基于医学知识库的智能分诊决策控制方法及系统与流程
本发明涉及基于医学知识库的智能分诊决策控制方法及系统,尤其涉及物联网设备结合人工智能技术和医学知识库对人体的健康进行智能诊断和决策的方法。
背景技术:
目前,普通大众的一贯思维是:有病去医院就诊或者去药店买自认为可以治病的药物。在医院,有专业的医疗设备对病人做生理病症进行判断,其判断结果辅助专业医生进行开对应的药物。然而,病人需要亲自在专业的医疗设备和专业的医务人员的帮助下才能准确判断病理。而在药店,病人购买自认为对症的药物进行治疗。这种主观的“自认为”通常不能精准的把握病因,不能给出正确全面的病理分析结果,即“药不能完全匹配病症”。抑或者病人通过远程医疗诊断,在医生的帮助下进行分析病理。在中国类似于需要医务人员或者病人参与的医疗方式,屡见不鲜。
随着强“人工智能+”(artificialintelligence,ai)时代的迅猛发展,可穿戴设备、远程医疗检测等物联网设备的应用也日益受到人们的青睐。“ai+健康产业”是研究ai者和医学学者致力于联手研究的热点话题。健康是关乎每个人的生活品质追求的基础,“ai+健康”是提升人们生活质量的助推者。因此,基于医学知识库的智能分诊决策控制对未来智能化、个性化和自动化的医学应用有着重要的市场价值。
技术实现要素:
针对上述医疗方式的不足,即需要人为的过多干预才能对症下药或者人对病症的主观臆断。该系统采用带有优先级的样本采样的角色者-评论家(actor-critic)的双网学习的方法对病人的生理特征,进行实时分类,预测和判断。该系统可以便携、准确和周期性地检测和记录病人的生理病症,通过智能学习模块匹配病症对应的医疗解决方案,并将优选的解决方案通过多种模式报备给用户,实现了无人干预的诊断、实时准确的预测和智能决策的功能。
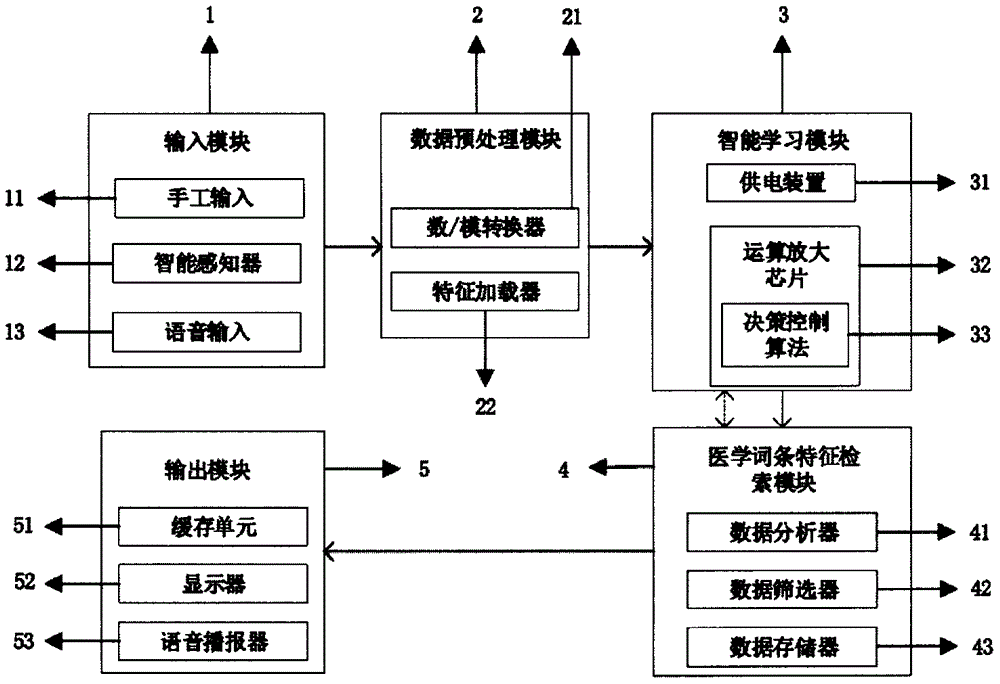
为了实现上述目的,本发明所采取的技术方案是:基于医学知识库的智能分诊决策控制方法及系统,包括输入模块、数据预处理模块、智能学习模块、医学词条特征化检索模块、输出模块、语音模块、智能感知器、数据转换模块、特征加载器、供电装置、运算放大芯片、数据分析器、数据筛选器、数据存储器、缓存单元和显示器。这些微型器件可以嵌入在物联网(iot)设备中,如智能手环等,其特征在于:所述的智能学习模块,采用带有优先级的采样方法进行深度学习来自所述的数据转换模块的特征,其基于医学知识库的特征对新的诊断数据或者检测数据进行实时分类处理;
所述的智能学习模块由供电装置、运算放大芯片和决策控制算法构成;所述的供电装置用于提供智能学习模块的电能支持;所述的运算放大芯片内核由所述的决策控制算法编程控制。
所述的决策控制算法流程如下:
s1:初始化actor和critic网络的权重分别为θπ和θq;初始化actor和critic目标网络的权重θπ′和θq′;
s2:判断当前时刻t是否小于规定的时间周期t,若t<t,则转带有优先级的采样选择算法;算法返回所选择的行为,转s3;否则,转s9;
s3:计算actor和critic函数,观测即时奖赏r;
所述的actor和critic函数,即在深度卷积学习过程中的v值和q值,其由贝尔曼方程式(1)和式(2)得到函数值。
其中,e[.]表示从长期看,所获得的期望的奖励。r是在下一时刻(t+1)的立即回报,pr(.)是转移概率。v函数是系统在当前状态s下采取策略π在转移概率pr(.)下到达下一状态s′所得到的累计奖赏值。q函数是当系统处于状态s,采用相应的行为a的期望折扣累计回报。
actor函数即v函数用于计算当前状态的累计奖赏值,critic函数即q函数用于对actor函数采用该策略的评价。q函数学习的最优策略通过式(3)获得。
s4:将转移样本(s,a,r,s′)放入回放池d中;
所述的回放池d用于将元组(s,a,r,s′)即:当前状态、行为、即刻奖赏和下一状态的值放入回放池,该元组作为样本数据用于后续状态行为选择的参考值,也是学习中经验积累的过程。
s5:根据式(4)计算critic网络在下一时刻的目标值o(s,a):
所述的式(4)为:
o(st+1,at+1)=r+βq(s′,a′)(4)
s6:根据式(5)计算当前critic网络与目标critic网络的时间差分误差(tderror):
δt=o(s,a)-q(st,at)(5)
s7:分别根据式(6)、(7)更新actor和critic网络的参数θπ和θq:
其中,λ0和λ1分别为很小的范围的参数,其范围通常设置为(0,1]。
s8:分别根据式(6)、(7)更新目标actor和目标critic网络的参数θπ′和θq′:
θπ′=μθπ+(1-μ)θπ′(8)
θq′=μθq+(1-μ)θq′(9)
其中μ为调整学习步长的参数,其范围通常设置为(0,1]。
s9:结束;
所述的带有优先级的采样选择算法的步骤如下:
l1:初始化样本回放池d中的每个样本的优先级pk,其中k表示选择第k个样本;
l2:判断d是否为空,若d不为空,则转l3;否则,转l7;
l3:根据式(10)选择转移样本,
其中,|d|表示样本回放池的大小。rk表示第k个样本的即刻奖赏。
l4:根据式(11)更新优先级:
pk(t+1)=pk+f(t,pk)(11)
其中,f(t,pk)表示一个记忆函数,由缓存单元反馈的关于样本pk的访问或者检索频率,其用归一化方式处理后的范围为[0,1]。
l5:根据医学特征词条检索模块的检索缓存记录,将检索结果排序;转l6;
l6:返回选择的行为;
l7:返回初始化的行为a。
所述的医学词条特征化检索模块包含有数据存储器、数据分析器和数据筛选器;所述的医学词条特征化检索模块与智能学习模块连接,并将智能学习模块的输出结果存入数据存储器;所述的数据存储器作为医学词条特征化检索模块的数据匹配资源库;所述的数据分析器结合智能传感器的探测结果和智能学习模块的学习结果进行分析,通过说书的数据筛选器将结果精准定位,向所述的输出模块输出分析匹配的一条或者若干条记录。
所述的数据转换模块包含有数/模转换器和特征加载器。所述的输入模块包含手工输入、智能感知器和语音输入三种模式;其用于对病症的数据感知和搜集。
所述的输出模块包括缓存单元、显示器和语音播报器,所述的缓存模块用于对高频检索的数据进行存储,以便于实时反馈结果给用户;所述的显示器用于对结果的显示;所述的语音播报器用于对检索结果的语音输出,并对响应的解决方案进行输出,如病因、病理和病方。
所述的输入模块与数据转换器连接;所述的数据转换器与智能学习模块连接;所述的智能学习模块与医学词条特征化检索模块连接;所述的医学词条特征化检索模块与输出模块连接。
有益效果:本发明提出基于医学知识库的智能分诊决策控制方法及系统。该系统采用改进的深度卷积神经网络(dnn)算法对医学词条特征进行表征、分类。对病理的决策,采用带有优先级序列的采样规则对角色者-评论家(actor-critic)的双网络进行学习的方法。该系统可以便携、准确和周期性地检测和记录病人的生理病症,通过智能学习模块匹配病症对应的医疗解决方案,并将优选的解决方案通过多种模式报备给用户,实现了无人干预的诊断、实时准确的预测和智能决策的功能。
附图说明
图1是基于医学知识库的智能分诊决策控制方法及系统的连接结构示意图;
图2是基于医学知识库的智能分诊决策控制方法及系统中决策控制算法流程图;
图3是基于医学知识库的智能分诊决策控制方法及系统中带有优先级的采样选择算法流程图;
具体实施方式
下面结合附图以及具体实施方式对本发明进行详细说明。
本发明提供基于医学知识库的智能分诊决策控制方法及系统,如图1所示,包括输入模块1、数据预处理模块2、智能学习模块3、医学词条特征化检索模块4、输出模块5、语音模块13、智能感知器12、数据转换模块21、特征加载器22、供电装置31、运算放大芯片32、数据分析器41、数据筛选器42、数据存储器43、缓存单元51和显示器52。
进一步地,所述的输入模块1包含三种模式的输入,即手工输入11、智能感知器12和语音输入13,三种模式均用于对病症的数据感知和搜集。
进一步地,所述的数据预处理模块2由数模转换器21和特征加载器22构成。所述的特征加载器22是对医学知识库的病理进行标签化,对新的输入样本,即人的生理病症进行转换和初步筛选数据,然后用带有标签的数据作为智能学习模块3的输入,进行抽象特征的提取判断和分类。
进一步地,所述的智能学习模块3由供电装置31、运算放大芯片32和决策控制算法33构成;所述的供电装置31用于提供智能学习模块的电能支持;所述的运算放大芯片32内核由所述的决策控制算法33编程控制。
进一步地,所述的决策控制算法流程如下:
s1:初始化actor和critic网络的权重分别为θπ和θq;初始化actor和critic目标网络的权重θπ′和θq′;
s2:判断当前时刻t是否小于规定的时间周期t,若t<t,则转带有优先级的采样选择算法;算法返回所选择的行为,转s3;否则,转s9;
s3:计算actor和critic函数,观测即时奖赏r;
所述的actor和critic函数,即在深度卷积学习过程中的v值和q值,其由贝尔曼方程式(1)和式(2)得到函数值。
其中,e[.]表示从长期看,所获得的期望的奖励。r是在下一时刻(t+1)的立即回报,pr(.)是转移概率。v函数是系统在当前状态s下采取策略π在转移概率pr(.)下到达下一状态s′所得到的累计奖赏值。q函数是当系统处于状态s,采用相应的行为a的期望折扣累计回报。
actor函数即v函数用于计算当前状态的累计奖赏值,critic函数即q函数用于对actor函数采用该策略的评价。q函数学习的最优策略通过式(3)获得。
s4:将转移样本(s,a,r,s′)放入回放池d中;
所述的回放池d用于将元组(s,a,r,s′)即:当前状态、行为、即刻奖赏和下一状态的值放入回放池,该元组作为样本数据用于后续状态行为选择的参考值,也是学习中经验积累的过程。
s5:根据式(4)计算critic网络在下一时刻的目标值o(s,a):
所述的式(4)为:
o(st+1,at+1)=r+βq(s′,a′)(4)
s6:根据式(5)计算当前critic网络与目标critic网络的时间差分误差(tderror):
δt=o(s,a)-q(st,at)(7)
s7:分别根据式(6)、(7)更新actor和critic网络的参数θπ和θq:
其中,λ0和λ1分别为很小的范围的参数,其范围通常设置为(0,1]。
s8:分别根据式(6)、(7)更新目标actor和目标critic网络的参数θπ′和θq′:
θπ′=μθπ+(1-μ)θπ′(8)
θq′=μθq+(1-μ)θq′(9)
其中μ为调整学习步长的参数,其范围通常设置为(0,1]。
s9:结束;
进一步地,所述的带有优先级的采样选择算法的步骤如下:
l1:初始化样本回放池d中的每个样本的优先级pk,其中k表示选择第k个样本;
l2:判断d是否为空,若d不为空,则转l3;否则,转l7;
l3:根据式(10)选择转移样本,
其中,|d|表示样本回放池的大小。rk表示第k个样本的即刻奖赏。
l4:根据式(11)更新优先级:
pk(t+1)=pk+f(t,pk)(11)
其中,f(t,pk)表示一个记忆函数,由缓存单元反馈的关于样本pk的访问或者检索频率,其用归一化方式处理后的范围为[0,1]。
l5:根据医学特征词条检索模块的检索缓存记录,将检索结果排序;转l6;
l6:返回选择的行为;
l7:返回初始化的行为a。
进一步地,所述的医学词条特征化检索模块4包含有数据分析器41、数据筛选器42和数据存储器43;所述的医学词条特征化检索模块4与智能学习模块3连接,并将智能学习模块3的输出结果存入数据存储器43;所述的数据存储器43作为医学词条特征化检索模块4的数据匹配资源库。
进一步地,输出模块5包括缓存单元51、显示器52和语音播报器53,所述的缓存模块51用于对高频检索的数据进行存储,以便于实时反馈结果给用户;所述的显示器52用于对结果的显示;所述的语音播报器53用于对检索结果的语音输出,并对响应的解决方案进行输出,如病因、病理和病方。
进一步地,所述的输入模块1与数据转换器2连接;所述的数据转换器2与智能学习模块3连接;所述的智能学习模块3与医学词条特征化检索模块4连接;所述的医学词条特征化检索模块4与输出模块5连接。
本发明提供基于医学知识库的智能分诊决策控制方法及系统,其决策控制算法流程图如图2所示,其与所述的决策控制算法步骤一致,这里不再赘述。
本发明提供基于医学知识库的智能分诊决策控制方法及系统中带有优先级的采样选择算法流程图,如图3所示,其与所述的带有优先级的采样选择算法的步骤一致,这里不再赘述。
通过上述方式,本发明基于医学知识库的智能分诊决策控制方法及系统,实时、便捷、智能化为病人实现足不出户、人不干预的病理诊断与治疗,具有广泛的市场应用前景。
上述描述仅作为本发明可实施的技术方案提出,不作为对其技术方案本身的单一限制条件。
- 还没有人留言评论。精彩留言会获得点赞!