通过语音分析估计肺容量的制作方法
通过语音分析估计肺容量
发明领域
1.本发明总体上涉及医疗诊断领域,并且尤其涉及肺容量的估计。
2.背景
3.医学界认识到肺容量的各种度量。例如,肺的肺活量(vc)被定义为深度吸气后肺中的空气体积和深度呼气后肺中的空气体积之差。潮气体积(tv)是正常吸气后的空气体积和正常呼气后的空气体积之差。(休息时tv可能低至vc的10%)。传统上,肺容量是在医院或诊所用肺活量计测量的。患有诸如哮喘、慢性阻塞性肺疾病(copd)和充血性心力衰竭(chf)的疾病的患者可能会经历肺容量减少。
4.美国专利申请公开2015/0216448(其公开内容通过引用并入本文)描述了用于测量用户肺活量和耐力以检测慢性心力衰竭、copd或哮喘的计算机化方法和系统。该方法包括在用户的移动通信设备上提供客户端应用,所述客户端应用包括用于执行以下操作的可执行的计算机代码:指导用户用空气来填充他的肺,并在呼气的同时发出一定响度(分贝)范围内的语声;通过移动通信设备接收并登记所述用户的语声;停止语声的登记;测量在所述响度范围内的语声接收时间的长度;以及在移动通信设备屏幕上显示接收时间的长度。
5.国际专利申请公开wo/2017/060828(其公开内容通过引用并入本文)描述了一种包括网络接口和处理器的装置。处理器被配置为经由网络接口接收患有与过量流体的积聚相关的肺部病症的受试者的语音,通过分析语音识别语音的一个或更多个语音相关参数,响应于语音相关参数评估肺部病症的状态,并且响应于此而生成指示肺部病症的状态的输出。
6.国际专利申请公开wo/2018/021920描述了一种语音气流测量系统,该语音气流测量系统包括特征提取模块,该特征提取模块被配置为从至少第一传感器和第二传感器接收与用户相关联的输入信号,并且从输入信号的至少一部分确定气流的估计形状和/或速率。该系统还可以包括头戴式装置,该头戴式装置包括第一传感器,该第一传感器定位在用户的至少第一气流内;第二传感器,该第二传感器定位在用户的至少第二气流内;以及遮蔽构件,该遮蔽构件适于遮蔽第一传感器免受第二气流影响,该屏蔽构件适于在用户使用头戴式装置时在屏蔽构件和用户面部之间提供空气间隙。
7.美国专利申请公开2016/0081611描述了用于分析与人的健康相关的气流的信息处理系统、计算机可读储存介质和方法。一种方法包括:获得人的语言交流的音频样本,获得人的地理信息,基于地理信息查询远程服务器,以及从远程服务器获得附加信息,该附加信息与地理信息相关,以及从一段时间内的至少一个音频样本中提取幅度变化的轮廓,幅度变化的轮廓对应于人的气流分布(profile)的变化。该方法还包括将幅度变化的轮廓与气流相关健康问题的典型周期性发作相关联,并且至少基于附加信息来确定幅度变化的轮廓是否由与地理信息相关的至少一个局部环境因素造成。
8.美国专利6,289,313描述了一种通过观察从数字语音编码器输出的声道参数值来估计人类生理和/或心理状况的状态的方法。用户对他的设备说话,该设备将输入语音从模拟形式变换为数字形式,对导出的数字信号执行语音编码,并本地提供语音编码参数值以
供进一步分析。存储的数学关系(例如用户特定的声道变换矩阵)被从存储器中检索并且用于计算相应的状况参数。基于这些计算的参数,可以导出用户状况的当前状态的估计。
9.美国专利申请公开2015/0126888描述了通过处理受试者用力呼气动作的声音的数字音频文件来生成基于呼气流量的肺功能数据的设备、系统和方法。一种被配置为生成基于呼气流量的肺功能数据的移动设备包括麦克风、处理器和数据储存设备。麦克风可操作来将受试者的用力呼气动作的声音转换成数字数据文件。处理器可操作地与麦克风耦合。数据储存设备可操作地与处理器耦合,并存储指令,当该指令被处理器执行时,使得处理器处理数字数据文件,以生成用于评估受试者的肺功能的基于呼气流量的肺功能数据。受试者的用力呼气动作的声音可以被转换成数字数据文件,而无需受试者的嘴和移动设备之间的接触。
10.murton、olivia m.等人,“acoustic speech analysis of patients with decompensated heart failure:a pilot study”,美国声学学会杂志142.4(2017):el401
‑
el407描述了一项使用声学语音分析监测患有心力衰竭(hf)的患者的初步研究,心力衰竭(hf)的特征是心脏内充盈压力增加和外周水肿。据推测,声带和肺部与hf相关的水肿会影响发声和语音呼吸。根据从接受住院利尿剂治疗的10例hf患者每日记录的持续元音段落和语音段落计算出声音扰动和语音呼吸特征的声学度量。治疗后,患者显示出较高比例的自动识别的嘎裂声(creaky voice)、增加的基频和减少的倒频谱峰突出变化,表明语音生物标记物可以作为hf的早期指标。
11.发明概述
12.根据本发明的一些实施例,提供了一种包括电路和一个或更多个处理器的系统。处理器被配置为协同执行过程,该过程包括从电路接收表示由受试者发出的语音的语音信号,该语音包括一个或更多个语音片段。该过程还包括将语音信号分成多个帧,使得帧的一个或更多个序列分别表示语音片段。该过程还包括通过对每个序列,计算由受试者在属于该序列的帧的期间呼出的空气的相应的估计的流速,并基于该估计的流速计算估计的空气总体积中相应的一个,来计算由受试者在发出语音片段的同时呼出的相应的估计的空气总体积。该过程还包括响应于估计的空气总体积,生成警报。
13.在一些实施例中,电路包括网络接口。
14.在一些实施例中,电路包括模数转换器,该模数转换器被配置为将表示语音的模拟信号转换成语音信号。
15.在一些实施例中,一个或更多个处理器由单个处理器组成。
16.在一些实施例中,每个帧的持续时间在5ms和40ms之间。
17.在一些实施例中,
18.一个或更多个语音片段包括通过相应的停顿彼此分开的多个语音片段,并且
19.该过程还包括通过区分表示语音片段的帧序列和表示停顿的帧序列来识别帧序列。
20.在一些实施例中,对于属于序列的帧中的每个帧,计算相应的估计的流速包括:
21.计算该帧的一个或更多个特征,以及
22.通过对至少一个特征应用将该至少一个特征映射到估计的流速的函数来计算估计的流速。
23.在一些实施例中,该过程还包括在接收信号之前:
24.接收表示由受试者发出的其它语音的校准语音信号,
25.接收气流速率信号,该气流速率信号表示由受试者在发出该其它语音时呼出的空气的测量的流速,以及
26.使用校准语音信号和气流速率信号,学习将至少一个特征映射到估计的流速的函数。
27.在一些实施例中,至少一个特征包括帧的能量。
28.在一些实施例中,该函数是至少一个特征的多项式函数。
29.在一些实施例中,该过程还包括:
30.基于特征,识别帧所属的声学语音单元(apu),以及
31.响应于apu选择函数。
32.在一些实施例中,从由音素、双音素、三音素和合成声学单元组成的apu类型的组中选择apu的类型。
33.在一些实施例中,
34.一个或更多个语音片段包括多个语音片段,
35.该过程还包括计算估计的空气总体积的一个或更多个统计数据,以及
36.生成警报包括响应于至少一个统计数据偏离基线统计数据来生成警报。
37.在一些实施例中,语音由受试者在受试者躺下时发出。
38.在一些实施例中,该过程还包括:
39.接收另一个语音信号,该另一个语音信号表示由受试者在受试者未躺下时发出的其它语音,以及
40.从该另一个语音信号计算基线统计数据。
41.在一些实施例中,该过程还包括从表示受试者的先前语音的另一个语音信号计算基线统计数据。
42.在一些实施例中,至少一个统计数据是从由平均值、标准偏差和百分位数组成的统计数据的组中选择的统计数据。
43.在一些实施例中,语音由音频传感器捕获,并且该过程还包括,在计算相应的估计的空气总体积之前,基于在发出语音时获取的嘴的图像,归一化语音信号以考虑到(account for)音频传感器相对于受试者的嘴的位置。
44.根据本发明的一些实施例,还提供了包括网络接口和处理器的装置。处理器被配置为经由网络接口接收表示由受试者发出的语音的语音信号,该语音包括一个或更多个语音片段。处理器还被配置为将语音信号分成多个帧,使得帧的一个或更多个序列分别表示语音片段。处理器还被配置为通过对每个序列,计算由受试者在属于该序列的帧的期间呼出的空气的相应的估计的流速,并基于该估计的流速计算估计的空气总体积中相应的一个,来计算由受试者在发出语音片段的同时呼出的相应的估计的空气总体积。处理器还被配置为响应于估计的空气总体积,生成警报。
45.在一些实施例中,每个帧的持续时间在5ms和40ms之间。
46.在一些实施例中,
47.一个或更多个语音片段包括通过相应的停顿彼此分开的多个语音片段,并且
48.处理器还被配置为通过区分表示语音片段的帧序列和表示停顿的帧序列来识别帧序列。
49.在一些实施例中,处理器被配置为通过对属于序列的帧中的每一帧,通过以下方式计算相应的估计的流速:
50.计算帧的一个或更多个特征,以及
51.通过对至少一个特征应用将该至少一个特征映射到估计的流速的函数来计算估计的流速。
52.在一些实施例中,处理器还被配置为在接收信号之前:
53.接收表示由受试者发出的其它语音的校准语音信号,
54.接收气流速率信号,该气流速率信号表示由受试者在发出该其它语音时呼出的空气的测量的流速,以及
55.使用校准语音信号和气流速率信号,学习将至少一个特征映射到估计的流速的函数。
56.在一些实施例中,至少一个特征包括帧的能量。
57.在一些实施例中,该函数是至少一个特征的多项式函数。
58.在一些实施例中,处理器还被配置为:
59.基于特征,识别帧所属的声学语音单元(apu),以及
60.响应于apu选择函数。
61.在一些实施例中,从由音素、双音素、三音素和合成声学单元组成的apu类型的组中选择apu的类型。
62.在一些实施例中,
63.一个或更多个语音片段包括多个语音片段,
64.处理器还被配置为计算估计的空气总体积的一个或更多个统计数据,并且
65.处理器被配置为响应于至少一个统计数据偏离基线统计数据来生成警报。
66.在一些实施例中,语音由受试者在受试者躺下时发出。
67.在一些实施例中,处理器还被配置为:
68.接收另一个语音信号,该另一个语音信号表示受试者在受试者未躺下时发出的其它语音,以及
69.从该另一个语音信号计算基线统计数据。
70.在一些实施例中,至少一个统计数据是从由平均值、标准偏差和百分位数组成的统计数据的组中选择的统计数据。
71.在一些实施例中,处理器还被配置为从表示受试者的先前语音的另一个语音信号计算基线统计数据。
72.在一些实施例中,语音由音频传感器捕获,并且处理器还被配置为在计算相应的估计的空气总体积之前,基于在发出语音时获取的嘴的图像,归一化语音信号以考虑到音频传感器相对于受试者的嘴的位置。
73.根据本发明的一些实施例,还提供了一种包括模数转换器的系统,该模数转换器被配置为将表示由受试者发出的语音的模拟信号转换成数字语音信号,该语音包括一个或更多个语音片段。该系统还包括一个或更多个处理器,该一个或更多个处理器被配置为协
同执行过程,该过程包括:从模数转换器接收语音信号,将语音信号分成多个帧,使得帧的一个或更多个序列分别表示语音片段,通过对每个序列,计算由受试者在属于该序列的帧的期间呼出的空气的相应的估计的流速,并基于该估计的流速计算估计的空气总体积中的相应的一个,来计算由受试者在发出语音片段的同时呼出的相应的估计的空气总体积,并且响应于估计的空气总体积,生成警报。
74.根据本发明的一些实施例,还提供了一种方法,该方法包括接收表示由受试者发出的语音的语音信号,该语音包括一个或更多个语音片段。该方法还包括将语音信号分成多个帧,使得帧的一个或更多个序列分别表示语音片段。该方法还包括通过对每个序列,计算由受试者在属于该序列的帧的期间呼出的空气的相应的估计的流速,并基于该估计的流速计算估计的空气总体积中相应的一个,来计算由受试者在发出语音片段的同时呼出的相应的估计的空气总体积。该方法还包括响应于估计的空气总体积,生成警报。
75.根据本发明的一些实施例,还提供了一种计算机软件产品,该计算机软件产品包括其中存储有程序指令的有形的非暂时性计算机可读介质。指令在由处理器读取时使得处理器:接收表示由受试者发出的语音的语音信号,该语音包括一个或更多个语音片段,将语音信号分成多个帧,使得帧的一个或更多个序列分别表示语音片段,通过对每个序列,计算由受试者在属于该序列的帧的期间呼出的空气的相应的估计的流速,并基于该估计的流速计算估计的空气总体积中相应的一个,来计算由受试者在发出语音片段的同时呼出的相应的估计的空气总体积,并且响应于估计的空气总体积生成警报。
76.根据结合附图进行的本发明的实施例的以下详细描述,本发明将得到更完全地理解,其中:
77.附图简述
78.图1是根据本发明的一些实施例的用于测量受试者的肺容量的系统的示意图;
79.图2
‑
3示意性地示出了根据本发明的一些实施例的用于校准图1的系统的技术;以及
80.图4是根据本发明的一些实施例的语音信号的处理的示意图。
具体实施方式
81.介绍
82.说话时,人倾向于在短暂的呼吸暂停期间吸气,而呼气会延长并受到控制。如本文使用的术语“语音呼气体积”(sev)指的是紧接在呼吸暂停之后的肺中的空气的体积与紧邻下一次呼吸暂停之前的肺中的空气的体积之间的差。sev通常明显大于休息时的tv,并且可能与vc的25%一样大。基于语音的响度、语音的语音学内容和语音的韵律,sev通常随呼吸而变化。
83.在下面的描述中,表示向量的符号被加下划线,使得例如符号“x”指示向量。
84.综述
85.许多患有肺部疾病的患者必须定期(有时甚至每天)监测其肺容量,以便在患者病情恶化的情况下能够进行早期医疗干预。然而,在医院或诊所进行常规肺活量计测试可能不方便且成本高。
86.因此,本发明的实施例提供了一种用于有效且方便地测量患者的肺容量(特别是
患者的sev)的过程,而不需要患者前往诊所。该过程可以由患者自己在患者家中仅仅使用电话(例如,智能手机或其它移动电话)、平板电脑或任何其它合适的设备进行,无需任何医务人员的直接参与。
87.更具体地,在本文描述的实施例中,患者的语音由设备捕获。然后自动分析该语音,并从所捕获的语音中计算出与患者的sev相关的统计数据(例如患者的平均sev)。随后,将统计数据与基线统计数据(例如在患者病情稳定时进行的先前会话的统计数据)进行比较。如果比较显示肺容量减小,并且因此显示患者病情恶化,则生成警报。
88.在上述过程之前,通常在医院或诊所执行校准过程。在校准期间,患者对着麦克风说话,同时测量(例如通过呼吸速度描记器(pneumotachograph)(还称为气流速度描记器(pneumotach)))患者的瞬时气流速率。来自患者的语音信号被采样和数字化,然后被分成大小相等的帧{x1,x2,
…
x
n
},每个帧的长度通常在5ms和40ms(例如,10ms
‑
30ms)之间,并且包括多个样本。然后从每个帧x
n
中提取特征向量v
n
。随后,基于特征向量{v1,v2,
…
v
n
}和从气流速度描记器测量结果导出的对应气流速率{φ1,φ2,
…
φ
n
},学习语音到气流速率函数φ(v),该函数φ(v)根据帧的特征来预测给定语音帧期间呼出的空气的流速。
89.例如,特征向量可以仅包括单个量这是帧的总能量。在这样的实施例中,语音到气流速率函数φ(v)=φ(u)可以通过根据帧能量回归气流速率来学习。因此,例如,函数可以是形式为φ
u
(u)=b0+b1u+b2u2+
…
+b
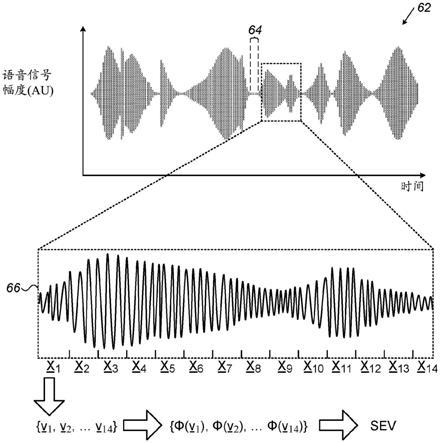
q
u
q
的多项式。
90.可替代地,特征向量可以包括帧的其它特征。基于这些特征,使用语音识别技术,每个帧或帧序列可以被映射到例如音素、双音素、三音素或合成声学单元的声学
‑
语音单元(apu)。换句话说,帧序列{x1,x2,
…
x
n
}可以被映射到apu序列{y1,y2,
…
y
r
},其中r≤n,该apu序列从一组唯一的apu{h1,h2,
…
h
m
}中提取。随后,可以学习语音到气流速率函数φ(v)=φ(u|h),该函数φ(v)=φ(u|h)随帧所属的apu h而变化。例如,可以针对每个apu根据帧能量分别使气流速率回归,使得针对每个apu获得一组不同的多项式系数{b0,b1,
…
b
q
}。因此,有利的是,语音到气流速率函数不仅可以考虑语音的能量,而且可以考虑语音的内容,如上所述,语音的内容影响sev。
91.在校准过程之后,如上所述,捕获患者的语音。捕获的语音然后被分成帧,如上所述用于校准过程。随后,从每个帧提取特征向量v
n
,并且识别吸气暂停。位于连续吸气暂停之间的每个语音帧序列{x1,x2,
…
x
l
}然后被识别为不同的相应单个呼气语音片段(sess)。随后,针对每个sess计算sev。特别地,给定sess的特征向量{v1,v2,
…
v
l
},sev可以被计算为其中t
l
是sess的持续时间。因此,给定m个sess,计算m个sev值{sev1,sev2,
…
sev
m
}。
92.随后,针对sev值计算统计数据。这些统计数据可以包括例如平均值、中位数、标准偏差、最大值或其它百分位数(例如第80个百分位数)。如上所述,然后可以将这些统计数据与来自先前分析的统计数据进行比较(例如,通过计算统计数据之间的各种差异或比率)。如果比较指示患者病情恶化,则可以生成报警。例如,可以响应于患者的平均sev的显著降低而生成报警。
93.在一些情况下,可以指导患者以更有可能显示患者医疗状况恶化的姿势来产生语音。例如,chf通常伴有端坐呼吸,即躺下时呼吸急促,使得chf患者的肺功能的微小变化只
有在患者躺下时才可以检测到。因此,为了对chf患者进行更有效的诊断,可以指导患者在躺下时(例如以仰卧位)说话。然后,可以将针对该位置计算的sev统计数据与针对不同位置(例如,就坐位置)计算的sev统计数据进行比较,并且如果观察到躺卧位置的sev较低,则可以生成报警。可替代地或附加地,可以将针对躺卧位置和/或躺卧位置与另一个位置之间的不一致性(disparity)的sev统计数据与先前的会话进行比较,并且可以响应于此生成报警。
94.本文所述的实施例可应用于患有影响肺容量的任何类型疾病(例如chf、copd、间质性肺疾病(ild)、哮喘、急性呼吸窘迫综合征(ards)、帕金森氏病、肌萎缩侧索硬化症(ald)或囊性纤维化(cf))的患者。
95.系统描述
96.首先参考图1,图1是根据本发明的一些实施例的用于测量受试者22的肺容量的系统20的示意图。
97.系统20包括由受试者22使用的音频接收设备32(例如移动电话、平板电脑、膝上型电脑或台式电脑)。设备32包括音频传感器38(例如麦克风)、处理器36和通常包括音频到数字(a/d)转换器42和网络接口(例如网络接口控制器(nic)34)的其它电路。典型地,设备32还包括数字储存设备,例如固态闪存驱动器、屏幕(例如触摸屏)和/或其它用户界面部件(例如键盘)。在一些实施例中,音频传感器38(以及可选地,a/d转换器42)属于设备32外部的单元。例如,音频传感器38可以属于通过有线连接或无线连接(例如蓝牙连接)连接到设备32的头戴式装置。
98.系统20还包括服务器40,该服务器40包括处理器28、例如硬盘驱动器或闪存驱动器的数字储存设备30(其还可以称为“存储器”)以及通常包括网络接口(例如网络接口控制器(nic)26)的其它电路。服务器40还可以包括屏幕、键盘和/或任何其它合适的用户界面部件。典型地,服务器40位于远离设备32的位置(例如在控制中心),并且服务器40和设备32通过网络24经由它们相应的网络接口彼此通信,该网络24可以包括蜂窝网络和/或互联网。
99.典型地,设备32的处理器36和服务器40的处理器28协同执行下面详细描述的肺容量评估技术。例如,当用户对设备32讲话时,用户语音的声波可以由音频传感器38转换成模拟语音信号,该模拟语音信号转而可以被a/d转换器42采样和数字化。(通常,可以以任何合适的速率(例如在8khz和45khz之间的速率)对用户的语音进行采样)。处理器36可以接收所得到的数字语音信号。处理器36然后可以经由nic 34将语音信号传送到服务器40,使得处理器28从nic 26接收语音信号。
100.随后,通过如下文参考图4所述处理语音信号,处理器28可以估计在受试者22发出各种语音片段时由该受试者呼出的空气的总体积。处理器28然后可以计算估计的空气总体积的一个或更多个统计数据,并将这些统计数据中的至少一个与存储在储存设备30中的基线统计数据进行比较。响应于至少一个统计数据偏离基线统计数据,处理器28可以生成警报(例如音频警报或视觉警报)。例如,处理器28可以向受试者和/或受试者的医生发出呼叫或发送文本消息。可替代地,处理器28可以将偏差通知给处理器36,然后处理器36可以生成警报(例如通过在设备32的屏幕上显示消息来将偏差通知给受试者)。
101.在其它实施例中,处理器36执行数字语音信号的至少一些处理。例如,处理器36可以估计受试者22呼出的空气的总体积,然后计算这些估计体积的统计数据。随后,处理器36
可以将统计数据传送给处理器28,然后处理器28可以执行与基线的比较,并且在适当的情况下生成警报。可替代地,整个方法可以由处理器36执行,使得系统20不必一定包括服务器40。
102.在另外的其它实施例中,设备32包括不包括a/d转换器或处理器的模拟电话。在这样的实施例中,设备32通过电话网络将模拟音频信号从音频传感器38发送到服务器40。典型地,在电话网络中,音频信号被数字化、以数字方式进行传送,然后在到达服务器40之前被转换回模拟的。因此,服务器40可以包括a/d转换器,该a/d转换器将经由合适的电话网络接口接收的输入模拟音频信号转换成数字语音信号。处理器28从a/d转换器接收数字语音信号,然后如本文所述处理该信号。可替代地,服务器40可以在信号被转换回模拟之前从电话网络接收信号,使得服务器不一定包括a/d转换器。
103.典型地,服务器40被配置为与属于多个不同受试者的多个设备通信,并处理这些多个受试者的语音信号。典型地,储存设备30存储数据库,在该数据库中存储了针对受试者的基线统计数据和/或其它历史信息。储存设备30可以在服务器40内部(如图1所示)或者在服务器40外部。处理器28可以被实现为单个处理器,或者被实现为处理器的协同网络化或集群的集合。例如,控制中心可以包括多个互连的服务器,这些服务器包括相应的处理器,这些处理器协同地执行本文描述的技术。
104.在一些实施例中,如本文所述,处理器28和/或处理器36的功能仅在硬件中(例如使用一个或更多个专用集成电路(asic)或现场可编程门阵列(fpga))实现。在其它实施例中,处理器28和处理器36的功能至少部分地在软件中实现。例如,在一些实施例中,处理器28和/或处理器36被实现为包括至少中央处理单元(cpu)和随机存取存储器(ram)的编程的数字计算设备。包括软件程序的程序代码和/或数据被加载到ram中以由cpu执行和处理。程序代码和/或数据可以例如通过网络以电子形式下载到处理器。可替代地或附加地,程序代码和/或数据可以被提供和/或存储在非暂时性有形介质(例如磁存储器、光存储器或电子存储器)上。这种程序代码和/或数据在被提供给处理器时产生机器或专用计算机,其被配置为执行本文所述的任务。
105.校准
106.现在参考图2
‑
3,其示意性地示出了根据本发明的一些实施例的用于校准系统20的技术。
107.在测量受试者22的肺容量之前,通常在医院或其他临床环境中执行校准过程,在该校准过程期间,服务器40学习将受试者语音的特征向量v映射到来自受试者的肺的空气的流速φ的函数φ(v)。使用同时捕获受试者的语音并测量来自受试者的肺的气流速率的设备来执行校准,使得语音可以与气流速率相关联。
108.例如,可以使用气流速度描记器44来执行校准。当受试者22对着气流速度描记器44说话时,设置在气流速度描记器内部的包括例如麦克风和a/d转换器的声音捕获单元52捕获受试者发出的语音,并将表示发出的语音的数字校准语音信号56输出到服务器40。同时,气流速度描记器测量受试者在发出语音的同时呼出的空气的流速。特别地,属于气流速度描记器的压力传感器48感测气流速度描记器网板46近端和远端的压力,并输出指示感测的压力的相应信号。基于这些信号,电路50计算网板46两端的压降,并进一步计算受试者呼气的流速,该流速与压降成比例。电路50向服务器40输出表示气流速率的数字气流速率信
号54(例如,以升/分钟为单位)。(在电路50输出模拟信号的情况下,该信号可以由属于服务器40的a/d转换器转换成数字气流速率信号54)。
109.气流速度描记器44可以包括任何合适的现成产品,例如由日本东京hoya公司的pentax medical提供的phonatory aerodynamic system
tm
(发音气动系统
tm
)。声音捕获单元52可以在其制造期间与气流速度描记器集成在一起,或者可以在校准之前专门安装。
110.在接收到校准语音信号56和气流速率信号54之后,服务器40的处理器28使用这两个信号来学习φ(v)。首先,处理器将校准语音信号分成多个校准信号帧58,每个帧具有任何合适的持续时间(例如,5ms
‑
40ms)和任何合适数量的样本。典型地,所有帧都具有相同的持续时间和相同数量的样本。(在图3中,每个帧的开始和结束由沿着水平轴的短垂直记号标记)。
111.接下来,处理器计算每个帧58的相关特征。这样的特征可以包括例如,帧的能量、帧中的过零率和/或表征帧的频谱包络的特征,例如帧的线性预测系数(lpc)或倒频谱系数,其可以如furui,sadaoki的“digital speech processing:synthesis and recognition,”(crc出版社,2000年)中所述的那样进行计算,该文献通过引用并入本文。基于这些特征,处理器可以计算帧的一个或更多个高级特征。例如,基于能量和过零率,处理器可以计算指示帧是否包含有声语音或无声语音的特征,如例如在bachu,r.等人的“separation of voiced and unvoiced speech signals using energy and zero crossing rate,”(asee区域会议,west point,2008)中所描述的,该文献通过引用并入本文。随后,处理器在该帧的特征向量v中包括一个或更多个计算的特征。
112.此外,对于每一帧,处理器计算气流速率φ(例如,通过在该帧跨越的时间间隔上对气流速率信号54进行平均或获取气流速率信号54的中位数,或者通过在该帧的中间处获取信号54的值)。处理器然后学习特征和气流速率值之间的相关性。
113.例如,处理器可以从校准语音信号56中导出帧能量信号60,该帧能量信号60包括每个帧的相应的帧能量u。接下来,处理器可以根据帧能量回归气流速率。处理器因此可以计算形式为φ
u
(u)=b0+b1u+b2u2+
…
+b
q
u
q
的多项式,该多项式在给定任何帧能量u的情况下,返回估计的气流速率φ
u
(u)。典型地,对于该多项式,b0=0。在一些实施例中,q=2(即,φ
u
(u)是二阶多项式),并且b1>0。通常,b1、b2和任何高阶系数的精确数值取决于各种参数(例如音频传感器38的增益、a/d转换器42的步长以及气流和语音信号的表达单位)。
114.在一些实施例中,处理器使用语音识别技术(例如下面描述的隐马尔可夫模型技术),基于帧的特征识别每个帧或帧序列所属的apu h。然后,处理器针对每个apu或针对每组相似的apu学习单独的映射函数φ(v|h)。
115.例如,上述回归可以针对每个apu单独执行,使得针对每个apu学习相应的多项式φ
u
(u)。一般而言,对于有声的音素,并且尤其是元音,说话者使用相对较低量的呼气气流生成相对较高的语音能量水平,而无声的音素需要更多的气流来生成相同量的语音能量。因此,相对于无声的音素,b1对于无声的音素可能更大(例如,大4倍
‑
10倍)。因此,作为纯粹说明性的示例,如果φ(u|/a/)(对于音素“/a/”)是0.2u
–
0.005u2,则φ(u|/s/)可能是1.4u
–
0.06u2。能量和气流之间的关系对于具有清晰过渡的辅音(例如,爆破音)相对于持续辅音可能更加非线性,使得φ针对前者可以包括更多高阶项。因此,继续上面的示例,对于爆破音/p/,φ(u|/p/)可以是u
–
0.2u2–
0.07u3。
116.一般而言,φ(v)可以包括如上文关于帧能量所描述的单变量多项式函数或多个特征的多变量多项式函数。例如,如果v包括k个分量v
1,
v2,
…
v
k
(帧能量通常是这些分量中的一个),φ(v)可以是形式为b0+b1v1+
…
+b
k
v
k
+b
11
v
12
+b
12
v1v2+
…
+b
1k
v1v
k
+b
22
v
22
+b
23
v2v3+
…
+b
2k
v2v
k
+
…
+b
kk
v
k2
的多变量二次多项式。可替代地或附加地,φ(v)可以包括任何其它类型的函数,例如三角多项式(例如,帧能量u的单变量三角多项式)或指数函数。
117.在一些情况下,受试者的嘴和声音捕获单元52之间的距离d1可以不同于(例如,小于)受试者的嘴和音频传感器38之间的预期距离d2。可替代地或附加地,气流速度描记器可能干扰受试者的语音记录。可替代地或附加地,声音捕获单元52的属性可以不同于音频传感器38的属性。
118.为了补偿这些差异,可以执行初步的校准过程。在该过程期间,从扬声器向气流速度描记器播放合适的音频信号,使得音频信号由声音捕获单元52记录。同样的音频信号也在没有气流速度描记器的情况下播放,并且由音频传感器38(或另一个相同的音频传感器)记录,该音频传感器38放置在离扬声器距离d2的地方。基于该初步的校准,学习将声音捕获单元52的记录映射到音频传感器38的记录的传递函数。随后,在学习φ(v)之前,将该传递函数应用于信号56。
119.在一些实施例中,使用上述校准过程,针对每个受试者学习相应的φ(v)。(对于其中φ(v)是依赖于apu的实施例,在校准期间从受试者获得的语音样本通常足够大且多样化,以便为每个感兴趣的apu包括足够数量的样本)。可替代地,可以根据从多个受试者获得的相对应的语音和气流速率信号的大集合导出独立于受试者的φ(v)。作为另一种选择,φ(v)可使用来自多个受试者的数据进行初始化(从而确保涵盖所有感兴趣的apu),然后使用上述校准过程针对每个受试者单独进行修改。
120.估计气流体积
121.现在参考图4,图4是根据本发明的一些实施例的语音信号处理的示意图。
122.在上述校准过程之后,服务器40的处理器28基于受试者的语音使用φ(v)来估计受试者22的肺容量。具体而言,处理器28首先经由设备32(图1)接收语音信号62,该语音信号62表示受试者发出的语音。处理器然后将语音信号62分成多个帧,并计算每个帧的相关特征(如上文参考图3针对信号56所述)。随后,基于这些特征,处理器识别分别表示语音的语音片段(在概述中称为“sess”)的那些帧序列66。
123.例如,受试者的语音可以包括多个语音片段,在这些语音片段期间,受试者产生有声的语音或无声的语音(其通过相应的停顿彼此分开),在相应的停顿期间没有产生语音,使得信号62包括多个序列66(这些序列66由表示停顿的其它帧64彼此分开)。在这种情况下,处理器通过区分表示语音片段的帧的那些序列和其它帧64来识别序列66。为了做到这一点,处理器可以使用与用于将帧映射到apu相同的语音识别技术。(换句话说,处理器可以将没有映射到“非语音”apu的任何帧识别为属于序列66的语音帧)。可替代地,处理器可以使用语音活动检测(vad)算法,例如ramirez,javier等人在“voice activity detection
‑
fundamentals and speech recognition system robustness”(intech,2007)中描述的任何算法,其公开内容通过引用并入本文。然后假设每个序列66对应于单次呼气,而假设序列之间的停顿对应于相应的吸气。
124.随后,处理器计算由受试者在发出语音片段的同时呼出的空气的相应的估计总体
积。为了执行该计算,处理器针对每个序列66计算在属于该序列的帧的期间由受试者呼出的空气的相应的估计的流速,然后,基于该估计的流速,计算针对该序列的空气的估计的总呼出体积,以上称为sev。例如,处理器可以通过将估计的流速乘以帧的持续时间来计算每个帧的估计的体积,然后对估计的体积进行积分。(在序列中的帧具有相同持续时间的情况下,这相当于将估计的流速的平均值乘以序列的总持续时间)。
125.例如,图4示出了包括14个帧{x1,x2,
…
x
14
}的示例序列。为了计算该序列期间由受试者呼出的空气的估计的总体积,处理器首先针对帧{x1,x2,
…
x
14
}中的每一帧计算该帧的一个或更多个特征,如上面参考图3所述。换句话说,处理器计算特征向量{v1,v2,
…
v
14
},或者,在仅使用单个特征(例如,帧能量)的情况下,计算特征标量{v1,v2,
…
v
14
}。然后,处理器通过对帧的至少一个特征应用在校准过程期间学习的适当的映射函数φ(v),来计算每个帧的估计的流速。例如,处理器可以基于帧的特征识别该帧所属的apu,响应于该apu选择适当的映射函数,然后应用所选择的映射函数。处理器因此获得估计的流速{φ(v1),φ(v2),
…
φ(v
14
)}。最后,处理器使用估计的流速来计算空气的总呼出体积。
126.如上文参考图1所述,响应于一个或更多个计算的sev值,处理器可以生成警报。例如,在单个语音片段以及因此单个sev值的情况下,处理器可以将sev与基线sev进行比较。响应于当前sev小于基线sev(例如,超过预定阈值百分比),可以生成警报。可替代地,在多个语音片段的情况下(如图4所示),处理器可以计算sev的一个或更多个统计数据,然后将这些统计数据与相应的基线统计数据进行比较。响应于至少一个统计数据偏离其基线(例如,由于小于或大于基线超过预定阈值百分比),可以生成警报。示例统计数据包括平均值、标准偏差和sev值的任何合适的百分位数(例如第50个百分位数(即中位数)或第100个百分位数(即最大值))。通常,鉴于sev通常随呼吸而变化,因此使用多个sev值的统计数据有助于进行更准确的诊断。
127.在一些实施例中,处理器从表示受试者的先前语音的另一个语音信号计算基线sev或多个sev的基线统计数据。先前的语音可能是例如在受试者病情稳定时的先前时间发出的。
128.在一些实施例中,受试者在躺下时被提示说话,使得信号62表示受试者在躺下时的语音。在这样的实施例中,基线sev或基线统计数据可以从由受试者在未躺下时发出的其它语音来计算。(该其他语音可能是在受试者的病情稳定时的先前时间、或者在当前的时间、在捕获信号62之前或之后发出的)。如果躺卧位置和非躺卧位置之间的不一致性超过阈值不一致性,则可以生成警报。例如,如果非躺卧位置的相关统计数据(例如平均sev)与躺卧位置的相关统计数据之间的百分比差异大于预定义的阈值百分比,或者如果这两个统计数据之间的比率偏离1超过预定义的阈值,则可以生成警报。可替代地或附加地,如果该不一致性大于在先前时间的不一致性,则可以生成警报。例如,如果当受试者的病情稳定时,受试者在躺卧位置的平均sev仅比在非躺卧位置低5%,但是现在受试者的平均sev在躺卧位置低10%,则可以生成警报。
129.在一些实施例中,受试者22被指导在每个会话期间发出相同的预定义的语音。在其它实施例中,会话之间的语音变化。例如,在每个会话期间,可以指导受试者从设备32的屏幕读取不同的相应文本。可替代地,受试者可以被指导自由说话,和/或回答各种问题(例如“你今天感觉如何?”)作为另一种替代,可以根本不提示受试者说话,而是可以在受试者
进行正常对话(例如正常的电话对话)时捕获受试者的语音。
130.在一些实施例中,如图3和图4所示,由处理器28定义的帧彼此不重叠;相反,每一帧中的第一个样本紧接在前一帧的最后一个样本之后。在其它实施例中,在信号56和/或信号62中,帧可以彼此重叠。这种重叠可以是固定的;例如,假设帧持续时间为20ms,每个帧的最前10ms可能与前一帧的最后10ms重叠。(换句话说,帧中最前50%的样本也可能是前一帧中最后50%的样本)。可替代地,重叠的大小可以在信号过程中变化。
131.典型地,如以上描述中假设的,每个帧具有相同的持续时间。可替代地,帧持续时间可以在信号过程中变化。注意,上述技术可以容易地适应于变化的帧持续时间;例如,每个帧x
n
的能量可以被归一化以说明该帧中的样本数量。
132.归一化语音信号
133.一般而言,由音频传感器38捕获的语音的幅度取决于音频传感器相对于受试者的嘴的位置和方向。这带来了挑战,因为如果音频传感器的位置或方向在会话之间变化,则来自不同会话的sev统计数据之间的比较可能不会产生有意义的结果。
134.为了克服这个挑战,音频传感器的位置和方向可以是固定的(例如,通过指导受试者总是将设备32保持在他的耳朵上、或者总是使用其中音频传感器的位置和方向是固定的头戴式装置)。可替代地,在每个会话期间,如上所述,可以指导受试者从设备32的屏幕读取文本,使得受试者总是将设备保持在相对于受试者的嘴大致相同的位置和方向。
135.作为另一种替代,在计算估计的气流速率之前,信号62可以被归一化,以便考虑到音频传感器相对于受试者的嘴的位置和/或方向。为了确定位置和方向,当受试者说话时,属于设备32的相机可以获取受试者的嘴的图像,然后可以使用图像处理技术以从图像计算音频传感器的位置和/或方向。可替代地或附加地,属于该设备的其它传感器(例如红外传感器)可以用于此目的。
136.更具体地,每个帧x
n
可以通过根据归一化方程x
n
=g(p
n
)
‑1z
n
对信号62中的原始帧z
n
进行归一化来计算,其中p
n
是表示在发出z
n
时音频传感器相对于受试者的嘴的位置和方向的向量,并且g(p
n
)是线性时不变算子,其对在给定p
n
的情况下声音到音频传感器的传播效果进行建模。(g(p
n
)=1,表示帧相对于其被归一化的特定位置和方向)。g(p
n
)可以被建模为有限脉冲响应(fir)系统或无限脉冲响应(iir)系统。在一些情况下,g(p
n
)可以被建模为纯衰减系统,使得x
n
=g(p
n
)
‑1z
n
对于标量值函数g(p
n
)简化为x
n
=z
n
/g(p
n
)。一般而言,g(p
n
)可以从声音传播的物理原理以及音频传感器的相关属性(例如音频传感器在各种方向上的增益)导出。
137.将帧映射到apu
138.一般而言,任何合适的技术都可以用来将帧映射到apu。然而,典型地,本发明的实施例利用语音识别中常用的技术(例如隐马尔可夫模型(hmm)技术、动态时间规整(dtw)和神经网络)。(在语音识别中,帧到apu的映射通常构成最终被丢弃的中间输出)。下面,简要描述hmm技术,该hmm技术使用简化的概率模型来产生语音以便于语音识别。
139.人类语音产生系统包括多个发音器官。在语音产生期间,语音产生系统的状态根据产生的声音而变化(例如,相对于每个器官的位置和张力)。hmm技术假设在每个帧x
n
期间,语音产生系统处于特定的状态s
n
。该模型假设从一帧到下一帧的状态转换遵循马尔可夫随机过程,即下一帧的状态概率仅取决于当前帧的状态的概率。
140.hmm技术将特征向量视为随机向量的实例,其概率密度函数(pdf)f
s
(v)由当前帧的状态“s”决定。因此,如果状态序列{s1,s2,
…
s
n
}是已知的,则特征向量序列{v1,v2,
…
v
n
}的条件pdf可以表示为f
s1
(v1)*f
s2
(v2)*
…
*f
sn
(v
n
)。
141.每个apu由特定的状态序列(具有特定的初始状态概率和状态之间的特定转换概率)表示。(尽管有上述说明,但应注意,被称为“合成声学单元”的一种类型的apu仅包含单个状态)。每个字(word)由状态序列表示,该状态序列是构成该字的apu的相应状态序列的连接(concatenation)。如果该字可以用不同的方式发音,则该字可以用几个状态序列来表示,其中每个序列具有对应于发音中出现变体的可能性的初始概率。
142.如果构成受试者话语的字是先验已知的,则该话语可以由状态序列表示,该状态序列是组成字的相应状态序列的连接。然而,在实践中,字不太可能是先验已知的,因为即使指导受试者阅读特定的文本,受试者也可能犯错误(例如读错字、跳过字或重复字)。因此,hmm状态被组织以便不仅允许从一个字到下一个字的转换,而且允许插入或删除字或apu。如果文本不是先验已知的,则所有apu的状态被组织以便允许从任何apu到任何其它apu的转换,其中任何两个apu的转换概率反映了在受试者说出的语言中第二个apu以其跟随第一个apu的频率。
143.(如上所述,apu可以包括例如音素、双音素、三音素或合成声学单元。每个合成声学单元由单个hmm状态表示)。
144.hmm技术进一步假设状态序列是马尔可夫序列,使得状态序列的先验概率由π[s1]*a[s1,s2]*a[s2,s3]*
…
*a[s
n
‑1,s
n
]给出,其中π[s1]是初始状态是s1的概率,并且a[s
i
,s
j
]是s
j
跟随s
i
的转换概率。因此,特征向量序列和状态序列的联合概率等于π[s1]*a[s1,s2]*a[s2,s3]*
…
*a[s
n
‑1,s
n
]*f
s1
(v1)*f
s2
(v2)*
…
*f
sn
(v
n
)。hmm技术找到状态序列{s1,s2,
…
s
n
},对于任何给定的特征向量序列{v1,v2,
…
v
n
},该状态序列最大化该联合概率。(这可以例如使用维特比(viterbi)算法来完成,该算法在rabiner和juang的“fundamentals of speech recognition”(prentice hall,1993)中进行了描述,其公开内容通过引用并入本文)。由于每个状态对应于特定的apu,所以hmm技术给出了针对话语的apu序列{y1,y2,
…
y
r
}。
[0145]
概率密度函数f
s
(v)的参数以及初始概率和转换概率是通过在大型语音数据库上进行训练来学习的。典型地,建立这样的数据库需要从多个受试者收集语音样本,使得hmm模型不是特定于受试者的。然而,基于在校准过程期间记录的受试者的语音,通用hmm模型可以适用于特定的受试者。如果将用于肺容量估计的语音内容是预先知道的,并且在校准过程期间从受试者获得了该语音的样本话语,则这样的适应可能特别有帮助。
[0146]
本领域中的技术人员将认识到,本发明不被限制于上文所具体示出和描述的内容。相反,本发明的实施例的范围包括上文所描述的各种特征的组合和子组合以及本领域技术人员在阅读以上描述之后将想到的未在现有技术中的其变型和修改。通过引用并入本专利申请中的文件被认为是本申请的组成部分,除了到任何术语在这些并入的文件中以与在本说明书中明确地或隐含地做出的定义相冲突的方式被定义的程度外,只应考虑在本说明书中的定义。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1