数据关联分析方法、装置、电子设备及存储介质与流程
本申请涉及数据处理技术领域,尤其涉及一种数据关联分析方法、装置、电子设备及存储介质。
背景技术:
snp位点(singlenucleotidepolymorphism,单核苷酸多态性)的关联分析是研究复杂疾病和基因之间联系的重要方法,snp位点主要是指单个核苷酸的突变而引起dna序列改变,从而导致物种染色体基因组多样性且有可能表现出不同的疾病症状。现寻找与目标性状相关的snp位点的方法有两种,一种是通过生物实验方法,但对于一些目标性状,其遗传因素的相关研究并不多,已知的遗传位点可能只是其中的一少部分;另外一种是通过全基因组关联分析方法进行确定,传统的全基因组关联分析方法主要采用多元线性回归的方法结合t检验寻找相关的snp位点,传统的多元线性回归方法面临样本量少、snp特征特殊的相关性等问题,寻找到的snp位点并不多。
技术实现要素:
本申请提供一种数据关联分析方法、装置、电子设备及存储介质,以实现snp位点关联分析准确率更高、效率更高的技术效果。
本申请提供一种数据关联分析方法,包括:
确定每一snp位点相对于目标性状的p值,所述p值用于表征对应snp位点与所述目标性状之间的相关程度;
基于预设p值阈值以及每一snp位点相对于目标性状的p值,确定与目标性状相关的至少两个snp位点。
根据本申请提供的一种数据关联分析方法,所述预设p值阈值是基于如下方法确定的:
确定至少两个候选p值阈值,以及每一候选p值阈值对应的snp位点集;
计算每一候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度;
将多基因风险评分准确度最高的snp位点集对应的候选p值阈值作为所述预设p值阈值。
根据本申请提供的一种数据关联分析方法,所述计算每一候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度,包括对每一候选p值阈值对应snp位点集下的样本集执行以下操作:
计算候选p值阈值对应的snp位点集下的样本集中每一样本子集的多基因风险评分准确度,所述样本子集是对所述样本集划分得到的;
基于所述候选p值阈值对应的snp位点集下的样本集中每一样本子集的多基因风险评分准确度,确定所述候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度。
根据本申请提供的一种数据关联分析方法,所述计算每一候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度,包括:
将每一候选p值阈值对应的snp位点集下的样本集中所有样本的多基因风险评分准确度的平均值作为样本集的多基因风险评分准确度;
或,将每一候选p值阈值对应的snp位点集下的样本集中所有样本的多基因风险评分准确度的最大值和最小值去掉之后的平均值作为样本集的多基因风险评分准确度;
或,将每一候选p值阈值对应的snp位点集下的样本集中所有样本的多基因风险评分准确度的中位数作为样本集的多基因风险评分准确度。
根据本申请提供的一种数据关联分析方法,所述计算候选p值阈值对应的snp位点集下的样本集中每一样本子集的多基因风险评分准确度,包括:
将样本子集作为测试子集,并将除所述测试子集以外的样本子集作为训练子集;
基于所述训练子集,确定多基因风险评分计算模型;
基于所述多基因风险评分计算模型,计算所述测试子集中每一样本的多基因风险评分;
基于所述测试子集中每一样本的多基因风险评分与对应样本的真实病情之间的相似度,确定所述测试子集的多基因风险评分准确度。
根据本申请提供的一种数据关联分析方法,所述确定每一snp位点相对于目标性状的p值,包括对每一snp位点进行处理:
基于snp位点在目标样本集中每一目标样本中的基因型与对应目标样本的性状特征,确定所述snp位点的回归系数;
对所述snp位点的回归系数进行置换检验,得到所述snp位点相对于所述目标性状的p值。
根据本申请提供的一种数据关联分析方法,所述基于snp位点在目标样本集中每一目标样本中的基因型与对应目标样本的性状特征,确定所述snp位点的回归系数,包括:
建立所述snp位点在所述目标样本中的基因型与所述目标样本的性状特征的回归方程;
基于所述snp位点在各个目标样本中的基因型与对应目标样本的性状特征的至少两个回归方程,采用偏最小二乘回归方法,计算所述snp位点的回归系数。
根据本申请提供的一种数据关联分析方法,所述对所述snp位点的回归系数进行置换检验,得到所述snp位点相对于所述目标性状的p值,包括:
对所述snp位点在各个目标样本的基因型与各个目标样本的性状特征之间的对应关系进行随机置换,并基于置换后的对应关系,计算所述snp位点的检验回归系数;
基于预设数量次随机置换得到的所述预设数量个检验回归系数的分布,确定所述snp位点相对于所述目标性状的p值。
本申请还提供一种数据关联分析装置,包括:
数据确定单元,用于确定每一snp位点相对于目标性状的p值,所述p值用于表征对应snp位点与所述目标性状之间的相关程度;
关联分析单元,用于基于预设p值阈值以及每一snp位点相对于目标性状的p值,确定与目标性状相关的至少两个snp位点。
根据本申请提供的一种数据关联分析装置,还包括p值阈值确定单元,用于确定所述p值阈值;
所述p值阈值确定单元,包括:
候选阈值模块,用于确定至少两个候选p值阈值,以及每一候选p值阈值对应的snp位点集;
评分准确度模块,用于计算每一候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度;
阈值确定模块,用于将多基因风险评分准确度最高的snp位点集对应的候选p值阈值作为所述预设p值阈值。
根据本申请提供的一种数据关联分析装置,所述评分准确度模块包括第一评分准确度子模块和第二评分准确度子模块;
所述第一评分准确度子模块,用于对每一候选p值阈值对应snp位点集下的样本集处理,计算候选p值阈值对应的snp位点集下的样本集中每一样本子集的多基因风险评分准确度,所述样本子集是对所述样本集划分得到的;
所述第二评分准确度子模块,用于对每一候选p值阈值对应snp位点集下的样本集处理,基于所述候选p值阈值对应的snp位点集下的样本集中每一样本子集的多基因风险评分准确度,确定所述候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度。
根据本申请提供的一种数据关联分析装置,所述评分准确度模块,用于将每一候选p值阈值对应的snp位点集下的样本集中所有样本的多基因风险评分准确度的平均值作为样本集的多基因风险评分准确度;
或,将每一候选p值阈值对应的snp位点集下的样本集中所有样本的多基因风险评分准确度的最大值和最小值去掉之后的平均值作为样本集的多基因风险评分准确度;
或,将每一候选p值阈值对应的snp位点集下的样本集中所有样本的多基因风险评分准确度的中位数作为样本集的多基因风险评分准确度。
根据本申请提供的一种数据关联分析装置,所述第一评分准确度子模块,具体用于将样本子集作为测试子集,并将除所述测试子集以外的样本子集作为训练子集;
基于所述训练子集,确定多基因风险评分计算模型;
基于所述多基因风险评分计算模型,计算所述测试子集中每一样本的多基因风险评分;
基于所述测试子集中每一样本的多基因风险评分与对应样本的真实病情之间的相似度,确定所述测试子集的多基因风险评分准确度。
根据本申请提供的一种数据关联分析装置,所述数据确定单元包括回归系数确定模块和置换检验模块;
所述回归系数确定模块,用于对每一snp位点处理,基于snp位点在目标样本集中每一目标样本中的基因型与对应目标样本的性状特征,确定所述snp位点的回归系数;
所述置换检验模块,用于对每一snp位点处理,对所述snp位点的回归系数进行置换检验,得到所述snp位点相对于所述目标性状的p值。
根据本申请提供的一种数据关联分析装置,所述回归系数确定模块包括回归方程确定子模块和偏最小二乘计算子模块;
所述回归方程确定子模块,用于建立所述snp位点在所述目标样本中的基因型与所述目标样本的性状特征的回归方程;
所述偏最小二乘计算子模块,用于基于所述snp位点在各个目标样本中的基因型与对应目标样本的性状特征的至少两个回归方程,采用偏最小二乘回归方法,计算所述snp位点的回归系数。
根据本申请提供的一种数据关联分析装置,所述置换检验模块包括检验回归系数子模块和p值确定子模块;
所述检验回归系数子模块,用于对所述snp位点在各个目标样本的基因型与各个目标样本的性状特征之间的对应关系进行随机置换,并基于置换后的对应关系,计算所述snp位点的检验回归系数;
所述p值确定子模块,用于基于预设数量次随机置换得到的所述预设数量个检验回归系数的分布,确定所述snp位点相对于所述目标性状的p值。
本申请还提供一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述任一种所述数据关联分析方法的步骤。
本申请还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述数据关联分析方法的步骤。
本申请提供的数据关联分析方法、装置、电子设备及存储介质,基于预设p值阈值以及每一snp位点相对于目标性状的p值,确定与目标性状相关的至少两个snp位点,相较于现有的基于查阅文献的方法,获取的与目标性状相关的snp位点更全面、更完整,准确率更高,且无需人为进行文献检索,效率更高。
附图说明
为了更清楚地说明本申请或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请提供的数据关联分析方法的流程示意图;
图2为本申请提供的预设p值阈值确定方法的流程示意图;
图3为本申请提供数据关联分析方法中步骤220的实施方式的流程示意图;
图4为本申请提供的数据关联分析方法中步骤221的实施方式的流程示意图;
图5为本申请提供的数据关联分析方法中步骤110的实施方式的流程示意图;
图6为本申请提供的数据关联分析方法中步骤111的实施方式的流程示意图;
图7为本申请提供的数据关联分析方法中步骤112的实施方式的流程示意图;
图8为本申请提供的数据关联装置的结构示意图之一;
图9为本申请提供的数据关联装置的结构示意图之二;
图10为本申请提供的p值阈值确定单元的结构示意图;
图11为本申请提供的评分准确度模块的结构示意图;
图12是本申请提供的数据关联装置的数据确定单元的结构示意图;
图13是本申请提供的数据关联装置的回归系数确定模块的结构示意图;
图14是本申请提供的数据关联装置的置换检验模块的结构示意图;
图15是本申请提供的电子设备的结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请中的附图,对本申请中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
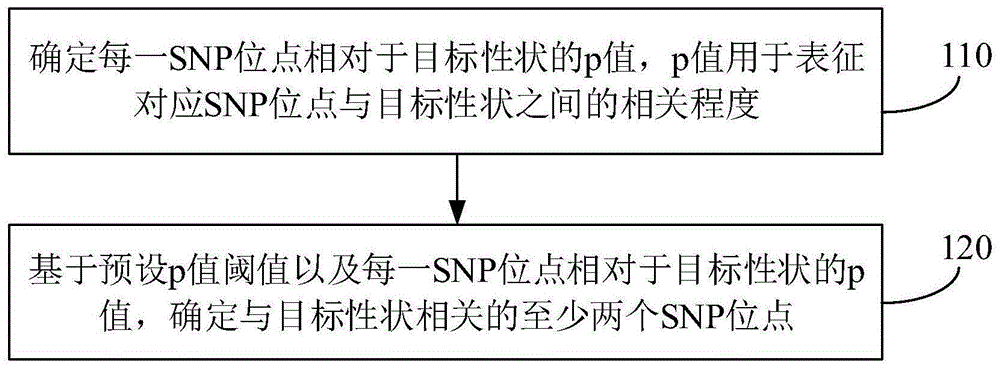
图1为本申请实施例提供的数据关联分析方法的流程示意图,如图1所示,该方法包括:
步骤110,确定每一snp位点相对于目标性状的p值,p值用于表征对应snp位点与目标性状之间的相关程度;
步骤120,基于预设p值阈值以及每一snp位点相对于目标性状的p值,确定与目标性状相关的至少两个snp位点。
具体地,单核苷酸多态性指的是由单个核苷酸—a、t、c或g的改变而引起的dna序列的改变,造成包括人类在内的物种之间染色体基因组的多样性,其中,a、t、c或g就是snp位点。目标性状可以为需要进行snp位点关联分析的性状,目标性状可以包括疾病性状,例如糖尿病、高血压等,也可以包括生理性状,例如肥胖等。基于目标性状,可以确定每一snp位点相对于目标性状的p值,其中,p值用于表征对应snp位点与目标性状之间的相关程度,若p值越小,则对应snp位点与目标性状之间的相关程度越高,若p值越大,则对应snp位点与目标性状之间的相关程度越低。此处,可以基于全基因组关联研究(genome-wideassociationstudies,gwas)获取每一snp位点相对于目标性状的p值。
在得到每一snp位点相对于目标性状的p值之后,可以基于预设p值阈值对snp位点进行筛选,将p值小于预设p值阈值的所有snp位点作为与目标性状相关的snp位点。此处,预设p值阈值可以通过实际经验确定,也可以基于目标性状自适应确定,本申请实施例对预设p值阈值的确定方式不作具体限定。
本申请实施例提供的方法,基于预设p值阈值以及每一snp位点相对于目标性状的p值,确定与目标性状相关的至少两个snp位点,相较于现有的基于查阅文献的方法,获取的与目标性状相关的snp位点更全面、更完整,准确率更高,且无需人为进行文献检索,效率更高。
基于上述任一实施例,图2为本申请实施例提供的预设p值阈值确定方法的流程示意图,如图2所示,该方法包括:
步骤210,确定至少两个候选p值阈值,以及每一候选p值阈值对应的snp位点集;
步骤220,计算每一候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度;
步骤230,将多基因风险评分准确度最高的snp位点集对应的候选p值阈值作为预设p值阈值。
具体地,为确定预设p值阈值,可以选取至少两个候选p值阈值,例如,5×10-8,5×10-7,5×10-6,5×10-5,5×10-4,5×10-3,对于一个候选p值阈值,将p值小于该候选p值阈值的所有snp位点组合的集合作为该p值阈值对应的snp位点集。
在得到每一候选p值阈值对应的snp位点集之后,以一个候选p值阈值对应的snp位点集为基础,计算样本集的多基因风险评分准确度,其中,样本集包括至少两个预先收集的样本,样本集的多基因风险评分准确度可以反映样本集中至少两个样本在一个候选p值阈值对应的snp位点集下计算的多基因风险评分的准确程度。
此处,可以将样本集中所有样本的多基因风险评分准确度的平均值作为样本集的多基因风险评分准确度,也可以将所有样本的多基因风险评分准确度的最大值和最小值去掉之后的平均值作为样本集的多基因风险评分准确度,还可以将所有样本的多基因风险评分准确度的中位数作为样本集的多基因风险评分准确度,本申请实施例对此不作具体限定。
在得到每一候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度之后,将多基因风险评分准确度最高的snp位点集对应的候选p值阈值作为预设p值阈值。
本申请实施例提供的方法,通过确定至少两个候选p值阈值,以及每一候选p值阈值对应的snp位点集,计算每一候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度,并将多基因风险评分准确度最高的snp位点集对应的候选p值阈值作为预设p值阈值,提高了预设p值阈值的准确性,进而提高了获取的与目标性状相关的snp位点的准确性。
基于上述任一实施例,图3为本申请实施例提供数据关联分析方法中步骤220的实施方式的流程示意图,如图3所示,步骤220包括对每一候选p值阈值对应snp位点集下的样本集执行以下操作
步骤221,计算候选p值阈值对应的snp位点集下的样本集中每一样本子集的多基因风险评分准确度,样本子集是对样本集划分得到的;
步骤222,基于该候选p值阈值对应的snp位点集下的样本集中每一样本子集的多基因风险评分准确度,确定该候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度。
具体地,为计算一个候选p值阈值对应的snp位点集下的样本集的多基因风险评分的准确度,可以将样本集划分为至少两个样本子集,计算该候选p值阈值对应的snp位点集下的每一样本子集的多基因风险评分准确度,并基于每一样本子集的多基因风险评分准确度,确定该候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度。对每一候选p值阈值执行上述操作,得到每一候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度。
此处,可以将样本集中所有样本子集的多基因风险评分准确度的平均值作为样本集的多基因风险评分准确度,也可以将所有样本子集的多基因风险评分准确度的最大值和最小值去掉之后的平均值作为样本集的多基因风险评分准确度,还可以将所有样本子集的多基因风险评分准确度的中位数作为样本集的多基因风险评分准确度,本申请实施例对此不作具体限定。
基于上述任一实施例,图4为本申请实施例提供的数据关联分析方法中步骤221的实施方式的流程示意图,如图4所示,步骤221包括:
步骤2211,将样本子集作为测试子集,并将除测试子集以外的样本子集作为训练子集;
步骤2212,基于训练子集,确定多基因风险评分计算模型;
步骤2213,基于多基因风险评分计算模型,计算测试子集中每一样本的多基因风险评分;
步骤2214,基于测试子集中每一样本的多基因风险评分与对应样本的真实病情之间的相似度,确定测试子集的多基因风险评分准确度。
具体地,将样本集划分为至少两个样本子集之后,选取其中一个样本子集作为测试子集,并将除测试子集以外的样本子集作为训练子集。基于训练子集,确定多基因风险评分计算模型,并采用得到的多基因风险评分计算模型计算测试子集中每一样本的多基因风险评分。在得到测试子集中每一样本的多基因风险评分之后,将每一样本的多基因风险评分与对应样本的真实病情进行比对,将每一样本的多基因风险评分与对应样本的真实病情之间的相似度作为测试子集的多基因风险评分准确度。对每一样本子集均执行上述步骤,即可得到每一样本子集的多基因风险评分准确度。
例如,将样本集中100个样本均分为10个样本子集,每一样本子集包括10个样本,从中选取1个样本子集作为测试子集,将其余9个样本子集作为训练子集,基于9个训练子集确定多基因风险评分计算模型,并基于多基因风险评分计算模型计算测试子集中10个样本的多基因风险评分,将测试子集中10个样本的多基因风险评分组成一个向量,将测试子集中10个样本的真实病情组成另一个向量,计算两个向量之间的相似度,例如余弦相似度,作为测试子集的多基因风险评分准确度。
现有的全基因组关联分析中确定任一snp位点相对于任一表征性状的p值通常采用的多元线性回归以及t-test组合的方法,但是由于snp位点数据之间存在多重相关性,且snp位点的数量远大于样本的数量,即自变量的数量大于因变量的数量,导致现有的p值计算的准确性较低。
对此,基于上述任一实施例,图5为本申请实施例提供的数据关联分析方法中步骤110的实施方式的流程示意图,如图5所示,步骤110包括对每一snp位点进行处理:
步骤111,基于snp位点在目标样本集中每一目标样本中的基因型与对应目标样本的性状特征,确定该snp位点的回归系数;
步骤112,对该snp位点的回归系数进行置换检验,得到该snp位点相对于目标性状的p值。
具体地,在执行步骤111之前,收集大量目标样本,组成目标样本集,此处,目标样本为用于确定各个snp位点相对于目标性状的样本。对于一个snp位点,基于该snp位点在目标样本集中每一目标样本中的基因型与对应目标样本的性状特征,确定该snp位点的回归系数,其中,目标样本的性状特征可以反映目标样本是否表征目标性状或目标样本表征目标性状的程度,例如,目标样本表征目标性状,其性状特征为1;目标样本不表征目标性状,其性状特征为0。
置换检验是一种检验显著性的统计方法,通过对所有样本的标签值进行重排序后数据的统计检验值进行计算来得到数据的经验分布。在得到一个snp位点的回归系数之后,可以对该snp位点的回归系数进行置换检测,进而得到该snp位点相对于目标性状的p值。
基于上述任一实施例,图6为本申请实施例提供的数据关联分析方法中步骤111的实施方式的流程示意图,如图6所示,步骤111包括:
步骤1111,建立该snp位点在该目标样本中的基因型与该目标样本的性状特征的回归方程;
步骤1112,基于该snp位点在各个目标样本中的基因型与对应目标样本的性状特征的至少两个回归方程,采用偏最小二乘回归方法,计算该snp位点的回归系数。
具体地,对于一个snp位点,以该snp位点在一个目标样本中的基因型为自变量,以该目标样本的性状特征为因变量,建立一个回归方程。基于该snp位点在各个目标样本中的基因型与对应目标样本的性状特征的至少两个回归方程,采用偏最小二乘回归方法,计算该snp位点的回归系数。
可选地,基于一个snp位点在一个目标样本中的基因型以及该目标样本的其他特征,例如年龄、bmi等,以及该目标样本的性状特征,建立回归方程。具体形式可以表示为:
ysnp+ycov~xdiease
式中,ysnp表示该snp位点在该目标样本中的基因型,ycov表示该目标样本的其他特征,xdiease表示目标样本的性状特征。
一个snp位点的回归系数可以用于衡量该snp位点对目标性状的贡献程度,具体可以通过如下公式计算回归系数r2:
式中,sst(totalsumofsquares,sst)为总平方和,sse(errorsumofsquares,sse)为残差平方和,yi为目标样本集中第i个目标样本的性状特征的标签值,yn为目标样本集的平均值,y′i为目标样本集中第i个目标样本的性状特征的预测值。
基于上述任一实施例,图7为本申请实施例提供的数据关联分析方法中步骤112的实施方式的流程示意图,如图7所示,步骤112包括:
步骤1121,对该snp位点在各个目标样本的基因型与各个目标样本的性状特征之间的对应关系进行随机置换,并基于置换后的对应关系,计算该snp位点的检验回归系数;
步骤1122,基于预设数量次随机置换得到的预设数量个检验回归系数的分布,确定该snp位点相对于目标性状的p值。
具体地,一个回归方程是以一个snp位点在一个目标样本中的基因型为自变量,以该snp位点在该目标样本中的性状特征为因变量建立的,即该snp位点在各个目标样本的基因型与各个目标样本的性状特征是存在一一对应的关系,将该snp位点在各个目标样本的基因型与各个目标样本的性状特征之间的对应关系进行随机置换,即打乱该snp位点在各个目标样本的基因型与各个目标样本的性状特征之间的对应关系,基于置换后的对应关系可以建立至少两个回归方程,采用偏最小二乘法,计算得到回归系数作为该snp位点的检验回归系数。每进行一次随机置换,即可得到该snp位点的一个检验回归系数,进行预设数量次随机置换,即可得到该snp位点的预设数量个检测回归系数,例如进行1000次随机置换,可以得到1000个检验回归系数。
基于预设数量个检测回归系数的分布,即可确定该snp位点相对于目标性状的p值。
基于上述任一实施例,图8为本申请实施例提供的数据关联装置的结构示意图,如图8所示,该装置包括:
数据确定单元810,用于确定每一snp位点相对于目标性状的p值,所述p值用于表征对应snp位点与所述目标性状之间的相关程度;
关联分析单元820,用于基于预设p值阈值以及每一snp位点相对于目标性状的p值,确定与目标性状相关的至少两个snp位点。
基于上述任一实施例,图9为本申请实施例提供的数据关联装置的结构示意图,该装置
基于上述任一实施例,图9为本申请实施例提供的数据关联装置的结构示意图,如图9所示,该装置还包括p值阈值确定单元830,用于确定所述p值阈值,图10为本申请实施例提供的p值阈值确定单元的结构示意图,如图10所示,p值阈值确定单元830包括:
候选阈值模块831,用于确定至少两个候选p值阈值,以及每一候选p值阈值对应的snp位点集;
评分准确度模块832,用于计算每一候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度;
阈值确定模块833,用于将多基因风险评分准确度最高的snp位点集对应的候选p值阈值作为所述预设p值阈值。
基于上述任一实施例,图11为本申请实施例提供的评分准确度模块的结构示意图,如图11所示,评分准确度模块832包括第一评分准确度子模块8321和第二评分准确度子模块8322;
所述第一评分准确度子模块8321,用于对每一候选p值阈值对应snp位点集下的样本集处理,计算候选p值阈值对应的snp位点集下的样本集中每一样本子集的多基因风险评分准确度,所述样本子集是对所述样本集划分得到的;
所述第二评分准确度子模块8322,用于对每一候选p值阈值对应snp位点集下的样本集处理,基于所述候选p值阈值对应的snp位点集下的样本集中每一样本子集的多基因风险评分准确度,确定所述候选p值阈值对应的snp位点集下的样本集的多基因风险评分准确度。
基于上述任一实施例,所述阈值确定模块,还用于将每一候选p值阈值对应的snp位点集下的样本集中所有样本的多基因风险评分准确度的平均值作为样本集的多基因风险评分准确度;
或,将每一候选p值阈值对应的snp位点集下的样本集中所有样本的多基因风险评分准确度的最大值和最小值去掉之后的平均值作为样本集的多基因风险评分准确度;
或,将每一候选p值阈值对应的snp位点集下的样本集中所有样本的多基因风险评分准确度的中位数作为样本集的多基因风险评分准确度。
基于上述任一实施例,所述第一评分准确度子模块8321,具体用于将样本子集作为测试子集,并将除所述测试子集以外的样本子集作为训练子集;
基于所述训练子集,确定多基因风险评分计算模型;
基于所述多基因风险评分计算模型,计算所述测试子集中每一样本的多基因风险评分;
基于所述测试子集中每一样本的多基因风险评分与对应样本的真实病情之间的相似度,确定所述测试子集的多基因风险评分准确度。
基于上述任一实施例,图12是本申请实施例提供的数据关联装置的数据确定单元的结构示意图,如图12所示,数据确定单元810包括回归系数确定模块811和置换检验模块812;
所述回归系数确定模块811,用于对每一snp位点处理,基于snp位点在目标样本集中每一目标样本中的基因型与对应目标样本的性状特征,确定所述snp位点的回归系数;
所述置换检验模块812,用于对每一snp位点处理,对所述snp位点的回归系数进行置换检验,得到所述snp位点相对于所述目标性状的p值。
基于上述任一实施例,图13是本申请实施例提供的数据关联装置的回归系数确定模块的结构示意图,如图13所示,回归系数确定模块811包括回归方程确定子模块8111和偏最小二乘计算子模块8112;
所述回归方程确定子模块8111,用于建立所述snp位点在所述目标样本中的基因型与所述目标样本的性状特征的回归方程;
所述偏最小二乘计算子模块8112,用于基于所述snp位点在各个目标样本中的基因型与对应目标样本的性状特征的至少两个回归方程,采用偏最小二乘回归方法,计算所述snp位点的回归系数。
基于上述任一实施例,图14是本申请实施例提供的数据关联装置的置换检验模块的结构示意图,如图14所示,置换检验模块812包括检验回归系数子模块8121和p值确定子模块8122;
所述检验回归系数子模块8121,用于对所述snp位点在各个目标样本的基因型与各个目标样本的性状特征之间的对应关系进行随机置换,并基于置换后的对应关系,计算所述snp位点的检验回归系数;
所述p值确定子模块8122,用于基于预设数量次随机置换得到的所述预设数量个检验回归系数的分布,确定所述snp位点相对于所述目标性状的p值。
本申请实施例提供的数据关联装置用于执行上述数据关联方法,其具体的实施方式与方法实施方式一致,且可以达到相同的有益效果,此处不再赘述。
图15示例了一种电子设备的实体结构示意图,如图15所示,该电子设备可以包括:处理器(processor)1510、通信接口(communicationsinterface)1520、存储器(memory)1530和通信总线1540,其中,处理器1510,通信接口1520,存储器1530通过通信总线1540完成相互间的通信。处理器1510可以调用存储器1530中的逻辑指令,以执行数据关联分析方法,该方法包括:确定每一snp位点相对于目标性状的p值,p值用于表征对应snp位点与目标性状之间的相关程度;基于预设p值阈值以及每一snp位点相对于目标性状的p值,确定与目标性状相关的至少两个snp位点。
此外,上述的存储器1530中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
本申请实施例提供的电子设备中的处理器1510可以调用存储器1530中的逻辑指令,实现上述数据关联方法,其具体的实施方式与方法实施方式一致,且可以达到相同的有益效果,此处不再赘述。
另一方面,本申请还提供一种计算机程序产品,下面对本申请提供的计算机程序产品进行描述,下文描述的计算机程序产品与上文描述的数据关联分析方法可相互对应参照。
所述计算机程序产品包括存储在非暂态计算机可读存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,计算机能够执行上述各方法所提供的数据关联分析方法,该方法包括:确定每一snp位点相对于目标性状的p值,p值用于表征对应snp位点与目标性状之间的相关程度;基于预设p值阈值以及每一snp位点相对于目标性状的p值,确定与目标性状相关的至少两个snp位点。
本申请实施例提供的计算机程序产品被执行时,实现上述数据关联方法,其具体的实施方式与方法实施方式一致,且可以达到相同的有益效果,此处不再赘述。
又一方面,本申请还提供一种非暂态计算机可读存储介质,下面对本申请提供的非暂态计算机可读存储介质进行描述,下文描述的非暂态计算机可读存储介质与上文描述的数据关联方法可相互对应参照。
本申请还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现以执行上述各提供的数据关联分析方法,该方法包括:确定每一snp位点相对于目标性状的p值,p值用于表征对应snp位点与目标性状之间的相关程度;基于预设p值阈值以及每一snp位点相对于目标性状的p值,确定与目标性状相关的至少两个snp位点。
本申请实施例提供的非暂态计算机可读存储介质上存储的计算机程序被执行时,实现上述数据关联方法,其具体的实施方式与方法实施方式一致,且可以达到相同的有益效果,此处不再赘述。
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到至少两个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
最后应说明的是:以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!