自动生成用于实验室仪器的规则的制作方法
相关申请的交叉引用
本申请要求2017年10月26日提交的美国临时申请no.62/577,465的优先权,其全部内容通过引用方式并入本文。
背景技术:
为了诊断疾病或评估受试者的健康,通常将使用一个或多个仪器从受试者收集生物样品以进行评估。例如,实验室可以具有可用于对生物样品执行测试的一系列不同仪器。可以进一步分析和处理这些测试结果以便制定诊断或确定需要附加测试。
在许多情况下,实验室工作人员在生物样品经历测试工作流程时监督生物样品,解释随附的测试结果,并且关于是否需要附加测试做出关键决定。由于这些实验室经常一次测试和分析许多受试者的生物样品,因此可能存在与检验所有这些生物样品所需的实验室工作人员的所有监督相关联的很大负担。
为了减轻这种负担,可以建立处理规则以用于使测试工作流程中的决定自动化。例如,可以建立许多规则,这些规则提出了一组状况或标准,在该组状况或标准下自动证实生物样品的测试结果,使得不需要对该生物样品进行附加测试。然而,单个实验室可以采用数百个或数千个此类规则,并且使用户(例如,实验室工作人员)生成所有这些规则可能类似地是巨大的时间和知识负担。
因此,需要使生成和实现用于测试工作流程的处理规则更容易的方式。这将使测试和评估许多生物样品变得更快,改善任何决定制定的准确性和一致性,并且减小所需的监督量。
本公开的实施方案可单独地和共同地解决这些和其他挑战。
技术实现要素:
本公开中描述的方法、系统和设备的实施方案可以用于自动生成在操作仪器以分析和处理生物样品(例如,针对分析物的存在、不存在或浓度)时使用的处理规则。
本公开的一个实施方案涉及一种方法,包括:执行针对第一多个样品的第一组测试命令;处理第一多个样品以获得第一多个测试结果;以及至少基于输入数据和第一多个测试结果生成一个或多个处理规则。在一个实施方案中,生成规则的步骤由计算机执行。方法还可以由样品处理系统执行,该样品处理系统包括:包括第一数据处理器和第一计算机可读介质的信息管理装置,以及包括第二数据处理器和第二计算机可读介质的控制系统。方法还可以包括:由信息管理装置接收针对第一多个样品的第一组测试命令;由信息管理装置向控制系统提供第一组测试命令;由控制系统接收来自一个或多个仪器的对应于第一组测试命令的第一多个测试结果;由控制系统将第一多个测试结果提供给信息管理装置;由信息管理装置从信息管理装置接收输入数据,由控制系统从信息管理装置接收输入数据;在生成一个或多个处理规则之后,由控制系统从信息管理装置接收针对附加多个样品的附加测试命令;以及在生成一个或多个处理规则之后,由控制系统执行针对附加多个样品的附加测试命令,使得根据一个或多个已生成处理规则在与控制系统通信的一个或多个仪器上处理附加多个样品。
本公开的另一个实施方案涉及一种样品处理系统,包括:数据处理器;以及计算机可读介质,该计算机可读介质包括可由数据处理器执行以执行方法的代码,该方法包括:执行针对第一多个样品的第一组测试命令;处理第一多个样品以获得第一多个测试结果;以及至少基于输入数据和第一多个测试结果生成一个或多个处理规则。样品处理系统还可以包括:包括第一数据处理器和第一计算机可读介质的信息管理装置;以及包括第二数据处理器和第二计算机可读介质的控制系统,该控制系统可通信地耦接到信息管理装置,其中第二数据处理器是数据处理器,其中第二计算机可读介质是计算机可读介质,并且其中执行针对第一多个样品的第一组测试命令包括由控制系统执行从信息管理装置接收的针对第一多个样品的第一组测试命令,使得在与控制系统通信的一个或多个仪器上处理第一多个样品。第一计算机可读介质可以包括代码,该代码可由第一数据处理器执行以致使第一数据处理器执行包括以下的方法:接收针对多个样品的第一组测试命令;以及向控制系统提供第一组测试命令。第二计算机可读介质包括代码,该代码可由第二数据处理器执行以致使第二数据处理器执行包括以下的方法:接收来自一个或多个仪器的对应于第一组测试命令的第一多个测试结果;将第一多个测试结果提供给信息管理装置;从信息管理装置接收输入数据;在生成一个或多个处理规则之后,由控制系统从信息管理装置接收针对附加多个样品的附加测试命令;以及在生成一个或多个处理规则之后,由控制系统执行针对附加多个样品的附加测试命令,使得根据一个或多个已生成处理规则在与控制系统通信的一个或多个仪器上处理附加多个样品。
本公开的另一个实施方案涉及非暂态计算机可读介质,该非暂态计算机可读介质包括可由一个或多个数据处理器执行以实现方法的代码,该方法包括:执行针对第一多个样品的第一组测试命令;处理第一多个样品以获得第一多个测试结果;以及至少基于输入数据和第一多个测试结果生成一个或多个处理规则。
下文将进一步描述本公开的这些和其他实施方案。
附图说明
图1示出了根据本公开的实施方案的样品处理系统的示例性框图。
图2示出了示例性流程图,该流程图示出了根据本公开的实施方案的通过自动生成的处理规则来执行测试的样品处理系统。
图3示出了根据本公开的实施方案的提示的示例性用户界面,该示例性用户界面显示与已生成处理规则相关联的确认请求。
图4示出了示例性流程图,该流程图示出根据本公开的实施方案的处理规则的自动生成。
图5示出了根据本公开的实施方案的用于历史数据的示例性数据结构,该数据结构可以用于识别用来生成处理规则的模式。
图6示出了根据本公开的实施方案的添加到规则集的示例性已生成处理规则。
图7是可用于执行各种实施方案的系统的框图。
具体实施方式
术语“仪器”或“分析器”可以包括能够分析或处理生物样品的任何合适的设备。分析器的示例包括pcr机、流式细胞仪、质谱仪、免疫分析器、血液学分析器、微生物学分析器和/或分子生物学分析器。具体地,免疫分析器可包括其上免疫测定已自动化的仪器。免疫测定法可以指用于基于抗体与抗原的相互作用来确定样品中的分析物的量或浓度的实验室方法。质谱仪可以包括可测量原子和分子的质量和相对浓度,并且可用于阐明分子(诸如肽和其他化学化合物)的化学结构的仪器。
术语“样品”可以指要分析的某物。“样品”包括生物样品或化学样品。“生物样品”可以包括生物体或组织,以及生物来源的任何固体、液体或气体,以及包含生物来源的生物/组织/分析物的任何固体、液体或气体。例如,可以是生物流体的生物样品的示例包括但不限于血液、血浆、血清、或其他体液或排泄物,诸如但不限于唾液、尿液、脑脊液、泪液、汗液、胃肠液、羊水、粘膜液、胸膜液、皮脂油、呼气等。可被认为是生物流体的生物样品的另一个示例是包含与个体相关联的核酸(例如,dna/rna)的溶液。
术语“分析物”可包括其存在、不存在或浓度将根据本公开的实施方案来确定的物质。典型的分析物可包括但不限于有机分子、激素(诸如甲状腺激素、雌二醇、睾丸素、孕酮、雌激素)、代谢物(诸如葡萄糖或乙醇)、蛋白质、胆固醇、脂质、碳水化合物和糖、类固醇(诸如维生素d)、肽(诸如降钙素原)、核酸片段、生物标志物(诸如抗生素,苯二氮之类的药品)、药物(诸如免疫抑制剂药物、麻醉剂、阿片类药物等)、在酶促过程中具有调节作用的分子,诸如启动子、活化剂、抑制剂或辅因子、微生物(诸如病毒(包括ebv、hpv、hiv、hcv、hbv、流行性感冒、诺如病毒、轮状病毒、腺病毒等))、细菌(幽门螺杆菌(h.pylori)、链球菌、mrsa、艰难梭菌(c.diff)、军团菌等)、真菌、寄生虫(疟原虫等)、细胞、细胞组分(诸如细胞膜)、孢子、核酸(诸如dna和rna)等。本公开的实施方案还可以允许同时分析相同类别或不同类别的多种分析物(例如,同时分析代谢物和蛋白质)。在本公开的实施方案中,对特定分析物诸如生物标志物的分析可指示特定状况(例如,疾病)与包含分析物的样品相关联。
术语“测试结果”可以包括相对于生物样品的分析或处理获得的测量值或特定值。测试结果可以由一个或多个仪器确定,或者由从这些仪器获得数据的信息管理装置确定。例如,与被分析的生物样品相关联的测试结果可以是胆固醇的量或浓度。测试结果可能以来自仪器的原始数据的形式,或者可能以从原始数据导出的数据的形式。在一些情况下,与原始数据相比,系统用户可以更容易解释导出数据。
生物样品的“特性”可以包括生物样品的性质。样品的性质可以与样品中的组分(例如,生物体、蛋白质等)的存在、不存在、或数量有关。生物样品的特性也可以与可能或可能不与生物样品相关联的疾病状况有关。例如,生物样品的特性可以包括那些生物样品是否与诸如以下的疾病相关联:老年痴呆症、心脏病、乳腺癌、结肠直肠癌、前列腺癌、卵巢癌、肺癌、胰腺癌、膀胱癌和肝细胞癌。生物样品的特性还可以涉及生物样品的物理性质,诸如生物样品的颜色或外观。
术语“规则集”可以包括用于与测试和处理特定类型的生物样品相关联的自动决定制定的一个或多个处理规则。在一些情况下,可以存在多个规则集,并且每个规则集可以对应于对生物样品执行测试的特定实体(例如,实验室)。处理规则可以包括用于验证样品或标记样品以进行附加测试/审查的规则和阈值。处理规则还可以包括用于处理样品的规则、满足命令所需的检测范围等。
术语“患者信息”可以包括与患者有关的任何合适数据。患者信息可以包括但不限于至少以下类型的信息:人口统计信息(姓名、地址、电话)、生物特征信息、患者id信息(用于标记样品的唯一标识符)、成像信息(x射线、ct、mri、us)、外科手术信息、药物信息(例如,患者正在服用或应当服用的特定药物以及剂量)、账单信息、emr信息、医师生成的信息(例如,生命体征、观察、医学变化)、以及历史患者信息(例如,正在监测的药物水平、慢性疾病信息、有关药物不良反应的信息等)。
术语“测试命令”可以包括用于分析或处理生物样品(例如,经由仪器)的任何合适类型的指令。示例性测试命令可以包括与生物样品相关联的患者信息、请求对生物样品的测试的患者或医疗保健提供者、对生物样品待执行的测试(例如,检测一个或多个特定分析物的存在或不存在)、以及与生物样品相关联的预期处理时间。测试命令还可以指定用于分析生物样品的特定类型的仪器。
术语“仪器”可以包括可作用于样品的任何合适的设备。仪器通常可以在处理样品后产生一个或多个测量值。仪器的示例可以包括免疫分析器、质谱仪、生化分析器、化学分析器、流式细胞仪等。仪器的其他示例可以包括封闭试管等分器、样品存储单元、样品制备单元等。
对生物样品的实验室测试可以由样品处理系统执行,该样品处理系统可以包括可用于自动化测试工作流程的各种方面的控制系统(有时称为“中间件”)。具体地,控制系统可以负责接收命令/指令以进行测试,基于指令确定要使用的适当测试工作流程和仪器,控制仪器的操作,以及分析和处理测试结果。
可以通过规则集中限定的一组可配置处理规则来管理这种自动化,这向每个实验室提供了配置控制系统以在满足某些状况时执行某些动作的能力。单个实验室可以采用数百个或数千个此类规则以便自动化或简化生物样品的测试。仅作为一个示例,一些处理规则可以提出一组状况或标准,在该组状况或标准下自动验证生物样品的测试结果。验证通常是必须在将与生物样品相关联的测试结果返回给请求方(例如,转诊医师或执业医师)之前执行的操作。因此,自动验证规则可以被配置用于自动区分需要附加审查或测试的某些测试结果或生物样品(并标记这些样品)与不需要附加审查或测试的测试结果或样品,并且可以立即返回给请求方。
如果提供了足够的数据,则控制系统可以能够从历史测试结果和对生物样品执行的历史测试(和其他动作)导出模式。控制系统可以使用这些模式来自动生成可被实现以在未来样品测试中自动化决定的处理规则。在一些情况下,已生成处理规则可以包括自动验证规则,这些自动验证规则可以用于通过增加被自动验证并返回给请求方的测试结果的百分比来减小所需的人工监督和审查。
在测试生物样品中使用自动生成的处理规则可以提供许多益处。例如,实验室人员将花费更少的时间来手动配置规则,并且将需要更少的实验室人员来监督对大量样品的测试。此外,手动限定处理规则可以意味着处理规则的有效性取决于编写规则的人的技能水平,并且技能水平之间的较大差异可以意味着与自动生成的处理规则相比,在手动限定的处理规则的有效性中存在巨大变化。另外,自动生成处理规则用作用于使规则集保持最新状态的更好机制(例如,如果特定实验室的测试实践或策略改变)。
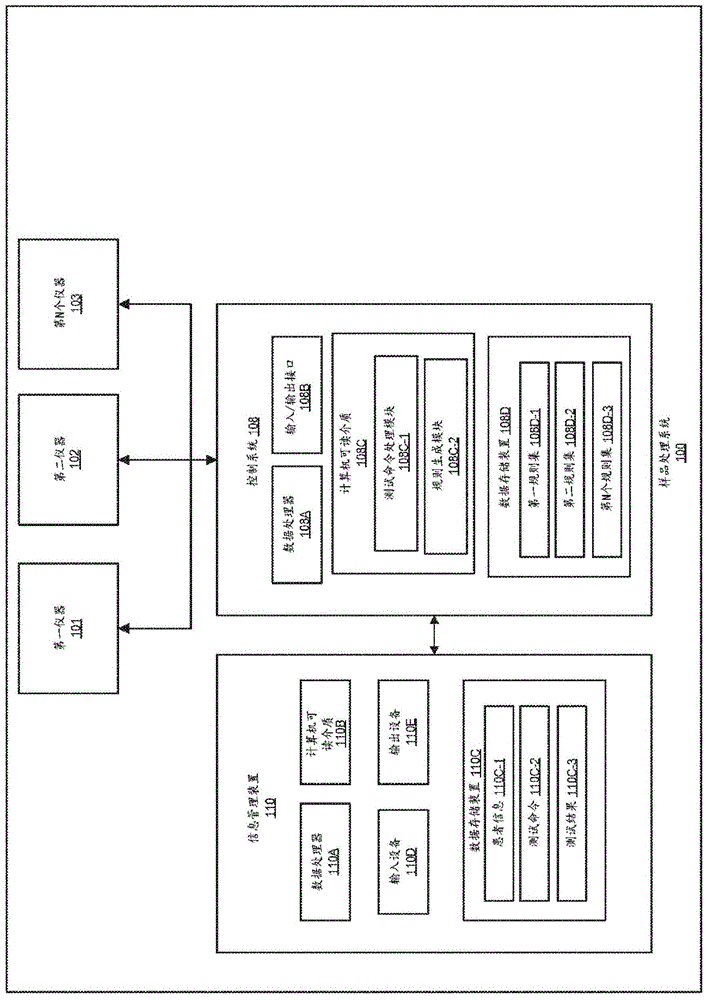
图1示出了根据本公开的实施方案的样品处理系统100的高级框图。在一些实施方案中,样品处理系统100包括多个仪器。多个仪器可以包括第一仪器101、第二仪器102等,一直到第n个仪器103。尽管在图1中示出了三个仪器,但应当理解,在样品处理系统100的其他实施方案中可能存在少于三个仪器或多于三个仪器。
在一些实施方案中,样品处理系统100可以包括控制系统108,该控制系统可以可通信地和可操作地耦接到仪器101、102、103。样品处理系统100还可以包括信息管理装置110。在这些部件中的每一个中可以存在允许在所示的设备和部件之间的数据传输的输入/输出接口。尽管在图1中示出了单独的控制系统108和单独的信息管理装置110,但应当理解在本公开的其他实施方案中,它们可以合并到单个计算机系统中。另外,运行信息管理装置110和控制系统108的软件可以是本地的,或者可以运行一个或多个远程服务器计算机(例如,在云中)。
在一些实施方案中,控制系统108可以控制仪器101、102和103和/或信息管理装置110,和/或向或从这些仪器和/或信息管理装置传输消息和指令。控制系统108可以包括数据处理器108a、输入/输出接口108b、非暂态计算机可读介质108c和数据存储部件108d(耦接到数据处理器108a)。非暂态计算机可读介质108c可包括代码,该代码可由数据处理器108a执行以执行本文所述的功能。尽管控制系统108在图1中被描述为单个实体,但应当理解,控制系统可以存在于分布式系统或基于云的环境中。非暂态计算机可读介质108c可以是第二计算机可读介质。第二计算机可读介质可以包括代码,该代码可由数据处理器108a执行以执行包括以下的方法:a)执行来自信息管理装置的针对第一多个样品的第一组测试命令,使得在与控制系统通信的一个或多个仪器上处理第一多个样品;b)接收来自一个或多个仪器的对应于多个测试命令的第一多个测试结果;c)将第一多个测试结果提供给信息管理装置;d)由控制系统从信息管理装置接收输入数据;e)至少基于输入数据和第一多个测试结果生成一个或多个处理规则;f)从信息管理系统接收针对附加多个样品的附加测试命令;以及h)执行针对附加多个样品的附加测试命令,使得根据一个或多个已生成处理规则在与控制系统通信的一个或多个仪器上处理附加多个样品。
数据处理器108a可以是第二数据处理器,并且可以包括任何合适的数据计算设备或此类设备的组合。示例性数据处理器可包括一起工作以实现期望的功能的一个或多个微处理器。数据处理器108a可包括cpu,该cpu包括至少一个高速数据处理器,该高速数据处理器足以执行用于执行用户和/或系统生成的请求的程序部件。cpu可以是微处理器,诸如amd的athlon、duron和/或opteron;ibm和/或motorola的powerpc;ibm和sony的cell处理器;intel的celeron、itanium、pentium、xeon和/或xscale;和/或类似的处理器。
计算机可读介质108c和数据存储装置108d可以是可存储电子数据的任何合适的一个或多个设备(诸如一个或多个存储器芯片、磁盘驱动器等),其通常使用任何合适的电、光和/或磁操作模式来进行操作。
计算机可读介质108c可包括代码,该代码可由数据处理器108a执行以执行任何合适的方法。在一些实施方案中,计算机可读介质108c可以包括用于测试命令处理模块108c-1和规则生成模块108c-2的代码。在一些实施方案中,测试命令处理模块108c-1可以被配置为接受由控制系统108接收的测试命令(例如,从信息管理装置110),并且处理这些测试命令以发送到仪器以便进行那些测试命令中指定的指令。在一些实施方案中,规则生成模块108c-2可以被配置为根据历史测试结果确定模式,并且基于这些模式自动生成处理规则。在图中,历史测试结果可以被示为存储在信息管理装置110内的测试结果110c-3,但在一些实施方案中,历史测试结果可以存储在不包含任何个人可识别信息的控制系统108内。
数据存储部件108d可以处于控制系统108的内部(如图所示)或外部。数据存储部件108d可以包括一个或多个存储器,包括一个或多个存储器芯片、磁盘驱动器等。数据存储部件108d可以包括各种规则集,诸如第一规则集108d-1、第二规则集108-d2等,一直到第n个规则集108-d3。这些规则集可以包含与仪器的操作有关的处理规则和参数,诸如与分析和处理生物样品相关联的规则。这些规则可以包括不同仪器的检测范围、不同仪器的处理逻辑等。规则可以包括静态规则(例如,在“y”状况下执行“x”动作)和/或动态规则。如上所述,规则集可以包括可用于确定使用哪个仪器或仪器组合来分析或处理生物样品的一个或多个规则。规则可以与生物样品相关联和/或可以合并与特定生物样品无关的数据。
在一些实施方案中,信息管理装置110可以耦接到控制系统108,并且信息管理装置110可以被配置为(i)存储患者信息,(ii)接受生物样品的一个或多个测试命令,以及(iii)从多个仪器101、102、103接收与生物样品相关联的一个或多个测试结果。
信息管理装置110可以包括数据处理器110a(其可以是第一数据处理器)和非暂态计算机可读介质110b。计算机可读介质110b可以包括用于致使数据处理器110a从仪器101、102、103接收生物样品的一个或多个测量值的代码。在一些实施方案中,数据处理器110a还可以将测量值与存储在数据存储装置110c中的数据存储中的患者信息110c-1进行比较,并且在比较后提供输出。计算机可读介质110b还可以包括代码,该代码可由数据处理器110a执行以执行包括以下的方法:接收多个样品的测试命令;并且将测试命令提供给控制系统。数据处理器110a和非暂态计算机可读介质110b可以具有与控制系统108中的数据处理器108a和计算机可读介质108c相同或不同的类型。
在一些实施方案中,信息管理装置110还可以包括数据存储装置110c,其可以存储患者信息110c-1、测试命令110c-2和测试结果110c-3。信息管理装置110还可以包括一个或多个输入设备110d和输出设备110e。输入设备可以包括触摸屏、键盘、指针、麦克风等。输出设备110e可以包括扬声器、显示器和触觉设备。
在一些实施方案中,信息管理装置110可以被配置为将(如由仪器101、102、103确定的)生物样品中的药物或代谢物的存在或不存在与数据存储装置110c中的患者信息110c-1进行比较。作为该比较的结果,可以由信息管理装置110经由耦接到数据处理器110a的输出设备(诸如显示器)提供输出(例如,提供给用户,诸如执业医生)。
输出可以具有任何合适的类型。例如,输出可以与将来自仪器101、102、103的测量值与患者信息110c-1(诸如患者姓名或患者病历号)组合的报告有关。在其他实施方案中,输出可以包括患者的任何或建议的药物与任何测量值的比较结果,或者它可以包括基于从仪器获得的测量值和患者信息110c-1的诊断或推荐。
在一些实施方案中,信息管理装置110可以包括实验室信息系统(lis)或医院信息系统(his)。在一些实施方案中,这些术语可以与信息管理装置110互换使用。在一些实施方案中,控制系统108可以包括用于控制和自动化仪器操作的中间件。
仪器101、102、103可以通过网络直接连接到lis。由仪器生成的数据(例如,测量值)可以被传输到lis或his。通过信息系统接口,lis可以允许在lis与中间件集线器之间进行通信。在一些实现方式中,中间件集线器可以向仪器101、102、103提供附加指令以便创建、取消、或修改供仪器执行的测试命令。在一些实施方案中,中间件集线器可以包括控制系统108,或者可以包括在控制系统108上运行的软件,使得控制系统108具有控制和自动化仪器101、102、103的操作的作用。
在一些实施方案中,规则集(例如,规则集108d-1、108d-2、108d-3)可以各自对应于特定实体(例如,实验室)。因此,具有其多个规则集的控制系统108可以被配置为针对许多实验室处理生物样品的测试。在其他实施方案中,控制系统108可以仅通过单个实验室来实现,并且因此在数据存储装置108d中可能仅有一个规则集可用。在一些实施方案中,可以为不同的样品类型、不同的患者类型等创建不同的规则集。
在一些实施方案中,规则集(例如,规则集108d-1、108d-2、108d-3)可以包含一组处理规则。处理规则的示例可以包括状况规则,其指定在满足一些预先指定状况时要执行的动作。例如,状况规则可以指定如果仪器执行测试并且所得值小于、等于或大于阈值,则执行特定动作。动作的示例可以是标记测试结果并且不将结果发送到lis(例如,信息管理装置)。因此,特定状况规则的示例可以是“如果测试t的结果值大于阈值x,则标记结果并将其不发送到lis”。
规则集可以具有与其相关联的任何数量的规则。在一些实施方案中,规则集可以具有数百个或甚至数千个限定的规则。这些处理规则可以使得工作流程的部分由样品处理系统100的部件执行。这些规则允许采用样品处理系统100的实体(例如,实验室)自动化其工作流程,减少其工作人员,并且改善分析和处理生物样品所需的周转时间。每个实验室可以有其自身规则集,该自身规则集具有非常特定于该实验室的规则。这些规则可以限定与在该实验室处执行的生物样品测试相关联的阈值、测试菜单、例外工作流程等。
由实验室采用的示例性规则集也可以指定自动证实状况,这些自动证实状况用于在如果满足某些状况(例如,诸如阈值)时允许测试结果进入工作流程的下面阶段。在规则集中指定的各种自动证实状况的组合“效果”可以取决于有多少个自动证实规则(例如,已经自动生成多少个不同的自动证实规则)以及自动证实状况针对这些规则有多严格而变化。例如,在一些实施方案中,由实验室采用的规则集可能导致实验室自动将约80%的测试结果发送到信息管理装置(例如,图1所示的信息管理装置110),其中剩余的20%的结果被标记以由实验室工作人员进行进一步检查。在一些实施方案中,由实验室采用的规则集的自动证实率可以为95%或更高,这意味着实验室自动将约95%或更多的测试结果发送到信息管理装置。
因此,在各种实施方案中,自动证实率可以取决于规则而从5%变化为98%,这些规则可以经由本文所述的方法自动生成和/或由用户(例如,实验室工作人员)指定。然而,整个规则集越依赖于由用户指定的规则,自动证实率将越取决于用户的规则编写技能水平以及自动证实状况的严格程度。在一些实施方案中,用户可以能够使用sql或各种软件工具来编写要添加到规则集的规则,这些软件工具提供图形用户界面和/或规则库(具有预构建规则)以用于轻松地构建、改变和自定义规则。然而,使用户生成进入规则集的所有规则可能涉及巨大的时间和知识负担;限定和实现规则集内的规则可能会花费数周和数小时的会议和研讨会。使ai或自动化算法基于过去的测试结果和动作自动生成规则可以减轻负担并且使得更容易增加自动证实率。
图2示出了如何自动生成处理规则并将其合并到规则集中的系统流程图。
在框212处,信息管理装置206(例如,图1所示的信息管理装置110)可以接收测试命令并将其发送到控制系统204,该控制系统将在框214处接收该测试命令。该命令可以源自于用户,该用户通常将是医学专业人员(例如,医师或护士)、实验室工作人员、或患者(例如,在患者以其名义命令进行测试的情况下,诸如经由在线平台)。在一些实施方案中,可以在信息管理装置206处生成测试命令。例如,用户可以通过经由信息管理装置206的界面输入测试命令来向信息管理装置206供应测试命令。在一些实施方案中,用户可以使用图1所示的输入设备110d来输入测试命令。在一些实施方案中,测试命令可以与信息管理装置206分开生成并且被发送到信息管理装置206。例如,可以在电子病历(emr)软件或系统中生成测试命令,并且将其发送到信息管理装置206。测试命令可能以多种方式发送到控制系统204。例如,信息管理装置206可以经由局域网(lan)或广域网(wan)可通信地耦接到控制系统204。另选地,信息管理装置206可以经由互联网可通信地耦接到控制系统204,如果控制系统204是使用分布式计算或云集群来实现的,则这可能特别有用。应当注意,在一些实施方案中,可以在控制系统204处生成测试命令,并且因此可以在没有图2所示的框212的情况下执行工作流程。
在框214处,控制系统204可以接收测试命令。在框216处,控制系统204可以通过将测试命令发送到一个或多个仪器202来执行测试命令。测试命令可以指示一个或多个仪器202分析和处理生物样品。
在框218处,仪器202可以基于所接收的测试命令来处理生物样品。在一些实施方案中,可能必须事先向仪器202供应生物样品。例如,用户可能必须手动地将生物样品馈送到仪器中。
在框220处,仪器202可以通过处理生物样品来生成测试结果,并且然后将这些测试结果发送到控制系统204。
在框222处,控制系统204可以接收测试结果。控制系统204然后可以将测试结果提供给信息管理装置206。
在框224处,信息管理装置206可以接收测试结果。可以将测试结果提供给用户(例如,医师或患者)以进行审查。
在框226处,信息管理装置206可以从用户接收输入数据。信息管理装置206可以将该输入数据发送到控制系统204。输入数据可以是可响应于样品的测试结果的任何合适数据。例如,在一些实施方案中,输入数据可能以针对被测试并且接收到其测试结果的相同样品的新测试命令的形式。在其他实施方案中,输入数据可能以从许多测试命令导出的数据的形式。例如,来自已经收到测试命令的样品的许多测试命令的数据可用作输入数据。
在框228处,控制系统204可以接收从信息管理装置206发送的输入数据。在一些实施方案中,用户可以直接向控制系统204提供输入数据,而不是通过信息管理装置206。因此,可以在没有图2所示的框226的情况下执行工作流程。
在框230处,控制系统204可以自动生成处理规则以添加到规则集。关于图4进一步详细描述处理规则的自动生成。在一些实施方案中,在生成处理规则之后,控制系统204可以将已生成处理规则发送到信息管理装置206。在框232处,信息管理装置206可以任选地生成确认请求并且将其显示给用户。确认请求可以向用户通知已生成处理规则并且征询用户的批准以便制定已生成处理规则。在一些实施方案中,确认请求可能以提示的形式显示,诸如图3所示的提示。
在一些实施方案中,在框234处,信息管理装置206可以从用户接收对已生成处理规则的确认。信息管理装置206可以向控制系统204通知批准了将已生成处理规则添加到规则集。
在框236处,信息管理装置206可以接收附加测试命令并且将其发送到控制系统204,该控制系统将在框238处接收该附加测试命令。
在框238处,控制系统204可以通过已添加到规则集的已生成处理规则来执行附加测试命令(如果规则与附加测试命令相关)。
在框240处,仪器202可以接收附加测试命令并且根据附加测试命令处理生物样品。结果可以被发送到控制系统204以用作生成处理规则的附加数据点。因此,图2中描绘的工作流程可以作为迭代循环,其中控制系统204连续地生成要添加到规则集的处理规则,并且随着它接收越来越多的测试结果而更新现有处理规则,这些测试结果用作在生成处理规则中使用的输入数据点。
图3示出了显示针对已生成处理规则的确认请求的提示的示例性用户界面。
如图所示,可能存在输出设备110e(例如,作为信息管理装置110)的一部分,该输出设备提供与信息管理装置110进行交互的用户(诸如执业医生或实验室工作人员)可看到的显示器。在一些实施方案中,输出设备110e可以是可显示用户界面(诸如用户界面110e-1)的监视器或屏幕。
用户界面110e-1可以用于向与确认请求(诸如图2中的框232处生成的确认请求)相关联的用户显示提示302。换句话说,提示302可以用于向用户通知已生成处理规则,并且从用户征询确认以将该规则实现到规则集中以用于使未来测试中做出的决定自动化。
例如,在所示的图中,提示302向用户通知样品处理系统的控制系统已检测到,当从分析器“x”获得的测试结果或测量值低于阈值“z”时,通常会在分析器“y”上重新运行由分析器“x”测试的“w”型样品。控制系统可以基于与对“w”型样品进行的许多过去测试相关联的历史数据来确定这一点。因此,控制系统可以生成处理规则以便在分析器“y”上自动重新运行“w”型样品。
如果用户选择“是”按钮304,则控制系统可以将已生成处理规则保存到规则集中,其中它将在未来测试中生效。例如,在用户针对先前示例中的提示选择“是”按钮304之后,则针对测量值低于阈值“z”的由分析器“x”测试的下一个“w”型样品,控制系统将自动命令分析器“y”对该样品执行测试而无需来自用户的任何附加手动输入。
如果用户选择“否”按钮306,则控制系统将不会将已生成处理规则保存到规则集中。在一些实施方案中,一旦用户选择“否”按钮306,该特定的已生成处理规则将不会被再次呈现给用户,除非用户经由将提供未实现的被拒绝处理规则的列表的用户界面来访问设置。在一些实施方案中,即使用户拒绝已生成处理规则,控制系统也可能以特定时间间隔(例如,在x天后,如果再次取消则在y天后,如果又一次取消则在z天后)继续向用户提示该特定处理规则。
图4示出了流程图,该流程图示出根据本公开的实施方案的处理规则的自动生成。具体地,图4从控制系统的角度示出了处理规则的生成。图4中描述的流程图的框可以在本质上类似于图2中示出的框222、228、230和238。
在框402处,针对被测试的每个生物样品,控制系统可以从测试该生物样品的一个或多个仪器接收测试结果。通常,测试结果将通过执行与该生物样品相关联的已接收测试命令来获得。控制系统可以直接从仪器接收这些测试结果。
在框404处,针对已被测试的每个生物样品,控制系统可以接收输入数据(例如,由用户(诸如执业医生)通过信息管理装置来输入),该输入数据描述基于样品的特性、测试参数和与样品相关联的测试结果而做出的动作或决定。例如,样品的测试结果可以包括被确定为小于阈值的值。由于该值小于阈值,因此可以标记测试结果以用于进一步审查。关于用于进一步审查的标记的信息可以被认为是输入数据的示例。另选地,可以标记测试结果以用于使用不同仪器的附加测试。与该样品相关联的输入数据将指示测试结果被标记以用于审查或附加测试,特别是因为测量值被确定为小于阈值。换句话说,与特定生物样品相关联的输入数据可以通知如何获得样品的测试结果,如何解释测试结果,以及由于该测试样品而执行了哪些动作。在一些情况下,输入数据可以是非常广泛的(例如,诸如如果基于测试结果和某些状况的满足执行了一系列动作“x”、“y”和“z”),并且可以按时间顺序记录使用样品和测试结果来执行的操作。在其他实施方案中,输入数据可以包括与已经输入到信息管理装置中的特定类型的第二多个样品相对应的第二多个测试命令。例如,信息管理装置110可以自动识别出第二多个样品是先前由系统运行的样品,但作为重新测试或回流测试过程的一部分被重新运行(例如,样品可以被绑定到相同患者)。当测试该特定类型的样品时,样品处理系统可以从该数据自动推断出操作样品处理系统的实体、重新测试或反射测试可以是合适的。
在框406处,针对已被测试的每个生物样品,控制系统可以将样品的测试结果与和该样品相关联的输入数据(例如,动作日志)组合或相关联。可以将组合数据添加到历史数据420,该历史数据用作过去生物样品、其历史测试结果、以及结合这些历史测试结果采取的任何动作的数据库。在一些情况下,样品的输入数据可能已经包括与该样品相关联的测试结果,这意味着控制系统可以仅保存输入数据。作为更具体的示例,考虑以下场景:患者可能经常为了胆固醇水平对其血液(例如,生物样品)进行测试。针对已经执行该测试的每个患者,历史数据420可以包括该患者的胆固醇水平以及基于所测量的胆固醇水平而采取的动作。例如,历史数据420可以将患者“x”描述为具有异常高的胆固醇水平“y”,这导致通过仪器“z”执行另一个测试以确认胆固醇测量值。通过不断地向历史数据添加新测试结果,可以基于从历史时间跨度获得的数据或者通过动态考虑新测试结果来限定模式。
在框408处,控制系统可以查看历史数据420,以便确定通过针对具有类似特性的生物样品或测试结果采取的动作而观察的模式。换句话说,控制系统对于对过去结果采取的动作进行回顾性审查以便导出处理规则。例如,控制系统可以将与为了胆固醇水平而测试血液的实例相关联的所有数据作为一个组进行查看,以便识别与基于胆固醇水平采取的动作相关联的模式。在一些实施方案中,控制系统可以查看可用数据的整个时间跨度。在一些实施方案中,由于实验室策略和实践可以随时间推移而变化,因此控制系统可以查看上一个月或两个月的数据以识别模式。在一些实施方案中,所使用的时间跨度可以取决于与样品一起使用的仪器或测试。例如,实验室在一天中可以执行数百次胆固醇水平测量,这意味着从上一个月聚集的数据可能足以辨别任何显著模式。然而,对于更深奥或罕见的测试,将需要更长的时间跨度以便收集更多的数据点以用于提取有意义的模式。可以基于模式逻辑422来识别模式,该模式逻辑可以被配置为在各种类型的场景中识别模式,这些场景中的一些将在下面解释。
模式的识别可以使用任何合适的机器学习算法。此类机器学习算法可以包括无监督学习过程,包括但不限于k均值、层次聚类、神经网络等。
在一个场景中,如果在测试结果或测量值高于或低于给定阈值时常规地采取某些动作,则可以确定模式。例如,可能经常发生以下情况:大于100的胆固醇测量值被标记以用于附加审查,而低于该100阈值的胆固醇量通常被验证。可以通过查看关于不同患者的测试结果所采取的动作来确定该阈值(例如,胆固醇为110或120的患者被标记用于附加审查,而胆固醇为85或95的患者被验证)。此模式可以用于支持在框410处的生成自动验证处理规则,其中100以下的任何胆固醇测试值被自动验证。验证仅是可采取的动作的一个示例。当满足状况时,可以进行测试工作流程中通常执行的任何其他动作,诸如使用其他仪器以基于测试结果对样品进行附加测试。除了阈值的恒定值外,还可以替代地使用值带。例如,如果测量值在第一值带内(例如,在80与100之间),则其可以被认为是可接受的。然而,如果值在该带外,则其可以被认为是不可接受的,在这种情况下,在框410处生成的处理规则可以重新测试样品或标记结果以供执业医师审查。同时,可以存在附加带,诸如第二值带(例如,在40与140之间),其中在第二值带外的测量值远超出可归因于仪器误差的可接受带。在值在第二带之外的情况下,已生成处理规则可以指定向人员通知仪器需要校准或者使用不同仪器对样品进行替代性测试。在一些实施方案中,模式和所生成的处理规则可以是更复杂的。例如,处理规则可以基于对多个不同分析物的测试结果进行组合,可以使用多个不同仪器来获得这些测试结果。
在另一个场景中,如果常规地一起采取某些动作或满足某些状况,则可以确定模式。例如,可能是以下情况:如果采取一组特定的三个动作,则通常将执行第四动作(例如,对于为该样品类型命令“x”、“y”和“z”测试的用户,他们也总是命令测试“a”)。通过足够的数据,可以确定这种类型的关系并将其自动实现到处理规则中。
一旦基于模式生成了处理规则,在框412处,控制系统可以发送与已生成处理规则相关联的确认请求。例如,该确认请求可以转到信息管理装置,该信息管理装置将向用户(例如,负责为规则集选择处理规则的实验室人员或管理员)显示。如果用户接受建议的处理规则,则确认批准将被发送回控制系统,并且在框414处,控制系统将已接受的处理规则添加到规则集424中,其中它可以在未来样品测试中被检索和实现。
总而言之,图4所示的过程可以具有改善用于在测试工作流程中做出自动决定的规则集的质量的许多特征。例如,可以保存来自过去样品测试的历史数据并且将其用于创建初始规则集,该初始规则集可以被自动创建或者可以涉及用户输入以使得用户可以接受或拒绝建议的规则。在一些情况下,规则可能是“模糊的”并且阈值不必一定是硬性界限。例如,即使控制系统确定在样品满足特定标准的情况中的98%(并且不是100%)下采取了某些动作,仍然可以检测到该关系。此外,控制系统可以不断地将当前数据(例如,针对正在对样品执行的新测试结果)添加到现有历史数据,并且使用当前数据可以改善添加到规则集的已生成规则的复杂性。
图5示出了根据本公开的实施方案的用于历史数据的示例性数据结构,该数据结构可以用于识别用来生成处理规则的模式。
如前所述,针对与患者相关联的样品的测试,历史数据420可以包括来自任何测试的测试结果以及与测试相关执行的动作。图5示出了与两个样品关联的记录,这些记录示出了如何可以存储历史数据420的数据结构的示例性实施方案,以便允许测试结果和执行的任何动作单独地组合成使得会更轻松地识别用于处理规则的自动生成的模式的格式。这仅是如何可以存储历史数据420的单个示例性实施方案;出于促进简化处理规则的生成的目的,存在存储历史数据420的其他方式。
在所示的图中,历史数据420中的记录502对应于已针对患者1测试的样品(例如,血液)。实际上,历史数据420中的记录可以各自具有其唯一标识符(例如,以确认没有重复记录),而出于hipaa的目的,可以移除所有患者的识别信息。在一些实施方案中,记录502可以指示为患者分析了哪种类型的样品,诸如血液、唾液等。在一些实施方案中,记录502可以用作对样品执行的动作的时间顺序记录,并且所列出的动作可能已经按照从上到下的顺序执行。
例如,如记录502所指示,仪器“x”可能已用于测量血液中的hdl胆固醇水平。该测试返回为60的hdl胆固醇水平。此后(或甚至同时),仪器“x”也可能已用于测量血液中的ldl胆固醇。测试返回为120的ldl胆固醇水平。在获得这两个测试结果之后,可以看出,患者1的样品最终由实验室工作人员验证。
记录504示出了针对与患者2相关联的样品(例如,血液)执行的类似测试阵列。仪器“x”用于测量患者2的hdl胆固醇,并且该测试返回为60的hdl胆固醇水平。此后(或甚至同时),仪器“x”也可能已用于测量血液中的ldl胆固醇,从而返回为160的ldl胆固醇水平。然而,并非在这两个测试后由实验室工作人员立即对样品进行验证(就像记录502中的情况一样),而是该样品被标记以用于附加审查。仪器“y”然后用于再次测量ldl胆固醇,从而返回为150的ldl胆固醇水平。在该测试之后,通知与患者相关联的医师(再次,患者/医师的姓名在此处可以不是必要的—仅在这种情况下已通知医师的指示)。
记录的此数据结构可以允许快速识别模式。例如,可以对历史数据420中的所有记录执行搜索以识别包括以下三个测试的所有记录:“使用仪器‘x’,测量hdl胆固醇”、“使用仪器‘x’,测量ldl胆固醇”、以及“使用仪器‘y’,测量ldl胆固醇”,并且记录504将为结果的一部分(在这种情况下,即使搜索指定三个测试必须按该顺序进行)。因此,搜索中的所有记录将是其中所有这三个测试都被执行的实例,这可以对识别用于处理规则生成的模式是有用的(例如,总是伴随这三个特定测试执行第四测试)。作为另一个示例,可以对历史数据420中的所有记录执行搜索以识别包括测试“使用仪器‘x’,测量ldl胆固醇”的所有记录,并且可以查看该测试的结果以及在该测试之后立即执行的动作以识别模式。
从这些示例中可以看出,在一些实施方案中,记录的数据结构将按时间顺序包含:(1)对样品执行的测试以及来自该测试的结果;和(2)在测试之间或之后执行的动作。这些描述的复杂度可能会有变化,并且可能包括完整的描述、伪代码、代码等。在一些实施方案中,记录还可以包含执行某些动作的注释或原因(例如,由实验室工作人员供应)。例如,记录504可以指示样品“被标记以用于附加审查”,特别是因为ldl胆固醇过高或超过阈值。这可以提供可用于识别模式以生成处理规则的附加信息。
图6示出了根据本公开的实施方案的添加到规则集的示例性已生成处理规则。
具体地,该图示出了可能已经使用包括来自图5的记录502和504的一组记录来导出的示例性处理规则。如果在图5中的记录502和504中指示的场景表示封装在历史数据420中包含的许多记录中的频繁发生事件,则可能是这种情况。
例如,在记录502中,仪器“x”测量处于120的ldl胆固醇,这导致由实验室工作人员进行验证。然而,在记录504中,ldl胆固醇的仪器“x”测量值处于160,这导致样品被标记以用于附加审查。如果在许多记录中,当由仪器“x”测量的ldl胆固醇高于140时标记样品以用于审查,而当由仪器“x”测量的ldl胆固醇低于140时验证样品,则这可能导致生成处理规则602。在处理规则602下,如果仪器“x”测量的ldl胆固醇超过140,则标记样品以用于附加审查。否则,验证样品。
作为另一个示例,在记录504中,仪器“y”用于测量处于150的ldl胆固醇,这将导致通知医师。可能是以下情况:在许多记录中,如果仪器“y”报告ldl胆固醇水平过高,则通知医师。例如,仪器“y”可以是非常准确但昂贵的用于测量ldl胆固醇的方法,从而使其非常适合辅助确认性ldl胆固醇测量。因此,在仪器“y”报告高ldl胆固醇水平的场景中,可能已经执行了广泛的测试,并且应当通知医师而不是标记样品以用于附加审查或执行更多测试。此模式可以导致生成处理规则604。在处理规则604下,如果仪器“y”测量的ldl胆固醇水平高于140,则通知医师。否则,验证样品。
作为又一个示例,在两个记录502和504中,仪器“x”用于测量hdl胆固醇和ldl胆固醇两者。可能是以下情况:在许多记录中,仪器“x”用于测量hdl和ldl胆固醇两者,因为解释这两种测量是重要的。因此,如果仪器“x”也用于测量hdl胆固醇,则仪器“x”应当总是用于测量ldl胆固醇。此模式可以导致生成处理规则606。在处理规则606下,如果仪器“x”用于测量hdl胆固醇,则还将发送使仪器“x”测量ldl胆固醇的指令。
图7示出了系统,该系统包括数字计算机700和可操作地耦接(其可以包括电子耦接)到数字计算机700的测量模块701。
在此示例中,数字计算机700可以包括各种典型的计算机部件,包括可操作地耦接在一起的系统总线704、一个或多个磁盘驱动器705、ram706和处理器707。取决于实施方案的确切性质,还可以存在其他部件。图7还示出了显示器708、键盘702和鼠标703。在一些实施方案中,这些部件和其他部件也可以是数字计算机的一部分。
系统还可以具有用于测量样品中的选定目标的特性(例如,已知或未知)的测量模块701。取决于被选择来测量目标响应的测量方法,该测量模块可以在本发明的不同实施方案之间变化。例如,根据一个实施方案,测量模块可以对样品进行pcr分析并且因此可以是实时pcr装置。实时pcr装置是可商购的。
在本发明的一个实施方案中,将样品放置在测量模块701中,其中处理样品并且测量来自样品的选定目标的特性(例如,数量)。然后,沿系统总线704将此数据(例如,测试结果)转移到数字计算机700中,并且可以使用处理器707将适当的处理规则应用于测试结果。指令致使处理器707执行处理规则(如上所述),这些处理规则可以存储在计算机可读介质(诸如ram706或磁盘驱动器705)上。然后可以在显示器708或其他输出设备(例如,打印机)上显示来自测试结果或已生成处理规则的输出。例如,已生成处理规则可以显示在显示器708上或以某种其他方式输出。
如上所述,在一些实施方案中,计算机可读介质可以存储或包括代码,该代码可以由处理器执行以实现用于根据已生成处理规则来分析和处理样品的方法。在一个实施方案中,方法可以包括:执行针对第一多个样品的第一组测试命令,处理第一多个样品以获得第一多个测试结果,以及至少基于输入数据和第一多个测试结果生成一个或多个处理规则。在一些实施方案中,该方法可以由样品处理系统执行,该样品处理系统包括:包括第一数据处理器和第一计算机可读介质的信息管理装置;以及包括第二数据处理器和第二计算机可读介质的控制系统,该控制系统可通信地耦接到信息管理装置。在一些实施方案中,由处理器执行以实现方法的代码还可以致使处理器执行以下的步骤:由信息管理装置接收针对第一多个样品的第一组测试命令;由信息管理装置向控制系统提供第一组测试命令;由控制系统接收来自一个或多个仪器的对应于第一组测试命令的第一多个测试结果;由控制系统将第一多个测试结果提供给信息管理装置;由信息管理装置从信息管理装置接收输入数据,由控制系统从信息管理装置接收输入数据;在生成一个或多个处理规则之后,由控制系统从信息管理装置接收针对附加多个样品的附加测试命令;以及在生成一个或多个处理规则之后,由控制系统执行针对附加多个样品的附加测试命令,使得根据一个或多个已生成处理规则在与控制系统通信的一个或多个仪器上处理附加多个样品。
本申请所述任一软件组件或功能均可通过软件代码的形式实施,所述代码可由处理器使用任何适当的计算机语言(例如,java、c++或perl),并利用例如常规技术或面向对象的技术实现。所述软件代码可作为一系列指令或命令存储在计算机可读介质(如随机访问存储器(ram)、只读存储器(rom)、磁介质(如硬盘驱动器或软盘)或光学介质(如cd-rom))中。任何所述计算机可读介质均可驻留在一个计算装置之中,且可存在于系统或网络中的不同计算装置之中。
以上描述是说明性而非限制性的。在回顾本公开时,本公开的多种变型对于本领域的技术人员而言将是显而易见的。因此,本公开的范围不应当根据上述具体实施方式确定,而是应当根据待审权利要求连同它们的完整范围或等同形式来确定。
在不脱离本公开范围的前提下,来自任何实施方案的一个或多个特征可以与任何其他实施方案的一个或多个特征相结合。
除非有明确的相反指示,否则,“一个”、“一种”或“所述”的叙述旨在表达“一个或多个”之意。
上文提及的所有专利、专利申请、公布和说明书以引用方式全文并入本文。
- 该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。
- 技术研发人员:维德·门哈特;克里斯托夫·默勒斯;桑托什·库卡尔
- 技术所有人:拜克门寇尔特公司
- 我是此专利的发明人
- 上一篇:一种机油稀释的计算方法与流程
- 上一篇:一种吸油装置及发动机的制作方法
- 该领域下的技术专家
- 如您需求助技术专家,请点此查看客服电话进行咨询。
- 1、司老师:1.制浆造纸 2.植物资源精细化工与化学 3.生物质精炼 4.天然产物化学
- 2、薛老师:1.CRISPR-Cas系统 2.基因编辑 3.基因修复 4.天然产物合成 5.单分子技术开发与应用
- 3、戴老师:1.天然药物(中药)合成生物学研究 2.酵母生物学与工程化研究
- 4、孟老师:1. 基于糖类的抗肿瘤药物的合成和活性评价及糖类疫苗的研制 2.功能糖类的化学酶法合成及构效关系研究 3.多糖及仿生材料功能的开发及应用
- 5、满老师:1.天然产品的提取分离与活性研究 2.天然产物活性与安全性评价 3.中药组方配伍机制研究
- 如您是高校老师,可以点此联系我们加入专家库。
- 还没有人留言评论。精彩留言会获得点赞!