一种用于癌症风险评估的设备和系统的制作方法
本申请涉及医疗领域.,特别是涉及一种用于癌症风险评估的设备和系统。
背景技术:
癌症是威胁人类生命健康的重大疾病,因此对于癌症的早期诊断和预防性治疗越来越引起社会的关注。
癌症存在广泛威胁性,因此对于癌症的早诊时机显得尤为重要。现有的最先进的pet-ct技术可以发现早期>2mm的肿瘤细胞。但pet-ct还有另一个致命缺陷——无法发现不能聚集放射性的氟代脱氧葡萄糖(fdg)癌细胞,或聚集了fdg的正常细胞与癌细胞重叠,这样会得出错误的结论。另外pet-ct的扫描存在致癌风险。所以,在已经发现2mm的癌细胞(109细胞数),对于超早期预防的概念还是存在不足,并且对于尚未患上癌症但已具有癌症高危风险的患者,也不能提前做到预判。
针对上述的现有技术中存在的不能尽早诊断出患者的癌症疾病以及不能对患者的癌症风险进行预判的技术问题,目前尚未提出有效的解决方案。
技术实现要素:
本公开的实施例提供了一种用于癌症风险评估的设备和系统,以至少解决现有技术中存在的现有技术中存在的不能尽早诊断出患者的癌症疾病以及不能对患者的癌症风险进行预判的技术问题。
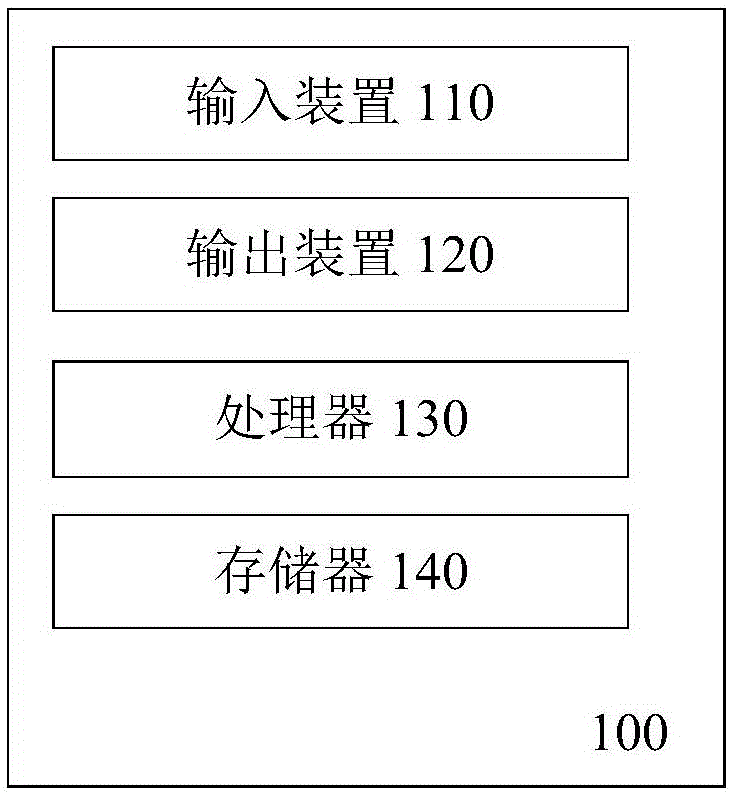
根据本公开实施例的一个方面,提供了一种用于癌症风险评估的设备,包括:输入装置,用于接收用户输入的信息;输出装置,用于向用户输出信息;处理器;以及存储器,与所述处理器连接,用于为所述处理器提供处理以下处理步骤的指令:从输入装置接收用于评估评估对象的癌症风险系数的参数;利用基于结构方程模型的计算模型,根据所述输入的参数,计算评估对象的癌症风险系数;以及通过所述输出装置输出所述评估对象的癌症风险系数。
根据本公开实施例的另一方面,还提供了一种用于癌症风险评估的系统,包括终端设备和服务器。所述终端设备配置用于接收用户输入的用于评估评估对象的癌症风险系数的参数,并将所述参数发送至所述服务器。以及所述服务器配置用于执行以下操作:从所述终端设备接收所述参数;利用基于结构方程模型的计算模型,根据所述输入的参数,计算评估对象的癌症风险系数;以及向所述终端设备发送所述评估对象的癌症风险系数。
在本公开实施例中,通过基于结构方程模型的计算模型,对输入的参数进行计算,从而确定癌症分享系数,达到了今早确诊癌症疾病以及预先评估癌症风险的目的,进而解决了现有技术中存在的不能尽早诊断出患者的癌症疾病以及不能对患者的癌症风险进行预判的技术问题。
附图说明
此处所说明的附图用来提供对本公开的进一步理解,构成本申请的一部分,本公开的示意性实施例及其说明用于解释本公开,并不构成对本公开的不当限定。在附图中:
图1是根据本公开实施例1所述的用于癌症风险评估的设备的示意图;
图2是根据本公开实施例2所述的用于癌症风险评估的系统的示意图;以及
图3是根据本公开实施例所述的结构方程模型的示意图。
具体实施方式
为了使本技术领域的人员更好地理解本公开的技术方案,下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚;完整地描述。显然,所描述的实施例仅仅是本公开一部分的实施例,而不是全部的实施例。基于本公开中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本公开保护的范围。
需要说明的是,本公开的说明书和权利要求书及上述附图中的术语“第一”;“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本公开的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程;方法;系统;产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程;方法;产品或设备固有的其它步骤或单元。
实施例1
图1示出了根据本实施例所述的用于癌症风险评估的设备100的示意图。参考图1所示,该设备100包括:输入装置110,用于接收用户输入的信息;输出装置120,用于向用户输出信息;处理器130;以及存储器140,与所述处理器连接,用于为所述处理器提供处理以下处理步骤的指令:从输入装置110接收用于评估评估对象的癌症风险系数的参数;利用基于结构方程模型的计算模型,根据所述输入的参数,计算评估对象的癌症风险系数;以及通过所述输出装置120输出所述评估对象的癌症风险系数。
正如前面所述的,现有的pet-ct医疗技术在确诊患者患上癌症时,往往是已经发现机体形成肿瘤,不能满足超早期的肿瘤预警概念,对于尚未患上癌症但是有癌症风险的患者,更不能提前做到预判。
有鉴于此,本实施例提出了利用基于结构方程模型的计算模型,根据输入的用于进行癌症风险评估的参数,计算评估对象的癌症风险系数的设备。
结构方程模型是一种非常通用的、主要的线性统计建模技术。结构方程模型是利用联立方程组求解,它没有很严格的假定限制条件,同时允许自变量和因变量存在测量误差。因此结构方程分析能同时处理多个因变量,并可比较及评价不同的理论模型。与传统的探索性因子分析不同,在结构方程模型中,我们可以提出一个特定的因子结构,并检验它是否吻合数据。
从而,本实施例利用结构方程模型对多个参数进行分析,从而能够比较准确地预测评估对象的癌症风险系数。解决了现有技术中存在的不能尽早诊断出评估对象的癌症疾病以及不能对评估对象的癌症风险进行预判的技术问题。
可选地,所述输入的参数包括由以下7个参数子集构成的参数集合,其中
第一参数子集包括以下各参数中的至少一项参数:睡眠的规律性;工作的规律性;饮食的规律性;运动的规律性;以及排便的规律性,
第二参数子集包括以下各参数中的至少一项参数:情绪状态;压力状态;焦虑状态;以及抑郁状态,
第三参数子集包括以下各参数中的至少一项参数:睡眠状态;入睡时间;夜间醒来的问题的严重性;早醒;总睡眠时间;总睡眠质量;白天情绪;白天身体功能;以及白天嗜睡情况,
第四参数子集包括以下各参数中的至少一项参数:体重指数;排便规律性;大便性状;口气;三餐规律性;夜宵情况;饮食内容;吸烟;饮酒;以及饮茶,
第五参数子集包括以下各参数中的至少一项参数:有氧运动时间;运动累计时间;高强度体育锻炼频率;中等强度体育锻炼频率;以及低强度活动频率,
第六参数子集包括评估对象涉及以下所述的至少一项药物因素、理化因素或职业因素:未经处理或轻度处理矿物油;铝生产;2-萘胺;中子辐射;镍化合物;n'-亚硝基降烟碱;4-(n-甲基亚硝胺基)-1-(3-吡啶基)-1-丁酮;中式咸鱼;室外空气污染;含颗粒物的室外空气污染;画家;油漆工;粉刷工;3,4,5,3',4'-五氯联苯;2,3,4,7,8-五氯二苯并呋喃;五氯苯酚;非那西汀;丙烯酰胺;阿霉素;α-氯化甲苯和苯甲酰氯的混合物;雄激素;类固醇;艺术玻璃,玻璃容器和压制器皿制造;阿扎胞苷;氨基甲酸乙酯;双氯乙亚硝脲;沥青;敌菌丹;碳电极制造;三氯乙醛;水合氯醛;氯霉素;1-(2-氯乙基)-3-环己基-1-亚硝基脲;4-氯-邻-甲苯胺;氯脲霉素;顺铂;含碳化钨的钴金属;杂酚油;环戊二烯并[cd]芘;4,4'-二氯二苯三氯乙烷;二嗪磷;二苯并[a,h]蒽;二苯并[a,j]吖啶;二苯并[a,l]芘;二氯甲烷;狄氏剂和可代谢为狄氏剂的艾氏剂;硫酸二乙酯;硫酸二甲酯;二甲氨基甲酰氯;二甲基甲酰胺;多溴联苯;盐酸甲基苄肼;1,3-丙烷磺内酯;四氯乙烯;四氟乙烯;7,8-氧化苯乙烯;溴乙烯;氟乙烯;1,2-二甲基肼;环氧氯丙烷;生物质燃料;家用燃料燃烧的室内排放;二溴乙烷;油炸;缩水甘油;草甘膦;美发师或理发师;在导致内源性亚硝化条件下摄入的硝酸盐或亚硝酸盐;联氨;磷化铟;2-氨基-3-甲基咪唑[4,5-f]喹啉;无机铅化合物;马拉硫磷;2-巯基苯并噻唑;5-甲氧基补骨脂素;甲磺酸甲酯;n-乙基-n-亚硝基脲;6-硝基联苯;氮芥;1-硝基芘;2-硝基甲苯;n-甲基-n'-硝基-n-亚硝基胍;n-甲基-n-亚硝基脲;n-亚硝基二乙胺;n-亚硝基二甲胺;非砷杀虫剂;石油炼制;吡格列酮;替尼泊苷;四溴双酚a;3,3′,4,4′-四氯偶氮苯;1,2,3-三氯丙烷;磷酸三(2,3-二溴丙基)酯;引用高于65℃的很热的饮料;涉及昼夜节律打乱的轮班工作;碳化硅晶须;以及摄入红肉;以及
第七参数子集包括反映抑郁程度和焦虑程度的以下各参数中的至少一项参数:抑郁情绪;有罪感;自杀;入睡困难;睡眠不深;早醒;工作和兴趣;迟缓;激越;精神焦虑;躯体性焦虑;胃肠道症状;全身症状;性症状;疑病;体重减轻;自知力;焦虑心境;紧张;害怕;失眠;认知功能;抑郁心境;躯体性焦虑;感觉系统症状;心血管系统症状;呼吸系统症状;胃肠消化道症状;生殖、泌尿系统症状;植物神经系统症状;与人谈话时的表现。
其中,以上参数涉及用户的生活、心理以及工作等方面。也就是说,根据实施例提供的设备,可以根据涉及用户的生活、心理以及工作等方面的具体参数,评估用户的癌症风险系数。从而提供了一种预测癌症风险系数的新的角度和途径。
并且,在具体实施过程中,以上参数可以通过调查问卷的方式从用户那里获取。例如,说明书后面的附录中附上了调查问卷的具体实例。
具体地,图3示出了结构方程模型的计算模型的示意图。该计算模型涉及4个变量,即自变量x、与自变量x对应的外生潜变量ξ、因变量y以及与因变量y对应的内生潜变量η。
其中,外生潜变量ξ为不受其他任何变量的影响,而仅仅影响其他变量。并且该变量不能直接观测,只能根据观测的自变量x进行推测。
内生潜变量η为总是受到至少一个其他变量的影响的变量。并且该变量不能直接观测,只能根据观测的因变量y进行推测。
从而,由于上面所述的参数子集比较全面地涵盖了评估癌症风险所涉及的各个方面,因此本实施例利用以上参数作为自变量的输入参数,可以基于结构方程模型对癌症风险系数进行统计。
可选地,利用基于结构方程模型的计算模型,根据所述输入的参数,计算评估对象的癌症风险系数的操作包括:
利用所述计算模型的以下计算公式,计算患者的癌症风险系数:
x=λxξ+δ(1)
y=λyη+ε(2)
η=bη+гξ+ζ(3)
z=wty(4),
其中,公式(1)和公式(2)为所述计算模型的观测模型的方程,公式(3)为所述计算模型的结构模型的方程,并且公式(1)为用于针对自变量的观测模型的方程,公式(2)为针对因变量的观测模型,公式(4)为表示所述癌症风险系数与因变量之间的关系的方程,并且其中
x表示作为自变量的所述输入的参数、ξ表示与自变量x对应的外生潜变量、y表示作为因变量的内生观测变量、η表示与因变量对应的内生潜变量以及z表示癌症风险系数,并且λx、λy、δ、ε、b、г以及ζ分别为各自线性方程的参数,w为与y对应的权重向量。
在癌症的风险系数的评估过程中,很多诱发癌症的因素,例如心理、职业以及生活习惯等因素,都是难以直接准确测量的。这种因素称为潜变量(latentvariable)。因此只能用一些外显指标(observableindicators),去间接测量这些潜变量。传统的统计方法不能有效处理这些潜变量,而结构方程模型则能同时处理潜变量及其指标。因此,本实施例的技术方案运用结构方程模型来评估癌症风险系数,可以有效地处理评估过程中涉及的潜变量因素,从而使得设计出的模型,更加符合实际评估工作的需要,也能够更加准确地预测癌症的风险系数。
进一步地,公式(1)展开为以下方程式:
x1至x64表示从所述7个参数子集中选取的64个输入参数,ξ1至ξ9表示9个外生潜变量,分别用于表示以下各项的分值:生活规律性、情绪状态、睡眠状态、饮食营养、运动习惯、药物因素、理化因素、职业因素以及社会心理因素;以及λx1,1至λx64,9和δ1至δ9为线性运算的系数。
也就是说,在本结构方程模型的设计过程中,将生活规律性、情绪状态、睡眠状态、饮食营养、运动习惯、药物因素、理化因素、职业因素以及社会心理因素这9项作为外生潜变量来进行设计。也就是说,这9项因素能够对自变量以及内生潜变量构成影响,是确定癌症风险的本初的因素。而这种设计显然是与癌症的病因分析相符合的。因此将这9项因素作为外生潜变量,能够准确地预测用户的癌症风险系数。
进一步地,公式(2)展开为以下方程式:
y1至y32表示因变量y的32个元素,并且η1至η7表示与因变量y对应的内生潜变量,并且λy1,1至λy32,7和ε1至ε32为线性运算的系数,其中,y1至y32为选自以下7个参数子集的32个参数:
第一参数子集包括以下各参数中的至少一项参数:肿瘤全外显子组;肿瘤全基因组;cfdna;ctdna;肿瘤甲基化;肿瘤乙酰化;以及mirna,
第二参数子集包括以下各参数中的至少一项参数:甲胎蛋白;癌胚抗原;ca15-3;癌抗原199;糖链抗原72-4;鳞状细胞癌相关抗原;神经元特异性烯醇化酶;细胞角蛋白19片段;癌抗原ca125;血清ca242;人绒毛膜促性腺激素;糖链抗原ca50;tsgf(恶性肿瘤特异生长因子);人附睾蛋白4(女);以及α-l-岩藻糖苷酶,
第三参数子集包括以下各参数中的至少一项参数:爱泼斯坦-巴尔病毒(eb);幽门螺杆菌;乙型肝炎病毒(慢性感染);丙型肝炎病毒(慢性感染);人免疫缺陷病毒i型(hiv)(感染);人乳头瘤病毒16,18,31,33,35,39,45,51,52,56,58,59型(hpv);人嗜t淋巴细胞病毒i型(htlv-i);卡波氏肉瘤疱疹病毒(kshv);华支睾吸虫(感染);麝后睾吸虫(感染);埃及血吸虫(感染);疟疾(高度流行地区恶性疟原虫感染引起的);人乳头瘤病毒68型(hpv);以及默克尔细胞多瘤病毒(mcv),
第四参数子集包括以下各参数中的至少一项参数:cd3+cd4-cd8-;cd3+cd4+cd8-(辅助性/诱导性t细胞);cd3+cd4-cd8+(细胞毒/抑制性t细胞);cd3+cd4+cd8+(双阳性t细胞);cd3+cd19-(总t细胞);cd3+cd19+;cd3-cd19+(b细胞);cd3+(cd16+cd56)-;cd3+(cd16+cd56)+(非hla依赖细胞毒t细胞);cd3-(cd16+cd56)+(自然杀伤细胞);cd3+dr-(静止t细胞);cd3+dr+(活化t细胞);cd3-dr+;cd3+cd25-(静止t细胞);cd3+cd25+(活化t细胞);cd3-cd25+;cd4+cd8+;以及lymphocyte(淋巴细胞);
第五参数子集包括以下各参数中的至少一项参数:促泌乳素;雌二醇;孕酮;促卵泡激素;睾酮;促黄体激素;促肾上腺皮质激素;垂体催乳素(prl);以及游离睾酮(ft),
第六参数子集包括以下各参数中的至少一项参数:超声影像;低剂量ct;mri;胃镜;以及肠镜,
第七参数子集包括以下各参数中的至少一项参数:谷丙转氨酶;谷草转氨酶;谷草转氨酶/谷丙转氨酶;总蛋白;白蛋白;球蛋白;白蛋白/球蛋白;碱性磷酸酶;谷酰胺转肽酶;总胆红素;直接胆红素;间接胆红素;胆碱酯酶;前白蛋白;血肌酐;尿酸;尿素;葡萄糖;甘油三酯;胆固醇;高密度脂蛋白;低密度脂蛋白;钙;磷;镁;钠;钾;氯;总二氧化碳;总胆汁酸;超敏c反应蛋白;肌酸激酶;肌酸激酶-mb;α-l-岩藻糖苷酶;转铁蛋白;以及视黄醇结合蛋白,
以及η1至η7分别指示以下7个方面的分值:基因水平、肿瘤标志物、病毒感染、免疫功能、代谢指标、激素水平、现代影像。
在结构方程模型的定义中,内生潜变量仍然是不可观测的潜在变量,但是内生潜变量又能够决定因变量。因此在本结构方程模型的设计中,将基因水平、肿瘤标志物、病毒感染、免疫功能、代谢指标、激素水平、现代影像的分值作为内生潜变量。一方面,这7个因素属于潜在的因素,不易直接观测;另一方面,这7个因素又受到外生潜变量(即前面所述的9向参数)的影响。因此选取这7个因素作为内生潜变量,既符合结构方程模型的定义,也符合癌症病因的分析。并且这7个因素能够由化验获得的参数来推测(上面所述的7个参数自己),从而可以通过选取适当的可观测的因变量来完成结构方程模型。
由于模型的自变量和因变量都是可调查和可观测的对象。因此有利于结构方程模型的样本采集和训练。
所述公式(3)展开为以下方程式:
其中b1,1至b7,7、γ1,1至γ7,9和ζ1至ζ7为线性运算的系数。并且可选地
可选地,公式(4)展开为以下方程式:
z=w1y1+w2y2+w3y3+w4y4+w5y5+w6y6+w7y7。其中,w1至w7为预先设置的分别与y1至y7对应的权重值。
从而,根据以上公式,本实施例所述的设备利用基于结构方程模型的计算模型,可以准确的计算出评估对象的癌症风险系数,从而解决了现有技术中存在的不能尽早诊断出评估对象的癌症疾病以及不能对评估对象的癌症风险进行预判的技术问题。
实施例2
图2示出了根据本实施例2所述的评估癌症风险的系统200的示意图。其中图2与图1的区别,仅在于图2是利用网络系统实现对癌症风险的评估。
具体地,系统200包括终端设备210和服务器220。其中,所述终端设备配置用于接收用户输入的用于评估评估对象的癌症风险系数的参数,并将所述参数发送至所述服务器;以及所述服务器,配置用于执行以下操作:从所述终端设备接收所述参数;利用基于结构方程模型的计算模型,根据所述输入的参数,计算评估对象的癌症风险系数;以及向所述终端设备发送所述评估对象的癌症风险系数。
从而,本实施例利用终端设备210和服务器220实现了用于评估癌症风险的系统200。本实施例的有益效果可以参考实施例1中的陈述,在此,不再赘述。
可选地,所述输入的参数包括由以下7个参数子集构成的参数集合,其中
第一参数子集包括以下各参数中的至少一项参数:睡眠的规律性;工作的规律性;饮食的规律性;运动的规律性;以及排便的规律性,
第二参数子集包括以下各参数中的至少一项参数:情绪状态;压力状态;焦虑状态;以及抑郁状态,
第三参数子集包括以下各参数中的至少一项参数:睡眠状态;入睡时间;夜间醒来的问题的严重性;早醒;总睡眠时间;总睡眠质量;白天情绪;白天身体功能;以及白天嗜睡情况,
第四参数子集包括以下各参数中的至少一项参数:体重指数;排便规律性;大便性状;口气;三餐规律性;夜宵情况;饮食内容;吸烟;饮酒;以及饮茶,
第五参数子集包括以下各参数中的至少一项参数:有氧运动时间;运动累计时间;高强度体育锻炼频率;中等强度体育锻炼频率;以及低强度活动频率,
第六参数子集包括评估对象涉及以下所述的至少一项药物因素、理化因素或职业因素:未经处理或轻度处理矿物油;铝生产;2-萘胺;中子辐射;镍化合物;n'-亚硝基降烟碱;4-(n-甲基亚硝胺基)-1-(3-吡啶基)-1-丁酮;中式咸鱼;室外空气污染;含颗粒物的室外空气污染;画家;油漆工;粉刷工;3,4,5,3',4'-五氯联苯;2,3,4,7,8-五氯二苯并呋喃;五氯苯酚;非那西汀;丙烯酰胺;阿霉素;α-氯化甲苯和苯甲酰氯的混合物;雄激素;类固醇;艺术玻璃,玻璃容器和压制器皿制造;阿扎胞苷;氨基甲酸乙酯;双氯乙亚硝脲;沥青;敌菌丹;碳电极制造;三氯乙醛;水合氯醛;氯霉素;1-(2-氯乙基)-3-环己基-1-亚硝基脲;4-氯-邻-甲苯胺;氯脲霉素;顺铂;含碳化钨的钴金属;杂酚油;环戊二烯并[cd]芘;4,4'-二氯二苯三氯乙烷;二嗪磷;二苯并[a,h]蒽;二苯并[a,j]吖啶;二苯并[a,l]芘;二氯甲烷;狄氏剂和可代谢为狄氏剂的艾氏剂;硫酸二乙酯;硫酸二甲酯;二甲氨基甲酰氯;二甲基甲酰胺;多溴联苯;盐酸甲基苄肼;1,3-丙烷磺内酯;四氯乙烯;四氟乙烯;7,8-氧化苯乙烯;溴乙烯;氟乙烯;1,2-二甲基肼;环氧氯丙烷;生物质燃料;家用燃料燃烧的室内排放;二溴乙烷;油炸;缩水甘油;草甘膦;美发师或理发师;在导致内源性亚硝化条件下摄入的硝酸盐或亚硝酸盐;联氨;磷化铟;2-氨基-3-甲基咪唑[4,5-f]喹啉;无机铅化合物;马拉硫磷;2-巯基苯并噻唑;5-甲氧基补骨脂素;甲磺酸甲酯;n-乙基-n-亚硝基脲;6-硝基联苯;氮芥;1-硝基芘;2-硝基甲苯;n-甲基-n'-硝基-n-亚硝基胍;n-甲基-n-亚硝基脲;n-亚硝基二乙胺;n-亚硝基二甲胺;非砷杀虫剂;石油炼制;吡格列酮;替尼泊苷;四溴双酚a;3,3′,4,4′-四氯偶氮苯;1,2,3-三氯丙烷;磷酸三(2,3-二溴丙基)酯;引用高于65℃的很热的饮料;涉及昼夜节律打乱的轮班工作;碳化硅晶须;以及摄入红肉;以及
第七参数子集包括反映抑郁和焦虑程度的以下各参数中的至少一项参数:抑郁情绪;有罪感;自杀;入睡困难;睡眠不深;早醒;工作和兴趣;迟缓;激越;精神焦虑;躯体性焦虑;胃肠道症状;全身症状;性症状;疑病;体重减轻;自知力;焦虑心境;紧张;害怕;失眠;认知功能;抑郁心境;躯体性焦虑;感觉系统症状;心血管系统症状;呼吸系统症状;胃肠消化道症状;生殖、泌尿系统症状;植物神经系统症状;与人谈话时的表现。
其中,以上参数涉及用户的生活、心理以及工作等方面。也就是说,根据实施例提供的设备,可以根据涉及用户的生活、心理以及工作等方面的具体参数,评估用户的癌症风险系数。从而提供了一种预测癌症风险系数的新的角度和途径。
并且,在具体实施过程中,以上参数可以通过调查问卷的方式从用户那里获取。
具体地,图3示出了结构方程模型的计算模型的示意图。该计算模型涉及4个变量,即自变量x、与自变量x对应的外生潜变量ξ、因变量y以及与因变量y对应的内生潜变量η。
其中,外生潜变量ξ为不受其他任何变量的影响,而仅仅影响其他变量。并且该变量不能直接观测,只能根据观测的自变量x进行推测。
内生潜变量η为总是受到至少一个其他变量的影响的变量。并且该变量不能直接观测,只能根据观测的因变量y进行推测。
从而,由于上面所述的参数子集比较全面地涵盖了评估癌症风险所涉及的各个方面,因此本实施例利用以上参数作为自变量的输入参数,可以基于结构方程模型对癌症风险系数进行统计。
可选地,利用基于结构方程模型的计算模型,根据所述输入的参数,计算评估对象的癌症风险系数的操作包括:
利用所述计算模型的以下计算公式,计算患者的癌症风险系数:
x=λxξ+δ(1)
y=λyη+ε(2)
η=bη+гξ+ζ(3)
z=wty(4),
其中,公式(1)和公式(2)为所述计算模型的观测模型的方程,公式(3)为所述计算模型的结构模型的方程,并且公式(1)为用于针对自变量的观测模型的方程,公式(2)为针对因变量的观测模型,公式(4)为表示所述癌症风险系数与因变量之间的关系的方程,并且其中
x表示作为自变量的所述输入的参数、ξ表示与自变量x对应的外生潜变量、y表示作为因变量的内生观测变量、η表示与因变量对应的内生潜变量以及z表示癌症风险系数,并且λx、λy、δ、ε、b、г以及ζ分别为各自线性方程的参数,w为与y对应的权重向量。
在癌症的风险系数的评估过程中,很多诱发癌症的因素,例如心理、职业以及生活习惯等因素,都是难以直接准确测量的。这种因素称为潜变量(latentvariable)。因此只能用一些外显指标(observableindicators),去间接测量这些潜变量。传统的统计方法不能有效处理这些潜变量,而结构方程模型则能同时处理潜变量及其指标。因此,本实施例的技术方案运用结构方程模型来评估癌症风险系数,可以有效地处理评估过程中涉及的潜变量因素,从而使得设计出的模型,更加符合实际评估工作的需要,也能够更加准确地预测癌症的风险系数。
进一步地,公式(1)展开为以下方程式:
x1至x64表示从所述7个参数子集中选取的64个输入参数,ξ1至ξ9表示9个外生潜变量,分别用于表示以下各项的分值:生活规律性、情绪状态、睡眠状态、饮食营养、运动习惯、药物因素、理化因素、职业因素以及社会心理因素;以及λx1,1至λx64,9和δ1至δ9为线性运算的系数。
也就是说,在本结构方程模型的设计过程中,将生活规律性、情绪状态、睡眠状态、饮食营养、运动习惯、药物因素、理化因素、职业因素以及社会心理因素这9项作为外生潜变量来进行设计。也就是说,这9项因素能够对自变量以及内生潜变量构成影响,是确定癌症风险的本初的因素。而这种设计显然是与癌症的病因分析相符合的。因此将这9项因素作为外生潜变量,能够准确地预测用户的癌症风险系数。
进一步地,公式(2)展开为以下方程式:
y1至y32表示因变量y的32个元素,并且η1至η7表示与因变量y对应的内生潜变量,并且λy1,1至λy32,7和ε1至ε32为线性运算的系数,其中,y1至y32为选自以下7个参数子集的32个参数:
第一参数子集包括以下各参数中的至少一项参数:肿瘤全外显子组;肿瘤全基因组;cfdna;ctdna;肿瘤甲基化;肿瘤乙酰化;以及mirna,
第二参数子集包括以下各参数中的至少一项参数:甲胎蛋白;癌胚抗原;ca15-3;癌抗原199;糖链抗原72-4;鳞状细胞癌相关抗原;神经元特异性烯醇化酶;细胞角蛋白19片段;癌抗原ca125;血清ca242;人绒毛膜促性腺激素;糖链抗原ca50;tsgf(恶性肿瘤特异生长因子);人附睾蛋白4(女);以及α-l-岩藻糖苷酶,
第三参数子集包括以下各参数中的至少一项参数:爱泼斯坦-巴尔病毒(eb);幽门螺杆菌;乙型肝炎病毒(慢性感染);丙型肝炎病毒(慢性感染);人免疫缺陷病毒i型(hiv)(感染);人乳头瘤病毒16,18,31,33,35,39,45,51,52,56,58,59型(hpv);人嗜t淋巴细胞病毒i型(htlv-i);卡波氏肉瘤疱疹病毒(kshv);华支睾吸虫(感染);麝后睾吸虫(感染);埃及血吸虫(感染);疟疾(高度流行地区恶性疟原虫感染引起的);人乳头瘤病毒68型(hpv);以及默克尔细胞多瘤病毒(mcv),
第四参数子集包括以下各参数中的至少一项参数:cd3+cd4-cd8-;cd3+cd4+cd8-(辅助性/诱导性t细胞);cd3+cd4-cd8+(细胞毒/抑制性t细胞);cd3+cd4+cd8+(双阳性t细胞);cd3+cd19-(总t细胞);cd3+cd19+;cd3-cd19+(b细胞);cd3+(cd16+cd56)-;cd3+(cd16+cd56)+(非hla依赖细胞毒t细胞);cd3-(cd16+cd56)+(自然杀伤细胞);cd3+dr-(静止t细胞);cd3+dr+(活化t细胞);cd3-dr+;cd3+cd25-(静止t细胞);cd3+cd25+(活化t细胞);cd3-cd25+;cd4+cd8+;以及lymphocyte(淋巴细胞);
第五参数子集包括以下各参数中的至少一项参数:促泌乳素;雌二醇;孕酮;促卵泡激素;睾酮;促黄体激素;促肾上腺皮质激素;垂体催乳素(prl);以及游离睾酮(ft),
第六参数子集包括以下各参数中的至少一项参数:超声影像;低剂量ct;mri;胃镜;以及肠镜,
第七参数子集包括以下各参数中的至少一项参数:谷丙转氨酶;谷草转氨酶;谷草转氨酶/谷丙转氨酶;总蛋白;白蛋白;球蛋白;白蛋白/球蛋白;碱性磷酸酶;谷酰胺转肽酶;总胆红素;直接胆红素;间接胆红素;胆碱酯酶;前白蛋白;血肌酐;尿酸;尿素;葡萄糖;甘油三酯;胆固醇;高密度脂蛋白;低密度脂蛋白;钙;磷;镁;钠;钾;氯;总二氧化碳;总胆汁酸;超敏c反应蛋白;肌酸激酶;肌酸激酶-mb;α-l-岩藻糖苷酶;转铁蛋白;以及视黄醇结合蛋白,
以及η1至η7分别指示以下7个方面的分值:基因水平、肿瘤标志物、病毒感染、免疫功能、代谢指标、激素水平、现代影像。
在结构方程模型的定义中,内生潜变量仍然是不可观测的潜在变量,但是内生潜变量又能够决定因变量。因此在本结构方程模型的设计中,将基因水平、肿瘤标志物、病毒感染、免疫功能、代谢指标、激素水平、现代影像的分值作为内生潜变量。一方面,这7个因素属于潜在的因素,不易直接观测;另一方面,这7个因素又受到外生潜变量(即前面所述的9向参数)的影响。因此选取这7个因素作为内生潜变量,既符合结构方程模型的定义,也符合癌症病因的分析。并且这7个因素能够由化验获得的参数来推测(上面所述的7个参数自己),从而可以通过选取适当的可观测的因变量来完成结构方程模型。
由于模型的自变量和因变量都是可调查和可观测的对象。因此有利于结构方程模型的样本采集和训练。
所述公式(3)展开为以下方程式:
其中b1,1至b7,7、γ1,1至γ7,9和ζ1至ζ7为线性运算的系数。并且可选地
可选地,公式(4)展开为以下方程式:
z=w1y1+w2y2+w3y3+w4y4+w5y5+w6y6+w7y7。其中,w1至w7为预先设置的分别与y1至y7对应的权重值。
从而,根据以上公式,本实施例所述的设备利用基于结构方程模型的计算模型,可以准确的计算出评估对象的癌症风险系数,从而解决了现有技术中存在的不能尽早诊断出评估对象的癌症疾病以及不能对评估对象的癌症风险进行预判的技术问题。
附录:调查问卷
(一)生活规律性
评分______分
(二)情绪状态
评分_______分
1、正常2、较正常3、一般4、不正常5、极不正常
(1)、正常:精神饱满,积极乐观向上,能转化压力,性情开朗。
(2)、较正常:精力较为充沛,有适当压力,能有效解决。
(3)、一般:精力尚可,压力较大,有时难以排解情绪(焦虑,抑郁,狂躁)。
(4)、不正常:精力不济,偶尔焦虑,抑郁或者狂躁易怒。
(5)、极不正常:精神恍惚,经常焦虑,抑郁或者狂躁易怒,恐惧甚至轻生。
参考标准
评价程度:0-不符合;1-有时符合;2-常常符合;3-总是符合
(三)睡眠状况
评分_______分
参考标准:
1)夜间睡眠时间7-9小时为好____________________________
2)以下睡眠问题,是否在过去1个月内每星期至少发生3次在您身上(如无,请选“0”)
(四)饮食营养
评分______分
(五)运动习惯
评分______分
(计算如散步,游泳,球类运动,跑步,太极,瑜伽等有益身体健康活动的总活动量)
参考内容
体育锻炼及膳食(5年前-现在)
以一周计算,进行以下体育锻炼的时间是(只计算每次持续30分钟以上的活动)
(六)药物、理化、职业因素量表
药物、环境理化、职业因素:
评分标准:1-5分
(七)社会心理因素量表
(1)抑郁:
总分超过35分,可能为严重抑郁;
超过20分,可能是轻或中等度的抑郁;
如小于8分,病人就没有抑郁症状。
一般的划界分,hamd17项分别为24分、17分和7分。
(2)焦虑:
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
在本发明的上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
在本申请所提供的几个实施例中,应该理解到,所揭露的技术内容,可通过其它的方式实现。其中,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,单元或模块的间接耦合或通信连接,可以是电性或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可为个人计算机;服务器或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘;只读存储器(rom,read-onlymemory);随机存取存储器(ram,randomaccessmemory);移动硬盘;磁碟或者光盘等各种可以存储程序代码的介质。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!