基于Smi2Vec的BiGRU药物毒性预测系统及预测方法与流程
本发明涉及药物性能预测领域,尤其涉及一种基于smi2vec的bigru药物毒性预测系统及预测方法。
背景技术:
药物设计与开发的过程需要耗费大量的人力、物力和财力,当通过生物或化学研究手段证明某一特定分子可实现某种治疗效果时,由于新发现的分子常因为毒性、低活性和低溶解度等多种问题而不能最终被研发成新药物,导致前功尽弃。
传统的神经网络曾被广泛用于药物性能预测,如生物活性、毒性、水溶性等,但是这些方法存在算法低效,难以用于批训练,容易出现过拟合等缺点。
相关技术中采用计算机方法来辅助栓选一些明显不符合标准的分子结构。由于计算机虚拟筛选不存在样品的限制,因此如果在药物研发早期先进行计算机虚拟筛选,然后再进行药理测试,这样的研发过程与传统策略比较,更具科学性、合理性,将显著地缩短新药的研发周期、降低研发费用。
先导物发现的主流方向在于分子的定量结构和活性关系(qsar)的研究,目前常用的qsar方法主要为二维定量构效关系方法(2d-qsar)、三维定量构效关系方法(3d-qsar)及四维定量构效关系方法(4d-qsar),这三种方法都会受限于自身的特点,基于大数据分析和机器学习的方法需要大量数据,对正负样本的分布要求较高;传统机器学习方法对于样本采集分类、训练需要耗费大量的时间;以上基于有监督和无监督的机器学习算法不仅需要大量数据,而且需要使用化学计量软件计算分子特征,同样需要耗费大量时间。
因此,有必要提供一种新的基于smi2vec的bigru药物毒性预测系统及预测方法来解决上述问题。
技术实现要素:
本发明要解决的技术问题是现有技术中药物性能预测的各种方法都会受限于自身的特点,基于大数据分析和机器学习的方法需要大量数据,对正负样本的分布要求较高;传统机器学习方法对于样本采集分类、训练需要耗费大量的时间;以上基于有监督和无监督的机器学习算法不仅需要大量数据,而且需要使用化学计量软件计算分子特征,同样需要耗费大量时间的技术问题。
本发明通过以下技术方案来解决上述技术问题:
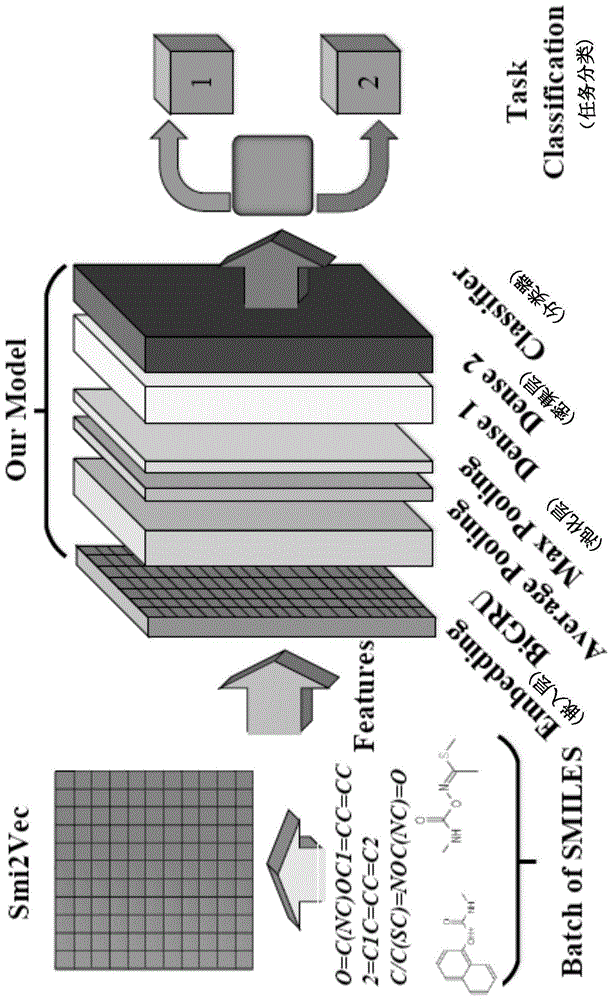
本发明提供了一种基于smi2vec的bigru药物毒性预测系统,包括:
smi2vec模块,所述smi2vec模块用于将分子特征转换为原子向量;
bigru药物毒性分类模型,用于训练所述原子向量,其设置于所述smi2vec输出端,所述bigru药物毒性分类模型包括1个嵌入层、1个bigru层、2个池化层及2个密集层;
及分类器,用于生成任务分类的输出标签,其设置于所述bigru药物毒性分类模型的输出端。
优选的,所述嵌入层设置于所述smi2vec模块的输出端,所述分类器设置于所述密集层的输出端。
本发明还提供了一种基于smi2vec的bigru药物毒性预测方法,包括:
步骤s1:构建数据集,所述数据集包括训练集、测试集及开发集;
步骤s2:smi2vec的转换:通过smi2vec模块将所述训练集中以smiles格式的分子特征转换为原子向量;
步骤s3:构建bigru药物毒性分类模型:所述bigru药物毒性分类模型包含1个嵌入层、1个bigru层、2个池化层、2个密集层;
步骤s4:将所述原子向量输入到所述bigru药物毒性分类模型对所述bigru药物毒性分类模型进行训练;
步骤s5:将所述bigru药物毒性分类模型的训练结果送至所述分类器,所述分类器优化损失函数后继续将所述训练结果送人所述bigru药物毒性分类模型进行训练;
步骤6:经过多次迭代计算,所述bigru药物毒性分类模型训练完成;
步骤7:对所述测试集中的数据进行smi2vec的转换并将转换结果输入到bigru药物毒性分类模型中,得到测试结果;
步骤s8:对所述测试结果进行分析和讨论。
优选的,所述数据集构建由所述训练集(80%)和所述测试集(20%)组成。
优选的,所述数据集构建由所述训练集(80%)、所述测试集(10%)及所述开发集(10%)组成。
优选的,所述步骤2具体的可分为以下步骤:
步骤21将smiles格式的分子切分成独立的原子,并对所述原子的特征进行提取;
步骤22用独热编码法对切分出的所述原子的逐一编码,将smiles分子转换为原子向量;
步骤23构建映射函数,用word2vec开源工具对所述训练集里的smiles分子进行预训练,生成字典,通过字典查询找到与之对应的样本向量,若在字典里缺失对应的样本向量,随机生成一个向量与之匹配。
优选的,在所述步骤s4中,所述原子向量依次至所述嵌入层、所述bigru层、所述池化层及所述密集层进行处理,以对所述bigru药物毒性分类模型进行训练。
优选的,在所述步骤s5中,将所述密集层的训练结果送至所述分类器,所述分类器优化损失函数后继续将所述训练结果送人所述嵌入层以继续对所述bigru药物毒性分类模型进行训练。
优选的,在所述步骤s6中,进行100次迭代计算或当连续5次迭代计算的结构不再变化时,所述bigru药物毒性分类模型即训练完成。
与相关技术相比,本发明提供的提出了一种基于smi2vec的bigru药物毒性预测系统及预测方法,利用smi2vec模块将smiles分子特征转换为原子向量,改方式对分子特征的提取提出了一种转换时间短、转换效率高的方向;另外,通过比较几种常用的传统机器学习模型,本发明提供的基于smi2vec的bigru药物毒性预测系统在tox21数据集上的表现均优于传统机器学习模型的性能,能够达到高稳定和高精准的要求;另外,本发明提供的基于smi2vec的bigru药物毒性预测系统具有对正负样本的分布要求低、对于样本采集分类、训练需要耗费时间短的优点。
【附图说明】
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图,其中:
图1为本发明提供的基于smi2vec的bigru药物毒性预测系统的框架图;
图2为图1中所述基于smi2vec的bigru药物毒性预测方法流程图;
图3为smi2vec的计算框图;
图4为原子向量的工作原理图;
图5为bigru药物毒性分类模型的主体架构图;
图6为本发明提供的基于smi2vec的bigru药物毒性预测方法与传统的分子表征方法ecfp的效果对比图。
【具体实施方式】
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
请结合参阅图1,图1为本发明提供的基于smi2vec的bigru药物毒性预测系统的框架图,本发明提供了一种基于smi2vec的bigru药物毒性预测系统,包括smi2vec模块、bigru(双向门控循环神经网络)药物毒性分类模型及分类器,其中:
所述smi2vec模块用于将分子特征转换为原子向量,具体的,所述smi2vec用于将smiles(simplifiedmolecularinputlineentryspecification,简化分子线性输入规范)格式的分子特征转换为原子向量;
所述bigru药物毒性分类模型用于训练所述原子向量,其设置于所述smi2vec输出端,所述bigru药物毒性分类模型包括1个嵌入层、1个bigru层、2个池化层及2个密集层;
所述分类器用于生成任务分类的输出标签,其设置于所述bigru药物毒性分类模型的输出端。
具体的,所述嵌入层设置于所述smi2vec模块的输出端,所述分类器设置于所述密集层的输出端。
请结合参阅图2-5,图2为图1中所述基于smi2vec的bigru药物毒性预测方法流程图;图3为smi2vec的计算框图;图4为原子向量的工作原理图;图5为bigru药物毒性分类模型的主体架构图。
本发明还提供了一种基于smi2vec的bigru药物毒性预测方法,其特征在于,包括:
步骤s1:构建数据集:所述数据集由训练集(80%)和测试集(20%)组成,当然,所述数据集也可由训练集(80%)、开发集(10%)及测试集(10%)组成。将所述数据集中对受体有影响的药物标记为1设定为正样本,没有影响的标记为0设定为负样本,去除所述负样本,以剔除干扰数据,降低所述数据集中的噪声影响;
步骤s2:smi2vec的转换:通过smi2vec模块将所述训练集中以smiles格式的分子转换为向量;
具体smi2vec的转换过程如下,
步骤2.1:将所述训练集中以smiles格式的分子切分成独立的原子,其中,对以基团出现的原子团则通过比配查询后提取出,视之为与单独的原子计算。
再对切分出的所述原子的数据提取统计得到如下特征:[‘c’,‘c’,‘(’,‘)’,‘o’,‘=’,‘n’,‘[’,‘]’,‘n’,‘h’,‘/’,‘-’,‘s’,‘cl’,‘@@’,‘@’,‘f’,‘+’,‘\’,‘s’,‘#’,‘o’,‘br’,‘p’,‘.’,‘i’,‘si’,‘%’,‘sn’,‘as’,‘se’,‘*’,‘hg’,‘b’,‘pt’,‘e’,‘au’,‘ge’,‘cu’,‘na’,‘fe’,‘sb’,‘t’,‘r’,‘co’,‘i’,‘pd’,‘zn’,‘pb’,‘m’,‘a’,‘cd’,‘ni’,‘a’,‘v’,‘d’,‘ag’,‘k’,‘g’,‘r’,‘al’,‘p’,‘l’,‘u’,‘ca’,‘t’,‘cr’,‘mn’,‘h’,‘li’,‘mg’,‘tl’,‘ti’,‘w’,‘in’,‘zr’,‘b’]。以上特征包含常见元素以及代表特殊价键,括号,特殊分子,离子等的符号,忽略数字,小数点。得到一个包含分子中所有统计特征的字典,字典值为该分子或字符出现次数;
步骤2.2:用独热编码法对切分出的所述原子逐一编码,将smiles分子转换为原子向量;
步骤2.3构建映射函数,用word2vec开源工具对所述训练集里的所述smiles字符串形式出现的分子进行预训练,生成字典,通过字典查询找到与之对应的原子向量,若在字典里缺失对应的原子向量,随机生成一个原子向量与之匹配;
步骤s3:构建bigru药物毒性分类模型,其中,所述bigru药物毒性分类模型包含1个嵌入层、1个bigru层、2个池化层及2个密集层;
步骤s4:将步骤2中所述向量输入到所述bigru药物毒性分类模型进行训练;
具体的,所述原子向量依次至所述嵌入层、所述bigru层、所述池化层及所述密集层进行处理,以对所述bigru药物毒性分类模型进行训练。
具体的训练过程如下,
步骤s41:输入x为药物的原子向量;
步骤42:输出y的真实值用[1,0]表示0,[0,1]表示1,每次训练和测试的结果为一个概率值,分别为a和b,且a+b=1,组成一个数据[a,b];
步骤43:所述bigru药物毒性分类模型中关键在于bigru环节,对于输入序列x=(x1,x2,...,xt),对于t时刻的每个gru单元中,当前隐藏层状态
这里φ和σ代表不同的激活函数,w,wz,wr和wr代表相对应的权值矩阵,bz和br分别表示更新门和重置门的偏执。一个更新门
步骤s5:将所述bigru药物毒性分类模型训练的结果送至所述分类器,所述分类器优化损失函数后继续送人所述bigru药物毒性分类模型进行训练,
具体的,将所述密集层的训练结果送至所述分类器,所述分类器优化损失函数后继续将所述训练结果送人所述嵌入层以继续对所述bigru药物毒性分类模型进行训练。
优选的,这里采用sigmoid函数来计算分类结果概率值yi,和之前的原始标签
yi=sigmoid(wiht+bi)
步骤6:经过多次迭代计算,得到最终训练完成的模型,具体的,进行100次迭代计算或当连续5次迭代计算的结构不再变化时,所述bigru药物毒性分类模型即训练完成;
步骤7:对所述测试集或所述测试集和所述开发集中的数据进行smi2vec的转换并将转换结果输入到训练完成的所述bigru药物毒性分类模型中计算,得到测试结果;
步骤s8:对步骤s7所得到的测试结果进行分析和讨论。
下面,将对本发明所提出的所述基于smi2vec的bigru药物毒性预测系统及预测方法的进行性能评测。
需要说明的是,本实施例中采用的所述数据集为tox21数据集(tox21datachallenge)对所述基于smi2vec的bigru药物毒性预测系统及预测方法的进行性能评测的性能进行评测,该数据集包含8013种可能对人体12种受体(nr-ar,nr-ar-lbd,nr-ahr,nr-aromatase,nr-er,nr-er-lbd,nr-ppar-gamma,sr-are,sr-atad5,sr-hse,sr-mmp,sr-p53)产生影响的数据。
首先,针对本发明提供的所述基于smi2vec的bigru药物毒性预测系统的性能评测,在本实施中,对所述tox21数据集中的每个任务进行了实验。在这组实验中,主要展示了radomforrest和svm传统机器学习模型的结果,因为radomforrest和svm传统机器学习模型比其他传统方法在所述tox21数据集上表现出更好的性能。具体来说,所述tox21数据集有12个任务。从下表可以看出,总体上,本发明所提出的所述基于smi2vec的bigru药物毒性预测系统在所述tox21数据集上均显示出最佳的性能。具体的,在所有任务类的验证集上本发明提供的所述基于smi2vec的bigru药物毒性预测系统相较于radomforrest和svm传统机器学习模型有12.74%-32.75%的性能提升,在测试集上有5%-40.4%的性能提升,实现了高标准的分类效果。
再次,请再结合参阅图6,图6为本发明提供的基于smi2vec的bigru药物毒性预测方法与传统的分子表征方法ecfp分别在rf(ranomforrest)、lr(logisticregression)、dt(decisiontree)、kn(k-nearestneighbor)模型上的效果对比图。为了体现分子表征方法的效果,和传统分子表征方法ecfp在相同的机器学习模型上训练,从所述tox21数据集的对比实验结果来看,本发明所提供的基于smi2vec的bigru药物毒性预测方法在4种模型上的roc-auc得分均优于传统方法。
与相关技术相比,本发明提供的提出了一种基于smi2vec的bigru药物毒性预测系统及预测方法,利用smi2vec模块将smiles分子特征转换为原子向量,改方式对分子特征的提取提出了一种转换时间短、转换效率高的方向;另外,通过比较几种常用的传统机器学习模型,本发明提供的基于smi2vec的bigru药物毒性预测系统在tox21数据集上的表现均优于传统机器学习模型的性能,能够达到高稳定和高精准的要求;另外,本发明提供的基于smi2vec的bigru药物毒性预测系统具有对正负样本的分布要求低、对于样本采集分类、训练需要耗费时间短的优点。
以上所述的仅是本发明的实施方式,在此应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出改进,但这些均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!