一种医疗流式数据血缘关系分析、存储方法及装置与流程
本发明涉及到一种医疗流式数据血缘关系分析、存储方法及装置。
背景技术:
早期,医疗数据以医院内部his(医院信息系统)、pacs(医学影像存档与通讯系统)、lis(实验室信息管理系统)三大系统的数据为核心,随着互联互通的深入,医院的应用系统越来越多,日产生的数据量成指数级上升,数据关系的复杂度也在不断上升,医疗数据采集面临着以下几类问题:医疗数据结构复杂,海量、散落在不同的信息系统、医疗数据分析方法不完善、缺乏统一的数据模型。同时,医疗监管部门对医院数据的监控、分析、决策的需求也在不断变化,业务标准也在不断的演进,对数据实时性、准确性要求越来越高,通过“定期etl抽取n+1天的结构化数据再加工存储的方式”已经满足不了医疗监管业务的需要。为了解决数据及时性的问题,流式数据(流数据,又可被称为实时数据)上报系统可以快速地统计上报数据,并计算监管指标。但是,针对流式数据的关联关系建模和流式数据的标准化(结构化)保存过程,存在非常大的处理难度。比如,数据标准的变化,数据建模过程是否能快速的调整;医院业务系统的流式数据到达存储系统,存在时间上的差异,需要一套完善的架构保障数据的一致性和完整性;医疗异构系统的流式数据之间的关联关系种类繁多,且存在较多不确定性,全部依靠人工分析几乎无法完成。流式数据是一套有顺序、快速、量大、连续到达的数据序列,通常情况下,流式数据是可以被视为随时间延续而无限递增的一个动态数据集合,医疗业务(包括门急诊、检查检验、住院、缴费等业务)的有序性和流式数据到达的无序性会导致想要流式数据与其他数据进行直接建立血缘关系变得非常复杂和困难。而在现有系统中,往往为了满足业务要求,经常会将多张表或临时表、中间表进行关联生成一张表,当业务表数据出现问题需要对数据进行追根溯源或者需要通过数据的血缘关系智能生成业务数据时,数据间的血缘关系就显得格外的重要。
因此,有必要针对上述问题,提供一种新的医疗流式数据的血缘关系分析和存储方法。
技术实现要素:
针对现有技术存在的问题,本发明提出了一种医疗流式数据血缘关系分析、存储方法及装置,能够正确分析出医疗流式数据之间的血缘关系,并基于血缘关系自动完成大批量医疗流式数据的结构化存储。
本发明所提供的技术方案为:
一方面,提供一种医疗流式数据血缘关系分析方法,包括以下步骤:
第一步、针对标准化处理后的医疗流式数据进行语义分析,解析其中的业务字段,将业务字段作为目标字段;
第二步、依据标准化处理后的医疗流式数据中包含的逻辑关系迭代拆分解析目标字段的血缘关系,包括与之对应的表依赖关系和字段依赖关系;
第三步、将拆解得到的表依赖关系和字段依赖关系存入血缘关系模型,并将血缘关系模型存储到血缘库。
另一方面,提供一种医疗流式数据存储方法,其特征在于,包括以下步骤:
步骤1、对采集到的医疗流式数据进行标准化处理;
步骤2、在血缘库中的血缘关系模型中通过比对检索(解析)医疗流式数据的血缘关系;根据医疗流式数据的血缘关系,将其标准处理化后的数据保存到标准库中;其中血缘关系模型是指根据上述医疗流式数据血缘关系分析方法获得的血缘关系模型。
进一步地,医疗流式数据的采集过程为:
sparkstreaming中的job程序启动时,首先会初始化获取血缘关系模型,通过spark广播机制将血缘关系模型分发至各采集医疗流式数据的服务器节点,通过广播机制有效防止了数据的冗余,提高了医疗流式数据的处理性能;
医疗流式数据的采集通过分布式、多线程应用程序设计并发作业,通过哈希取模算法hash(field)%n将每条医疗流式数据的采集任务分配至医疗业务系统中各个采集医疗流式数据的服务器节点,其中field表示每条医疗流式数据的主键值,n表示采集医疗流式数据的服务器节点数;每个采集医疗流式数据的服务器节点,对分配给其的医疗流式数据采集任务,根据血缘关系模型中相应医疗流式数据对应的血缘关系,完成相应医疗流式数据的独立采集;然后,各采集医疗流式数据的服务器节点把采集完成的医疗流式数据按照相应业务独立的业务逻辑进行封装,然后发送至消息中间件kafka集群中,最后由sparkstreaming从kafka集群中获取医疗流式数据。
进一步地,sparkstreaming每接获取一条医疗流式数据,就会对其进行标准化处理,然后依据血缘关系模型中该医疗流式数据对应的血缘关系,对该医疗流式数据进行血缘关系溯源,解析出该医疗流式数据整体的血缘关系;
sparkstreaming解析完医疗流式数据整体的血缘关系后,针对当前的医疗流式数据,基于其整体的血缘关系自动匹配属于其的家族数据,得到一条完整的数据脉,最后进行数据的持久化,即按以下两种情况递归判断血缘关系并进行结构化存储,以保证数据的一致性和完整性:
情况一、父表的数据到达,则将相应数据存入标准库,并触发通知子表进行存储动作,子表依次递归将相应数据从缓存库取出存储到标准库中;
情况二、子表的数据到达,依据血缘库血缘关系模型中的表依赖关系,在标准库查看是否存在相应的上一级父表数据,若不存在则将数据暂存至缓存库备查;若存在,则触发通知上一级父表查询是否存在更上一级父表数据,直至root节点,如果已通知至root节点查询,则触发情况一执行。
进一步地,当新的一批数据到来后,启动自学习过程,具体地:
对于标准库中的数据,根据医疗业务数据的自身特点,提取每个数据的特征,构建它们的特征向量,分别记为xi,i=1,2,…,n;
将标准库中的数据分为不同的类别(组别),在相同的类别中的数据对应的特征向量之间的距离应该都很近(即它们的相似度很高),相似度越高的数据其血缘关系匹配度越高。通过k-means聚类算法,将标准库中的数据分为k个类别,这k个类别的中心记为μj,j=1,2,…,k;设经过聚类之后特征向量为xi的数据所属的类别为ti,ti∈{1,2,…,k},k-means聚类算法即通过迭代找寻最佳的分类结果ti,i=1,2,…,n,使损失函数l值最小,损失函数l定义为:
将当前最佳的分类结果对应的l值记录在血缘库中;并计算当前最佳的分类结果对应的l值与血缘库上一次记录的l值的差值。若差值高于特定值,说明数据模型修改较大,血缘库中血缘关系模型的正确性不够高,则按照上述的医疗流式数据血缘关系分析方法更新血缘库中的血缘关系模型。
另一方面,提供一种医疗流式数据血缘关系分析装置,包括以下模块:
语义分析模块,用于针对标准化处理后的医疗流式数据进行语义分析,解析其中的业务字段,将业务字段作为目标字段;
血缘关系解析模块,用于依据标准化处理后的医疗流式数据中包含的逻辑关系迭代拆分解析目标字段的血缘关系,包括与之对应的表依赖关系和字段依赖关系,并将拆解得到的表依赖关系和字段依赖关系存入血缘关系模型。
另一方面,提供一种医疗流式数据存储装置,包括以下模块:
标准化处理模块,用于对采集到的医疗流式数据进行标准化处理;
数据存储模块,用于在血缘关系模型中通过比对检索(解析)医疗流式数据的血缘关系;根据医疗流式数据的血缘关系,将其标准处理化后的数据保存到标准库中;其中血缘关系模型是指根据上述的医疗流式数据血缘关系分析装置获得的血缘关系模型。
另一方面,提供一种电子设备,包括存储器及处理器,所述存储器中存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器实现上述的医疗流式数据血缘关系分析或存储方法。
另一方面,提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述的医疗流式数据血缘关系分析或存储方法。
有益效果:
本发明提出了一种医疗流式数据血缘关系分析方法,针对标准处理化后的医疗流式数据,进行语义分析,解析其中的业务字段作为目标字段;再迭代拆分解析目标字段的血缘关系,得到与之对应的表依赖关系和字段依赖关系;最后将拆解得到的表依赖关系和字段依赖关系存入血缘关系模型,并将血缘关系模型存储到血缘库。基于自学习过程,利用标准库存储的数据验证血缘库中血缘关系模型的正确性,并及时更新调整血缘关系模型,同时基于血缘关系自动完成大批量医疗流式数据的结构化存储。本发明具有良好的效果,适用于医疗监管系统应对业务标准变化和医疗数据类型增多的场景,能够快速、正确地分析出医疗流式数据之间的血缘关系,并基于血缘关系自动完成大批量医疗流式数据的结构化存储,极大降低了人工处理工作量,节省了时间,有效地提升了实施医疗流式数据的利用效率,增强了所保存到的异构系统采集的医疗流式数据的一致性和完整性。
附图说明
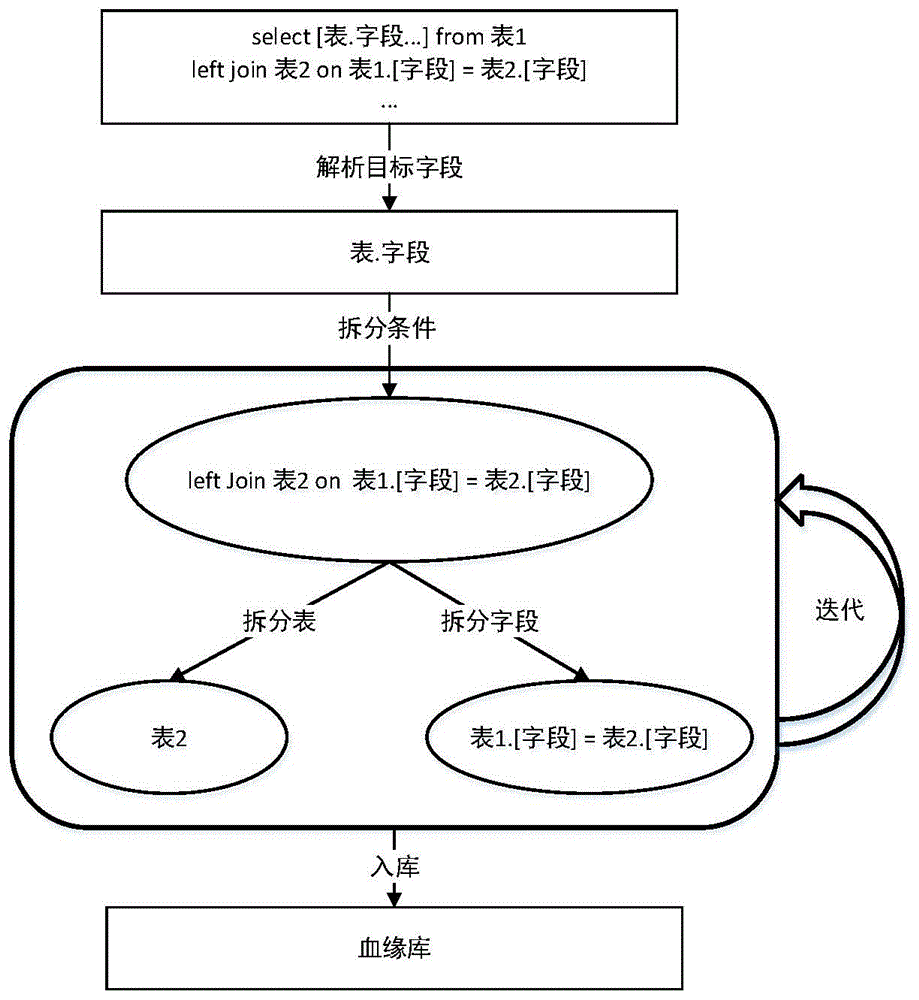
图1为本发明实施例中一种医疗流式数据血缘关系分析方法流程图;
图2为本发明实施例中血缘关系模型结构图;
图3为本发明实施例中不同的表依赖关系,其中,图3(a)为一父一子,图3(b)为一父两子,图3(c)为树形结构;
图4为本发明实施例中一种医疗流式数据存储方法流程图;
图5为本发明实施例中业务数据的持久化处理流程图。
具体实施方式
以下结合附图和具体实施例对本发明进行进一步具体说明。
实施例1:
本实施例提供一种医疗流式数据血缘关系分析方法,包括以下步骤:
第一步、针对标准化处理后的医疗流式数据,根据医疗业务系统的业务数据模型(业务数据结构)、行业规范、医院数据集成平台标准进行语义分析,解析其中的业务字段(即有业务意义的字段),例如门急诊业务中的患者诊疗卡号、就诊时间、挂号费用、诊断标准和诊断结果等;将业务字段作为目标字段;
第二步、依据标准化处理后的医疗流式数据中包含的逻辑关系(即医疗数据涉及的业务之间直接、间接或者潜在的逻辑关系)迭代拆分解析目标字段的血缘关系(依赖关系),包括与之对应的表依赖关系(表与表之间的依赖关系)和字段依赖关系(字段与字段之间的依赖关系);
第三步、将拆解得到的表依赖关系和字段依赖关系存入血缘关系模型,并将血缘关系模型存储到血缘库。
其中第一步中的医疗流式数据是指各医疗业务系统(指医院内部原有的涉及医疗数据的所有同构/异构的业务系统,包含但不限于his,lis,pacs等)的医疗流式数据。
图1为本发明分析医疗流式数据的血缘关系的流程图,图中,第一个方框表示将各医疗业务系统的数据进行标准化处理后的sql语句;第二个方框表示通过对sql语句进行语义分析后,得到目标字段来源于哪个表;第三个方框表示针对目标字段找到与之对应的表依赖关系和字段依赖关系;第四个方框表示将分析得的依赖关系存入到血缘库中。
如图2所示,每条医疗流式数据在血缘关系模型中通过三个部分进行描述,三个部分是指总约束、表依赖关系和字段依赖关系(字段血缘);其中总约束用于描述该医疗流式数据在医疗业务系统中的业务数据模型,在总约束中为医疗流式数据设置一个主键值,不同的医疗流式数据主键值不同,表依赖关系和字段依赖关系用于描述该医疗流式数据目标字段的血缘关系。通过构建血缘关系模型,将医疗业务系统中的业务数据的元数据对应的规范、标准和约定等转换为固定描述(结构化描述),为医疗流式数据的结构化存储奠定基础。在血缘关系模型中查询某一条医疗流式数据对应的血缘关系的方法为:首先,根据总约束中设置的该医疗流式数据的主键值,然后,查找该医疗流式数据对应的表依赖关系和字段依赖关系。在后续医疗流式数据的存储过程中,可以基于医疗流式数据对应的表依赖关系判断是父表的数据到达还是子表的数据到达。
如图3所示,表依赖关系包括以下几种情况:
1)一父一子:如图3(a)所示,表b依赖表a,类似sql语句:select*fromaleftjoinbona.id=b.id
2)一父两子:如图3(b)所示,表b和表c都依赖表a,类似sql语句:select*fromaleftjoinbona.id=b.idleftjoincona.xxx=c.xxx
3)树形结构,最顶层的表为父表,称作root节点:如图3(c)所示,表b和表c都依赖表a表,d依赖表b,类似sql语句:select*fromaleftjoinbona.id=b.idleftjoincona.xxx=c.xxxleftjoindonb.yyy=d.yyyy。
实施例2:
本实施例提供一种医疗流式数据存储方法,如图4所示,包括以下步骤:
步骤1、对采集到的医疗流式数据进行标准化处理;
步骤2、在血缘库中的血缘关系模型中通过比对检索(解析)医疗流式数据的血缘关系;根据医疗流式数据的血缘关系,将其标准处理化后的数据保存到标准库中。
进一步地,医疗流式数据的采集过程为:
sparkstreaming(实时医疗流式数据处理系统)中的job(作业)程序启动时,首先会初始化获取血缘关系模型数据,通过spark广播机制将血缘关系模型数据分发至各采集医疗流式数据的服务器节点,通过广播机制有效防止了数据的冗余,提高了医疗流式数据的处理性能;
医疗流式数据的采集通过分布式、多线程应用程序设计并发作业,通过哈希取模算法hash(field)%n(field表示每条医疗流式数据的主键值,n表示采集医疗流式数据的服务器节点数)将每条医疗流式数据的采集任务分配(映射)至医疗业务系统中各个采集医疗流式数据的服务器节点;每个采集医疗流式数据的服务器节点,对分配给其的医疗流式数据采集任务,根据血缘关系模型中相应医疗流式数据对应的血缘关系,完成相应医疗流式数据的独立采集;然后,各采集医疗流式数据的服务器节点把采集完成的医疗流式数据按照每项业务独立的业务逻辑进行封装,然后发送至消息中间件kafka集群中(kafka集群就相当于医疗流式数据的管道,它保障了医疗流式数据的完整性与稳定性),最后由sparkstreaming从kafka集群中获取并处理医疗流式数据。
进一步地,sparkstreaming每接收到一条医疗流式数据,就会对其进行标准化处理,然后依据血缘关系模型中该医疗流式数据对应的血缘关系,对该医疗流式数据进行血缘关系溯源,解析出该医疗流式数据整体的血缘关系。
sparkstreaming解析完医疗流式数据整体的血缘关系后,会针对当前的医疗流式数据,通过血缘关系从缓存库中自动匹配属于自己的家族数据,完成一条完整的数据脉,最后进行数据的持久化,如图5所示,在持久化过程中按以下两种情况递归判断血缘关系并进行结构化存储,以保证数据的一致性和完整性:
情况一、父表的数据到达,则将相应业务字段数据存入标准库,并触发通知子表进行存储动作(即向下存储通知),子表依次递归将相应数据从缓存库取出存储到标准库中;
情况二、子表的数据到达,依据血缘库血缘关系模型中的表依赖关系,在标准库查看是否存在相应的上一级父表数据,若不存在则将数据暂存至缓存库备查;若存在,则触发通知上一级父表查询是否存在更上一级父表数据(即向上递归查询依赖广播),直至root节点,如果已通知至root节点查询,立即触发情况一执行。
进一步地,定期对标准库的数据进行检索、验证数据的一致性和完整性,从而对血缘库中的血缘关系(表依赖关系和字段依赖关系)进行评分和自更新。
血缘库中的血缘关系模型,是不断优化和训练过程得出来的。本发明设定以下迭代优化算法,确保血缘关系模型的更新。
当新的一批数据到来后,启动自学习过程。具体地,对于标准库中的数据,根据医疗业务数据的自身特点,提取每个数据的特征,构建它们的特征向量,分别记为xi,i=1,2,…,n;
将标准库中的数据分为不同的类别(组别),在相同的类别中的数据对应的特征向量之间的距离应该都很近(即它们的相似度很高),相似度越高的数据其血缘关系匹配度越高。通过k-means聚类算法,将标准库中的数据分为k个类别,这k个类别的中心记为μj,j=1,2,…,k;设经过聚类之后特征向量为xi的数据所属的类别为ti,ti∈{1,2,…,k},k-means聚类算法即通过迭代找寻最佳的分类结果ti,i=1,2,…,n,使损失函数l值最小,损失函数l定义为:
将当前最佳的分类结果对应的l值记录在血缘库中;并计算当前最佳的分类结果对应的l值与血缘库上一次记录的l值的差值。若差值高于特定值,说明数据模型修改较大,则按照上述的医疗流式数据血缘关系分析方法更新血缘库中的血缘关系模型。
实施例3:
本实施例提供一种医疗流式数据血缘关系分析装置,包括以下模块:
语义分析模块,用于针对标准化处理后的医疗流式数据进行语义分析,解析其中的业务字段,将业务字段作为目标字段;
血缘关系解析模块,用于依据标准化处理后的医疗流式数据中包含的逻辑关系迭代拆分解析目标字段的血缘关系,包括与之对应的表依赖关系和字段依赖关系,并将拆解得到的表依赖关系和字段依赖关系存入血缘关系模型。
所述装置中各模块的工作原理参见上述方法实施例中相应步骤的具体实现过程。
实施例4:
本实施例提供一种医疗流式数据存储装置,包括以下模块:
标准化处理模块,用于对采集到的医疗流式数据进行标准化处理;
数据存储模块,用于在血缘关系模型中通过比对检索(解析)医疗流式数据的血缘关系;根据医疗流式数据的血缘关系,将其标准处理化后的数据保存到标准库中;其中血缘关系模型是指根据上述实施例中的医疗流式数据血缘关系分析装置获得的血缘关系模型。
所述装置中各模块的工作原理参见上述方法实施例中相应步骤的具体实现过程。
实施例5:
本实施例提供一种电子设备,包括存储器及处理器,所述存储器中存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器实现上述实施例中医疗流式数据血缘关系分析或存储方法。
实施例6:
本实施例提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述实施例中的医疗流式数据血缘关系分析或存储方法。
- 还没有人留言评论。精彩留言会获得点赞!