一种肺癌预后预测模型、构建方法及装置与流程
本发明属于生物医学技术领域,具体涉及一种肺癌预后预测模型、构建方法及装置。
背景技术:
肺癌发病率和死亡率在我国恶性肿瘤中均居前列。据报道,我国每年新增肺癌患者60多万,而死亡患者超过50多万,且死亡率逐年上升。肺癌包括非小细胞肺癌和小细胞肺癌,而非小细胞肺癌主要包括肺腺癌和肺鳞癌两种病理类型,其中肺腺癌是最为常见的肺癌类型,具有术后易发生远处转移和预后较差的特点。
临床上,肺癌可否手术取决于tnm分期,而可切除的肺癌患者的预后取决于肿瘤浸润的组织病理学标准。肺癌的临床分期和组织病理学分型是目前肺癌的临床预后指标,然而肺癌术后预后差别大。
研究已经证明肺癌预后与瘤内浸润的免疫细胞有很强的相关性,如高cd8+t细胞浸润与肺癌较好的预后有关;nk/t细胞显著浸润提示肺鳞癌患者具有良好预后。深入了解肺癌肿瘤内浸润免疫细胞的成分以及其对肺癌预后的影响越来与重要。迄今,基于传统的临床指标和分期只能粗略区分不同分期的肺癌,无法满足临床实践中个体化治疗越来越高的要求。目前,尚无整合肺癌肿瘤内浸润免疫细胞的组合模型用于临床预测肺癌预后。研究肺癌瘤内免疫相关因素可能更利于理解肺癌预后不同的机制。
技术实现要素:
本发明的主要目的在于克服现有技术的缺点与不足,提出一种肺癌预后预测模型、构建方法及装置,本发明从分子和免疫细胞水平实现了肺癌患者预后的风险分层,显著地将高低风险的患者分开,进而可以预测肺癌的临床结果,指导个体化治疗,具有较高的临床应用价值。
为了达到上述目的,本发明采用以下技术方案:
一种肺癌预后预测模型构建方法,包括以下步骤:
收集肺癌样本原始基因表达数据和相应的临床生存数据,对基因表达数据进行标准化后,获得基因表达矩阵;
获取肿瘤内免疫细胞类型并计算各类型免疫细胞的相对比值;
从获取的免疫细胞类型中筛选出构建预后预测模型的参数并获取对应的回归系数,所述参数为多种免疫细胞类型;
基于筛选出的参数,根据其相对比值和对应的回归系数,计算免疫评分,得到肺癌预后预测模型。
进一步的,所述收集肺癌样本原始基因表达数据和相应的临床生存数据具体为从geneexpressionomnibus数据库筛选并下载,并且在收集过程中去除临床数据不完整和总生存时间小于一个月的样本数据。
进一步的,所述对基因表达数据进行标准化具体采用mas5算法。
进一步的,所述获取肿瘤内免疫细胞的类型并计算各类型免疫细胞的相对比值具体为采用cibersort反卷积算法;
所述cibersort反卷积算法具体为根据多种免疫细胞类型特异性的基因标签,从肿瘤的基因表达数据中获取肿瘤组织内免疫细胞类型和计算免疫细胞的相对比值,计算公式具体如下:
m=s*f
其中,m为基因表达矩阵,s为免疫细胞类型特异性的基因标签,f为免疫细胞的相对比值。
进一步的,所述筛选出构建预后预测模型的参数具体为采用lasso回归算法并采用交叉验证法根据方差最小确定最优调整参数λ,从而确定用于构建预测模型的最优变量;
所述lasso回归算法具体为:
lasso目标函数=残差平方和+λ*系数的绝对值之和,公式表达为:
其中,loss(w)是lasso目标函数,yj是n*1观测向量,xji为预测变量,即免疫细胞类型,wi是系数;
用交叉验证方法确定最优调整参数λ。
进一步的,所述构建预后预测模型的参数具体为:
幼稚b细胞、记忆b细胞、cd8+t细胞、幼稚cd4+t细胞、静息记忆cd4+t细胞、活化记忆cd4+t细胞、滤泡辅助性t细胞、静息nk细胞、m0型巨噬细胞、m1型巨噬细胞、m2型巨噬细胞、静息树突状细胞、活化树突状细胞、静息肥大细胞、活化肥大细胞、嗜酸性粒细胞以及嗜中性粒细胞。
进一步的,所述肺癌预后预测模型具体表示为:
i=∑f*c
其中,i为免疫评分,f为各免疫细胞的相对比值,c为各免疫细胞类型对应的回归系数。
本发明还包括一种肺癌预后预测模型,模型采用本发明提供的构建方法构建而成。
本发明还包括一种肺癌预后预测装置,基于本发明提供的肺癌预后预测模型,包括数据收集模块、免疫细胞类型分析模块、参数筛选模块、预后模型构建模块以及预测输出模块;
所述数据收集模块用于收集肺癌样本原始基因表达数据和相应的临床生存数据,并对收集的数据进行预处理和标准化;
所述免疫细胞类型分析模块用于获取肿瘤组织内免疫细胞类型并计算各免疫细胞类型的相对比值;
所述参数筛选模块用于从免疫细胞类型中筛选出用于构建预后预测模型的参数并获取相对应的回归系数;
所述预后模型构建模块用于根据被选为参数的免疫细胞类型的相对比值及其对应的回归系数,计算免疫评分,构建肺癌预后预测模型;
所述预测输出模块用于通过最大选择等级统计确定cutoff值,将得到的免疫评分与cutoff值进行比较,输出被测患者的风险值。
进一步的,所述输出被测患者的风险值具体为,小于或等于cutoff值,被测患者属于低风险,大于cutoff值,被测患者属于高风险。
本发明与现有技术相比,具有如下优点和有益效果:
1、本发明基于分子和免疫细胞水平构建肺癌预后预测模型,实现了肺癌患者预后的风险分层,显著地将高低风险的患者分开,进而可以预测肺癌的临床结果,指导个体化治疗,具有较高的临床应用价值。
2、本发明找到与肺癌生存相关的免疫细胞亚型,并建立了这些免疫细胞亚型和生存时间之间的预后模型。
3、本发明建立的模型是从开源的公共数据库中下载肺腺癌患者的基因表达数据和临床数据,解决了样品收集难,测序费用高,以及对病人随访的问题。
附图说明
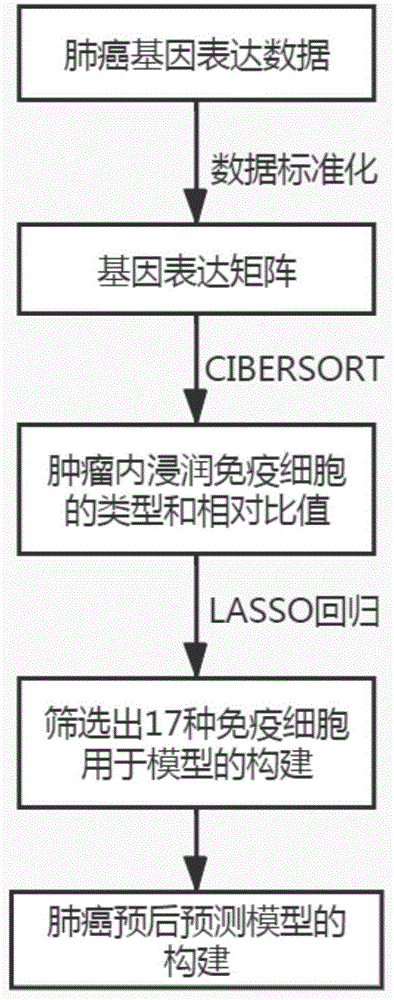
图1是本发明方法的流程图;
图2a是本发明的lasso回归模型图;
图2b是本发明的lasso回归模型图;
图3是本发明的用于确定cutoff值的标准化对数秩统计图;
图4是实施例1的高低风险生存曲线比较图;
图5是实施例1的roc曲线图;
图6是实施例2的高低风险生存曲线比较图;
图7是实施例2的roc曲线图;
图8是本发明装置的结构示意图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
相关术语解释:
cibersort反卷积算法:由斯坦福大学开发,该算法直接根据基因表达数据推测和量化肿瘤组织中22种浸润性免疫细胞的成分和占比,可以同时确定22种免疫细胞类型,克服了常规免疫组化和免疫荧光实验的繁琐与检测少量标记物的难点,同时也克服了临床标本少难以获得,不能满足多组学实验的需求的劣势。
22种免疫类型具体为包括幼稚b细胞(bcellsnaive)、记忆b细胞(bcellsmemory)、浆细胞(plasmacells)、cd8+t细胞(tcellscd8)、幼稚cd4+t细胞(tcellscd4naive)、静息记忆cd4+t细胞(tcellscd4memoryresting)、活化记忆cd4+t细胞(tcellscd4memoryactivated)、滤泡辅助性t细胞(tcellsfollicularhelper)、调节性t细胞(tcellsregulatory)、γδt细胞(tcellsgammadelta)、静息nk细胞(nkcellsresting)、活化nk细胞(nkcellsactivated)、单核细胞(monocytes)、m0型巨噬细胞(macrophagesm0)、m1型巨噬细胞(macrophagesm1)、m2型巨噬细胞(macrophagesm2)、静息树突状细胞(dendriticcellsresting)、活化树突状细胞(dendriticcellsactivated)、静息肥大细胞(mastcellsresting)、活化肥大细胞(mastcellsactivated)、嗜酸性粒细胞(eosinophils)以及嗜中性粒细胞(neutrophils)。
实施例1
如图1所示,本发明,肺癌预后预测模型的构建方法包括以下步骤:
s1、从geneexpressionomnibus(geo)数据库筛选并下载1175例肺腺癌样本原始基因表达数据和相应的临床生存信息,数据均来自同一芯片测序平台(gpl570)。使用mas5算法对原始基因表达数据进行标准化后,获得基因表达矩阵。去除临床数据不完整和和总生存时间小于一个月的样本,剩余849个样品;
s2、使用cibersort反卷积算法,推测肺腺癌肿瘤内免疫细胞的成分以及计算其相对比值,计算公式如下:
m=s*f
其中,m为基因表达矩阵,s为免疫细胞类型特异性的基因标签,f为免疫细胞的相对比值。
s3、采用lasso回归算法从步骤s2所得免疫细胞类型中筛选用于构建预后模型的参数,并获得相应的回归系数,具体为采用lasso回归算法并采用交叉验证法根据方差最小确定最优调整参数λ,从而确定用于构建预测模型的最优变量;
所述lasso回归算法能够进行变量筛选和降低模型的复杂程度。变量筛选是指不把所有的变量都放入模型中进行拟合,而是有选择的把变量放入模型从而得到更好的性能参数。复杂度调整是指通过一系列参数控制模型的复杂度,从而避免过度拟合。变量数越多,模型复杂度就越高,同时也面临过度拟合的危险。
在本实施例中,根据最优参数值,最终有17种免疫细胞类型被筛选作为计算免疫评分的参数,如图2a、图2b所示,图2a曲线最低点确定惩罚值(即曲线最低点对应的上坐标),在图2b的相应惩罚值的位置划上一条竖虚线,每一条曲线代表一个参数,与该惩罚值相交的参数即为计算免疫评分所需参数,参数所对应的纵坐标即为该参数的回归系数;
所述lasso回归算法具体为:
lasso目标函数=残差平方和+λ*系数的绝对值之和,公式表达为:
其中,loss(w)是lasso目标函数,yj是n*1观测向量,xji为预测变量,即免疫细胞类型,wi是系数;
用交叉验证方法确定最优调整参数λ;
r语言实现代码如下:
>library("glmnet")
>library("survival")
>x<-read.csv("x.csv",row.names=1)
>y<-data.matrix(surv(x$time,x$status))
>cv.fit<-cv.glmnet(x,y,family="cox",maxit=1000)
>coef.min=coef(cv.fit,s="lambda.min")
所述17种免疫细胞类型及其对应的回归系数如下表所示:
s4、基于筛选出的参数,根据其相对比值和对应的回归系数,计算免疫评分,得到肺癌预后预测模型,具体为:
i=∑f*c
其中,i为免疫评分,f为各免疫细胞的相对比值,c为各免疫细胞类型对应的回归系数。
基于本实施例构建方法,得到肺癌预后预测模型,使用该模型进行预测包括以下步骤:
根据肺癌预后预测模型得到免疫评分,使用最大选择等级统计(maxstat)方法确定cutoff值,具体为:
使用maxstat基于标准化对数秩检验计算最大选择的秩统计量,将最高点定义为cutoff值所在的点,如图3所示;具体代码如下:
>library("survival")
>x<-read.csv("roc.csv",row.names=1)
>mod<-maxstat.test(surv(os,events)~immunoscore,data=x,smethod="logrank",pmethod="lau92",iscores=true)
>cutpoint<-signif(mod$estimate[[1]],digits=2)
>plot(mod)。
根据该cutoff值将病人划分为高风险组和低风险组。使用kaplan-meier法绘制生存曲线,并使用log-rank检验进行高低风险组生存曲线的比较。
在本实施例中,cutoff的值为-0.23,如果被测病人的免疫评分小于或等于-0.23,那么该病人属于低风险,如图4所示,预测该病人五年生存率是81.2%;反之,如果免疫评分大于-0.23,该病人属于高风险,预测该病人五年生存率是48.7%。
基于本实施例中所得肺癌预后预测模型的预测结果检验,包括以下步骤:
使用log-rank检验,进行高低风险组生存曲线的比较,如图4所示,横坐标代表病人的生存时间(以月为单位),纵坐标代表总生存率,log-rank检验显著性p<0.0001,说明高低风险组之间的生存曲线具有显著的差异。
应用roc曲线图评价模型的临床准确性,如图5所示,为roc曲线图,横坐标是假阳性率(1-特异度),纵坐标是真阳性率(灵敏度),计算模型auc值为0.719,说明模型预测结果准确性较高。
实施例2
本实施例用于对实施例1建立的预后预测模型进行验证;
在本实施例中,肺癌预后预测模型的构建方法包括以下步骤:
s1、从geneexpressionomnibus数据库筛选并下载576例肺腺癌样本原始基因表达数据和相应的临床生存信息,数据均来自同一芯片测序平台(gpl96)。使用mas5算法对原始基因表达数据进行标准化后,获得基因表达矩阵。去除临床数据不完整和和总生存时间小于一个月的样本,剩余557个样品;
s2、使用cibersort反卷积算法,推测肺腺癌肿瘤内免疫细胞的成分以及计算其相对比值,计算公式如下:
m=s*f
其中,m为基因表达矩阵,s为免疫细胞类型特异性的基因标签,f为免疫细胞的相对比值。
s3、基于实施例1筛选出的17个参数,根据其在本实施例中的相对比值和在实施例1中建立的预后预测模型中的回归系数,计算免疫评分,具体为:
i=∑f*c
其中,i为免疫评分,f为各免疫细胞的相对比值,c为各免疫细胞类型对应的回归系数。
s4、将所获得的肺癌预后免疫评分值与实施例1所定义的cutoff值-0.23进行分层,确定所述患者的预后。
如果检测计算得病人预后风险值小于或等于-0.23,那么这个病人就属于低风险,可以预测该病人五年生存率是66.5%;反之,如果病人风险值大于-0.23,那么这个病人就属于高风险,可以预测该病人五年生存率是53.7%。
使用log-rank检验,进行高低风险组生存曲线的比较,如图6所示,横坐标代表病人的生存时间(以月为单位),纵坐标代表总生存率,log-rank检验显著性p=0.0212,说明高低风险组之间的生存曲线具有显著的差异。
应用roc曲线图评价模型的临床准确性,如图7所示,为roc曲线图,横坐标是假阳性率(1-特异度),纵坐标是真阳性率(灵敏度),计算模型auc值为0.60,说明建立的预后预测模型预测结果的准确性较高。
在另一个实施例中,如图8所示,还提供了基于上述实施例所构建的肺癌预后预测模型的肺癌预后预测装置,装置包括数据收集模块、免疫细胞类型分析模块、参数筛选模块、预后模型构建模块以及预测输出模块;
所述数据收集模块用于收集肺癌样本原始基因表达数据和相应的临床生存数据,并对收集的数据进行预处理和标准化;
所述免疫细胞类型分析模块用于获取肿瘤组织内免疫细胞类型并计算各免疫细胞类型的相对比值;
所述参数筛选模块用于从免疫细胞类型中筛选出用于构建预后预测模型的参数并获取相对应的回归系数;
所述预后模型构建模块用于根据被选为参数的免疫细胞类型的相对比值及其对应的回归系数,计算免疫评分,构建肺癌预后预测模型;
所述预测输出模块用于通过最大选择等级统计(maxstat)确定最佳cutoff值,将得到的免疫评分与最佳cutoff值进行比较,输出被测患者风险值。
还需要说明的是,在本说明书中,诸如术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其他实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!