一种筛选骨折后形成血栓因素的方法与流程
本发明属于软件开发技术领域,尤其是涉及一种筛选骨折后形成血栓因素的方法。
背景技术:
血栓是指在活体的心脏和血管内,血液发生凝固或血液中某些有形成分凝集形成固体质块。正常情况下,血液具有潜在的可凝固性,主要作用是在外伤、出血等情况下起到局部凝固、止血等作用。
血栓的形成是血液在流动状态,由于血小板的活化和凝血因子被激活致血液发生凝固。血栓的形成条件包括:心血管内皮细胞的损伤、血流状态的异常以及血液凝固性增加。
如果血栓没有经过正规处理,机化到某个血管壁上,会形成静脉石或者陈旧性血栓,会引起血管腔变窄,从而导致下肢静脉高压,继而引起静脉曲张等一系列表现,引起腿肿、腿胀、腿痛,甚至引起跛行。
深静脉血栓还有非常严重的并发症,即肺栓塞,肺栓塞的发生几率在临床上非常高。肺栓塞一旦发生大面积的血栓脱落,会在短短的几分钟之内导致患者猝死。
患者骨折后,骨折端直接损伤血管内膜,启动血凝系统,骨折后卧床制动活动少导致血流缓慢,骨折后的失血,加上骨折端释放一些化学物质导致血液的高凝状态,所以容易形成血栓。
除此之外,临床中骨折后形成血栓具有多种关联因素,现阶段无法对高危因素进行全面的筛选和预定,不能很好的预测和排查,不利于患者预防和恢复。
技术实现要素:
本发明要解决的问题是提供一种筛选方法;尤其应用在医疗领域,通过患者健康数据,智能分析出骨折后形成血栓的多种关联因素,自动筛选出高危因素及所占比例,智能化程度高,算法精确度高的一种筛选骨折后形成血栓因素的方法。
为解决上述技术问题,本发明采用的技术方案是:一种筛选骨折后形成血栓因素的方法,包括以下步骤,
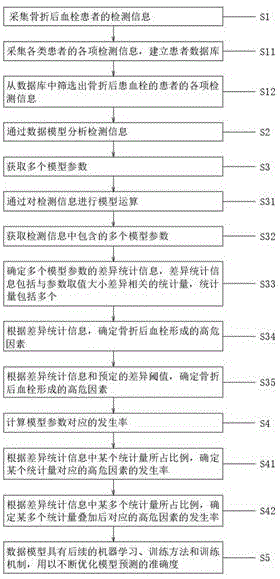
s1:采集骨折后血栓患者的检测信息;
s2:通过数据模型分析所述检测信息;
s3:获取多个模型参数;
s4:计算所述模型参数对应的发生率。
进一步的,所述数据模型包括但不限于逻辑回归模型、决策树模型、梯度提升决策树gbdt模型,概率分析模型。
进一步的,所述s3包括以下步骤,
s31:通过对所述检测信息进行模型运算;
s32:获取所述检测信息中包含的多个所述模型参数;
s33:确定多个所述模型参数的差异统计信息,所述差异统计信息包括与参数取值大小差异相关的统计量;
s34:根据所述差异统计信息,确定骨折后血栓形成的高危因素。
进一步的,所述统计量包括多个。
进一步的,所述s3还包括以下步骤,
s35:根据所述差异统计信息和预定的差异阈值,确定骨折后血栓形成的高危因素。
进一步的,所述s4包括以下步骤,
s41:根据所述差异统计信息中某个统计量所占比例,确定所述某个统计量对应的所述高危因素的发生率;
s42:根据所述差异统计信息中某多个统计量所占比例,确定所述某多个统计量叠加后对应的所述高危因素的发生率。
进一步的,还包括以下步骤,
s5:所述数据模型具有后续的机器学习、训练方法和训练机制,用以不断优化模型预测的准确度。
进一步的,本发明还提供一种装置,运行上述的数据处理方法。
进一步的,本发明还提供一种设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的算法,所述处理器执行所述计算机程序时实现上述的数据处理方法。
进一步的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机算法,所述计算机算法被处理器执行时实现上述的数据处理方法。
本发明具有的优点和积极效果是:
本发明通过将机器学习、人工智能引入到对患者相应数据库的处理之中,构建了相应的预测模型和算法,通过不同维度对数据库中患者的各项指标和状况进行综合处理,确定引起患者骨折后形成血栓的高危因素,通过计算高危因素的发生率,提高了预防效率。并在模型的基础时建立后续的机器学习、训练方法和训练机制,以不断优化模型预测的准确度,自动化程度高,实用性强。
附图说明
图1是本发明实施例的整体流程图。
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
下面结合附图对本发明实施例做进一步描述:
如图1所示,一种筛选骨折后形成血栓因素的方法,主要针对临床中骨折后形成血栓具有多种关联因素,通常状况下无法对高危因素进行筛选和预定的问题,而研发的一种通过筛选以往骨折后血栓患者的检测信息,智能分析出高危因素,从而计算出高危因素的发生率。具体包括以下步骤:
s1:采集骨折后血栓患者的检测信息。
s11:采集各类患者的各项检测信息,建立患者数据库。
s12:从数据库中筛选出骨折后患血栓的患者的各项检测信息。
数据库可以以一个医院作为一个整体,建立一个数据库;也可以一定区域内的多家医院资源共享,建立一个数据库;或者以社会整个医疗资源作为一个整体,建立数据量更大、更全面的数据库。
s2:通过数据模型分析检测信息。
数据模型包括但不限于逻辑回归模型、决策树模型、梯度提升决策树gbdt模型,概率分析模型。模型参数可以是模型计算过程中使用到的各个参数,例如权重系数等。对于较为复杂的神经网络模型,可以选取同一隐藏层对应的模型参数进行分析。
s3:获取多个模型参数。
s31:通过对检测信息进行模型运算。
s32:获取检测信息中包含的多个模型参数。
s33:确定多个模型参数的差异统计信息,差异统计信息包括与参数取值大小差异相关的统计量,统计量包括多个。
s34:根据差异统计信息,确定骨折后血栓形成的高危因素。
具体的,数据模型为逻辑回归模型,更简单地,采用的是如下线性回归函数:y=f(a,x)=a1*x1+a2*x2+a3*x3+a4*x4+a5*x5
其中,a1到a5为输入数据,x1到x5为模型参数。
目前许多逻辑回归模型在处理连续变量的源数据时,为了提高后续计算效率,会首先对变量进行分箱,然后进行独热(one-hot)编码转换,这样处理的结果是,与模型参数直接运算的变量取值都是0或1。也就是说,以上a1到a5是与源数据对应的经处理的输入数据,取值为0或1。并且,源数据处理的过程也是由数据模型进行,因此模型提供方可以知晓这些输入变量的含义。例如,在一个例子中,输入变量数据a1是对连续变量“患者年龄”进行分箱、编码的结果,表示年龄是否大于40岁,当取0时,表示小于40岁,取1时表示大于40岁。
类似地,输入变量数据a2和a3可以是对连续变量“既往慢性病史”进行分箱、编码的结果,其中a2表示患者是否患有糖尿病史,a3表示患者是否患有高血压史等等。因此,当a2和a3均取0,表示患者没有既往慢性病史;当a2取1,a3取0,表示患者患有糖尿病史,没有高血压史;当a2和a3均取1,表示患者既患有糖尿病史,又患有高血压史。
对于以上的公式,通过对模型参数x1到x5进行异常的差异化设置,筛选出若干高危因素。
差异统计信息可以直接简单的运算出高危因素的发生率。例如,差异统计信息包括统计量中的参数量与总参数量的比值,该比值就可以作为发生率评估信息。比值越大,发生率越高,比值越小,发生率越低。筛选发生率高的统计量作为高危因素。
s35:根据差异统计信息和预定的差异阈值,确定骨折后血栓形成的高危因素。
具体的,x1,x2,...x5的取值分别是0.9,0.12,0.303,0.03,0.034。上述5个参数中,x1的取值接近1,x2和x3为同一量级,但是有3倍的差距,而x4和x5则比x1到x3小一个量级。通过这样差距较大的参数设置,有可能通过结果反推输入变量的值。例如,可以推出如下结果:
如果:0.4<y<0.9,那么:a1=0,a2=1,a3=1;
如果:0.9<y<1.0,那么:a1=1,a2=0,a3=0;
如果:1.0<y<1.3,那么:a1=1,a2=1,a3=0;
如果:y>1.3,那么:a1=1,a2=1,a3=1。
由此,可以通过输出结果y的范围,反推出输入变量a1,a2和a3的取值,进而获取到患者信息,例如通过a1取值推断患者是否大于40岁,根据a2和a3的取值推断患者的既往慢性病史。
针对这样的情况,可以获取以下统计量中的一项或多项作为第一统计量:参数的方差;多个模型参数的两两组合中,参数取值比例高于预设比例阈值的组合数目,参数取值之差高于预设差值阈值的组合数目,等等。例如,对于以上的x1到x5,可以形成10种两两参数组合,如果预设比例阈值为10,那么参数取值比例高于预设比例阈值(10)的组合数目为3,即x1x4,x1x5,x3x4这3个组合。此外还可以计算参数取值之差过大的组合数目等统计量。
具体的,可以针对不同的差异统计量,设置不同的差异阈值,例如针对取值大小比例的统计量,设置比例阈值;针对位数差值的统计量,设置差值阈值等。
针对同一差异统计量,可以设置多个差异阈值,从而将差异统计量划分为不同范围,这些不同范围对应于不同的发生率。例如,对于统计量s1:参数最大值与最小值的比值,可以设置第一阈值10和第二阈值100,当s1低于第一阈值10时,发生率低;s1大于第一阈值10小于第二阈值100时,发生率为中;s1大于第二阈值100时,发生率高,选取发生率高的因素,作为高危因素。
s4:计算模型参数对应的发生率。
s41:根据差异统计信息中某个统计量所占比例,确定某个统计量对应的高危因素的发生率。例如,患者年龄大于40岁时,骨折后血栓发生率为29.2%,患者年龄小于40岁时,骨折后血栓发生率为17.3%。
s42:根据差异统计信息中某多个统计量所占比例,确定某多个统计量叠加后对应的高危因素的发生率。例如,患者年龄大于40岁,且患有糖尿病史时,骨折后血栓发生率为40%。
s5:数据模型具有后续的机器学习、训练方法和训练机制,用以不断优化模型预测的准确度。
本发明具有的优点和积极效果是:
本发明通过将机器学习、人工智能引入到对患者相应数据库的处理之中,构建了相应的预测模型和算法,通过不同维度对数据库中患者的各项指标和状况进行综合处理,确定引起患者骨折后形成血栓的高危因素,通过计算高危因素的发生率,提高了预防效率。并在模型的基础时建立后续的机器学习、训练方法和训练机制,以不断优化模型预测的准确度,自动化程度高,实用性强。
以上对本发明的一个实施例进行了详细说明,但所述内容仅为本发明的较佳实施例,不能被认为用于限定本发明的实施范围。凡依本发明申请范围所作的均等变化与改进等,均应仍归属于本发明的专利涵盖范围之内。
- 还没有人留言评论。精彩留言会获得点赞!