基于粒子群算法和神经网络的辛烷值损失预测方法与流程
本发明涉及石油化工
技术领域:
,特别是指一种基于粒子群算法和神经网络的辛烷值损失预测方法。
背景技术:
:随着工业的发展,人们在享受到更加便捷生活的同时也对环境造成了一定的破坏。当今世界对环保问题越来越重视,小型车辆的主要燃料是汽油,汽车尾气的排放是造成大气环境污染的主要因素之一。因为汽车市场的迅速发展,汽油的消耗量越来越大,导致释放到大气中的汽车尾气污染物的量越来越大。我国对此制定了日益严格的汽油质量标准,汽油清洁化重点是尽量保持其辛烷值的情况下降低汽油中的硫、烯烃含量。同时,辛烷值是反映汽油燃烧性能的最重要指标,并作为汽油的商品牌号(例如89#、92#、95#)。国ⅴ的汽油标准首次规定了商品汽油硫含量不能高于10μg/g,国ⅵ汽油标准在规定控制硫含量不超过10μg/g的同时,要求烯烃和芳烃含量尽可能降低,进一步降低氮氧化物和颗粒物的排放限值。随着催化裂化过程中原料逐渐重质化和劣质化,生产的汽油中硫含量也在逐渐增大。同时由于催化裂化汽油中烯烃和硫分布不均匀,汽油馏分中烯烃含量高,而重汽油馏分中硫含量高。传统的加氢脱硫技术,在脱硫的同时烯烃饱和量较大,因而造成辛烷值损失较大。因此大幅度降低催化裂化汽油的硫含量,适当降低烯烃的含量,同时保持较低的辛烷值和收率损失,成为了催化裂化汽油脱硫精制的目标。我国商品汽油的70%都是催化裂化汽油。故必须对催化裂化汽油进行精制处理,以满足对汽油质量要求。现有技术在对催化裂化汽油进行脱硫和降烯烃过程中,在一定程度上降低了汽油辛烷值。辛烷值每降低1个单位,相当于损失约150元/吨。增加汽油辛烷值和减少汽油中的硫含量,同时能够产生巨大的经济效益。化工过程的建模一般是通过数据关联或机理建模的方法来实现的,取得了一定的成果。但是由于炼油工艺过程的复杂性以及设备的多样性,它们的操作变量(控制变量)之间具有高度非线性和相互强耦联的关系,而且传统的数据关联模型中变量相对较少、机理建模对原料的分析要求较高,对过程优化的响应不及时,所以效果并不理想。技术实现要素:针对上述
背景技术:
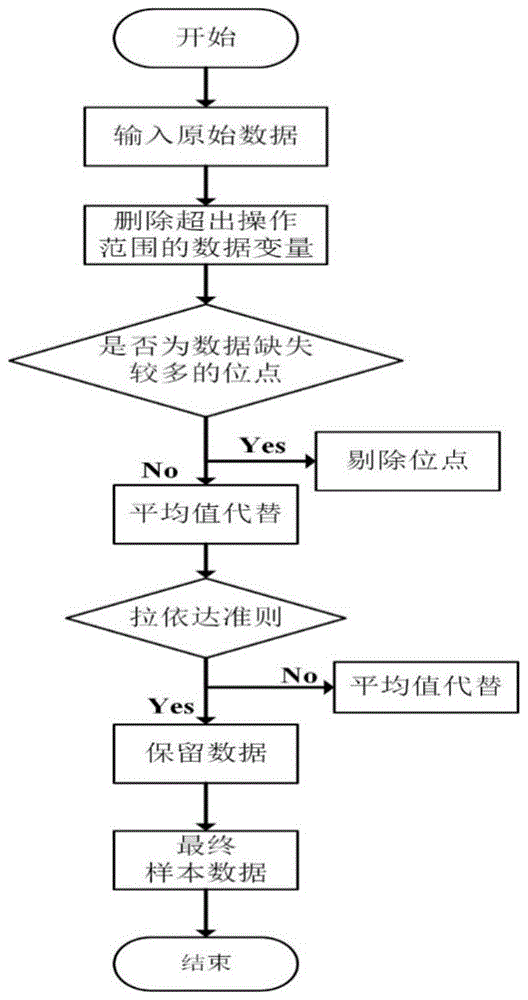
中存在的不足,本发明提出了一种基于粒子群算法和神经网络的辛烷值损失预测方法,解决了现有数据关联模型中变量相对较少,机理建模对原料的分析要求较高,对过程优化的响应不及时,优化效果差的技术问题。本发明的技术方案是这样实现的:一种基于粒子群算法和神经网络的辛烷值损失预测方法,其步骤如下:步骤一:采集催化裂化汽油精制脱硫装置中的操作变量的原始数据和辛烷值损失值数据,并对操作变量的原始数据进行预处理,得到操作变量的样本数据;步骤二:采用决策树回归和皮尔森相关系数对操作变量的样本数据进行特征筛选,得到特征变量及特征变量对应的样本数据;步骤三:构建四层bp神经网络,利用特征变量对应的样本数据和辛烷值损失值数据对四层bp神经网络进行训练得到bp神经网络模型,并将bp神经网络模型作为辛烷值损失预测模型;步骤四:利用粒子群算法和辛烷值损失预测模型对特征变量对应的样本数据进行迭代寻优,输出最小的辛烷值损失值对应的特征变量的取值。所述对操作变量的原始数据进行预处理,得到操作变量的样本数据的方法为:s11、根据操作变量的原始数据的取值范围,对超出取值范围的原始数据进行剔除,得到数据i;s12、将数据i中的第一个操作变量作为当前变量;s13、判断当前变量中数据的缺失个数是否大于9,若是,则认为当前变量存在数据严重缺失,并将当前变量剔除;否则,当前变量无缺失或缺失较少,并采用当前变量的平均值对当前变量的数据缺失处进行补充;s14、将数据i中的下一个操作变量作为当前变量,重复执行步骤s13,直至扫描整个数据i,得到数据ii;s15、利用拉依达准则对数据ii中的操作变量进行处理得到数据iii,再利用步骤s12~步骤s14的操作方法对数据iii进行处理,得到操作变量的样本数据。所述利用拉依达准则对数据ii中的操作变量进行处理得到数据iii的方法为:s15.1、采用等精度测量方法对数据ii中的操作变量x进行处理,得到操作变量x的数据结果x1,x2,...,xn,其中,x=1,2,...,m,m为操作变量的数量,n为操作变量x的数据维度;s15.2、计算操作变量x的数据结果x1,x2,...,xn的平均值x及剩余误差vi=xi-x,其中,i=1,2,...,n;s15.3、利用贝塞尔公式计算操作变量x的标准误差σ;s15.4、判断数据结果xi的剩余误差vi是否满足|vi|=|xi-x|>3σ,若是,判定xi为含有粗大误差值的坏值,将数据结果xi对应的数据删除,否则,将数据结果xi对应的数据保留;s15.5、循环执行步骤s15.1至s15.4,直至遍历数据ii,得到数据iii。所述采用决策树回归和皮尔森相关系数对操作变量的样本数据进行特征筛选,得到特征变量的样本数据方法为:s21、将操作变量的样本数据输入决策树回归模型中,得到操作变量的权重;s22、将权重大于0.01的操作变量作为预选特征变量;s23、计算预选特征变量的样本数据之间的皮尔森相关系数,判断预选特征变量之间是否存在强共线性;s24、对存在强共线性的预选特征变量进行分析,删除作用小的预选特征变量,得到特征变量及特征变量的样本数据。所述预选特征变量的样本数据之间的皮尔森相关系数得计算方法为:计算两个预选特征变量的样本数据x′k、xk″之间的皮尔森相关系数:其中,n′表示特征维度,是x′k的均值,是xk″的均值,r(x′k,xk″)∈[-1,1]表示x′k与xk″的相关程度,若两个样本x′k与xk″是完全相关的,则r的取值为-1或者1;若相关系数r大于等于0.8或小于等于-0.8,则认为两个样本x′k与xk″之间存在强相关,若两个样本完全无关,则r取值为0。所述特征变量包括辛烷值、稳定塔顶压力、干气出装置温度、精制汽油出装置流量、蒸汽进装置压力、加热炉炉膛压力、e-101f管程出口管温度、e-101a壳程出口管温度、d-201水包界位、r-102#1通风挡板温度、k-103a进气压力和8.0mpa氢气至反吹氢压缩机出口。所述利用特征变量对应的样本数据和辛烷值损失值数据对四层bp神经网络进行训练得到bp神经网络模型的方法为:s31、将特征变量对应的样本数据进行归一化处理;s32、对四层bp神经网络进行初始化,初始化连接权值wp、wq、wz,阈值θ1、θ2、θ3;s33、将特征变量对应的归一化后的样本数据和辛烷值损失值数据输入四层bp神经网络中;s34、计算隐含层的输出:其中,wp表示输入层和第一个隐含层的连接权值,wq表示第一个隐含层和第二个隐含层的连接权值,wz表示第二个隐含层和输出层的连接权值,θ1表示第一个隐含层的阈值,θ2表示第二个隐含层的阈值,θ3表示输出层的阈值,p表示输入层神经元数,q表示第一个隐含层的神经元数,z表示第二个隐含层的神经元数,g表示网络的输入参数,g1表示第一个隐含层的输出,g2表示第二个隐含层的输出,y表示输出层的输出;s35、计算输出层和隐含层的误差:e3=(dy)y(1y)其中,d表示网络的期望输出,e3表示输出层误差,e1表示第一个隐含层的误差,e2表示第二个隐含层的误差;s36、对连接权值、阈值进行修正,返回步骤s33,直到满足设定的精度目标值或达到预定的最大迭代次数,得到bp神经网络模型。所述利用粒子群算法和辛烷值损失预测模型对特征变量对应的样本数据进行迭代寻优的方法为:s41、设置迭代次数为t,最大迭代次数为tmax,种群大小为q,粒子的最大速度c1=c2=0.5,确定各个特征变量的上限和下限,导入h组特征变量,将稳定塔顶压力、干气出装置温度、精制汽油出装置流量、蒸汽进装置压力、加热炉炉膛压力、e-101f管程出口管温度、e-101a壳程出口管温度、d-201水包界位、r-102#1通风挡板温度、k-103a进气压力和8.0mpa氢气至反吹氢压缩机出口作为粒子群算法的自变量;s42、利用第h组稳定塔顶压力、干气出装置温度、精制汽油出装置流量、蒸汽进装置压力、加热炉炉膛压力、e-101f管程出口管温度、e-101a壳程出口管温度、d-201水包界位、r-102#1通风挡板温度、k-103a进气压力和8.0mpa氢气至反吹氢压缩机出口的原始数据初始化种群中的粒子的位置和速度,并初始化种群的最优适应度值;s43、更新粒子的速度和位置,将粒子位置对应的数据和辛烷值进行归一化处理后输入辛烷值损失预测模型,得到第h组特征变量对应的辛烷值损失预测值;s44、根据第h组特征变量对应的辛烷值损失预测值与第h组特征变量对应的辛烷值损失值计算第t次迭代的第h组特征变量对应的适应度值,并将最小的适应度值对应的粒子位置作为第h组特征变量对应的最优适应度值;s45、t=t+1,判断t是否达到最大迭代次数tmax,若是,将第h组特征变量对应的最优适应度值作为第h组特征变量的取值,执行步骤s46,否则,返回步骤s43;s46、h=h+1,判断h是否大于h,若是,迭代结束,否则,返回步骤s42。所述粒子的速度和位置的更新方法为:vld′=ωvld′+c1random(0,1)(pld′-xld′)+c2random(0,1)(pg′d′-xld′)xld′=xld′+vld′其中,xid表示第l个微粒的第d′维的位置,vld′表示第l个微粒的第d′维的速度,ω称为惯性因子,pld′表示第l个微粒的第d′维的个体极值,pg′d′表示第d′维的全局最优解,random(0,1)表示[0,1]之间的随机值,l=1,2,...,q,d′=1,2,...,11;所述第h组特征变量对应的适应度值的计算方法为:其中,δl表示第h组特征变量的第l个微粒的适应度,θl表示第l个微粒对应的辛烷值损失值,θ表示将第l个微粒对应的数据和辛烷值输入辛烷值损失预测模型得到的辛烷值损失预测值。本技术方案能产生的有益效果:(1)在数据采集过程中,由于采集装置、生产环境等因素的影响,每条数据均有可能存在问题,因此对数据进行处理,降低了不良数据对预测模型的准确性的影响;(2)通过降维的方法筛选出特征变量,通过特征变量建立辛烷值损失预测模型,再使用粒子群算法在产品硫含量不大于5μg/g的约束条件下和辛烷值损失预测模型对应的主要操作变量的取值范围内进行寻优,以达到辛烷值损失降幅大于30%的优化目标,避免了重复训练的过程,提高了预测效率,降低了辛烷值的损失。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明的数据预处理流程图。图2为本发明计算的经过决策树回归筛选出的14个特征变量的皮尔森相关系数。图3为本发明的特征选择流程图。图4为本发明采用的四层bp神经网络结构图。图5为本发明的bp神经网络训练流程图。图6为本发明的预测效果图。图7为本发明采用的粒子群算法的流程图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明实施例提供了一种基于粒子群算法和神经网络的辛烷值损失预测方法,具体步骤如下:步骤一:采集催化裂化汽油精制脱硫装置中的操作变量的原始数据和辛烷值损失值数据,并对操作变量的原始数据进行预处理,得到操作变量的样本数据;在采集过程中可能由于各种原因出现数据缺失、数据异常等问题,从而导致数据质量下降,直接使用这些存在异常的数据可能会导致结果出现较大的偏差,因此需要对数据进行预处理操作。在数据处理异常值方法中,通常有:剔除数据、剔除缺失值、平均值替换和不处理。是否决定对异常值进行剔除处理,需要具体情况进行具体分析。分析异常值出现原因,将有助于判断是否舍弃异常值。本实施例首先对存在超出取值范围的数据进行删除处理;然后对缺失数据较多的变量进行删除处理,对缺失数据较少的变量采用平均值代替缺失值的处理方法;最后使用拉依达准则对数据进行异常值判断,并用平均值代替异常值。如图1所示,数据预处理的具体方法为:s11、根据操作变量的原始数据的取值范围,对超出取值范围的原始数据进行剔除,得到数据i;采集的数据是某石化企业进行催化裂化汽油精制脱硫装置中采集的数据样本,该数据文件反映的是在同一精制脱硫装置中影响产品辛烷值损失的因素。由于采集设备精度较低,工业现场环境恶劣等因素,在数据采集过程中,可能会出现明显不符合常理的错误数据。为了不影响后续数据的使用,需要对存在明显错误的数据进行预处理。例如285号和313号操作数据的数据位点和采集总时长如表1所示。表1数据样本对原始数据进行预处理,首先超出范围的数据进行判断,并对其按照一定原则进行清洗。在对285号数据样本和313号数据样本共354个数据变量进行数据预处理之前,根据354个数据变量的取值范围约束,对原始数据进行初步的分析,把2个文件中354个数据变量中超出范围的变量进行统计,统计的结果如下表2所示:表2数据样本中超出范围的变量情况由上表2可知,在285号数据样本中,不存在超出范围位点;在313号数据样本中,存在26个参数中存在超出范围的数据共179条,这里将26个参数中超出范围的数据删除,并将其视为缺失值。s12、将数据i中的第一个操作变量作为当前变量;s13、判断当前变量中数据的缺失个数是否大于9,若是,则认为当前变量存在数据严重缺失,并将当前变量剔除;否则,当前变量无缺失或缺失较少,并采用当前变量的平均值对当前变量的数据缺失处进行补充;在观察分析数据样本的过程中,考虑到部分变量可能数据缺失过多也可能缺失不多对结果影响不大两种情况。因此,需要采取一定的原则对其进行数据的处理。这里,判断的标准是变量缺失数据个数是否大于9。若大于9,则对此参数中所有数据均做删除处理,反之对参数中存在缺失的变量使用前后两个小时数据的平均值代替。如果首先对超出范围的变量进行平均值补充,由于这些变量中可能存在数据缺失的情况,这种情况下可能会将这些变量误判为正常数据,同时对缺失值进行补充。在这种情况下进行数据建模,由于数据失真,导致最终得出的预测结果是错误的,不准确的。s14、将数据i中的下一个操作变量作为当前变量,重复执行步骤s13,直至扫描整个数据i,得到数据ii;拉依达准则是指假设一组检测的数据中只含有随机误差,对其进行计算处理得到标准偏差,按一定的概率确定一个区间,认为凡超过这个区间的误差,就不属于随机误差而是粗大误差,含有粗大误差的数据应予以剔除。粗大误差主要由观测过程中某些不确定或者不可控的意外因素引起,有多种的可能性,比如仪器故障、观测设备不准确等问题。粗大误差是随机的,它的产生是难以避免的。预测模型的准确性取决于得到的观测数据是否准确。其中粗大误差会对观测的结果造成直接影响,可能会导致建立的预测模型的准确性低于预期。s15、利用拉依达准则对数据ii中的操作变量进行处理得到数据iii,再利用步骤s12~步骤s14的操作方法对数据iii进行处理,得到操作变量的样本数据。利用拉依达准则对数据ii中的操作变量进行处理得到数据iii的方法为:s15.1、为了降低粗大误差带来的干扰,采用等精度测量方法(这里等精度测量指的是在相同的环境条件下,对同一测量进行多次重复测量的测量方法)对数据ii中的操作变量x进行处理,得到操作变量x的数据结果x1,x2,...,xn,其中,x=1,2,...,m,m为操作变量的数量,n为操作变量x的数据维度;s15.2、计算操作变量x的数据结果x1,x2,...,xn的平均值x及剩余误差vi=xi-x,其中,i=1,2,...,n;s15.3、利用贝塞尔公式计算操作变量x的标准误差σ;s15.4、判断数据结果xi的剩余误差vi是否满足|vi|=|xi-x|>3σ,若是,判定xi为含有粗大误差值的坏值,将数据结果xi对应的数据删除,否则,将数据结果xi对应的数据保留;s15.5、循环执行步骤s15.1至s15.4,直至遍历数据ii,得到数据iii。利用拉依达准则对285号样本数据和313号样本数据去除异常值。在285号样本数据中,数据变量均符合拉依达准则;在313号样本数据中,有52组变量中的66条数据不符合拉依达准则,每个变量中不符合拉依达准则的数据均不大于9个,因此对其相应位点数据取其变量的平均值进行补充。在对原始数据的预处理基础上,经过以上一系列数据异常值判断、数据缺失值处理、数据清除等数据预处理操作,最终得到清洗后的数据。对清洗后的数据进行求平均值操作,以得到样本285与样本313处理后的数据。其中,删除的样本数据变量统计如表3所示,最终得到的处理后的样本数据如表4所示。表3删除的样本数据变量统计表4处理后的样本数据步骤二:为了构造更快,形式更简单、准确性更高的预测模型,需要对数据进行特征选择。本实施的数据共有367个变量,需要对这367个变量进行特征选择。采用决策树回归和皮尔森相关系数对操作变量的样本数据进行特征筛选,得到特征变量及特征变量对应的样本数据。如图3所示,获得特征变量的实现方法为:s21、将操作变量的样本数据输入决策树回归模型中,计算操作变量的权重;在建立降低辛烷值损失预测模型的过程中,由于操作变量过多,使用决策树回归可以很大程度上减少变量的个数。决策树回归是一种基本的分类与回归的算法,是对训练集中数据表现出的属性进行总结分类,为表现出来的属性找到一个确切的描述与分类的模型,由该模型可以对未来不可预测的数据进行分类。breiman等人在1984年提出的分类与回归树(cart)模型是决策树中比较典型的模型之一。cart主要流程分为三步,分别是特征选择、树的生成和剪枝。与其他模型的单一功能不同,cart既可以用于分类也可以用于回归。在给定输入随机变量x条件下,采用cart会得到随机变量y的条件概率分布。在降低辛烷值损失模型中,输入的是367个操作变量,输出为辛烷值损失。cart算法由以下两步组成:1.决策树生成:基于训练数据集生成决策树,生成的决策树要尽量大;2.决策树剪枝:用验证数据集对已生成的树进行剪枝并选择最优子树,这时用损失函数最小作为剪枝的标准。决策树生成和剪枝是cart算法的两个关键步骤。决策树的生成就是递归地构建二叉决策树的过程。对回归树用平方误差最小化标准,进行特征选择,生成二叉树。s21.1、将367个操作变量作为输入变量x′,操作变量对应的辛烷值损失值数据作为输出变量y,输入变量x′与输出变量y是一一对应关系,将输入变量x′和输出变量y联合后作为训练数据集:d={(x1′,y1),(x2′,y2)...(xn′,yn)}其中,d为训练数据集,n为操作变量的数量;s21.2、将输入空间划分m′个单元r1,r2,...,rm′,在单元rm上有一个固定的输出值cm,则回归树模型为:其中,f(x′)表示待预测样本的值,x′表示待预测样本,i(·)表示指示函数,m=1,2,...,m′;i(x′∈rm)表示判断待预测样本是否在区域内的函数,如果是i(x′∈rm)=1,否则i(x′∈rm)=0,就是区域rm的均值。s21.3、利用平方误差表示回归树模型对于训练数据集的预测误差:其中,xi′′表示第i′个的输入变量,yi′表示第i′个的输入变量对应的输出变量,i′=1,2,...,n′,n′表示单元rm上输入变量的数量;s21.4、为表示回归树对于训练数据的预测误差,每个单元上的最优输出值采用平方差最小的准则进行求解。计算单元rm上的所有输入变量xi′′对应的输出变量yi′的均值,也即单元rm上的输出值cm的最优值s21.5、采用启发式的方法,选择第j个输入变量xj′和输入变量xj′的取值s′作为切分变量和切分点,并定义两个区域:r1(j,s′)={x′|xj′≤s′}r2(j,s′)={x′|xj′>s′}r1和r2两个区域代表的是二叉树(j特征的特征值s′作为逻辑判断条件)所划分的两个区域(样本集合);j代表的是样本xj′的第j个特征(是一个索引值),xj′代表的是xj′第j个特征的特征值;s′则代表j的指定特征值。s21.6、构建寻找最优切分变量j和最优切分点s的函数:其中,c1表示第一个特征层的样本值,c2表示第二个特征层的样本值,这里套了两层求最小值的函数min,第一最小值的函数min是各个特征在自己的特征值层面上选出最小值,即各个特征选出最佳分割特征值,外层最小值的函数min则是在各个特征层面上,选择误差最小的特征,这样选出了“最佳”的分割特征值,是局部最佳的特征值。s21.7、针对固定切分变量j找到最优切分点s:其中,表示c1的均值,表示c2的均值;s21.8、在输入变量中筛选出最优的切分变量j,构成一个对(j,s′);s21.9、依次将输入空间划分为两个区域,对每个区域重复执行步骤s21.1至s21.18,直到满足停止条件为止,得到最小二乘树的回归树模型。在获得最小二乘树的回归树模型的过程中通过操作变量的基尼值获得操作变量的权重。s22、将权重大于0.01的操作变量作为预选特征变量;经过决策树回归选取相关系数大于0.01的14个特征变量作为特征指标。表5展现的本实施例用于建立降低辛烷值损失模型所选取的14个特征指标。表5用干建立降低辛烷值损失预测模型的14个特征指标s23、计算预选特征变量的样本数据之间的皮尔森相关系数,判断预选特征变量之间是否存在强共线性;皮尔森相关系数多数情况下是用来描述两个样本的线性相关的度量。考虑到特征变量之间可能存在强共线性,对经过决策树回归筛选出的特征变量进行皮尔森相关系数的计算。计算两个预选特征变量的样本数据x′k、xk″之间的皮尔森相关系数:其中,n′表示特征维度,是x′k的均值,是xk″的均值,r(x′k,xk″)∈[-1,1]表示x′k与xk″的相关程度,若两个样本x′k与xk″是完全相关的,则r的取值为-1或者1;若相关系数r大于等于0.8或小于等于-0.8,则认为两个样本x′k与xk″之间存在强相关,若两个样本完全无关,则r取值为0。s24、对存在强共线性的预选特征变量进行分析,删除作用小的预选特征变量,得到特征变量及特征变量的样本数据。对经过决策树回归筛选出的14个特征变量进行皮尔森相关系数的计算,得到其皮尔森相关系数如图2所示。通过分析图2皮尔森相关系数可以看出,序号1和序号2之间,序号12和序号14之间存在强共线性。序号1为辛烷值(原料),序号2辛烷值(产品),由于建立的模型输出的变量是由辛烷值(原料)经过一系列操作变量得到的,因此去掉序号2辛烷值(产品)变量。序号12是p-101b入口过滤器差压,序号14是d101原料缓冲罐压力,表6分别给出了序号12和序号14与未被选取的相关指标之间的皮尔森相关系数,由于序号14与其它诸多工艺之间存在较强联系,因此本实施例保留序号14,删除序号12。表6序号12和序号14与未被选取相关指标之间的皮尔森相关系数经过上述处理,获得的特征变量包括辛烷值、稳定塔顶压力、干气出装置温度、精制汽油出装置流量、蒸汽进装置压力、加热炉炉膛压力、e-101f管程出口管温度、e-101a壳程出口管温度、d-201水包界位、r-102#1通风挡板温度、k-103a进气压力和8.0mpa氢气至反吹氢压缩机出口。步骤三:构建四层bp神经网络,利用特征变量对应的样本数据和辛烷值损失值数据对四层bp神经网络进行训练得到bp神经网络模型,并将bp神经网络模型作为辛烷值损失预测模型;辛烷值的损失决定了最终产品的经济效益。在进行催化裂化的过程中涉及的参数种类众多,而且国家对此制定了严格的质量标准,需要对工艺参数进行大量调整。从原料到成品,中间经过了很长的工艺流程。如今大部分是凭借着历史生产经验依据辛烷值的损失指标确定原料加工时的方案,往往还需通过大量实验证明。因此需要找到一种能够更省时、更经济和更高效的预测方法来优化汽油生产工业。bp神经网络由于其优点突出,近十几年来被广泛应用于数据预测等问题上。在通过建模对质量进行预测问题时,需要考虑bp神经网络中隐含层的个数。近年来,在小样本预测模型中,四层bp神经网络由于其运行速度快,精度高等优点已经成为主流。考虑到辛烷值的损失预测模型是一个小样本的预测模型,输入变量12个,输出变量1个。因此,本实施例使用双隐层的四层bp神经网络模型对辛烷值的损失进行预测,并使用线性回归等方法与其进行对比,证明了四层bp神经网络在本问题的准确性以及合理性。如图4所示为四层bp神经网络结构图。标准的bp神经网络模型共有3个部分组成,最外面为输入层,中间层可具有1个或者多个隐含层,最后面是网络的输出层,输出运算结果。bp神经网络的过程由两个阶段组成,第一阶段是输入信号的前向传播过程,从输入层经过隐含层,最后到达输出层;第二阶段是误差的反向传播,从输出层到隐含层,最后到输入层,依次调节隐含层到输出层的权重和偏置,输入层到隐含层的权重和偏置。为了较为科学和全面地选取指标,本发明首先结合bp神经网络的描述方法,给出了如表7的所定义的bp神经网络描述指标:表7bp神经网络描述指标如图5所示,bp神经网络训练流程为:s31、将特征变量对应的样本数据进行归一化处理;s32、对四层bp神经网络进行初始化,初始化连接权值wp、wq、wz,阈值θ1、θ2、θ3;s33、将特征变量对应的归一化后的样本数据和辛烷值损失值数据输入四层bp神经网络中;s34、计算隐含层的输出:其中,wp表示输入层和第一个隐含层的连接权值,wq表示第一个隐含层和第二个隐含层的连接权值,wz表示第二个隐含层和输出层的连接权值,θ1表示第一个隐含层的阈值,θ2表示第二个隐含层的阈值,θ3表示输出层的阈值,p表示输入层神经元数,q表示第一个隐含层的神经元数,z表示第二个隐含层的神经元数,g表示网络的输入参数,g1表示第一个隐含层的输出,g2表示第二个隐含层的输出,y表示输出层的输出;s35、计算输出层和隐含层的误差:e3=(d-y)y(1-y)其中,d表示网络的期望输出,e3表示输出层误差,e1表示第一个隐含层的误差,e2表示第二个隐含层的误差;s36、依照权值、阈值修正公式对连接权值、阈值进行修正,返回步骤s33,直到满足设定的精度目标值或达到预定的最大迭代次数,得到bp神经网络模型。本实施例筛选出12个主要建模特征指标,如表8所示:表8建立降低辛烷值损失模型12个特征指标将表8中特征参数作为输入指标,将辛烷值损失作为输出指标进行bp神经网络的训练。由于输入的数据单位不统一,有的数据范围比较大,比如自变量12范围是0-40000000,有的数据范围比较小,如自变量2的范围为0.6~0.7。这种情况可能会导致bp神经网络在训练过程中,收敛速度慢、训练时间长。数据范围大的自变量可能会对对整体数据的影响偏大,从而导致该部分的权重偏大,范围小的数据导致该部分的权重将偏小,从而导致训练的模型不准确。同样的,在进行运算的过程中需要将网络训练的数据进行归一化处理。归一化处理公式如下,处理后的数据如表9所示。表9输入变量的归一化处理神经网络中,每次批选择的个数与网络的迭代个数可能会对结果造成不同的影响。本实施例分别采用15次、20次、100次、200次,批处理分别选择20、50进行参数选择实验。实验结果表明,使用最大迭代次数为20次,批处理选择为20时预测的精度较高。模型参数选择的对比结果如表10所示。表10模型参数选择的对比结果如表10所示,模型的评价指标一般用平均绝对误差(mae)、均方误差(mse)、均方根误差(rmse)来表示。其中,mae、mse、rmse的公式分别如下。通过交叉验证的方法,选取70%的数据作为训练集,选取30%的数据作为测试集。其中,在70%的数据中选择10%的数据作为验证集,其余数据用于模型的训练。本实施例通过对比四层bp神经网络与其它回归算法(例如线性回归、岭回归、贝叶斯岭回归、基于ard的贝叶斯岭回归)以及随机向量函数链神经网络(rvflnn)算法进行比较,得到的预测评价指标如表11所示。表11不同算法评价指标的比较结果由表11得知,使用四层bp神经网络具有更高的精度。其具体的预测效果图如图6所示。步骤四:利用粒子群算法和辛烷值损失预测模型对特征变量对应的样本数据进行迭代寻优,输出最小的辛烷值损失值对应的特征变量的取值。在保证产品硫含量不大于5μg/g的前提下,利用预测模型获得325个数据样本,辛烷值损失降幅大于30%的样本对应的主要变量作为优化后的操作条件(优化过程中原料、待生吸附剂、再生吸附剂的性质保持不变,以它们在样本中的数据为准)。本发明使用粒子群算法进行寻优求解,只有保证产品硫含量不大于5μg/g的前提,且辛烷值损失降幅大于30%才会输出其优化条件。eberhart和kennedy在1995年时通过对鸟群觅食行为的进行了研究,提出了粒子群算法(particleswarmoptimization,pso)。假设存在一个场景:一群鸟在一片区域中随机寻找一块食物,所有的鸟只知道当前的位置距离食物还有多远,不知道食物在哪里的情况下进行寻找,最简单有效的策略就是寻找鸟群中离食物最近的个体进行搜素。pso算法就是从这种生物种群行为特性中得到启发并用于求解优化问题。用一种粒子来模拟上述的鸟类个体,每个粒子可视为n维搜索空间中的一个搜索个体。粒子的当前位置即为对应优化问题的一个候选解,粒子的飞行过程即为该个体的搜索过程,粒子的飞行速度可根据粒子历史最优位置和种群历史最优位置进行动态调整。粒子仅具有两个属性:速度和位置,速度代表移动的快慢,位置代表移动的方向。每个粒子单独搜寻的最优解叫做个体极值,粒子群中最优的个体极值作为当前全局最优解。不断迭代,更新速度和位置。最终得到满足终止条件的最优解。如图7所示,利用粒子群算法和辛烷值损失预测模型对特征变量对应的样本数据进行迭代寻优的方法为:s41、设置迭代次数为t,最大迭代次数为tmax=150,种群大小为q=40,粒子的最大速度c1=c2=0.5,确定各个特征变量的上限和下限,导入h组特征变量,将稳定塔顶压力、干气出装置温度、精制汽油出装置流量、蒸汽进装置压力、加热炉炉膛压力、e-101f管程出口管温度、e-101a壳程出口管温度、d-201水包界位、r-102#1通风挡板温度、k-103a进气压力和8.0mpa氢气至反吹氢压缩机出口作为粒子群算法的自变量;s42、利用第h组稳定塔顶压力、干气出装置温度、精制汽油出装置流量、蒸汽进装置压力、加热炉炉膛压力、e-101f管程出口管温度、e-101a壳程出口管温度、d-201水包界位、r-102#1通风挡板温度、k-103a进气压力和8.0mpa氢气至反吹氢压缩机出口的原始数据初始化种群中的粒子的位置和速度,并初始化种群的最优适应度值;s43、更新粒子的速度和位置,将粒子位置对应的数据和辛烷值进行归一化处理后输入辛烷值损失预测模型,得到第h组特征变量对应的辛烷值损失预测值;所述粒子的速度和位置的更新方法为:vld′=ωvld′+c1random(0,1)(pld′-xld′)+c2random(0,1)(pg′d′-xld′)xld′=xld′+vld′其中,xid表示第l个微粒的第d′维的位置,vld′表示第l个微粒的第d′维的速度,ω称为惯性因子,ω称为惯性因子,其值为非负。ω较大时,在对全局进行寻优时能力强,对局部进行寻优时能力强,ω较小时,全局寻优能力弱。通过调整ω的大小,可以对全局寻优性能和局部寻优性能进行调整。加速常数用c1和c2表示,前者作为每个粒子的个体学习因子,后者作为每个粒子的社会学习因子。pld′表示第l个微粒的第d′维的个体极值,pg′d′表示第d′维的全局最优解,random(0,1)表示[0,1]之间的随机值,l=1,2,...,q,d′=1,2,...,11;个体极值为每个粒子找到的最优解,从这些最优解找到一个全局值,叫做本次全局最优解。通过与历史全局最优值进行比较,更新历史全局最优值,并将其对应的粒子群的数据更新。s44、根据第h组特征变量对应的辛烷值损失预测值与第h组特征变量对应的辛烷值损失值计算第t次迭代的第h组特征变量对应的适应度值,并将最小的适应度值对应的粒子位置作为第h组特征变量对应的最优适应度值;所述第h组特征变量对应的适应度值的计算方法为:其中,δl表示第h组特征变量的第l个微粒的适应度,θl表示第l个微粒对应的辛烷值损失值,θ表示将第l个微粒对应的数据和辛烷值输入辛烷值损失预测模型得到的辛烷值损失预测值。s45、t=t+1,判断t是否达到最大迭代次数tmax,若是,将第h组特征变量对应的最优适应度值作为第h组特征变量的取值,执行步骤s46,否则,返回步骤s43;s46、h=h+1,判断h是否大于h,若是,迭代结束,否则,返回步骤s42。本实施例基于python(3.7.3)开发环境,并结合tensorflow(2.1.0)、numpy(1.18.1)、pandas(1.0.1)、sklearn(0.0)、scikit-opt(0.5.9)、keras(2.3.1)扩展模块搭建模型实验环境。确定主要操作变量及其取值范围。根据辛烷值损失预测模型,选择12个主要变量,考虑到辛烷值(原料)属于原始变量,无法操作。因此,选择11个主要变量作为寻优参数,并确定其取值范围来约束粒子变量的移动区域。11个主要变量及其取值范围如表12所示。表1211个主要操作变量及其取值范围根据粒子群优化算法,确定主要操作变量及其约束范围,在满足硫含量低于5μg/g的前提,使辛烷值损失降幅达到最优。在粒子群迭代150代以后,算法终止,得到最终的主要变量。其中,部分数据如下表13所示。表13部分最终的主要变量序号0123456789辛烷值90.690.590.790.489.691.090.490.590.490.2稳定塔顶压力0.70.70.70.70.70.70.70.70.70.7干气出装置温度40404040404040404040精制汽油出装置流160160160160160160160160160160本发明研究了降低辛烷值损失模型,利用python对数据进行了预处理,使得到的试验数据更加准确、合理。使用一种决策树回归和皮尔森系数相结合的方法筛选出12个变量,作为降低辛烷值损失预测模型的主要特征变量。然后建立了辛烷值损失预测模型。采用筛选出的12个特征变量,通过四层bp神经网络建立辛烷值损失预测模型,并与其他回归模型进行比较以证明模型的优越性与可靠性。最后利用粒子群算法寻找最优参数。其中,以辛烷值损失降幅为优化目标,以产品硫含量不大于5μg/g为约束条件,利用粒子群算法在主要操作变量的范围内寻找令辛烷值损失降幅最大的操作变量的数值。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1