一种基于深度信念网络的中药不良作用识别方法与流程
本发明涉及药品不良作用识别技术领域,具体涉及一种基于深度信念网络的中药不良作用识别方法。
背景技术:
中药在我国有着悠久的应用历史,是我国古代人们在长期生活与医疗实践当中不断总结出来的。中医治病常以方剂为单位,研究方剂对疾病的作用机制有助于解释中医方剂配伍以及治病的科学性。而方剂是由多个单位药物组成,绝大多数的药物具有很好的药物安全性。与西药相比,中药具有伤害小且不易产生药物耐受性及依赖性的特点,但中药也有可能会对患者产生一些不良作用。因此,从海量的中药文献中识别并提取出中药的不良作用,对增加中医临床疗效、减少对患者的不良反应等多个方面都能起到极其重要的推动作用。
随着自然语言处理技术的发展,命名实体识别可用于从大量文献提取某类实体。目前,命名实体识别方法主要包括基于词典、基于规则、基于统计学模型、基于深度学习等四种策略。基于词典和规则的识别方法通常需要人工制定词典以及规则,通过总结实体本身具有的规则和其上下文语境规则来将实体提取出来,该方法可以很好的适应中药文本中不良作用实体表达方式随意的特点。但由于中药不良作用没有标准词库,需要自己构建,因此该方法难以实现自动化识别、且效果往往较差。基于统计学模型的识别方法包括hmm、memm和crf等机器学习模型,这类识别方法适用于对反复出现的实体进行识别,常被用于从文本中提取人名、地名等短语结构,而中药的不良作用不同于一般实体,其表达方式多种多样,很难将其全部识别出来,因此该种方法并不完全适合于中药不良作用的实体识别任务。此外,一些研究尝试将实体识别任务转化为分类问题,这种方法首先需要有一部分语料作为分类模型的训练语料,语料的质量在一定程度上影响着分类结果的好坏。目前采用深度学习模型来进行实体识别工作往往能取得更好的实验结果,克服了识别结果对人工语料标注精度的依赖性,相比其他实体识别方法具有更好的精确度。
经大量调研发现,上述命名实体识别方法在西药不良反应的实体识别领域有开展研究工作,且主要针对英文文献。目前基于中药文献的中药不良反应实体识别研究工作相当匮乏,均依赖于人工方法进行不良反应实体的提取,这主要是由于中药不良反应的文本描述随意性,长度、句式等相对不固定。这种人工标注法虽然可以对实体准确提取,但难以实现自动化,需要消耗较大的人力成本,难以对日益增加的中药文献进行有效利用。目前结合文本挖掘技术的药物不良作用识别工作均应用在西药领域,且主要针对英文文献开展,而对于中药不良作用的实体识别仍然停留在人工层面;同时,基于词典、规则或特定统计学模型的方法,通常需要消耗较大的人力成本进行语料库的构建,而且这些方法在随意性较强的中药文献中难以准确提取出不良作用描述,识别效果通常较差且耗时较长。
技术实现要素:
针对现有技术中的上述不足,本发明提供的一种基于深度信念网络的中药不良作用识别方法解决了难以准确提取出不良作用描述,识别效果通常较差且耗时较长的问题。
为了达到上述发明目的,本发明采用的技术方案为:一种基于深度信念网络的中药不良作用识别方法,包括以下步骤:
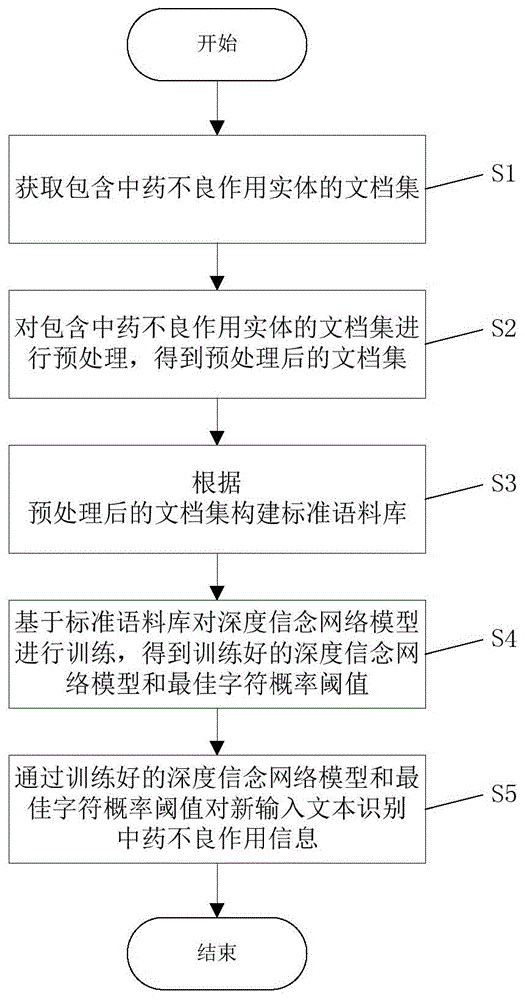
s1、获取包含中药不良作用实体的文档集;
s2、对包含中药不良作用实体的文档集进行预处理,得到预处理后的文档集;
s3、根据预处理后的文档集构建标准语料库;
s4、基于标准语料库对深度信念网络模型进行训练,得到训练好的深度信念网络模型和最佳字符概率阈值;
s5、通过训练好的深度信念网络模型和最佳字符概率阈值对新输入文本识别中药不良作用信息。
进一步地:所述步骤s1中文档集的获取方法包括:利用关键词从中文期刊文献数据库中进行文献检索,并以pdf格式下载检索到的文献并生成pdf文档集,和通过搜索引擎进行检索,并通过网页爬虫的方法将检索到的信息保存为txt文本格式。
进一步地:所述步骤s2中预处理的具体方法为采用pdfbox工具包对pdf文档集进行文本内容提取为txt文本格式,并对文档集中的干扰信息进行过滤。
进一步地:所述步骤s3中标准语料库的构建方法为:
根据标点“。”对预处理后的文档集进行分割,通过bio规则对分割好的句子进行序列标注,其中bio规则具体为:使用b表示中药不良反应实体的开头,使用i表示不良反应实体去除开头的其他部分,使用o表示除不良反应实体以外的部分。
进一步地:所述步骤s4中的具体步骤为:
s41、将标准语料库中的所有字符表示为多个由二值化字符组成的多维向量;
s42、通过多维向量计算每一层rbm的网络结构参数,将网络结构参数固定后,对每层rbm网络进行训练得到最优解,在dbn网络顶部加入bp网络进行反向调优,完成整个dbn网络的训练;
所述dbn网络由三层rbm网络叠加而成;
s43、计算最佳字符概率阈值。
进一步地:所述步骤s41的具体步骤为:通过分词对标准语料库中的所有词进行编号并对其构建词袋模型,通过one-hot算法根据词袋模型的词频提取特征向量,将特征向量通过训练窗口将特征向量组合成二值化字符组成的多维向量。
进一步地:所述步骤s42的具体步骤为:
s421、将多维向量作为第一层rbm网络的显层输入,并为该多维向量分配初始化权值w0;
s422、对该层rbm网络的初始显性神经元v(0)计算得到一个由其对应的隐性神经元h(0)重构出的新的显性神经元v(1),并更新该层rbm网络的权值为:
w=w0+λ(p(h(0)=1|v(0))v(0)t-p(h(1)=1|v(1))v(1)t)
上式中,w为更新后的rbm网络的权值,λ为预先设定的学习率,t为向量转置运算,h(1)为重构出的新的显性神经元v(1)对应的新的隐性神经元,p()为概率运算;
通过设定的学习率λ固定该层rbm网络的权值w,完成对第一层rbm网络的训练;
s423、将第一层rbm网络的隐性神经元作为第二层rbm网络的输入向量,重复步骤s422完成对第二层rbm网络的训练,将第二层rbm网络的隐性神经元作为第三层rbm网络的输入向量,重复步骤s422完成对第三层rbm网络的训练;
s424、在dbn网络的顶部加入bp网络进行反向调优,将第三层rbm网络的隐层数据向量作为bp网络的输入;
s425、通过bp网络将分类错误信息自顶向下传播至每一层rbm网络,微调层间迁移参数,使dbn网络达到最优;
所述层间迁移参数包括权值w、rbm网络中从隐层神经元到显层神经元的偏移向量和rbm网络中从显层神经元到隐层神经元的偏移向量。
进一步地:所述步骤s43最佳字符概率阈值通过对字符概率阈值求偏导计算可得,所述字符概率阈值的计算公式为:
上式中,δ为字符概率阈值,ej为每个不良作用实体,d为中药文献合集,ci为第i个字符,p(ci|δ)为第i个字符属于该不良作用实体组成部分的概率。
本发明的有益效果为:本发明能够对中药不良作用进行有效的整理和归纳,有助于中药不良作用实体数据库构建。并将传统的中药毒副作用研究与人工智能方法进行有机的统一,实现对于药物不良作用实体的全自动提取,减少人工提取药物不良作用的时间以及经济损耗,实现了在中药不良作用实体识别研究方法学上的优化。后期,本发明也可以根据不同中药文献集,实现针对特定中药的不良作用识别和关系挖掘,可以有效适用于各种中医药文献,不需要重新训练深度信念网络模型,可以直接从输入中药文献中识别并提取出药物不良作用实体。
附图说明
图1为本发明流程图;
图2为本发明中单层rbm的结构图;
图3为本发明中dbn的结构图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
如图1所示,一种基于深度信念网络的中药不良作用识别方法,包括以下步骤:
s1、获取包含中药不良作用实体的文档集;
文档集的获取方法包括:利用关键词从中文期刊文献数据库中进行文献检索,并以pdf格式下载检索到的文献并生成pdf文档集,和通过搜索引擎进行检索,并通过网页爬虫的方法将检索到的信息保存为txt文本格式。
s2、对包含中药不良作用实体的文档集进行预处理,得到预处理后的文档集;
获取大量包含药物不良作用描述的中药文献,对原始文档数据进行信息提取,只保留文档正文文本数据,形成新的文档集。对于不同类型文档的输入,需要制定不同的文本内容提取方法,预处理的具体方法为:采用pdfbox工具包对pdf文档集进行文本内容提取为txt文本格式。
此外,由于读取的文档类型不同,文档格式存在差异,文档包含干扰信息,因此需要对文档提取的文本内容进行规范化,从而符合化学命名识别模型的输入要求。例如:来源于科技文献的文本,其中包含期刊信息、作者信息、邮编信息、邮箱信息、参考文献列表等,而这些信息普遍出现在该类文档中,需要对此类信息进行过滤,从而尽可能保留正文信息。
s3、根据预处理后的文档集构建标准语料库;
标准语料库的构建方法为:
根据标点“。”对预处理后的文档集进行分割,通过bio规则对分割好的句子进行序列标注,其中bio规则具体为:使用b表示中药不良反应实体的开头,使用i表示不良反应实体去除开头的其他部分,使用o表示除不良反应实体以外的部分。
例如句子:“柴胡主要成分为柴胡皂苷,柴胡皂苷能导致肾上腺肥大、胸腺萎缩,使人体免疫功能降低。其具有肾毒性,长期服用会损伤肾脏。”目的在于标记出诸如“肾毒性”等中药不良作用实体信息短句,以及“使人体免疫力降低”等长句。
该句式可以标记为:“柴/o胡/o主/o要/o成/o分/o为/o柴/o胡/o皂/o苷/o,/o柴/o胡/o皂/o苷/o能/o导/b致/i肾/i上/i腺/i肥/i大/i、/o胸/b腺/i萎/i缩/i,/o使/b人/i体/i免/i疫/i功/i能/i降/i低/i。/o其/o具/b有/i肾/i毒/i性/i,/o长/o期/o服/o用/o会/o损/b伤/i肾/i脏/i。/o”
s4、基于标准语料库对深度信念网络模型进行训练,得到训练好的深度信念网络模型和最佳字符概率阈值;
深度信念网络在结构上是由多层玻尔兹曼机(restrictedboltzmannmachines,rbm)叠加而成,单层rbm的结构如图2所示,神经元vi表示显性神经元节点,用于接收输入,hi表示隐性神经元节点,用于提取特征。对于本发明的不良反应实体识别任务,采用三层rbm串联的深度信念网络模型,如图3所示,其中标签信息y在最后一层rbm的输入中加入。
步骤s4的具体步骤为:
s41、将标准语料库中的所有字符表示为多个由二值化字符组成的多维向量;
具体步骤为:通过分词对标准语料库中的所有词进行编号并对其构建词袋模型,通过one-hot算法根据词袋模型的词频提取特征向量,将特征向量通过训练窗口将特征向量组合成二值化字符组成的多维向量。
以“柴胡主要成分为柴胡皂苷,柴胡皂苷能导致肾上腺肥大”这两句话为例,先通过分词来对所有词进行编号并对其构建词袋模型(bagofwords),得到“1柴胡,2主要,3成分,4为,5皂苷,6能,7导致,8肾上腺肥大”这一编号结果,使用one-hot算法根据词频提取特征向量,从而将该文本描述转化为二值化字符向量[11110000,10001111]。在实际进行文本向量化时,词袋模型对应的语料库为步骤s3中得到的中药文献规范化语料库。其中,训练窗口设置主要是控制向量组合的窗口大小,可以设置为10、50、100等,具体大小可根据实验效果和数据的不同进行调整。
s42、通过多维向量计算每一层rbm的网络结构参数,将网络结构参数固定后,对每层rbm网络进行训练得到最优解,在dbn网络顶部加入bp网络进行反向调优,完成整个dbn网络的训练;
所述dbn网络由三层rbm网络叠加而成;
具体步骤为:
s421、将多维向量作为第一层rbm网络的显层输入,并为该多维向量分配初始化权值w0;
对训练集中的每一条数据分别计算其使隐层神经元被开启的概率,以数据向量v(0)为例,当σ(wjv(0))大于任意一个随机值时,则将该层rbm中显性神经元v(0)对应的隐性神经元
上式中v和h的上标用于区别不同的输入数据向量,下标j表示同一个向量中的不同维度,b表示从显层元到隐层元的偏移向量。将上式计算出的隐性神经元统计概率用来表示当前隐性神经元
h(0)~p(h(0)|v(0))
如下公式所示,采用上式构建出的隐性神经元h(0)来重构当前rbm的显性神经元v(0),并将该层rbm的初始权值wj更新为
其中,a表示从隐层元到显层元的偏移向量,用上式计算出的统计概率来表示更新后的显性神经元的值(将v(0)更新为v(1)):
v(1)~p(v(1)|h(0))
用更新后的显层神经元v(1)(采用h(0)重构得到的)经如下公式计算出隐层神经元
s422、对该层rbm网络的初始显性神经元v(0)计算得到一个由其对应的隐性神经元h(0)重构出的新的显性神经元v(1),并更新该层rbm网络的权值为:
w=w0+λ(p(h(0)=1|v(0))v(0)t-p(h(1)=1|v(1))v(1)t)
上式中,w为更新后的rbm网络的权值,λ为预先设定的学习率,t为向量转置运算,h(1)为重构出的新的显性神经元v(1)对应的新的隐性神经元,p()为概率运算;
选择好的学习率λ固定该层rbm网络的权值w,完成对第一层rbm网络的训练;
s423、将第一层rbm网络的隐性神经元作为第二层rbm网络的输入向量,重复步骤s422完成对第二层rbm网络的训练,将第二层rbm网络的隐性神经元作为第三层rbm网络的输入向量,重复步骤s422完成对第三层rbm网络的训练;
s424、在dbn网络的顶部加入bp网络进行反向调优,将第三层rbm网络的隐层数据向量作为bp网络的输入;
s425、通过bp网络将分类错误信息自顶向下传播至每一层rbm网络,微调层间迁移参数,使dbn网络达到最优;
所述层间迁移参数包括权值w、rbm网络中从隐层元到显层元的偏移向量和rbm网络中从显层元到隐层元的偏移向量。
s43、计算最佳字符概率阈值。
最佳字符概率阈值通过对字符概率阈值求偏导计算可得,所述字符概率阈值的计算公式为:
上式中,δ为字符概率阈值,ej为每个不良作用实体,d为中药文献合集,ci为第i个字符,p(ci|δ)为第i个字符属于该不良作用实体组成部分的概率。
s5、通过训练好的深度信念网络模型和最佳字符概率阈值对新输入文本识别中药不良作用信息。
- 还没有人留言评论。精彩留言会获得点赞!