预测大蒜鳞茎中功能性成分含量的方法与流程
本发明涉及检测分析技术领域,具体而言,具体涉及预测大蒜鳞茎中功能性成分含量的方法。
背景技术:
大蒜(拉丁名:alliumsativuml.)是重要的药食同源植物,具有抗菌、防癌抗癌、预防和治疗心血管疾病、抗氧化等重要的生理功能。中国是世界上最大的大蒜生产国和出口国。根据fao相关数据显示,2016年中国大蒜生产量和出口量分别为21.26和1.53百万吨,均占到世界产量和出口量的80%以上。大蒜鳞茎中主要的功能性成分为一类含硫化合物,包括大蒜素(allicin)等硫代亚磺酸类物质及其蒜氨酸(alliin)、甲基蒜氨酸(methiin)、s-甲基-l-半胱氨酸(smc)、s-烯丙基-l-半胱氨酸(sac)、s-(反-1-丙烯基)-l-半胱氨酸(spc)、γ-l-谷氨酰-s-甲基-l-半胱氨酸(gsmc)和γ-l-谷氨酰-s-烯丙基-l-半胱氨酸(gsac)等风味前体物质。目前,大蒜中含硫化合物的检测定量方法主要为液相色谱、液相色谱-串联质谱等,该类方法一般需要昂贵的大型仪器设备及标准品,且标准品目前存在不稳定、够买困难等现状,因此难以运用于实际生产中大蒜品质的监测与评估。
鉴于此,特提出本发明。
技术实现要素:
本发明的目的在于提供预测大蒜鳞茎中功能性成分含量的方法。
本发明是这样实现的:
本发明实施例提供一种预测大蒜鳞茎中功能性成分含量的方法,包括:
采用测得的贯穿大蒜鳞茎整个生长期的不同生长时期的表观特征数据和与不同生长时期对应的该大蒜鳞茎中功能性成分含量数据建立opls回归模型,以表观特征数据为x变量,大蒜鳞茎中功能性成分含量数据为y变量,表观特征分别为鳞茎高、鳞茎横径、鳞茎重、鳞芽高、鳞芽背宽、鳞芽重和水分含量,大蒜整个生长期指从大蒜鳞芽开始发育时至生长结束;
将功能性成分含量未知的同种类大蒜鳞茎的表观特征数据导入建立的opls回归模型中,即可得到该大蒜鳞茎在该生长时期的大蒜鳞茎中功能性成分的预测含量。
在可选的实施方式中,参与建立opls回归模型的表观特征数据为至少四组。
在可选的实施方式中,每组表观特征数据为多个大蒜鳞茎的表观特征数据的平均值;
优选地,每组表观特征数据为至少20个大蒜鳞茎的表观特征数据的平均值。
在可选的实施方式中,大蒜鳞茎中功能性成分含量数据为allicin含量数据和7种风味前体物质总含量数据,其中7种风味前体物质总含量为methiin、smc、alliin、gsmc、sac、spc和gsac含量之和。
在可选的实施方式中,在建立opls回归模型之前还包括对不同生长时期的大蒜鳞茎进行采样,两个相邻的采样时间间隔相同或不同。
在可选的实施方式中,两个相邻的采样时间间隔为7天。
在可选的实施方式中,采用游标卡尺测量鳞茎高、鳞茎横径、鳞芽高以及鳞芽背宽。
在可选的实施方式中,采用电子天平测量鳞茎重和鳞芽重。
在可选的实施方式中,将大蒜鳞芽切成片,称取目标重量的大蒜鳞芽,烘干后,根据烘干前后质量,测其中水分。
在可选的实施方式中,烘干条件为温度100~110℃,烘干时间为5.5~6.5h。
本发明具有以下有益效果:
本发明通过上述设计得到的预测方法,通用测得的大蒜不同生长时期的表观特征数据和测得的该大蒜鳞茎中功能性成分含量数据建立的opls回归模型,使用时将大蒜鳞茎某一生长时期的表观特征数据导入建立的模型中能够得出该生长时期较为准确的大蒜鳞茎中功能性成分的预测含量数据。该方法可运用于大蒜实际生产过程中,为大蒜的采收及质量控制等提供依据。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
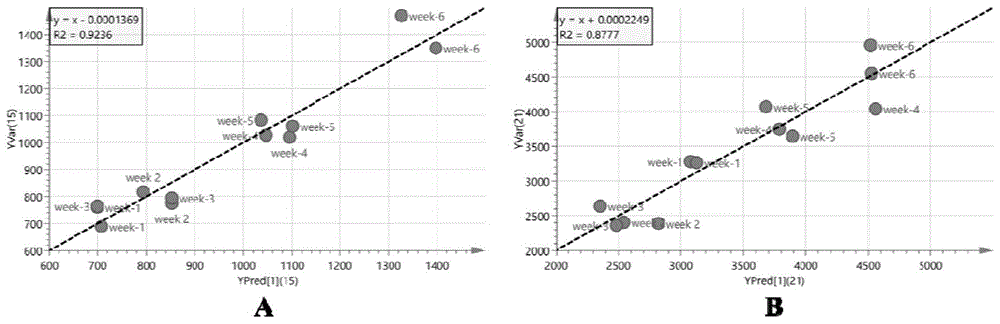
图1为不同生长期大蒜鳞茎中allicin和7种风味前体物质总含量实测值与预测值对应关系图;
图2为allicin和7种风味前体物质总含量预测模型中x变量的vip值;
图3为allicin和7种风味前体物质总含量预测模型中置换检验结果。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将对本发明实施例中的技术方案进行清楚、完整地描述。实施例中未注明具体条件者,按照常规条件或制造商建议的条件进行。所用试剂或仪器未注明生产厂商者,均为可以通过市售购买获得的常规产品。
下面对本发明实施例提供的预测大蒜鳞茎中功能性成分含量的方法进行具体说明。
预测大蒜鳞茎中功能性成分含量的方法,包括:
采用测得的贯穿大蒜鳞茎整个生长期的不同生长时期的表观特征数据和与不同生长时期对应的该大蒜鳞茎中功能性成分含量数据建立opls回归模型,以表观特征数据为x变量,大蒜鳞茎中功能性成分含量数据为y变量,表观特征分别为鳞茎高、鳞茎横径、鳞茎重、鳞芽高、鳞芽背宽、鳞芽重和水分含量,大蒜整个生长期指从大蒜鳞芽开始发育至生长结束;
将功能性成分含量未知的同种类大蒜鳞茎的表观特征数据导入建立的opls回归模型中,即可得到该大蒜鳞茎在该生长时期的大蒜鳞茎中功能性成分的预测含量。
大蒜鳞茎的大小、重量、水分含量等指标随着生长发育阶段的不同而发生改变,且其测定方法较为快捷、简便、绿色。正交偏最小二乘法(orthogonalpartialleastsquares,opls)能有效去除预测矩阵中与因变量无关的信息,提高模型的准确性及解释能力。因此,通过建立opls回归模型,寻找大蒜鳞茎表观农艺特征和功能性成分含量水平的关系,用表观特征指标预测大蒜鳞茎中功能性成分含量具有重要的实际意义。
经验证,本发明提供的预测大蒜鳞茎中功能性成分含量的方法,通用测得的大蒜不同生长时期的表观特征数据和测得的该大蒜鳞茎中功能性成分含量数据建立的opls回归模型,使用时将同种类大蒜鳞茎某一生长时期的表观特征数据导入建立的模型中能够得出该生长时期较为准确的大蒜鳞茎中功能性成分的预测含量数据。
为了提高建立的模型预测的准确性,优选地,参与建立opls回归模型的表观特征数据为至少两组。更优选地,每组表观特征数据为多个大蒜表观特征数据的平均值。进一步优选地,每组表观特征数据为至少20个大蒜鳞茎的表观特征数据的平均值。
具体地,大蒜鳞茎中功能性成分含量数据为allicin含量数据和7种风味前体物质总含量数据,7种风味前体物质总含量为methiin、smc、alliin、gsmc、sac、spc和gsac含量之和。
在建立opls回归模型之前还包括对不同生长时期的大蒜鳞茎进行采样,测大蒜不同生长时期的表观特征数据,和该大蒜鳞茎中功能性成分含量。两个相邻的采样时间间隔相同或不同。
例如,相邻的采样时间相同时可以是每隔1、2、3…10天等测一次;相邻的采样时间不同可以是第1天采样第一次、第2天采样第二次、第7天采用三次、第14天采用第四次……等。但为了保证根据不同采样时间测得的表观特征数据和功能性成分含量数据建立的opls回归模型预测的准确性,建议采样间隔天数不要过长。
在本发明优选的实施方式中,两个相邻的采样时间间隔为7天。
表观数据特征的检测:
采用游标卡尺测量鳞茎高、鳞茎横径、鳞芽高以及鳞芽背宽。采用电子天平测量鳞茎重和鳞芽重。将大蒜鳞芽切成片,称取目标重量的大蒜鳞芽,烘干后,根据烘干前后质量,测其中水分。优选地,为保证烘干效果,烘干条件为温度100~110℃,烘干时间为5.5~6.5h,具体实验时,通常在温度105℃下烘干6h。
大蒜鳞茎中功能性成分含量采用现有技术检测即可。
实验例1
采用本发明提供的评估方法验证本发明提供的预测大蒜鳞茎中功能性成分含量的方法的可行性。
1、本实验例中使用的仪器与软件、试剂与标准品及大蒜样品如下:
(1)仪器与软件:
uhplcdionexultimate3000system(美国thermofisher公司);uhplc-qtrap6500(美国sciex公司);xbridgec18柱(美国waters公司);uplcbehc18column(美国waters公司);milli-q去离子水发生器(美国milipore公司);qusel平行研磨仪e0301(微思行(北京)科技有限公司);梅特勒-托利多分析电子天平(梅特勒-托利多仪器(上海)有限公司);scdeallvx-iii多管涡旋振荡仪(北京踏锦科技有限公司);simca-p14.1(瑞典umetrics公司);
(2)试剂与标准品
hplc级乙腈和甲醇(德国merck公司);lc-ms级乙腈和甲酸(美国fisher公司);s-(反-1-丙烯基)-l-半胱氨酸(s-(trans-1-propenyl)-l-cysteine,spc)、γ-谷氨酰胺-s-甲基-l-半胱氨酸(γ-l-glutamyl-s-methyl-l-cysteine,gsmc)和s-甲基-l-半胱氨酸亚砜(s-methyl-l-cysteinesulfoxide,methiin)由北京思源勇拓有限公司合成;γ-谷氨酰胺-s-烯丙基-l-半胱氨酸(γ-l-glutamyl-s-allyl-l-cysteine,gsac)购于美国usp公司;s-烯丙基-l-半胱氨酸(s-allyl-l-cysteine,sac)、s-烯丙基-l-半胱氨酸亚砜(s-allyl-l-cysteinesulfoxide,alliin)和s-甲基-l-半胱氨酸(smc)购自阿尔塔科技有限公司;二烯丙基硫代亚磺酸酯(diallylthiosulfinate,allicin)购自美国chromadex公司。
(3)大蒜样品的采集
本实验例中大蒜品种为金乡白皮,产地为山东省济宁市金乡县(n35°04′1.84″,e116°18′21.41″),于2017年10月播种,2018年5月采收。自大蒜鳞芽开始发育时开始采样,每隔1周采样1次,直至大蒜正常采收后的两周终止采样。样品采集时间分别为2018年4月19日(week1)、4月26日(week2)、5月3日(week3)、5月10日(week4)、5月17日(week5)、5月24日(week6)。所有样品采集均设置3个重复,每个重复每个生长阶段至少采集20个大蒜鳞茎。将大蒜鳞茎剥皮后,每个重复取约300g未损坏的大蒜鳞芽于-70℃进行冷冻干燥。大蒜冷冻干燥完成后,采用平行研磨仪行粉碎,过60目筛后于-80℃冰箱中保存待测。
2、本实验例中大蒜鳞茎表观农艺指标的获取方法,步骤如下:
不同生长阶段大蒜采收后去除茎叶、根须后,清除表面泥土。采用游标卡尺测量大蒜鳞茎的鳞茎高、鳞茎横径、鳞芽高、鳞芽背宽;采用电子天平测量大蒜鳞茎的鳞茎重、鳞芽重(随机选取50个鳞芽,称重,随后计算平均重量);将大蒜鳞芽切成薄片,用分析天平称取10克大蒜置于铝盒中,于105℃下烘干6小时,测其水分含量。大蒜鳞茎相关指标测定结果如表1所示。
表1大蒜鳞茎相关指标
3、本实例中大蒜鳞茎中功能性成分的检测方法,步骤如下:
(1)7种风味前体物质的检测方法:
样品前处理:准确称取200mg大蒜粉于50ml离心管中,加入20ml的0.1%甲酸溶液,涡旋1min后于常温下超声10min。将混合溶液于10000rpm条件下离心5min,取上清液过0.22μm滤膜于进样小瓶中,将提取液稀释400倍,smc、sac和spc采用提取原溶液进行测定,gamc、gsac、methiin和alliin采用400倍稀释液进行测定。仪器条件:采用xbridgec18柱(4.6mm×150mm,3.5μm)进行色谱分离,柱温40℃,流速0.3ml/min。流动相为0.1%甲酸水溶液(a相)和0.1%甲酸乙腈溶液(b相),梯度洗脱:0–2min,98%a;2–14min,2%a;14–15min,2%a;15–15.1min,98%a;15.1–18min,98%a。进样量5μl。质谱采用电喷雾电离(esi)源,正离子多重反应监测(mrm)模式,监测离子对等相关检测参数见表2。气帘气,35psi;离子源气体(1),50psi;离子源气体(2),50psi;离子源温度,550℃;离子喷雾电压,4500v。各化合物定量结果见表3。
表27种风味前体物质的检测参数
注:*定量离子对;1:ce为碰撞电压;2:dp为去簇电压。
(2)allicin检测方法
准确称取200mg大蒜冻干粉于50ml离心管中,加入10ml预冷水,迅速涡旋15s,再加入10ml预冷水,涡旋30s。将混合提取液在4℃、10000rpm条件下离心5min,取上清液过0.22μm滤膜后进样分析。采用uplcbehc18柱(2.1mm×50mm,1.7μm)进行色谱分离,柱温28℃,流速0.3ml/min。流动相为水(a相)和甲醇(b相),50%a等度洗脱。进样盘温度设为4℃,进样量5μl,波长254nm。allicin定量结果见表3。
表37种风味前体物质及allicin检测结果(单位:mg/100g干重)
4、本实例中opls回归模型的建立,步骤如下:
将步骤2和步骤3中所获取的数据集导入到simca-p14.1进行模型的建立。将表1中的7个指标均设置为x变量,包括鳞茎高、鳞茎横径、鳞茎重、鳞芽高、鳞芽背宽、鳞芽重和水分含量。将表3中7种风味前体物质总含量和allicin的浓度设置为y变量将每个生长阶段3个重复数据中的2个重复数据(第1组和第3组)用来建立opls回归模型,剩余第2组数据作为预测集用来验证模型的可行性。分别以allicin和7种风味前体物质总含量为y变量建立opls回归模型。通过r2、q2、rmsee和rmsecv共4个指标对模型进行评估。当r2越接近1,代表模型的拟合能力越强;q2>0.5和>0.9分别代表模型预测能力较好和极好。通过建模发现,allicin和7种风味前体物质总含量的r2分别为0.924和0.822,q2分别为0.878和0.769,表明预测模型的拟合能力和预测能力良好。allicin和7种风味前体物质总含量预测值与实测值相对应关系分别见图1a和图1b。此外,allicin的rmsee和rmsecv值分别为86.04和100.20,7种风味前体物质总含量的rmsee和rmsecv值分别为360.61和404.65,与原始值相比,均在可接受的范围内。通过vip值分布图可分析各x变量对模型贡献的大小。从图3可以看出变量4(鳞芽高)对allicin(图2a)和7种风味前体物质总含量(图2b)两个回归模型的贡献均最大,变量1(鳞茎高)的贡献均最小。
为了进一步验证该模型的可靠性,采用了置换检验对模型进行验证。通过200次随机改变类别变量y的排列顺序,得到累积贡献率r2和预测能力q2。allicin模型中置换检验的r2和q2回归线与纵轴的截距分别为0.42和-1.31(图3a),7种风味前体物质总含量模型中置换检验的r2和q2回归线与纵轴的截距分别为0.31和-0.94(图3b),最右端鉴别模型的原始q2值大于左边任何一个y变量随机排列模型的q2值,说明所构建的opls回归模型没有出现过拟合现象,预测能力较好,模型可靠。
实验例2
采用已建立opls回归模型预测未知样品中allicin和7种风味前体物质总含量的方法,步骤如下:
将预测集数据中的x变量导入已建立的opls回归模型中,根据鳞茎高、鳞茎横径、鳞茎重、鳞芽高、鳞芽背宽、鳞芽重和水分含量可得出预测的allicin和7种风味前体物质总含量值,金乡白皮大蒜鳞茎中allicin和7种风味前体物质总含量的实测值和预测值如表4所示。从表4可以看出,allicin和7种风味前体物质总含量的预测值与实测值偏差较小,进一步证明了模型的可靠性。
表4大蒜鳞茎中allicin和7种风味前体物质总含量的实测值和预测值
综上所述,本发明提供的预测大蒜鳞茎中功能性成分含量的方法,通用测得的大蒜不同生长时期的表观特征数据和测得的该大蒜鳞茎中功能性成分含量数据建立的opls回归模型,使用时将同种类大蒜鳞茎某一生长时期的表观特征数据导入建立的模型中能够得出该生长时期较为准确的大蒜鳞茎中功能性成分的预测含量数据。该方法可运用于大蒜实际生产过程中,为大蒜的采收及质量控制等提供依据。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!