一种基于群体智能的药物-靶标相互作用预测方法与流程
本发明涉及生物信息
技术领域:
,尤其涉及网络药理学中的药物-靶标相互作用预测方法,具体涉及一种基于群体智能的药物-靶标相互作用预测方法。
背景技术:
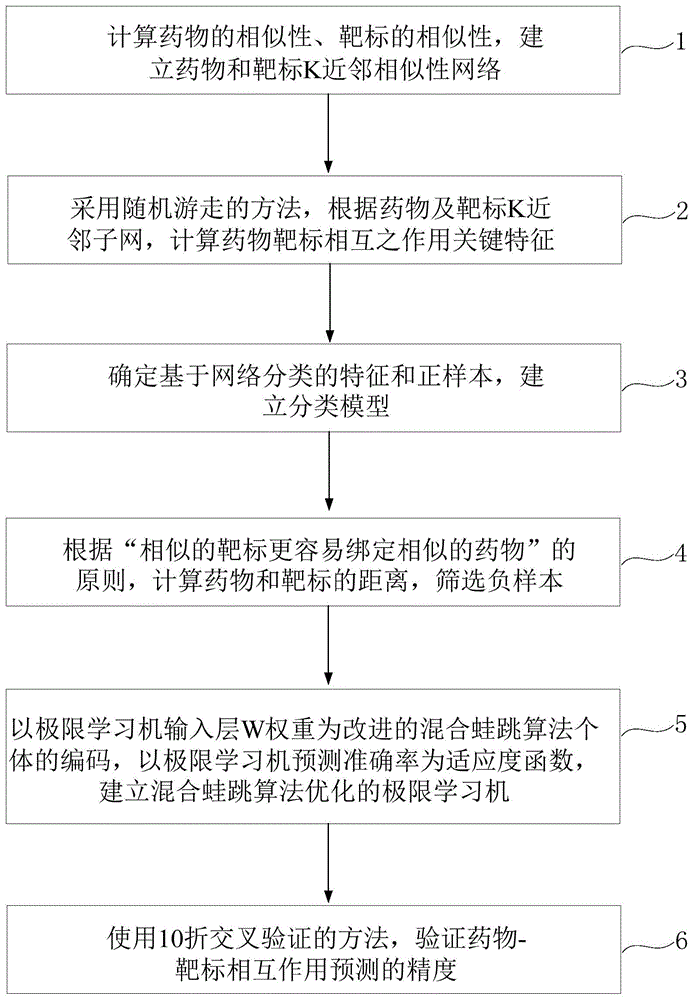
:发现新的药物靶标,是药物研发的“重磅性”发现,也是药物研发的源头。传统的以实验的方式发现新的药物,一般需要8-10年的时间,研发的成本高且周期漫长。随着基因组学、蛋白质组学、代谢组学、系统生物学等生物信息学技术的迅速发展,以大数据为依托的,融合机器学习与网络药理学的计算方法得到研究者的关注。关键的问题是如何从已有的数据中发现和识别出新的药物-靶标相互作用关系。关于药物-靶标相互作用预测问题,实际上一直被认为是机器学习中的两类分类问题。一种药物与一种靶标之间有相互作用的属于一类;没有相互作用的属于另外一类。因此,目前流行的机器学习方法是建立两部图分类模型和一部图分类模型。对于两部图分类模型,是分别计算药物的相似性和靶标的相似性矩阵,然后,使用分类器,分别对药物空间和靶标空间进行预测,再用集成的方法进行药物-靶标相互作用预测。而一部图分类模型是直接根据药物和靶标的原始特征进行特征选择,并用分类器进行分类。上述过程是药物-靶标相互作用的典型的预测方法,这些方法存在如下缺点:1)对于两部图分类模型和一部图分类模型,都会随着数据样本的增加或特征的增加,而降低分类器预测的精度。2)药物-靶标相互作用对的负样本的产生比较困难,目前的方法是把药物和靶标没有确定的样本对当做负样本,这使得一些正样本被错误的判断为负样本,从而降低了预测的精度。3)当前的方法所使用的分类器,大部分都对一些重要参数很敏感,而这些参数的选择没有做深度的优化。申请公布号为cn109887540a的中国专利公开了一种基于异构网络嵌入的药物靶标相互作用预测方法,首先使用随机游走的方法,获得关键样本特征,并采纳了神经网络算法及随机森林算法,一定程度上提高了预测的精度。然而,其中算法的参数没有得到优化,其预测精度仍然较低。申请公布号为cn109712678a的中国专利公开了一种关系预测方法、装置及电子设备,该方法重点考虑了药物、靶标及疾病的数据融合,而对分类器的性能及参数优化方面没有大的改进,依然存在分类器参数缺乏优化的问题。申请公布号为cn110021341a的中国专利公开了一种基于异构网络的gpcr药物和靶向通路的预测方法,提出了药物及通路的异构网络,并采纳rbm分类器进行预测。然而,rbm的性能对三个重要参数比较敏感,亟需对其优化。申请公布号为cn109872781a的中国专利公开了基于xgboost的药物靶点识别方法,该方法重点采纳了成分分析等以提取关键特征,然后使用cart分类器进行预测,然而,cart参数也没有得到优化。技术实现要素:本发明的目的在于提供一种基于群体智能的药物-靶标相互作用预测方法,针对现有技术中分类器预测精度低等问题,本发明结合两部图和一部图的优点,提出了基于网络的分类模型;对于负样本的筛选,我们提出了一种自学的负样本选择方法;对于分类器参数敏感的问题,提出了一种群体智能优化的极限学习机,实现分类器参数的智能优化。首先,我们对收集的药物和靶标的原始数据计算并建立其相似性矩阵;对于已经确定的药物-靶标相互作用对表达为1,对未知的药物靶标相互作用表达为0,建立药物靶标相互作用的邻接矩阵(无向图);根据“相似的药物往往更容易与相似的靶标产生相互作用”的原则,修订药物靶标邻接矩阵;对于每个药物节点,搜索其最近的药物与每个靶标的最近靶标的路径,计算路径长度,作为分类器的新的特征;通过网络搜索和计算,建立新的分类模型;然后,根据“相似的药物往往更容易与相似的靶标产生相互作用”的原则,筛选负样本;最后,利用群体智能算法的优势,对极限学习机的网络参数进行优化,以预测精度为适应度函数,进行训练和学习,最后验证了药物靶标相互作用预测的精度,结果发现,本发明有效提高预测的精度和速度。本发明上述目的通过以下技术方案实现:本发明提供一种基于群体智能的药物-靶标相互作用预测方法,包括以下步骤:步骤1:从数据库获取药物与靶标的数据,分别计算药物相似性、靶标相似性,建立全局药物与靶标相互作用网络;步骤2:采用随机行走的方法,从所述全局药物与靶标相互作用网络中提取用来分类的关键特征,将网络中的药物与靶标相互作用连接权重作为类编号;步骤3:根据相似的药物与相似的靶标绑定的原则,筛选分类的负样本;步骤4:采用极限学习机作为药物-靶标相互作用分类器;步骤5:采用群体智能算法对极限学习机输入权重进行优化,所述群体智能算法使用全局搜索与局部搜索相结合的方法。可选地,所述步骤1中,所述数据库可以为kegg、drugbank等现有数据库。可选地,所述步骤1中,获取的所述数据包括药物、靶标及已知的药物-靶标相互作用数据。可选地,所述步骤1中,使用simcomp算法计算药物的相似性。可选地,所述步骤1中,使用smith–watermanscores算法计算靶标的相似性。可选地,所述步骤1中,所述靶标为蛋白质等。可选地,所述步骤2包括以下步骤:步骤2-1:以任意一个药物节点为起点,计算其k个最近关联的药物节点;同时,在靶标子网络中,以任意一个靶标节点为终点,计算其k个最近关联的靶标节点,在全局网络中,根据邻接矩阵的权重,搜索从药物到靶标的最近路径,求总和,作为网络分类的基本特征;步骤2-2:计算不同搜索路径的总距离,作为分类的不同关键特征:kf表示药物i与药物j相互作用的一个特征,di和dj表示药物基本特征,ti和tj表示靶标基本特征,sim()为药物或靶标的相似性函数,weight()表示药物与靶标的相互作用权重。可选地,所述步骤2-1中,k一般为[3,10]区间的整数。可选地,所述步骤2中,药物与靶标相互作用权重为1,表示正样本的类标号,建立分类模型。可选地,所述步骤3中,筛选分类的负样本时,根据相似的药物更容易与相似的靶标产生相互作用的原则,分别计算药物di与tj的k个最近的邻居的相互作用,计为同样的,计算靶标tj与药物di的k个最近的邻居的相互作用,计为计算总分,排序,排序最低的作为负样本,wi表示药物与靶标相互作用权重,di表示药物与药物的相似性权重,ti表示靶标与靶标的相似性权重。可选地,所述步骤4中,得到基于极限学习机算法的输入层权重wi和偏移量bi矩阵,使用群体智能算法对其优化。可选地,所述步骤5中,所述群体智能算法选自混合蛙跳算法、粒子群算法、进化算法、人工蜜蜂群算法、教与学优化算法的任一种。可选地,所述步骤5中,所述群体智能算法为改进的混合蛙跳算法,具体包括如下步骤:步骤5-1:以极限学习机的输入层权重和偏移对混合蛙跳的每个个体做编码,以极限学习机的预测准确率作为混合蛙跳算法的适应度值,进行搜索;步骤5-2:对于混合蛙跳算法根据适应度值,进行蛙跳子群的划分;步骤5-3:采纳levy分布,实现蛙跳的局部搜索,公式如下:xw表示最差的青蛙的位置,xbest表示局部子群中最好的青蛙的位置,xm表示局部子群中的平均位置,levyflight表示levy分布的随机数;步骤5-4:采纳相互学习机制,实现全局搜索,公式如下:x'i=xi+rand.(xpopa(u)-xpopb(v))+rand.(xbest-xpopb(v)),xpopa(u)和xpopb(v)表示青蛙群中随机选择的青蛙位置,xbest表示最佳的青蛙位置;步骤5-5:极限学习机的隐含层,采纳moorepenrose逆矩阵计算隐含层权重w。使用极限学习机作为分类器,给定训练集及隐含层数目h,和激活函数g(ai,bi,xj),公式如下:wi表示与输入层与隐含层连接的权重向量,bi表示输入层与隐含层的偏移向量,βi表示隐含层与输出层的连接权重,oj表示预测的类标号。可选地,所述步骤5-5中,采用极限学习机moorepenrose逆矩阵计算隐含层权重w,公式如下:β=h+t。h+表示moorepenrose逆矩阵计算,t表示极限学习机的输出层已知的类标号数据,β是隐含层与输出层之间的权重。本发明还提供一种群体智能算法的药物-靶标相互作用预测装置,包括:全局药物与靶标相互作用网络获得模块,用于从数据库获取药物与靶标的数据,分别计算药物相似性、靶标相似性,结合药物-靶标相互作用邻接矩阵,建立全局药物与靶标相互作用网络;类编号获得模块,用于从所述全局药物与靶标相互作用网络中提取用来分类的关键特征,将网络中的药物与靶标相互作用连接权重作为类编号;分类的负样本筛选模块,用于根据相似的药物与相似的靶标绑定的原则,筛选分类的负样本;极限学习机优化模块,用于采纳群体智能算法对极限学习机输入权重进行优化,所述群体智能算法使用全局搜索与局部搜索相结合的方法。本发明还提供一种电子设备,包括:处理器、存储器和总线,所述存储器存储有所述处理器可执行的机器可读指令,当电子设备运行时,所述处理器与所述存储器之间通过总线通信,所述机器可读指令被所述处理器执行时执行上述方法的步骤。本发明具有以下有益效果:本发明提出了一种基于群体智能的药物-靶标相互作用分类方法,针对目前药物-靶标相互作用分类问题中三个主要问题:1)两部图和一部图分类,都会随着数据样本的增加或特征的增加,而降低了分类器预测的精度。2)药物-靶标相互作用对的负样本的产生比较困难,目前的方法把药物和靶标没有确定的样本对被当做负样本,这使得一些正样本被错误的判断为负样本,从而降低了预测的精度。3)当前的方法所使用的分类器,大部分都对一些重要参数很敏感,而这些参数的选择没有做深度的优化。为了解决这三个主要问题,本发明使用基于网络特征的分类模型替换了两部图和一部图;采用自学习的负样本筛选方法来选择合适负样本;采纳改进的混合蛙跳算法优化极限学习机输入层权重,从而大大提高了药物-靶标相互作用预测的精度。附图说明图1显示为本发明实施例的混合蛙跳优化的药物-靶标相互作用分类流程图。图2显示为本发明实施例的基于网络特征的药物-靶标相互作用分类原理模型图。图3显示为本发明实施例的药物-靶标相互作用分类中负样本筛选原理图。图4显示为本发明实施例的混合蛙跳优化极限学习机的药物-靶标相互作用流程图。图5显示为本发明实施例的lsfla-elm算法的auc曲线及算法收敛曲线图。具体实施方式以下结合说明书附图和具体实施例来进一步说明本发明,但实施例并不对本发明做任何形式的限定。本发明提出的一种群体智能优化的药物靶标相互作用分类的方法,以解决目前两部图和一部图预测精度低的问题,提高预测的精度,现有技术存在的问题具体包括负面样本的筛选不准确及现有分类器对参数设置不合理,从而降低了预测的精度的问题。针对这些问题,本发明结合了两部图和一部图的共同优点,提出了基于网络的分类模型,使用“相似的药物往往更容易与相似的靶标产生相互作用的”的原则,筛选负样本。然后,使用改进的混合蛙跳算法对极限学习机中的输入权重进行优化,从而提高药物-靶标相互作用分类的精度。本发明提出的技术方案如下:使用图排列算法计算药物的相似性计算,使用smith–watermanscores方法计算蛋白质(靶标)的相似性计算。在药物子网络中,以任意一个药物节点为起点,计算其k个最近关联的药物节点;同时,在靶标子网络中,以任意一个靶标节点为终点,计算其k个最近关联的靶标节点。在全局网络中,根据邻接矩阵的权重,搜索从药物到靶标的最近路径,求总和,作为网络分类的基本特征。根据邻接矩阵,对权重为1的,作为分类的正样本;而负样本的筛选,采纳自学的计算方法。对负样本的筛选,根据“相似的药物往往更容易与相似的靶标产生相互作用的”的原则,分别计算药物di与tj的k个最近的邻居的相互作用,计为同样的,计算靶标tj与药物di的k个最近的邻居的相互作用,计为计算总分,排序,排序最低的作为负样本,wi表示药物与靶标相互作用权重,di表示药物与药物的相似性权重,ti表示靶标与靶标的相似性权重。使用极限学习机作为分类器,给定训练集及隐含层数目h,和激活函数g(x)。随机产生输入层权重w和偏移量b矩阵,计算隐含层输出矩阵h,计算输出权重β,β=h+t,h+表示moorepenrose逆矩阵计算,t表示极限学习机的输出层已知的类标号数据,β是隐含层与输出层之间的权重。选择群体智能算法中的混合蛙跳算法,改进搜索策略,用来对极限学习机中的收入权重w进行优化。设置q个解的群体智能算法的蛙跳子群,每个个体用极限学习机中的收入权重对其编码,而极限学习及的预测的准确率作为每个个体的适应度函数。考虑群的多样性,保证全局搜索和局部搜索的平衡的原则,采纳局部搜索和全局搜索基础的修改原则,改进搜索策略。最终,获得极限学习机输入层最佳权重,采纳10-折交叉验证的方法,计算群体智能优化的极限学习机预测的精度。实施例1图1是混合蛙跳优化的药物-靶标相互作用分类流程图。图1中提出的方法具体如下:步骤1:从国际公开的数据库中搜索药物、靶标及已知的药物-靶标相互作用数据(比如从kegg、drugbank等数据库中搜集)使用simcomp算法计算药物的相似性,使用smith–watermanscores算法计算蛋白质(靶标)的相似性。本实施例中使用国际金标准数据集yamanishietal.(2008(enzymes,ionchannels,gpcrsandnuclearreceptors)做为验证,该数据集可以在网上查到,网址为http://web.kuicr.kyoto-u.ac.jp/supp/yoshi/drugtarget/。步骤2:基于网络特征的提取具体实现方法可以如图2所示。虚线区域内表示的是药物与靶标的随机行走范围,黑色箭头表示行走路径。可以看出,从药物di到靶标ti之间的路径有很多条,每一条路径的距离总和作为分类样本的关键特征。关键特征公式如下:kf表示药物i与药物j相互作用的一个特征,di和dj表示药物基本特征,ti和tj表示靶标基本特征,sim()为药物或靶标的相似性函数,weight()表示药物与靶标的相互作用权重。步骤3:将药物相似性与靶标相似性连接起来(连接方式可以是简单连接或随机游走,本例采纳简单连接方式),药物与靶标相互作用权重为1,表示正样本的类标号,建立分类模型。步骤4:根据“相似的靶标更容易绑定相似的药物”的原则,计算药物和靶标的距离,筛选负样本。负样本的筛选原理如图3所示,需要建立药物di和靶标ti的距离(虚线表示该药物和靶标没有相互作用),具体如下:步骤4-1:首先,根据药物的相似性计算,选出k个离药物di最相似的药物(本例k=3),计算这3个药物与靶标ti的相互作用权重,公式如下:ad表示药物对靶标的影响程度,wi表示药物与靶标相互作用权重,ddi表示与药物di最近的药物的相似性;步骤4-2:同样的,据靶标的相似性计算,选出k个离靶标图ti最相似的靶标(k=3),计算这3个靶标与药物di的相互作用权重,公式如下:at表示靶标对药物的影响程度,wi表示药物与靶标相互作用权重,tti表示与靶标ti最近的靶标的相似性;步骤4-3:计算总距离,公式如下:td=e-(ad+at);ad表示药物对靶标的影响程度,at表示靶标对药物的影响程度,td表示药物和靶标的共同影响程度,它的值越大,越可能是负样本;步骤4-4:将所有的td距离降序排列,选出与正样本的距离最大的样本为负面样本。将药物的相似性与靶标的相似性连接为一个完整药物-靶标特征。步骤5:使用改进的混合蛙跳算法对极限学习机进行优化,提出混合蛙跳的极限学习机作为分类器,具体步骤如图4所示:步骤5-1:随机产生q个青蛙个体{x1,x2,x3,...,xq},每个青蛙个体使用极限学习机输入层权重编码,以极限学习机的输入层最小误差为适应度值。步骤5-2:根据适应度值大小降序排列,均匀划分为k个子群,在每个子群中选出最佳青蛙个体xbest和最差青蛙个体xworst。步骤5-3:局部搜索公式如下:其中levy搜索公式如下:x'w表示更新后的青蛙的位置,xw表示最差的青蛙的位置,xbest表示局部子群中最好的青蛙的位置,xm表示局部子群中的平均位置,levyflight表示levy分布的随机数。u和v表示正态分布的随机数,σ表示方差;σu=1;ω表示步长扩展参数。step表示levy步长。步骤5-4:完成全局搜索,公式如下:x'i=xi+rand.(xpopa(u)-xpopb(v))+rand.(xbest-xpopb(v)),x'i表示更新后的青蛙的位置,xpopa(u)和xpopb(v)表示青蛙群中随机选择的青蛙位置,xi表示青蛙的原始位置,xbest表示最佳的青蛙位置。对于极限学习机,给定训练集及隐含层数目h,和激活函数g(ai,bi,xj)。xj表示输入样本,ai表示输入层与隐含层连接的权重向量,bi表示输入层与隐含层的偏移向量,βi表示隐含层与输出层的连接权重,oj表示预测的类标号。步骤5-5:采用极限学习机moorepenrose逆矩阵计算隐含层w权重,公式如下:β=h+t。β表示隐含层与输出层的连接权重,h+表示moorepenrose逆矩阵计算,t表示极限学习机的输出层已知的类标号数据。步骤5-6:判断是否满足收敛条件,如果不满足,就退到步骤5-2,重新搜索。步骤6:使用10-折交叉验证方法验证提出的方法的预测精度。其中参数设置包括:群大小np=50,最大适应度评估数目为2500,青蛙子群数目为5,局部迭代数目为9,levy参数beta=0.6,auc(areaundercurve,曲线下面积)与aupr(areaundercurveofprecisionvsrecall,精度曲线下面积与召回率)的和作为适应度函数。本实施例采纳了药物-靶标相互作用金标准数据集中的nuclearreceptor(nr)数据集和g-proteincoupledreceptor(gpcr)数据集。其中nr数据集有54个药物和26个靶标。gpcrs数据集有223个药物和95个靶标,分别按正样本与负样本比例(1:3)进行。auc及收敛曲线验证了提出的算法的性能。图5为使用改进的混合蛙跳优化的极限学习机算法(lsfla-elm)进行药物-靶标相互作用预测的auc曲线及算法的收敛曲线。图5(a)显示了两个数据集nr和gpcr的auc曲线。图5(b)显示了混合蛙跳算法的搜索曲线,可以看出lsfla对elm参数不断的优化,从而提高了适应度函数的值,也就是提高了预测的精度。表1和表2显示为我们提出的算法与目前最先进的(state-of-theartalgorithm)其他3个算法(netlaprls,blm-nii,nrlmf)(三个算法比较结果见参考文献,yongliu,minwu,chunyanmiao,peilinzhao,xiao-lili,neighborhoodregularizedlogisticmatrixfactorizationfordrug-targetinteraction,prediction.ploscomputationalbiology,2016.|doi:10.1371/journal.pcbi.1004760,第11页和第12页)比较表。表1不同算法精度比较(auc)表2不同算法精度比较(aupr)算法lsfla-elm(%)netlaprls(%)blm-nii(%)nrlmf(%)nr99.0246.565.972.8gpcr96.1761.652.474.9从表1和表2可以看出,我们提出的方法的性能超过目前最先进的其他3个算法。综上所述,本发明提出了基于网络特征的分类模型,根据“相似的药物更可能与相似的靶标进行绑定”的原则筛选负面样本,然后使用改进的混合蛙跳算法对极限学习机进行优化,从而显著提高了预测的精度。上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1