BCG信号的AHI指数检测方法与流程
本发明涉及ahi指数检测技术领域,尤其是涉及一种操作方便,费用低廉,对病人干扰小,准确率高的bcg信号的ahi指数检测方法。
背景技术:
睡眠呼吸暂停低通气指数,即ahi,它是英文apnea-hypopneaindex的缩写,或称为呼吸紊乱指数(respiratorydisturbance,rdi),就是呼吸暂停,低通气指数,是衡量睡眠呼吸健康方面的一个重要标准。
监测ahi指数的现有技术为:通过传统的睡眠监测方法是多导睡眠监测(psg),其工作原理为:通过连接在患者身上的电极、导线采集整个睡眠过程中口鼻气流、脑电、眼电、胸腹式呼吸运动、血氧饱和度等睡眠呼吸参数,从而对睡眠呼吸暂停疾病作出诊断。这种方法测试结果准确,适用于所有睡眠障碍性疾病的诊断。但需要患者在医院进行监测,需要改变睡眠环境,还需要在患者身上连接较多导线,测试过程不够舒适,且程序繁琐。
bcg信号即心冲击图信号,原理是心脏的收缩会将压力传导到压电薄膜(pvdf)传感器上,传感器将压力信号转换为电信号,这就是所谓的心冲击图信号。
技术实现要素:
本发明的发明目的是为了克服现有技术中的ahi指数监测过程中,需要患者在医院进行监测,需要改变睡眠环境,测试过程不够舒适,程序繁琐的不足,提供了一种操作方便,费用低廉,对病人干扰小,准确率高的bcg信号的ahi指数检测方法。
为了实现上述目的,本发明采用以下技术方案:
一种bcg信号的ahi指数检测方法,包括如下步骤:
(1-1)准备训练集和测试集;
(1-2)数据滤出呼吸波;
对si进行滤波处理,用二阶butterworth滤波器0.08hz~0.5hz带通滤波,过滤出呼吸波信号si_filter;
(1-3)特征提取;
(1-4)训练和验证模型;
(1-5)计算bcg信号的ahi指数。
bcg信号是基于pvdf(压电薄膜)传感器的信号采集系统,可以采集到心脏收缩过程中的心冲击图信号(原理是心脏的收缩会将压力传导到压电薄膜传感器上,传感器将压力信号转换为电信号,就是所谓的心冲击图信号),将这种信号叫做bcg信号。
基于压电薄膜传感器的bcg信号采集设备,只需放置于人的胸部附近位置即可收集到bcg信号,适用场景如晚上睡觉时候,人平躺于床上,传感器放置于床单下胸部附近位置即可。
本发明将bcg信号数据按照5秒一段进行数据分段,对分段的数据提取多个特征利用训练好的机器学习模型进行分类,分类划分数据段是0则包含了呼吸暂停事件;1是未包含互相暂停事件。然后对连续的0进行合并,统计平均一个小时内出现0的次数即为ahi指数。
本发明的主要内容是基于心冲击图(bcg)信号结合机器学习的检测ahi指数的方法。与传统检测方法相比较,有很高的相关性,本发明的呼吸事件检出率与典型的psg相比,相关系数≥0.98。
本发明具有操作方便,费用低廉,对病人干扰小,准确率高的特点。
作为优选,步骤(1-1)包括如下步骤:
收集同一时间段内的ahi病人的bcg信号数据和psg信号数据,根据psg设备导出的发生呼吸暂停的时间段a1,将与时间段a1对应的时间段内的bcg数据导出,按照5秒一段进行划分,将上述数据段标记为0,即包含了呼吸暂停事件;
收集非ahi病人的bcg信号数据,按照5秒一段进行划分,将上述数据段标记为1,即未包含呼吸暂停事件;
从标记为0的数据段和标记为1的数据段里,选择80%的数据段作为训练集,将剩下的20%数据段作为测试集。
作为优选,数据的分段方法如下:
bcg信号数据x={x1,x2,x3,...,xn}是时间序列信号,n为数据总数,bcg信号数据的采样频率fs为125hz;
将n个bcg数据分成k段,k=n/625,n是625倍数;
将第i段数据记为si,i∈[1,2,3,…,k];
si={x625i-624,x625i-623,...,x625i};
将yi称为对应si的标记,yi为0,则表示包含呼吸暂停事件;yi为1,则表示未包含呼吸暂停事件。
作为优选,(1-3)包括如下步骤:
设定mean()是计算均值的函数,std()是计算标准差的函数,diff()是计算前后差值的函数,max()是计算最大值的函数,min()是计算最小值的函数,sum()是计算和的函数,cumsum()是计算某维度累积和的函数,length()是计算长度的函数,median()是计算中位数的函数,abs()是计算绝对值的函数,prctile()是计算百分位数的函数,log()是计算对数的函数,envelope()是计算包络谱的函数,findpeaks()是计算波峰波谷的函数,xcorr()是计算相关性的函数,fft()是快速傅里叶变换的函数,ar()是计算ar模型(自回归模型)的函数;
对每一段滤波后的数据段si_filter进行归一化得到segi_filter:
对si进行归一化得到segi:
利用如下公式获取segi_filter的上界upi和下界downi:
[upi,downi]=envelope(segi_filter,2fs);
upi代表上界,downi代表下界,upi和downi都是数组序列,y,z都是整型数据值;
upi={y625i-624,y625i-623,...,y625i},
downi={z625i-624,z625i-623,...,z625i};
对upi和downi之差s_updowni进行一次归一化,得到s_updown_standardi:
s_updowni=upi-downi
使用findpeaks查找波峰:
[pks,pkslocs]=findpeaks(s_updown_standardi,fs)
pks和pkslocs分别是波峰和波峰位置,pks和pkslocs都是数组序列,表达形式如下:
pks={bf1,bf2,...,bfm}
pkslocs={bf_loc1,bf_loc2,...,bf_locm}
m代表找到的波峰的数量,设j=1,2,3,...,m;bfj代表在序列s_updown_standardi找到的第j个波峰的顶点数值(是整型数值),bf_locj代表找到的第j个波峰的顶点在序列s_updown_standardi的索引值(是整型数值);
使用findpeaks查找波谷:
[vls,vlslocs]=findpeaks(-s_updown_standardi,fs)
vls和vlslocs分别是波谷和波谷位置,vls和vlslocs都是数组序列,表达形式如下:
vls={bg1,bg2,...,bgl}
vlslocs={bg_loc1,bg_loc2,…,bg_locl}
l代表找到的波谷的数量,设h=1,2,3,...,l;bgh代表在序列s_updown_standardi找到的第h个波谷的顶点数值(是整型数值),bg_loch代表找到的第h个波谷的顶点在序列s_updown_standardi的索引值(是整型数值);
提取28个特征,28个特征分别为上下界差值均值特征renvdiffmean(i),上下界差值标准差特征renvdiffstd(i),upi和downi的相关性比例特征renvcorr(i),波峰数量频比特征rratep(i),
波谷数量频比特征rratev(i),波峰均值百分比特征rsdmedianp(i),波谷均值百分比特征rsdmedianv(i),呼吸波峰数量特征rnumpks(i),呼吸波谷数量特征rnumvls(i),波峰差异累计和特征rpkscummax(i),波谷差异累计和特征rvlscummax(i),ar模型下的10个特征,bcg信号能量值特征tpower(i),过零率特征tzcr(i),数据段segi频谱高能量均值特征fhighmeannorm(i),数据段segi频谱能量波峰特征fbrpeaknorm(i),数据段si频谱能量波峰特征fhighmean(i),数据段si频谱中短能量比例特征fmhf(i),数据段si频谱中长能量比例特征fvhf1(i)。
作为优选,针对si,提取28个特征,将每一段数据的28个特征的值,输入到支持向量机训练调试模型svm_model中,每一段数据经过svm_model计算得到对应的类别yi,当yi为0时,表示包含呼吸暂停事件;当yi为1时,表示未包含呼吸暂停事件;设置kernel核是线性模型即“linear”,惩罚系数c是0.5,使用一对多模式“ovr”,训练完的模型能够达到在测试集上的正确率到95%;
针对si,提取28个特征,将每一段数据的28个特征的值,输入到随机森林训练调试模型forest_model中,每一段数据经过forest_model计算得到对应的类别yi,当yi为0时,表示包含呼吸暂停事件;当yi为1时,表示未包含呼吸暂停事件;树的数量是30,做有放回抽样,训练完的模型能够达到在测试集上的正确率到96%。
作为优选,对bcg信号数据按照5秒一段进行分段,然后对每一段数据计算28个特征,输入到训练好的模型中,得到输出0或者1,0代表这段数据包含了呼吸暂停事件,1表示未包含呼吸暂停事件,计算完所有的数据段以后,将所有的连续的0合并成一个0,计算0出现的次数zero_num,用次数zero_num除以bcg数据总小时数hours即得到了ahi指数,ahi指数=zero_num/hours。
作为优选,renvdiffmean(i)=mean(s_updowni),
renvdiffstd(i)=std(s_updowni),
计算upi和downi的相关性ce(i),
ce(i)=xcorr(upi,downi,2fs),
则
其中,
rsdmedianp(i)=
median(pks)/abs((prctile(pks,75)-prctile(pks,25))),
rsdmedianv(i)=
median(vls)/abs((prctile(vls,75)-prctile(vls,25))),
rnumpks(i)=length(pks),
rnumvls(i)=length(vls),
rpkscummax(i)=max(cumsum(diff(pks))),
rvlscummax(i)=max(cumsum(-diff(vls)));
使用ar模型处理bcg信号:
armodel=ar(segi),
得到ar模型的10个特征如下所示:
arcoef1(i)=armodel.a(2)
arcoef2(i)=armodel.a(3)
arcoef3(i)=armodel.a(4)
arcoef4(i)=armodel.a(5)
arcoef6(i)=armodel.a(7)
arcoef8(i)=armodel.a(9)
arcoef9(i)=armodel.a(10)
arcoef10(i)=armodel.a(11)
arcoef13(i)=armodel.a(14)
arcoef14(i)=armodel.a(15)。
其中,armodel是数据段segi的ar模型(自回归模型),armodel.a(2)代表模型的自回归系数第2个参数;以此类推,armodel.a(3)代表模型的自回归系数第3个参数,armodel.a(4)代表模型的自回归系数4个参数。
作为优选,
其中,
tzcr(i)为在si里从头到尾遍历元素,当前一个元素和相邻的后一个元素正负符号不同,则tzcr(i)累积计算+1的和;
计算数据段segi频谱能量freqpownorm(i),
freqpownorm(i)=abs(fft(segi)),
fhighmeannorm(i)=mean(freqpownorm(i)(91∶300)),
其中,freqpownorm(i)是一个数组序列,freqpownorm(i)(91∶300)表示freqpownorm(i)的第91个元素到第300个元素组成的序列;
fbrpeaknorm(i)=max(freqpownorm(i)(1∶15)),
其中,freqpownorm(i)是一个数组序列,freqpownorm(i)(1∶15)表示freqpownorm(i)的第1个元素到第15个元素组成的序列;
计算si频谱能量freqpow(i):
freqpow(i)=abs(fft(si))
fhighmean(i)=mean(freqpow(i)(91∶300)),
其中,freqpow(i)是一个数组序列,freqpow(i)(91∶300)表示freqpow(i)的第91个元素到第300个元素组成的序列。
作为优选,
fmhf(i)=sum(freqpow(i)(10∶20))/(sum(freqpow(i)(1∶9))+sum(freqpow(i)(21∶300))),
其中,freqpow(i)是一个数组序列,freqpow(i)(1∶9)表示freqpow(i)的第1个元素到第9个元素组成的序列;freqpow(i)(10∶20)表示freqpow(i)的第10个元素到第20个元素组成的序列;freqpow(i)(21∶300)表示freqpow(i)的第21个元素到第300个元素组成的序列;
fvhf1(i)=sum(freqpow(i)(21∶45))/(sum(freqpow(i)(1∶20))+sum(freqpow(i)(46∶300)));
其中,freqpow(i)是一个数组序列,freqpow(i)(21∶45)表示freqpow(i)的第21个元素到第45个元素组成的序列;freqpow(i)(1∶20)表示freqpow(i)的第1个元素到第20个元素组成的序列;freqpow(i)(46∶300)表示freqpow(i)的第46个元素到第300个元素组成的序列。
因此,本发明具有如下有益效果:呼吸事件检出率与典型的psg相比,相关系数≥0.98;操作方便,费用低廉,对病人干扰小,准确率高。
附图说明
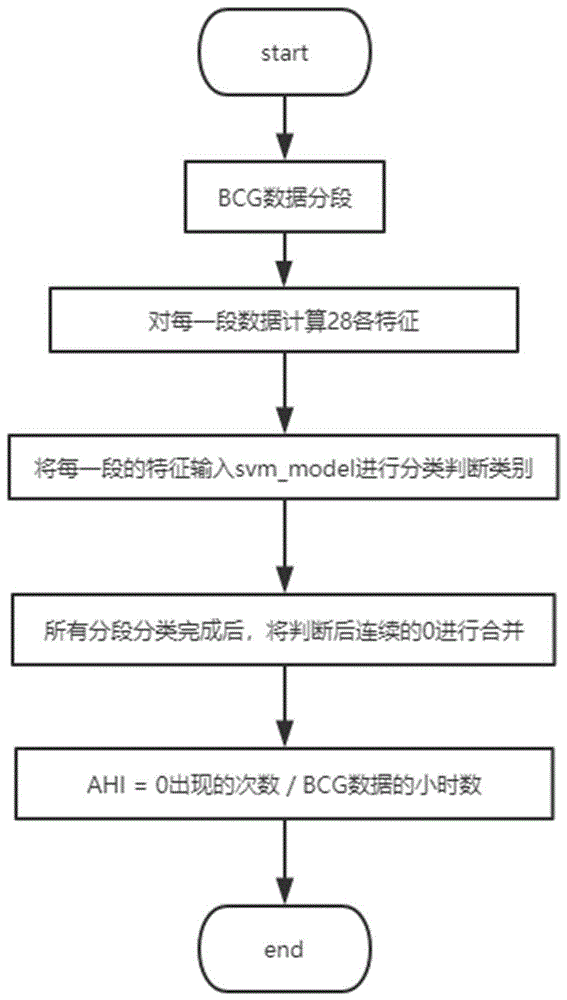
图1是本发明的一种流程图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步的描述。
如图1所示的实施例是一种bcg信号的ahi指数检测方法,包括如下步骤:
(1-1)准备训练集和测试集;
收集同一时间段内的ahi病人的bcg信号数据和psg信号数据,根据psg设备导出的发生呼吸暂停的时间段a1,将与时间段a1对应的时间段内的bcg数据导出,按照5秒一段进行划分,将上述数据段标记为0,即包含了呼吸暂停事件;
收集非ahi病人的bcg信号数据,按照5秒一段进行划分,将上述数据段标记为1,即未包含呼吸暂停事件;
从标记为0的数据段和标记为1的数据段里,选择80%的数据段作为训练集,将剩下的20%数据段作为测试集;
数据的分段方法如下:
bcg信号数据x={x1,x2,x3,...,xn}是时间序列信号,n为数据总数,bcg信号数据的采样频率fs为125hz;
将n个bcg数据分成k段,k=n/625,n是625倍数;
将第i段数据记为si,i∈[1,2,3,…,k];
si={x625i-624,x625i-623,...,x625i};
将yi称为对应si的标记,yi为0,则表示包含呼吸暂停事件;yi为1,则表示未包含呼吸暂停事件。
(1-2)数据滤出呼吸波;
对si进行滤波处理,用二阶butterworth滤波器0.08hz~0.5hz带通滤波,过滤出呼吸波信号si_filter;
(1-3)特征提取;
设定mean()是计算均值的函数,std()是计算标准差的函数,diff()是计算前后差值的函数,max()是计算最大值的函数,min()是计算最小值的函数,sum()是计算和的函数,cumsum()是计算某维度累积和的函数,length()是计算长度的函数,median()是计算中位数的函数,abs()是计算绝对值的函数,prctile()是计算百分位数的函数,log()是计算对数的函数,envelope()是计算包络谱的函数,findpeaks()是计算波峰波谷的函数,xcorr()是计算相关性的函数,fft()是快速傅里叶变换的函数,ar()是计算ar模型(自回归模型)的函数;
对每一段滤波后的数据段si_filter进行归一化得到segi_filter:
对si进行归一化得到segi:
利用如下公式获取segi_filter的上界upi和下界downi:
[upi,downi]=envelope(segi_filter,2fs);
upi代表上界,downi代表下界,upi和downi都是数组序列,y,z都是整型数据值;
upi={y625i-624,y625i-623,...,y625i},
downi={z625i-624,z625i-623,...,z625i};
对upi和downi之差s_updowni进行一次归一化,得到s_updown_standardi:
s_updowni=upi--downi
使用findpeaks查找波峰:
[pks,pkslocs]=findpeaks(s_updown_standardi,fs)
pks和pkslocs分别是波峰和波峰位置,pks和pkslocs都是数组序列,表达形式如下:
pks={bf1,bf2,...,bfm}
pkslocs={bf_loc1,bf_loc2,...,bf_locm}
m代表找到的波峰的数量,设j=1,2,3,...,m;bfj代表在序列s_updown_standardi找到的第j个波峰的顶点数值(是整型数值),bf_locj代表找到的第j个波峰的顶点在序列s_updown_standardi的索引值(是整型数值);
使用findpeaks查找波谷:
[vls,vlslocs]=findpeaks(-s_updown_standardi,fs)
vls和vlslocs分别是波谷和波谷位置,vls和vlslocs都是数组序列,表达形式如下:
vls={bg1,bg2,...,bgl}
vlslocs={bg-loc1,bg_loc2,…,bg_locl}
l代表找到的波谷的数量,设h=1,2,3,...,l;bgh代表在序列s_updown_standardi找到的第h个波谷的顶点数值(是整型数值),bg_loch代表找到的第h个波谷的顶点在序列s_updown_standardi的索引值(是整型数值);
提取28个特征,28个特征分别为上下界差值均值特征renvdiffmean(i),上下界差值标准差特征renvdiffstd(i),upi和downi的相关性比例特征renvcorr(i),波峰数量频比特征rratep(i),
波谷数量频比特征rratev(i),波峰均值百分比特征rsdmedianp(i),波谷均值百分比特征rsdmedianv(i),呼吸波峰数量特征rnumpks(i),呼吸波谷数量特征rnumvls(i),波峰差异累计和特征rpkscummax(i),波谷差异累计和特征rvlscummax(i),ar模型下的10个特征,bcg信号能量值特征tpower(i),过零率特征tzcr(i),数据段segi频谱高能量均值特征fhighmeannorm(i),数据段segi频谱能量波峰特征fbrpeaknorm(i),数据段si频谱能量波峰特征fhighmean(i),数据段si频谱中短能量比例特征fmhf(i),数据段si频谱中长能量比例特征fvhf1(i)。
renvdiffmean(i)=mean(s_updowni),
renvdiffstd(i)=std(s_updowni),
计算upi和downi的相关性ce(i),
ce(i)=xcorr(upi,downi,2fs),
则
其中,
rsdmedianp(i)=
median(pks)/abs((prctile(pks,75)-prctile(pks,25))),
rsdmedianv(i)=
median(vls)/abs((prctile(vls,75)-prctile(vls,25))),
rnumpks(i)=length(pks),
rnumvls(i)=length(vls),
rpkscummax(i)=max(cumsum(diff(pks))),
rvlscummax(i)=max(cumsum(-diff(vls)));
使用ar模型处理bcg信号:
armodel=ar(segi),
得到ar模型的10个特征如下所示:
arcoef1(i)=armodel.a(2)
arcoef2(i)=armodel.a(3)
arcoef3(i)=armodel.a(4)
arcoef4(i)=armodel.a(5)
arcoef6(i)=armodel.a(7)
arcoef8(i)=armodel.a(9)
arcoef9(i)=armodel.a(10)
arcoef10(i)=armodel.a(11)
arcoef13(i)=armodel.a(14)
arcoef14(i)=armodel.a(15)。
其中,armodel是数据段segi的ar模型(自回归模型),armodel.a(2)代表模型的自回归系数第2个参数;以此类推,armodel.a(3)代表模型的自回归系数第3个参数,armodel.a(4)代表模型的自回归系数4个参数。
上面公式中,
tzcr(i)为在si里从头到尾遍历元素,当前一个元素和相邻的后一个元素正负符号不同,则tzcr(i)累积计算+1的和;
计算数据段segi频谱能量freqpownorm(i),
freqpownorm(i)=abs(fft(segi)),
fhighmeannorm(i)=mean(freqpownorm(i)(91∶300)),
其中,freqpownorm(i)是一个数组序列,freqpownorm(i)(91∶300)表示freqpownorm(i)的第91个元素到第300个元素组成的序列;
fbrpeaknorm(i)=max(freqpownorm(i)(1∶15)),
其中,freqpownorm(i)是一个数组序列,freqpownorm(i)(1∶15)表示freqpownorm(i)的第1个元素到第15个元素组成的序列;
计算si频谱能量freqpow(i):
freqpow(i)=abs(fft(si))
fhighmean(i)=mean(freqpow(i)(91∶300)),
其中,freqpow(i)是一个数组序列,freqpow(i)(91∶300)表示freqpow(i)的第91个元素到第300个元素组成的序列。
fmhf(i)=sum(freqpow(i)(10∶20))/(sum(freqpow(i)(1∶9))+sum(freqpow(i)(21∶300))),
其中,freqpow(i)是一个数组序列,freqpow(i)(1∶9)表示freqpow(i)的第1个元素到第9个元素组成的序列;freqpow(i)(10∶20)表示freqpow(i)的第10个元素到第20个元素组成的序列;freqpow(i)(21∶300)表示freqpow(i)的第21个元素到第300个元素组成的序列;
fvhf1(i)=sum(freqpow(i)(21:45))/(sum(freqpow(i)(1∶20))+sum(freqpow(i)(46∶300)));
其中,freqpow(i)是一个数组序列,freqpow(i)(21∶45)表示freqpow(i)的第21个元素到第45个元素组成的序列;freqpow(i)(1∶20)表示freqpow(i)的第1个元素到第20个元素组成的序列;freqpow(i)(46∶300)表示freqpow(i)的第46个元素到第300个元素组成的序列。
(1-4)训练和验证模型;
针对si,提取28个特征,将每一段数据的28个特征的值,输入到支持向量机训练调试模型svm_model中,每一段数据经过svm_model计算得到对应的类别yi,当yi为0时,表示包含呼吸暂停事件;当yi为1时,表示未包含呼吸暂停事件;设置kernel核是线性模型即“linear”,惩罚系数c是0.5,使用一对多模式“ovr”,训练完的模型能够达到在测试集上的正确率到95%。
(1-5)计算bcg信号的ahi指数。
对bcg信号数据按照5秒一段进行分段,然后对每一段数据计算28个特征,输入到训练好的支持向量机训练调试模型svm_model中,得到输出0或者1,0代表这段数据包含了呼吸暂停事件,1表示未包含呼吸暂停事件,计算完所有的数据段以后,将所有的连续的0合并成一个0,计算0出现的次数zero_num,用次数zero_num除以bcg数据总小时数hours即得到了ahi指数,ahi指数=zero_num/hours。
应理解,本实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!