音频设备的接受者的音乐感知的改善的制作方法
音频设备的接受者的音乐感知的改善
1.相关申请的交叉引用
2.本技术作为pct国际专利申请于2020年6月15日提出申请,并且要求于2019年6月17日提交的美国临时专利申请序列号62/862,181的优先权,其全部公开内容通过引用整体并入。
背景技术:
3.近几十年来,具有一个或多个可植入部件的医疗设备(本文中通常称为可植入医疗设备)已经向接受者提供了范围广泛的治疗益处。具体地,诸如听力假体(例如,骨传导设备、机械刺激器、耳蜗植入物等)、可植入起搏器、除颤器、功能性电性刺激设备以及其他可植入医疗设备等之类的部分或完全可植入医疗设备已经在执行拯救生命和/或改善生活方式功能和/或接受者监测方面获得了成功。
4.多年以来,可植入医疗设备的类型和由此执行的功能范围已经得以增加。例如,现在许多可植入医疗设备通常包括永久或暂时植入接受者体内的一个或多个仪器、装置、传感器、处理器、控制器、或其他功能性机械部件或电气部件。这些功能性设备通常用于诊断、预防、监测、治疗或管理疾病/其伤害或症状,或研究、更换或修改解剖结构或生理过程。这些功能设备中的许多功能设备利用从作为可植入医疗假体的一部分或与之结合操作的外部设备接收的功率和/或数据。
技术实现要素:
5.在一个示例中,存在一种计算机实现的过程,包括:使用来自一个或多个第一换能器的第一换能器信号来确定音乐活动在听觉假体的接受者附近发生;使用来自一个或多个第二换能器的第二换能器信号来确定接受者感知音乐活动的能力的指示;使用指示生成对接受者的音乐感知的分析;以及基于分析来采取与接受者有关的治疗动作。
6.在另一示例中,存在一种过程,包括:在服务器处维护模板,该模板定义换能器信号与音乐感知之间的关联;以及在服务器处接收与听觉假体的接受者相关联的接受者换能器信号;使用模板和接受者换能器信号来生成对接受者的音乐感知的分析;以及基于分析来采取与听觉假体有关的治疗动作。
7.在另一示例中,一种计算机实现的过程,包括:从与听觉假体的接受者相关联的一个或多个换能器收集换能器信号;使用换能器信号生成接受者的音乐感知的指示;使用这些指示来生成对接受者的音乐感知的分析;以及使用该分析来采取与接受者有关的治疗动作。
8.在另一示例中,存在一种系统,包括服务器,该服务器包括处理单元;存储器;模板,该模板存储在存储器中,该模板定义换能器信号与音乐感知之间的关联;指令,该指令存储在存储器中,该指令当由处理单元执行时使得处理器:从听觉假体应用接收与听觉假体的接受者相关联的接受者换能器信号;使用模板和接受者换能器信号来生成对接受者的音乐感知的分析;以及基于分析来采取与听觉假体有关的治疗动作。
附图说明
9.在所有附图中,相同的数字表示相同的元件或相同类型的元件。
10.图1示出了包括接受者的听觉假体和通过网络连接到服务器的计算设备的示例系统。
11.图2示出了用于针对听觉假体的接受者的音乐感知而采取治疗动作的第一示例过程。
12.图3示出了用于针对听觉假体的接受者的音乐感知而采取治疗动作的第二示例过程。
13.图4示出了用于针对听觉假体的接受者的音乐感知而采取治疗动作的第三示例过程。
14.图5示出了可以受益于本文中所描述的技术的使用的示例耳蜗植入物系统。
15.图6是可以受益于本文中公开的技术的使用的示例经皮骨传导设备的视图。
16.图7示出了可以受益于本文中公开的技术的使用的具有无源可植入部件的示例经皮骨传导设备。
17.图8示出了通过其可以实现所公开的示例中的一个或多个示例的示例计算系统。
具体实施方式
18.除了理解语音的能力之外,听力损失还可以影响人们感知和欣赏音乐的能力。音乐感知不仅可以涵盖接受者是否喜欢音乐,而且还可以涵盖接受者是否能够将音乐识别为与噪声或其他种类的声音不同的东西。听觉假体可以用于通过引起听觉假体的接受者的听力感知来治疗听力损失。但是,由听觉假体引起的听力感知并非总是适当地模仿自然听力感知。结果,接受者可能无法将音乐输入所引起的听力感知实际上感知为音乐感知(例如,接受者可能将音乐输入仅仅感知为噪声)。虽然接受者可以学习理解音乐,从而改善他或她的音乐感知,但是在没有辅助的情况下,这样做可能会很困难。同样,虽然听觉假体可以被编程为改善音乐再现,但是这样做可能很困难,并且不利于听觉假体再现人类语音的能力。
19.通常,经训练的专业人员(例如,听觉病学家)在初始试穿会话期间对听觉假体进行编程。但是,通常,编程的重点是听觉假体以听觉假体的接受者可以理解的方式再现人类语音的能力。如果在编程期间根本没有考虑到音乐享受,则通常基于心理生理度量(例如,频谱辨别)或与在试穿会话期间确定的音乐有关的主观测量来对听觉假体进行编程。一旦达到可接受水平,该过程结束。在编程之后,可以指令接受者执行康复活动(例如,每天聆听音乐)或监测听觉假体的性能(例如,通过对功能性聆听索引执行评估)。然而,这些技术通常没有充分解决接受者感知音乐的能力以及听觉假体令人满意地再现音乐的能力。
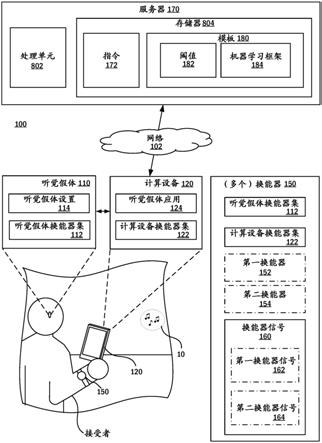
20.结果,即使在听觉假肢的协助下,具有听力损伤的许多个体也无法欣赏音乐。对于这些个体而言,无法欣赏音乐会严重影响他们的整体生活质量。进一步地,所感知的缺乏益处甚至可能诱发反安慰剂效应(nocebo effect),从而导致所有性能度量(不仅是音乐度量)的结果都会有所减少。听觉假体再现音乐的能力可以有助于个体欣赏音乐的能力。
21.本文中所公开的示例与改善听觉假体的接受者的音乐感知有关。可以通过基于对接受者感知如基于来自换能器的信号确定的音乐活动的能力的分析而采取的治疗动作来实现这种改善。治疗动作可以与对听觉假体的接受者的听力损伤的治疗有关。
22.在一个示例实现方式中,在接受者每天使用听觉假体期间收集来自接受者附近的换能器的信号。换能器信号可以用于确定接受者是否以及如何响应音乐活动。换能器可以包括听觉假体本身的传感器、以及与接受者相关联的个人设备的换能器或传感器,诸如可穿戴设备(例如,智能手表或心率监测器)或移动电话。比如,接受者的(例如,听觉假体的)植入的麦克风可以产生与血流(例如,当植入的麦克风放置在动脉附近时)或呼吸活动(例如,当植入的麦克风放置在噪声/喉咙/胸部附近时)有关的信号。呼吸和血流的增加可能与接受者对音乐的响应相关。同样,植入的电极(例如,听觉假体的植入的电极)或外部电极(例如,头戴式电极)可以检测到指示对音乐的响应的脑干、中脑或皮层激活(例如,如果电极位于头部或耳蜗附近)。接着,对信号进行处理,以计算接受者感知音乐的能力的指示。比如,换能器信号可以用于通过确定接受者正在响应音乐活动来确定指示。
23.这些指示被汇总,并且应用逻辑来计算与接受者的音乐感知有关的分析(例如,包括性能度量)。然后,该分析可以用作触发器,以执行与帮助接受者欣赏音乐有关的一个或多个治疗动作。上文和本文中所描述的基于换能器的途径有利地允许以无需训练有素的临床医生的方式来改善接受者(例如,经由治疗动作)感知音乐的能力,这种途径可以在个体的真实世界的声音环境中执行,并且可以以接受者友好的方式实现(例如,与临床声音棚测试相反)。进一步地,在许多情况下,该途径可以以对接受者透明的方式来实现。所公开的系统和过程可以以独立方式自动确定接受者处于应当感知音乐的环境中,分析接受者的音乐感知,并且使用该分析来治疗接受者(例如,该分析可以用于自动计算功能性聆听索引,实现康复程序,或修改听觉假体的设置)。接受者及其临床医生可以简单地使用该过程所生成的数据,诸如经由基于分析而提供的定期进度报告。进一步地,基于换能器的途径可以向接受者提供一种以客观可量化的方式计量与音乐的互动的工具。这可以确保新听觉假体正在工作,并且提供指示接受者正在改善的客观措施。
24.示例系统
25.图1示出了通过其可以实现本文中所描述的一个或多个过程的系统100。如所示出的,系统100包括接受者的听觉假体110以及计算设备120。计算设备120通过网络102连接到服务器170。另外,一个或多个换能器150位于系统100内。该图示出了音乐活动10在接受者附近的发生。
26.音乐活动10是音乐的可闻发生。音乐活动10可以采用多种形式中的任一形式,其包括预先录制的音乐、现场音乐、正式音乐(例如,商业生产的音乐)、或非正式音乐(例如,在生日聚会上演唱或哼唱的人)。音乐活动10可以具有各种音效水平,诸如在背景中(例如,在餐厅中播放音乐)或在前景中(例如,在音乐会上)。音乐活动10可以包括音乐经由扬声器播放或音乐经由听觉假体110本身回放。
27.网络102是诸如因特网之类的计算机网络,该计算机网络便于连接到网络102的计算设备之间的数据的电子通信。
28.示例系统—听觉假体
29.听觉假体110是与接受者的听觉系统(例如,听觉设备)有关的设备。在许多示例中,听觉假体110是被配置为治疗接受者的听力损伤的医疗设备。听觉假体110可以采取多种形式,这些形式包括耳蜗植入物、电声设备、经皮骨传导设备、被动经皮骨传导设备、有源经皮骨传导设备、中耳设备、完全可植入听觉设备、几乎可植入听觉设备、脑干听觉设备、牙
齿锚固听力设备、其他听觉假体、以及上述形式的组合(例如,双耳系统,其包括接受者第一耳朵的假体和另一耳朵的相同或不同的类型的假体)。图5(示出了耳蜗植入物)、图6(示出了经皮(percutaneous)骨传导设备)以及图7(示出了透皮(transcutaneous)骨传导设备)中更详细地描述了听觉假体110的示例实现方式。在所示出的示例中,听觉假体110包括听觉假体换能器集112,并且根据听觉假体设置114进行操作。本文中所公开的技术可以与诸如消费者听觉设备(例如,助听器或个人声音放大产品)之类的听觉设备一起使用。
30.听觉假体换能器集112可以是听觉假体110的一个或多个部件的集合,该一个或多个部件基于所感测的发生(诸如关于听觉假体110周围环境的数据、听觉假体110本身、或接受者)来生成换能器信号。在许多示例中,听觉假体换能器集112包括外部麦克风。听觉假体换能器集112可以包括一个或多个其他传感器,诸如一个或多个植入的麦克风、加速度计、陀螺仪传感器、位置传感器、拾音线圈、相机、瞳孔计、生物传感器(例如,心率或血压传感器)、以及光传感器等。听觉假体换能器集112可以包括设置在听觉假体110的壳体内的部件以及(例如,经由有线连接或无线连接)电耦合到听觉假体110的设备。
31.在各示例中,听觉假体换能器集112包括经由fm(频率调制)连接而连接到听觉假体110的远程设备,诸如远程麦克风(例如,cochlear true wireless mini microphone2+)、电视音频流式传输设备或电话剪辑设备、以及具有fm传输能力的其他设备。听觉假体换能器集112还可以包括获得关于听觉假体110的使用的数据的传感器,诸如在听觉假体110上操作的软件传感器,该软件传感器跟踪数据,诸如:接受者佩戴听觉假体110的时间、接受者取下听觉假体110(例如,其外部部分)的时间、修改听觉假体设置114中的一个或多个听觉假体设置的时间、听觉假体110正在其下操作的当前场景模式(例如,如由场景分类器确定)、以及使用听觉假体设置114的特定设置操作听觉假体110的持续时间、以及其他数据。
32.在各示例中,听觉假体换能器集112还可以包括场景分类器。场景分类器是一种软件,该软件(例如,从听觉假体换能器集112的一个或多个其他传感器)获得关于听觉假体周围的环境的数据并且确定环境的分类。可能分类可以包括例如语音、噪声和音乐、以及其他分类。然后,听觉假体110可以使用分类来自动更改听觉假体设置114以适合环境101。例如,当场景分类器确定假体周围的环境有风时,可以选择风噪场景以自动修改听觉假体设置114以减轻风噪。在另一示例中,场景分类器可以确定音乐正在附近发生并且自动修改听觉假体设置114以改善音乐再现。在于2016年6月9日提交的题为“假体的高级场景分类(advanced scene classification for prosthesis)”的us2017/0359659中描述了示例场景分类器,其出于任何目的和全部目的通过引用整体并入本文。
33.听觉假体设置114是其值会影响听觉假体110的操作方式一个或多个参数。例如,听觉假体110从环境接收声音输入(例如,使用听觉假体110的麦克风),将声音输入转换为刺激信号,并且使用刺激信号来产生刺激(例如,振动刺激或电气刺激)以引起听者的听力感知。听觉假体设置114通常存储在听觉假体110上的存储器中。
34.听觉假体设置114可以包括具有刺激通道的频带的最小刺激水平和最大刺激水平的映射。然后,该映射由听觉假体110使用以控制要提供的刺激的数量。比如,在听觉假体110是耳蜗植入物的情况下,该映射基于所接收的声音输入来影响刺激耳蜗植入物的哪些电极以及刺激数量大小。在一些示例中,听觉假体设置114包括接受者可选择的两个或更多个预先定义的设置分组。两个或更多个预先定义的设置分组中的一个预先定义的设置分组
可以是默认设置。
35.听觉假体设置114还可以包括声音处理设置,该声音处理设置在声音输入被转换成刺激信号之前修改声音输入。这样的设置可以包括例如特定音频均衡器设置可以提高或降低各种频率下的声音强度。在各示例中,听觉假体设置114可以包括所接收的声音输入引起刺激的最小阈值、用于防止刺激超过会引起不适的水平的最大阈值、增益参数、响度参数、以及压缩参数。听觉假体设置114可以包括影响听觉假体110所产生的动态刺激范围的设置。如上文所描述的,许多听觉假体设置114影响听觉假体110的物理操作,诸如听觉假体110如何响应于从环境101接收的声音输入而向接受者提供刺激。在美国专利号9,473,852和9,338,567中描述了设置、设置修改和预处理的示例,其出于任何目的和所有目的通过引用整体并入本文。
36.示例系统—计算设备
37.计算设备120是与听觉假体110的接受者相关联的计算设备。在许多示例中,计算设备120是蜂窝电话、平板电脑、智能手表、或心率监测器,但是可以采用其他形式。尽管主要在接受者的背景下对计算设备120进行描述,但是该计算设备120可以是父母或接受者的看护者拥有或主要使用的计算设备。计算设备120可以诸如经由通过网络102通信的听觉假体应用124与服务器170通信。在所示出的示例中,计算设备120包括计算设备换能器集122和听觉假体应用124。
38.计算设备换能器集122是获得数据的计算设备120的一个或多个部件的组。计算设备换能器集122可以包括一个或多个传感器,诸如麦克风、加速计、陀螺仪传感器、位置传感器、生物传感器(例如,心率或血压传感器)、以及光传感器等。计算设备换能器集122可以包括设置在计算设备120的壳体内的部件以及(例如,经由有线连接或无线连接)电耦合到计算设备120的设备。在一些示例中,计算设备换能器集122包括软件传感器,诸如从一个或多个数据流(例如,从计算设备120流式传输到听觉假体110的音频)获得数据的软件。计算设备换能器集122还可以包括传感器,该传感器获得关于计算设备120本身的使用方式的数据。
39.在各示例中,计算设备120包括听觉假体应用124,该听觉假体应用124在计算设备120上操作并且与听觉假体110协作。听觉假体应用124是作为计算机可执行指令存储在计算设备120的存储器中的计算机程序,该计算机程序当被执行时,执行与听觉假体110有关的一个或多个任务。比如,听觉假体应用124可以控制听觉假体110(例如,通过自动或基于在计算设备120处从接受者接收的输入来修改听觉假体设置),监测听觉假体110的使用,并且从听觉假体110获得数据。计算设备120可以使用例如无线射频通信协议(例如,蓝牙)连接到听觉假体110。听觉假体应用124可以通过这种连接从听觉假体110传输或接收数据。听觉假体应用124可以用于将音频诸如从计算设备换能器集122的麦克风或在计算设备120上运行的应用(例如,视频或音频应用)流式传输到听觉假体110。在其他示例中,在计算设备120上运行的另一应用可以将音频流式传输到听觉假体110。在示例中,听觉假体应用124通过获取关于听觉假体110的数据来用作计算设备换能器集122的一部分。
40.示例系统—换能器
41.多个换能器150中的换能器150是响应于所检测的条件而产生换能器信号160的部件。在一个示例中,换能器150可以包括以下种类的换能器中的一个或多个换能器:被配置
为提供移动传感器信号的一个或多个移动传感器、被配置为提供身体噪声信号的一个或多个植入的麦克风、被配置为提供耳声发射信号的一个或多个耳声发射传感器、被配置为提供植入电极传感器信号的一个或多个植入的电极、被配置为提供外部电极传感器信号的一个或多个外部电极(例如,头戴式电极或粘附电极)、被配置为提供eeg信号的一个或多个eeg(脑电图)传感器、被配置为提供与程序操作有关的信号的一个或多个程序传感器、以及被配置为提供一个或多个外部麦克风信号的一个或多个外部麦克风。移动传感器可以是多种不同种类的移动传感器中的任一移动传感器。例如,移动传感器可以包括加速度计或陀螺仪,诸如听觉假体110或计算设备120的加速度计或陀螺仪。换能器150可以位于系统100中的多种位置中的任一位置。例如,如所示出的,换能器150包括听觉假体换能器集112和计算设备换能器集122。换能器150可以位于其他地方,诸如位于接受者所佩戴的可穿戴换能器(例如,如可以在智能手表中找到)中。
42.如所示出的,换能器150可以包括换能器150的两个或更多个子组,诸如第一换能器152和第二换能器154。这些组可以指示换能器150的任何物理或逻辑划分。在一个示例中,第一换能器152是被配置为产生第一换能器信号162的第一换能器150,该第一换能器信号162指示在接受者附近是否正在发生音乐活动10。在一个示例中,第二换能器154是被配置为产生第二换能器信号164的换能器150,该第二换能器信号164指示接受者的音乐感知。在各示例中,各组之间可以存在重叠(例如,同一换能器可以位于换能器的多个子组中)。在其他示例中,各组不会重叠。
43.换能器信号160中的换能器信号160是由换能器150产生的数据。依据产生换能器信号160的换能器150的配置,换能器信号160可以采取多种不同形式中的任一形式。当在整个系统100中使用并移动换能器信号160时,换能器信号160的形式和特点可以发生改变。例如,换能器信号160可以从实时模拟信号开始,该实时模拟信号在换能器150内被转换为实时数字信号,然后,该实时数字信号以实时数据分组的形式传输到听觉假体应用124,以批量发送(例如,非实时)到服务器170。附加地,当在整个系统100中使用并移动换能器信号160时,可以对换能器信号160进行处理。比如,换能器信号160可以转换为标准化格式,并且附加有相关元数据(例如,时间戳、换能器标识符等)。
44.示例系统—服务器
45.服务器170是远离听觉假体110的服务器计算设备以及计算设备120。服务器170经由网络102通信耦合到计算设备120。在许多示例中,服务器170通过计算设备120(例如,经由听觉假体应用124)间接通信耦合到听觉假体110。在一些示例中,服务器170直接通信耦合到听觉假体110。在某些实现方式中,听觉假体110和计算设备120可以被认为是服务器170的客户端设备。在一些示例中,服务器170所提供的功能性或其部件(例如,指令172和模板180)可以由接受者(例如,计算设备120或听觉假体110)本地的设备提供或位于其上。听觉假体应用124可以是被配置为与服务器170交互的客户端应用。服务器170包括处理单元802和存储器804,其在图8中进行更详细地描述。服务器170还包括指令172以及存储在存储器804中的一个或多个模板180。
46.指令172是处理器可执行程序指令,当由处理单元802执行时,处理器可执行程序指令使得处理单元802执行动作或操作,诸如图2至图4的过程中所描述的动作或操作。
47.一个或多个模板180中的模板180可以是例如参考、比较器或变换器,可以使用或
针对该参考、比较器或变换器对所获得的数据(例如,信号或指示)进行处理。比如,模板180可以包括定义换能器信号的值的数据结构,该换能器信号的值是或不是接受者是否响应音乐的指示。模板180可以包括相对于特定接受者进行个性化或非个性化的模板180。例如,在试穿听觉假体110期间,接受者可以暴露于音乐,测量(例如,如经由换能器150测量的)接受者的客观反应,并且将该客观反应存储为未来换能器信号160可以与之进行比较的接受者的经个性化的模板180。在另一示例中,测量了多个人(例如,在统计学上具有显着性的样本量的人)对音乐的客观反应,并且将该客观反应存储为特定个体可以与之进行比较的模板。进一步地,一个或多个模板180可以由一个或多个临床医生创建或策划。模板180可以采取多种不同形式,这些形式包括一个或多个阈值182和一个或多个机器学习框架184。
48.在一些示例中,一个或多个模板180包括换能器信号160或指示可以与之进行比较的一个或多个阈值182。阈值182可以描述例如换能器信号160可以与之进行比较以用于本文中所描述的过程的范围或特定值。比如,阈值182可以定义节奏范围,在该节奏范围中,重复行为被认为指示音乐活动(例如,范围在0.4hz与4hz之间的节奏可以指示随着所感知的音乐而跳舞、鼓掌、或以其他方式移动)。
49.在各示例中,模板180包括经训练的机器学习框架184,该经训练的机器学习框架184被配置为接收换能器信号160作为输入并且基于其来提供输出(例如,感知音乐的能力的指示)。在各示例中,经训练的机器学习框架184包括神经网络。
50.机器学习框架184是软件以及实现机器学习能力的相关数据。在许多示例中,机器学习框架184包括两个主要部件:机器学习模型和接口。机器学习模型是学习的结构化表示,诸如学习的实现方式和学习的内容。例如,在机器学习模型包括神经网络的情况下,机器学习模型可以定义神经网络的表示(例如,神经网络的节点、节点之间的连接、所关联的权重、以及其他数据),诸如经由一个或多个矩阵或其他数据结构。在另一示例中,在机器学习模型包括决策树的情况下,机器学习模型可以定义决策树(例如,决策树的节点及其之间的连接)。机器学习模型可以包括许多不同类型的机器学习技术。例如,机器学习模型可以定义许多不同的神经网络、决策树和其他机器学习技术及其之间的连接。比如,第一神经网络的输出可以流到第二神经网络的输入,其中第二神经网络的输出流到决策树中以产生最终输出。该接口定义与模型结合使用的软件接口。例如,接口可以定义用于向机器学习模型提供输入、从该机器学习模型接收输出,训练该机器学习模型,并且维护该机器学习模型的功能和过程。机器学习框架184的一个或多个方面可以使用机器学习工具包来实现,诸如:加利福尼亚州山景城的google inc.的tensorflow;加利福尼亚旧金山的openai的openai gym;或华盛顿州雷德蒙市的microsoft corp.提供的microsoft azure machine learning。
51.机器学习框架184可以被训练或以其他方式配置为接收数据(例如,来自一个或多个换能器150的一个或多个换能器信号160)作为输入并且基于其来提供输出。例如,机器学习框架可以被训练并配置为接收加速度计和陀螺仪信号作为输入并且提供信号是否指示接受者是否有能力感知音乐(例如,接受者是否正在响应音乐)的指示。
52.示例过程
53.图2至图4示出了针对听觉假体110的接受者的音乐感知而采取治疗动作的示例过程。该过程可以使用诸如图1中所描述的系统之类的系统来执行。过程的一个或多个方面
(例如,其操作中的一个或多个操作)可以被实现为作为指令172的一部分存储的一个或多个指令。
54.示例过程—第一示例过程
55.图2示出了用于针对听觉假体110的接受者的音乐感知而采取治疗动作的第一示例过程200。如所示出的,过程200开始于操作210。
56.操作210包括确定音乐活动10的发生。在一个示例中,操作210包括:使用来自一个或多个第一换能器152的第一换能器信号262确定音乐活动10在听觉假体110的接受者附近的发生。可以以多种方式中的任一方式来确定音乐活动10在接受者附近的发生。在一个示例中,基于听觉假体110的场景分类器的确定,听觉假体110在音乐特定的声音处理模式下进行操作,可以响应于此来确定音乐活动10的发生。在一个示例中,可以响应于从接受者(例如,在计算设备120处)接收到指示正在发生音乐活动10的输入而确定音乐活动的发生。
57.作为另一示例,操作210可以包括:基于位置数据来确定音乐活动10在接受者附近的发生。位置数据可以用于确定接受者是否处于可能发生音乐活动10的位置(例如,音乐会场所或可能具有背景音乐的餐馆)。在一个示例中,位置数据可以包括计算设备120所生成的基于卫星的位置数据(例如,基于gps的位置数据)。在另一示例中,该位置数据基于附近无线广播,诸如wi
‑
fi ssid(服务集标识符)。这样的无线广播可以用于确定当前位置以及当前位置类型。比如,当听觉假体110正在在音乐场所中操作时,计算设备120可以检测被称为“音乐场所wi
‑
fi”的wi
‑
fi ssid,该wi
‑
fi ssid可以用作音乐活动10正在发生的指示。
58.在一个示例中,换能器信号160可以用于确定音乐活动10的发生。比如,外部麦克风(例如,听觉假体换能器集112的外部麦克风)可以产生指示声音环境在接受者附近的音频换能器信号。可以(例如,在听觉假体110、计算设备120、服务器170或其组合处)分析音频换能器信号。在一个示例中,可以分析音频换能器信号以确定音频换能器信号的质量是否指示音乐活动10的发生。例如,可以(例如,使用模板180)分析音频换能器信号的频率、幅度调制和频谱扩展来确定是否满足指示音乐活动的发生的可能性阈值。在另一示例中,可以分析音频换能器信号以不仅确定是否正在发生音乐活动10,而且还确定音乐活动10的种类以及与关于该音乐活动10的元数据的标识。种类和元数据可以通过例如对音频换能器信号执行音频指纹识别以标识正在播放的特定音乐内容,并然后基于标识符来获得元数据来确定。执行音频指纹识别可以包括:将音频换能器信号的一部分作为输入传输到音频指纹识别服务(例如,如可以由gracenote、shazam或soundhound提供的),并且从中接收作为输出的音乐活动10的标识(如果可用)和与音频换能器信号有关的元数据。
59.在各示例中,模板180包括与确定音乐活动10的发生有关的一个或多个模板。例如,可能存在与频谱特点或节奏有关的一个或多个阈值182,当满足时,该一个或多个阈值指示发生了音乐活动10。在另一示例中,模板包括一个或多个机器学习框架184,该一个或多个机器学习框架184被训练为接收作为输入的换能器信号160并且提供关于是否发生了音乐活动10的预测作为输出。
60.音乐活动10的发生可以基于诸如操作212中所描述的数据流之类的数据流。
61.操作212包括:检测212从计算设备120提供给听觉假体110的音乐数据流214。音乐数据流214是引起接受者的听觉感知的从源(例如,计算设备120)到听觉假体110的音乐数据流。音乐数据流214可以采取多种形式,并且可以以多种方式中的任一方式提供给听觉假
体110。在一个示例中,音乐数据流214可以是在计算设备120(例如,智能电话)与听觉假体110之间通过射频连接(例如,经由蓝牙或wi
‑
fi)的数据流。音乐数据流214可以以多种方式中的任一方式来检测。在一个示例中,听觉假体110检测音乐数据流214,并且提供换能器信号160,该换能器信号160指示听觉假体正在接收音乐数据流214。在一个示例中,计算设备120检测到计算设备120正在提供音乐数据流214并且提供指示它正在将音乐数据流214提供给听觉假体110的换能器信号160。在一个示例中,听觉假体应用124提供音乐数据流并且检测音乐数据流214。关于音乐数据流的信号160还可以包括关于音乐数据流214的元数据,诸如音乐数据流214所提供的音乐活动10的歌曲名称、艺术家、专辑或流派。响应于检测212到音乐数据流214正在提供给听觉假体,确定发生了音乐活动10。在操作210之后,过程200的流程可以移至操作220。
62.操作220包括:确定接受者感知音乐活动10的能力的指示222。在一个示例中,响应于在操作210中确定音乐活动10的发生,执行操作220。通过响应于检测到音乐活动10而执行操作220,可以通过避免使用资源来确定音乐不存在时接受者感知音乐的能力来节省计算资源(例如,网络带宽、处理周期和电池寿命)。在其他示例中,无论是否检测到音乐活动10,执行操作220都是有益的。例如,可以执行在没有检测到音乐活动10的情况下执行操作220,以获得未来数据可以与之进行比较的否定数据。换句话说,对于系统100而言,获得关于音乐活动10没有发生时接受者如何表现的数据以更好确定音乐活动10正在发生时接受者如何表现是有益的。
63.可以基于接受者是否(并且在一些实现方式中,在多大程度上)有能力感知音乐活动10来确定指示222。在一个示例中,接受者感知音乐的能力的指示222是与接受者是否有能力感知音乐有关并且暗示了接受者是否有能力感知音乐的数据。暗示性可以相对于阈值182(例如,数据更有可能只是接受者有或没有能力感知音乐活动10)。指示222的确定可以采取多种形式。在一个示例中,指示222可以仅包括接受者是否已感知音乐活动10的二进制指示。在另一示例中,指示222可以包括接受者有能力感知音乐的相对程度。在又一示例中,指示222可以包括关于指示222和音乐活动10的元数据。在一些实现方式中,可以确定每个音乐活动10的单个指示222。在其他实现方式中,每个音乐活动10可以有多个指示222。比如,指示222可以包括或基于来自多个换能器150的换能器信号160的聚合,或所接收的与音乐活动10有关的每组换能器信号160可能有一个指示222(例如,对于单个音乐活动10,接受者没有感知到音乐活动10的指示222可以基于麦克风数据,而接受者正在感知音乐活动10的指示222可以基于移动数据)。确定指示222可以包括:使用来自换能器150的换能器信号160(诸如来自一个或多个第二换能器154的第二换能器信号164)。可以分析与音乐活动10同时发生的换能器信号160,以确定是否存在接受者感知到音乐活动10的指示222。
64.作为一个示例,操作220可以包括:基于呼吸速率或心率的改变来确定指示222,该呼吸速率或心率的改变可以与诸如个体随着音乐而跳舞、演唱或其他互动的剧烈程度之类的活动速率有关。这种确定可以基于换能器信号160,诸如与呼吸活动有关的声音和从换能器150(诸如可植入麦克风)获得的血液流动。
65.作为另一示例,操作220可以包括:基于神经激活来确定指示222。神经激活可以指示对音乐的情感或高水平互动或对音乐的感知。该确定可以基于诸如传感器或eeg信号之类的换能器信号160,该换能器信号160被处理为计算来自诸如可植入电极或eeg传感器之
类的换能器150的特定频谱带(例如,诸如α、β、γ、δ波的皮质频带)中的功率。
66.作为另一示例,操作220可以包括:基于某些种类的说话、演唱、说唱或哼唱(诸如可以从所接收的麦克风信号的速率、音量、持续时间、基频、音高和频谱特性中确定的说话、演唱、说唱或哼唱)来确定指示222。
67.作为另一示例,操作220可以包括:基于从接受者接收的用户输入来确定指示222。例如,操作220可以包括:响应于确定音乐活动10的发生,向接受者发送通知,以向接受者询问关于音乐活动10的一个或多个问题,诸如接受者是否可以听到音乐活动10以及接受者如何评价他或她对音乐活动10的体验。来自接受者的响应可以用于确定指示222。
68.作为另一示例,操作220可以包括:基于移动传感器信号来确定指示。例如,基于换能器信号160,可以确定接受者正在将他或她的头或手及时移动到音乐的指示222。关于操作224对这种确定方式进行更详细的描述。
69.可以以多种方式分析换能器信号160以确定指示222。例如,换能器信号160可以与模板180进行比较。可以预先定义模板180,可以基于接受者的响应的先前记录来学习该模板180,或可以基于其他个体的响应的先前记录学习该模板180。在一些示例中,模板可以定义已知音乐的特征(例如,节奏、旋律)。例如,移动信号可以与已知或同时检测的音乐信号的特征进行比较,使得可以确定接受者的运动的频率是否与音乐的节奏的频率相似或接受者是以与音乐的旋律和谐的方式演唱还是与音乐的人声同步。以这种方式,指示222不仅可以包括接受者是否感知到音乐活动10,而且可以包括接受者有能力感知到音乐活动10的程度。比如,可以比较接受者演唱与音乐活动10本身之间的谐和性(harmony)。音乐信号可以以多种方式中的任一方式(诸如上文在操作210中所描述的方式)来检测。另外或取而代之的是,接受者的活动可以与已知正在经历相同音乐活动10的其他个体的活动进行比较。比如,可以确定接受者是否正在以与舞伴或快闪族的另一成员类似的方式移动。这种确定可以导致确定指示222。
70.在一些示例中,操作220包括操作224和操作226。
71.操作224包括:将在一频率下的重复行为标识为音乐行为。例如,因为重复行为可以指示随着所感知的音乐而跳舞、鼓掌或以其他方式移动,所以响应于频率在典型音乐节奏范围(例如,0.4hz至4hz)内,这种行为可以被标识为音乐行为。这种行为可以使用来自一个或多个移动换能器的信号来标识。在另一示例中,响应于频率与在操作210中标识的音乐活动10的频率相匹配(例如,在阈值量之内)的音乐行为,重复行为可以被标识为音乐行为。在操作224之后,流程可以移至操作226。
72.操作226包括:基于音乐行为来确定接受者是否有能力感知音乐活动10。例如,响应于重复行为被标识为音乐行为,指示222被确定为接受者有能力感知音乐活动10。在一些示例中,响应于重复行为被标识为非音乐行为,指示222被确定为接受者无能力感知音乐活动10。在一个示例中,运动的程度用于确定与音乐活动10的互动程度(例如,更多的运动意味着与音乐活动的互动更多)。
73.在一些示例中,操作226包括:确定接受者是否正在对听觉提示或另一感觉所提供的提示做出反应。例如,在一些实例中,重复行为或来自接受者的另一响应可能受到非听觉提示的影响,并非受到接受者通过听觉假体110感知音乐活动10的影响。比如,接受者可能正在响应其他人围绕接受者的移动(例如,接受者基于看到其他鼓掌而非听到节拍而合着
音乐鼓掌)或由音乐可视化器或与音频一起播放的视频(例如,接受者可能会通过观看音乐视频而非聆听音乐来响应视觉提示)所提供的视觉提示。作为另一例子,接受者可以感觉音乐(例如,通过物理感觉音乐的低音成分或通过感觉舞伴的移动)并且响应触觉而非音乐的听觉成分。如此,操作226可以包括:确定接受者是否以及在多大程度上可能受到非音频提示的影响;以及在生成指示222时使用这种确定。比如,操作220可以确定接受者正在响应音乐活动10,但是可以确定响应由于非音频提示而引起。响应于这种确定,指示222可以被设置为指示接受者不能感知音乐活动10或与可能已经以其他方式指示的情况相比,接受者不太能感知音乐活动10。可以通过使用换能器150测量非音频提示来确定非音频提示。例如,相机可以用于测量是否以及在多大程度上存在视觉提示。在另一示例中,换能器150可以用于确定接受者是正在观看音乐视频(例如,可以提供视觉提示)还是正在经由耳机聆听音乐(例如,其可以指示接受者没有感觉到来自扬声器的低音)。补偿由非听觉提示引起的行为可以通过改善过程200所使用的数据质量来提高准确性。
74.在操作220之后,过程200的流程可以移至操作230。
75.操作230包括:使用一个或多个指示222来生成对接受者的音乐感知的分析232。换能器信号160、指示222和其他相关数据可以在听觉假体110上、与接受者(例如,移动电话)相关联的计算设备120、或用于形成对接受者的音乐感知的分析232的服务器170上聚合。在各示例中,分析232是表示基于换能器信号160、指示222以及关于接受者的音乐感知的其他相关数据而生成的结论或推论的数据。分析232可以基于与一个或多个音乐活动10有关的一个或多个指示222来生成。分析232可以基于随着时间而对指示的比较(诸如接受者的音乐感知如何改变)来生成。在一个示例中,在临床就诊期间(例如,在听觉假体110的初始试戴期间或在检查预约期间)测量接受者的音乐感知,以产生初始指示222,并且随后指示222与初始指示进行比较,并且包括在分析232中。
76.在一个示例中,使用决策树或决策规则生成分析232,该分析232描述了要基于特定指示得出的推论或结论。比如,决策规则可以指定响应于指示222指示接受者没有感知到具有特定人声类型的歌手的音乐活动10,在分析232中包括接受者难以感知具有特定人声类型的歌手的音乐活动10。
77.分析232可以包括度量,诸如与音乐活动10的互动的总数、与音乐活动10的错过互动的总数、每天的互动的总数、错过互动的比率以及平均互动等级。附加地,可以计算这种度量的趋势。趋势可以揭示接受者的听觉健康方面的有用信息,诸如确定接受者的好转或下降。这种趋势信息对于确定接受者的治疗选项。如果检测到或得知度量,则可以基于音乐信号的质量(诸如主导频率、节奏、音量、流派、歌手(例如,男歌手、女歌手、年龄、口语、口音等))来对度量进行细分。通过允许在接受者如何感知特定音乐特征的基础上得出结论,细分还可以增强分析。例如,分析232可以包括度量,该度量指示与男高音人声范围相比较,接受者能够更好地感知具有男中音人声范围的歌手所演唱的音乐。
78.在操作230之后,过程200的流程可以移至操作240。
79.操作240包括:基于分析232来采取与接受者有关的治疗动作242。在一个示例中,治疗动作242是与治疗与接受者的听觉系统相关联的医疗条件有关的动作。基于分析232,可以确定或推荐各种治疗动作242。在一个示例中,治疗动作242包括:诸如向临床医生(例如,以帮助指导治疗)或看护者(例如,以帮助向看护者保证听觉假体110按照预期运转)报
告听觉假体110关于音乐的表现质量。在一个示例中,治疗动作242包括:提供估计接受者感知音乐的能力的度量。在一个示例中,治疗动作242包括:推荐纠正动作。
80.在一个示例中,治疗动作242包括:与接受者和音乐互动的能力和接受者的音乐偏好相关地推荐一首或多首音乐。在一个示例中,治疗动作242推荐纠正动作(例如,诸如通过从单侧假体前进到双侧假体重新配置、重新编程或修改治疗)。
81.治疗动作242还可以包括:使用分析232(例如,其度量)作为音乐康复训练程序的输入。音乐康复程序可以采取多种形式中的任一形式。在一个示例中,康复游戏是cochlear ltd的bring back beat智能手机应用。康复程序可以按递增方式提供更具挑战性的音乐(例如,从每分钟节拍低的音乐过渡到每分钟节拍高的音乐)。分析232可以用于设置提供给接受者的音乐的相对难度水平。进一步地,接受者对康复程序的使用可以用作用于执行本文中所描述的过程的输入数据。
82.在一个示例康复程序中,康复者(例如,执行康复任务的人或软件)向接受者提供或推荐音乐。然后,换能器信号160可以用于确定接受者的音乐感知水平和关于康复者所提供或推荐的音乐的薄弱区域。然后,音乐内容的递送基于接受者的音乐感知水平来修改以训练接受者。比如,修改可以集中在接受者的音乐感知的特定薄弱区域(例如,如基于分析232而确定的)上。修改可以包括:增加康复者所提供或推荐的音乐的复杂性(例如,通过从音乐中添加或减去人声或乐器)或更改音乐的音频信号的质量(例如,通过在音乐中引入中断或添加噪声或失真)。分析232可以包括对接受者的音乐感知的估计(例如,接受者感知和与音乐互动的能力),并且据此推荐几首新音乐。例如,这些新音乐可以基于音乐信号相对于个体能力(例如,较难但不令人生畏)的困难程度和接受者的音乐偏好(例如,流派)。可以增加这些新音乐的相对难度。
83.在另一示例康复程序中,康复者提示接受者演唱或哼唱音乐内容,并且性能与客观参考进行比较。在另一示例中,康复者可以指令接受者标识音乐内容项。在又一示例中,修复者可以尝试基于接受者演唱或哼唱音乐内容的曲调来标识音乐内容。
84.在另一示例中,通过基于参与康复来向接受者提供奖励以增加互动来使用康复过程的游戏化。在其他示例中,接受者的音乐偏好用于修改康复程序,使得接受者更有可能享受并继续参与康复。
85.在另一治疗动作中,通过基于音乐作品的演唱或哼唱来使个体再现测试音乐作品的保真度。虽然康复程序可以被配置为直接改善接受者的音乐感知,但是还可以使用间接途径,诸如通过测量并训练接受者的演唱或音高发音能力。
86.在一些示例中,操作240包括操作244。
87.操作244包括:通过改变听觉假体110的一个或多个设置来修改听觉假体110的治疗操作。例如,基于分析232,可以确信听觉假体设置114为次优,从而引起接受者关于音乐的听觉感知并且可以确信对听觉假体设置114的一个或多个改变可以改善听觉假体关于音乐的性能。基于该确定,一个或多个改变可以(例如,通过报告)提供给接受者或临床医生或(例如,经由听觉假体应用)提供给听觉假体110本身。然后,改变听觉假体设置114,从而修改了听觉假体110的进行中操作。在一些示例中,改变场景特定听觉假体设置114。比如,与音乐模式(例如,如由听觉假体的场景分类器确定的)相关联的听觉假体设置114被改变,而在其他模式中并不改变。该场景特定途径可能是有利的,因为改善听觉假体110产生接受者
可理解的基于音乐的听觉感知能力的改变可能对听觉假体110产生接受者可理解的基于语音的听力感知伴有不利影响。
88.示例过程—第二示例过程
89.图3示出了用于针对听觉假体的接受者的音乐感知而采取治疗动作的第二示例过程300。在各示例中,过程300开始于操作310。
90.操作310包括在服务器170处维护一个或多个模板180,该一个或多个模板180定义换能器信号160与音乐感知之间的关联。维护模板180可以包括:以可用形式将模板180存储在服务器170可访问的存储器(例如,存储器804)中。在各示例中,操作310包括操作312。
91.操作312包括:生成或更新一个或多个模板180。在一个示例中,操作312包括:从用户(例如,临床医生)接收一个或多个模板180。操作312可以包括:使用与多个个体有关的换能器信号160来生成或更新一个或多个模板180。例如,操作312可以包括:聚合与多个个体有关的换能器信号160并且在其上手动或自动生成模板180。比如,使用聚合的换能器信号160,可以确定具有特定特点的移动数据指示对音乐活动10的响应。因此,可以生成模板180,该模板指定如果未来接收到具有这些特定特点的移动数据,则应当确定接受者有能力感知音乐活动的指示222。可以使用对所接收的换能器信号160的统计分析来生成一个或多个模板180。
92.在各示例中,操作312包括:训练模板180的一个或多个机器学习框架184。依据所使用的机器学习模型类型,训练机器学习框架184可以以多种不同方式中的任一方式发生。通常,训练可以以下方式发生。首先,获得训练数据以用于训练机器学习模型。训练数据通常是可用于训练机器学习框架的具有已知训练输入和期望训练输出的人策划数据集合或机器策划数据集合。在操作312的情况下,训练数据可以包括来自许多不同个体的策划换能器信号160以及实际或预期输出。一般而言,训练包括:使用机器学习框架184的接口将训练输入作为输入提供给机器学习的学习框架184。机器学习框架184使用机器学习模型处理输入并且产生输出。然后,基于机器学习模型的实际输出与预期输出(例如,与所提供的训练输入相对应的训练输出)之间的比较,损失函数用于计算损失值。基于损失值来修改机器学习模型的属性(例如,机器学习模型中的连接的权重),从而训练模型。对于大量训练数据,该训练过程继续进行,直至损失值足够小。在各示例中,经训练的机器学习框架184使用验证输入输出数据(例如,期望输出与不同于训练数据的特定输入相对应的数据)来验证,并且在成功验证之后,机器学习框架184用于生产。类似过程可以用于训练一个或多个机器学习框架184,以产生与分析232或治疗动作242有关的输出。
93.在操作310之后,过程300可以移至操作320。
94.操作320包括:在服务器170处接收接受者换能器信号160。例如,可以从计算设备120或直接从换能器150本身接收换能器信号160。接受者换能器信号160与听觉假体110的接受者相关联。可以从一个或多个设备的一个或多个换能器150接收换能器信号160。
95.在一些示例中,换能器信号160从换能器150或与其相关联的设备推送到服务器170。在其他示例中,服务器170向换能器150或与其相关联的设备发送请求以获得换能器信号160。
96.在一些示例中,计算设备120在被发送到服务器170之前收集换能器信号160。在一些示例中,计算设备120周期性地从计算设备换能器集122和与其相关联的其他换能器150
或设备获得读数。在一些示例中,计算设备120响应于请求(例如,从听觉假体应用124接收的请求)而获得读数。计算设备120可以收集多种频率的换能器信号160,并且换能器信号160的数量同样可以改变。比如,在一些示例中,换能器信号160的获得和传输在没有实质性延迟的情况下发生。在其他示例中,包括换能器150的设备(例如,听觉假体110)可以批量获得并存储换能器信号160,并且将换能器信号160不太频繁地传输到计算设备120或服务器170。
97.在操作320之后,过程300的流程可以移至操作330。
98.操作330包括:使用模板180和接受者换能器信号160来生成对接受者的音乐感知的分析232,如相对于关于图2的操作220和操作230所描述的。在一些示例中,操作330包括操作332和操作334。在一些示例中,操作330包括操作336和操作338。
99.操作332将接受者换能器信号160提供给经训练的机器学习框架184作为输入。操作332可以包括例如从一个或多个机器学习框架184中选择机器学习框架184。该选择可以基于例如换能器信号160的类型。在一些示例中,选择一个以上的机器学习框架184。在一些示例中,可以将来自多个不同换能器150的换能器信号160组合在一起(例如,级联)以将输入数据形成到机器学习框架中。操作332还可以包括:对换能器信号160进行预处理以与机器学习框架184一起使用。比如,换能器信号160可以被放置到机器学习框架184的特定格式中。比如,机器
‑
学习框架184可以被配置为接收矢量格式的输入数据,并且换能器信号160可以被转换为这种格式,以准备提供换能器信号160作为输入。在各示例中,可以使用机器学习框架184的接口或与机器学习框架184的接口协作来执行转换和提供。在一个示例中,该接口提供将换能器信号160转换为有用格式然后提供经转换的信号作为机器学习框架184的机器学习模型的输入的功能。在操作332之后,过程300的流程可以移至操作334。
100.操作334包括:从经训练的机器学习框架184接收334接受者接收音乐的能力的指示222作为输出。例如,机器学习框架184的接口可以从模型接收输出,将输出转换为指示222,然后提供指示222作为输出。然后,指示222可以用于诸如使用结合操作230所描述的技术中的一种或多种技术生成分析232。
101.操作336包括:比较接受者换能器信号160与阈值182。在操作336之后,过程的流程可以移至操作338。操作338包括:响应338于接受者换能器信号160满足阈值182,确定接受者有能力感知音乐。
102.在操作330之后,过程300的流程可以移至操作240。
103.操作240包括:基于分析232来采取与听觉假体110有关的治疗动作242。操作240可以具有如上文关于过程200所描述的操作240的特性。
104.示例过程—第三示例过程
105.图4示出了用于针对听觉假体的接受者的音乐感知而采取治疗动作的第三示例过程400。在所示出的示例中,过程400开始于操作410。
106.操作410包括:从与听觉假体110的接受者相关联的一个或多个换能器150收集换能器信号160。操作410可以包括与在本文中的操作320中所描述的技术类似的一种或多种技术。换能器信号160可以包括来自多种不同种类的换能器的信号。在一个示例中,操作410包括:从一个或多个移动传感器接收移动传感器信号。在一个示例中,接收移动传感器信号可以包括:从听觉假体的加速度计接收加速度计信号;从听觉假体的陀螺仪接收陀螺仪信
号;从接受者的移动设备的加速度计接收加速度计信号;或从接受者的移动设备的陀螺仪接收陀螺仪信号。在一个示例中,操作410包括:从植入的麦克风接收身体噪声传感器信号。在一个示例中,操作410包括:从植入的电极接收植入的电极传感器信号。在一个示例中,操作410包括:从外部麦克风接收外部麦克风信号。在操作410之后,过程400的流程移至操作420。
107.操作420包括:使用换能器信号160生成接受者的音乐感知的指示222。操作420可以包括:与本文中的操作330中所描述的技术类似的一种或多种技术。在一个示例中,移动传感器信号用于生成手部运动的指示。在一个示例中,身体噪声传感器信号用于生成接受者的血流活动的指示。附加地或取而代之的是,身体噪声传感器信号可以用于生成接受者的呼吸活动的指示222。在其他示例中,身体噪声传感器信号可以用于生成接受者语音活动的指示222。在一些示例中,植入的电极传感器信号用于生成脑干激活的指示。在其他示例中,植入的电极信号用于生成中脑或皮层激活的指示222。在各示例中,外部麦克风信号用于生成接受者的语音活动的指示222。在操作420之后,过程400的流程移至操作430。
108.操作430包括:使用指示222生成对接受者的音乐感知的分析232。操作430可以包括与本文中的操作340中所描述的技术类似的一种或多种技术。在一个示例中,生成分析232包括:比较指示222与一个或多个模板。在一个示例中,生成分析232包括:比较指示222与一首音乐(例如,与音乐活动10相关联的一首音乐)的特征。在一个示例中,生成分析232包括:比较指示222与取自其他个体的其他指示。在一个示例中,分析232包括度量。该度量可以包括例如描述与音乐互动的数目的度量、描述错过互动比率的度量、以及描述平均互动等级的度量。在一个示例中,根据诸如主导音乐频率、音乐节奏、音乐音量、音乐流派和音乐歌手类型之类的音乐质量对度量进行分类。在操作430之后,过程的流程可以移至操作240。
109.操作240包括:基于分析232来采取与听觉假体有关的治疗动作242。操作240可以具有如上文关于过程200所描述的操作240的特性。
110.示例听觉假体
111.如先前所描述的,听觉假体110可以采取多种形式中的任一形式。下文在图5至图7中对这些形式的示例进行更详细的描述。比如,听觉假体110可以是图5的耳蜗植入物系统510、图6的经皮骨传导设备600、或图7的透皮骨传导设备700。这些不同的听觉假体110可能受益于与上文所描述的系统和过程一起使用。比如,过程200可以用于定制听觉假体110以基于音乐输入来以至少关于引起听觉感知改进的方式运转。
112.听觉假体示例—耳蜗植入物系统
113.图5示出了可以受益于本文中所公开的技术的使用的示例耳蜗植入物系统510。耳蜗植入物系统510包括可植入部件544,该可植入部件544通常具有内部接收器/收发器单元532,刺激器单元520和细长引线518。内部接收器/收发器单元532准许耳蜗植入物系统510从外部设备550接收信号和/或向外部设备550传输信号。外部设备550可以是佩戴在头部上的按钮声音处理器,该按钮声音处理器包括接收器/收发器线圈530和声音处理部件。可替代地,外部设备550可以仅仅是传输器/收发器线圈,该传输器/收发器线圈与耳背式设备通信,该耳背式设备包括声音处理部件和麦克风。
114.可植入部件544包括内部线圈536,并且优选地包括相对于内部线圈536固定的磁
体(未示出)。该磁体可以与内部线圈536一起嵌入在柔韧硅酮或其他生物可相容密封剂中。所发送的信号通常与外部声音513相对应。内部接收器/收发器单元532和刺激器单元520(有时统称为刺激器/接收器单元)气密密封在生物可相容壳体内。所包括的磁体(未示出)可以便于外部线圈530和内部线圈536操作对准,从而使得内部线圈536能够从外部线圈530接收功率和刺激数据。外部线圈530包含在外部部分内。细长引线518具有近端,该近端连接到刺激器单元520;以及远端546,该远端546植入在接受者的耳蜗540中。细长引线518通过受者的乳突骨519从刺激器单元520延伸到耳蜗540。细长引线518用于基于刺激数据来向耳蜗540提供电性刺激。可以使用声音处理部件基于外部声音513以及基于听觉假体设置114来创建刺激数据。
115.在某些示例中,外部线圈530经由射频(rf)链路将电信号(例如,功率和刺激数据)传输到内部线圈536。内部线圈536通常是具有多匝电绝缘的单股或多股铂或金线的导线天线线圈。内部线圈536的电绝缘可以通过柔性硅酮模制来提供。各种类型的能量传送(诸如红外(ir)、电磁、电容和电感传送)都可以用于将功率和/或数据从外部设备传送到耳蜗植入物。虽然上述描述已经描述了由绝缘导线形成的内部线圈和外部线圈,但是在许多情况下,内部线圈和/或外部线圈可以经由导电迹线来实现。
116.听觉假体示例—经皮骨传导设备
117.图6是可以受益于本文中所公开的技术的使用的经皮骨传导设备600的示例的视图。例如,可以使用所公开的技术的一个或多个方面来定制设备600的听觉假体设置114。骨传导设备600位于该设备的接受者的外耳601背面。骨传导设备600包括声音输入元件626以接收声音信号607。声音输入元件626可以是麦克风、拾音线圈等。在本示例中,声音输入元件626可以位于例如骨传导设备600上或中,或位于从骨传导设备600延伸的电缆上。此外,骨传导设备600包括声音处理器(未示出)、振动电磁致动器、和/或各种其他操作部件。
118.更具体地,声音输入元件626将所接收的声音信号转换为电信号。这些电信号由声音处理器处理。声音处理器生成使得致动器振动的控制信号。换句话说,致动器将电信号转换成机械力以将振动赋予接受者的颅骨636。电信号到机械力的转换可以基于听觉假体设置114,使得不同的听觉假体设置114可以导致由相同声音信号607生成不同的机械力。
119.骨传导设备600还包括耦合装置640,该耦合装置将骨传导设备600附接到接受者。在所示出的示例中,耦合装置640附接到植入接受者中的锚系统(未示出)。示例性锚系统(也称为固定系统)可以包括固定到颅骨636的经皮基台。基台从颅骨636延伸穿过肌肉634、脂肪628和皮肤632,以使耦合装置640可以附接到该基台。这种经皮基台提供了用于耦合装置640的附接位置,该附接位置便于机械力的有效传输。
120.听觉假体示例—透皮骨传导设备
121.图7示出了具有可以受益于从本文中所公开的技术的使用的无源可植入部件701的透皮骨传导设备700的示例。透皮骨传导设备包括外部设备740和可植入部件701。可植入部件701包括安装在骨骼738上的无源板755,并且与位于外部设备740的壳体744中的振动致动器742经皮耦合。板755可以是永磁体的形式,或可以是生成磁场或对磁场起反应的另一形式,或以其他方式准许在外部设备740与可植入部件750之间建立足以保持外部设备740抵靠接受者的皮肤732的磁性吸引。
122.在一个示例中,振动致动器742是将电信号转换为振动的部件。在操作中,声音输
入元件726将声音转换为电信号。具体地,透皮骨传导设备700将这些电信号提供给振动致动器742,或提供给处理电信号的声音处理器(未示出),然后将那些经处理的信号提供给振动致动器742。其中声音处理器处理电信号的形式可以基于听觉假体设置114来修改。振动致动器742将(经处理的或未经处理的)电信号转换为振动。因为振动致动器742机械耦合到板746,所以振动从振动致动器742传递到板746。植入的板组件752是可植入部件750的一部分,并且由铁磁材料制成,该铁磁材料的形式可以是永磁体,该永磁体生成磁场和/或对磁场起反应,或准许在外部设备740与可植入部件750之间建立足以保持外部设备740抵靠接受者的皮肤732的磁性吸引。因而,由外部设备740的振动致动器742产生的振动从板746跨越皮肤732、脂肪734和肌肉736传送到板组件752的板755。这可以由于振动通过组织的机械传导来实现,从而导致外部设备740与皮肤732直接接触和/或在两个板746、755之间产生磁场。在诸如基台之类的实体对象不会穿透皮肤的情况下,传送这些振动。
123.可以看出,在该示例中,植入的板组件752基本刚性地附接到骨固定装置757。但是,在该示例和其他示例中,可以使用其他骨骼固定装置。在这点上,可植入板组件752包括通孔754,该通孔754的轮廓而被设计为骨固定器757的外部轮廓。因此,通孔754形成轮廓被设计为骨固定装置757的暴露段的骨固定装置接口段。在一个示例中,段的尺寸和维度被设计为使得关于段至少存在滑动配合或过盈配合。板螺钉756用于将板组件752稳固到骨固定装置757上。板螺钉756的头部可以大于通过可植入板组件752的孔,因此板螺钉756将可植入板组件752可靠保持到骨固定装置757。与骨固定装置757接口的板螺钉756的部分基本上与下文更详细描述的基台螺钉相对应,所以准许板螺钉756容易适配到用于经皮骨传导设备中的现有骨固定装置中。在一个示例中,板螺钉756被配置为使得用于从骨固定装置757安装和/或从其移除基台螺钉的相同工具和程序可以用于从骨固定装置757安装板螺钉756和/或从骨固定装置757移除板螺钉756。在一些示例中,硅酮层759可以设置在板755与骨骼738之间。
124.示例计算系统
125.图8示出了通过其可以实现所公开的示例中的一个或多个示例的合适计算系统800的示例。可以适合与本文中所描述的示例一起使用的计算系统、环境或配置包括但不限于个人计算机、服务器计算机、手持式设备、膝上型设备、多处理器系统、基于微处理器的系统、可编程消费者电子产品(例如,智能电话)、网络pc、小型计算机、大型计算机、平板电脑、包括上述系统或设备中的任一系统或设备的分布式计算环境等。计算系统800可以是通过与一个或多个远程设备的通信链路在联网环境中操作的单个虚拟或物理设备。远程设备可以是听觉假体(例如,听觉假体110)、个人计算机、服务器、路由器、网络个人计算机、对等设备或其他公共网络节点。在各示例中,计算设备120和服务器170包括计算系统800的一个或多个部件或部件的变体。进一步地,在一些示例中,听觉假体110包括计算系统800的一个或多个部件。
126.在其最基本的配置中,计算系统800包括至少一个处理单元802和存储器804。
127.处理单元802包括可以获得并执行指令的一个或多个硬件或软件处理器(例如,中央处理单元)。处理单元802可以与计算系统800的其他部件通信并控制其性能。
128.存储器804是一个或多个基于软件或硬件的计算机可读存储介质,其可操作为存储处理单元802可以访问的信息。存储器804除其他事项外还可以存储处理单元802可以执
行以实现应用或使得执行本文中所描述的操作的指令、以及其他数据。存储器804可以是易失性存储器(例如,ram)、非易失性存储器(例如,rom)或其组合。存储器804可以包括暂态存储器或非暂态存储器。存储器804还可以包括一个或多个可移除或不可移除存储设备。在各示例中,存储器804可以包括ram、rom、eeprom(电可擦除可编程只读存储器)、闪存、光盘存储器、磁存储器、固态存储、或可用于存储信息以供稍后访问的任何其他存储器介质。在各示例中,存储器804包括经调制数据信号(例如,具有以在信号中编码信息的方式来设置或改变其特点中的一个或多个特点的信号),诸如载波或其他传送机制,并且包括任何信息递送介质。作为示例而非限制,存储器804可以包括诸如有线网络或直接有线连接之类的有线介质,以及诸如声学、rf、红外和其他无线介质或其组合的无线介质。
129.在所说明的示例中,系统800还包括网络适配器806、一个或多个输入设备808、以及一个或多个输出设备810。系统800可以包括其他部件,诸如系统总线、部件接口、图形系统、功率源(例如电池)、以及其他部件。
130.网络适配器806是提供网络访问的计算系统800的部件。网络适配器806可以提供有线网络方位或无线网络访问,并且可以支持多种通信技术和协议中的一种或多种通信技术和协议,诸如以太网、蜂窝、蓝牙、近场通信和rf(射频)。网络适配器806可以包括一个或多个天线以及被配置为用于根据一种或多种无线通信技术和协议进行无线通信的相关部件。
131.一个或多个输入设备808是计算系统800通过其接收来自用户的输入的设备。除了其他输入设备之外,一个或多个输入设备808还可以包括物理可致动的用户接口元素(例如,按钮、开关或转盘)、触摸屏、键盘、鼠标、笔和话音输入设备。
132.一个或多个输出设备810是计算系统800能够通过其向用户提供输出的设备。除了其他输出设备之外,输出设备810还可以包括显示器、扬声器、以及打印机。
133.应当领会,虽然上文已经示出并讨论了该技术的特定用途,但是按照该技术的许多示例,所公开的技术可以与多种设备一起使用。上文讨论并不意味着暗示所公开的技术仅适用于在与附图所示的系统类似的系统内实现。例如,虽然主要在听觉假体(例如,耳蜗植入物)的背景下对本文中所描述的某些技术进行描述,但是本文中所公开的技术通常可适用于医疗设备(例如,提供疼痛管理功能性或诸如深部脑刺激之类的治疗性电刺激的医疗设备)。一般而言,在不脱离本文中所公开的过程和系统的情况下,可以使用附加配置来实践本文中的过程和系统和/或可以排除所描述的一些方面。进一步地,本文中所描述的技术可以适用于确定接受者对诸如视觉刺激、触觉刺激、嗅觉刺激、味觉刺激或其他刺激之类的其他刺激的响应。同样,本文中所使用的设备不必限于听觉假体,而可以是被配置为支持人类感觉的其他医疗设备,诸如仿生眼。
134.本公开参考附图描述了本技术的一些方面,在这些附图中仅示出了可能方面中的一些可能方面。然而,其他方面可以以许多不同形式体现,而不应被解释为局限于本文中所阐述的各方面。相反,提供这些方面是为了使本公开透彻和完整,并且将可能方面的范围充分传达给本领域技术人员。
135.应当领会,相对于本文中的附图所描述的各个方面(例如,部分、部件等)并不旨在将系统和过程局限于所描述的特定方面。因而,在没有背离本文中所公开的方法和系统的情况下,附加配置可以用于实践本文中的方法和系统和/或可以排除所描述的一些方面。
136.同样,在公开了过程的步骤的情况下,出于说明本发明的方法和系统的目的而对那些步骤进行了描述,并不旨在将本公开局限于特定步骤顺序。例如,在没有脱离本公开的情况下,可以按不同次序执行步骤,可以同时执行两个或更多个步骤,可以执行附加步骤,并且可以排除所公开的步骤。进一步地,可以重复所公开的过程。
137.尽管本文中描述了特定方面,但是技术的范围不局限于那些特定方面。本领域技术人员将认识到本技术范围内的其他方面或改进。因此,仅作为说明性方面公开了特定结构、动作或介质。该技术的范围由所附权利要求及其中的任何等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1