一种医疗影像辨识的方法与系统与流程
本发明涉及医疗影像辨识技术领域,尤其是涉及医疗影像辨识的预训练模型的方法与系统。
背景技术:
近年来,由于imagenet提供了数百万张以上的图片数据库,例如:猫、狗、飞机、自行车等不同种类的对象图片,使人工智能的图片辨识技术得以建立以大数据数据驱动的深度学习类神经网络技术,并使目前人工智能的深度学习技术在应用于自然界的大部份对象的辨识时,能具有与人类能力相近的辨识率。
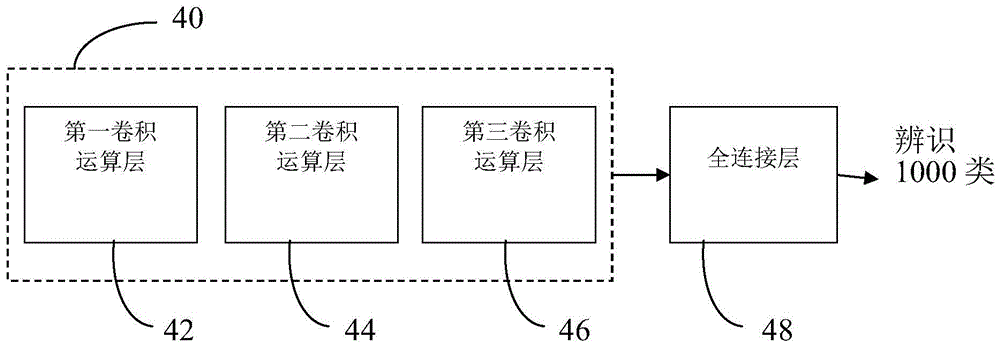
利用imagenet所建立的类神经网络进行预训练模型(pre-trainmodel)日益成熟,如图1所示,现有的预训练模型系利用如imagenet所提供的大量影像数据库经由第一卷积运算层(convolutionlayer)42、第二卷积运算层44与第三卷积运算层46的卷积神经网络(convolutionneuralnetwork,cnn)进行运算分析后所建立的模型做为骨干(basestructure)40,将其接近最终辨识输出结果的最后数层更改为适合的应用方面的全连接层(fullconnectionlayer)48,可应用于相关对象影像辨识技术领域的影像分类、预测数值(回归)、目标检测、分割等应用。
然而,由于个人医疗信息的保密性,imagenet这类的公开数据库缺乏大量的医疗影像可供医疗影像辨识技术使用,并且由于单一病例的影像数量有限,难以提高医疗影像预训练模型的准确率。因此,建立以医疗影像为主的预训练模型,以进一步提升医疗影像的影像分类、目标检测、分割等应用的准确率,就成为目前人工智能技术领域的重要目标。
技术实现要素:
本发明提供一种医疗影像辨识的方法与系统,所述医疗影像辨识的方法与系统利用不同疾病标记的影像数据进行运算分析建立预训练模型。
本发明提供的技术方案如下:
本发明的第一实施例提供一种医疗影像辨识的方法,所述医疗影像辨识的方法包括:
步骤一:输入具有复数类疾病标记的复数个影像数据,每个所述影像数据至少具有一种疾病标记;
步骤二:建立一个第一预训练模型,并将具有复数类疾病标记的复数个所述影像数据以混合方式同时对所述第一预训练模型进行训练;
步骤三:将具有第一疾病标记的所述影像数据输入至所述第一预训练模型;
步骤四:以所述第一预训练模型为骨干,建立一个第二预训练模型;
步骤五:使用具有第一疾病标记的所述影像数据对所述第二预训练模型进行训练与验证。
本发明的第一实施例中,所述步骤四进一步包括步骤:冻结所述第一预训练模型至少一个卷积运算层的参数。
本发明的第一实施例中,所述步骤一的所述复数类疾病标记至少包括三类疾病标记。
本发明的第一实施例中,所述复数个影像数据为相同格式的影像数据。
本发明的第一实施例中,所述影像数据的格式为x光(x-ray)、计算机断层扫描(computedtomography,ct)、核磁共振造影(magneticresonanceimaging,mri)、超声波、病理切片摄影或眼底摄影的其中一种。
本发明的第二实施例提供一种医疗影像辨识的系统,所述医疗影像辨识的系统包括:
一个骨干,所述骨干包括第一卷积运算层、第二卷积运算层与第三卷积运算层,所述第一卷积运算层、所述第二卷积运算层与所述第三卷积运算层用以至少对具有第一疾病标记的影像数据与具有第二疾病标记的影像数据进行运算分析后建立一个预训练模型;
一个第四卷积运算层或全连接层用以对所述骨干所建立的所述预训练模型所输出的数据数据训练其辨识有无第一疾病特征;
一个第五卷积运算层或全连接层用以对所述骨干所建立的所述预训练模型所输出的数据数据训练其辨识有无第二疾病特征。
本发明的第二实施例中,所述医疗影像辨识的系统另包括一个第六卷积运算层或全连接层,所述第六卷积运算层或全连接层用以在所述预训练模型经过所述第一疾病标记的影像数据与所述第二疾病标记的影像数据的预训练后,对一个具有第三疾病标记的影像数据进行辨识。
本发明的第二实施例中,所述医疗影像辨识的系统在进行辨识具有所述第三疾病标记的影像数据时,冻结所述骨干中至少一个卷积运算层的参数。
本发明的第二实施例中,所述第一疾病标记、所述第二疾病标记与所述第三疾病标记的影像数据为相同格式的影像数据。
本发明的第二实施例中,所述影像数据的格式为x光、计算机断层扫描、核磁共振造影、超声波、病理切片摄影或眼底摄影的其中一种。
本发明实施例带来的有益效果为:本发明实施例可适用在医疗影像辨识技术的领域,包括x-ray、ct、mri、超音波、病理切片摄影或眼底摄影等的影像辨识技术领域,本发明实施例也可以应用于医疗影像的分类、预测数值(回归)、目标检测、分割等需求。本发明实施例利用不同疾病标记的影像数据进行运算分析建立预训练模型,在医疗影像辨识技术领域常见的有效数据数量不足的情况下对于提升影像辨识准确率有明显帮助。
附图说明
为了更清楚地说明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单介绍,以下描述中的附图仅仅是发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为现有技术的影像辨识技术的示意图。
图2为本发明的第一实施例提供的医疗影像辨识的系统示意图。
图3为本发明的第二实施例提供的医疗影像辨识的系统示意图。
图4为本发明的第二实施例的实验准确率分析图。
图5为本发明的第三实施例提供的方法流程图。
图6为本发明的第四实施例提供的方法流程图。
图7为本发明的第四实施例提供的实验准确率分析图。
具体实施方式
在具体实施方式中提及“实施例”意指结合实施例描述的特定特征、结构或特性可以包含在本发明的至少一个实施例中。在说明书中的不同位置出现的相同用语并非必然被限制为相同的实施方式,而应当理解为与其它实施例互为独立的或备选的实施方式。在本发明提供的实施例所公开的技术方案启示下,本领域的普通技术人员应理解本发明所描述的实施例可具有其他符合本发明构思的技术方案结合或变化。
以下各实施例的说明是参考附加的图式,用以例示本发明可用以实施的特定实施例。本发明所提到的方向用语,例如[上]、[下]、[前]、[后]、[左]、[右]、[内]、[外]、[侧面]、[竖直]、[水平]等,仅是参考附加图式的方向。因此,使用的方向用语是用以说明及理解本发明,而非用以限制本发明。
在发展医疗影像的人工智能辨识技术时,最常遇到的问题通常是在需要判断某种疾病病征的情况时,该疾病的可供参考的有效数据数量与其他自然界领域的有效数据数量相比非常少,在大数量数据驱动的模型下,有效数据数量是模型准确度重要的因素之一。而在医疗影像的人工智能辨识技术中,也常用imagenet这类通用的影像数据库当作预训练模型的骨干(basestructure),但医疗影像并不是通常可见的自然界的影像数据,其与通常可见的自然界的影像数据存在较大的差异。使用不同疾病所建立的多任务(multi-task)的预训练模型的辨识准确度会比仅使用imagenet这类通用的影像数据库当作预训练模型来的更高。因此本发明系利用大量不同疾病但都是在相同的某种情境下(例如:x-ray、ct、mri、超音波、病理切片摄影或眼底摄影等)的影像,以多任务(multi-task)的方式建立一个预训练模型,再将此预训练模型当作骨干应用于某种疾病下。根据本发明所揭示的具体实施例,请参阅图2所示的第一实施例的医疗影像辨识的系统,以北美放射科协会(radiologicalsocietyofnorthamerica,rsna)与美国史丹佛大学(lelandstanfordjunioruniversityinunitedstates,以下简称“史丹佛大学”)所提供的数万张医疗影像数据库为例,rsna提供约3万余张胸腔x-ray的影像,其中皆有标示(label)正常或肺炎之标记,史丹佛大学提供名为mura(musculoskeletalradiographs)的1万余张的骨科x-ray影像数据库,其中皆有标示正常或不正常之标记。我们将这两个完全不同疾病和不同部位的x-ray的医疗影像数据,建立一个多任务(multi-task)的训练模型。第一实施例中的骨干10系利用经由第一卷积运算层(convolutionlayer)102、第二卷积运算层104与第三卷积运算层106的卷积神经网络(convolutionneuralnetwork,cnn)对rsna提供的3万余张胸腔x-ray影像与史丹佛大学的mura提供的1万余张的骨科x-ray影像进行运算分析后所建立的模型,通过骨干10运算分析后所输出的数据数据分别通过第四卷积运算层或全连接层(fullconnectionlayer)108与第五卷积运算层或全连接层110以分别训练其辨识有无肺炎特征或骨骼异常特征的结果。本实施例中的卷积运算层数量可视实际应用需求进行调整。本实施例的实际应用时亦可视不同需求加入其他运算层,例如:非线性层(rectifiedlinearlayer)、降采样层(poolinglayer)等。本发明可适用的影像辨识领域并不仅限于本实施例中所例示的肺炎或骨骼影像辨识领域。
在上述预训练完成后,再将此预训练模型的骨干10部分应用于rsna提供的骨龄预测的影像数据库,建立可辨识骨龄的模型。请参阅图3所示的第二实施例的医疗影像辨识的系统,骨干10对rsna提供的骨龄预测的影像数据库经由第一卷积运算层102、第二卷积运算层104与第三卷积运算层106进行运算分析后,所输出的数据数据通过第六卷积运算层或全连接层202以进行辨识骨龄的结果。本实施例中的卷积运算层数量可视实际应用需求进行调整。本实施例的实际应用时亦可视不同需求加入其他运算层,例如:非线性层(rectifiedlinearlayer)、降采样层(poolinglayer)等。本发明可适用的影像辨识领域并不仅限于本实施例中所例示的骨龄影像辨识领域。
请参阅图4,经过实验证实,在不同数量级的数据下,使用本发明的预训练模型所得到的影像辨识准确率比使用imagenet所建立的模型更高,尤其在数据比较少的情况下,改善的幅度更为明显,在医疗影像辨识技术领域常见的有效数据数量不足的情况下对于提升影像辨识准确率有明显帮助。
请参阅图5所示的第三实施例,第三实施例为建立医学影像的预训练模型的方法流程,其包括以下步骤:
步骤302:输入具有d0疾病标记的影像数据;
步骤304:输入具有d1疾病标记的影像数据;
步骤306:输入具有d2疾病标记的影像数据;
步骤308:建立multi-task的模型m0,并将d0、d1、d2等疾病标记的影像数据以混合方式同时对模型m0进行训练;
步骤310:将具有d3疾病标记的影像数据输入至模型m0;
步骤312:以模型m0为骨干,建立新的模型m1,使用具有d3疾病标记的影像数据对模型m1进行训练与验证;
步骤314:得到d3疾病特征判读的模型m1。
上述第三实施例中的预训练模型的训练过程中,在步骤302、步骤304、步骤306所使用的不同疾病标记的种类总数至少为2类以上,每个影像数据至少具有一种疾病标记,可以根据实际应用的需求进行增加。
由于在相同的影像辨识应用情境下,预训练模型在最前面几层的特征是类似的,因此训练时可以冻结前面几层的参数,以提高影像辨识的准确率。请参阅图6所示的第四实施例,第四实施例为建立医学影像的预训练模型的方法流程,其中冻结至少骨干中一个卷积运算层的参数,第四实施例的方法流程包括以下步骤:
步骤402:输入具有d0疾病标记的影像数据;
步骤404:输入具有d1疾病标记的影像数据;
步骤406:输入具有d2疾病标记的影像数据;
步骤408:建立multi-task的模型m0,并将d0、d1、d2等疾病标记的影像数据以混合方式同时对模型m0进行训练;
步骤410:将具有d3疾病标记的影像数据输入至模型m0;
步骤412:以模型m0为骨干,建立新的模型m1,冻结m0至少一个卷积运算层的参数,使用具有d3疾病标记的影像数据对模型m1进行训练与验证;
步骤414:得到d3疾病特征判读的模型m1。
上述第四实施例中的预训练模型的训练过程中,在步骤402、步骤404、步骤406所使用的不同疾病标记的种类总数至少为2类以上,每个影像数据至少具有一种疾病标记,可以根据实际应用的需求进行增加。
请参阅图7,经过实验证实,在相同的影像辨识应用情境下,进行不同数量级的实验分析,冻结前面几层的卷积运算层参数而只训练之后的卷积运算层,所得到的预训练模型可以增加预测的准确率,在数据比较少的情况下,改善的幅度更为明显。使用本发明的冻结前面几层的预训练模型所得到的影像辨识准确率也比使用imagenet所建立的模型更高,尤其在数据比较少的情况下,改善的幅度更为明显,在医疗影像辨识技术领域常见的有效数据数量不足的情况下对于提升影像辨识准确率有明显帮助。
上述实施例仅为例示本发明之实施方式,本发明可适用的领域不仅限于上述实施例所例示的特定医疗影像领域,本发明亦可使用其他疾病在相同的情境下(例如:x-ray、ct、mri、超音波、病理切片摄影或眼底摄影等)的影像辨识技术领域,本发明也可以应用于医疗影像的分类、预测数值(回归)、目标检测、分割等需求。
综上所述,虽然本发明已以优选实施例揭露如上,但上述优选实施例并非用以限制本发明,本领域的普通技术人员,在不脱离本发明的精神和范围内,所衍生的各种更动与变化,皆涵盖于本发明以权利要求界定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!