多模态骨质疏松分层预警方法及系统与流程
本发明属于医疗数据分类领域,尤其涉及一种多模态骨质疏松分层预警方法及系统。
背景技术:
:本部分的陈述仅仅是提供了与本发明相关的
背景技术:
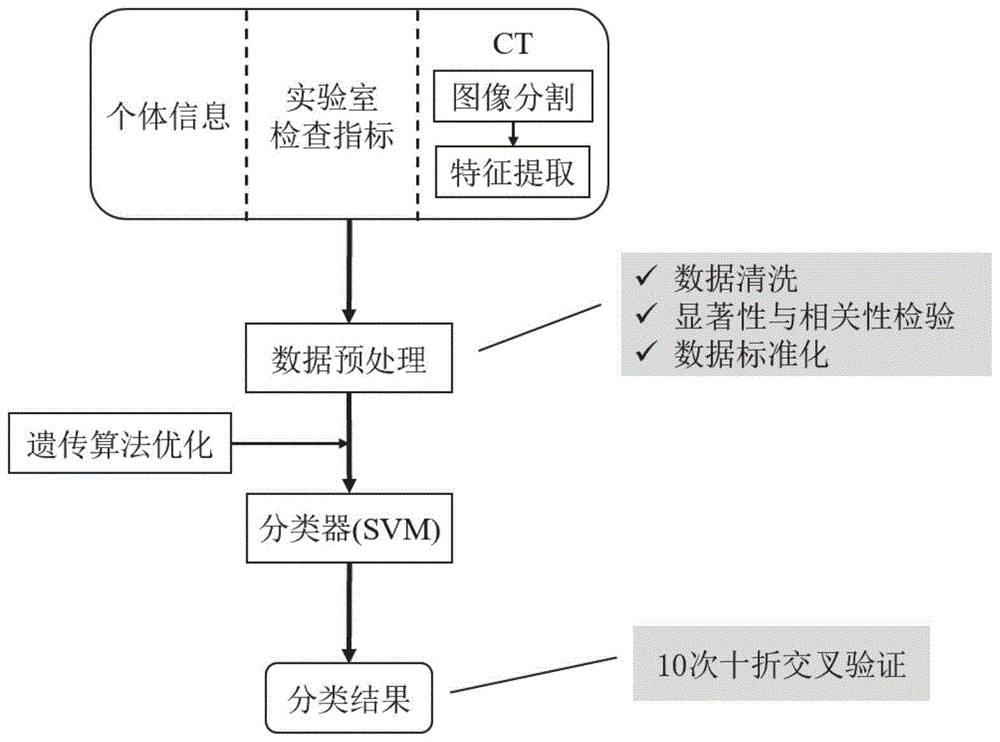
信息,不必然构成在先技术。原发性骨质疏松是一种常见的以骨量减少和骨微结构遭到破坏为特征的骨骼疾病,多发生于老年人中,特别是绝经后的妇女群体中。随着人口老龄化进程的加速,骨质疏松的发病率日益增高,已成为继心血管疾病和糖尿病之后的全球第三大慢性疾病。骨质疏松又被称为“沉默的杀手”,在发病早期并无明显症状,一般直到患者发生脆性骨折时才会被发现,这往往会给患者带来极大的痛苦和经济负担,但骨质疏松是可防、可治的,因此骨质疏松的早期筛查与识别是治疗的关键。双能x线吸收检测法(dualenergyx-rayabsorptiometry,dxa)通过测定人体腰椎或其他部位骨矿物质密度与骨骼健康人群的差异来推断骨折发生的风险,是由世界卫生组织推荐的用于骨质疏松临床诊断的“金标准”。但是由于dxa设备昂贵、有辐射暴露的风险,以及公众对骨质疏松的认识不足等原因,导致骨密度的检测率较低,严重影响了骨质疏松的治疗。近年来,随着人工智能技术的发展,机器学习已经被广泛应用于各个领域,在医疗领域也得到了认可,被用于辅助医生诊断。目前对骨质疏松的识别研究主要利用既有的影像学数据,输入特征参数单一,而实际骨质疏松的识别与除了影像学数据之外的参数也具有关联性。目前仅仅只采用单一的影像学数据,未考虑其他相关特征信息与骨质疏松识别的关系,影响骨质疏松的识别精度。技术实现要素:为了解决上述问题,本发明提供一种多模态骨质疏松分层预警方法及系统,其通过挖掘多模态体检数据与骨质疏松间的联系,建立了一个三层预警模型,旨在不增加额外成本和辐射损害的同时,实现对骨质疏松的准确筛查。为了实现上述目的,本发明采用如下技术方案:本发明的第一个方面提供一种多模态骨质疏松分层预警方法。一种多模态骨质疏松分层预警方法,包括:接收三层输入特征,这三层输入特征分别为个体信息、实验室检查指标和腰椎ct图像特征;对三层输入特征进行数据清洗、显著性与相关性检测及数据标准化预处理;从预处理的三层输入特征中筛选出各层最优输入特征并形成输入特征集,经多模态骨质疏松分层预警模型,输出骨质疏松预警结果;其中,多模态骨质疏松分层预警模型是svm分类器,svm分类器的优化过程为:使用遗传算法同时进行超参数优化和各层最优输入特征选择。本发明的第二个方面提供一种多模态骨质疏松分层预警系统。一种多模态骨质疏松分层预警系统,包括:输入特征接收模块,其用于接收三层输入特征,这三层输入特征分别为个体信息、实验室检查指标和腰椎ct图像特征;预处理模块,其用于对三层输入特征进行数据清洗、显著性与相关性检测及数据标准化预处理;预警输出模块,其用于从预处理的三层输入特征中筛选出各层最优输入特征并形成输入特征集,经多模态骨质疏松分层预警模型,输出骨质疏松预警结果;其中,多模态骨质疏松分层预警模型是svm分类器,svm分类器的优化过程为:使用遗传算法同时进行超参数优化和各层最优输入特征选择。本发明的第三个方面提供一种计算机可读存储介质。一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述所述的多模态骨质疏松分层预警方法中的步骤。本发明的第四个方面提供一种计算机设备。一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述所述的多模态骨质疏松分层预警方法中的步骤。与现有技术相比,本发明的有益效果是:本发明针对目前骨质疏松检测率低的问题,通过挖掘多模态体检数据与骨质疏松间的联系,建立了一个三层预警模型,旨在不增加额外成本和辐射损害的同时,实现对骨质疏松的准确筛查;为提高模型性能,本发明采用遗传算法对模型的超参数进行优化,并对输入的特征进行选择,从而降低特征维度,提高了模型的泛化能力,达到了更好的分类效果。附图说明构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。图1为本发明实施例的多模态骨质疏松分层预警方法流程图;图2为甘油三酯数据分布的箱体图;图3为遗传算法的流程图;图4为输入特征为个体信息和实验室检查指标所对应的模型的roc曲线;图5为输入特征为个体信息、实验室检查指标和腰椎ct图像特征所对应的模型的roc曲线。具体实施方式下面结合附图与实施例对本发明作进一步说明。应该指出,以下详细说明都是例示性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属
技术领域:
的普通技术人员通常理解的相同含义。需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。本发明提出的是多模态骨质疏松分层预警模型,如图1所示,模型按照输入特征在体检中出现的普遍程度分为三层,下面将结合附图对模型的实施方式进行阐述:实施例一结合图1,本实施例的一种多模态骨质疏松分层预警方法原理为:步骤1:接收三层输入特征,这三层输入特征分别为个体信息、实验室检查指标和腰椎ct图像特征;步骤2:对三层输入特征进行数据清洗、显著性与相关性检测及数据标准化预处理;步骤3:从预处理的三层输入特征中筛选出各层最优输入特征并形成输入特征集,经多模态骨质疏松分层预警模型,输出骨质疏松预警结果;其中,多模态骨质疏松分层预警模型是svm(supportvectormachine,支持向量机)分类器,svm分类器的优化过程为:使用遗传算法同时进行超参数优化和各层最优输入特征选择。在具体实施中,本实施例的多模态骨质疏松分层预警模型的优化过程同时优化超参数优化和各层最优输入特征选择。多模态骨质疏松分层预警模型的输入参数由三层构成,输入参数逐层增加,每层增加的输入参数分别为个体信息、实验室检查指标、ct图像特征。在优化svm分类器之前,采集样本数据,样本数据包括个体信息、实验室检查指标、腰椎ct图像,研究对象选取的是做过腰椎dxa骨密度检查且非继发性骨质疏松患者;在ct图像上,手动分割腰椎椎体,作为感兴趣区域(regionofinterests,rois),排除骨折的椎体;提取各个椎体的图像特征;将提取的特征数据进行处理,构建数据队列;使用svm作为分类器,采用10次十折交叉验证评估模型的性能。其中,个体信息中包含的年龄、bmi、绝经等是骨质疏松症的高危因素,腰椎ct图像的纹理特征在骨质疏松与正常骨骼间存在差异,有助于骨质疏松的识别。svm分类器模型是根据数据来源的难易程度分层的,第一层只包含个体基本信息,第二层在第一层的基础上又添加了实验室检查数据,第三层又继续添加了提取的ct图像特征。第一层和第二层的处理方法基本一致,但第三层加入图像后,处理步骤增加了图像手动分割与特征提取。模型分层是为了根据实际应用中输入的特征进行骨质疏松的识别,层数越高,识别的准确率也越高。个体信息和实验室检查指标是经过预处理后直接进行融合构建数据队列的,图像是提取出特征并经预处理后再与个体信息和实验室检查指标进行特征融合。最后为消除量纲的影响,所有连续特征做标准化处理。下面介绍基于优化的支持向量机的多模态骨质疏松分层预警模型的第一层和第二层,即输入参数包括研究对象的个体信息和实验室检查指标,具体步骤如下:1.获取研究对象的个体信息和实验室检查指标所述的研究对象均做过腰椎骨密度检查,并依据dxa检测结果确定是否为骨质疏松患者,其中骨质疏松特指原发性骨质疏松,继发性骨质疏松被排除在外;本实施例共收集795个样本,均来源于某医院骨科。所述的个体信息包括年龄、性别、身高、体重、舒张压、收缩压、脉压、是否绝经。所述的实验室检查指标包括血常规和生化全套,其中血常规指标包括白细胞、中性粒细胞比率、中性粒细胞计数、淋巴细胞比率、淋巴细胞计数、单核细胞计数、单核细胞比率、红细胞、血红蛋白、红细胞压积、血小板计数、血小板压积、血沉;生化全套包括谷丙转氨酶、谷草转氨酶、谷氨酸脱氢酶、γ-谷丙酰基转肽酶、碱性磷酸酶、腺苷脱氨酶、总胆红素、直接胆红素、间接胆红素、前白蛋白、总蛋白、白蛋白、球蛋白、总胆固醇、高密度脂蛋白胆固醇、低密度脂蛋白胆固醇、甘油三酯、葡萄糖、尿素氮、肌酐、乳酸脱氢酶、钾、钠、氯、钙、磷、镁。2.将获取的数据进行处理,确定模型的输入参数。所述特征处理主要包括数据清洗和统计学分析。获取的数据除性别和是否绝经外均为连续特征,联合所述的两个特征,用0、1、2分别表示女性未绝经、女性绝经、男性,并因此剔除性别特征。个体间的身高、体重不具备直接的可比性,因此构建身体质量指数(bodymassindex,bmi)作为新的特征,定义如下式所示:式中,weight表示体重,单位是千克(kg);height表示身高,单位是厘米(cm)。数据清洗主要包括缺失值处理和异常值处理;对缺失比率超过20%的特征和具有缺失值的样本做删除处理;通过绘制特征的箱体图或散点图查看特征值的分布情况,将离群点视为异常值并做删除处理,以甘油三酯为例,如图2所示,有一样本的特征值极有可能为异常值,故删除该样本。采用统计学方法剔除在骨质疏松和骨骼健康间无显著差异及特征间高度相关的特征,从而降低输入特征的空间维度,降低模型过拟合的风险。经缺失值和异常值处理后,本示例最终共有663个样本,样本分布情况如表1所示,年龄在组间无显著差异。表1样本数量分布与组间年龄分布采用曼-惠特尼u检验选择组间存在显著差异的连续特征,采用卡方检验检验“绝经”特征在两组别间是否有显著差异;显著性水平p=0.05。采用pearson相关性检验判断特征间的相关性,特征间pearson相关系数|γ|>0.8的特征只保留其中一个。经统计学检验后,特征数由46降为25。由于模型采用的分类器svm对特征量纲敏感,故对选择出有显著差异的连续特征做标准化处理,将数据分布缩放为标准正态分布,以消除不同特征间量纲的影响,特征标准化的转换公式为:其中,xnew、x、μ、σ分别表示转换后的特征值、原特征值、特征总体均值、特征总体标准差。对绝经特征采用onehot编码,避免对无序特征进行排序。3.使用参数优化和特征选择的svm作为分类器,得到分类结果。所述svm分类器的优化是使用遗传算法同时进行模型超参数优化和输入特征选择,根据模型的分类效果选择最优参数和特征子集;为处理非线性优化问题,引入核函数技巧;svm的分类标签根据dxa的检测结果标定。所述的svm的优化包括超参数优化和特征选择,优化方法选择遗传算法(geneticalgorithm,ga),ga的操作流程如图3所示。svm本质是线性分类器,引入核函数技巧,使得svm具备处理非线性问题的能力,本发明选用高斯核函数。svm需要优化的参数包括惩罚系数c和高斯核参数g,c、g值对模型的性能有很大影响;c越大,对误分类样本的惩罚越大,模型越容易过拟合,反之容易欠拟合;g越大,支持向量越少,模型越容易过拟合,反之容易欠拟合。本发明设定c的范围为[0,100],精度为0.1;g的范围为[0,10],精度为0.001。ga在优化c和g的同时,还要从输入特征中选取最具相关性的特征。ga的种群规模和迭代次数对算法的寻优能力有重要影响,为了兼顾算法性能与求解速度,本实施例将上述参数值分别设定为200,100;染色体编码方式采用二进制编码,前10位编码表示c的值,11-24位表示g的值,剩余编码表示选中的特征,长度取决于输入特征的个数,其中0表示未选用该特征,1表示选用该特征,二进制编码与参数值的对应关系如下式所示:式中y表示编码对应的参数值,x表示二进制编码的值,a、b分别表示参数取值范围的下限和上限,n表示编码位数,n值的大小由下式确定:式中p表示参数的精度。ga是模拟自然界中生物进化而提出的一种优化算法,通过选择每一代中的优秀个体,并模拟染色体间的交叉、变异来求解问题。在ga算法中,每一个个体都代表了问题的一个基本可行解,解码每个个体即可得到对应的参数值与选择的特征子集;将解码结果输入到svm中,根据10次十折交叉验证的结果评价模型的性能。为了确定所述每代中的优秀个体,需要定义一个适用度函数来评价个体的优劣程度;在医疗诊断中,最常见的评价指标是敏感性(sensitivity)和特异性(specificity),为了综合衡量两者的大小,本发明使用两者的调和均值score作为ga的适应度函数,敏感性、特异性和score的定义是如下式所示:其中,tn、tp、fn、fp分别表示真阴性、真阳性、假阴性、假阳性,是由混淆矩阵得出,在本示例中,阳性表示骨质疏松,阴性表示骨骼健康,混淆矩阵如下表2所示:表2模型分类的混淆矩阵所述的ga求解问题的三个关键步骤是选择、重组和变异。选择是将每一代中的优秀个体保留到下一代的方法;本实施例中使用的选择算子是轮盘赌,同时保留每代适应度函数值最高的个体进入下一代。重组是将优秀个体的染色体进行交叉重组,提升算法的搜索能力;本实施例中使用的重组算子是多点交叉算子,交叉概率为0.9。变异是随机改变染色体某一片段的编码,避免算法陷入局部最优解,提升种群的多样性;使用的变异算子是二进制变异算子,变异的概率为0.1。通过不断的迭代与进化,ga最终会选择出进化过程中的最优个体,该个体对应的可行解即为本实例的最优解,对应的模型即为本发明最终使用的模型。所述的十折交叉验证是机器学习中常用的一种避免模型过拟合的方法,该方法将训练集划分成样本量相等的十份,并依次选择其中的九份进行模型的训练,剩余的一份作为测试,重复十次,保证所有的样本都用于了一次且仅一次的测试;取十次测试的结果作为模型的评价。所述的模型的评价,除上述的敏感性、特异性和score外,还有准确率和roc分析。准确率(accuracy)的定义如下式所示:roc分析也是一种常用的评价指标,以假阳性率(falsepositiverate,fpr)为横轴,以真阳性率(truepositiverate,tpr)为纵轴,通过不断地降低分类阈值,描绘出一条曲线;为客观的评价roc的效果,以roc曲线的面积(areaundercurve,auc)来表示。真阳性率和假阳性率的定义式如下式所示:本实例通过上述步骤使用svm做分类器,实现对骨质疏松的分类;同时,为避免样本顺序对分类器的影响,将数据集随机打乱十次,即ga同时在十个数据集上运行,选取在十个数据集上平均分类性能最优的个体作为模型的最优解,分类结果如下表3所示,roc曲线如图4所示,其中1stlayer,rbe,ba,2ndlayer分别对应表3的第一层、血常规、生化全套、第二层。可以看出即使在仅使用个体信息时,模型的分类准确率即可达到75.65%;在加上实验室检查指标后,模型的性能得到了进一步的提升。表3不同输入参数对应的模型分类效果输入参数准确率scoreauccg第一层75.65%75.93%0.810.78200.7666血常规60.60%60.55%0.6494.91690.0232生化全套73.12%72.74%0.7725.70870.0211第二层78.28%78.55%0.8417.59530.0183同时,为了检验ga在筛选最优特征子集,降低特征输入维度方面的性能,表4显示了使用ga筛选最优特征子集与未使用ga筛选最优特征子集的对比效果,可以看出ga筛选特征后,模型的性能并未降低,而输入特征的数量大大降低,且特征维度越高,效果越明显。表4ga筛选特征对模型分类性能的影响本实例利用遗传算法优化svm实现对骨质疏松的分类,遗传算法启发式地寻找svm的最优超参数及最优特征子集,在不降低模型性能的前提下,减小了输入特征空间的维度,从而有利于减小模型的复杂度,提升模型的泛化能力。本实例采用患者的个体信息和实验室检查指标作为模型的输入,即展示了模型第一级和第二级的分类效果,结果表明模型对骨质疏松识别的准确率较高。在上述以个体信息和实验室检查指标为输入参数的基础上,进一步加入提取的腰椎ct图像特征,完善多模态骨质疏松分层预警模型的输入,实现对骨质疏松的准确识别。具体的实施步骤如下:1.获取研究对象的信息,包括个体信息、实验室检查指标、腰椎ct图像。所述研究对象的纳入标准和样本来源同上述示例相同,本示例共纳入样本119个。本示例进一步加入影像学数据,用以反映骨骼的形态;与健康骨骼相比,骨质疏松的骨骼会出现皮质骨变薄、骨小梁的结构遭到破坏,因此加入影像学数据有助于骨质疏松的识别。2.在ct图像上,手动分割腰椎椎体作为感兴趣区域(regionofinterests,rois),排除骨折的椎体。利用获取的平扫ct图像重建矢状位图像,所述被分割的ct图像选取的是重建矢状位图像最中间的一张。dxa骨密度检测的部位是腰椎l1-l4,故手动分割出l1-l4作为rois,其中骨折的锥体被排除在外;手动分割的锥体包括两种:只包含松质骨的椎体和既包含松质骨又包含皮质骨的锥体,分别用于提取图像的形状特征和纹理特征。将分割出的锥体图像的尺寸统一缩放为64×64。3.提取各个椎体的图像特征。所述的图像特征包括纹理特征和形状特征,其中纹理特征提取的是锥体的纹理分布,故分割的锥体既包含皮质骨又包含松质骨;形状特征提取的是骨小梁的形状,采用最大类间方差法(otsu)分割出骨小梁的形状,由于otsu对图像像素敏感,皮质骨的存在会影响分割结果,故形状特征在只包含松质骨的锥体上提取。在上述矢状位图像分割出多节未骨折腰椎椎体,取来源于同一张矢状位ct图像上的多节锥体的图像特征的均值和标准差作为最终的图像特征。纹理特征是基于三种方法提取:灰度共生矩阵、灰度梯度矩阵、灰度直方图,其中灰度共生矩阵对应的特征有能量、熵、对比度、逆差矩和相关性,灰度梯度矩阵对应的特征是均值、方差、偏态、峰度,灰度直方图对应的特征是均值、方差、歪斜度、峰态、能量、熵;灰度共生矩阵的步长调整为1个像素,并取四个方向上特征的均值和标准差作为最终的灰度共生矩阵的特征。形状特征包括周长、面积、区域致密度、体态比、圆形度、实心度、矩形度和7个hu不变矩;由于otsu在同一张图像上分割出的骨小梁包含多个部分,取各个部分的均值和标准差作为最终的形状特征。4.将上述提取的个体信息、实验室检查指标、ct图像特征进行处理,确定模型的输入特征。本示例共提取出142个特征,经统计学检验后,特征数由142降为45,各项目包含的特征数量如下表5所示。表5统计学差异检验前后特征数量的变化5.使用参数优化和特征选择的svm作为分类器,得到分类结果。参数优化和特征选择的过程如上述采用遗产算法同时进行超参数优化和各层最优输入特征选择的过程相同,此处不再累述。本示例使用的基于优化的svm分类器的分类效果如下表6所示,其中模型的第一层仅包含个体信息,第二层加入了实验室检查指标,第三层进一步加入了ct图像;模型的roc曲线如图5所示,其中1stlayer、2ndlayer、3rdlayer分别对应表6中的第一层、第二层和第三层。结果显示,通过不断的加入重要指标,模型的分类性能得到提升,且ct图像所反映的信息对骨质疏松的识别具有重要作用,能够达到dxa检测的效果。表6不同输入参数对应的模型分类效果本示例即展示了所提出的基于优化的支持向量机的骨质疏松分层预警模型的性能,通过挖掘体检数据中的有效信息,在不增加额外费用的条件下实现了对骨质疏松的识别,识别准确率高,且根据输入参数的多少构建了三层预警模型,能够实现对骨质疏松高危人群的筛查。实施例二本实施例提供了一种多模态骨质疏松分层预警系统,其包括:(1)输入特征接收模块,其用于接收三层输入特征,这三层输入特征分别为个体信息、实验室检查指标和腰椎ct图像特征。所述的个体信息包括年龄、性别、身高、体重、舒张压、收缩压、脉压、是否绝经。所述的实验室检查指标包括血常规和生化全套,其中血常规指标包括白细胞、中性粒细胞比率、中性粒细胞计数、淋巴细胞比率、淋巴细胞计数、单核细胞计数、单核细胞比率、红细胞、血红蛋白、红细胞压积、血小板计数、血小板压积、血沉;生化全套包括谷丙转氨酶、谷草转氨酶、谷氨酸脱氢酶、γ-谷丙酰基转肽酶、碱性磷酸酶、腺苷脱氨酶、总胆红素、直接胆红素、间接胆红素、前白蛋白、总蛋白、白蛋白、球蛋白、总胆固醇、高密度脂蛋白胆固醇、低密度脂蛋白胆固醇、甘油三酯、葡萄糖、尿素氮、肌酐、乳酸脱氢酶、钾、钠、氯、钙、磷、镁。图像特征包括纹理特征和形状特征,其中纹理特征提取的是锥体的纹理分布,故分割的锥体既包含皮质骨又包含松质骨;形状特征提取的是骨小梁的形状,采用最大类间方差法(otsu)分割出骨小梁的形状,由于otsu对图像像素敏感,皮质骨的存在会影响分割结果,故形状特征在只包含松质骨的锥体上提取。在上述矢状位图像分割出多节未骨折腰椎椎体,取来源于同一张矢状位ct图像上的多节锥体的图像特征的均值和标准差作为最终的图像特征。纹理特征是基于三种方法提取:灰度共生矩阵、灰度梯度矩阵、灰度直方图,其中灰度共生矩阵对应的特征有能量、熵、对比度、逆差矩和相关性,灰度梯度矩阵对应的特征是均值、方差、偏态、峰度,灰度直方图对应的特征是均值、方差、歪斜度、峰态、能量、熵;灰度共生矩阵的步长调整为1个像素,并取四个方向上特征的均值和标准差作为最终的灰度共生矩阵的特征。形状特征包括周长、面积、区域致密度、体态比、圆形度、实心度、矩形度和7个hu不变矩;由于otsu在同一张图像上分割出的骨小梁包含多个部分,取各个部分的均值和标准差作为最终的形状特征。(2)预处理模块,其用于对三层输入特征进行数据清洗、显著性与相关性检测及数据标准化预处理。具体地,对提取特征的处理主要包括缺失值和异常值处理,以及采用统计学方法选择在骨质疏松和骨骼健康的样本间有显著差异的特征;具体方法是分别采用曼-惠特尼u检验和卡方检验分别比较连续特征和类别特征在两组间的差异,采用pearson相关性检验检测连续特征间的相关性;显著性水平p=0.05,pearson相关系数|γ|=0.8;对类别特征进行onehot编码,避免对无序特征进行排序;对连续特征做标准化处理,将特征数据转化为标准正态分布。所述特征处理主要包括数据清洗和统计学分析。获取的数据除性别和是否绝经外均为连续特征,联合所述的两个特征,用0、1、2分别表示女性未绝经、女性绝经、男性,并因此剔除性别特征。数据清洗主要包括缺失值处理和异常值处理;对缺失比率超过20%的特征和具有缺失值的样本做删除处理;通过绘制特征的箱体图或散点图查看特征值的分布情况,将离群点视为异常值并做删除处理,以甘油三酯为例,如图2所示,有一样本的特征值极有可能为异常值,故删除该样本。采用统计学方法剔除在骨质疏松和骨骼健康间无显著差异及特征间高度相关的特征,从而降低输入特征的空间维度,降低模型过拟合的风险。(3)预警输出模块,其用于从预处理的三层输入特征中筛选出各层最优输入特征并形成输入特征集,经多模态骨质疏松分层预警模型,输出骨质疏松预警结果;其中,多模态骨质疏松分层预警模型是svm分类器,svm分类器的优化过程为:使用遗传算法同时进行超参数优化和各层最优输入特征选择。svm分类器的优化是使用遗传算法同时进行模型超参数优化和输入特征选择,根据模型的分类效果选择最优参数和特征子集;为处理非线性优化问题,引入核函数技巧;svm的分类标签根据dxa的检测结果标定。所述的svm的优化包括超参数优化和特征选择,优化方法选择遗传算法(geneticalgorithm,ga),ga的操作流程如图3所示。svm本质是线性分类器,引入核函数技巧,使得svm具备处理非线性问题的能力,本发明选用高斯核函数。svm需要优化的参数包括惩罚系数c和高斯核参数g,c、g值对模型的性能有很大影响;c越大,对误分类样本的惩罚越大,模型越容易过拟合,反之容易欠拟合;g越大,支持向量越少,模型越容易过拟合,反之容易欠拟合。本发明设定c的范围为[0,100],精度为0.1;g的范围为[0,10],精度为0.001。ga在优化c和g的同时,还要从输入特征中选取最具相关性的特征。为了确定所述每代中的优秀个体,需要定义一个适用度函数来评价个体的优劣程度;在医疗诊断中,最常见的评价指标是敏感性(sensitivity)和特异性(specificity),为了综合衡量两者的大小,本发明使用两者的调和均值score作为ga的适应度函数,敏感性、特异性和score的定义是如下式所示:其中,tn、tp、fn、fp分别表示真阴性、真阳性、假阴性、假阳性,是由混淆矩阵得出,在本示例中,阳性表示骨质疏松,阴性表示骨骼健康,混淆矩阵如下表所示:模型分类的混淆矩阵所述的ga求解问题的三个关键步骤是选择、重组和变异。选择是将每一代中的优秀个体保留到下一代的方法;本实施例中使用的选择算子是轮盘赌,同时保留每代适应度函数值最高的个体进入下一代。重组是将优秀个体的染色体进行交叉重组,提升算法的搜索能力;本实施例中使用的重组算子是多点交叉算子,交叉概率为0.9。变异是随机改变染色体某一片段的编码,避免算法陷入局部最优解,提升种群的多样性;使用的变异算子是二进制变异算子,变异的概率为0.1。通过不断的迭代与进化,ga最终会选择出进化过程中的最优个体,该个体对应的可行解即为本实例的最优解,对应的模型即为本发明最终使用的模型。所述的十折交叉验证是机器学习中常用的一种避免模型过拟合的方法,该方法将训练集划分成样本量相等的十份,并依次选择其中的九份进行模型的训练,剩余的一份作为测试,重复十次,保证所有的样本都用于了一次且仅一次的测试;取十次测试的结果作为模型的评价。所述的模型的评价,除上述的敏感性、特异性和score外,还有准确率和roc分析。准确率(accuracy)的定义如下式所示:roc分析也是一种常用的评价指标,以假阳性率(falsepositiverate,fpr)为横轴,以真阳性率(truepositiverate,tpr)为纵轴,通过不断地降低分类阈值,描绘出一条曲线;为客观的评价roc的效果,以roc曲线的面积(areaundercurve,auc)来表示。真阳性率和假阳性率的定义式如下式所示:实施例三本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述实施例一所述的多模态骨质疏松分层预警方法中的步骤。实施例四本实施例提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述实施例一所述的多模态骨质疏松分层预警方法中的步骤。本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(read-onlymemory,rom)或随机存储记忆体(randomaccessmemory,ram)等。以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1