基于自适应风险度的安全半监督学习的脑电信号识别方法与流程
本发明属于脑-机接口领域,涉及一种基于自适应风险度的安全半监督学习的脑电信号识别方法。
技术背景
基于运动想象的bci系统通过采集受试者的大脑皮层信号,并对信号进行建模,然后解读出受试者的大脑意图或指令,实现大脑对轮椅、智能假肢等外部设备的控制。对于中枢神经系统受到严重损伤的患者,基于运动想象的bci系统提供了一种与外界交流和控制的途径,有助于提高其生活质量和自理能力,在康复医疗、军事等领域具有重大实际意义。
提高对运动想象模式的识别率是bci系统的核心所在,要获得高性能的识别算法需要采取充足的标记样本,给受试者带来精神压力和工作量。而且采集到的运动想象数据可能会具有一定的风险性,导致信号识别率下降。因此减少用户训练时间和提高算法识别率成为了bci系统实用化的亟待解决的问题。针对如何减少受试者训练时间的问题,bci国际竞赛2005年给出了用于竞赛的运动想象标准数据集(iva),该数据集只包含少量的标记样本。为了解决该问题,李远清等人2008年首次将半监督学习算法引入脑电信号识别中,用于识别右手/脚两类运动想象任务,获得了良好的效果。尧德中等人将tsvm用于识别多类运动想象脑电信号,采用一对多策略将算法推广到三类情形,在不同标记样本数量下平均识别率最高为71.7%,但相比于传统的svm算法,提高了2%-9%。以上研究表明,基于半监督学习的脑电信号识别算法能够较好地提高bci系统识别性能。在安全半监督学习算法方面,m.kawakita等人于2014年在该算法的基础上进一步将离散的样本空间推广到连续空间,提出了一种新的安全半监督学习算法,并应于回归问题中。国内研究者也相继关注了这一问题,李宇峰和周志华于2011年同时提出了两种安全的半监督支持向量机(s4vms和s3vm-us),获得了较好的分类结果。但是目前在多类问题上,缺少基于自适应的安全半监督信号识别方法。
技术实现要素:
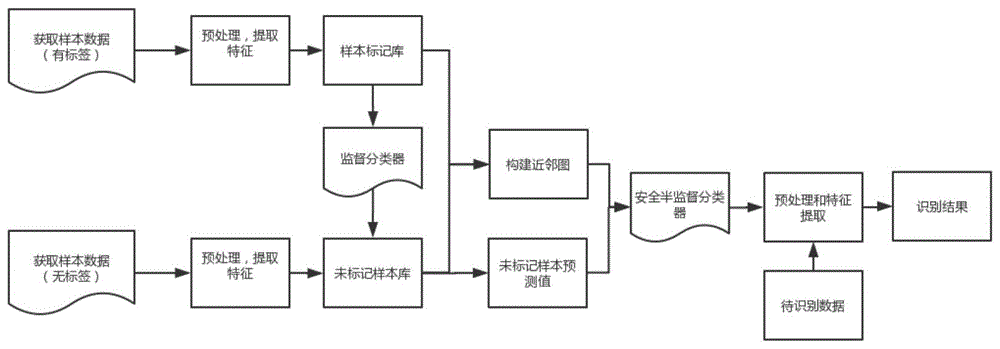
本发明是针对提高半监督分类器的准确度,提出一种基于自适应安全半监督学习的脑电信号识别方法。基本思路是首先进行样本预处理和特征提取。组成标记和未标记脑电信号样本库。计算近邻图w,训练多类监督分类器g(x)并且得到未标记样本预测标签。利用l2,1范数构建目标函数,利用交替迭代优化技术求解优化问题,得到最终的安全半监督分类器f(x)。本方法能够自适应的识别脑电信号,增强了bci系统的识别性能和鲁棒性。
技术方案:一种基于自适应安全半监督学习的脑电信号识别方法,包含以下步骤:
步骤一:采集受试者的脑电信号,其中部分经过人为标注,组成标记数据;剩下的构成未标记数据。
步骤二:对样本数据进行预处理,使用的方法是独立成分分析(independentcomponentanalysis,ica),之后通过共空间模式(commonspatialpattern,csp)进行特征提取,从而组成标记和未标记脑电信号样本库。
步骤三:构建近邻图w,通过从标记样本训练多类监督分类器g(x),之后得到未标记样本预测值。
步骤四:利用l2,1范数构建目标函数,通过迭代优化得到最优的矩阵系数从而得到最好的安全半监督分类器f(x)。
步骤五:输入待识别信号,通过预处理和特征提取,获取样本特征,利用安全半监督分类器f(x)对样本信号进行识别,得到识别结果。
本发明相对于现有技术所具有的效果:本方法所需的标记样本数量较少,可自适应估计和降低标记和未标记样本的风险,提高脑电信号的识别率,增强了bci系统的鲁棒性和实用性。
附图说明
图1为本发明具体实施流程图;
具体实施方式
结合说明书附图进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
如图1所示,本发明的实施主要包含四个步骤:(1)脑电信号的输入和预处理,组成数据库;(2)构建近邻图w,并且训练多类监督分类器,得到未标记样本的预测标签;(3)利用l2,1范数构建优化问题,得到目标函数,通过迭代优化的方式训练安全半监督分类器;(4)输入待识别信号,利用安全半监督分类器进行信号识别
步骤一:输入标记和未标记eeg信号
有多类想象任务,共有c类,采集受试者的脑电信号,其中部分经过人为标注。分为xa和xb,xa类是已经标记过的样本,标签y有c类,xb类是未标记过的样本样本。标记和未标记样本数量分别为na和nb。
步骤二:对样本数据进行预处理和特征提取。
首先使用独立成分分析(ica)进行数据预处理。将已标记的样本作为训练集,未标识的样本作为测试集。
使用csp进行特征提取,首先利用多类标记样本计算协方差矩阵,
然后计算混合空间协方差矩阵,由奇异值分解定理进行特征分解,之后计算白化矩阵。接下来构造空间滤波器,最后得到特征向量。
步骤三:通过从标记样本库提取训练集,训练多类监督分类器g(x)。多类监督分类器的目标函数:
其中yi表示标记样本的标签,λ为正则化系数;
利用再生核理论和representertheorem,把目标函数改写为矩阵形式:
对于d维样本其中标记样本有l组,y∈rc为c维标签向量,若xi属于c中第k类,则y的第i行第k列yik的值为1,其余为0。||·||2为关于表达式的二范数,||g||k表示函数g(x)分类器的rkhs范数,使用mercer核计算gram矩阵k,其中k由所有标记和未标记样本构成,上式中的kl表示的是k的前l行和l列:
通过对目标函数的α求导为零求出g(x)。
g(x)=kα'。
之后得到未标记样本预测标签。
步骤四:考虑到标记和未标记样本的风险性,建立基于自适应风险度的安全半监督学习算法,从而安全使用运动想象数据,以更好地提高分类器的鲁棒性和识别率,其目标函数如下:
其中上述所有λ1,λ2,λ3均为正则化系数,yi表示标记样本的标签,fk表示函数f(x)分类器的rkhs范数,;
wij为p近邻图w中样本之间的权重,其表达式为:
其中np(xi)表示xi的邻近数据集;σ表示高斯核宽度。
所述的目标函数涉及到l1,2范数,传统的求解稀疏方法并不能有效解决此类问题因此,本方法拟采用交替迭代优化方法寻找最优值。将上述目标函数转换为:
其中:
上述三式子中的ζ是极其小的数字,在优化问题中,si和rj看作标记样本的安全度和未标记样本的风险度。对于标记样本xi,如果其预测值和真实值的差距越小,表示风险度越小,那么所占的权重应该更大,即si越大。换句话说,对于风险度高的标记样本xi,其权重si应该较小,对目标函数的影响也就较小。
对于未标记样本xj,如果其风险度rj较小,则其预测结果更倾向于半监督学习算法,也就是最后一项的权重较小;如果风险度rj较大,由于增强了最后一项的权重,其预测结果更倾向于监督学习算法。因此,本方法可降低标记和未标记样本的使用风险。pij可以看作拉普拉斯图
根据再生核理论和representertheorem,更新上述目标优化函数:
ku为k的后u行也就是未标记行,kul是的ku前l列,对角矩阵s,r中sii=si,rii=rj,
更新α*之后可对s,p,r进行更新;直至达到最优解。
步骤五:输入新的信号,进行预处理和特征提取,得到样本xc,计算核函数kc,利用安全半监督模型得到结果。
- 还没有人留言评论。精彩留言会获得点赞!