睡眠自动分期的算法的制作方法
本发明涉及睡眠算法领域,具体涉及一种睡眠自动分期的算法。
背景技术:
在人的睡眠过程中利用生理信息根据国际睡眠医学标准可将不同睡眠时间段划分为wake、rem、n1、n2和n3期,共五个正常类别。
近年来利用计算机设备和程序监测人睡眠状态并自动地将其分类的方法开始广泛应用。虽然现代电子信息技术、机器学习理论、生物医学工程等方面飞速发展,但利用机器学习理论的睡眠自动分期方法在科研、医学应用、消费电子等领域中仍没有国际公认的标准。主要原因包括人睡眠的基础机制理论并不透彻完善、临床医生和研究人员对睡眠人工分期国际标准缺乏足够理解和信任导致睡眠状态分类一致性低、睡眠监测系统的开发人员缺少专家经验、非正常睡眠模式混杂在正常睡眠模式中等。
凡是睡眠自动分期算法涉及特征工程的,开发人员很难有专家经验深刻理解睡眠的生理过程,专家知识主要来自美国睡眠医学学会的睡眠技术指导手册以及实践中摸索得到的人工分期的准则。
凡是睡眠自动分期算法涉及神经网络的,其算法模型很难拟合好实际数据,造成欠拟合模型情况,机器的判定结果的准确率远低于预期。
总体来说,现有睡眠自动分期的系统不足以精确达到区分正常睡眠状态。现有的基于特征工程的机器学习算法和基于神经网络的机器学习算法在少量数据范围内达到60%到90%的准确率,现有的算法都将整夜睡眠的生理信号数据片段作独立性假设没有时间连续性的考量,整个自动分期技术的稳定性、通用性、普适性和实用性等亟待优化。
技术实现要素:
本发明的目的在于提供一种睡眠自动分期的算法,解决现有睡眠自动分期算法稳定性、通用性、普适性以及实用性差的问题。
为解决上述的技术问题,本发明采用以下技术方案:
一种睡眠自动分期的算法,包括如下步骤:a.特征层利用多层感知器提取抽象特征合并传统基于专家经验的手工特征作为睡眠的信息表征;b.然后在机器模型层利用双向门控循环单元bi-gru作为网络模型;c.最后在修正层利用条件随机场crf方法作为时间连续性修正。
作为本发明的进一步优选,所述步骤a中利用多层感知器提取抽象特征合并传统基于专家经验的手工特征作为睡眠的信息表征包括如下步骤:s1、将由人睡眠中采集的生理数据制作数据集,包含脑电信号、眼电信号和下颌肌电信号,c={c1,c2,...,cn},c表示所有人的数据集合,n表示人数(或完成整夜睡眠的次数);s2、将每个人的一整夜连续的数据按时间顺序分成s段,各个段代表着不同睡眠阶段信息,随着时间推移,各段睡眠数据需要用不同算法模型来学习拟合,因此每段单独制作一个数据集,产生s个段数据集,每个段数据集包含n×m个样本数据,m为每段数据包含样本点的数量,一个样本点表示一个睡眠期,其时间跨度通常为30秒,每个样本点包含l个信号采样点,所以c的数据集样本量为s×n×m×l;s3、上述s个段数据集分别进行特征工程,其中方式包括提取抽象特征:自编码器;提取传统特征:时域特征、频域特征和非线性动力学特征,所有特征拼接成向量,每段数据生成m个向量,并顺序排列形成序列,即段序列;所述步骤b中的在机器模型层利用双向门控循环单元bi-gru作为网络模型包括如下步骤:s4、在机器模型层,双向门控循环单元bi-gru网络模型利用上述段序列作为样本来训练,s个段数据集分别包括n×m个段序列,各个段数据集分别按一定比例划分训练集和测试集,各个段数据集分别训练结束后,将模型保存;s5、用于训练的样本点输入到已经训练完成的双向门控循环单元bi-gru网络模型后,在最后得到睡眠阶段的分类标签;s6、将每夜晚睡眠的s段样本的标签序列拼接成一个超长序列,即一整夜数据最后对应一个完整的整夜标签序列,整夜标签序列是一维向量,其维度为t=s×m,含有n条整夜标签序列集依然按照先前划分是三集分开,训练集包含ct条,验证集包含cv条,测试集包含c条;所述步骤c中的在修正层利用条件随机场crf方法作为时间连续性修正包括步骤s7,步骤s7是将在s6步骤中得到的标签训练集序列输入到修正层,利用条件随机场crf方法在上下文信息转移提取方面的优势,具体指crf线性链方法为上述序列建模,通过维特比算法解码出最优标签序列路径,修正整夜标签序列,使其不断和专家人工睡眠分期判定结果的标签序列吻合。
作为本发明的进一步优选,所述步骤s1中还包括了如下子步骤:s11、在人睡眠中通过带有生理信号采集功能的多导睡眠仪设备按美国睡眠医学学会标准来监测、记录和存储人体生理信号数据;s12、不同种类的生理信号的原始信号数据经过采样后数字化后,分别进行零相位数字滤波以防止具有非平稳性质的生理信号出现相位失真,去除信号中极低频的基线、工频噪声和高频噪声,信号预处理即完成;s13、将上述生理信号中眼电信号、下颌肌电信号和脑电信号提取,利用三导信号进行原始数据集c={c1,c2,...,cn}制作,来自n个人个体的n条整夜睡眠数据,按人划分各自子集。
作为本本发明的进一步优选,所述步骤s2中还包括了如下子步骤:s21、合理设置切分阶段的模式,单人一整夜睡眠数据是按时间连续的,本发明算法将其整个连续过程划分s个阶段,被切分段的生理信号代表着睡眠过程不同信息,算法模拟专家人工睡眠分期时会对整夜信号数据有若干个趋势阶段的预判经验,更具一个阶段具有多长时间的跨度来设置每段样本点个数m;s22、为算法模型的前期准备制作具体数据集,在上述原始数据集基础上划分出s个段数据集,数据量大小不能出错,各段数据集均包含来自n个人的n×m个样本点,样本点是睡眠分期最小单位,其时间跨度为30秒,一个样本点对应于一个类别标签,类别标签有五个,其包括wake、rem、n1、n2和n3;s23、将标签和数据对齐,核对段数据集制作并保存至文件。以上数据集的制作是本发明的关键步骤,深刻影响整个算法的结果和性能。
作为本本发明的进一步优选,所述步骤s3中还包括了如下子步骤:s31、提取传统特征,根据信号计算特征向量xi维度为k。特征向量xi中的m个特征包括:时域特征量、频域特征量和非线性动力学特征量,时域特征量包含统计学特征量和几何学特征量。频域特征量包括功率谱密度特征量和时频特征量,非线性动力学特征量包括分形维数特征量和复杂度特征量,上述每种特征量均由各自参数和计算方式决定若干具体特征量;s32、提取抽象特征。通过人工神经网络领域的自编码器进行抽象特征提取,利用其无监督学习特性,拟合出能够对输入数据高效表示的人工神经网络,不添加额外人工辅助工作,而将输入的信号数据用固定的低维度的向量高效表征,即为自编码,其输出维度一般小于输入的信号维度,即自编码器数据降维特性。本发明采用自编码器,具有多个编码层,编码的复杂程度取决于神经网络堆叠层的层数,堆叠层数适当增加,可以有效地对输入数据进行压缩表示;s33、对上述的各个样本点进行特征工程,拼接成特征向量ξi,(ξi∈rkξi∈rk)各段中样本点必须按时间顺序排列成段序列,对应特征向量也排列成段序列seq,实际上段序列构造的整个特征空间为三维张量x∈rn×m×k。
作为本本发明的进一步优选,所述步骤s4中还包括了如下子步骤:s41、将seq生成的特征空间的张量x划分为最终训练数据集、验证数据集和测试数据集;s42、将上述按带有时间顺序的段序列seq输入到双向门控循环单元bi-gru网络模型,seq生成的特征空间的张量x∈rn×m×k的应满足bi-gru输入层要求,合理设置网络模型的结构、训练模式和初始参数,之后加载数据集开始模型的训练;s43、上述双向门控循环单元bi-gru网络模型在达到预设定的终止条件后保存模型。
作为本本发明的进一步优选,所述步骤s5中还包括了如下子步骤:s51、利用上述网络模型将数据全部前向传播,得到数据样本与之对应的睡眠分类阶段的标签,其中数据样本为上述段数据集生成的训练集和验证集;s52、将上述机器模型的分类结果标签与之专家人工分类结果标签比对,并且记录各个数据集的准确率、召回率和f1分数等评价指标,网络模型至此构建完成。
作为本本发明的进一步优选,所述步骤s7中还包括了如下子步骤:s71、构建条件随机场crf模型,将步骤s6中的标签序列训练集和对应专家人工分期的标签序列输入到条件随机场crf模型,设置特征函数个数k,迭代训练出最优的参数,进而得到条件随机场的条件概率p(y|x),即模型学习到睡眠阶段时间依赖性转移的上下文信息的,阶段转移和睡眠时间息息相关,也是本发明针对睡眠的特性利用crf模型的概率转移的关键一步;s72、测试crf模型修正后的结果,利用上述条件概率p(y|x)和验证集里的标签序列xs来计算出最优的标签序列y*,最后计算准确率等评价指标。统计对比crf修正模型和上述网络模型的结果。
与现有技术相比,本发明至少能达到以下有益效果中的一项:
1.选择合适的数据段切分,使得算法对于睡眠各阶段的适应性更强;
2.传统特征和抽象特征融合,扩增特征的表达能力,使得算法的精准度更高;
3.通过时间关联的网络和概率修正,有效增强算法在时间连续性上的解释。
附图说明
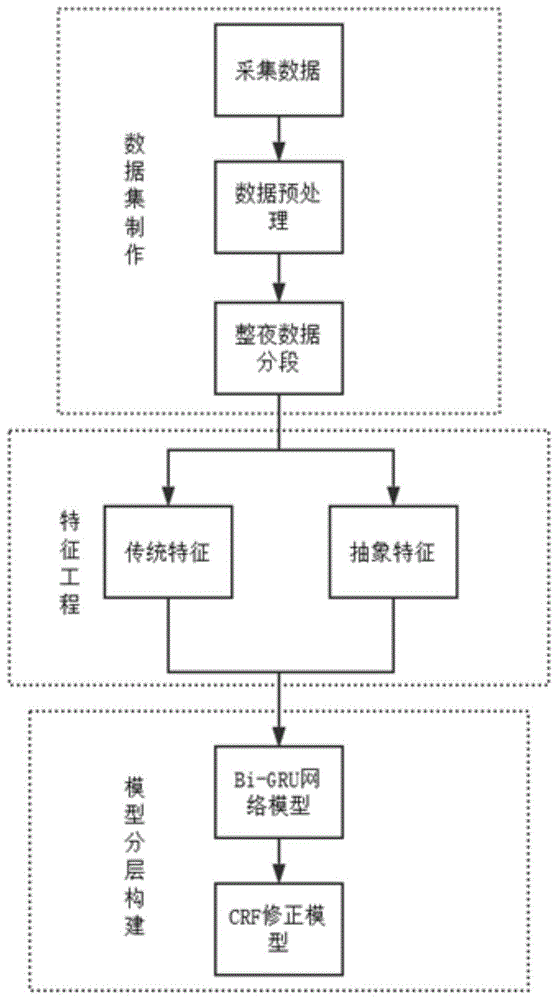
图1为本发明算法整体框图。
图2为本发明数据集制作流程示意图。
图3为本发明数据集制作示意图。
图4为本发明数据样本结构示意图。
图5为本发明栈式自编码器框图。
图6为本发明栈式自编码器第一层示意图。
图7为本发明栈式自编码器第二层示意图。
图8为本发明栈式自编码器输出层示意图。
图9为本发明栈式自编码器整体示意图。
图10为本发明bi-gru网络模型示意图。
图11为本发明gru节点内部结构。
图12为本发明加入crf修正的整体机器模型层示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
具体实施例1:
图1、图2、图3、图4、图5、图6、图7、图8、图9、图10、图11、图12示出了一种睡眠自动分期的算法,如图1所示,本发明整体思路按照数据集制作,特征工程和模型分层三大流程进行逐步细化一个睡眠自动分期算法模型的构建。
如图2所示,数据集制作流程分为数据采集、数据预处理和整夜数据分段三个子部分。首先,将由人睡眠中采集的生理数据制作数据集,包含脑电信号(eletroencephalogram,eeg)、眼电信号(electrooculogram,eog)和下颌肌电信号(electromyography,emg)等常规生理信号。c={c1,c2,...,cn},c表示所有人的数据集合,n表示人数(或完成整夜睡眠的次数)。
在人睡眠中通过带有生理信号采集功能的多导睡眠仪设备按美国睡眠医学学会标准来监测、记录和存储人体生理信号数据。
不同种类的生理信号的原始信号数据经过采样后数字化后,分别进行零相位数字滤波以防止具有非平稳性质的生理信号出现相位失真。去除信号中极低频的基线、工频噪声和高频噪声,信号预处理即完成。
将上述生理信号中眼电信号、下颌肌电信号和脑电信号提取,利用三导信号进行原始数据集c={c1,c2,...,cn}制作。来自n个人个体的n条整夜睡眠数据,按人划分各自子集。
将数据的结构进行可视化,如图3和图4所示,把每个人的一整夜连续的数据按时间顺序分成s段,各个段代表着不同睡眠阶段信息,随着时间推移,各段睡眠数据需要用不同算法模型来学习拟合。因此每段单独制作一个数据集,产生s个段数据集,每个段数据集包含n×m个样本数据,m为每段数据包含样本点的数量。一个样本点表示一个睡眠期,其时间跨度通常为30秒。每个样本点包含l个信号采样点。所以c的数据集样本量为s×n×m×l。
合理设置切分阶段的模式。单人一整夜睡眠数据是按时间连续的,本发明算法将其整个连续过程划分s个阶段,被切分段的生理信号代表着睡眠过程不同信息。算法模拟专家人工睡眠分期时会对整夜信号数据有若干个趋势阶段的预判经验。更具一个阶段具有多长时间的跨度来设置每段样本点个数m。
为算法模型的前期准备制作具体数据集,在上述原始数据集基础上划分出s个段数据集。数据量大小不能出错,各段数据集均包含来自n个人的n×m个样本点,样本点是睡眠分期最小单位,其时间跨度为30秒,一个样本点对应于一个类别标签。类别标签有五个,其包括wake、rem、n1、n2和n3。
将标签和数据对齐,核对段数据集制作并保存至文件。以上数据集的制作是本发明的关键步骤,深刻影响整个算法的结果和性能。
上述s个段数据集分别进行特征工程,其中方式包括提取抽象特征:自编码器;提取传统特征:时域特征、频域特征和非线性动力学特征。所有特征拼接成向量,每段数据生成m个向量,并顺序排列形成序列,即段序列。
其中提取传统特征。根据信号计算特征向量xi维度为k。特征向量xi中的m个特征包括:时域特征量、频域特征量和非线性动力学特征量。时域特征量包含统计学特征量和几何学特征量。频域特征量包括功率谱密度特征量和时频特征量。非线性动力学特征量包括分形维数特征量和复杂度特征量。上述每种特征量均由各自参数和计算方式决定若干具体特征量。
其中提取抽象特征。通过人工神经网络领域的自编码器(autoencoders)进行抽象特征提取。利用其无监督学习特性,拟合出能够对输入数据高效表示的人工神经网络。不添加额外人工辅助工作,而将输入的信号数据用固定的低维度的向量高效表征,即为自编码。其输出维度一般小于输入的信号维度,即自编码器数据降维特性。本发明采用自编码器(stackedautoencoders,sa),具有多个编码层,编码的复杂程度取决于神经网络堆叠层的层数,堆叠层数适当增加,可以有效地对输入数据进行压缩表示。
如图5、6、7、8、9展示栈式自编码器的网络结构原理,提取抽象特征。
对上述的各个样本点进行特征工程,拼接成特征向量ξi,(ξi∈rk)各段中样本点必须按时间顺序排列成段序列,对应特征向量也排列成段序列seq。实际上段序列构造的整个特征空间为三维张量x∈rn×m×k。
经过数据集制作流程和特征工程,数据集结构即达到本发明的设计思想,充分体现特征融合和数据的时间依赖性。
如图10所示,在机器模型层,双向门控循环单元bi-gru网络模型利用上述段序列作为样本来训练,s个段数据集分别包括n×m个段序列。
将seq生成的特征空间的张量x划分为最终训练数据集、验证数据集和测试数据集。
交叉验证后,各个段数据集分别训练结束,最后将模型保存。
将上述按带有时间顺序的段序列seq输入到双向门控循环单元bi-gru网络模型。seq生成的特征空间的张量x∈rn×m×k的应满足bi-gru输入层要求。合理设置网络模型的结构、训练模式和初始参数,之后加载数据集开始模型的训练。
上述双向门控循环单元bi-gru网络模型在达到预设定的终止条件后保存模型。
利用上述网络模型将数据全部前向传播,得到数据样本与之对应的睡眠分类阶段的标签。其中数据样本为上述段数据集生成的训练集和验证集。
将上述机器模型的分类结果标签与之专家人工分类结果标签比对,并且记录各个数据集的准确率、召回率和f1分数等评价指标,网络模型至此构建完成。
用于训练的样本点输入到已经训练完成的双向门控循环单元bi-gru网络模型后,在最后得到睡眠阶段的分类标签。
将每夜晚睡眠的s段样本的标签序列拼接成一个超长序列,即一整夜数据最后对应一个完整的整夜标签序列。整夜标签序列是一维向量,其维度为t=s×m。含有n条整夜标签序列集依然按照先前划分是三集分开,训练集包含ct条,验证集包含cv条,测试集包含c条。
将上述标签训练集序列输入到修正层,利用条件随机场crf方法在上下文信息转移提取方面的优势,具体指crf线性链方法为上述序列建模,通过维特比算法解码出最优标签序列路径。修正整夜标签序列,使其不断和专家人工睡眠分期判定结果的标签序列吻合。
构建条件随机场crf模型。将步骤s6中的标签序列训练集和对应专家人工分期的标签序列输入到条件随机场crf模型,设置特征函数个数k,迭代训练出最优的参数,进而得到条件随机场的条件概率p(y|x),即模型学习到睡眠阶段时间依赖性转移的上下文信息的,阶段转移和睡眠时间息息相关,也是本发明针对睡眠的特性利用crf模型的概率转移的关键一步。
测试crf模型修正后的结果。利用上述条件概率p(y|x)和验证集里的标签序列xs来计算出最优的标签序列y*。最后计算准确率等评价指标。统计对比crf修正模型和上述网络模型的结果。
尽管这里参照本发明的多个解释性实施例对本发明进行了描述,但是,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本申请公开的原则范围和精神之内。更具体地说,在本申请公开、附图和权利要求的范围内,可以对主题组合布局的组成部件和/或布局进行多种变型和改进。除了对组成部件和/或布局进行的变形和改进外,对于本领域技术人员来说,其他的用途也将是明显的。
- 还没有人留言评论。精彩留言会获得点赞!