0007534在我们circbank中对应的名称是hsa_circddx42_005,从该名称中我们就可以得到该circrna来源于人ddx42基因,转录顺序为第5号circrna。大大提高了circrna名称的可读性和信息量;此外,本发明的circbank数据系统从circrna基本基因注释、序列保守性、circrna-mirna互作,翻译潜能、基因突变和rna修饰信息等6大维度对每个circrna进行全面注释,是真正的circrna大型综合数据系统。本发明circbank数据库系统具有如下优点:1、通过本发明circbank数据系统的circrna命名模块,可直观看出circrna来源宿主基因的名称,一致性好。对于新发现的circrna也适用于本命名系统,如hsa_circhipk3_001,表示来源于蛋白编码基因hipk3的001号circrna。目前国际上使用的circbase数据库的命名则采用阿拉伯数字,如hsa_circ_0021592,可读性比较差,单从名称很难看出该circrna来自hipk3的001号circrna;2、circbank数据系统综合分析了所有人circrna与小鼠circrna序列间保守性。一般认为物种间保守性高的circrna往往有更重要的生物学功能,本系统利用序列比对技术对所有人跟小鼠的circrna的进行了分析,并在系统中进行了注明。方面使用者检索查询保守性高的circrna,国内外尚未出现该功能;3、circbank数据库采用miranda和targetscan两种算法对所有人类circrna进行了mirna结合位点预测,通过该系统可检索每个人circrna结合mirna的情况。采用两种以上的算法在预测准确度上更高;4、结合最新最稳定的计算机数据库技术,架构circbank数据管理系统,保障数据快速稳定检索和分析,采用mysql进行数据管理,采用dbconnector、datareader/writer等进行数据模型处理,用户使用检索界面则采用人机交互层(interactionlayer)技术,实现用于各类数据检索和分析请求;通过利用本发明circbank数据系统工具可以加速科研工作者的研究进度,越来越多circrna研究成果出现,也会日益扩展circbank数据系统本身的信息量,使得circbank预测分析系统更准确。为研究circrna在人类疾病中的诊断和治疗带来帮助。附图说明图1为本发明circbank数据库系统的运行架构图;图2为六个模块在circbank中数据架构图;图3为circbank数据库系统命名方式;图4为circrna基因基本特征注释信息示意图;图5为circrna序列检索提取功能展示的序列图;图6为circrna结合mirna信息示意图;图7为circrna基因序列保守性分析示意图;图8为circrna详细信息检索circbankid反馈结果示意图;图9为circrna详细信息检索microrna反馈结果示意图。具体实施方式下面将结合说明书附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明的circbank数据库实现了对circrna基因构建了全新命名体系,综合了circrna基因序列、基因注释信息、mirna结合预测、翻译蛋白潜能、序列保守性、序列突变信息和circrna转录后修饰等信息,是人类circrna基因的综合检索系统。该circrna基因信息系统,汇集了前沿的大数据挖掘技术,为circrna在生物医学科研中的研究提供便利的检索和预测方法,通过该系统可加速circrna生物医学科研的进展。实施例一种circbank数据库系统,其由三部分组成,最底层为数据持久层(datapersistencelayer),采用mysql数据库作为数据管理系统,在磁盘上保存了生物信息记录、数据文件及系统日志文件,如circrnasdatafile、mirnasdatafile、logfile等;中间层为数据模型层(modellayer),提供与数据库连接及数据处理接口,完成来自上层的业务请求,实现对业务逻辑的处理,如dbconnector、datareader/writer等;最上层为人机交互层(interactionlayer),为用户提供各种功能接口,包括各级菜单和各种图形界面组件,交互层接受用户请求,对请求进行分析和分发,最后对处理结果进行展示或保存为一格式的文件;所述circbank数据系统的运行架构如图1所示;所述circbank数据系统包括circrna科学命名模块、circrna-mirna结合预测分析模块、circrna保守性分析模块、circrna的m6a修饰信息模块、circrna突变分析模块、circrna蛋白翻译潜能分析模块;其中各个模块在circbank中数据架构如图2所示;1.circrna全新科学命名方式对于circbank数据库系统命名方式如图3所示,采用如下命名规则:(1)命名基本格式:物种_circ基因名_三位阿拉伯数字,如hsa_circhipk3_001;(2)一个基因名只对应一个circrna时,则命名为:物种_circ基因名_001;(3)同一基因名对应多个circrna时,三位阿拉伯数字的规则,主要依据转录起始和终止靠前的的原则来排列,谁先转录谁排前,同时转录看谁先终止;(4)针对正链来源的circrna,依据circrna坐标起点数值从左到右、小到大排列顺序,排在最前的命名为001,依次002……;(5)针对负链来源的circrna,依据circrna坐标起点数值从右到左、从大到小排列顺序,排在前面的命名为001,依次002……;(6)遇到转录起始终止坐标完全一致但序列长度不一致的circrna时,三位阿拉伯数字前加大写v,依据序列从长到短,依次v001,v002……;(7)同一基因名对应既有正链又有负链来源的circrna时,按以上规则先命名正链的circrna再命名负链的;(8)如果circrna没有对应的基因名,则按对应的染色体来命名,数字按5位阿拉伯数字计数如下表1所示:表1染色体坐标正/负链转录本号基因名称chr11:33307958-33369559+nm_005734na则命名为:hsa_circ_chrll_00001;2.circrna基因基本注释信息如图4所示,通过网页直接展示circrna相关基本注释信息,如circbankid号,宿主基因名称(hostgenesymbol),circbaseid号,对应转录本编号(besttranscript),circrna基因在染色体上的坐标信息(position),基因间区域(annotation),circrna序列长度(length)。3.circrna序列检索提取功能如图5所示,circrna序列检索提取功能,网页上直接提供对应circrna的成熟序列。4.circrna结合mirna的信息如图6所示,采用miranda和targetscan两种算法预测circrna与mirna之间的配对关系,使得结果更为准确。5.circrna翻译蛋白潜能的预测评估如下表2所示,通过蛋白翻译预测算法工具(cpat:coding-potentialassessmenttool),进行预测circrna的编码潜能:表26.circrna基因序列保守性分析如图7所示,通过序列对比分析,提供人circrna对应保守的小树circrna序列。7.circrna转录后修饰信息如下表3所示,本发明数据系统收录所有报道circrna转录后修饰相关研究的数据:表38.circrna基因突变数据信息如下表4所示,本发明数据系统整合分析了circrna基因位置上包含的人类疾病相关基因突变位点信息,为circrna在疾病研究方面提供最直接参考信息:表4上表4中,mutationid为circrna基因区域包含的基因突变位点id号;mutationgenomeposition为突变位点在基因组上坐标信息;mutationstrand为染色体正负链;pubmedpmid为参考文献的pubmedid号;9.circrna数据库系统运行方式circrna科学命名模块、circrna-mirna结合预测分析模块、circrna保守性分析模块、circrna的m6a修饰信息模块、circrna突变分析模块、circrna蛋白翻译潜能分析模块等六大模块数据主要放在数据模型层,用户通过人机交互层在网页上就可以分别检索六大模块相关的数据信息。(1)主页快捷搜索若用户想查询hipk3基因相关的信息,可在主页搜索框内,输入hipk3基因名称,点击search按钮,随后将返回hipk3基因来源的circrna等信息,如下表5所示:表5上述表5中包含hipk3基因来源的circrnas信息表,每行代表一个circrnas的信息,包含circbank数据库id号,对应circbase数据库的id号,染色体坐标(strand,length),circrna序列长度(length),该circrna可结合的microrna(microrna),基因名称(gene_symbol),对应在小鼠中保守的circrna的id号(conserved_mouse_circrna)。circbankid和microrna列均包含超链接,点击可进入详细界面;(2)circrna详细信息检索若需检索hsa_circhipk3_001这个circrna分子的详细信息,可在“circrna”搜索框中,输入circbankid号hsa_circhipk3_001,点击search按钮,将返回hsa_circhipk3_001相关的列表信息,如下表6所示:表6上述表6中点击circbankid中的hsa_circhipk3_001将返回hsa_circhipk3_001相关的详细信息,如图8所示,包含circrna科学命名模块(basicinformation)、circrna保守性分析模块、circrna的m6a修饰信息模块、circrna突变分析模块、circrna蛋白翻译潜能分析模块。点击mirna将返回circrna-mirna结合预测分析模块信息,如图9所示,主要是hsa_circhipk3_001可能结合的mirna。本发明的circbank数据系统利用mysql、dbconnector和人机交互等计算机技术手段实现circrna数据综合管理和检索分析功能,具有如下优点:1.circrna全新科学命名系统,有利于circrna研究规范和传承;2.circrna基因基本特征注释信息,全面可靠;3.circrna序列检索提取功能,方便直观;4.circrna结合mirna的信息,综合两种算法,更准确;5.circrna翻译蛋白潜能的预测评估,算法可靠,更准确;6.circrna基因序列保守性分析,全新功能;7.circrna转录后修饰信息,circrna最前沿的研究领域;8.circrna基因突变信息整合,第一次将人类疾病相关突变与circrna进行关联,为circrna在疾病方面研究提供第一手参考信息。相对比现有技术,本发明的更多优点如下:circrna数量众多,人类现已发现的circrna数量达到14万多种,如何组织管理这么多的circrna信息,迫切需要一个科学的管理系统。circrna命名方面尚未有统一规范实用的体系,目前已发布的其他系统,要么直接以阿拉伯数字命名,比如circbase数据库:hsa_circ_0007534,虽然可以解决circrna数量多而名字不重叠的问题,但给理解circrna分子带来了困难。而本发明circbank数据库引入circrna来源基因的信息并结合转录起始信息,可直观的从circrna名称上了理解更多circrna的信息,如上面的hsa_circ_0007534在我们circbank中对应的名称是hsa_circddx42_005,从该名称中我们就可以得到该circrna来源于人ddx42基因,转录顺序为第5号circrna。大大提高了circrna名称的可读性和信息量。circrna分子在人体中大量存在,且功能强大,已有研究报道发现,circrna在人类疾病,如肿瘤、老年痴呆和心血管疾病等都存在密切关联。如何阐释circrna在这些疾病中的分子功能和分子机制,为上述疾病的诊断和治疗将带来重要突破。目前已有circrna数据库都功能单一,只针对其中某个方向或其中一部分,很难为全面理解circrna分子特性和功能带来益处。本发明的circbank数据库从circrna基本基因注释、序列保守性、circrna-mirna互作,翻译潜能、基因突变和rna修饰信息等6大维度对每个circrna进行全面注释,是真正的circrna大型综合数据库。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1