视力检测装置的制作方法
本申请属于视力检测
技术领域:
,更具体地说,是涉及一种视力检测装置。
背景技术:
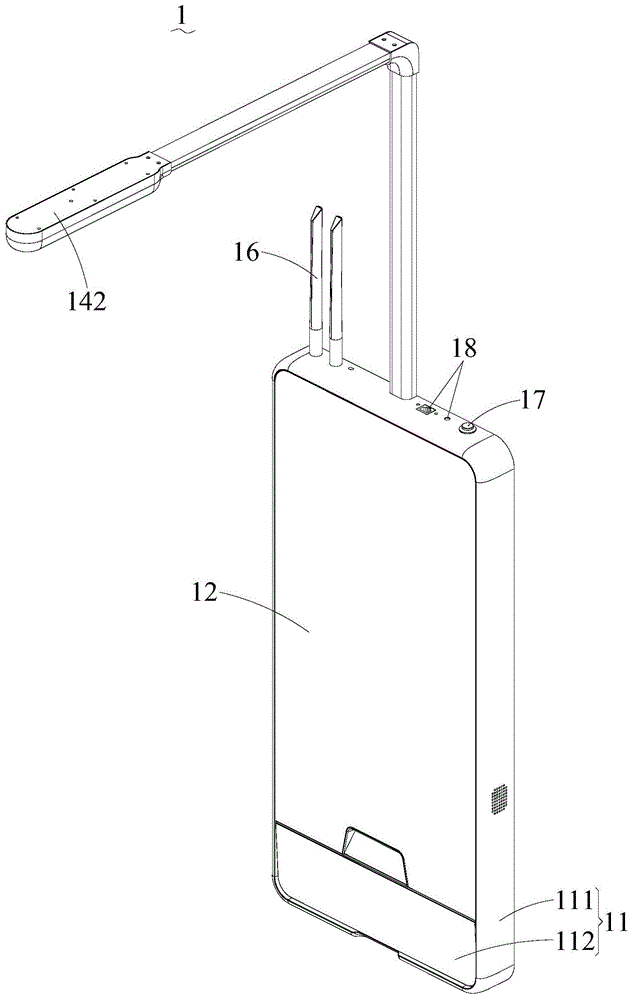
:在视力检测时,通常是医护人员在显示屏上指定一个视力测试图标,然后根据检测者的语音来判断正误。通过重复上述操作,以初步了解检测者的视力。然而,医护人员与检测者之间通过语音进行沟通的方式,存在以下不足之处:1、在嘈杂环境条件下,语音沟通辨识度较弱,影响正常交流,进而影响视力判断;2、对于特殊人群,如耳聋等,无法语音沟通交流,影响视力检测的顺利进行;3、需要医护人员全程陪同,人工成本高,无法实现独立自主检测。因此,视力检测装置的使用局限性大,适应性较差。技术实现要素:本申请实施例的目的在于提供一种视力检测装置,以解决相关技术中存在的视力检测装置的使用局限性大,适应性差的问题。为实现上述目的,本申请实施例采用的技术方案是:提供一种视力检测装置,包括:遮眼器,所述遮眼器包括外壳、安装于所述外壳中的控制板、与所述控制板电性连接的电源和安装于所述外壳上的按键,所述电源安装于所述外壳中,所述电源与所述控制板电性连接,所述按键与所述控制板电性连接;中控机,与所述控制板通信连接,用于显示视力检测图标,以及接收所述按键发出的信号并将该信号与所述视力检测图标的方向进行比对以获得视力检测结果,并存储所述视力检测结果。采用上述结构,本申请通过将遮眼器的控制板与中控机通信连接,检测者通过按键判断视力检测图标的信号可传输至中控机,中控机可将该信号与视力检测图标的方向进行比对以获得视力检测结果并存储。因此,本申请通过按键取代传统语音确认的方式,不受检测环境及检测者自身条件的限制,视力检测装置的使用局限性小,适应性好;而且,无需医护人员全程陪同作业,可实现自主独立检测,人工成本低。在一个实施例中,所述中控机上开设有容置所述遮眼器的容置槽。采用上述结构,容置槽用于容置遮眼器,便于遮眼器的存储。在一个实施例中,所述外壳的一端为遮眼部,所述外壳的另一端为手持部;所述容置槽包括供所述遮眼部伸入的第一卡槽、供所述手持部伸入的第二卡槽和连通所述第一卡槽与所述第二卡槽的第三卡槽,所述遮眼器的中部位置正对所述第三卡槽设置。采用上述结构,通过第一卡槽和第二卡槽分别对遮眼器的两端进行固定,遮眼器的安装稳固性好;第三卡槽便于检测者对遮眼器的取放。在一个实施例中,所述第二卡槽的深度大于所述第一卡槽的深度,所述第三卡槽的深度大于所述第二卡槽的深度。采用上述结构,遮眼器的中部位置与第三卡槽的底面之间存在间距,可供检测者的手部伸入其中,方便对遮眼器的取放。在一个实施例中,所述控制板上安装有无线充电模块,所述中控机上对应安装有用于与所述无线充电模块配合以对所述电源充电的充电线圈。采用上述结构,可实现对遮眼器的无线充电,以提高遮眼器的续航能力。在一个实施例中,所述外壳包括底壳和与所述底壳相连的上盖,所述底壳与所述上盖之间围合成容置腔;所述控制板和所述电源分别设于所述容置腔中。采用上述结构,可提高遮眼器的密封性能,提高防水、防尘能力。在一个实施例中,所述底壳的内周面上间隔安装有多个卡勾,所述上盖上对应于各所述卡勾的位置开设有卡孔。采用上述结构,便于底壳与上盖之间的拆装,方便对遮眼器的维护。在一个实施例中,所述中控机包括机壳、安装于所述机壳上的显示屏、用于接收所述按键发出的信号的感应器单元和用于接收所述感应器单元发出的信号的主控制单元;所述感应器单元和所述主控制单元分别安装于所述机壳中,所述显示屏和所述感应器单元分别与所述主控制单元电性连接,所述主控制单元与所述控制板通信连接。采用上述结构,在视力检测过程中,当显示屏上显示视力检测图标时,检测者对该视力检测图标进行识别,感应器单元检测到该识别信号后,并将该识别信号传递至主控制单元,主控制单元将该识别信号转化为视力检测结果并存储。随后,主控制单元控制显示屏自动切换视力检测图标,检测者对该视力检测图标再进行识别。通过上述重复操作,可对检测者的视力进行直观且准确地分析及判断,并对检测者的视力结果进行保存,以供下次比对分析。因此,该中控机无需医护人员协助,就能实现对检测者视力的自主独立检测,可实现智能化作业,适应性好。在一个实施例中,所述机壳包括壳体和安装于所述壳体上的门板;所述壳体上开设有所述容置槽,所述门板遮盖所述容置槽。采用上述结构,便于遮眼器的取放。在一个实施例中,所述门板的一端铰接于所述壳体上,所述门板的另一端安装有磁吸件;所述容置槽的内侧壁上对应安装有用于与所述磁吸件磁吸连接的电磁锁,所述电磁锁与所述主控制单元电性连接。采用上述结构,通过磁吸件与电磁锁的配合,可实现门板的自动开合,操作方便快捷。附图说明为了更清楚地说明本申请实施例中的技术方案,下面将对实施例或示范性技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本申请实施例提供的视力检测装置的结构示意图;图2为图1的爆炸示意图;图3为本申请实施例提供的中控机去掉门板后的结构示意图;图4为图3中a处的放大示意图;图5为本申请实施例提供的门板的结构示意图;图6为本申请实施例提供的视力检测装置去掉门板后的结构示意图;图7为图6中b处的放大示意图;图8为本申请实施例提供的遮眼器的结构示意图;图9为图8的爆炸示意图;图10为本申请实施例提供的视力检测装置的功能等效示意图。其中,图中各附图主要标记:1-中控机;10-感应器单元;11-机壳;111-壳体;112-门板;1121-磁吸件;1122-触控板;113-容置槽;114-第一卡槽;115-第二卡槽;116-第三卡槽;117-充电线圈;118-电磁锁;119-感应开关;12-显示屏;13-主控制单元;131-获取模块;132-关键点预测模块;133-标注模块;134-训练模块;135-处理模块;14-传感器单元;141-摄像头;142-高度传感器;143-体温传感器;144-距离传感器;15-喇叭;16-天线;17-电源开关;18-接口;19-读卡器;2-遮眼器;21-外壳;211-遮眼部;212-手持部;213-底壳;2131-卡勾;2132-参照板;2133-限位挡板;214-上盖;2140-开口;22-控制板;221-方向触点;23-电源;24-方向键;241-防滑凸点;25-确认键;26-磁铁。具体实施方式为了使本申请所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。需要说明的是,当元件被称为“固定于”或“设置于”另一个元件,它可以直接在另一个元件上或者间接在该另一个元件上。当一个元件被称为是“连接于”另一个元件,它可以是直接连接到另一个元件或间接连接至该另一个元件上。此外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”、“第三”的特征可以明示或者隐含地包括一个或者更多个该特征。在本申请的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。“若干”的含义是一个或一个以上,除非另有明确具体的限定。在本申请的描述中,需要理解的是,术语“中心”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本申请和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本申请的限制。在本申请的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本申请中的具体含义。在整个说明书中参考“一个实施例”或“实施例”意味着结合实施例描述的特定特征,结构或特性包括在本申请的至少一个实施例中。因此,“在一个实施例中”或“在一些实施例中”的短语出现在整个说明书的各个地方,并非所有的指代都是相同的实施例。此外,在一个或多个实施例中,可以以任何合适的方式组合特定的特征,结构或特性。请参阅图1和图2,现对本申请实施例提供的视力检测装置进行说明。该视力检测装置包括中控机1和遮眼器2。遮眼器2与中控机1之间为通信连接。此处,该通信连接可以为导线连接、无线局域网络连接、蓝牙连接等,在此不作唯一限定。此结构,该视力检测装置采用上述的中控机1,可实现检测者独立自主进行视力测试作业,无需医护人员陪护,减少人工成本;实现视力检测的智能化,适应性好。在一个实施例中,遮眼器2处于工作状态且蓝牙无连接时,遮眼器2持续广播蓝牙连接报文。蓝牙连接成功后,与中控机1进行唯一绑定。中控机1与遮眼器2均处于工作状态时,自动建立蓝牙连接。遮眼器2处于休眠状态时,断开与中控机1的蓝牙连接。在一个实施例中,请参阅图2和图10,中控机1包括机壳11,安装于机壳11上的显示屏12,以及分别安装于机壳11中的感应器单元10与主控制单元13。其中,显示屏12和感应器单元10分别与主控制单元13电性连接。机壳11安装于墙面上,进而实现中控机1安装固定于墙面上。显示屏12用于显示视力检测图标,该视力检测图标一般为上下左右四个方向设置的字母e,以符合国家标准视力检测要求。感应器单元10用于接收检测者识别视力检测图标时发出的信号,上述信号可以理解为由遮眼器2上的按键输出的视力检测图标的方向信号,即当检测者按压不同方向的按键时,如按压方向朝上的按键时,遮眼器2发出第一信号;按压方向朝下的按键时,遮眼器2发出第二信号,以此类推。当感应器单元10接收第一信号后,并与显示屏12上显示的视力检测图标进行对比分析,当第一信号转化为的检测结果与显示屏12上显示的视力检测图标相同时,表面检测正确;反之则错误。主控制单元13用于控制显示屏12切换视力检测图标,以及接收感应器单元10的信号并将该信号与视力检测图标的方向进行比对以获得视力检测结果,并存储该视力检测结果。此处可以理解为,当检测者进行视力检测时,显示屏12上显示第一个视力检测图标后,主控制单元13会间隔同等时间对视力检测图标进行切换,比如3s、4s、5s等时间后,显示屏12上会显示下一个视力检测图标。如此循环往复,直至视力检测结束。感应器单元10将接收到的检测者识别视力检测图标时发出的信号传输给主控制单元13,主控制单元13通过内部设定程序对该信号进行正误判断,并对视力检测结果进行存储记录,并根据国家视力检测表进行对照比对,以核准检测者的视力。主控制单元13将感应器单元10传输来的信号转化为视力检测结果的算法可采用本领域的常规技术手段,在此不作一一赘述。在一个实施例中,请参阅图8和图9,遮眼器2包括外壳21,分别安装于外壳21中的控制板22与电源23,以及安装于外壳21上的按键;电源23与控制板22电性连接,控制板22与主控制单元13通信连接。其中,按键包括方向键24与确认键25,方向键24和确认键25分别与控制板22电性连接。此处,该通信连接可以为导线连接、无线局域网络连接、蓝牙连接等,在此不作唯一限定。此结构,遮眼器2可与中控机1实现通信连接,检测者可以根据方向键24选择显示屏12上显示的视力检测图标的方向,并通过确认键25将选择的结果传输至中控机1进行分析判断,并生成最终的视力检测结果并存储,实现独立自主检测的目的。此结构,本申请通过将遮眼器2的控制板22与中控机1通信连接,检测者通过按键判断视力检测图标的信号可传输至中控机1,中控机1可将该信号与视力检测图标的方向进行比对以获得视力检测结果并存储。因此,本申请通过按键取代传统语音确认的方式,不受检测环境及检测者自身条件的限制,视力检测装置的使用局限性小,适应性好;而且,无需医护人员全程陪同作业,可实现自主独立检测,人工成本低。在一个实施例中,请参阅图2和图6,机壳11包括壳体111和安装于壳体111上的门板112;壳体111上开设有容置槽113,门板112遮盖容置槽113。此结构,该容置槽113可用于容置遮眼器2,从而便于遮眼器2的存储。在一个实施例中,请参阅图4、图7和图8,外壳21的一端为遮眼部211,另一端为手持部212。遮眼部211可为圆形结构,手持部212可为圆柱体结构。此处,圆形的遮眼部211不容易因视力检测装置位置的偏摆而造成测量失准,有利于准确地测出中控机1与遮眼器2之间的距离。容置槽113的底部开设有用于容置遮眼部211的第一卡槽114、用于容置手持部212远离遮眼部211的一端的第二卡槽115和连接第一卡槽114与第二卡槽115的第三卡槽116;遮眼器2的遮眼部211可放置于第一卡槽114中,遮眼器2的手持部212的端部可放置于第二卡槽115中,遮眼器2的中间位置位于第三卡槽116中。此结构,通过第一卡槽114和第二卡槽115可实现对遮眼器2两端的夹持固定,第三卡槽116方便对遮眼器2的取放。在一个实施例中,请参阅图4和图7,第二卡槽115的深度大于第一卡槽114的深度,第三卡槽116的深度大于第二卡槽115的深度。此结构,遮眼器2的两端的夹持力不同,提高遮眼器2的安装稳固性,有效防止遮眼器2的脱落。遮眼器2的中部位置正对第三卡槽116,遮眼器2与第三卡槽116的底面之间存在间距,可供检测者的手部伸入其中,方便对遮眼器2的取放。在一个实施例中,请参阅图2和图7,控制板22上安装有无线充电模块(图未示),机壳11中对应安装有用于与无线充电模块配合以对电源23进行无线充电的充电线圈117。此结构,当遮眼器2安装于容置槽113中时,中控机1可对电源23进行无线充电,以提高遮眼器2的续航能力。在一个实施例中,当遮眼器2存放于容置槽113中时,遮眼器2处于关机或休眠状态。当遮眼器2取出或有按键触发时,遮眼器2处于工作状态。当遮眼器2连续十分钟没有按键触发,遮眼器2进入休眠状态;再次触发按键,进入工作状态。当中控机1处于开启状态时,遮眼器2电量充满后,可进行自动断电保护。在中控机1与遮眼器2处于蓝牙连接状态时,遮眼器2每隔三分钟向中控机1发出电源23的电量信息,以实现中控机1对遮眼器2电量的实时监控,并能向检测者实时显示遮眼器2的电量信息。在一个实施例中,遮眼器2上安装有指示灯。指示灯可发出三种颜色的色光,可以分别指示遮眼器2的不同工作状态。当遮眼器2与中控机1蓝牙连接时,遮眼器2处于工作状态,此时指示灯显示白色并常亮。当遮眼器2的电量低于设定值时,指示灯显示红色并闪烁,以提醒需要充电。当遮眼器2与中控机1未蓝牙连接或遮眼器2发生故障时,指示灯熄灭。当遮眼器2处于充电状态时,指示灯显示红色并常亮。当遮眼器2充电完成时,指示灯显示绿色并常亮。当然,在其它实施例中,指示灯的颜色可以根据需要进行调节,在此不作唯一限定。在一个实施例中,机壳11上安装有用于检测外部物件是否被容纳于容置槽113中的到位检测器,该到位检测器与主控制单元13电连接。具体地,当遮眼器2被容纳于容置槽113中时,到位检测器能够检测到遮眼器2的存放信息,并将该存放信息传送给主控制单元13,主控制单元13获取到该存放信息后,确定遮眼器2被放入容置槽113中,便于后续对遮眼器2的充电作业。在一个实施例中,到位检测器可以包括霍尔传感器和磁铁26,霍尔传感器用于感应磁铁26的磁极变化以生成感应信号,主控制单元13根据该感应信号检测遮眼器2是否放入容置槽113中。当指示灯亮起时,表明遮眼器2放回至容置槽113中。在一些实施例中,到位检测器可以设为光线传感器、距离传感器、限位开关或磁性传感器等,在此不作唯一限定。在一个实施例中,请参阅图9,外壳21包括底壳213和与底壳213相连的上盖214,底壳213与上盖214之间围合成容置腔,控制板22、电源23及磁铁26分别设置于该容置腔中,可有效提高防水、防尘性能。上盖214上开设有开口2140,方向键24活动安装于开口2140中,便于实现快速安装。该方向键24可呈“十”字构型,开口2140的截面构型与方向键24的构型呈对应设置。方向键24的四个凸出的端部之顶面分别设置有防滑凸点241,一方面,防滑凸点241可形成“上”、“下”、“左”、“右”四个方向的指示标识,即使在光照强度较低的环境下,也可以通过防滑凸点241来识别视力检测图标;另一方面,起到一定的防滑作用。底壳213正对于遮眼部211的位置设置有参照板2132,参照板2132可作为中控机1的参照物,进而提高中控机1与遮眼器2之间距离测量的准确性。在一个实施例中,控制板22上具有四个分别对应于方向键24的四个凸出的端部的方向触点221,各方向触点221与控制板22电连接。通过按压方向键24不同的凸出的端部,可实现与对应方向触点221的接触。在一个实施例中,请参阅图9,底壳213中间隔设置有两个限位挡板2133,电源23设置在两个限位挡板2133之间,可实现对电源23的限位固定。在一个实施例中,请参阅图9,底壳213的内周面上间隔设置有多个卡勾2131,上盖214上对应开设有多个卡孔(图未示),各卡勾2131可卡入对应的卡孔中,进而实现底壳213与上盖214之间的卡扣连接,便于底壳213与上盖214之间的拆装,方便对遮眼器2的维护。在一个实施例中,请参阅图2、图4和图5,门板112的一端铰接于壳体111上,门板112的另一端安装有磁吸件1121;容置槽113的内侧壁上对应安装有用于与磁吸件1121磁吸连接的电磁锁118,电磁锁118与主控制单元13电性连接。其中,磁吸件1121可为磁铁块。此结构,当电磁锁118断电或者正向充电时,电磁锁118的磁性与磁吸件1121的磁性相反,电磁锁118与磁吸件1121磁性吸合,实现门板112的自动关闭;当电磁锁118反向充电时,电磁锁118的磁性与磁吸件1121的磁性相同,电磁锁118与磁吸件1121之间相互排斥,实现门板112的自动打开,从而可实现门板112的自动开合,操作方便快捷。在一个实施例中,壳体111上安装有用于显示门板112开合状态的指示灯。比如,当门板112关闭时,指示灯显示一种颜色;当门板112打开时,指示灯显示另一种颜色;通过颜色的变换来提示门板112的开合状态。在一个实施例中,请参阅图2、图4和图5,容置槽113的内侧壁上安装有感应开关119,感应开关119与主控制单元13电性连接;门板112上对应安装有用于触控感应开关119的触控板1122。此结构,在关闭门板112时,触控板1122触控感应开关119,感应开关119将触控信号传输给主控制单元13,主控制单元13向指示灯发出指令,指示灯亮起以提示门板112处于关闭状态;在打开门板112时,触控板1122与感应开关119分离,感应开关119将分离信号传输给主控制单元13,主控制单元13向指示灯发出指令,指示灯亮起以提示门板112处于打开状态。通过感应开关119及触控板1122的配合,可提高门板112开合的安全性与可靠性。在一个实施例中,容置槽113的内侧壁上安装有用于弹性抵推门板112的弹性件(图未示)。此结构,当门板112关闭时,门板112挤压弹性件,弹性件受外力压缩变形;当门板112打开时,弹性件在回弹力的作用下抵推门板112,从而可提高门板112的开门效率及可靠性。其中,弹性件可为弹片或弹簧等,在此不作唯一限定。在一个实施例中,中控机1还包括用于对容置槽113进行杀菌处理的消毒灯(图未示);消毒灯安装于容置槽113中,消毒灯与主控制单元13电性连接。此结构,消毒灯可对安装于容置槽113中的遮眼器2进行消毒杀菌处理,提高遮眼器2使用的安全性。其中,当遮眼器2放入容置槽113中,门板112关闭时,3min后消毒灯工作,15min后自动关闭。在一个实施例中,请参阅图10,中控机1还包括用于监测检测者之体貌特征的传感器单元14;传感器单元14安装于机壳11上,传感器单元14与主控制单元13电性连接。此结构,通过传感器单元14可对检测者的体貌信息进行检测,一方面可用于存储检测者的数据信息,便于中控机1对检测者身份验证和后续重复检测,方便对比分析;另一方面,可提高视力检测装置的功能多样性。在一个实施例中,请参阅图2和图10,传感器单元14包括用于对检测者进行人脸识别的摄像头141、用于对检测者进行体温检测的体温传感器143、用于测量检测者与显示屏12之间距离的距离传感器144和用于对检测者进行身高检测的高度传感器142;摄像头141、体温传感器143、距离传感器144和高度传感器142分别安装于机壳11上,摄像头141、体温传感器143、距离传感器144和高度传感器142分别与主控制单元13电性连接。此结构,摄像头141可采集检测者的脸部信息,用于数据存储及人脸识别登录。体温传感器143可用于对检测者的体温进行检测。距离传感器144可用于测量检测者与显示屏12之间的距离,并可以根据距离校正视力值。高度传感器142可用于测量检测者的高度。当然,在其它实施例中,传感器单元14可以根据实际需要进行调整,在此不作唯一限定。通过体温传感器143对检测者的体温进行测试的具体步骤如下:1、在显示屏12的首页上点击“进入体温检测”按钮,中控机1进入体温检测流程;2、中控机1界面显示人脸轮廓,并配文引导,将人脸调整到轮廓中;摄像头141检测到人脸并识别身份后,距离传感器144根据人脸的距离,引导检测者向前或向后调整至40cm-50cm的间距;随后启动体温传感器143,检测并记录检测者的体温数据;3、检测者可以根据体温传感器143检测的体温进行后续作业。比如,当体温正常时,检测者可以选择继续测试或结束测试。当体温偏高(高于37.3度)或偏低(低于35度)时,检测者可以选择重新测试,也可以选择继续测试或结束测试,体温以第二次测量的数据为准。当选择继续测试或重新测试时,中控机1均返回至第二步骤重新开始。在一个实施例中,请参阅图2,中控机1还包括安装于机壳11上的喇叭15;喇叭15与主控制单元13电性连接。此结构,通过喇叭15可实现中控机1语音的外放功能,以向检测者清楚且准确地传达指令及相关检测信息。在一个实施例中,请参阅图2,中控机1还包括安装于机壳11上的天线16,该天线16与主控制单元13电性连接。此结构,通过天线16可提高中控机1与遮眼器2连接的稳定性与可靠性。在一个实施例中,请参阅图2,中控机1还包括分别安装于机壳11上的电源开关17和多个接口18。此结构,电源开关17可以控制中控机1的开闭。多个接口18可包括网线接口、数据传输接口、usb(universalserialbus,通用串行总线)接口等,可用于与外部终端实现数据交互。在一个实施例中,请参阅图2,中控机1还包括安装于机壳11上的读卡器19,该读卡器19与主控制单元13电性连接。此结构,读卡器19可用于识别检测者的身份信息。只有通过身份验证后,才能进入中控机1操作系统进行后续作业。本申请实施例提供的视力检测装置适用于为学校的学生建立屈光档案,通过自主检测的方式,减少医护人员的工作量,提高学生整体视力检测频率及自主检测频率,对学生的视力进行及时纠正治疗,有效降低全国青少年的近视率。本申请实施例提供的视力检测装置的具体视力检测步骤如下:1、信息录入:管理员后台统一录入学生信息。2、设备绑定:管理员刷卡进入中控机1系统,选择“扫描”按钮,中控机1扫描蓝牙设备;随后选择遮眼器2的id编号对应的蓝牙信号,实现中控机1与遮眼器2的蓝牙连接。绑定成功后,下一次开机时,可自动与上一次连接的蓝牙设备进行连接通信。3、人脸录入:管理员选择“设置”按钮,选择人员并由摄像头141录入人脸信息。4、取遮眼器2:(1)检测者在中控机1首页选择“视力检测”按钮,进入身份验证流程,检测者通过人脸识别或刷一卡通实现身份验证并进入中控机1系统。其中,刷一卡通识别是指通过读卡器19识别磁卡的操作;(2)电磁锁118反向充电,电磁锁118与磁吸件1121分离,门板112打开。5、测试点引导:中控机1的显示屏12显示位置引导信息,并语音提示检测者站到指定区域,并按下遮眼器2上的确认键25进行确认。6、身份验证识别:中控机1通过摄像头141进行人脸采集并确认检测者身份。7、视力检测前准备:(1)显示屏12显示检测者的基本信息,如姓名、学号、年级、班级等;(2)中控机1语音提示“请将遮眼器2遮住左眼”或者“请将遮眼器2遮住右眼”;(3)中控机1根据距离传感器144计算检测者与显示屏12之间的距离;(4)语音提示“开始检测,请保持遮眼器2状态”,并实时监测遮眼器2遮挡眼睛的状态。8、视力检测过程:(1)检测者根据看到的显示屏12上显示的视力检测图标e的开口方向,通过遮眼器2上的“上”、“下”、“左”、“右”四个方向键24进行确认;(2)检测者按下确认键25后,显示屏12切换不同的视力检测图标e;(3)重复上述步骤,直至测出被检测眼睛所能辨认的最小行视标,并记录该眼睛的视力值;(4)根据距离传感器144测得的检测者与显示屏12之间的距离,校正实际视力值。其中,实际视力值=测试视力值+e,e指代常数。视力校正表如下:距离m11.21.522.53456.3810校正值e-0.7-0.6-0.5-0.4-0.3-0.2-0.10+0.1+0.2+0.39、测试结果输出:显示屏12上显示本次检测者视力数据及近10次测试数据曲线。10、测试结束:检测者将遮眼器2放入容置槽113中,电磁锁118正向充电,电磁锁118与磁吸件1121磁吸连接,门板112关闭;中控机1三分钟后给遮眼器2充电,并返回首页。本申请提供的视力检测装置可实现人脸关键点检测模型训练,其具体训练步骤如下:101、获取多个样本人脸视频流,一个上述样本人脸视频流包括一个人脸的多张视频帧,上述样本人脸视频流在上述人脸保持静止状态时采集。具体的,可以获取上述多个样本人脸视频流,可以预先采集不同人的人脸静止的视频流,每人每个视频流可以包含几十张以上的人脸视频帧,其中,每个人脸可以是不同的角度,但每一个视频流中的人脸需保持静止。102、采用第一人脸关键点模型,对上述多个样本人脸视频流中每个样本人脸视频流的每一视频帧进行关键点预测,获得上述每一视频帧的预测人脸关键点。具体的,上述第一人脸关键点模型可以是任意一种预先训练的、可用于关键点检测的模型。一般的,为了建立人脸关键点检测模型,需要标有特征点的大量人脸图象(包括多个人的不同表情和姿态)作为训练数据。特征点可以标记在脸的外部轮廓和器官的边缘。可以使用关键点标识表示不同的关键点,需要注意的是各个标定点的顺序在训练集中的各张图像需要一致。本申请实施例中的第一人脸关键点模型可以包括使用已标注的人脸关键点数据训练好的人脸关键点检测模型。上述关键点预测即人脸关键点检测、定位或者人脸对齐,是指给定人脸图像,定位出人脸面部的关键区域位置,如包括眉毛、眼睛、鼻子、嘴巴、脸部轮廓等。采用上述第一人脸关键点模型对上述每一视频帧进行关键点预测,获得每一视频帧的预测人脸关键点,具体可以包括每个关键点坐标。在一种实施方式中,上述步骤102可以包括:使用人脸检测算法对上述多个样本人脸视频流中每个样本人脸视频流的每一视频帧进行人脸检测,获得上述每一视频帧中的人脸检测框;采用上述第一人脸关键点模型,预测上述每一视频帧中的人脸检测框的人脸关键点,获得上述每一视频帧的预测人脸关键点。具体的,可以使用任意常用的人脸检测算法对样本人脸视频流中的每一帧进行人脸检测,得到每一视频帧对应的人脸框,其中上述人脸检测算法可以使用如dlib、mtcnn(multi-taskcascadedconvolutionalnetwork)、resnet10-ssd等,本申请实施例对此不做限制。然后可以根据人脸检测框,使用上述训练好的第一人脸关键点模型,预测每一个检测框的人脸关键点。103、根据上述每个样本人脸视频流的每一视频帧的预测人脸关键点,确定上述每个样本人脸视频流对应的一组人脸关键点坐标,一个上述样本人脸视频流对应的一组人脸关键点坐标用于表示上述样本人脸视频流的每一视频帧的人脸关键点位置。其中,每个样本人脸视频流对应的一组关键点坐标对应于一组人脸关键点,该一组人脸关键点指的是通过关键点检测的方式检测到的用于表征人脸中的各个位置的关键点。可以理解的是,对于其中一个样本人脸视频流,该样本人脸视频流中的各个视频帧对应同一组人脸关键点坐标。具体的,对于一个视频流的人脸,可以根据其中视频帧的预测人脸关键点,确定一组人脸关键点坐标,来代表该样本人脸视频流的每一视频帧的人脸关键点位置,比如通过预设的规则计算出一组人脸关键点坐标或者从所有帧中选取一帧的人脸关键点坐标作为该样本人脸视频流对应的一组人脸关键点坐标。该步骤可以理解为对每个视频流进行标注,对于其中一个视频流中的不同视频帧,通过同一组人脸关键点坐标来对每一视频帧进行标注。在一种可选的实施方式中,上述根据上述每个样本人脸视频流的每一视频帧的预测人脸关键点,确定上述每个样本人脸视频流对应的一组人脸关键点坐标,包括:对一个上述样本人脸视频流的全部视频中同一关键点标识对应的预测人脸关键点坐标取平均值,获得上述全部视频中每个关键点标识对应的平均坐标值;将上述全部视频中每个关键点标识对应的平均坐标值确定为上述一个样本人脸视频流对应的一组人脸关键点坐标,以获得上述每个样本人脸视频流对应的一组人脸关键点坐标。上述方法表示,对于一个样本人脸视频流来讲,可以求取每一个视频流中所有视频帧的人脸关键点坐标的平均值,作为该视频流每一帧的人脸关键点标注。可以理解为,人脸图像中相同关键点标识所表示的关键点是同一人脸位置的关键点,则具体可以将全部视频中同一关键点标识对应的预测人脸关键点坐标取平均值,以获得上述全部视频中每个关键点标识对应的平均坐标值,则获得的每个关键点标识对应的平均坐标值即为该样本人脸视频流对应的一组人脸关键点坐标。通过上述步骤对每个样本人脸视频流进行处理,可以获得每个样本人脸视频流对应的一组人脸关键点坐标。通过使用训练好的人脸关键点模型,对人脸静止的视频流进行预测,并使用人脸关键点均值坐标作为视频流中每一帧的标注,可以使视频流中的每一帧具有相同的关键点,并且不同的人的每一个关键点具有一致性。在一种可选的实施方式中,上述根据上述每个样本人脸视频流的每一视频帧的预测人脸关键点,确定上述每个样本人脸视频流对应的一个人脸关键点坐标,可包括:在一个上述样本人脸视频流的全部视频中同一关键点标识对应的预测人脸关键点坐标中,取中间值,获得上述全部视频中每个关键点标识对应的中间坐标值;将上述全部视频中每个关键点标识对应的中间坐标值确定为上述一个样本人脸视频流对应的一组人脸关键点坐标,以获得上述每个样本人脸视频流对应的一组人脸关键点坐标。其中,上述全部视频中每个关键点标识对应的中间坐标值,指的是在所有相同关键点标识的关键点中,选择处于大小适中的关键点坐标,可以分析相同标识的关键点坐标的聚集程度,选取处于最中间的一个关键点坐标。或者对所有相同关键点标识的关键点分别取横坐标和纵坐标的中值,以获得上述每个关键点标识对应的关键点的中间坐标值,作为该样本人脸视频流对应的一组人脸关键点坐标。通过上述步骤对每个样本人脸视频流进行处理,可以获得每个样本人脸视频流对应的一组人脸关键点坐标。可选的,还可以有其它方式确定每个样本人脸视频流对应的一组人脸关键点坐标,本申请实施例对此不做限制。104、根据上述样本人脸视频流和上述每个样本人脸视频流对应的人脸关键点坐标,对上述第一人脸关键点模型进行训练,获得第二人脸关键点模型。在确定每个样本人脸视频流对应的一组人脸关键点坐标之后,即获得了标注好的视频流数据,可以将其作为训练样本对模型进行训练。使用标注好的样本人脸视频流对上述第一人脸关键点模型进行重新训练,可以获得用于在人脸静止不动时,人脸关键点预测不抖动的模型。在一种可选的实施方式中,上述步骤102之前,该方法还包括:获取样本人脸数据,上述样本人脸数据包括多个人物的多张人脸图像,上述人脸图像有对应的人脸关键点标记,上述多个人物中每个人物的多张人脸图像包括不同姿态的人脸;使用上述样本人脸数据进行关键点模型训练,获得上述第一人脸关键点模型。具体的,如上所述,上述第一人脸关键点模型可以使用已标注关键点信息的人脸图像作为样本进行训练。使用已经标注的不同人脸姿态的样本人脸数据进行关键点模型训练,获得上述第一人脸关键点模型。进一步可选的,上述步骤104可包括:根据上述样本人脸视频流和上述每个样本人脸视频流对应的人脸关键点坐标,以及上述样本人脸数据,对上述第一人脸关键点模型进行训练,获得上述第二人脸关键点模型。本申请实施例中在对前述第一人脸关键点模型进行再训练时,也可以加上人工标注的人脸关键点数据,即除了前述步骤获得的已标注的样本人脸视频流,还可以包括部分或全部对人脸图像进行标注的样本人脸数据(用于训练获得第一人脸关键点模型的样本数据)。105、获取人脸视频流,上述人脸视频流包括一个人脸的多张视频帧,上述人脸视频流在上述人脸保持静止状态时采集。具体的,人脸关键点检测装置可以通过摄像头141采集包含人脸的视频,即获取上述人脸视频流,其中该人脸视频流包括一个人脸的多张视频帧。需要注意的是该人脸视频流是在上述人脸保持静止状态时采集。106、采用第二人脸关键点模型对上述人脸视频流中的多张视频帧进行关键点预测,获得上述人脸视频流对应的人脸关键点坐标,将上述人脸视频流对应的人脸关键点坐标作为上述人脸视频流中每一视频帧的人脸关键点坐标。由于采用人脸静止视频流的标注数据进行训练,使得训练的第二人脸关键点模型对人脸静止的视频流进行关键点预测,并解决该场景下关键点抖动的问题。训练好的第二人脸关键点模型可以预测该人脸视频流对应的关键点,即可以获得该人脸视频流对应的一组人脸关键点坐标,并将其作为人脸视频流中每一视频帧的人脸关键点坐标,可以保持预测关键点的稳定性。本申请实施例中的人脸关键点检测模型训练方法可以获得去抖动效果更好的模型,去抖动可以建立在人脸关键点预测之后,解决了大量的视频流数据难以标注,并难以准确标注的问题。通过上述步骤实现静止人脸的视频流中人脸关键点检测,可以应用于各种人脸关键点检测场景,比如人脸识别、各类人脸图像处理等,此处不做限制,可以减少其中的关键点抖动问题,提高依据关键点处理的操作准确度,使处理效果更佳。总体而言,本申请实施例的方法主要是,使用已经标注的不同人不同姿态的人脸关键点数据进行关键点模型训练,得到预训练模型1,然后使用预训练模型1对视频流图像进行关键点预测,得到视频流图像的关键点标注,再获得视频流的关键点标注,进而基于上述视频流的关键点标注在预训练模型1上进行微调,获得最终的关键点模型2。本申请实施例通过获取多个样本人脸视频流,一个上述样本人脸视频流包括一个人脸的多张视频帧,上述样本人脸视频流在上述人脸保持静止状态时采集,采用第一人脸关键点模型,对上述多个样本人脸视频流中每个样本人脸视频流的每一视频帧进行关键点预测,获得上述每一视频帧的预测人脸关键点,根据上述每个样本人脸视频流的每一视频帧的预测人脸关键点,确定上述每个样本人脸视频流对应的人脸关键点坐标,一个上述样本人脸视频流对应的人脸关键点坐标用于表示上述样本人脸视频流的每一视频帧的人脸关键点位置,根据上述样本人脸视频流和上述每个样本人脸视频流对应的人脸关键点坐标,对上述第一人脸关键点模型进行训练,获得第二人脸关键点模型;其中通过使用训练好的第一人脸关键点模型对样本人脸视频流进行预测,得到视频流中每帧的关键点标注,再根据获得每帧的关键点标注,确定一个视频流的关键点标注,使一个视频流每一帧具有相同的关键点,并且不同的人的每一个关键点具有一致性;通过再标注的、使用静止状态的人脸的视频流对模型进行训练,使得训练得到的模型能够学习到视频流中每帧人脸图像的关键点的一致性,从而在检测人脸静止的视频流能够保持预测关键点的稳定性,消除抖动。不需要依靠大量的人工标注样本数据,减少人工成本,也不需要一些方法中通过结合视频流中前后两帧的关键点进行去抖动,处理更简单且有效。基于上述人脸关键点检测模型训练方法实施例的描述,本申请实施例提供的主控制单元13可包括:获取模块131,用于获取多个样本人脸视频流,一个上述样本人脸视频流包括一个人脸的多张视频帧,上述样本人脸视频流在上述人脸保持静止状态时采集;关键点预测模块132,用于采用第一人脸关键点模型,对上述多个样本人脸视频流中每个样本人脸视频流的每一视频帧进行关键点预测,获得上述每一视频帧的预测人脸关键点;标注模块133,用于根据上述每个样本人脸视频流的每一视频帧的预测人脸关键点,确定上述每个样本人脸视频流对应的一组人脸关键点坐标,一个上述样本人脸视频流对应的一组人脸关键点坐标用于表示上述样本人脸视频流的每一视频帧的人脸关键点位置;训练模块134,用于根据上述样本人脸视频流和上述每个样本人脸视频流对应的人脸关键点坐标,对上述第一人脸关键点模型进行训练,获得第二人脸关键点模型。可选的,上述标注模块133具体用于:对一个上述样本人脸视频流的全部视频中同一关键点标识对应的预测人脸关键点坐标取平均值,获得上述全部视频中每个关键点标识对应的平均坐标值;将上述全部视频中每个关键点标识对应的平均坐标值确定为上述一个样本人脸视频流对应的一组人脸关键点坐标,以获得上述每个样本人脸视频流对应的一组人脸关键点坐标。可选的,上述标注模块133还具体用于:在一个上述样本人脸视频流的全部视频中同一关键点标识对应的预测人脸关键点坐标中,取中间值,获得上述全部视频中每个关键点标识对应的中间坐标值;将上述全部视频中每个关键点标识对应的中间坐标值确定为上述一个样本人脸视频流对应的一组人脸关键点坐标,以获得上述每个样本人脸视频流对应的一组人脸关键点坐标。可选的,上述关键点预测模块132具体用于:使用人脸检测算法对上述多个样本人脸视频流中每个样本人脸视频流的每一视频帧进行人脸检测,获得上述每一视频帧中的人脸检测框;采用上述第一人脸关键点模型,预测上述每一视频帧中的人脸检测框的人脸关键点,获得上述每一视频帧的预测人脸关键点。可选的,上述获取模块131还用于,在上述关键点预测模块132采用第一人脸关键点模型,对上述多个样本人脸视频流中每个样本人脸视频流的每一视频帧进行关键点预测之前,获取样本人脸数据,上述样本人脸数据包括多个人物的多张人脸图像,上述人脸图像有对应的人脸关键点标记,上述多个人物中每个人物的多张人脸图像包括不同姿态的人脸;上述训练模块134还用于,使用上述样本人脸数据进行关键点模型训练,获得上述第一人脸关键点模型。可选的,上述训练模块134具体用于:根据上述样本人脸视频流和上述每个样本人脸视频流对应的人脸关键点坐标,以及上述样本人脸数据,对上述第一人脸关键点模型进行训练,获得上述第二人脸关键点模型。可选的,上述主控制单元13还包括处理模块135;上述获取模块131还用于,在上述获得第二人脸关键点模型之后,获取人脸视频流,上述人脸视频流包括一个人脸的多张视频帧,上述人脸视频流在上述人脸保持静止状态时采集;上述处理模块135用于,采用上述第二人脸关键点模型对上述人脸视频流中的多张视频帧进行关键点预测,获得上述人脸视频流对应的人脸关键点坐标,将上述人脸视频流对应的人脸关键点坐标作为上述人脸视频流中每一视频帧的人脸关键点坐标。应理解,上述实施例中各步骤的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本申请实施例的实施过程构成任何限定。以上所述仅为本申请的可选实施例而已,并不用以限制本申请,凡在本申请的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本申请的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1