基于注意力机制的微生物与疾病关联关系预测方法及系统与流程
本申请涉及生物学技术领域,特别是涉及基于注意力机制的微生物与疾病关联关系预测方法及系统。
背景技术:
本部分的陈述仅仅是提到了与本申请相关的背景技术,并不必然构成现有技术。
人类生活在充满细菌,真菌和病毒等微生物的环境中,人体是这些微生物的主要栖息地之一,虽然很难感觉到这些小生物的存在,但它们无处不在。众所周知,成千上万的微生物寄居于人体口腔、肠道、皮肤、子宫、肺等器官中。据估计,人体中微生物总数为1014,是人体细胞数量的十倍。它们在人类健康,新陈代谢,免疫防御,营养吸收,癌症控制和病原菌定植保护中发挥重要作用。大量的实验结果表明,许多疾病与微生物菌群的变化有关。例如,来自啮齿动物模型和人体研究的证据表明,肠道微生物的组成对免疫系统有重要影响,并可能影响t1d风险。与健康组相比,哮喘患者中富集细菌的含量要高得多。还有一些证据表明,在大肠癌患者中检测到的卵磷脂酶阴性梭状芽胞杆菌和乳杆菌更为丰富。越来越多的临床研究揭示了微生物与人类疾病之间存在着关联关系。伴随人工智能、机器学习和数据挖掘理论的发展,利用计算方法预测潜在的人类微生物—疾病关联关系亟需研究。
发明人发现,传统的微生物研究方法的局限导致人类对寄居在体内的95%的微生物所知甚少,使用传统的湿实验方法来鉴定微生物-疾病关联昂贵且费时。仅采用hmdad这一个数据库的关联信息来描述疾病信息和微生物信息,在预测关联关系时,仅这些信息是远远不够的,然而目前的研究远远无法满足需求,因此亟需补充其他信息,完善疾病-微生物关联关系,补充额外的微生物、疾病信息。
技术实现要素:
为了解决现有技术的不足,本申请提供了基于注意力机制的微生物与疾病关联关系预测方法及系统;利用疾病-表型信息来刻画疾病,引入微生物的go信息、基因信息来丰富微生物的描述,提升模型构建的精准性。
第一方面,本申请提供了基于注意力机制的微生物与疾病关联关系预测方法;
基于注意力机制的微生物与疾病关联关系预测方法,包括:
获取疾病多源信息;对疾病多源信息进行处理,得到若干种疾病表示向量;对若干种疾病表示向量进行融合,得到最终的疾病表示向量;
获取微生物多源信息;对微生物多源信息进行处理,得到若干种微生物表示向量;对若干种微生物表示向量进行融合,得到最终的微生物表示向量;
计算最终的疾病表示向量与最终的微生物表示向量二者之间的关联度,当关联度大于设定阈值,则表示微生物与疾病之间存在关联关系,否则表示二者之间不存在关联关系。
第二方面,本申请提供了基于注意力机制的微生物与疾病关联关系预测系统;
基于注意力机制的微生物与疾病关联关系预测系统,包括:
疾病向量表示模块,其被配置为:获取疾病多源信息;对疾病多源信息进行处理,得到若干种疾病表示向量;对若干种疾病表示向量进行融合,得到最终的疾病表示向量;
微生物向量表示模块,其被配置为:获取微生物多源信息;对微生物多源信息进行处理,得到若干种微生物表示向量;对若干种微生物表示向量进行融合,得到最终的微生物表示向量;
关联关系预测模块,其被配置为:计算最终的疾病表示向量与最终的微生物表示向量二者之间的关联度,当关联度大于设定阈值,则表示微生物与疾病之间存在关联关系,否则表示二者之间不存在关联关系。
第三方面,本申请还提供了一种电子设备,包括:一个或多个处理器、一个或多个存储器、以及一个或多个计算机程序;其中,处理器与存储器连接,上述一个或多个计算机程序被存储在存储器中,当电子设备运行时,该处理器执行该存储器存储的一个或多个计算机程序,以使电子设备执行上述第一方面所述的方法。
第四方面,本申请还提供了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成第一方面所述的方法。
第五方面,本申请还提供了一种计算机程序(产品),包括计算机程序,所述计算机程序当在一个或多个处理器上运行的时候用于实现前述第一方面任意一项的方法。
与现有技术相比,本申请的有益效果是:
本申请立足于利用数据挖掘方法挖掘疾病-微生物的新型关联关系,设计一套完整的疾病信息微生物菌群信息挖掘以及之间关联关系预测系统,供广大研究者使用。该发明的实施将为疾病菌群研究奠定理论和工具基础,将对疾病的早发现早治疗、个性化用药、新药的研制提供助力。
引入元路径随机游走获得疾病和微生物的多源信息表示,并利用注意力机制,实现了多源数据融合多方面信息预测微生物—疾病的关联关系。
引入元路径随机游走获取不同异构网络的疾病表示,实现了基于不同疾病数据源的疾病信息提取,特别适用于异构网络信息的提取;引入元路径随机游走获取不同异构网络的微生物表示,实现了基于不同微生物数据源的微生物信息提取,特别适用于异构网络信息的提取;采用了基于注意力机制的关联预测方法,有效地衡量了不同数据源的信息比重,并可构建有效的微生物-疾病关联预测模型。
本申请附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本申请的实践了解到。
附图说明
构成本申请的一部分的说明书附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。
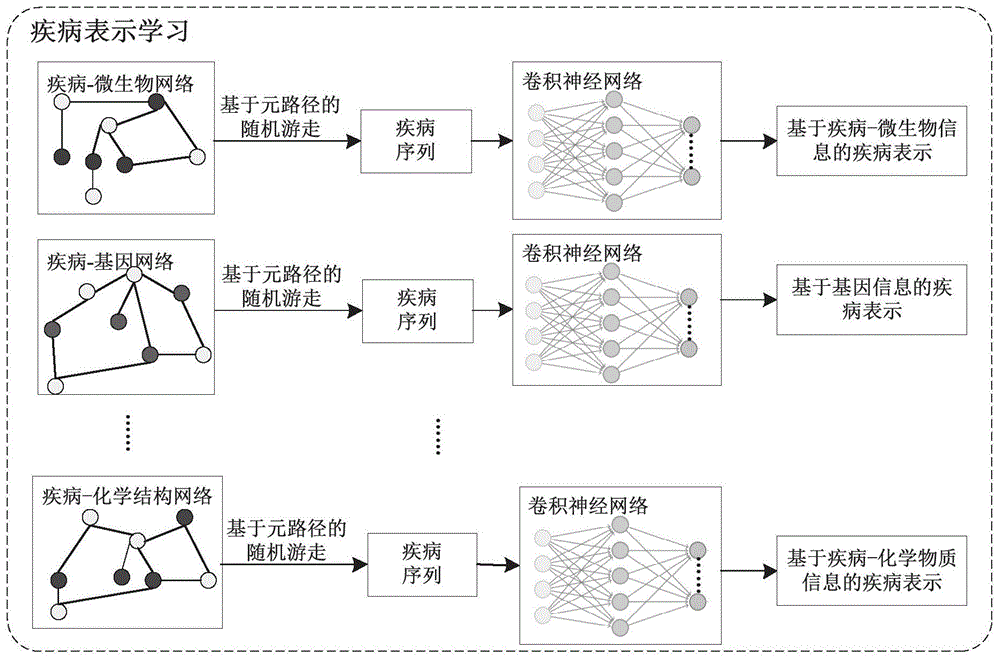
图1为第一个实施例的疾病表示学习方法流程图;
图2为第一个实施例的微生物表示学习方法;
图3为第一个实施例的skip-gram模型结构;
图4为第一个实施例的基于注意力机制的疾病多源信息融合方法;
图5为第一个实施例的基于注意力机制的微生物多源信息融合方法。
具体实施方式
应该指出,以下详细说明都是示例性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
实施例一
本实施例提供了基于注意力机制的微生物与疾病关联关系预测方法;
基于注意力机制的微生物与疾病关联关系预测方法,包括:
s101:获取疾病多源信息;对疾病多源信息进行处理,得到若干种疾病表示向量;对若干种疾病表示向量进行融合,得到最终的疾病表示向量;
s102:获取微生物多源信息;对微生物多源信息进行处理,得到若干种微生物表示向量;对若干种微生物表示向量进行融合,得到最终的微生物表示向量;
s103:计算最终的疾病表示向量与最终的微生物表示向量二者之间的关联度,当关联度大于设定阈值,则表示微生物与疾病之间存在关联关系,否则表示二者之间不存在关联关系。
作为一个或多个实施例,所述s101:获取疾病多源信息,具体疾病多源信息,包括:
获取疾病与症状信息、疾病与基因信息、疾病与化学物信息和疾病与蛋白信息。
示例性的,获取疾病多源信息,具体为:引入disease-microbe、disease-symptom、disease-gene、disease-chemical和disease-protein的相关信息。其中,disease-symptom描述了各疾病的症状信息;disease-gene描述了致病基因相关的信息,disease-protein可以从基因层面刻画疾病的特征,因为蛋白质是人体在分子水平上的基本功能单元,从人类蛋白质的角度来研究疾病之间的关系是一种直接的方法。鉴于疾病不仅与遗传有关,还与环境的化学物质有关,在进行疾病的描述时,引入disease-chemical疾病和化学物质的关系。所有的信息均取自开放的数据库,具体为:disease-microbe信息取自hmdad数据库,disease-symptom取自humandiseasenetwork(hsdn)数据库,其他信息计划从thecomparativetoxicogenomicsdatabase获取。
作为一个或多个实施例,如图1所示,所述s101:对疾病多源信息进行处理,得到若干种疾病表示向量;具体步骤包括:
将疾病与症状关联信息描述为疾病与症状关联信息网络;采用随机游走算法对疾病与症状关联信息网络处理,得到第一疾病信息;第一疾病信息输入到卷积神经网络中得到第一疾病表示向量;
将疾病与基因关联信息描述为疾病与基因关联信息网络;采用随机游走算法对疾病与基因关联信息网络处理,得到第二疾病信息;第二疾病信息输入到卷积神经网络中得到第二疾病表示向量;
将疾病与化学物关联信息描述为疾病与化学物关联信息网络;采用随机游走算法对疾病与化学物关联信息网络处理,得到第三疾病信息;第三疾病信息输入到卷积神经网络中得到第三疾病表示向量;
将疾病与蛋白关联信息描述为疾病与蛋白关联信息网络;采用随机游走算法对疾病与蛋白关联信息网络处理,得到第四疾病信息;第四疾病信息输入到卷积神经网络中得到第四疾病表示向量。
示例性的,以上每个相互作用的关联关系,其实可以看作是一个异构网络。为获得每个网络中的疾病的相关信息。采用元路径的随机游走序列来获得疾病的相关信息。从特定的疾病节点为种子节点,设定游走深度,利用随机游走算法,获得此疾病的序列。鉴于疾病会存在多条路径,则需要将多条路径信息拼接起来如式(1)所示
其中,
其他相关网络也采用相同方法,分别获得
例如,在疾病-微生物网络中,采用如下方式获得疾病的表示:步行者可以分别走进疾病网络和微生物网络,通过疾病-微生物网络跳转到其他网络。因此,在每个步骤,可以计算到达节点的概率。在(s+1)个步骤中,概率为
其中
从微生物到微生物的转移概率sm′为:
sm′(i,j)表示从微生物mi到mj的转移概率,λ∈(0,1)表示步行者以概率(1-λ)停留在微生物网络中。
表示从微生物网络到疾病网络的转变概率的md'定义为:
其中,
表示从疾病网络到微生物网络的转变概率的dm'定义为:
其中,
dm′(i,j)表示表示从疾病di到微生物mj的转变概率,ξ∈(0,1)表示从疾病跳到微生物网络的概率。
sd'表示从疾病到疾病的转变概率,定义为:
其中,
sd′(i,j)表示从疾病di到疾病dj的转移概率,(1-ξ)表示停留在疾病网络中的概率。
转移概率的坟墓为0时,则该转移概率设置为0。向量ps和向量ps+1之间的距离逐渐变小,直至小于1e-10。最后我们得到一个静态的概率分布,它表示从种子节点到每个节点的概率。
为确定参数λ,γ,η和ξ四个参数。本申请采用粒子群算法得到最优参数。在粒子群算法中,解决方案被认为是一种叫做粒子的鸟,在四维空间中搜索所有粒子,其值在0和1之间。通过适应度函数评估所有粒子(参数值)以判断当前解是否良好。考虑到准确度和高auc,适应度函数f(xi)定义为:
f(xi)=nactual-npredicted(xi),
其中,nactual=450表示实际病微生物的关联数,npredicted(xi)表示xi=[λi,γi,ηi,ξi]t测试中使f(xi)最小的前十组数值。
在粒子群算法中,每个粒子都具有位置和速度,根据粒子i的位置xi和速度vi的迭代更新公式为
vi=w*vi+c1*r1*(pbi-xi)+c2*r2*(gb-xi),
xi=xi+vi,
其中,vi第i个粒子的速度,w表示速度变化权重,c1和c2表示学习过程中的两个正常数,pbi表示前i步的最佳参数值,gb表示全局最佳粒子xi表示第i个粒子。为了避免局部最优解,我们允许粒子以一定的概率变异,即它们有时可以重置它们的位置,直到满足收敛标准。在满足收敛准则后,我们得到全局最佳粒子作为最优参数。
由此可以产生疾病i在微生物网络中获得的表示。同理可获得疾病在其他网络中的表示。
作为一个或多个实施例,如图4所示,所述s101:对若干种疾病表示向量进行融合,得到最终的疾病表示向量;具体步骤包括:
采用注意力机制,将第一、第二、第三和第四疾病表示向量进行融合,得到最终的疾病表示向量。
示例性的,根据前述疾病的表示学习方法,将获取到疾病不同信息源下的表示向量。接下来需要融合微生物不同来源的表示向量。鉴于不同来源的表示向量对疾病的影响和描述作用也是不一样的,例如基于症状的疾病信息描述的更多的是疾病发作时的表征。为有效地区分并体现不同表示向量或不同数据源的重要性,本申请采用机器学习目前广泛应用的注意力机制。由于注意力机制能够给模型赋予区分重要性的能力,具有赋予权重的能力,其已成功于机器翻译、语音识别、图像标注等很多领域,如,在语音识别中,注意力机制可为句子中的每个词赋予不同的权重,从而获得更为有效的模型。因此,本申请选择注意力机制来融合前面得到的各信息源的信息。
下面详细说明注意力机制在本模型中的具体应用:给定疾病在某个网络的表示,使用多层感知机来计算注意力分数,例如疾病在基因网络的注意力分数根据式(2)计算。
其中,
每个网络的隐向量的最终注意力权重是通过使用将上述注意力分数依据式(3)标准化来获得的。该值可以理解为不同网络对全局隐向量的贡献的大小。
获得疾病的所有信息源的隐向量的所有注意力权重wia后,可根据式(4)计算疾病的全局隐向量di
作为一个或多个实施例,所述s102:获取微生物多源信息;具体步骤包括:
获取微生物与疾病的已知关联信息、微生物与宿主的关联信息和微生物基因序列信息。
示例性的,所述s102:获取微生物多源信息;具体步骤包括:
对于微生物的信息提取,采用多源信息刻画微生物。其中,microbe-disease信息取自hmdad数据,描述了菌群失衡导致的相关疾病的信息;microbe-host描述了微生物和宿主之间的关系;微生物的基因序列信息描述微生物菌群的dna信息。microbe-disease信息取自hmdad数据库,microbe-host信息计划从thecomparativetoxicogenomicsdatabase获取,微生物的基因序列信息将从ncbi网站获取。
作为一个或多个实施例,如图2所示,所述s102:对微生物多源信息进行处理,得到若干种微生物表示向量;具体步骤包括:
将微生物与疾病的已知关联信息描述为微生物与疾病的关联网络;采用随机游走算法对微生物与疾病的关联网络进行处理,得到微生物与疾病的随机游走序列;将微生物与疾病的随机游走序列输入到卷积神经网络中,得到第一微生物表示向量;
将微生物与宿主的关联信息描述为微生物与宿主的关联网络;采用随机游走算法对微生物与宿主的关联网络进行处理,得到微生物与宿主的随机游走序列;将微生物与宿主的随机游走序列输入到卷积神经网络中,得到第二微生物表示向量;
将微生物基因序列信息,采用wordvec模型进行处理得到k-ner的嵌入向量,将k-ner的嵌入向量输入到卷积神经网络中,得到第三微生物表示向量。
示例性的,对于微生物序列的获得可采用式(1)的方法分别获得
对于微生物的基因信息,本申请采用基因序列信息进行特征提取。鉴于word2vec工具计算可以单词的矢量表示,已广泛应用于许多自然语言处理任务以及其他研究应用中,并且其可以反映单词在序列中的位置关系并保留结构信息,所以本申请采用word2vec进行微生物基因信息的提取。首先将基因序列划分为k-mers,然后将k-mers视为单词。使用word2vec,获得每个k-mer的嵌入向量。
word2vec中提供了两种学习算法:连续词袋和skip-gram。这些算法学习单词表示法以帮助预测句子中的其他单词。word2vec中的skip-gram模型基于给定的语料库训练每个单词的单词向量。给定句子中的一个单词(单词w(t)),skip-gram可以根据以下公式预测附近单词wi(t-k≤i≤t+k)的概率为p(w(t+i)|w(t))当前单词w(t)的概率。每个单词向量都反映附近单词的位置。
skip-gram模型(图3)的目标是最大化以下值:
其中,k表示窗口的大小,w(t+i)(-k≤i≤k)表示当前单词w(t)附近的k个单词,n表示单词数。
由以上训练过程可得各k-mer得嵌入向量,对于需要提取特征的具体微生物菌群,首先将其基因序列分割为k-mer,并补足到固定长度,然后利用前期训练得到的嵌入向量,送入到后续的卷积神经网络进行特征映射。
为提取特征,采用一组卷积过滤器来处理随机游走获得的微生物序列。卷积核大小为(c*100)。使用三种类型的卷积滤波器,大小分别为3、4和5。所有内核在整个表示向量上执行卷积。
例如,使用一个大小为(c*100)的卷积内核,特征图的构造如下:
其中,f(m)表示特征图的第m个元素,relu表示整流线性单位激活函数,w(i,j)表示通过训练编译的卷积核的权重,c表示滤波器的大小,
relu用于将卷积计算的负结果设置为零,其定义为:
每种过滤器类型均使用多个过滤器。令nc为卷积过滤器的数量,应用
为减少特征图的空间尺寸,在卷积运算之后采用最大池化。函数定义一个最大池化层,其合并窗口的大小为2×1,步幅为2;
其中,
最终结果合并在一起:
fam=[zc1,zc2,zc3],(12)
其中,c1=3,c2=4和c3=5表示使用的三种滤波器大小。然后,fam由完全连接的隐藏层处理以产生
由此可以产生微生物j在疾病网络中获得的表示:
同理可获得其他网络中的表示。
作为一个或多个实施例,如图5所示,所述s102:对若干种微生物表示向量进行融合,得到最终的微生物表示向量;具体步骤包括:
基于注意力机制,将第一、第二和第三微生物表示向量进行融合,得到最终的微生物表示向量。
示例性的,根据前述微生物获得的基于网络和基因序列的表示学习方法,将分别的到微生物的不同信息源下的表示向量。接下来为融合微生物不同来源的表示向量,同样选择注意力机制层来为不同的信息源赋予不同的权重。鉴于注意力机制能够给模型赋予区分重要性的能力,具有赋予权重的能力,因此设计了注意力机制层融合前述不同信息获得疾病的表示(图5)。
下面详细说明注意力机制在本模型中的具体应用:给定微生物在各个网络的隐向量,使用多层感知机根据式(13)来计算注意力分数。例如微生物根据疾病-微生物网络所获信息的注意力分数根据式(13)计算。
其中,
每个网络的隐向量的最终注意力权重是通过使用将上述注意力分数依据式(14)标准化来获得的。该值可以理解为不同网络对全局隐向量的贡献的大小。
获得微生物的所有信息源的隐向量的所有注意力权重
作为一个或多个实施例,所述s103:计算最终的疾病表示向量与最终的微生物表示向量二者之间的关联度;具体步骤包括:
基于sigmoid函数,计算最终的疾病表示向量与最终的微生物表示向量二者之间的关联度。
基于元路径随机游走的疾病表示学习。为解决疾病信息相对较少的问题,引入疾病-症状信息、疾病-基因信息、疾病-化学物信息和疾病-蛋白信息,从不同的层面刻画疾病信息。众多信息中的相互作用描述为不同的网络,网络中存在不同的节点和关系,采用随机游走算法获得在不同网络中疾病的信息,然后采用卷积神经网络获得疾病表示。
基于元路径随机游走的微生物表示学习。对于微生物菌群的相关信息,主要采用微生物-疾病的关联信息和微生物-宿主的信息构建异构网络。然后采用随机游走算法获得微生物在不同网络中随机游走的序列。同时,对于微生物的刻画,本申请引入微生物基因序列信息。对于基因序列信息,采用目前在自然语言处理中广泛应用的word2vec模型训练基因k-mer的嵌入向量。基于此向量获得特定微生物序列的嵌入向量表达。针对上述获得的基于网络的信息和基于基因序列的信息,后续都将采用卷积神经网络得到微生物的表示。
对上述获得的疾病信息和微生物信息,采用基于注意力机制的信息融合端到端的关联关系预测模型构建;根据前述疾病的表示学习方法,将分别获取到疾病的不同信息源下的表示向量。接下来需要融合疾病不同来源的表示向量。鉴于不同来源的信息对疾病的影响和描述作用也是不一样的,例如基于症状的疾病信息描述的更多的是疾病发作时的表征。为有效地区分并体现不同表示向量或不同数据源的重要性,本申请采用机器学习目前广泛应用的注意力机制。由于注意力机制能够给模型赋予区分重要性的能力,具有赋予权重的能力,因此设计了注意力机制层融合前述不同信息获得疾病的表示。
根据前述方法可获得微生物基于网络的表示向量和基于基因序列的表示向量,为了给不同的信息赋予权重,采用注意力机制层融合前述不同信息获得微生物的全局表示向量。
实施例二
本实施例提供了基于注意力机制的微生物与疾病关联关系预测系统;
基于注意力机制的微生物与疾病关联关系预测系统,包括:
疾病向量表示模块,其被配置为:获取疾病多源信息;对疾病多源信息进行处理,得到若干种疾病表示向量;对若干种疾病表示向量进行融合,得到最终的疾病表示向量;
微生物向量表示模块,其被配置为:获取微生物多源信息;对微生物多源信息进行处理,得到若干种微生物表示向量;对若干种微生物表示向量进行融合,得到最终的微生物表示向量;
关联关系预测模块,其被配置为:计算最终的疾病表示向量与最终的微生物表示向量二者之间的关联度,当关联度大于设定阈值,则表示微生物与疾病之间存在关联关系,否则表示二者之间不存在关联关系。
此处需要说明的是,上述疾病向量表示模块、微生物向量表示模块和关联关系预测模块对应于实施例一中的步骤s101至步骤s103,上述模块与对应的步骤所实现的示例和应用场景相同,但不限于上述实施例一所公开的内容。需要说明的是,上述模块作为系统的一部分可以在诸如一组计算机可执行指令的计算机系统中执行。
上述实施例中对各个实施例的描述各有侧重,某个实施例中没有详述的部分可以参见其他实施例的相关描述。
所提出的系统,可以通过其他的方式实现。例如以上所描述的系统实施例仅仅是示意性的,例如上述模块的划分,仅仅为一种逻辑功能划分,实际实现时,可以有另外的划分方式,例如多个模块可以结合或者可以集成到另外一个系统,或一些特征可以忽略,或不执行。
实施例三
本实施例还提供了一种电子设备,包括:一个或多个处理器、一个或多个存储器、以及一个或多个计算机程序;其中,处理器与存储器连接,上述一个或多个计算机程序被存储在存储器中,当电子设备运行时,该处理器执行该存储器存储的一个或多个计算机程序,以使电子设备执行上述实施例一所述的方法。
应理解,本实施例中,处理器可以是中央处理单元cpu,处理器还可以是其他通用处理器、数字信号处理器dsp、专用集成电路asic,现成可编程门阵列fpga或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
存储器可以包括只读存储器和随机存取存储器,并向处理器提供指令和数据、存储器的一部分还可以包括非易失性随机存储器。例如,存储器还可以存储设备类型的信息。
在实现过程中,上述方法的各步骤可以通过处理器中的硬件的集成逻辑电路或者软件形式的指令完成。
实施例一中的方法可以直接体现为硬件处理器执行完成,或者用处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器、闪存、只读存储器、可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成上述方法的步骤。为避免重复,这里不再详细描述。
本领域普通技术人员可以意识到,结合本实施例描述的各示例的单元及算法步骤,能够以电子硬件或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
实施例四
本实施例还提供了一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成实施例一所述的方法。
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!