一种用于诊治失眠病症的中医古籍数据处理方法
本发明涉及计算机技术在中医领域的应用,特别涉及一种用于诊治失眠病症的中医古籍数据处理方法。
背景技术:
失眠病症是临床最为常见疾病之一,是指入睡困难、夜间睡眠维持困难和早醒,是睡眠量的不足或质的不佳。近年来,我过失眠等神经精神疾病发病率迅速增高。相关文献显示,35%的人口曾患急性失眠病症,而9%-12%的人息慢性失眠病症,失眠病症已经成为许多国家广泛关注的社会公共卫生问题。
中医运用整体观念和辩证论治疗失眠病症具有独特的优势,这在临床已经得到验证。因此在研究古今文献基础上,从中医药探寻治疗失眠病症的有效治疗方案,具有非常重要的现实意义。
虽然中医古籍是历代医家学习和参考的知识源泉,然而,数千年来传承下来的中医古籍,由于知识量过于庞大,且其以文本的形式分散记录于不同的医案文献,严重限制了后人对其进行系统地理解和学习,并从中寻找规律,总结经验。
1)中医语言在用词中具有较强的模糊性,忽略该特点的语义分析易导致错误结论的产生;
2)证候多样以及诊断及疗效判定标准不统一;
3)缺乏客观评价中医药治疗方案治疗失眠病症的优势指标。
这也导致现阶段的中医药诊断数据研究应用,多是基于结构化的知识文本展开的。中医药古籍文本的结构化需要大量人工劳动,难以应对海量的古籍文本,因此,急需寻找一种中医古籍诊治失眠病症的数据处理方法,能够解决中医古籍语言复杂性问题,快速准确的分析失眠案例,帮助人们系统理解和学习,并寻找规律,掌握经验,从而为患者提供有效的治疗方案。
技术实现要素:
有鉴于此,本发明旨在提出一种用于诊治失眠病症的中医古籍数据处理方法,以解决现有依据中医古籍诊治失眠病症,知识量庞大且分散,严重限制后人系统理解和学习,影响治疗方案的技术问题。
为达到上述目的,本发明的技术方案是这样实现的:
一种用于诊治失眠病症的中医古籍数据处理方法,包括步骤:
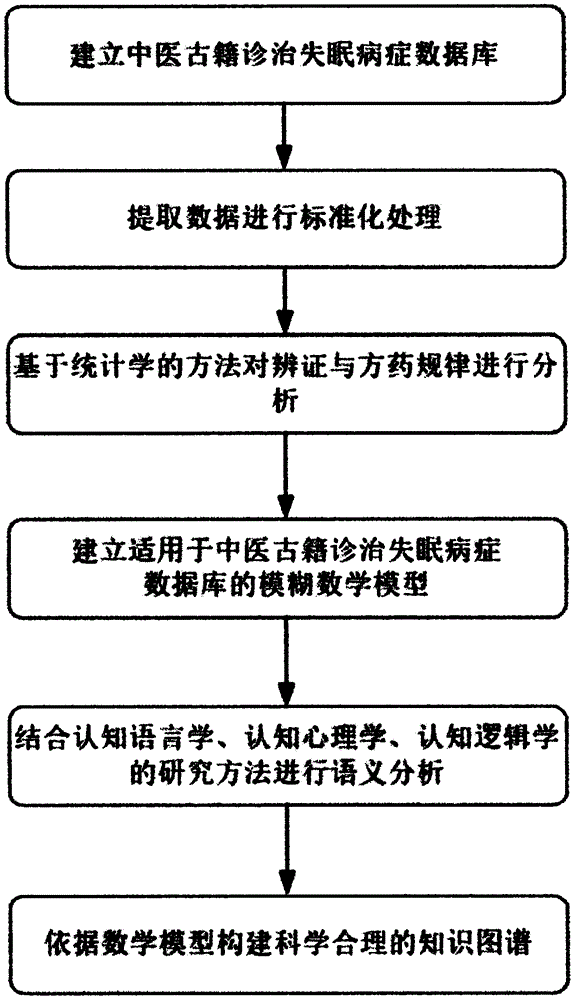
s1:建立中医古籍诊治失眠病症数据库;
s2:提取数据并进行标准化处理;
s3:基于统计学的方法对辨证与方药规律进行分析;
s4:建立适用于中医古籍诊治失眠病症数据库的模糊数学模型;
s5:结合认知语言学、认知心理学和认知逻辑学研究方法进行语义分析;
s6:依据数学模型在图形数据库中构建科学合理的知识图谱。
进一步的,所述的s1中建立中医古籍诊治失眠病症数据库方法包括制定纳入标准与排除标准。
所述的纳入标准包括古籍文献中需明确指明相关条文的论述与失眠有关,和治疗失眠病症的医案,其所用方剂需具有完整的药物组成。
所述的排除标准包括古籍条文描述中无法明确失眠病症者或条文相互重复。
本研究以《中华医典》等数据库、工具书收录的古籍条文为数据源,以“失眠”、“卧不安”等描述失眠症状的词汇为检索词进行查询,结合纳入与排除标准,收录相关数据。
进一步的,所述的s2中提取数据并进行标准化处理包括名称的规范化和计量单位的统一。
由于中医语言多样化的特点,不同医家在对相同事物(包括药名、病名、主症等)描述时大量使用别名、异名。数据的标准化处理有助于在大量的条文数据中发掘其内在的本质规律。
进一步的,所述的s3中基于统计学的方法对辨证与方药规律进行分析过程采用聚类分析方法或关联分析方法。
采用统计的方法分析失眠病症数据库中不同类别知识的分布规律,探讨时间变化、证候变化对知识表述规律的影响,为模糊数学模型的建立和语义分析提供基础,从统计学角度分析数据库条文的诊治规律,探讨历代医家诊治失眠病症的辨证与方药特点,为后续融合模糊逻辑的知识图谱构建提供技术支撑。
进一步的,所述的s4中建立适用于中医古籍诊治失眠病症数据库的模糊数学模型方法包括:
1)确定中医古籍诊治失眠病症数据库的指标参数;
2)确定各参数指标的权重;
3)针对参数指标构造判断矩阵;
4)对判断矩阵进行求解;
5)进行一致性检验,一致性比率是否小于等于0.1,如果是判断矩阵成立进行6),如果否返回3);
6)优化指标权重;
7)建立模糊关系矩阵;
8)确定隶属度函数,代入指标权重;
9)归一化计算,完成模糊数学模型的建立。
进一步的,所述的隶属度函数所属的类型为正态型函数,或升半cauchy型函数,或降半cauchy型函数,或梯形函数。
进一步的,所述的中医古籍诊治失眠病症数据库的参数指标与证候相关,或与症状相关。
进一步的,所述的s5中结合认知语言学进行语义分析具体包括采用概念隐喻方法对符合模糊数学模型的条文进行语义关联和语义融合。
进一步的,应用该数据处理方法的模块包括:
中医古籍数据源模块,用于提供原始条文;
数据输入模块,用于在中医古籍数据源模块中进行搜索;
标准输入模块,用于在搜索和筛选条文时进行标准纳入和标准排除;
中医诊治失眠数据库构建模块,用于存放和初步处理搜索和筛选后的失眠病症数据;
数据处理模块,包括标准化处理模块、统计分析模块、模糊数学模块、语义分析模块,对中医诊治失眠病症数据库构建模块进行标准化处理、统计分析、模糊数学分析、语义分析;
知识图谱构建模块,用于中医诊治失眠病症数据库进行知识图谱构建。
本发明所述的一种用于诊治失眠病症的中医古籍数据处理方法构建方法具有以下优势:
(1)本发明所述的一种用于诊治失眠病症的中医古籍数据处理方法,用现代知识理论与传统中医药知识进行结合,解决了在诊治失眠病症过程中中医古籍复杂性的问题,帮助后人快速有效并且系统的学习理解相关知识,为诊治失眠病症提供有效的方案;
(2)本发明所述的一种用于诊治失眠病症的中医古籍数据处理方法,在中医古籍文本语义分析过程中结合使用模糊逻辑分析的方法,有助于实现对中医语义的科学描述。通过构建知识图谱的方法对这些知识进行整合,建立以知识为中心资源的语义集成服务,可以为中医药的现代化研究提供高价值参考。
(3)本发明所述的一种用于诊治失眠病症的中医古籍数据处理方法,对模糊化处理后的数据库进行知识图谱构建,采用当前较为成熟的知识图谱构建方法进行分析计算。相比于传统的知识图谱构建,采用模糊数学模型对诊治失眠中医古籍中语言的模糊性进行描述,有利于提高算法识别的准确率和覆盖率。
附图说明
构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明实施例所述的一种用于诊治失眠病症的中医古籍数据处理方法的主要步骤流程图;
图2为本发明实施例所述的一种用于诊治失眠病症的中医古籍数据处理方法所需的系统模块。
图3为本发明实施例所述的一种用于诊治失眠病症的中医古籍数据处理方法的详细流程图;
具体实施方式
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
在本发明中涉及“第一”、“第二”、“上”、“下”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”、“上”、“下”的特征可以明示或者隐含地包括至少一个该特征。另外,各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当实施例之间的技术方案能够实现结合的,均在本发明要求的保护范围之内。
下面将参考附图并结合实施例来详细说明本发明。
如图1所示,一种用于诊治失眠病症的中医古籍数据处理方法,包括以下步骤:
s1:建立中医古籍诊治失眠病症数据库;
s2:提取数据并进行标准化处理;
s3:基于统计学的方法对辨证与方药规律进行分析;
s4:建立适用于中医古籍诊治失眠病症数据库的模糊数学模型;
s5:结合认知语言学、认知心理学和认知逻辑学研究方法进行语义分析;
s6:依据数学模型在图形数据库中构建科学合理的知识图谱。
具体的,本实施例以计算机为载体,如图2所示,包括中医古籍数据源模块、数据输入模块、标准输入模块、中医诊治失眠数据库构建模块、数据处理模块、知识图谱构建模块;其中数据处理模块包括标准化处理模块、统计分析模块、模糊数学模块、语义分析模块;
中医古籍数据源模块提供原始条文,通过数据输入模块在中医古籍数据源模块中进行搜索,同时标准输入模块进行标准纳入,将初步筛选的失眠病症数据条文放入中医诊治失眠病症数据库构建模块,标准输入模块进行标准排除,在中医诊治失眠病症数据库构建模块清除重复条文,数据处理模块对中医诊治失眠病症数据库构建模块进行标准化处理、统计分析、模糊数学分析、语义分析,最后进行知识图谱构建。
如图3所示,首先,建立中医古籍诊治失眠病症数据库,具体步骤为:
1)选取目标数据源,本实施例以《中华医典》等数据库、工具书收录的古籍条文为数据源;
2)以“失眠”、“卧不安”等描述失眠症状的词汇为检索词进行查询,得到n条相关的条文;
3)查询第h条条文;
4)并结合纳入标准进行判断,判断条文是否明确指出与失眠相关,如果与失眠不相关,则h=h+1,返回3)对第h条条文进行查询,重新判断条文是否与失眠相关;如果与失眠相关,进行下一步;
5)判断该条文中相关方剂所用药物是否完整,如果不完整,h=h+1,返回3)对第h条条文进行查询;如果记载药物完整,进行下一步;
6)初步建立中医诊治失眠病症数据库,将当前条文录入数据库,并判断h是否等于n,当h≠n,h=h+1,返回3)对第h条条文进行查询,当h=n,初步完成对中医诊治失眠数据库建立,进行下一步;
7)判断条文是否重复,如果有重复条文,仅收录年代最早者,将其他重复条文删除,进行下一步;
8)校对整理各个条文;
9)建立准确的中医古籍诊治失眠病症数据库;
10)分类标注数据信息,完善数据库:对数据库中所有条文进行分类标注,标注信息包括:条文出处、朝代、作者、类型(理论论述或者临床医案)、临床医案中失眠是否为主症等。
在该实施例中,n的值为整数值,并且n≥1,h的值为整数值,且h≥1,h≤n,h的初始值为1,即对条文进行查询及判断时,从第一条条文开始。
第二,提取数据并对数据标准化处理。数据标准化处理主要针对医案描述展开,包括药名、病名、症状等别名、异名的标准化,以及病程、年龄、剂量等计量单位的标准化。参照《中国药典》、《中药大辞典》对药物名称进行规范,将药物别名、异名等进行统一,如将“枣”、“南枣”、“红枣”等统一规范为“大枣”;橘白、橘皮等统一为陈皮。医案对疾病名称有记录者,若为规范名称,则如实记录;若疾病名称不规范者,则将其规范后录入,如“太阳中风”、“外感风寒”“太阳伤寒”等规范为“感冒”。若缺失者,则参考医案描述、结合主症等,予以补充。症状名称的规范主要参考《中医症状鉴别诊断学》、《中医诊断学》等书籍,如“头晕”、“眩晕”、“头晕目眩”虽然表述有所不同,但是其病机本质相同,所以都规范为“眩晕”。对病程、年龄、剂量等的计量单位,均统一为现代用法,如年、月、日、克等单位。
第三,对标准化处理后的古籍医案,分析其诊治失眠的辨证与方药规律,主要采取统计学中的聚类分析方法,具体步骤如下:
1)根据证候与症状、药方与药物的相关性,对聚类变量进行确定,本实施例选取的聚类对象有证候、症状、药方、药物,证候的主要分类为如心火偏亢、肝郁化火、痰热内扰的实证和阴虚火旺、心脾两虚、心胆气虚的虚证,症状主要分类有心烦不寐、多梦易醒、心悸不安、神疲食少、急躁昂怒、脘腹胀满,胸闷嗳气等。药方:朱砂安神丸、龙胆泻肝汤、黄连温胆汤、黄连阿胶汤、安神定志丸等。药物:黄连、甘草、柴胡、当归、黄芩、生地黄等。以每个聚类因素下的相关分类作为聚类变量,分别对聚类对象进行聚类分析;
2)研究聚类变量的频率分布;
2)聚类中心初始化;
3)分层聚类分析,以欧式距离平方作为度量方法,组内平均连接法作为聚类方法;
4)聚类结果,分析总结失眠辩证与方药规律。
根据相关规律,在数据库整体研究的基础上,划分不同朝代,研究历代医家诊治规律的演变。
第四,建立适用于中医古籍诊治失眠病症数据库的模糊数学模型。中医对病名、症状等的描述和定义有着较强的模糊性,如在脉象的描述中,经常使用微、弱、沉、迟、濡、细等词汇,这些词汇间缺乏清晰的界定。此外,还有类似的大量模糊词汇充斥于中医语言,知识的模糊性为计算机的信息处理大幅增加了困难。采用模糊数学模型辅助分析,将定性分析定量化,可显著降低中医语言的复杂性。
以标准化处理后的中医古籍诊治失眠病症数据库为数据源,统计分析不同知识的分布规律。研究内容主要包括:证候相关知识(如心火偏亢、肝郁化火、痰热内扰的实证和阴虚火旺、心脾两虚、心胆气虚的虚证)、症状相关知识(如急躁昂怒,不寐多梦,脘腹胀满,胸闷嗳气等)。在分析知识整体分布规律的基础上,研究朝代、医家、证候等因素对知识模糊性的影响,如失眠患者的弱、细脉象,在不同证候亚组下,其分布规律大概率是不一致的,可能心脾两虚证更倾向于使用“细”,而心胆气虚证更倾向于使用“弱”。研究不同亚组下的知识模糊性,有利于更准确地建立模糊数学模型。
主要步骤如下:
1)确定参数指标;确定对知识模糊性影响较大的因素,比如证候、症状、药方、药物等,将参数指标作为评价对象的因素集,可以按评价因素划分为几级,第一级评价因素下设置下属的第二级评价因素,第二级评价因素可以设置下属的第三级评价因素,依次类推,建立完整的指标评价体系,本实施例中仅选取影响因素最大的证候、症状、药方、功效为例作为第一级评价因素,ui={u1,u2,u3,u4},i=4。
证候相关因素如心火偏亢、肝郁化火、痰热内扰的实证和阴虚火旺、心脾两虚、心胆气虚的虚证,可在证候下建立第二级评价因素,同理,症状相关因素如咳嗽、呕吐、腹满等,可在症状下建立第二级评价因素。
2)确定各参数指标的权重;a=(a1,a2,a3,a4)为权重向量,其中ai表示第i个因素的权重,要求ai≥0,∑ai=1,同理,列出第二级评价因素权重向量。根据指标重要度进行两两比较,根据标度法对指标定量化,例如a与b相比重要性一样高,对指标赋值为1,a与b相比重要性略高,对指标赋值为3,a与b相比重要性绝对高,赋值为5。
在对指标重要度进行比较时,采用专家调查法,指通过匿名方式征询有关专家的意见,对专家意见进行统计、处理、分析和归纳,客观综合多数专家经验和主观判断,对大量难以采用技术方法进行定量分析的因素做出合理估算。两两比较判断的因素必须是同一层的,属于上一层的同一指标。
3)针对参数指标构造判断矩阵;
其中,i,j=1,2……,n,并且bii=1,
4)对判断矩阵进行求解;ma=λmaxa求解矩阵m的最大特征值λmax对应的特征向量a;常用的方法有求和法与平方根法等;
(1)求和法:
(2)方根法:
5)对判断矩阵的值进行一致性检验,判断一致性比率是否小于等于0.1,如果是则进行下一步,如果否,返回3);对这些因素主观判断具有不稳定性,因此难以将同一准则下的因素差异度量的十分准确,两两比较得到的判断矩阵不一定满足一致性条件。因此利用层次分析法中的数量标准衡量判断矩阵的不一致程度:一致性比例:cr=ci/ri,
当cr≤0.1时,判断矩阵具有一致性,否则就不具有一致性。
ci=(λmax-n)/(n-1);
6)进一步的对权重结果进行优化处理:
7)建立模糊关系矩阵;r=(c1,c2,...,cn)t=(rij)n×m。
8)确定隶属度函数;并代入指标权重;
9)归一化计算,完成模糊数学模型的建立,ci=a(i)·ri。
基于不同知识的分布规律,选用合适的隶属度函数对知识的模糊性进行评价。所用隶属函数类型包括:正态型函数、升半cauchy型函数、降半cauchy型函数、梯形函数等。以心脾两虚证失眠患者的舌质为例,如果从统计规律看,舌质以淡红舌为主,伴有少量淡白舌和鲜红舌,可建立梯形函数对隶属度进行描述。使用类似方法描述其余知识的模糊性。
第五,结合认知语言学、认知心理学和认知逻辑学的研究方法,对失眠数据库中的条文进行语义分析和语义融合;
以认知语言学为例,优选的采用概念隐喻的方法探讨中医古籍对人体。病因、症状、药方等认知;中医古籍中概念隐喻根据不同的源域,分为三种类型:方位隐喻、实体隐喻和结构隐喻,中医古籍中存在“上热下寒”、“表寒里热”等概念,并且通过实体有形的隐喻来说明同一条件下不同的人罹患不同疾病的相对抽象现象,中医古籍中将“金木水火土”五种物质的认知象征化或形象化,并其相生、相克、相乘和相悔的关系结构化,并将这一结构运用到人五脏六腑的结构认知中,从而产生了肝木、心火、脾土、肺金和肾水等结构概念,并用五行之间的结构关系解释五脏六腑间的传导关系。
应用认知语言学的方法以及语料库语言学的方法,遴选中医病因病机领域六淫——风、寒、暑、湿、燥、火等,正邪相争,阴阳失调,升降失常等基本的概念隐喻来研究相关条文的语义,进一步分析人体、证候、症状、病因、药方等之间的关系。
第六,对模糊化处理后的数据库进行知识图谱构建,采用当前较为成熟的知识图谱构建方法进行分析计算;
知识图谱构建具体方法为:对中医古籍诊治失眠病症数据库中实体词语进行提取,通过基于记忆网络和基于统计方法神经网络进行实体识别,利用结合注意力机制的神经网络对实体关系进行抽取,以实体为节点,以实体关系为边集,进行知识图谱的建立。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!