一种具有疾病推理的智能医疗系统及其诊断方法与流程
本发明属于智能医疗领域,特别涉及一种具有疾病推理的智能医疗系统及其诊断方法。
背景技术:
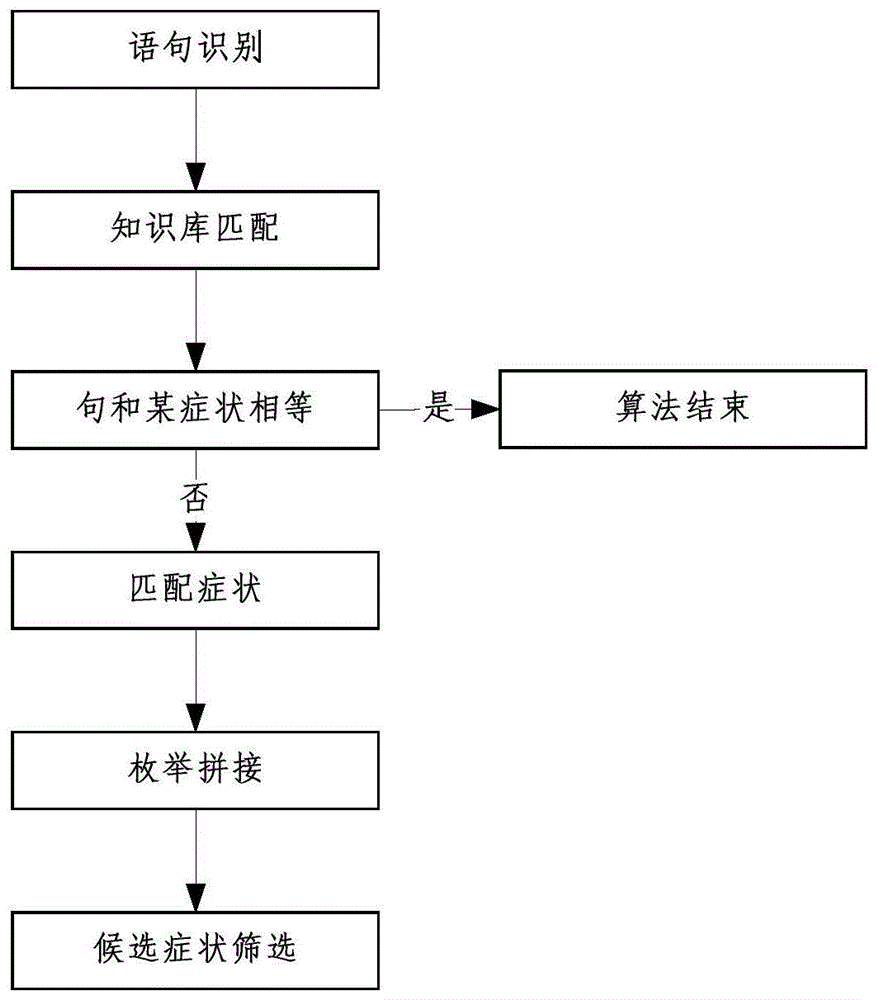
:随着物联网技术的快速发展,物联网技术将会被应用到智能医疗的各个领域。药品生产、防伪方面,应用rfid技术,根据药品的rfid标签,读出药品的生产原地,生产日期、物流过程等信息,监督从药品生产到药品使用之间的各个环节。病人病历档案方面,实现医疗信息化,实现病人相关信息,如病人的病历信息、病人的个人相关信息、病人的病情信息等信息的实时记录、有效传输与处理利用,使得在医院内部和医院之间通过联网,实时地、有效地共享相关信息。但是目前缺少将诊断、医疗资源调配、生理评估集合的平台。在医疗系统中,高昂的运营和医疗成本以及药品短缺问题给医疗行业带来了巨大的压力,可能导致病人满意度低下,一个全面的医疗资源补充系统对于医护人员保持医疗资源,特别是消费品的最佳水平,满足病人的需求至关重要。医疗设备和消费品是医护人员必须从不同的医疗供应商订购的共同资源。对于医疗设备,供应商提供定期维护,以确保耐用。因此,医护人员主要关注的是在补货过程中订购口罩、尿布、药品等消耗性医疗资源。目前,医疗工作者依靠过去的经验和个人判断,根据当前的需求,下医嘱补充医疗资源。然而,现有的补货决策系统存在两大问题。首先,为了防止缺货问题,工人们更愿意补充大量的医疗资源。它导致不必要的资源被储存在库存中,并导致高运营和医疗成本。其次,对药品的需求是基于病人的健康状况。如果需求出现不可预测的变化,工人很难立即预测和订购药品,从而导致药品短缺。如果没有适当的工具和技术来存储和分析数据,医护人员就很难补充足够的医疗资源来满足需求。这可能导致老年人因治疗延误和费用高昂而满意度较低。为了解决这些问题,提出了一种基于模糊关联规则挖掘和模糊逻辑技术的智能医疗资源补充系统(imrs),用于确定医疗资源补充的订购频率和数量。当前我国医疗健康市场存在一个重要特征,那就是医疗健康信息不对称。病人往往只有在医院医生的交流中能获取一定的医疗信息,在日常生活中很少接触到这些信息,例如医疗服务的需求,治疗效果如何等等信息对民众来说都是不透明的,这也让病人就医的过程中承担了更多的风险。随着人工智能技术的发展,传统专家系统也即将退出历史的舞台。但是在人工智能医疗技术之中依旧能看到专家系统的影子,以传统的专家系统为基础,创建的人工智能医疗技术可以获得更高效的表现。生理参数大数据应用领域非常之广,几乎涵盖我们每个人的生命过程。随着大数据理论的不断取得突破,与大数相关的技术日趋成熟,与大数相关的产业不断形成与完善,大数据将渗透到各行各业的各个方方面面,重塑人们的生活方式和就医体验,但是缺少通过大数据对病人的生理评估,缺少帮助医生为病人制定个性化的医疗方案。技术实现要素:为解决上述问题,本提供一种具有疾病推理的智能医疗系统及其诊断方法,为了实现上述目的,本发明的技术方案为:一种具有疾病推理的智能医疗系统,包括感知层、网络层、应用层,感知层包括智能终端、监测包括心电、呼吸、血压、血氧、脉搏,体温生理参数的传感器以及维持病人生理状态的医疗设备;感知层的各个传感器以及医疗设备都安装有采集节点,采集节点采集人体的生理参数;网络层通过多种通信方式,包括3g/4g、无线wifi或互联网,将数据以tcp/ip格式上传到物联网应用服务器环境进行处理;应用层为医疗监护平台,包括呼吸监控系统、心电监控系统、资源调配系统、诊断系统、生理评估系统;诊断系统分为在线部分和离线部分,在线部分包括用户输入界面、问题理解模块、疾病诊断模块,离线部分包括信息采集模块、词向量训练模块、知识库挖掘模块、知识库,其中,信息采集模块将外部采集的关于疾病诊断的信息作为原始数据提供给知识库挖掘模块和词向量训练模块,知识库挖掘模块读取解析好的数据,按照数据的种类,调用不同的算法进行分析;输出为量化的知识库,用户通过用户输入界面输入自己的描述之后,调用问题理解模块转化为症状的列表;一种具有疾病推理的智能诊断方法,包括如下步骤:步骤1、建立知识库;步骤2、对用户陈述进行问题理解;步骤3、利用知识库进行疾病推理;步骤4、根据疾病推理得出的结论判断是否确诊,是则输出诊断报告,进入步骤6,否则进入步骤5;步骤5、提供症状选择,用户选择症状,返回步骤3,用户选择症状反馈给疾病推理;步骤6、结束。其中,步骤3、利用知识库进行疾病推理,具体为:疾病关联特征有:性别、年龄和症状,某个症状可能为病人有或者强调了没有,计算病人得某个疾病的概率被归纳为分类问题,分类输入为上述特征,目标类别为疾病列表,估计在已有约束下的疾病的分布,目标函数表达为:si表示病人有症状,表示没有症状,目标函数可以转化为:其中,利用上述目标函数遍历知识库,得到概率最大时的dj,即推理得到疾病。本发明的有益效果:1)zigbee技术作为内部网络组网方式,搭建医护人员与被监护人员之间的桥梁,实现医护人员对被监护人的实时诊断和监护,取代了传统监护系统中采用的线缆,既方便被监护人进行移动,也给被监护人减少了因烦乱的线而带来的困扰和心理压力;2)本发明将远挖掘技术和模糊逻辑相结合的医疗资源管理系统,以补充医疗行业的医疗资源,通过采用数据挖掘,帮助医护人员提取病人的健康状况与控制特定疾病药物剂量之间的关系;通过考虑补货因素,包括药品用量的变化、供应商的交货期和尿布的更换频率,医务人员可以确定补货的订货频率和医疗资源的数量。对于没有历史数据的新养老院,护理人员可以参考类似养老院的数据来构建规则,从而确定补充医疗资源的数量,结果表明,该系统在降低运营和医疗成本的同时,为老年人提供适当的治疗,有助于提高医疗服务质量;3)基于互联网医疗数据,通过自动化的数据挖掘方法,建立了一个量化的医疗知识库,并且将其运用于医疗诊断中,在诊断系统中,结合语义分析和词向量的分析,从而更好的提取用户的症状,并利用贝叶斯算法根据用户的症状推断用户可能的疾病;4)将医生问诊的形式引入系统,让系统可以询问用户是否还有其他的症状,从而可以达到更加精确的诊断的目的;5)建立了一个量化的医疗知识库,通过命名体识别等数据挖掘的技术,在医疗文本中识别疾病和症状,建立了一个疾病和症状的字典,在医疗问答的数据中,识别用户的症状、年龄、性别和疾病,从而建立了疾病和症状、年龄、性别的量化的关系;6)结合了语义分析和词向量分析,提高了对于用户症状识别的精度,本在精确度和召回率上都优于只使用字典进行匹配的结果。7)利用分类器推断用户的疾病,并且将医生问诊加入到了问答系统中,让系统具有和用户交互的能力,诊断系统可以在不断的交互中提高对于用户疾病的判断精确度,能够帮助用户注意到自己没有注意到的症状。8)本发明以生理参数分析为背景,将深度学习方法运用到多维大数据中,将传统的医疗与新兴的大数据技术相结合,构建一种基于生理大数据的健康状态评估新方法,该评估方法是一种有效的方式在不影响所学习得到特征质量的同时能够提高网络的学习效率;9)基于数据分析后采用概率阈值和聚类分析的方法确定了病人患病发的概率和生理危险等级。附图说明图1为本发明的智能诊断方法流程图;图2为本发明的知识库建立流程图;图3为本发明的用户陈述进行问题理解流程图;图4为本发明的生理评估方法流程图。具体实施方式下面结合附图与实施例对本发明作进一步的说明。本发明的实施例参考图1-4所示。一种智能医疗系统,包括感知层、网络层、应用层,感知层包括智能终端、监测包括心电、呼吸、血压、血氧、脉搏,体温生理参数的传感器以及维持病人生理状态的医疗设备;感知层的各个传感器以及医疗设备都安装有采集节点,采集节点采集人体的生理参数,通过路由器与智能终端和医疗监护平台进行数据交换,采集节点zigbee的rf无线收发装置组成,路由器通过usb接口或者无线网络连接到智能终端,路由器通过zigbee组网协议建立网络与采集节点进行通信,路由器在采集节点与智能终端之间建立通信链接,是信息传输过程的枢纽,路由器有两个重要的功能,一是接收到智能终端的采集信息指令后,根据路由器存储的序号列表,与接收到的指令中所需要的采集节点建立通信链路;二是接收来自采集节点传输的生理参数信息,按照系统定义的格式组成信息帧,之后通过通信链路传递给医疗监护平台;网络层:通过多种通信方式,包括3g/4g、无线wifi或互联网,将数据以tcp/ip格式上传到物联网应用服务器环境进行处理;应用层为医疗监护平台,包括呼吸监控系统、心电监控系统、资源调配系统、诊断系统、生理评估系统;诊断系统分为在线部分和离线部分,在线部分包括用户输入界面、问题理解模块、疾病诊断模块,离线部分包括信息采集模块、词向量训练模块、知识库挖掘模块、知识库,其中,信息采集模块将外部采集的关于疾病诊断的信息作为原始数据提供给知识库挖掘模块和词向量训练模块,知识库挖掘模块读取解析好的数据,按照数据的种类,调用不同的算法进行分析;资源调配系统由三个模块组成,即:数据收集模块,知识发现模块和决策支持模块。生理评估系统通过构建生理评估模型,对生理参数进行处理,并评估病人的生理危险等级。其中,路由器连接智能终端后,首先要进行初始化操作,协议栈初始化,zigbee无线收发模块的通信模式是广播模式,上电初始化以后,搜寻网络范围内的设备,开始osal轮询操作,监听事件的发生,与采集节点进行组网;等待智能终端发送采集指令,处于无限循环监控的状态;如果上位机发送采集指令,调用相关的事件处理函数,传输到相应的采集节点进行采集,采集完后,在通过zigbee网络传输给智能终端;采集节点通过zigbee无线收发模块与路由器组网后,路由器根据应用层医疗监护平台的标识簇id,进行信息的传递,根据协议栈表中的地址,选取对应的采集节点;路由器组建好zigbee网络后,就会进入系统轮询状态,对串口监听,当有数据传送过来时,启动事件处理函数;智能终端通过串口向路由器发送采集指令时,将指令放入到缓冲区,路由器通过串口回调函数,对缓冲区的数据按照通信协议进行读取,并将读取到的数据帧进行分析,获取到目标节点号,发送给对应的目标节点;医疗监护平台控制整个系统,将接收到的数据进行解析并实时的显示,实时响应用户的操作以及监护人员在控制页面对相应的节点进行操作,控制采集节点对数据采集,对整个zigbee网络进行监控,建立存储病人的生理参数、诊断信息、药品供应的数据库,并能够取出数据库的数据绘制历史生理参数曲线,观察生理参数数据在某段时间内的变化;医疗监护平台功能包括:(1)生理参数数据采集医疗监护平台通过zigbee组网技术接收采集节点与路由器组成zigbee网络传递过来的多个生理参数数据,智能终端控制路由器工作,数据传送格式是按照系统定义的数据帧格式进行传输;通过向路由器发送采集指令,路由器启动串口中断,控制下位机对应的采集节点采集参数数据,采集节点采集完之后经过封装成系统定义的数据帧格式通过zigbee的rf无线收发装置发送给路由器,路由器发送给软件监护平台,接收到数据帧格式后,经过对应的解析,解析成十六进制字符串,在根据节点编号显示在软件控制界面相对应的位置上,实时监护用户的生理参数信息;(2)生理参数数据管理接收到路由器传输过来的生理参数数据后,实时存储到数据库,医护人员调用某个病人某段时间的历史生理参数数据,进行某段时间的身体状况以及身体健康的评估;数据库存储病人信息表和病人病历表,病人病历表中病人的编号id对应节点,对应的id接收到对应的节点的发送过来的信息,实时的存储到数据中,每隔30秒接收一次数据,30秒进行一次存储,实时存储多条数据;(3)生理参数数据分析和处理显示界面采集节点信息,并存储到数据库,医护人员对任意一段时间内的数据都可以进行查询,绘制历史生理参数曲线。医护人员对病人生理参数进行实时监控,每一个病人不同时间段采集得到的数据存放在数据库相应的表格中,医护人员可以选择想要观察的时间段进行数据的查看,并对该时间段的数据进行曲线绘制,方便医护人员进行数据分析。通过查询病人的id,查出该病人所有存储的数据。然后输入时间曲线,查询该段时间内的数据,并绘制出对应的生理参数曲线图;(4)人机交互医护人员通过操作软件界面对应的功能按钮,完成相对应的功能。软件要面向用户,具备可操作性;通过人机交互,来完成对系统的操作,完成对zigbee网络信息的采集。其中,采集节点采集数据的过程如下:步骤1、采集节点采集数据后,封装成数据帧的格式传输给上位机,上位机经过运算得出对应的数据值;步骤2、采集节点的zigbee模块进行初始化操作,设置射频参数,z-stack协议栈初始化;步骤3、zigbee的通信模式设置为广播模式,采集节点就会搜寻zigbee网络中的其他设备,路由器组建zigbee网络,等待上位机发送操作指令;步骤4、当上位机发送指令到路由器,路由器转发给对应的采集节点,采集节点收到采集数据的指令后,单片机被中断唤醒,单片机将采集到的指令和采集节点自身的采集节点标识封装成相应的数据帧发送给路由器步骤5、单片机会进入低功耗的休眠模式,等待下一个串口中断的唤醒;其中,步骤3的组建zigbee网络具体为:采用星型拓扑结构构建无线zigbee网络,网络规模为1个路由器和多个采集节点,路由器是网络中的核心,负责星型网络的组建和维护、以及采集节点的加入、生理参数数据的采集和与智能终端之间的通信;步骤3.1,上电启动,进行硬件、串口和z-stack协议栈初始化,开始建立新的网络,路由器根据z-stack协议栈配置好的网络参数进行信道扫描;步骤3.2,根据扫描的次数来判断是否有其他zigbee网络的出现,如果有其他的zigbee网络,则此次扫描失败,在扫描次数范围内继续进行扫描;步骤3.3,当扫描达到预设次数且无其他的zigbee网络,则确认信道,路由器调用z-stack协议栈相关的函数来建立新的zigbee网络;步骤3.4,开始定时操作进入osal轮询状态查看是否有新的事件发生;步骤3.5,循环监听是否有采集节点加入网络,检测是否有新的入网请求、连接请求以及数据处理请求,如果监听到有新的请求,会调用相关的函数处理事件;步骤3.6,路由器内部的led指示灯亮起,表明组网成功;步骤3.7,如果监听到采集节点连接请求,调用相关函数处理请求,并为采集节点分配新的网络地址;步骤3.8,处理好采集节点入网请求后,继续进入无线循环监听状态,监控是否有rf收发器发送的入网请求以及从串口发送过来的采集指令的请求,并等待新的采集节点的加入。其中,医疗资源调配系统由三个模块组成,即:数据收集模块,知识发现模块和决策支持模块。其中,数据采集模块采用集中式数据仓库,对员工行为、治疗数据、病人数据、药物数据、症状数据、供应商数据等六类相关数据进行采集和存储,下表显示了六种数据类型,在收集相关数据并存储到集中式数据仓库之后,所有重要的参数都被传输到下一个模块知识发现模块,以发现参数之间隐藏的关系;表1六种数据类型其中,知识发现模块采用了远挖掘集成数据模糊集思想和数据挖掘技术。在该模块中,从数据仓库中提取病人的历史记录作为输入参数,通过将病人历史记录中的量化参数转化为模糊集,启动数据挖掘过程,形成有用的关联规则,步骤如下:步骤1,将病人历史记录ri的每个健康状态pj转换为模糊集fij,并表示为其中,fijk为历史记录ri中健康状态pj之间的关系;wijk为历史记录ri中健康状态pj第k种模糊区间,tj为健康状态;pj模糊区间的索引;ri为病人的第i个历史记录,pj为第j种健康状态,h为病人历史记录的索引;步骤2,设置初始值k=1,统计健康状态pj的出现频次countjk,步骤3,寻找使得countjk最大的健康状态pj,countjk最大值为max-countjk,并在接下来的挖掘过程中找到表示健康状态pj相应的最大模糊区域max-wij;步骤4,设置初始值s=1,将max-countjk的值与预先定义的最小支持阈值αjk进行比较,其中,ls为集合,s为计数,如果ls中的max-countjk小于αjk,则去除max-countjk;步骤5,在ls中生成所有可能的项集,如果每个项集b的计数小于最小支持阈值的最大值αb的,则去除该项集,否则,将计数足够的项放入数据集合ls+1中;步骤6,对于新的数据集合ls+1,识别ri中项集b的模糊值fib,并求出每个项集的模糊计数countb;步骤7,检查(s+1)项集中每个参数的计数值与其对应的最小支持阈值,如果小于αb,则去除countb;步骤8,检查ls+1是否为空,如果s=1且存在空值,则保留算法;如果s≥2且存在空值,则转到步骤10;否则,进入步骤9;步骤9,设置s=s+1,重复步骤58;步骤10,如果k≥tj,则集中提取并构造所有可能的关联规则,计算所有可能关联规则的置信值,进入步骤11;否则设置k=k+1,重复步骤2-9;步骤11,对照预定义的置信阈值λ检查关联规则的置信值;如果置信值小于λ,则拒绝关联规则,用如果那么的格式表示病人的健康状况与药物剂量变化之间的关系;其中,健康状况包括心率、收缩压、呼吸次数、体重指数,药物为药物一和药物二,与符号的对应关系如下表所示,表2健康状况与符号的对应关系参数符号心率(每分钟)a收缩压(mmhg)b舒张压(mmhg)c呼吸次数(每分钟)d体重指数(kg/m2)e药物一(%)f药物二(%)g其中,模糊等级、隶属函数对应表如下所示:表3模糊等级和隶属度对应关系表其中,关联规则和置信值对照表如下所示:表4关联规则和置信值对照表关联规则置信值如果{b.rh}那么{f.sui}0.82如果{f.sui}那么{b.rh}0.78如果{c.n}那么{e.nw}0.72如果{g.sil}那么{e.nw}0.72如果{a.ng,b.rh}那么{f.sui}0.75如果{a.ng,f.sui}那么{b.rh}1其中,决策支持模块,除了知识发现模块的输出外,数据仓库中的其他补充参数,如库存中的现有药物水平和供应商的交货期,都被传输到决策支持模块进行决策。在模糊系统的模糊化中,这些具有定量值的参数首先被转换成模糊集的if-then格式,确定模糊集隶属函数的公式如下所示,其中s是模糊集,x数据集,μs(xi)是元素xi的隶属函数,将模糊集输入到模糊推理机中,通过对专家预先定义的决策规则进行匹配,生成模糊推理机输出的模糊集,通过面积中心计算解模糊进而转化为数值,面积中心计算公式如下:其中y是补给变化,wj是权重,cj是重心,aj表示集合x的面积,表示不再集合x的面积,决策支持模块的输出,确定最合适的医疗资源订货频率和数量。该医疗资源调配系统能够(1)提高综合管理评审的有效性,与传统的基于库存和订单数量的补货方法相比,为医疗资源的补货提供了一种系统的方法。根据对医疗资源的需求,医疗助理可以很容易地估算出适当的医疗资源补充量。这可以防止过度医疗资源的储存,从而解决积压问题。同时,可以大大降低补充不必要医疗资源的成本;(2)、提高医疗服务质量,通过采用远距挖掘技术,医护人员可以获得病人健康状况与控制疾病药物剂量关系的相关知识。另一方面,模糊逻辑的使用增加了确定订购频率和补充医疗资源数量的可靠性。从而使病人能及时得到适当的治疗,并对提供的服务质量更加满意;(3)提出了将远挖掘技术和模糊逻辑相结合的医疗资源配置,以补充医疗行业的医疗资源。它通过采用数据挖掘过程,帮助医护人员提取病人健康状况与控制特定疾病药物剂量之间的关系。另一方面,通过考虑补货因素,包括药品用量的变化、供应商的交货期和尿布的更换频率,医务人员可以确定补货的订货频率和医疗资源的数量。对于没有历史数据的新养老院,护理人员可以参考医院的数据来构建规则,从而确定补充医疗资源的数量,结果表明,该系统在降低运营和医疗成本的同时,为病人提供适当的治疗,有助于提高医疗服务质量。智能诊断系统分为在线部分和离线部分,在线部分包括用户输入界面、问题理解模块、疾病诊断模块,离线部分包括信息采集模块、词向量训练模块、知识库挖掘模块、知识库,其中,信息采集模块将外部采集的关于疾病诊断的信息作为原始数据提供给知识库挖掘模块和词向量训练模块,知识库挖掘模块读取解析好的数据,按照数据的种类,调用不同的算法进行分析。输出为量化的知识库,用户通过用户输入界面输入自己的描述之后,调用问题理解模块转化为症状的列表。智能诊断方法,包括如下步骤:步骤1、建立知识库;步骤2、对用户陈述进行问题理解;步骤3、利用知识库进行疾病推理;步骤4、根据疾病推理得出的结论判断是否确诊,是则输出诊断报告,进入步骤6,否则进入步骤5;步骤5、提供症状选择,用户选择症状,返回步骤3,用户选择症状反馈给疾病推理;步骤6、结束。其中,步骤1,具体为:步骤1.1、信息采集模块将外部采集的关于疾病诊断的信息作为原始数据提供给知识库挖掘模块,信息来源为网站数据;步骤1.2、知识库挖掘模块将原始数据进行类型划分,类型包括结构化数据、半结构化数据,无结构化数据,并进行相应的数据处理;具体为,(1)结构化数据结构化数据是指表格、列表、树状结构和有重复模式的段落,重复模式的段落可以通过分割来转化为表格处理,把相似的实体放到同一列或者同一行,实体包括病名、病原体、病理、症状、诊断、治疗,对表格中的每一列进行分类,所有特征针对的都是表格中的一列;结构化数据的特征包括:表头分值、空格比例、表格不同比例、内容真实行数和列的下标,具体如下表。表5结构化数据的特征描述表根据结构化数据的特征判断哪些表格可以使用,并将可以使用的表格的单元格与已有的知识库进行匹配,如果某一列中超过一半的表格能和知识库匹配,就认为这是一个疾病的列,通过结构化分类器进行整理后,加入知识库;(2)半结构数据半结构化数据相对于无结构的普通文本存在一定结构,然后又不是像数据库中的定义良好的结构化的表,半结构化数据包括网页中的html数据、xml数据和json数据。半结构化数据通过网页标签解析进行识别,按照标签的路径发现不同网页之间相似的实体,将相似的实体在同一列,从而将实体整理成结构化数据的表格形式,可按照结构化数据的特征提取方式对实体进行分列,通过结构化分类器进行整理后,加入知识库;(3)无结构数据无结构数据是指用自然语言表示的文本,为疾病百科、医疗问答、医疗文本以及医生诊断,无结构数据采用句型模式进行整理,包括如下步骤:步骤1.2.a1、输入无结构数据,以句为单位进行截取;步骤1.2.a2、对句进行切分,在知识库存储的病名、病原体、病理、症状、诊断、治疗的实体与各个句的词进行匹配,将匹配的词替换为通配符,从而将无结构数据转换为句型模式;例如,“感冒了会发烧”,感冒是病名,发烧是症状,则句型模式就是“[疾病]了就会[症状]”,[疾病]和[症状]为通配符;步骤1.2.a3、获取所有句型模式,对每种句型模式出现次数进行统计,出现次数超过阈值的句型模式加入模式库;步骤1.2.a4、以句为单位,用模式库中的模式匹配出所有符合的句,将通配符对应位置的词提取出来,统计每种词的提取次数,将提取次数超过阈值的词加入到知识库中;步骤1.2.a5、比较步骤4提取的词与步骤2中知识库中词重复度,如果重复度超过90%,则结束,否则返回步骤1。其中,结构化分类器进行整理具体为:步骤1.2.b1、对获取的表格数据进行识别和汇总,统计每种实体出现的频率,去除频率低于阈值的疾病和症状;步骤1.2.b2、计算疾病的先验概率p(dj),该疾病占所有可能的疾病的比例,计算公式为:其中,fdj为编号为j的疾病dj的出现次数,k为预先随机变量取值,优选为10;步骤1.2.b2.2、计算症状的先验概率p(si),计算公式为:其中,fsi为编号为i的症状si的出现次数,k为预先随机变量取值,优选为10;步骤1.2.b3、计算性别的先验概率p(gi),计算公式为:其中,fgi为编号为i的性别gi的出现次数;步骤1.2.b4、计算年龄的先验概率p(ai):针对于年龄,划分为7个区间,如下表所示:表7年龄划分表计算公式为:其中,fai表示编号i的年龄段ai出现的次数;步骤1.2.b5、计算疾病和症状的关系概率p(si|dj),统计在患有疾病dj的情况下,症状si出现的概率,计算公式如下:其中,fsidi为疾病j和症状i共同出现的次数;步骤1.2.b6、计算疾病和性别的关系概率p(gi|dj),统计在患有疾病dj的情况下,性别gi出现的概率,计算公式如下:其中,fsidj为疾病j和症状i共同出现的次数,k′为预先随机变量取值,优选为20;步骤1.2.b7、计算疾病和年龄的关系概率p(ai|dj),统计在患有疾病dj的情况下,年龄段为ai出现的概率,计算公式如下:其中,faidj为表示患有疾病dj并且年龄段为ai共同出现的次数;步骤1.2.b8、综合关系概率,通过步骤1.2.b2步骤1.2.b7分别计算结构化数据和半结构化数据的疾病和性别的关系概率、疾病和年龄的关系概率、疾病和年龄的关系概率,进行综合概率计算:其中,pz(si|dj)为疾病和症状的综合关系概率,p1(si|dj)表示从结构化数据中得到的疾病和症状的关系概率,p2(si|dj)表示从半结构数据中得到的疾病和症状的关系概率,α表示两个关系概率之间的权重比例,α取值优选为0.3;其中,pz(gi|dj)为疾病和性别的综合关系概率,p1(gi|dj)表示从结构化数据中得到的疾病和性别的关系概率,p2(gi|dj)表示从半结构数据中得到的疾病和性别的关系概率;其中,pz(ai|dj)为疾病和年龄的综合关系概率,p1(ai|dj)表示从结构化数据中得到的疾病和年龄的关系概率,p2(ai|dj)表示从半结构数据中得到的疾病和年龄的关系概率。其中,步骤2、对用户陈述进行问题理解,具体为:步骤2.1、通过包括逗号、句号和问号在内的标点符号将用户的用户陈述拆成句,对于每个句进行分别识别;步骤2.2、通过知识库匹配,识别出现在知识库中与症状或者症状别名匹配的句;步骤2.3、按照语义相等的算法,判断整个句是否和某个症状相等,如果有匹配的结果,整个算法结束,否则进入步骤2.4;其中,两个词a、b的语义相等被定义为存在一个切分方法,使得词a、b被切分为相同的段数,对应的段,是同义词或者完全相等。例如“面部肌肉痉挛”和“面肌抽搐”两个词,划分为“面部/肌肉/痉挛”和“面/肌/抽搐”。各自都是三段,并且相对应的“面部”和“面”,“肌肉”和“肌”,“痉挛”和“抽搐”都是近义词。就叫这两个词在语义上相等。步骤2.4、按照语义包含,匹配出句包含的症状,计算症状和整个句的语义相似度,作为候选症状;其中,语义包含是指,词a语义包含词b,被定义为词b存在一个划分,使得词b中的每一段,都和a的个分词结果中的某一个词是同义的。例如“今天天气不错,可是我肚子很疼”语义包含“腹痛”。首先将a进行分词,分词结果为{“今天天气”,“不错”,“可是”,“我”,“肚子”,“很”,“疼”}。然后b存在一个切分“腹/痛”,其中“腹”和“肚子”是同义词,“痛”和“疼”是同义词,所以就认为是词a语义包含词b。步骤2.5、枚举所有可能的拼接,计算拼接和候选症状的相似度,将最大的分数作为词向量分析相似度的值,如果所有的拼接都不能匹配,将段进行加权,计算tf-idf分值和向量相似度;具体为:对于词t和文档d,词频的计算公式为:tf(t,d)表示文档d中词t的词频,ft,d表示文档d中单词t的出现次数,max{}为极大值函数,对于文档集合d,某个单词t的逆向文档频率idf(t,d)计算公式为:其中,n为隐藏层节点的数量,tf-idf分值tfidf(t,d,d)为:tfidf(t,d,d)=tf(t,d)×idf(t,d),词向量分析可以在给定一个没有标注的语料库的情况下,把每个词被表示为一个向量。而这个向量表示了词的语义信息。向量va和vb之间的余弦值就是向量相似度,步骤2.6、将所有tf-idf分值和向量相似度小于阈值的候选症状删掉,在推理依据有冲突的症状中选择语义相似度最大的作为结果进行返回;其中,语义相似度是按照编辑距离的思想进行定义的,对于词a和词b,编辑距离是指最少进行多少个原子操作,能够使得词a变成词b,原子操作包括:删除任意一个字符、插入任意一个字符和改变任意一个字符,语义编辑距离是最少进行多少这样子的原子操作,可以使得两个字符串语义相等,如下式所示:步骤3、利用知识库进行疾病推理,具体为:疾病关联特征有:性别、年龄和症状,某个症状可能为病人有或者强调了没有,计算病人得某个疾病的概率被归纳为分类问题,分类输入为上述特征,目标类别为疾病列表,估计在已有约束下的疾病的分布,目标函数表达为:si表示病人有症状,表示没有症状,目标函数可以转化为:其中,利用上述目标函数遍历知识库,得到概率最大时的dj,即推理得到疾病;步骤5、提供症状选择,具体为:计算信息增益,n表示疾病dj的总数,g(disease,si)表示症状si导致的整体样本disease的信息增益,p(dj|si,g,a)表示在症状si、性别g、年龄a条件下的,疾病dj的概率分布,症状si与年龄导致的整体disease的信息增益,h(disease|si)和分别表示在给定症状si和非给定症状的情况下的整体样本disease条件熵,p(si)和分别表示给定症状si和非给定症状的先验概率,提供选择的症状si应该符合信息增益最大,提高供g(disease,si)最大时的症状si。其中,生理评估方法如下:步骤1、生理参数预处理;建立生理参数矩阵cq,q为生理参数序号,q=1、2......,其中,其中,表示第l种第t时刻被采集的生理参数,共有m种生理参数,共有n0个时刻;步骤2、标准化处理,得到标准化生理参数矩阵sq,其中,表示第l种第t时刻被采集的标准化生理参数;步骤3、选定生理数据集中的标准化生理参数矩阵sq输入变量,设定平移窗口的长度lk和步长ak,依次从输入变量中提取每一行标准化生理参数,利用平移窗口遍历每一行标准化生理参数,将其切割为若干数据区其中,i为向上取整获得的值,k=1、2......k,k为网络层数;步骤4、数据区加上一个偏移bk作为可微函数的输入变量,得到映射矩阵hk,其中,为映射参数;步骤5、设定大小为gk的池化窗口,最大值池化映射矩阵hk,得到数据矩阵ik:其中,为第k次的特征参数;步骤6、以数据矩阵ik更新步骤3中的标准化生理参数矩阵sq,以k+1来更新k,重新设定平移窗口的长度lk+1和步长ak+1,重新设定大小为gk+1的池化窗口,重新设定偏移bk+1,返回步骤4,直到k=k,k为最大更新次数,得到最终数据矩阵ik,其中,为最终特征参数,lk和ak分别为第k次进行步骤4时的平移窗口长度和步长;gk为第k次进行步骤4时,设定的池化窗口大小;步骤7、计算每个最终数据的分布概率值,p(xl)是以最终数据矩阵ik为多元高斯分布为多元高斯分布输入的高斯函数模型,通过p(xl)计算得到生理参数的概率;其中,为生理参数在时刻t上构成的特征参数向量,μ为特征均值向量,∑为协方差矩阵,步骤8、根据特征点的概率值大小,划定等概率线,将所有的划分为几个不同的概率区间,同一概率区间的生理状态为一个一个等级,概率值小的生理危险等级较高,从而评估病人的生理状况,判断公式如下:其中,εii=(0,1,2,...,n)为概率阈值,n为概率等级总数,划分规则为按照生理参数的概率p(xl)在一个某个概率区间的特征数量占总的特征数量的一个百分比,且特征的概率越小,特征点所属于的生理状态危险等级越高,其生理状态也就越差。其中,概率阈值εi确定如下:步骤8.1,从每个特征参数向量xl中随机选取1个特征构成聚类质心点为u1,u2,...,ul,...,um;步骤8.2,计算每个特征参数向量xl其余各点到聚类质心点ul的聚类中心的距离,将每个点聚类到离聚类质心点ul最近的聚类中去;步骤8.3,计算每个聚类中所有点的坐标平均值,并将平均值作为新的聚类中心;步骤8.4,反复执行步骤8.2、步骤8.3,直到聚类中心不再进行大范围移动或者聚类次数达到要求为止;步骤8.5,输出聚类中心个数,作为概率等级总数n,计算出每个聚类中心的特征数量与总的特征数量的百分比,按照百分比的大小,确定划分概率区间阈值εi。以上所述实施方式仅表达了本发明的一种实施方式,但并不能因此而理解为对本发明范围的限制。应当指出,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1