一种基于深度学习的糖尿病与高血压概率计算方法与流程
本发明属于大数据医疗与人工智能领域,尤其是涉及一种基于深度学习的糖尿病与高血压概率计算方法。
背景技术:
随着糖尿病与高血压在人群中发病率越来越高,人们对自身的健康管理也变得越来越重视,因此医院与其他的体检机构当前已经积累了大量的电子体检数据,使得糖尿病与高血压的大数据分析成为了可能。
根据2017年发布的《中国2型糖尿病防治指南》的报告,成年人2型糖尿病达到了10.4%,60岁以上的老年人发病率在20%以上,而在这之中未确诊的糖尿病人群占总数的63%,高血压的患病率更是达到了23%,防治这两种疾病已经到了刻不容缓的地步。
随着人们生活水平的提高、保健意识的增强,健康体检逐渐成为一种社会时尚,人们已经改变了只有在得病时才去医院的传统观念,定期体检已经被大多数人所接受。因此,医院积累了海量的电子体检数据,使大数据有了用武之地。
大数据医疗是当前的一个热点,是指通过大数据相关技术,分析医疗领域的数据并挖掘其中的知识从而大幅度提高医疗服务。在过去几十年中,大数据已经深深地影响了每一个企业,包括医疗保健行业。如今,大量的数据可以让医疗保健更加高效,更加个性化。
而另一方面近些年来的人工智能领域的也掀起了新的浪潮,在图像、自然语言、语音识别等不同的任务中都取得了非常杰出的成果。本发明中所涉及的为当前人工智能领域中前沿的技术模型的变式与衍生。因为糖尿病与高血压这两种疾病本身具有非常强的相关性,所以本文所述的方法是一种同时分析糖尿病与高血压疾病的多任务预测的创新。
技术实现要素:
本发明提供了一种基于深度学习的糖尿病与高血压概率计算方法,可同时计算糖尿病与高血压疾病的概率,辅助医生进行更好的判断。
本发明的技术方案如下:
一种基于深度学习的糖尿病与高血压概率计算方法,包括以下步骤:
(1)采集用户体检数据后进行数据清洗和预处理,再对数据中的数字数据和文本数据分别进行编码操作,得到训练数据;
(2)建立糖尿病与高血压多任务概率计算模型,所述多任务概率计算模型包含由全连接层搭建的数字特征提取器和以bert模型为主体的文本特征提取器;
(3)使用训练数据对上述多任务概率计算模型进行训练,根据模型计算的结果与糖尿病、高血压标签的重合情况对网络参数进行优化,直到模型收敛;
(4)将需要计算糖尿病与高血压概率的体检数据进行清洗、预处理和编码操作后输入上述训练完的模型,计算得到糖尿病概率与高血压概率。
步骤(1)中,所述数据清洗包括:筛选体检数据中糖尿病与高血压相关的检查项,对检查项缺失较多的体检数据进行删除,对检查项缺失较少的体检数据进行填补,得到m个数字数据和n个文本数据;所述的预处理包括对数字数据进行归一化处理,对文本数据建立相应的字典。
采用均值法、相邻值或数据分布采样法对检查项缺失较少的体检数据进行填补。
所述的编码操作的具体过程为:将数字数据生成m个k维且相互正交的基向量,基向量模长为1,将数字特征数值乘以对应的基向量,再将这些特征向量矢量相加,得到数字特征对应的向量,或直接以m个数字特征对应的数值得到数字特征对应的向量;将文本数据建立文本特征中的字典,使用word2vec方法(cbow、skip-gram、glove等)预训练字向量,得到文本特征对应的l维字向量或字向量编码。
步骤(2)中所述的糖尿病与高血压多任务概率计算模型包括了全连接层搭建的数字特征提取器,以及以bert为主体的文本特征提取器。
所述的全连接层搭建的数字特征提取器中的全连接层层数为2~4层,每一层的输入输出矩阵均为2维矩阵,且每一层全连接层后对输出进行降维操作。若某层的输入矩阵为d*k,d为特征数量,k为特征维度,则输出矩阵为
所述的bert模型是目前自然语言处理领域中流行的,以transformerblock为基本单元的纵向叠加而成的双向编码结构。transformerblock的数量为l,且每一个transformerblock对应有a个multi-headattention和h的隐藏层。
作为优选,berttransformerblock数量l范围为12~24,muti-headattention数量a的范围为12~16,隐藏层大小h范围为768~1024.
步骤(3)的具体步骤为:
(3-1)将训练数据中的数字特征向量和文本字向量分别输入数字特征提取器和文本特征提取器,得到特征提取后的向量v1与v2;
(3-2)将提取到的v1与v2使用全连接层或transformerblock进行特征融合,得到最终的融合向量v3;
(3-3)将得到的融合向量v3通过两个softmax层计算概率,再使用两个binarycrossentropyloss或两个focalloss计算与糖尿病、高血压标签的偏差;
(3-4)将步骤(3-3)计算得到的loss,反向传播,使用优化算法sgd或adam进行优化,收敛后得到最终的多任务预测模型。
所述的binarycrossentropyloss的计算公式为:
其中,i为样本的序号,m为数据中的样本数量,
所述的focalloss的计算公式为:
其中,i为样本的序号,m为数据中的样本数量,
与现有技术相比,本发明具有以下有益效果:
1、本发明通过分别编码数字特征与文本特征并提取,最终融合到一个模型中综合考量,大大提高了相关任务的准确性。
2、本发明可根据全连接数字特征提取器中的权重,对每一个特征进行重要性分析,提高模型可解释性。
3、本模型考虑了高血压与糖尿病本身可能存在一定相关性,所以在模型输出设计中采用了多任务分类的方式,同时输出糖尿病、高血压的患病概率。
4、模型的文本特征编码器采用bert模型,bert模型在拟合能力和并行性方面,大大优于经典的循环神经网络模型。
附图说明
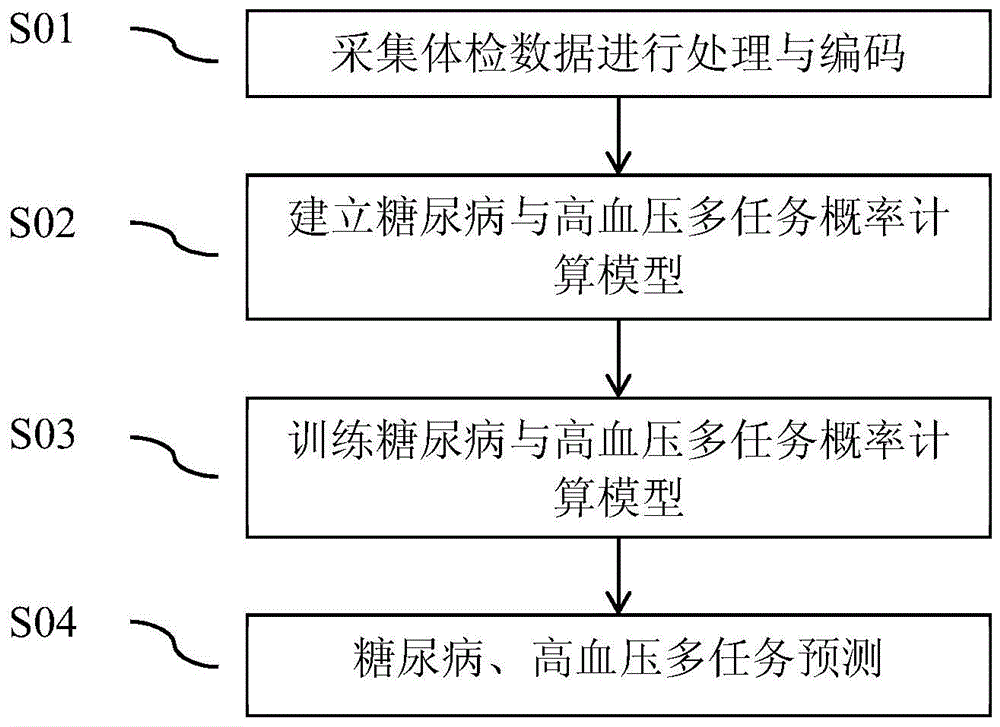
图1为本发明实施例一种基于深度学习的糖尿病与高血压概率计算方法的流程示意图;
图2为本发明实施例中糖尿病与高血压多任务概率计算模型的结构图;
图3为本发明实施例中bert模型的transformerblock结构图。
具体实施方式
下面结合附图和实施例对本发明做进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
如图1所示,一种基于深度学习的糖尿病与高血压概率计算方法,包括:
s01,体检数据处理与编码
(1-1)数据清洗:
根据糖尿病与高血压预测任务,筛选出与糖尿病、高血压相关的检查项,将这些检查项分为数字特征(仅含数字)与文本特征。
每一条医疗记录对应多个与糖尿病、高血压相关的检查项,删去缺失检查数据过多的医疗记录,校对检查项中异常项。
医疗记录中的部分缺失的数字特征使用均值法、相邻值、数据分布采样法填补。
(1-2)数据预处理:
数字特征预处理-归一化:求得数字特征均值与方差,再将数字特征减去均值、除以方差,将数字特征的均值与方差控制为0和1.
文本特征预处理-建立字典:对文本数据中所有出现的汉字建立字典,统计字频,将字频少于5的字,从字典中删除。
(1-3)数据编码:
数字特征编码:生成m个与数字特征对应的相互正交的基向量,并控制其模长为1,将数字特征中的数值乘以其对应的基向量,即可得到数字特征对应的特征表示向量,这样既保证了不同数字特征之间相互独立,又保证了其模长在[0,1]之间,或直接以m个数字特征对应的数值得到数字特征对应的向量。
文本特征编码:对每一个文本字典中的字,随机生成它对应的l维字向量。使用word2vec方法,包括cbow,skip-gram,glove等中的其中一种,在其他大量的文本语料或体检的文本数据中预训练字向量。
s02,建立糖尿病与高血压多任务概率计算模型
如图2所示,糖尿病与高血压多任务概率计算模型包括:图左侧虚线框与右侧虚线框中的两个特征提取器分支。左侧的全连接层提取器分支对数字特征进行编码操作,得到对数字部分的向量表达hcls,而右侧bert分支的使用l个transformerblock对文本字向量进行编码操作,得到最终对文本部分的向量表达hcls′。再使用一个全连接层或一个transformerblock对两个向量表达融合,得到联合的向量表达v。再根据两个分类目标,使用全连接层映射到对应的类别,最后使用softmax层计算概率。
s03,训练糖尿病与高血压多任务概率计算模型
(3-1)将步骤(1-3)中编码的数字特征向量与文本字向量分别输入全连接层搭建的数字特征提取器与bert模型的文本特征提取器,分别得到特征提取后的向量v1与v2。
(3-2)将步骤(3-1)中提取到的v1与v2,再使用全连接层或transformerblock进行特征融合,得到最终的融合向量v3。
transformerblock的结构如图3所示,transformerblock中的输入向量首先输入multi-headattention层,将输入向量使用全连接层映射到h组q,k,v向量,对h组q,k,v向量分别进行attention操作。所述的attention操作公式如下:
其中,q,k,v分别对应的是q,k,v向量,而dk为k向量的维度。
multi-headattention将h组得到的计算结果拼接,使用全连接层得到multi-headattention操作的向量。该向量与输入向量相加后,进行归一化操作的中间结果向量。该中间结果向量再进行一次全连接层操作后,与自身相加,并进行归一化操作,得到最终transformerblock的输出向量。
(3-3)将步骤(3-2)得到的融合向量v3,通过两个softmax层计算概率,再使用两个binarycrossentropyloss或focalloss计算与糖尿病、高血压标签的偏差。
本文所叙述的binarycrossentropyloss的计算公式为:
其中,i为样本的序号,m为数据中的样本数量,
本文所叙述的focalloss的计算公式为:
其中,i为样本的序号,m为数据中的样本数量,
(3-4)将步骤(3-3)所计算的loss,反向传播,使用优化算法sgd或adam进行优化,收敛后得到最终的多任务预测模型。
s04,糖尿病、高血压多任务预测
(4-1)将需要预测糖尿病与高血压用户的体检数据根据步骤(1-3)中的流程同样进行清洗、预处理以及编码,得到数字特征对应的特征向量与文本字向量。
(4-2)将步骤(4-1)中得到的数字特征向量与文本字向量分别输入全连接层构成的数字特征提取器与bert的文本特征提取器中,得到对应的编码向量v1′与v2′
(4-3)将步骤(4-2)中提取到的v1′与v2′,再使用全连接层或transformerblock进行特征融合,得到最终的融合向量v3′。
(4-4)将步骤(4-3)中提取到的v3′,通过计算糖尿病和高血压的softmax层,分别计算对应的糖尿病患病概率与高血压概率。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!