一种年龄相关性黄斑变性的风险预测算法模型和装置的制作方法
本发明涉及医学生物检测领域,具体涉及一种年龄相关性黄斑变性(age-relatedmaculardegeneration,amd)的风险预测算法模型和装置。
背景技术:
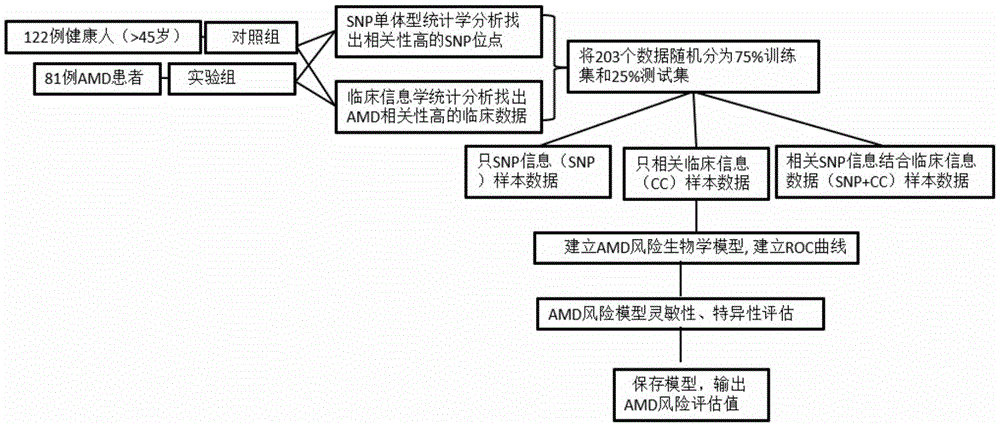
:年龄相关性黄斑变性(age-relatedmaculardegeneration,amd)是致老年人失明的主要因素。该病具有与年龄、性别、吸烟、种族及遗传等因素相关的复杂病因,为不可逆性的视觉丧失,目前针对该疾病尚无有效的治疗手段。amd具有较高的发病率,荟萃分析结果表明全球amd总的发病率为8.01%,欧洲、非洲及亚洲人群amd的发病率分别为11.2%、7.1%和6.8%。我国老年人群早期amd和晚期amd发病率分别为4.7%-9.2%和0.2%-1.9%。预测至2020年和2040年,全球amd患者将分别达到1.96亿和2.88亿。随着我国人口老龄化的加快,amd具有明显的上升趋势。amd的发生为环境因素和遗传因素综合作用的结果,其中遗传因素在该疾病的发生风险中占有较高比例,达45-70%。amd病因复杂,其发病机制与遗传和环境因子均相关,如上所述,遗传因素在该病的发生风险中占有重要比例。显然,若综合考量遗传和环境因素,并结合视力、眼压、眼底检查及眼底血管荧光造影、光学断层扫描等常规及辅助amd的检查,这必然能够极大提高对amd的精准诊断与有效风险评估,也将有益于amd的预防及其早期发现与治疗。因此,本领域迫切需要开发一种可靠的对amd进行早期预测和诊断的方法。技术实现要素:本发明的目的就是提供一种年龄相关性黄斑变性(age-relatedmaculardegeneration,amd)的风险预测算法模型和装置。在本发明的第一方面,提供了一种生物标志物集合,所述的集合包括选自下组两种的生物标志物:rs2338104、rs754203、或其组合。在另一优选例中,所述生物标志物集合为用于诊断黄斑变性(amd)疾病的生物标志物集合,还包括选自下组的生物标志物:rs2284664、rs2071277、rs1999930、rs10490924、rs5749482、或其组合。在另一优选例中,所述生物标志物集合为用于诊断黄斑变性(amd)疾病的生物标志物集合,包括选自表a的生物标志物:表a编号染色体位置突变碱基rs233810412:109457363c>grs75420314:99691630a>grs22846641:196733395c>trs20712776:32203906t>crs19999306:116065971c>trs1049092410:122454932g>trs574948222:32663679c>g在另一优选例中,所述生物标志物集合用于诊断黄斑变性(amd)疾病,或用于制备一试剂盒或试剂,所述的试剂盒或试剂用于评估待测对象的黄斑变性(amd)疾病患病风险(易感性)或诊断(包括早期诊断和/或辅助诊断)待测对象黄斑变性(amd)疾病。在另一优选例中,所述的集合包括选自表b的生物标志物:表b在另一优选例中,所述的集合包括生物标志物b1~b2。在另一优选例中,所述的集合还包括生物标志物b3~b7。在另一优选例中,所述的集合还包括生物标志物:rs551397、rs800292、rs10737680、rs3753396、rs1410996、rs2284664、rs1065489、或其组合。在另一优选例中,所述的生物标志物或生物标志物集合来源于血液、血浆、血清或口腔拭子样品。在另一优选例中,通过pcr对各个生物标志物进行检测。在另一优选例中,应用荧光定量pcr进行dna片段的扩增及单碱基的延伸。在另一优选例中,应用massarratanalyzer4system进行生物标准物的检测。在另一优选例中,所述pcr包括qpcr、荧光定量pcr。在另一优选例中,所述的集合用于amd患病风险的评估或诊断。在另一优选例中,所述的评估待测对象的amd患病风险包括amd的早期筛查。在本发明的第二方面,提供一种用于amd患病风险的评估或诊断的试剂组合,所述试剂组合包括用于检测如本发明第一方面所述的集合中各个生物标志物的试剂。在本发明的第三方面,提供一种试剂盒,所述的试剂盒包括如本发明第一方面所述的集合和/或如本发明第二方面所述的试剂组合。在另一优选例中,如本发明第一方面所述的集合中各个生物标记物用作标准品。在另一优选例中,所述的试剂盒还包括一说明书。在本发明的第四方面,提供一种生物标志物集合的用途,用于制备一试剂盒,所述的试剂盒用于amd患病风险的评估或诊断,其中,所述生物标志物集合包括选自下组的两种生物标志物:rs2338104、rs754203、或其组合。在另一优选例中,用于amd患病风险的评估或诊断时,所述生物标志物集合还包括选自下组的生物标志物:rs2284664、rs2071277、rs1999930、rs10490924、rs5749482、或其组合。在另一优选例中,所述的评估包括步骤:(1)提供一来源于待测对象的样品,对样品中所述集合中各个生物标记物的snp分型值(即表2的a1或者a2)进行检测;(2)将步骤(1)测得的位点信息与一参考数据集进行比较;较佳地,所述的参考数据集包括来源于amd患者和健康对照者的如所述集合中各个生物标记物的;在另一优选例中,所述的样品选自下组:血液、血浆、血清和口腔拭子。在另一优选例中,所述的将步骤(1)测得的位点信息与一参考数据集进行比较,还包括建立有监督机器学习的多元统计模型从而输出患病可能性的步骤,较佳地,所述的机器学习模型为xgboost分析模型。在另一优选例中,如果所述的患病可能性>0.5,所述的对象被判定为具有amd疾病患病风险或患有amd疾病。在另一优选例中,在步骤(1)之前,所述的方法还包括对样品进行处理的步骤。在本发明的第五方面,提供一种用于评估或诊断待测对象的amd患病风险的的方法,包括步骤:(1)提供一来源于待测对象的样品,对样品中所述集合中各个生物标记物的位点信息(如snp分型值(即表2的a1或者a2))进行检测;(2)将步骤(1)测得的分型与一参考数据集进行比较;较佳地,所述的参考数据集包括来源于amd患者和健康对照者的如所述集合中各个生物标记物的数据;在另一优选例中,所述的样品选自下组:血液、血浆、血清和口腔拭子。在另一优选例中,所述的将步骤(1)测得分型计算出相应的数据与一参考数据集进行比较,还包括建立有监督集成学习的机器学习模型从而输出患病可能性的步骤,较佳地,所述的机器学习模型为xgboost分析模型。在另一优选例中,如果所述的患病可能性>0.5,所述的对象被判定为具有amd疾病患病风险或患有amd疾病。在另一优选例中,在步骤(1)之前,所述的方法还包括对样品进行处理的步骤。在本发明的第六方面,提供一种筛选用于评估或诊断amd患病风险候选化合物的方法,包括步骤:(1)在测试组中,向待测对象施用测试化合物,检测测试组中来源于所述对象的样品中集合中各个生物标记物的水平v1;在对照组中,向待测对象施用空白对照(包括溶媒),检测对照组中来源于所述对象的样品中所述集合中各个生物标记物的水平v2;(2)对上一步骤检测得到的水平v1和水平v2进行比较,从而确定所述测试化合物是否是治疗amd的候选化合物,其中所述集合包括两种或多种选自下组的生物标志物:rs2338104、rs1999930、rs10490924。在另一优选例中,所述的待测对象患有amd。在另一优选例中,如果一个或多个选自子集h的生物标志物的水平v1显著低于水平v2,表明测试化合物为治疗amd的候选化合物。在另一优选例中,所述“显著低于”指水平v1/水平v2的比值≤0.8,较佳地≤0.6,更佳地,≤0.4。在本发明的第七方面,提供一种生物标志物集合的用途,用于筛选评估或诊断amd患病风险的候选化合物和/或用于评估候选化合物对amd的治疗效果,其中,所述生物标志物集合选自下组的两种生物标志物:rs2338104、rs754203、或其组合。在另一优选例中,所述生物标志物还包括:rs2284664、rs2071277、rs1999930、rs10490924、rs5749482、或其组合。在本发明的第八方面,提供一种amd早期辅助筛查系统,其特征在于,所述系统包括:(a)amd相关疾病特征输入模块,所述amd相关疾病特征输入模块用于输入某一对象的amd相关疾病特征;其中所述的amd相关疾病特征包括选自下组a的位点信息(如snp分型值(即表2的a1或者a2))的两种或多种:rs2284664、rs2071277、rs1999930、rs10490924、rs2338104、rs754203、rs5749482、或其组合;(b)amd相关疾病判别处理模块,所述处理模块对于输入的amd相关疾病特征,按预定的判断标准进行评分处理,从而获得风险度评分;并且将所述风险度评分与amd相关疾病的风险度阈值进行比较,从而得出辅助筛查结果,其中,当所述风险度评分高于所述风险度阈值时,则提示该对象患amd相关疾病的风险高于正常人群;和(c)辅助筛查结果输出模块,所述输出模块用于输出所述的辅助筛查结果。在另一优选例中,所述步骤(a)中,还包括以下amd相关疾病特征:年龄、糖尿病情况、身体质量指数(bmi指数)、肾损伤情况、动脉粥样硬化、饮酒情况、是否经常在户外情况。在另一优选例中,所述的对象是人。在另一优选例中,所述的对象包括婴幼儿、青少年或成年人。在另一优选例中,在所述处理模块中,如下进行风险度评分处理:在另一优选例中,所述的特征输入模块包括样本采集仪。在另一优选例中,所述的特征输入模块选自下组:massarratanalyzer4system分型输出模块、askme模块。在另一优选例中,所述的amd相关疾病的判别处理模块包括一处理器,以及一储存器,其中所述的储存器中存储有基于amd相关疾病特征的amd相关疾病的风险度阈值数据或模型。在另一优选例中,所述的输出模块包括报告系统(如askme的报告系统)。应理解,在本发明范围内中,本发明的上述各技术特征和在下文(如实施例)中具体描述的各技术特征之间都可以互相组合,从而构成新的或优选的技术方案。限于篇幅,在此不再一一累述。附图说明图1显示了本发明的技术路线。图2显示了应用massarratanalyzer4system进行基因snp分型实验步骤。图3显示了logistic回归,随机森林,adaboost,以及xgboost分类器的重复1000次随机拆分训练集和测试集,测试集平均结果做roc曲线,特征变量包含临床信息和位点信息(snp+cc)。图4显示了xgboost重复1000次学习和预测,测试集的平均预测结果做roc曲线,“cc”为特征变量只有临床信息数据、“snp”为特征变量只有snp位点,snp+cc为特征变量包含临床信息和位点信息。图5显示了xgboost输出的前10个特征变量的重要性分数。图6显示了变量数目与roc-auc分数的关系。过程是根据xgboost模型得到变量特征的重要性(feature-importance)分数,根据该分数再次优化筛选模型,逐个按照重要性分数从大到小增加特征变量的数目并输入模型进行训练和测试,得到测试的roc-auc最优所需要的变量数目,图中所示最优roc-auc对应的变量数目为4,即可将重要性分数的前四个特征变量当成输入变量,此时roc-auc得分最高。图7显示了将xgboost作为机器学习模型,年龄,rs754203,rs2338104,糖尿病作为变量,将1000次的测试集平均值做roc曲线。具体实施方式本发明人经过广泛而深入的研究,首次开发了一种年龄相关性黄斑变性(age-relatedmaculardegeneration,amd)的风险预测算法模型和装置。本发明采用7个相关snp的风险(oddratio)值,结合7个临床信息,并采用机器学习方法构建风险预测算法模型与装置。本发明可辅助临床进行amd的提前预测,早期诊断,对降低amd发病率,提高其疾病治疗率均具有重大临床意义。在此基础上完成了本发明。术语rs2338104:序列tgaaaaagttctaaaattagatagt[c/g]gttatggcctcacaacttgtgaata,染色体位置12:109457363,参与基因kctd10rs754203:序列gtgctgtcctggggcccaggagccc[c/t]gggggcaaggctctgccctgttgct,染色体位置14:99691630,参与基因cyp46a1(geneview)rs2284664:序列agaaaaataccagtctccatagatc[a/g/t]taaagcaaatagatggtcttaaaat,染色体位置1:196733395,参与基因cfhrs2071277:序列ggcagtgactgatgcagtgtgtgac[a/g]tctaatctcccccataattacaggc,染色体位置6:32203906,参与基因notch4rs1999930:序列ataggacagattctagattttcctt[a/c/g/t]tgatacagagaaatataagacataa,染色体位置6:116065971,参与基因frkrs10490924:序列tttatcacactccatgatcccagct[g/t]ctaaaatccacactgagctctgctt,染色体位置10:122454932,参与基因arms2rs5749482:序列tgggaactgactaatacagcatgta[c/g]gaactatgaaatatgaattgtgtaa,染色体位置:32663679,参与基因loc105373002、syn3年龄相关性黄斑变性(age-relatedmaculardegeneration,amd)为黄斑区结构的衰老性改变。主要表现为视网膜色素上皮细胞对视细胞外节盘膜吞噬消化能力下降,使未被完全消化的盘膜残余小体潴留于基底部细胞原浆中,并向细胞外排出,沉积于bruch膜,形成玻璃膜疣,由此继发的种种病理改变后,则导致黄斑部变性发生,或者引起bruch膜本断裂,脉络膜毛细血管通过破裂的bruch膜进入rpe下及视网膜神经上皮下,形成脉络膜新生血管。由于新生血管壁的结构异常,导致血管的渗漏和出血,进而引发一系列的继发性病理改变。老年性黄斑变性大多发生于45岁以上,其患病率随年龄增长而增高,是当前老年人致盲的重要疾病。单核苷酸多态性(singlenucleotidepolymorphism,snp)主要是指在基因组水平上由单个核苷酸的变异所引起的dna序列多态性。snp在人类基因组中广泛存在,平均每个碱基对中就有1个,估计其总数可达300万个甚至更多。snp是一种二态的标记,由单个碱基的转换或颠换所引起,也可由碱基的插入或缺失所致。snp既可能在基因序列内,也可能在基因以外的非编码序列上。xgboost一种boosting的有监督集成学习模型,由多个相关联的cart树联合构成。cart是一种二叉决策树,每次分枝时,是穷举每一个特征列的每一个阈值,根据gini系数找到使不纯性降低最大的特性列以及其阀值,然后按照特征列<=阈值,和特征列>阈值分成的两个分枝,每个分支包含符合分支条件的样本;用同样方法继续分枝直到该分支下的所有样本都属于统一类别,或达到预设的终止条件,若最终叶子节点中的类别不唯一,则以多数样本的类别作为该叶子节点的类别。xgboost可表示为如下公式:为预测值,f表示所有可能的cart树,f表示一棵具体的cart树。模型的目标函数为如下公式:为损失函数和,∑ω(fk)为正则项,obj(θ)取最小值的点就是这个节点的预测值,最小的函数值为最小损失函数。xgboost采用加法训练法,分步骤优化目标函数,首先优化第一棵树,再优化第二棵树,直至优化完k棵树。roc-auc一种评价模型准确性的方法,roc曲线为受试者工作特征曲线(receiveroperatingcharacteristiccurve),以假阳性概率(falsepositiverate)为横轴,真阳性(truepositiverate)为纵轴所组成的坐标图,是反映敏感性和特异性连续变量的综合指标。auc为roc曲线下方面积(areaunderthecurve)。roc-auc值在1.0和0.5之间,越接近于1,说明诊断效果越好,在0.5~0.7时有较低准确性,在0.7~0.9时有一定准确性,auc在0.9以上时有较高准确性。auc=0.5时,说明诊断方法完全不起作用,无诊断价值。auc<0.5不符合真实情况,在实际中极少出现。本发明的主要优点包括:1)本发明在临床领域首次以位点信息和临床数据预测amd风险值,适合于高通量样本的检测;2)本发明预测未来年龄患amd的风险,可提示改变生活习惯等对风险值的作用,对于amd疾病有预防警示的作用。下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。下列实施例中未注明具体条件的实验方法,通常按照常规条件,例如sambrook等人,分子克隆:实验室手册(newyork:coldspringharborlaboratorypress,1989)中所述的条件,或按照制造厂商所建议的条件。除非另外说明,否则百分比和份数是重量百分比和重量份数。实施例1.从108个备选snp位点数据通过统计分析筛选出算法模型和装置需要用的amd疾病相关的7个位点数据。招募实验训练组和对照组进行snp统计和临床信息学分析,通过大量筛选,找到108个snp位点,snp位点见表1。snp分型数据由以下步骤得到:1.样本采集:采用下方两种采集方式。a)血液样本采集方式:全血采集2-4ml于edta抗凝管中。b)口腔拭子采集方式:尼龙植绒口腔拭子刮取受检人员口腔上颚及口腔两侧黏膜,至口腔拭子尼龙植绒部位全部湿润为止,将采好样的口腔拭子样本放入盛有样本保护液(1-2ml)的试管中保存。2.样本运输:在放有样本的泡沫盒中加入冰袋低温运输。3.应用7500荧光定量pcr进行dna片段的扩增及单碱基的延伸。首先配置染料mix:1)、配置染料时,应多配几个孔,配置完成后放入-20℃保存;其次染料法和探针法的混合液离心管管壁上应做上标记,避免两种染料混淆;再按顺序加入试剂,即mixture(17μl),引物1(1μl)样本(2μl);最后封膜,上机,完成。4.应用massarratanalyzer4system进行基因snp分型,操作步骤如图2所示。5.通过全基因组范围内snp关联分析(gwas)技术得到amd相关的snp位点,关联分析包含以下几个假设:1)genotypicmodel(基因型模型),假设a为次等位基因,a为主等位基因,3种不同的基因型有不同的影响。2)dominantmodel(显性模型),即aa/aa与aa基因型有不同的影响。3)recessivemodel(隐性模型),即aa与aa/aa有不同的影响4)allelicmodel(等位模型),即a和a有不同的影响基于上述假设,计算卡方值。o为观测频率,e为预期频率。如(2)的假设,第一步我们计算出aa或者aa(两者满足一个)基因型在正常人中的观测频率和预期频率之差,除以预期频率得到的值v1,第二步按照正常人的计算方法计算出aa或者aa在疾病当中的值v2,第三步分别按照上述方法得到aa在正常人中的值v3以及在疾病当中的值v4,计算出卡方值则为v1+v2+v3+v4。通过卡方值得到其相关性的p值,根据p值小于0.05筛选得到14个相关位点。这14个相关位点内部有存在共线性的染色体,通过算法排除共线性大的7个位点,具体算法如下:做50个snp位点的划窗(window),该划窗每次移动5个snp,计算其中1个与其他各位点的多重相关指数r2,计算1/(1-r2)的vif指数,若该指数大于2,则排除这些snp位点。排除掉rs551397、rs800292、rs10737680、rs3753396、rs1410996、rs2284664、rs1065489位点,最终得到rs2284664,rs2071277,rs1999930,rs10490924,rs2338104,rs754203,rs5749482位点。上述流程后,得到了所需要的位点,其信息见表2。6.snp位点基因型清洗数据变成相应的数值,该数值定位计算出的amd7个相关位点的or值(oddratio)。or值(oddratio)是指事物发生的概率与不发生的概率之比。公式如下:or=(na/na)/(ma/ma)=(na×ma)/(ma×na)假设a为次等位基因,na为疾病中a的基因个数,na为疾病中不是a的基因个数,ma为对照中a的基因个数,ma为对照中不是a的基因个数。它有以下作用:a)or>1时,说明病例组的a的频率大于非病例组的,即a有较高的发病危险性。b)or<1时,说明病例组的a的频率低于非病例组的,即a有保护作用。c)疾病与a等位联系愈密切,比值比的数值愈大。表1.初始选定的snp位点编号(美国国立生物技术信息中心(ncbi)数据库的dbsnp的统一编号)表2.基因组范围内snp关联分析(gwas)技术得到amd相关的snp位点信息chrsnpa1f_af_ua2chisqporsel95u951rs2284664t0.26870.3762c4.250.039240.60910.24140.37950.97776rs2071277c0.36720.4471t7.5910.0224700.71750.23040.45681.1276rs1999930t0.036760.004587c5.2040.022538.2821.1010.957171.6710rs10490924t0.53970.4231g4.2860.038421.5990.22731.0242.49612rs2338104g0.42060.2905c5.9510.014711.7730.23591.1172.81614rs754203g0.28680.3773a7.9250.0190200.66360.23520.41861.05222rs5749482g0.23530.3636c6.420.011280.53850.2460.33250.872第一列chr为位点的染色体信息,第二列为snp位点的编号,第三列(a1)为次等位基因型,第四列f_a为a1基因型疾病观察到的频率,第五列为f_u为a1等位基因在健康人中观察到的频率,第六列为另一个等位基因型即主等位基因(a2),第七列chisq为卡方值,第八列p为卡方值换算得到的p值,第九列or则为or风险值,剩下十、十一、十二则为or值的标准误及其上95%置信区间的上值和下值。后续基因型将由次等位基因的or值进行替换,例如假设a为次等位基因,a为主等位基因,包含一个次等位基因(aa)替换为or值,包含两个次等位基因(aa)将替换为or值得平方,如没有该次等位基因(aa)则替换为1.实施例2.根据受试者在问卷情况整理获得年龄、身高体重指数(bmi)、高血压情况、高血脂情况、糖尿病情况、肾损伤情况、是否经常在户外、是否素食、从来没有吸过烟、从来没有饮过酒、动脉粥样硬化情况、眼睛手术情况、性别情况等13个临床调查数据。实施例3.机器学习算法可分为三类:监督学习,非监督学习和半监督学习。监督学习为通过一部分输入数据和输出数据之间的相应关系,生成函数,将输入映射到合适的输出,比如分类。本发明的样本数据都已在临床确诊,带有已分类好的标签,因此将在有监督的机器学习分类模型中进行探索选择。分别将所有样本只有snp位点信息的数据(snp),所有样本只有临床信息的数据(cc),以及结合snp位点和临床信息的综合数据(snp+cc)作为输入数据,样本的诊断结果作为输出分类标签。根据以下步骤进行算法构建:a)将所有数据随机分成75%的训练集和25%的测试集。b)构建机器学习分类器。用snp+cc作为输入数据,先后尝试logistic回归,随机森林,adaboost,以及xgboost。c)交叉验证调参,选取得分最好的参数。d)用测试集进行结果验证。e)模型评价。上述步骤重复1000次,计算测试集的平均受试者曲线的曲线下方面积(roc-auc)。选取最高roc-auc得分的xgboost为最佳模型(见图3)。f)特征变量筛选。分别将临床信息(cc),位点信息(snp),结合临床信息与位点信息(snp+cc)作为输入数据,通过xgboost进行分类,重复1000次,测试集平均受试者曲线见图4,可以看出snp+cc的roc-auc最高。g)进一步优化特征筛选。xgboost模型得到变量特征的重要性(feature-importance)分数(例如前10个的重要性见图5),根据该分数再次优化筛选模型,将改分数从大到小,逐个增加变量数目去训练和测试模型,从而得到变量数目与roc-auc分数的关系图(见图6)。结果显示,输入4个最重要的变量(年龄,rs754203,rs2338104,糖尿病)的数据训练并测试模型,模型测试得到的roc-auc分数最高。h)将xgboost作为机器学习模型,年龄,rs754203,rs2338104,糖尿病作为输入变量,得到1000次的平均roc-auc为(0.800±0.06)。i)存储模型,用于后续测量数据的amd风险预测。j)风险值输出:即学习训练完的算法模型预测输入的测试数据在0(对照)和1(患amd疾病)之间的概率,最终将1(患疾病)概率值确认为风险值,将风险值超过0.5的判定为患amd疾病。在本发明提及的所有文献都在本申请中引用作为参考,就如同每一篇文献被单独引用作为参考那样。此外应理解,在阅读了本发明的上述讲授内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。序列表<110>上海宝藤生物医药科技股份有限公司上海宝藤医学检验所有限公司<120>一种年龄相关性黄斑变性的风险预测算法模型和装置<130>p2018-2112<160>7<170>siposequencelisting1.0<210>1<211>52<212>dna<213>人工序列(artificialsequence)<400>1tgaaaaagttctaaaattagatagtcggttatggcctcacaacttgtgaata52<210>2<211>52<212>dna<213>人工序列(artificialsequence)<400>2gtgctgtcctggggcccaggagcccctgggggcaaggctctgccctgttgct52<210>3<211>53<212>dna<213>人工序列(artificialsequence)<400>3agaaaaataccagtctccatagatcagttaaagcaaatagatggtcttaaaat53<210>4<211>52<212>dna<213>人工序列(artificialsequence)<400>4ggcagtgactgatgcagtgtgtgacagtctaatctcccccataattacaggc52<210>5<211>54<212>dna<213>人工序列(artificialsequence)<400>5ataggacagattctagattttccttacgttgatacagagaaatataagacataa54<210>6<211>52<212>dna<213>人工序列(artificialsequence)<400>6tttatcacactccatgatcccagctgtctaaaatccacactgagctctgctt52<210>7<211>52<212>dna<213>人工序列(artificialsequence)<400>7tgggaactgactaatacagcatgtacggaactatgaaatatgaattgtgtaa52当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1