一种使用Bert做疾病标准化映射分类的方法及系统与流程
本发明涉及自然语言处理技术领域,具体涉及一种使用bert做疾病标准化映射分类的方法及系统。
背景技术:
在医院的临床诊断中,医生根据病人情况给出疾病的诊断名称。由于地域、文化、习惯等差异,医生对疾病诊断名称的书写和录入并不规范,具有较大的随意性。而且各个医院因为医学研究和临床上的需求,编制了各自的疾病名称和编码体系,虽然我国也有统一的标准:“疾病诊断分类与代码”,但在很多实际应用场景下需要在不同标准之间进行映射。当前的处理方式多采用人工处理的方式,即由专业的医疗病案专家逐一确定疾病的标准名称,或者映射到其他标准。进而造成效率极低和带来的成本极高的缺陷。虽然现有技术中,也出现了一些计算机软件辅助工具,但也多是字符级的模糊匹配,准确率不高,对医疗病案专家的帮助有限,仍存在效率不高的缺陷。
技术实现要素:
本发明实施例的目的是提供一种使用bert做疾病标准化映射分类的方法及系统,以解决现有技术中,医疗病案专家处理时,仍存在效率不高的缺陷。
第一方面:本发明实施例提供了一种使用bert做疾病标准化映射分类的方法,所述方法包括:
对获取的原始疾病诊断数据进行标注,并将其映射到预设的疾病标准规范名称和分类上,以形成两个训练数据集;其中,所述原始疾病诊断数据包括疾病诊断名称和编码;
通过bert对所述两个训练数据集进行学习训练以得到两层训练模型;
通过所述两层训练模型分别对待处理的疾病诊断名称进行处理,以得到中间处理结果;
对所述中间处理结果进行排名处理,以得到最终排列的多个疾病标准名称。
作为本发明的一个优选的技术方案,所述方法还包括:
在学习训练前进行预处理,所述预处理具体包括:
去掉空值;
去掉空格;
去掉停用词;
对于编码与疾病诊断名称位置错乱的,调换编码与疾病诊断名称的位置。
作为本发明的一个优选的技术方案,对获取的原始疾病诊断数据进行标注,并将其映射到预设的疾病标准规范名称和分类上,以形成两个训练数据集,具体包括:
通过病案专家进行标注,将所述疾病诊断名称映射到国家疾病标准名称上,以形成所述疾病诊断名称映射到疾病标准名称的标准疾病名称训练数据集;
再根据所映射的国家疾病标准名称,基于疾病诊断分类与代码为每条原始疾病诊断数据进行标准化分类,以形成所述疾病诊断名称映射到疾病标准分类的标准疾病分类训练数据集。
作为本发明的一个优选的技术方案,通过bert对所述两个训练数据集进行学习训练以得到两层训练模型,具体包括:
使用bert针对所述标准疾病名称训练数据集进行学习训练,获得疾病名称模型;
使用bert针对所述标准疾病分类训练数据集进行学习训练,获得疾病分类模型。
作为本发明的一个优选的技术方案,通过所述两层训练模型分别对待处理的疾病诊断名称进行处理,以得到中间处理结果,具体包括:
通过所述疾病名称模型为待处理的疾病诊断名称进行分类计算,以获得该疾病诊断名称数据所映射的疾病标准名称,并选取概率排名前n个疾病标准名称;
通过所述疾病分类模型为待分类的疾病诊断名称进行分类,以获得该疾病诊断名称数据所映射的疾病标准分类,选取概率排名前m个疾病标准分类;
所述n个疾病标准名称和m个疾病标准分类即为所述中间处理结果。
作为本发明的一个优选的技术方案,对所述中间处理结果进行排名处理,以得到最终排列的多个疾病标准名称,具体包括:
对n个疾病标准名称中的各元素计算其疾病名称权重值;
对m个疾病标准分类中的各元素计算其疾病分类权重值;
再根据所述疾病名称权重值和疾病分类权重值计算n个疾病标准名称中各元素的二次权重,并根据所述二次权重的大小进行排序,以得到所述最终排列。
作为本发明的一个优选的技术方案,所述方法还包括:
接收并展示所述最终排列的多个疾病标准名称。
第二方面:本发明实施例提供了一种使用bert做疾病标准化映射分类的系统,所述系统包括:
数据预处理模块,用于对获取的原始疾病诊断数据进行标注,并将其映射到预设的疾病标准规范名称和分类上,以形成两个训练数据集;其中,所述原始疾病诊断数据包括疾病诊断名称和编码;
bert训练学习模块,用于通过bert对所述两个训练数据集进行学习训练以得到两层训练模型;
数据分类模块,用于通过所述两层训练模型分别对待处理的疾病诊断名称进行处理,以得到中间处理结果;
分类结果重排模块,用于对所述中间处理结果进行排名处理,以得到最终排列的多个疾病标准名称;
用户界面模块,用于接收并展示所述最终排列的多个疾病标准名称。
作为本发明的一个优选的技术方案,所述数据预处理模块,还用于在学习训练前进行预处理,所述预处理具体包括:
去掉空值;
去掉空格;
去掉停用词;
对于编码与疾病诊断名称位置错乱的,调换编码与疾病诊断名称的位置。
采用上述技术方案,具有以下优点:本发明提出的一种使用bert做疾病标准化映射分类的方法及系统,通过形成的训练数据集为模型训练提供了可行性,能够对疾病诊断数据做标准化映射,使得医疗病案专家在对医院的疾病诊断名称做标准化映射时,可提高处理效率,同时对待处理的疾病诊断名称进行双重处理,也相应提高了最终映射的准确度。
附图说明
图1为本发明实施例提供的一种使用bert做疾病标准化映射分类的方法流程图;
图2为本发明实施例提供的一种疾病诊断分类的分层结构示意图;
图3为本发明实施例提供的一种使用bert做疾病标准化映射分类的系统结构图。
具体实施方式
为了使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述,以下实施例用于说明本发明,但不用来限制本发明的范围。
参考图1至图2所示,本发明实施例提供的一种使用bert做疾病标准化映射分类的方法,所述方法包括:
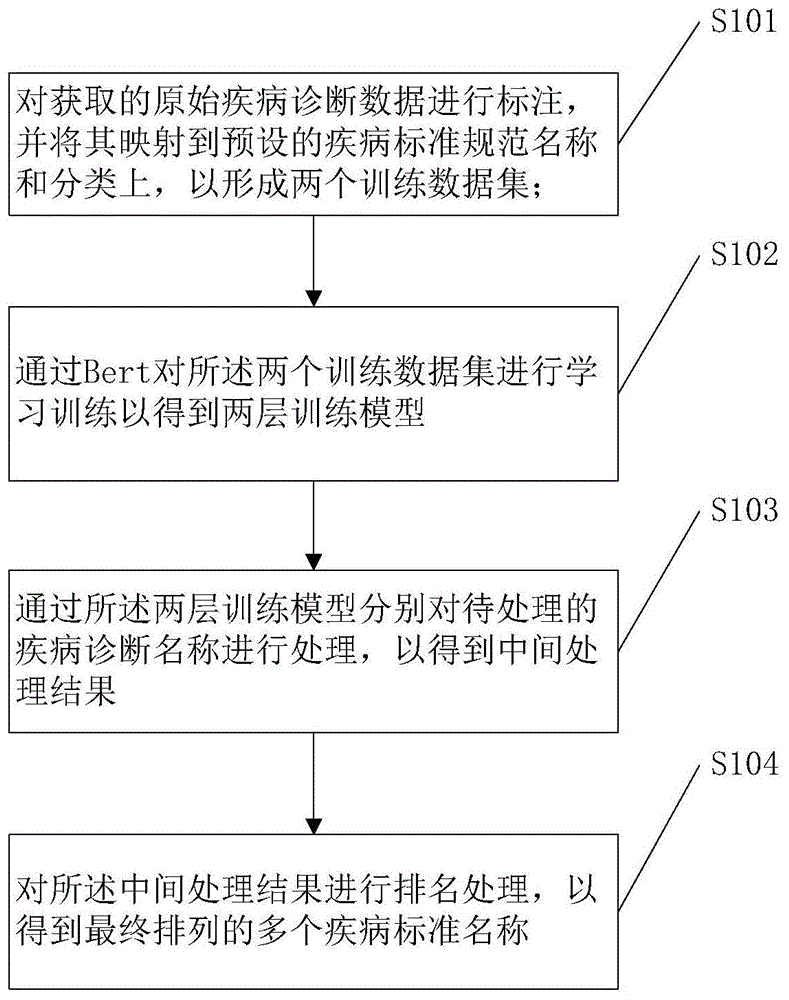
s101,对获取的原始疾病诊断数据进行标注,并将其映射到预设的疾病标准规范名称和分类上,以形成两个训练数据集;其中,所述原始疾病诊断数据包括疾病诊断名称和编码。
具体地,从医院收集原始疾病诊断数据,由病案专家人工进行标注,数据格式例如:“i49.200房室交界性逸搏”。所提供的数据存储在excel格式的表格中,由病案专家人工进行标注,映射到国家疾病标准名称和编码上,例如前述“i49.200房室交界性逸搏”由专家判断映射为“i49.403结性逸搏”,并填写在excel表格中,形成疾病诊断名称映射到疾病标准名称的“标准疾病名称”训练数据集,excel表格中有四列:诊断疾病编码,诊断疾病名称,标准疾病编码,标准疾病名称;
同时,根据所映射的国家疾病标准名称,通过python程序,基于“疾病诊断分类与代码国家临时版本1.1”为每条疾病语料标注疾病的“分类”。“疾病诊断分类与代码国家临时版本1.1”共分四个层级:“分类”、“类目”、“亚目”、“疾病”。可参照图2所示;“分类”共有311种,“疾病”共有34969种;
例如前文所述的例子“i49.200房室交界性逸搏”映射的病标准名称为“i49.403结性逸搏”,其所属的疾病“分类”为“i30-i52其他类型的心脏病”。(标准化疾病分类共计311种)形成疾病诊断名称映射到疾病标准分类的“标准疾病分类”训练数据集,可存储在单独的一个excel表格中,excel表格中有四列:诊断疾病编码,诊断疾病名称,标准疾病分类编码,标准疾病分类名称;其中,python程序中所用到的库包括pandas和numpy。
所述“标准疾病名称”训练数据集和“标准疾病分类”训练数据集即为形成的两个训练数据集。
应用时,为了后期更好的训练效果,所述方法还包括:
在学习训练前进行预处理;可对原始疾病诊断数据和映射得到的国家疾病标准数据进行预处理,具体为:
去除掉excel表格中诊断疾病名称数据中的空值,删除掉空格,并根据特殊字符停用词表去除特殊字符;对于编码与名称错位的情况作出判断,如果诊断名称单元格中检测不到中文字符,而诊断编码单元格中存在中文字符,则对编码和名称的位置做调换,预处理完成后,生成新的excel数据表格;其中,在数据预处理中还使用sklearn包用于切分数据集、打乱数据集和复制数据等处理,使用pickle包,对目标列进行序列化生成数据字典,提高数据类别的检索效率。
s102,通过bert对所述两个训练数据集进行学习训练以得到两层训练模型。
具体地,通过前文描述可知,所述两个训练数据集包括包括标准疾病名称训练数据集和标准疾病分类训练数据集,bert是自然语言处理中的一种技术,bert是经过预训练的transformer,预训练中使用了“语言遮蔽”和“下句预测”技术,所以在多项自然语言处理任务中取得了极好的效果;
使用bert-basechinese预训练模型,针对标注的“标准疾病名称”数据训练集进行学习训练,获得“疾病名称模型”;
使用bert-basechinese预训练模型,使用bert针对标注的“标准疾病分类”数据训练集进行学习训练,获得“疾病分类模型”。
s103,通过所述两层训练模型分别对待处理的疾病诊断名称进行处理,以得到中间处理结果。
具体地,通过前文描述可知,所述两层训练模型包括疾病名称模型和疾病分类模型,即形成一个二层模型,在这个二层模型中,由于每一种“疾病名称”一定属于唯一一种“分类”,“分类”是包含“疾病名称”的更大的概念,因此,可以理解疾病名称模型为小分类模型,疾病分类模型为大分类模型;
使用生成的“疾病名称模型”为待分类的一条疾病诊断名称进行分类,以获得该疾病诊断名称数据所映射的疾病标准名称,可选取概率排名前10的疾病标准名称;
同样的,使用生成的“疾病分类模型”为待分类的疾病诊断名称进行分类,以获得该疾病诊断名称数据所映射的疾病标准分类,可选取概率排名前10的疾病标准分类;需要说明的是,这里的个数只是举例说明,并不是对其进行限制。
s104,对所述中间处理结果进行排名处理,以得到最终排列的多个疾病标准名称。
具体地,对n个疾病标准名称中的各元素计算其疾病名称权重值;
对m个疾病标准分类中的各元素计算其疾病分类权重值;
再根据所述疾病名称权重值和疾病分类权重值计算n个疾病标准名称中各元素的二次权重,并根据所述二次权重的大小进行排序,以得到所述最终排列;
应用时,根据前文所述,n与m均取10,更为细致的步骤为:
使用大分类模型“疾病分类模型”预测获得的“疾病分类”值为集合c={c1.......c10},其中ci是一个子集合,其中包含了多个“疾病名称”元素;
使用小分类模型“疾病名称模型”预测的“疾病名称”为集合d={d1......d10},其中di是一个元素,代表一个“疾病名称”。任何一个di“疾病名称”必须唯一属于一个“疾病分类”,可从“疾病诊断分类与代码国家临时版本1.1”中查找到di对应的“疾病分类”;
为c中的每个元素计算“分类权重值”:
为d中的每个元素计算“疾病权重值”:
再为d计算每个元素的二次权重
其中,i、x的取值范围为1至10,
如果di所属“分类”不在c中,则该di的“分类权重值”
计算完成后,再根据
应用时,一种更简单的重排方法为,可只选取概率排名前3的疾病标准分类,假设为cj,j=0-2;
重新排序后标准疾病名称的前3假设为ro,o=0-2;
针对c0按照i的大小顺序检索di中是否存在d∈c0,如果有,则按i顺序取前3,构成集合即为ro;如果d∈c0的数量不足3个,则针对c1按照i的大小顺序检索di中是否存在d∈c1,按i顺序取d的值与d∈c0的值合并,且总数为3,三个di的值为最终结果;如果总数不足3,则针对c2按照i的大小顺序检索di中是否存在d∈c2,按i顺序取d的值与d∈c0和d∈c1的值合并,且总数达到3,三个di的值为最终结果;如果总数不足3,则按i顺序取di,与d∈c0和d∈c1和d∈c2的值合并,取总数为3,三个di的值为最终结果ro。
最后,在基于django框架开发的web交互页面上展现生成的3个结果,推荐给医疗病案专家,供其选择正确的疾病名称,此步骤还使用fastapi提供接口,为web用户界面提供数据。
通过bert预训练为小样本下模型训练提供了可行性,对诊断疾病名称数据的标准化映射自动化,起到了很好的效果,一条命中准确率可达到91%;
二层模型进一步解决了“疾病”条目过多,单条条目下可用训练的标注语料过少的问题,结合“二层模型分类结果重排机制”三条命中准确率可达到97%。
通过上述方案,通过形成的两个训练数据集为形成两层模型训练提供了可行性,能够对疾病诊断数据做疾病名称和疾病分类的两层标准化映射,使得医疗病案专家在对医院的疾病诊断名称做标准化映射时,可提高处理效率,同时对待处理的疾病诊断名称进行分层预测处理,并通过重排机制对预测结果进行排序,也相应提高了最终映射的准确度。
参考图3,基于上述同样的发明构思,本发明实施例还提供了一种使用bert做疾病标准化映射分类的系统,所述系统包括:
数据预处理模块,用于对获取的原始疾病诊断数据进行标注,并将其映射到预设的疾病标准规范名称和分类上,以形成两个训练数据集;其中,所述原始疾病诊断数据包括疾病诊断名称和编码。
具体地,通过病案专家进行标注,将所述疾病诊断名称映射到国家疾病标准名称上,以形成所述疾病诊断名称映射到疾病标准名称的标准疾病名称训练数据集;
再根据所映射的国家疾病标准名称,基于疾病诊断分类与代码为每条原始疾病诊断数据进行标准化分类,以形成所述疾病诊断名称映射到疾病标准分类的标准疾病分类训练数据集。
bert训练学习模块,用于通过bert对所述两个训练数据集进行学习训练以得到两层训练模型。
具体地,使用bert-basechinese预训练模型,针对标注的“标准疾病名称”数据训练集进行学习训练,获得“疾病名称模型”;
使用bert-basechinese预训练模型,使用bert针对标注的“标准疾病分类”数据训练集进行学习训练,获得“疾病分类模型”。
数据分类模块,用于通过所述两层训练模型分别对待处理的疾病诊断名称进行处理,以得到中间处理结果。
具体地,通过所述疾病名称模型为待处理的疾病诊断名称进行分类计算,以获得该疾病诊断名称数据所映射的疾病标准名称,并选取概率排名前n个疾病标准名称;
通过所述疾病分类模型为待分类的疾病诊断名称进行分类,以获得该疾病诊断名称数据所映射的疾病标准分类,选取概率排名前m个疾病标准分类;
所述n个疾病标准名称和m个疾病标准分类即为所述中间处理结果。
分类结果重排模块,用于对所述中间处理结果进行排名处理,以得到最终排列的多个疾病标准名称;
具体地,对n个疾病标准名称中的各元素计算其疾病名称权重值;
对m个疾病标准分类中的各元素计算其疾病分类权重值;
再根据所述疾病名称权重值和疾病分类权重值计算n个疾病标准名称中各元素的二次权重,并根据所述二次权重的大小进行排序,以得到所述最终排列;其细致的处理步骤,参见前文所述,在此不再赘述。
用户界面模块,用于接收并展示所述最终排列的多个疾病标准名称。
具体地,基于django框架开发的web交互页面,用于接收需要分类的疾病诊断名称数据,并传递到数据分类模块,最终接收从分类结果重排模块生成的n个疾病标准名称结果,并展现在web页面上。
进一步的,所述数据预处理模块,还用于在学习训练前进行预处理,所述预处理具体包括:
去掉空值;
去掉空格;
去掉停用词;
对于编码与疾病诊断名称位置错乱的,调换编码与疾病诊断名称的位置。
需要说明的是,上述各模块中,相关的具体实施方式可参见前文所述,在此不再重复描述;本系统使用python语言开发,其训练和预测基于pytorch框架下实现,其web使用django框架。
上述系统的应用,将门诊提供的疾病诊断名称数据映射到标准化疾病名称和编码上,提供可能性最高的多条标准化名称和编码,推荐给病案专家,供病案专家甄选,解决了纯手工作业的低效问题和计算机辅助工具准确率不高,只能起到有限帮助的缺陷。在将bert技术应用到疾病标准化映射和推荐中,解决了标准化“疾病”类目过多,针对每一种“疾病”类目的训练数据过少的问题。
在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体地”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。
最后需要说明的是,以上描述仅为本申请的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本申请中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离本申请构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。
- 还没有人留言评论。精彩留言会获得点赞!