基于深度学习的3D点云的对象检测和实例分割的制作方法
基于深度学习的3d点云的对象检测和实例分割
技术领域
1.本发明涉及基于深度学习的3d点云的对象检测和实例分割,并且具体地但不限于涉及使用深度学习在3d点云中的对象检测的方法和系统,涉及使用深度学习的3d点云的实例分割的方法和系统、用于在3d点云中的对象检测的深度神经网络系统、用于3d点云的实例分割的深度神经网络系统以及用于执行这些方法的计算机程序产品。
背景技术:
2.在图像处理中,实例分割是指对象检测的过程,其中检测图像中的特定对象(通常通过确定包含每个检测的对象的边界框并为每个标识出的对象创建像素掩模)。实例分割可以被认为是对象检测,其中输出是像素掩模,而不仅仅是边界框。因此,与旨在对图像中的每个像素进行分类的语义分割不同,实例分割旨在标记所确定的边界框中的像素。最近,基于所谓的掩模r-cnn深度学习方案的2d相机图像的快速且可靠的实例分割在解决真实世界的问题时得到越来越多的应用。然而,在诸如自主驾驶、机器人和某些医疗应用等许多应用中,需要被分析的传感器信息表示3d场景,而不是2d场景。这些3d应用程序依赖于光学扫描仪(例如,激光扫描仪,诸如于测量应用中使用的lidar,和在牙科中使用的口内扫描仪)生成的信息,光学扫描仪通常以点云的形式生成不均匀的3d体数据。这些数据不是以数据的同质网格(例如,像素或者-非光学3d扫描仪、例如ct扫描仪的情况-体素)的形式被结构化。
3.基于光学扫描仪的数据采集方案通常以点云数据集或简称为点云的形式生成3d体数据。点云的数据点可以表示对象的表面。通常,点云包括大量不均匀分布在3d空间中的点。3d空间可以包括数据点密集分布的区域、数据点稀疏分布的区域和根本没有数据点的区域(例如,对象“内部”的空的空间)。术语点云可以指任何类型的3d数据集,其中每个点都可以被表示为3d空间中的向量。这些点可以与其他属性(例如,颜色等)相关联。特殊类型的点云包括3d表面限定,例如三角形网格或多边形网格。
4.尽管基于点云的3d分析是一个快速发展的技术领域,但用于3d对象检测和实例分割的方案与其2d对应方案相比,仍处于起步阶段。目前,已知的解决3d实例分割的来源很少。qi等人在他们的文章“frustum pointnets for3dobject detection from rgb-d data(用于从rgb-d数据检测3d对象的截锥点网)”,ieee conference on computer vision and pattern recognition,pp.918
–
927(2018)中描述了涉及两个阶段的混合框架,其中在第一阶段中,在2d图像中检测对象的2d边界框,在第二阶段中,在部分由2d边界框界定的3d搜索空间中处理3d点云。同样,hou等人在他们的文章“3d-sis:3d semantic instance segmentation of rgb-d scans(3d-sis:rgb-d扫描的3d语义实例分割)”,arxiv preprint arxiv:1812.07003(2018)中描述了一个模型,其中首先2d图像由2d卷积网络处理。此后,将学习到的特征反向投影到体素化的点云数据上,其中,提取到的2d特征和几何信息相结合,以获得对象提案(object proposal)和每个体素的掩模预测。上述模型对2d图像和体素化的依赖性限制了这种方法的性能。
5.在另一种方法中,yi等人在他们的文章“generative shape proposal network for 3d instance segmentation in point cloud(点云中3d实例分割的生成形状提案网络)”,arxiv preprint arxiv:1812.03320(2018)中描述了一种合成分析策略,其中,不是直接确定点云中对象的边界框,而是使用条件变分自动编码器(cvae)。然而,gspn训练需要对cvae部分和基于区域的网络(其对提案执行分类、回归和掩模生成)进行相当复杂的单独两阶段的训练。
6.在又一种方法中,对象提案是基于聚类方案确定的。wang等人在他们的文章“similarity group proposal network for 3d point cloud instance segmentation(用于3d点云实例分割的相似度组提案网络)”,ieee conference on computer vision and pattern recognition,pp.2569
–
2578(2018)中描述了使用嵌入特征空间中每对点的特征之间的相似度矩阵来指示给定的点对是否属于同一对象实例。然而,计算这样的按对的距离对于大型点云是不切实际的。同样,liu等人在他们的文章“masc:multi-scale affinity with sparse convolution for3dinstance segmentation(masc:用于3d实例分割的稀疏卷积的多尺度亲和力)”arxiv preprint arxiv:1902.04478(2019)中描述了点云的体素化,以通过3d u-net模型和聚类方案处理体数据,从而通过比较其在经训练的u-net的若干隐藏层中提取的特征来找到每对点之间的相似度。大型精细化点云的体素化和相似度计算极大地限制了这种方法的性能。
7.因此,从以上可以看出,本领域需要改进的3d点云的实例分割。特别地,需要能够对3d点云进行准确、快速和计算高效的实例分割的方法和系统。
技术实现要素:
8.如本领域技术人员将理解的,本发明的各方面可以体现为系统、方法或计算机程序产品。因此,本发明的多方面可以采取完全硬件实施例、完全软件实施例(包括固件、驻留软件、微代码等)或结合软件和硬件方面的实施例(本文中可以都统称为“电路”、“模块”或“系统”)的形式。本公开中描述的功能可以被实现为由计算机的微处理器执行的算法。此外,本发明的多方面可以采取体现在一个或更多个计算机可读介质中的计算机程序产品的形式,该计算机可读介质具有体现在其上、例如存储在其上的计算机可读程序代码。
9.可以利用一个或更多个计算机可读介质的任何组合。计算机可读介质可以是计算机可读信号介质或计算机可读存储介质。计算机可读存储介质可以是例如但不限于电子、磁性、光学、电磁、红外、或半导体系统、设备或装置或前述的任何合适的组合。计算机可读存储介质的更具体示例(非详尽列表)将包括以下:具有一根或更多根线的电连接、便携式计算机软盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦可编程只读存储器(eprom或闪存)、光纤、便携式光盘只读存储器(cd-rom)、光学存储装置、磁存储装置或前述的任何合适的组合。在本文的上下文中,计算机可读存储介质可以是任何有形介质,其可以包含或存储供指令执行系统、设备或装置使用或与其结合使用的程序。
10.计算机可读信号介质可以包括例如在基带中或作为载波的一部分的传播的数据信号,其具有体现在其中的计算机可读程序代码。这样的传播信号可以采取多种形式中的任何一种,包括但不限于电磁、光学或其任何合适的组合。计算机可读信号介质可以是任何不是计算机可读存储介质并且可以通信、传播或传输程序以供指令执行系统、设备或装置
使用或与其结合使用的的计算机可读介质。
11.体现在计算机可读介质上的程序代码可以使用任何适当的介质来传输,包括但不限于无线、有线、光纤、电缆、rf等,或者上述的任何合适的组合。可以以一种或更多种编程语言的任何组合来编写用于执行本发明的多方面的操作的计算机程序代码,所述编程语言包括诸如java(tm)、scala、c++、python等的功能或面向对象的编程语言,以及诸如“c”编程语言或类似的编程语言的常规的程序编程语言。程序代码可以完全在用户计算机上执行,部分在用户计算机上执行,作为独立软件包执行,部分在用户计算机上并且部分在远程计算机上执行,或者完全在远程计算机、服务器或虚拟服务器上执行。在后一种情况下,远程计算机可以通过任何类型的网络(包括局域网(lan)或广域网(wan))连接到用户计算机,或者可以与外部计算机连接(例如,使用因特网服务提供商通过因特网)。
12.下面参考根据本发明的实施例的方法、设备(系统)和计算机程序产品的流程图和/或框图描述本发明的多方面。将理解的是,流程图和/或框图的每个框以及流程图和/或框图中的框的组合可以由计算机程序指令来实现。可以将这些计算机程序指令提供给通用计算机、专用计算机或其他可编程数据处理设备的处理器,特别是微处理器、或中央处理单元(cpu)或图形处理单元(gpu)以产生机器,使得指令经由计算机的处理器、其他可编程数据处理设备或其他装置执行而创建用于实现流程图和/或框图的一个框或多个框中指定的功能/动作的部件。例如,但不限于,可以使用的硬件逻辑组件的说明性类型包括现场可编程门阵列(fpga)、专用集成电路(asic)、专用标准产品(assp)、片上系统(soc)、复杂可编程逻辑器件(cpld)等。
13.这些计算机程序指令还可以存储在计算机可读介质中,所述计算机可读介质可以指导计算机、其他可编程数据处理设备或其他装置以特定方式运行,使得存储在计算机可读介质中的指令产生制造品,其包括实现流程图和/或框图的一个框或多个框中指定的功能/动作的指令。也可以将计算机程序指令加载到计算机、其他可编程数据处理设备或其他装置上,以引起一系列操作步骤在计算机、其他可编程设备或其他装置上执行以产生计算机实现的过程,使得在计算机或其他可编程设备上执行的指令提供用于实现流程图和/或框图的一个框或多个框中指定的功能/动作的过程。
14.附图中的流程图和框图示出根据本发明的各个实施例的系统、方法和计算机程序产品的可能实现方式的架构、功能和操作。就这点而言,流程图或框图中的每个框可以表示代码的模块、节段或部分,其包括用于实现指定的逻辑功能的一个或更多个可执行指令。还应注意,在一些替代实施方式中,框中指出的功能可以不按图中指出的顺序发生。例如,取决于所涉及的功能,相继示出的两个框实际上可以基本上同时执行,或者有时可以以相反的顺序执行这些框。还应注意,框图和/或流程图的每个框以及框图和/或流程图中的框的组合可以由执行指定功能或动作的基于专用硬件的系统或者专用硬件和计算机指令的组合来实现。
15.在本技术中,描述了用于3d点云的对象检测和实例分割方案的方法和系统。点云表示数据集,该数据集至少限定点在点云中的几何位置(例如,点的笛卡尔坐标)。此外,在一些实施例中,这些点也可以与其他属性(例如,颜色或法线向量)相关联。因此,点云的点可以限定信息的向量,至少包括3d空间中的位置。可以通过使用3d光学扫描仪扫描预定对象来生成点云。这样的对象可以例如是牙颌面结构,其中牙颌面结构可以包括牙列,该牙列
包括牙齿。
16.在一个方面,本发明涉及一种点云(优选地,由3d光学扫描仪生成的点云,例如口内扫描(ios)点云)中对象检测的方法,其中,该方法可以包括:由第一类型的神经网络确定与点云的点相关联的第一特征,该点云包括表示点云的至少3d空间中的一个或多个对象的点,该第一特征限定点云的每个点的几何信息,该第一类型的网络被配置为接收点云的点作为输入;由第二类型的深度神经网络基于第一特征确定第二特征,该第二特征限定关于在均匀3d网格的节点的位置处的点云的局部几何信息,节点均匀分布在点云的3d空间中;基于第二特征确定一个或多个对象提案,对象提案限定围绕3d网格的节点定位的3d边界框,该3d边界框包含点云的可以限定对象的点,该3d边界框限定3d锚点;以及由第三类型的深度神经网络确定3d锚点的分数,该分数指示3d锚点包括限定对象或对象的部分的点的概率,该确定基于位于3d锚点中的第二特征。
17.该方法提供了准确且有效的方式来检测点云中的对象。该过程直接应用于点云(输入数据),以便嵌入在点云中的所有几何信息都可以用于对象检测。此外,该过程通过评估新域(网格域)中的特征来确在点云中的对象,而无需对点云中的每个点进行分类。这样,该过程提供了非常有效的方式来检测(预测)表示预定对象的点是否存在于点云中。
18.在实施例中,还可以训练第二类型的深度神经网络以确定均匀3d网格的节点的分数,该分数指示3d锚点包括限定对象或对象的部分的点的概率。
19.在实施例中,第一点云特征可以包括第一特征向量,每个第一特征向量与点云的点相关联;和/或,第二点云特征可以包括第二特征向量,每个第二特征向量与均匀3d网格的节点相关联。
20.在实施例中,第一点云特征可以由第一类型的深度神经网络确定,第一类型的深度神经网络限定特征提取网络。
21.在实施例中,第一类型的网络可以被配置为接收点云的点并且生成第一特征,优选地,与点云的点相关联的第一特征向量。
22.在实施例中,第一类型的深度神经网络可以包括多个卷积层,该多个卷积层包括多层感知器(mlp),特征提取网络被配置为在其输入处接收点云的点并且在其输出处为点云的每个点生成特征向量。
23.在实施例中,特征提取网络可以包括一个或多个χ-conv层,每个χ-conv层被配置为对提供给χ-conv层的输入的点和对应的特征进行加权和置换,并且随后使置换后的点和特征经受卷积核,优选地,特征提取网络被配置为包括χ-conv层的pointcnn。
24.在实施例中,第二类型的深度神经网络可以表示对象提案网络,该对象提案网络包括多个卷积层,多个卷积层中的每一个包括多层感知器(mlp),该多层感知器(mlp)包括一个或多个卷积核。
25.在实施例中,多个卷积层中的至少一个可以被配置为接收第一特征和均匀3d网格的节点并且基于第一特征确定第二特征。
26.在实施例中,可以基于点在点云的3d空间中的空间分布来确定均匀3d网格。
27.在实施例中,对象提案网络可以被配置为蒙特卡洛卷积网络(mccnet),其包括多个蒙特卡洛(mc)空间卷积层,优选地,包括被配置为确定位于点云的3d空间中的节点x的位置处的卷积的卷积核的mc空间卷积层。
28.在实施例中,确定卷积包括:确定感受野r内的相邻点y,该感受野限定卷积核的视场(fov);为每个相邻点y确定概率密度函数p(x,y);使用相邻点y和每个相邻点的概率密度值p(x,y)基于蒙特卡洛估计确定节点处的卷积。
29.在实施例中,第三类型的深度神经网络可以表示对象分类网络,第三类型的深度神经网络包括多个全连接(fc)多层感知器(mlp)层,第二类型的深度神经网络被配置接收与3d锚点相关联的特征并使用这些特征来确定与3d锚点相关联的分数,该分数指示3d锚点包括限定对象或对象的部分的点的概率。
30.在一个方面,本发明可以涉及一种计算机系统,该计算机系统适用于点云(优选地,由3d光学扫描仪生成的点云,例如口内扫描(ios)点云)中的对象检测,该计算机系统包括:
31.计算机可读存储介质,其中包含有计算机可读程序代码,该程序代码包括预处理算法和至少经训练的第一3d深度神经网络、计算机可读程序代码;以及处理器,优选地,微处理器,其耦接到计算机可读存储介质,其中,响应于执行第一计算机可读程序代码,该处理器被配置为执行可执行操作,包括:由第一类型的神经网络确定与点云的点相关联的第一特征,该点云包括表示点云的3d空间中的一个或多个对象的点,该第一特征限定点云的每个点的几何信息,该第一类型的网络被配置为接收点云的点作为输入;由第二类型的深度神经网络基于第一特征确定第二特征,该第二特征限定关于点云在均匀3d网格的节点的位置处的局部几何信息,节点均匀分布在点云的3d空间中;基于第二特征确定一个或多个对象提案,对象提案限定围绕均匀3d网格的节点定位的3d边界框,该3d边界框包含点云的可以限定对象的点,该3d边界框限定3d锚点;以及由第三深度神经网络确定3d锚点的分数,该分数指示3d锚点包括限定对象或对象的部分的点的概率,该确定基于位于3d锚点中的第二特征。
32.在一个方面,本发明可以涉及一种计算机系统,该计算机系统适用于点云(优选地,由3d光学扫描仪生成的点云,例如口内扫描(ios)点云)的实例分割,该计算机系统包括:计算机可读存储介质,其中包含有计算机可读程序代码,该程序代码包括预处理算法和至少经训练的第一3d深度神经网络、计算机可读程序代码;以及处理器,优选地,微处理器,其耦接到计算机可读存储介质,其中,响应于执行第一计算机可读程序代码,该处理器被配置为执行可执行操作,包括:由第一类型的深度神经网络确定与点云的点相关联的第一特征,该点云包括表示点云的3d空间中的一个或多个对象的点,该第一特征限定点云的每个点的几何信息,该第一类型的网络被配置为接收点云的点作为输入;由第二类型的深度神经网络确定第二特征,该第二特征限定关于点云在均匀3d网格的节点的位置处的局部几何信息,节点均匀分布在点云的3d空间中;基于第二特征确定对象提案,对象提案限定包含可以限定对象的点的3d体积,对象提案的3d体积限定围绕3d网格的节点定位的3d锚点;由第三类型的深度神经网络确定分类的3d锚点,该确定基于第二特征集,该第二特征集是位于3d锚点中的第二特征的子集;由第四类型的深度神经网络(对象位置预测器网络)确定对象体积,对象体积的中心位置与对象实例的中心位置重合,并且对象体积的尺寸与对象实例的外部尺寸相匹配,该确定基于第二特征集;以及由第五类型的深度神经网络(掩模预测器网络)基于位于对象体积中的点集和第一点云特征集确定分类的点,分类的点包括属于对象实例的第一分类点和不属于对象实例的第二分类点。
33.在另一方面,本发明可以涉及一种训练深度神经网络系统以用于点云(优选地,口内扫描(ios)点云)中的对象检测的方法,该方法包括:向深度神经网络系统的输入提供训练点云样本,该训练点云样本包括一个或多个标记的对象实例,该深度神经网络系统至少包括特征提取网络、对象提案网络和对象分类网络;基于第二特征计算对象提案,该第二特征限定关于点云在均匀3d网格的节点的位置处的局部几何信息,节点均匀分布在点云的3d空间中,该第二特征由对象提案网络确定,其中,该对象提案网络被配置为基于特征提取网络生成的第一特征确定第二特征,该特征提取网络在其输入处接收训练点云样本,该对象提案限定在均匀3d网格的节点周围的3d边界框,该3d边界框可以包括限定对象的点,3d边界框限定3d锚点;确定3d锚点与训练点云样本中的标记的对象实例的3d边界框之间的重叠,并且如果重叠高于预定阈值,则将3d锚点标记为正,如果重叠低于预定阈值,则标记为负;由对象分类网络使用3d锚点中的点云特征确定对于正和/或负标记的3d锚点的一个或多个对象预测,并且基于一个或多个对象预测、正和/或负标记的3d锚点和第一损失函数,确定第一损失值;以及使用第一损失值,同时使用反向传播方法训练特征提取网络、对象提案网络和对象分类网络。
34.在又一方面,本发明可以涉及一种训练深度神经网络系统以用于点云(优选地,由3d光学扫描仪生成的点云,例如口内扫描(ios)点云)的实例分割的方法,该方法包括:向深度神经网络系统的输入提供训练点云样本,该训练点云样本包括一个或多个标记的对象实例,该深度神经网络系统至少包括特征提取网络、对象提案网络、对象分类网络、对象位置预测器网络和掩模预测器网络;基于第二特征计算对象提案,该第二特征限定关于点云在均匀3d网格的节点的位置处的局部几何信息,节点均匀分布在点云的3d空间中,该第二特征由对象提案网络确定,其中,该对象提案网络被配置为基于特征提取网络生成的第一特征确定第二特征,该特征提取网络在其输入处接收训练点云样本,该对象提案限定3d边界框,该3d边界框限定3d锚点;确定3d锚点与训练点云样本中的标记的对象实例的3d边界框之间的重叠,并且如果重叠高于预定阈值,则确定为正3d锚点,如果重叠低于预定阈值,则确定为负3d锚点;由对象分类网络使用3d锚点中的点云特征确定对于正和负标记的3d锚点的一个或多个对象预测,并且基于一个或多个对象预测和第一损失函数确定第一损失值;由对象位置预测器网络基于3d锚点中的特征确定对象体积的位置和尺寸预测,并使用位置和尺寸预测以及第二损失函数来确定第二损失贡献;由掩模预测器网络基于对象体积中的点云特征确定分类的点,分类的点包括属于对象实例的第一分类点和不属于对象实例的第二分类点,并且使用分类的点和第三函数来确定第三损失贡献;以及使用第一损失贡献、第二损失贡献和第三损失贡献,并且使用、优选地同时使用反向传播方法来训练特征提取网络、对象提案网络、对象分类网络、对象位置预测器网络和掩模预测器网络。第一点云特征和第二3d网格特征可以通过神经网络的系统的训练过程同时隐式学习。
35.本技术中描述的方法和系统基于对象检测和实例分割模型(方案),其可称为掩模-mc网络(mask-mcnet)。mask-mcnet允许在3d点云(例如,由口内扫描仪生成的口内扫描(ios)数据)中进行准确高效的对象检测和实例分割。与已知的深度学习模型相比,该模型不需要用于处理点云的体素化步骤。因此,可以在保留点云的精细几何信息的同时处理数据,这对于详细结构的成功分割很重要。此外,通过提取第一点云特征并将其转换为均匀3d网格上的第二点云特征,mask-mcnet可以有效地处理高度非均匀点云数据的处理,从而快
速生成点云中的对象提案。这种特性对于该方案对大型点云数据结构(例如,超过100k个点)的可扩展性很重要。实验结果表明,mask-mcnet在测试数据上实现了98%的iou(intersection of union,交并比)分数,从而在点云分割任务中优于最先进的网络。mask-mcnet的性能接近人类水平,并且只在几秒钟的处理时间内就可获得完整的点云对象检测和分割,而这对人类来说是耗时且劳动密集型的任务。
36.在某些实施例中,该系统可以包括三个模块,其中,每个模块可以包括一个或多个子网络。第一模块(特征提取)可以包括被训练为将输入点集的几何位置变换到高维特征空间中的深度神经网络。如此获得的每个点的高维特征向量可以被转移到跨越整个3d空间的3d网格。这种转换由第二模块(对象提案)执行,该模块可以包括蒙特卡洛卷积网络或其他合适的网络架构。该网络可以被训练为将包含在不规则点云的每个点的特征向量中的信息(从第一模块获得)分配和转换到规则网格域。为了检测在每个候选边界框(也称为锚点)内是否存在对象(例如,牙齿),可以采用第三模块,该第三模块包括两个子网络。候选锚点包围的网格节点上的所有特征由分类子网络检查,以检测与3d空间中的对象具有高度重叠的锚点。在分类子网络肯定地检测到锚点的情况下,另一个子网络(对象位置预测器网络)用于估计候选锚点边界框与候选锚点边界框中对象的中心的差值,并与它们的地面真值(ground truth)进行比较。在对每个对象进行局部化后,采用可以由基于mlp的级联网络组成的掩模生成器网络对来自输入点云的在检测到的边界框内的所有点进行二进制分类。这种分类任务旨在找到属于完全被检测到的边界框包围的每个对象的点。因此,该模型能够首先通过拟合以每个对象的中心为中心的3d边界框来检测输入点云中的所有对象,然后指示属于每个检测到的边界框内的每个单独牙齿的所有点。
37.认为虽然本技术中的实施例标识和描述(功能上)分离的网络组件,例如,分离的深度学习网络,但可替代地,在其他实施例中这些分离的网络组件的组合可以被认为是单个连接的网络。将参考附图进一步说明本发明,附图将示意性地示出根据本发明的实施例。应当理解,本发明不以任何方式限于这些具体实施例。
附图说明
38.图1是根据本发明的实施例的用于3d点云的对象检测和实例分割的深度学习系统的图示。
39.图2a-2d描绘了根据本发明的实施例的用于3d点云的对象检测和实例分割的方案。
40.图3描绘了根据本发明的另一个实施例的用于3d点云的对象检测和实例分割的深度学习系统。
41.图4a和图4b描绘了根据本发明的各个实施例的用于点云的对象检测和实例分割的过程的流程图。
42.图5描绘了根据本发明的实施例的特征提取网络的一部分的示意图。
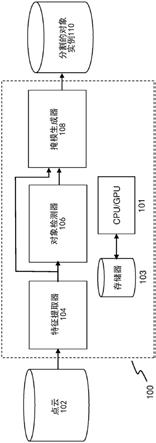
43.图6描绘了根据本发明的另一个实施例的特征提取网络的一部分的示意图。
44.图7描绘了根据本发明的实施例的对象提案网络的示意图。
45.图8a和图8b描绘了根据本发明的实施例的蒙特卡洛卷积网络的一部分的示意图。
46.图9描绘了根据本发明的实施例的对象分类网络的示意图。
47.图10描绘了根据本发明的实施例的对象位置预测器网络的示意图。
48.图11描绘了根据本发明的实施例的掩模预测器网络的示意图。
49.图12a和图12b描绘了根据本发明的各个实施例的训练深度学习系统的流程图。
50.图13描绘了根据本发明的实施例的由mask-mcnet确定的正分类的3d锚点的可视化。
51.图14a至图14h描绘了根据本发明的实施例的由深度学习系统生成的经分割的ios数据的示例。
52.图15描绘了根据本发明的实施例的后处理经分割的点云的流程图。
53.图16是示出示例性数据处理系统的框图,该示例性数据处理系统可用于执行本技术中描述的方法和软件产品。
具体实施方式
54.本公开中描述的实施例包括基于一个或多个深度神经网络(dnn)的用于不规则(非均匀)3d点云的准确且高效的对象检测和实例分割的系统和计算机实现的方法。点云可以指限定一个或多个对象或包括一个或多个对象的场景的3d表示的采样点集。每个采样点(简称为点)可以由3d笛卡尔坐标系中的向量表示,该3d笛卡尔坐标系不是通用的(即,笛卡尔坐标系在两个ios数据集之间可能不同)。点云可以被结构化为3d表面网格,其中,3d空间中的点可以限定三角形或多边形网格,这些点共同描述3d空间中的表面网格。与网格相关联的法线向量可以限定3d空间中的取向。与点云中的每个点相关联的法线向量可以表示垂直于由每个点及其相邻点组成的表面的向量。与欧几里得2d和3d数据集(例如,像素和体素表示)不同,点云是不规则的、置换不变的,并且每次扫描可能具有可变数量的点。在本技术中,术语点云用于指代任何非欧几里得3d数据集,其用于基于3d空间中的点来表示3d空间中的对象。
55.图1描绘了根据本发明的实施例的用于点云的对象检测和实例分割的深度学习系统的示意图。特别地,图1描绘了用于3d点云的实例分割的系统100。在图2a至图2d中示意性地描绘了由系统进行的3d点云的对象检测和实例分割的过程。该系统可以在一个或多个计算机上实现,该一个或多个计算机包括连接到存储器103的一个或多个处理单元101。该系统可以被配置为执行多个单元,该多个单元包括3d深度神经网络,其可以被训练为在其输入处接收点云(的一个或多个部分)和可选地接收与点云相关联的空间信息,并根据经训练的模型处理数据。该系统可以被实现为独立系统(例如,服务器系统或网络应用,例如,云应用),该独立系统连接到数据存储和检索系统,例如,数据库系统等,该系统包括一个或多个存储单元,例如数据库。
56.如图1所示,深度学习系统可以包括多个单元,该多个单元至少包括特征提取器104、对象检测器106和掩模生成器108。特征提取器可以包括第一深度神经网络,该第一深度神经网络被配置为在其输入处接收不规则的3d点云102。在图2a中描绘了点云表示的示意图。点云可以包括表示一个或多个(不同)对象(例如:表示球体204
1-3
的第一对象和/或表示圆柱体的第二对象206
1,2
)的表面的至少一部分的点的不规则集合。通常,点可以表示为坐标,例如3d空间202中的笛卡尔坐标x,y,z。第一深度神经网络可以被配置为确定点云的每个点的特征向量。在实施例中,特征可以被格式化为特征向量,即,多元素向量(在示例中
为256个元素)。与点相关联的特征向量可以描述该点与3d点云中的其他点(通常是位于距该点一定距离内的其他点)之间的空间相关性。对象检测器和掩模生成器可以使用特征向量来有效地执行点云中对象的实例分割。
57.对象检测器106可以包括被配置为生成对象提案的深度神经网络系统。对象提案可以包括点云的3d空间中的体积,该体积包括具有高概率表示某个对象的点集。为此,深度神经网络系统可以确定点云的3d空间中的预定大小和位置的3d边界框,该3d边界框很可能包含表示对象的点。对象检测器的深度神经网络系统可以被配置为在其输入处接收点云(或点云的子集(例如,分块(patch)))和3d网格207。如图2b所描绘的,3d网格可以限定点云的3d空间中一定密度的节点207。3d网格的节点可以限定3d空间中对象提案的中心。这样,对象检测器的深度神经网络系统可以限定对象提案网络,该对象提案网络被配置为确定位于3d网格的节点上的对象提案,例如,3d边界框,其中,3d网格包括跨越点云的3d空间的多个节点。每个3d边界框(可称为锚点)与基于特征提取器计算出的特征向量而确定的特征相关联。因此,给定如图2a中所描绘的点云和如图2b中所描绘的节点的3d网格,对象检测器的深度神经网络系统可以确定3d边界框,每个3d边界框的中心位于3d网格的节点中的一个节点上,并且每个3d边界框包含与3d边界框中的点相关的特征。这在图2c中示意性地示出。如该图所示,对象检测器生成与不同对象关联的锚点,例如,与第一对象208
1-3
相关联的锚点和与第二对象206
1,2
相关联的锚点。
58.对象检测器可以包括另一深度神经网络,其被配置为对位于每个锚点中的特征进行分类。该网络可以限定对象分类网络,该对象分类网络被训练为接收与位于锚点中的点相关联的特征作为其输入,并使用这些特征来确定锚点是否包含表示预定对象的点。
59.掩模生成器108可以处理已经由对象分类网络分类为包含预定对象的锚点内的点。在对象提案网络中输入的锚点的中心和尺寸由3d网格确定。因此,锚点不一定提供对象中心的准确位置及其尺寸。为了生成对象的准确位置,掩模生成器可以包括深度神经网络,该深度神经网络被训练为确定包含表示预定对象的点的3d边界框的中心和尺寸。该神经网络可以称为对象位置预测器网络。
60.此外,基于准确地定位和定尺寸的3d边界框,掩模生成器可以选择位于3d边界框中的点。
61.3d边界框中的点可以包括表示对象的点和作为背景的部分的点。可以使用深度神经网络来执行点的分类,该深度神经网络可以被称为掩模预测器网络。掩模预测器网络可以例如将点分类为属于预定对象(例如,一个或多个不同的对象)。在一些实施例中,它可以将属于3d边界框内的未知对象的点分类为背景。掩模生成器网络在每个边界框内的正分类的点可以称为“掩模”。下面更详细地描述对象分类网络、对象位置预测器网络和掩模预测器网络。
62.图2d描绘了该过程的结果,包括其中每个点集表示第一对象(例如,球形对象)的实例的三个分割点集212
1-3
和其中每个点集214
1-3
表示第二对象(例如,圆柱形对象)的实例的两个分割点集。
63.参考图1和图2描述的深度学习系统能够通过使用能够直接处理点云的点的深度神经网络来准确和高效地进行3d点云的对象检测和实例分割,从而不需要如从现有技术解决方案中已知的点云的体素化。深度神经网络可以基于深度多层感知器(mlp)网络。
64.图3描绘了根据本发明的实施例的用于3d点云的对象检测和实例分割的深度学习系统的示意图。图3中的深度学习系统被配置为将实例分割应用在由3d光学扫描仪生成的点云上。这里,实例分割是指使用计算模型为属于对象(例如,牙齿)的实例的所有点分配独特标签的过程。通常,计算模型包括一个或多个经训练的神经网络。
65.在实施例中,3d光学扫描仪可以是用于扫描牙齿的口内扫描仪(ios)。由ios生成的点云可以称为ios点云。ios点云在表示各个牙齿的点集中的自动实例分割对于牙科、种植学和正畸学中的许多应用来说是非常需要的。ios点云可以包括大的点集,通常有数十万或更多的点,包括有关牙冠和牙龈(齿龈)的解剖结构的高分辨率信息。在一些实施例中,也可以将点云转换为网格数据结构(例如在对点应用三角测量算法之后)。
66.如图3所示,可以将诸如ios点云或ios点云的一块(patch)的输入数据302提供给特征提取器304。ios点云块可以包括n个点,其中n可以在不同的块之间变化。输入数据可以包括限定点云的点的坐标312,其中,可以基于笛卡尔坐标系x、y、z来限定坐标。此外,在点限定3d表面网格的实施例中,输入数据还可以包括由多个点限定的表面的法线向量314。网格可以限定图形,该图形包括在由点云中的点限定的位置处的多个顶点。作为三角测量算法的结果,相邻的顶点可以通过边彼此连接。每个三角形包括网格中三个相邻的顶点,这些顶点可以限定表面(有时称为“面”)。这样,可以计算出垂直于这样的面定向的法线向量。为了将法线向量分配给顶点(点),可以计算每个顶点所贡献的面(即,三角形)的所有法线向量的平均值。因此,在3d表面网格的n个点的块的情况下,特征提取网络的输入数据可以表示为n
×
6矩阵,包括n个点坐标和n个关联的法线向量。更多生成的输入数据可以包括点的3d位置和一个或多个其他属性(法线向量、颜色等)。
67.特征提取器可以包括特征提取网络316(也可以称为骨干网络)。特征提取网络是深度神经网络,其可被训练为在其输入处接收点云或点云块并确定点云的点的特征向量324。在实施例中,特征提取网络可以被训练为确定点云的每个点的特征向量。特征向量可以限定描述点云的每个点周围的几何信息的多个特征。例如,在示例性实现方式中,特征提取网络可以生成n个特征向量(其中,n表示输入点的数量),其中,每个特征向量可以包括多个特征元素,例如,256个元素。
68.在实施例中,特征提取网络可以被实现为基于深度多层感知器(mlp)的网络,该网络应用于整个点云(或,取决于硬件限制,应用于点云块)。在实施例中,基于mlp的网络可以被配置作为所谓的pointcnn网络。pointcnn网络在以下文章中进行了描述:li等人发表在2018年的neural information processing systems(nips)上的文章“pointcnn:convolution onχ-transformed points(pointcnn:对χ变换点的卷积)”,arxiv:1801.07791v5,2018年11月5日。虽然可以对特征提取器网络(骨干网络)做出多种选择,但pointcnn网络架构的优点(参考图5和图6进行了更详细的描述)在于,它允许处理点云的精细细节并且它具有较小的模型尺寸。特征提取网络的输出可以是n
×
256的特征矩阵(其中,n表示输入点的数量)。与点云的点相关联的特征向量可以包含该点周围的体积中丰富的几何信息。在其他实施例中,能够从点云数据集中提取特征的其他深度神经网络也可以用于特征提取网络,包括但不限于pointnet(qi,cr等人:pointnet:deep learning on point sets for 3d classication and segmentation(pointnet:点集的深度学习以用于3d分类和分割),proc.computer vision and pattern recognition(cvpr),ieee1(2),4(2017)),
qi,charles ruizhongtai等人:pointnet++:deep hierarchical feature learning on point sets in a metric space(pointnet++:度量空间中点集的深度分层特征学习),advances in neural information processing systems,2017)、pointgrid(le,t.,等人:pointgrid:a deep network for3dshape understanding(pointgrid:用于3d形状理解的深度网络),proceedings of the ieee conference on computer vision and pattern recognition.pp.9204{9214(2018))、mccnet(hermosilla,p.,等人:monte carlo convolution for learning on non-uniformly sampled point clouds(用于学习非均匀采样点云的蒙特卡洛卷积),siggraph asia 2018technical papers.p.235.acm(2018))、pointcnn(li,y.,等人:pointcnn,arxiv preprint arxiv:1801.07791(2018))、spidercnn(xu,y等人:spidercnn:deep learning on point sets with parameterized convolutional filters(spidercnn:使用参数化卷积滤波器对点集的深度学习),eccv 2018。
69.由特征提取网络确定的特征向量可以提供给对象检测器306的输入,该对象检测器306包括所谓的对象提案网络318。对象提案网络可以被训练为接收来自特征提取网络的特征向量324并且接收节点的3d网格,节点限定点云(或点云块)的3d空间中所谓的锚点。3d网格限定跨越点云的3d空间的节点的3d布置。锚点可以限定具有中心位置[xa,ya,za]和尺寸[w,d,h]的3d边界框。锚点的中心可以由3d网格的节点确定。
[0070]
点云的点通常限定“表面点”,即由3d光学扫描仪确定的对象的表面的样本。这种扫描仪的示例是ios扫描仪。由特征提取网络计算出的特征通常包括关于3d空间的流形(manifold)的局部几何信息。换言之,这种丰富的几何信息可以将对象的局部表面编码为3d空间中表面的局部曲率。然而,对于回归任务,例如准确定位包围对象的3d边界框,模型需要将来自3d表面网格的3d几何信息聚合到点云的3d空间的空的空间(例如,对象内部的空的空间)中。例如,为了准确确定对象,模型需要关于点云的表示对象的点的集合的不同部分(例如,侧面)的3d空间信息。点云的体素化和应用3d cnn以处理体素化的体数据将是解决该问题的常规方法。然而,如前所述,非均匀点云的体素化将严重限制神经网络在量化误差方面的性能,因为将点云转换为体数据会劣化几何信息的精细细节。
[0071]
为了解决现有技术的缺点,对象提案网络可以被配置为将来自对象表面的丰富的几何信息(如编码在由特征提取网络确定的特征向量中)分配和转移到整个3d空间中(例如,对象(例如,牙齿)内部的空的空间中)。在实施例中,所谓的蒙特卡洛卷积网络(mccnet)架构可以用于实现对象提案网络318。参照图7和图8更详细描述的mccnet架构可以包括一个或多个基于多层感知器(mlp)的网络。特别地,mccnet可以包括若干模块化mlp子网络,这些模块化mlp子网络包括具有类似于卷积核集的功能的至少两个隐藏层。这些层可以称为mccnet的卷积层。这样,mccnet能够对核的视场(fov)内任意(新的)点集计算卷积,而不管它是否存在于输入点集内。换句话说,卷积层的输出生成位置的新点集。这些位置可以是点云上的任意位置,甚至是在点云中没有样本的位置。这样,mccnet允许计算点的非均匀分布的卷积。
[0072]
mccnet被配置为将特征提取网络计算出的特征从点云域(特征与点云的3d空间中的点关联)转移到基于节点的3d网格的新域,节点的3d网格跨越点云的3d空间。该新域可以称为网格域,其中特征与跨越点云的3d空间(输入空间)的3d网格的节点相关联。在实施例
中,节点的3d网格可以作为输入数据提供给网络。在实施例中,网格生成器319可以生成特定节点密度的3d网格326并将3d网格提供给对象提案网络的输入。网格生成器可以被配置为基于点云的点的信息生成3d网格。例如,网格生成器可以基于提供给图3的系统的输入的点云确定3d网格的节点密度。基于点云确定3d网格的节点确保与点云的点相关联的特征向量的足够的细节由mccnet转移到3d网格域。
[0073]
因此,如图3所示,对象提案网络可以接收来自特征提取网络的特征向量并接收3d网格326,该3d网格326跨越点云的整个3d空间或至少其大部分。基于该输入,对象提案网络可以被配置为确定3d锚点,这些锚点可以用作对象提案,即包括表示对象的点的特定形状的体积,例如,3d边界框。3d边界框可以具有任何合适的形状,例如,矩形、球形、圆柱形等。
[0074]
对象提案网络不作出关于对象在3d空间中的可能位置的任何假设。在实施例中,3d网格可以是限定均匀分布在点云的3d空间中的节点的均匀网格。在这种情况下,3d网格的空间分辨率可以确定模型在准确度和计算能力方面的性能。选择低分辨率3d网格可能导致在小对象(例如,ios数据情况下的门牙)内定位的锚点太少,而高分辨率网格可能导致计算效率低。
[0075]
为了提高模型的准确度和效率,在实施例中,可以向网络提供非均匀网格来代替均匀网格。非均匀3d网格可以包括靠近对象表面的节点的密集分布和远离对象表面的距离处的节点的稀疏分布。网格生成器可以基于馈送到网络输入的点云和初始密集的均匀3d网格来确定非均匀3d网格。可以通过使用节点与点云中最接近该节点的点之间的距离过滤掉初始密集的3d网格的节点来获得非均匀3d网格。此外,可以使用网格分辨率的预定下界。来自3d网格的距点云最近的邻居点比阈值更远的节点,如果网格中存在与阈值相比更靠近这些节点的任何点,则被移除。
[0076]
对象提案网络的上述特性使得能够将特征从点云域(特征与点在点云的3d空间中的位置相关联)转移到上述网格域(特征与跨越点云3d空间的3d网格的节点的位置相关联)。在实施例中,对象提案网络可以生成m个3d锚点(例如,与3d网格的m个节点相关联的m个3d边界框),每个锚点的中心与被馈送到对象提案网络的输入的3d网格的节点重合。此外,对于3d网格的每个节点,对象提案网络可以确定属于以该节点作为其中心坐标的3d锚点的几何信息(特征)。对象分类网络322可以基于锚点中的特征来确定锚点是否包括表示对象的点。对象分类网络对锚点中特征的评估可以产生分类的3d锚点(例如,3d边界框),其中,每个分类的3d锚点包含属于某个对象的点。丢弃被分类的且不包含对象的锚点。
[0077]
来自mccnet输入的第一mlp网络可以用作用于将点云域的特征转移到网格域的卷积层。数据由mccnet的隐藏层进一步处理。基于每个卷积核的fov,“表面点”的几何信息将分布在3d网格的节点上。在实施例中,3d网格的每个节点可以表示一个锚点(k=1)的位置(例如,中心)。在另一个实施例中,3d网格的每个节点可以表示多个锚点(k》1)的位置,其中,与节点相关联的k个锚点可以具有不同的纵横比。因此,由对象提案网络318生成的3d锚点的总量可以是k
×
m。
[0078]
基于每个3d锚点内部的特征,对象分类网络322可以预测3d锚点是否包含对象。为此,对象分类网络可以确定每个3d锚点的分数,其中,该分数可以表示3d锚点包括或不包括对象实例的概率。阈值可用于确定分数是否指示3d锚点包含限定对象的点。
[0079]
对象分类网络322可以被实现为具有固定长度输入的全连接mlp。在这种情况下,
每个锚点内部的特征集需要是固定长度的。因此,对象提案网络318与对象分类网络322之间的插值模块320可用于确定每个3d锚点的固定特征集。例如,在实施例中,插值模块可以确定(插值)每个3d锚点以具有s
×s×
s个节点。s的值可以在2到12之间。这样,每个3d锚点可以具有固定长度的特征集。例如,可以使用利用网格的最近邻居节点(例如,三个最近邻居)以及这些最近邻居节点的基于其到3d空间中的新节点的距离的特征向量的加权的插值。因此,插值模块可以为由对象提议网络确定的k
×
m个3d锚点确定k
×m×
s3个特征的输出矩阵。
[0080]
如果对象检测器已经确定出点云包括一个或多个包括对象的3d锚点,则可以触发掩模生成器308以对一个或多个3d锚点中的每一个中的点进行分类。分类过程可以确定3d锚点中的哪些点可以表示对象。在这种情况下,对象位置预测器网络可以接收关于哪些3d锚点被对象分类网络分类为包含对象的信息340。可以将分类的3d锚点332提供给对象位置预测器网络334,该对象位置预测器网络334被配置为确定准确地包围对象的体积。该体积可以称为对象体积。对象体积可以具有与对象的中心位置准确地匹配的中心位置。此外,对象体积的尺寸可以准确地匹配对象的外部尺寸。在实施例中,对象位置预测器网络可以生成用于将分类的3d锚点重新定位和重新缩放成对象体积的信息。
[0081]
可以将对象体积的位置和尺寸提供给3d裁剪模块336,该模块可以使用位置和尺寸从点云中裁剪出对象块。每个对象块可以包括定位在对象体积内的点云的点。这样,每个对象块可以限定点集,其包括表示对象检测器306预测的(检测到的)对象的点。在实施例中,3d裁剪模块可以使用m
×
k个对象体积中的每一个来裁剪来自点云的p个点。此外,p个点中的每一个可以与特征提取网络生成的n个特征向量之一相关联。
[0082]
因此,对于每个对象体积,3d裁剪模块可以从点云中提取p个点,其中,每个点与特征向量324相关联,导致m
×k×
p个特征向量,其中,每个特征向量可以具有多个(例如,256个)特征元素。
[0083]
可以将对象块和关联的特征向量提供给掩模预测器网络338,该掩模预测器网络338被配置为将对象块中的点分类为分类的点,即,属于对象的点和不属于对象的点(例如,背景)。该分类过程可以产生表示对象的点的经分割的实例,例如,ios块310中的经分割的牙齿实例,如图3所描绘的。
[0084]
因此,从上面可以看出,可以采样三个单独的基于mlp的网络来处理对象提案网络的输出。第一网络(对象分类网络)负责预测网格域中的每个点是正还是负。如果网格上的节点属于至少一个正锚点,则它被认为是正的。正锚点是那些与数据中的对象具有高iou(重叠)的锚点。因此,采用第一网络进行网格节点的分类。正锚点内的所有点都由两个其他网络(对象位置预测器网络和掩模预测器网络)处理。这些网络中的一个被训练为估计正锚点(候选)的中心与其被分配的地面真值中心之间的空间位移。第二网络(对象位置预测器网络)负责预测正锚点的大小(例如,3d立方体的宽度、高度和深度)与其地面真值的等效值之间的差值。总的来说,网络中的一个对网格节点执行分类,接下来的两个网络已用于解决回归问题。为了分割属于被3d框包围的对象的所有点,采用子网络。该网络(称为掩模预测器网络)负责对每个3d边界框内的点进行分类。
[0085]
图4a和图4b描绘了根据本发明的各个实施例的用于点云的检测和实例分割的过程的流程图。这些过程可以由以上参考图1至图3描述的深度学习系统的模块来执行。图4a
描绘了由经训练的神经网络的系统检测点云中的对象的过程的流程图。如图所示,该过程可以包括接收点云的第一步骤402,该点云包括表示点云的3d空间中的一个或多个对象的点。在下一步骤(步骤404)中,可以确定点云的第一点云特征。在实施例中,第一点云特征可以由第一类型的深度神经网络基于点云的点来确定。第一点云特征可以限定关于点云在点云的每个点的位置处的局部几何信息。在实施例中,第一点云特征可以限定第一特征向量。与点相关联的每个特征向量可以限定关于该点周围空间的几何信息,例如,关于该点周围的特定体积内存在或不存在点的几何信息、这些点之间的相对距离和由这些点限定的局部曲率。
[0086]
第三步骤406可以包括由对象提案网络将第一点云特征转换为第二点云特征。这里,第二点云特征可以限定关于点云在跨越点云的3d空间的3d网格的节点的位置处的局部几何信息。进一步的第四步骤(步骤408)可以包括基于第二特征生成一个或多个对象提案。对象提案可以限定一个(或多个)3d边界框,该3d边界框定位在3d网格的节点周围,其中,3d边界框可以包含点云的可以限定对象的点。由对象提案网络生成的这种3d边界框也可以称为3d锚点。
[0087]
每个3d锚点可以定位在3d网格的节点周围,并且与每个3d锚点相关联的第二特征向量可以限定由3d锚点限定的空间内的几何信息。第二特征向量的确定可以包括将第一特征向量和3d网格的节点提供给第二深度神经网络的输入,并且第二深度神经网络在其输出处提供对于每个3d锚点的第二特征向量。
[0088]
第五步骤410可以包括从位于3d锚点中的第二特征中选择特征集;以及由对象分类网络基于该特征集确定3d锚点的分数。该分数可以指示3d锚点包括限定对象或对象的部分的点的概率。
[0089]
图4a中描绘的过程提供了一种准确且有效的方式来预测点云中的对象。第一特征向量的确定可以包括将点云的点提供给第一深度神经网络的输入,并且第一深度神经网络在其输出处提供对于点云的点的第一特征向量。该过程直接应用于点云(输入数据),而无需体素化等,因此嵌入在点云中的所有几何信息都可以用于对象检测。此外,该过程通过评估新域(网格域)中的特征来确定点云中的对象,而无需对点云中的每个点进行分类。这样,该过程提供了非常有效的方式来检测(预测)表示预定对象的点是否存在于点云中。
[0090]
图4b描绘了用于点云的实例分割的过程的流程图。该过程可以在参照图4a描述的对象检测过程之后执行。实例分割过程可以以如下步骤412开始:接收包含在被对象分类网络正分类为包含对象实例的3d锚点中的特征集。进一步的步骤(步骤414)可以包括由对象位置预测器网络确定对象体积。对象位置预测器网络可以生成对象实例的中心位置。或者,对象位置预测器网络可以生成对象实例的外部尺寸。在实施例中,对象体积的中心位置可以与对象实例的中心位置重合。在另一个实施例中,对象体积的尺寸可以匹配对象实例的外部尺寸。
[0091]
可以使用对象体积的位置和尺寸来从点云裁剪点集并且从第一点云特征裁剪点云特征集(步骤416)。可以由掩模预测网络来确定分类的点(步骤418)。分类的点可以基于第一点云特征集确定,其中,分类的点可以包括属于对象实例的第一分类点和不属于对象实例的第二分类点。经裁剪的点集和匹配的点特征可以输入到掩模预测网络中(步骤418),该网络将每个点分类为是对象实例的部分或不是对象实例的部分(背景)。
[0092]
因此,图4b中描绘的过程步骤通过准确地确定包含表示对象的点的点云的3d空间中的体积,允许对点云的点进行有效的实例分割。这样,该过程允许对点进行分割,而无需像常规语义分割过程中已知的那样对点云的每个点进行分类。
[0093]
图5和图6描绘了根据本发明的实施例的特征提取网络的一部分的示意图。特别地,这些图描绘了特征提取网络504的深度神经网络架构的示意图,该特征提取网络504能够直接处理可以由n个点表示的点云502的点,其中,每个点可以由笛卡尔坐标(和可选地,法线向量)表示。深度学习网络可以被配置为基于mlp的网络。在实施例中,基于mlp的网络可以具有pointcnn网络架构(如在图3的描述中已经简短提到的)。如图5所示,基于mlp的网络模型502可以包括所谓的χ-conv层506
1-9
的堆叠。每个χ-conv层可以被配置为在卷积算子进行处理之前对输入点及其对应的特征进行加权和置换。
[0094]
在图6中有更详细地描绘了χ-conv层的结构。χ-conv层由参数n、c、k和d表征。每个χ-conv层返回具有c个通道的n个代表点,其中,代表点是在其处计算卷积的点(表示3d点云空间(即,输入空间)中的位置)。此外,通道表示特征向量的维度。例如,与256维特征向量相关联的点具有256个通道。常数k是每个代表点的相邻点数,d是χ-conv层的扩张率,即,输入到该层的点与作为输出生成的点之间的比率。
[0095]
每个χ-conv层的视场(fov)可以包括k个最近邻(knn)点609(即,最靠近在其处计算卷积的点的位置的点)的固定集。此外,χ-conv层可以包括两个或更多个mlp网络610、612。这些mlp网络针对k个输入点的坐标学习k
×
k的χ-变换。χ-conv层的结果是将knn点特征聚合和投影到代表点集,然后应用卷积。
[0096]
图5和图6中描绘的pointcnn模型能够学习点云中点之间的局部几何相关性。与用于点云的其他已知的深度学习模型相比,该模型的学习参数的量要少得多。这是有益的,因为在小数据集上不太容易有严重的过拟合。网络的输入可以是点云506的点(例如,n个点,其中每个点为x、y、z坐标和(可选地)法线向量的元素,从而限定n x 6矩阵)。网络510的输出可以是特征向量集(例如,n个向量,其中每个向量具有多个特征元素,例如,256个特征元素),其中,每个特征向量与点云的点相关联。特征向量可以是多元素向量(在示例中为256个元素),其中,向量的每个元素表示类别概率。
[0097]
图7描绘了根据本发明的实施例的对象提案网络的示意图。如图所示,对象提案网络704的架构包括mlp层的多层堆叠。网络可以称为蒙特卡洛卷积网络(mccnet),其包括蒙特卡洛(mc)空间卷积层712
1-4
、批量标准化(bn)层714
1-6
和1x1卷积层716
1-3
。对象提案网络可以被配置为接收在点云域702中限定的特征向量(即,与点云相关联的特征向量,其中每个特征向量限定点云的点附近的几何信息)和节点的3d网格707。在实施例中,节点的3d网格可以由3d网格生成器708生成。在一些实施例中,非均匀3d网格可以用作3d网格。在这种情况下,3d网格生成器可以通过从密集的均匀3d网格710过滤节点来确定。1
×
1卷积层具有c
in
个输入通道和c
out
个输出通道。这些层可用于减小或增大点特征的数量。
[0098]
如图所示,第一mc空间卷积层7121可被配置为接收点云域的特征向量和3d网格的m个节点。基于该输入,卷积层将点云域的特征向量转换为网格域的特征向量。输入数据将由网络的隐藏层进一步处理。基于每个卷积核的fov,“表面点”的几何信息将分布在3d网格的节点上,导致网格域706中的m个特征向量。
[0099]
蒙特卡洛卷积层是能够为非结构化数据(例如,点云的点)计算卷积的卷积层。mc
卷积层在以下文章中进行了描述:hermosilla等人的文章“monte carlo convolution for learning on non-uniformly sampled point clouds(用于非均匀采样点云学习的蒙特卡洛卷积)”,acm transactions on graphics,第37卷,第6期,第235篇,2018年11月。如图所示,mc卷积层可以由四个参数来表征,其中,符号a|b|c|d表示该层被配置为使用等于d的视场(fov)将点从层次b层映射到层次c。常数a确定在层的输出侧处特征向量的维度。
[0100]
图8示意性地示出了蒙特卡洛卷积层的工作,该卷积层被配置为将特征f从点云域转换到网格域。卷积运算可以被限定为两个函数f和g的乘积的积分:
[0101]
(f*g)(x)=∫f(y)g(x-y)dy
[0102]
其中,函数f是要被卷积的r3(在这种情况下是由特征提取网络确定的特征向量)上的标量函数,函数g是卷积核,是r3上的标量函数。特别地,函数f可以限定对于离散样本xi∈s(给定数据点)的集合s的特征函数。如果除了每个点的空间坐标之外没有提供其他信息,则f可以表示二进制函数,如果点仅由其空间坐标表示,该函数在样本表面具有值“1”,否则值为“0”。在其他变型中,函数f还可以考虑其他类型的输入信息,包括例如颜色、法线等。
[0103]
对于分层网络结构(例如,多层网络),来自第一卷积层的输出表示形成后续卷积层的输入的特征。由于g的值仅取决于相对位置,因此卷积积分是平移不变的。对于大型数据集,评估整个点云上的卷积积分可能是有问题的,因此g的域可以被限制到以0为圆心和半径为1的球体。为了支持多个半径,g的输入可以通过将其除以感受野r(即,卷积核的球形视场(fov)的半径)来被标准化。特别地,可以选择r作为场景边界框直径b的一部分,例如,r=0.1
·
b。由于点云数据被标准化为方差等于1,因此场景边界的直径被认为等于1(b=1)。这将导致尺度不变。这种相对核大小将使处理对具有不同大小(直径)的输入扫描有效。该构造可以得到快速评估的紧凑支持核(compactly supported kernel)。
[0104]
多层感知器(mlp)网络可用于核g,类似于上面引用的hermosilla等人的作品。在实施例中,mlp网络可以确定空间偏移δ=(x-y)/r,包括三个标准化的坐标,并将它们除以感受野r。mlp网络的输出是单个标量。为了平衡准确度和性能,可以使用许多隐藏层(例如,两个或三个),其中,每个隐藏层可以包括多个神经元。在实施例中,隐藏层可以包括6-12个神经元,优选地,8个神经元。mlp核中的参数的数量随着输入和输出向量的维度增大。因此,在实施例中,具有多个输出(其表示不同的g核)的一个mlp可用于减小可训练参数的数量(例如,如果mlp的输出产生8个不同的g,则减少8倍)。由于mlp网络的输出相对于其输入是可微的,因此可以使用反向传播算法来更新核的参数。在实施例中,可以使用梯度下降优化方案来训练网络。
[0105]
为了计算每个采样点中的卷积,需要评估卷积积分。由于仅特征函数f的样本集可用,因此可以使用所谓的蒙特卡洛积分来确定3d点云空间中点x处的卷积的估计。在蒙特卡洛积分方法中,随机样本集可用于计算积分值。基于该方法,点x的卷积的估计可以由以下表达式给出:
[0106][0107]
其中,n(x)是邻域指数(neighbourhood index)集,即,属于半径为r(感受野)的球
体中的相邻点的指数的集合,plx是当点x是固定的时(即,在点x处计算卷积)点处的概率密度函数(pdf)的值。这里,x是点云的3d空间中的任意输出点,其不一定需要与输入点集中的点重合。在实施例中,mccnet的第一卷积层的输出可以是3d网格的点(在本技术中,3d网格的点也被称为节点,以使其区别于点云的点)。在更深层(第2层和后续层)中,每层的输出点可以是初始3d网格的点的子集。这些输出点被称为代表点。蒙特卡洛卷积的该特性允许重新采样到其他层次或其他规则域(例如,节点的均匀3d网格)或不规则域(节点的非均匀3d网格)。
[0108]
在3d网格的节点分布不均匀的情况下,对于每个点plx的值将是不同的,并且可能不仅取决于样本位置还取决于感受野(即,fov)的半径r以及感受野中其他点的分布。由于给定点云的样本密度是未知的,因此可以通过称为核密度估计的技术对其进行近似。估计的函数在样本密集的情况下具有高值,而在样本稀疏的情况下具有低值。该函数可以基于以下表达式计算:
[0109][0110]
其中,δ是确定所得样本密度函数的平滑度的带宽,h是密度估计核,其是非负函数,其积分等于1(例如,高斯函数),d是r3的三个维度之一,以及σ是高斯窗的半径。可以使用其他类型的函数来代替高斯核密度估计器,包括但不限于epanechnikov、quartic或tri-cube核估计器。
[0111]
mc卷积在3d网格808中节点位置x800处的点云样本上的应用在图8a和图8b中示出。图8a描绘了点云的3d输入空间(输入空间)中节点的3d网格。为清楚起见,未示出点云的点。
[0112]
图8b描绘了节点x周围的区域的更详细的图示。该图描绘了节点x和节点x周围的点云的点为了清楚起见,在图8b中,除了节点x之外的3d网格808的节点未示出。为了计算卷积,与球形视场(fov)802(半径等于r)内的点相关联的特征由mlp核处理。对于fov中点云的每个点804,可以局部计算点密度函数(pdf),其具有半径等于σ的高斯窗806。注意,代替节点的规则的3d网格,可以使用节点的不规则的网格,例如,如参照图7所描述的。
[0113]
关于给定节点x的点的pdf总是相对于感受野中的所有其他点。因此,不能预先计算点的密度,因为它的值对于由x和半径r限定的每个感受野都是不同的。在均匀采样的情况下(例如,体素或点的均匀分布(例如,均匀网格)),对于所有给定的点,密度函数p可以被设置为恒定值。由mc卷积层计算出的卷积的输出相对于核的输入和学习参数是可微的。
[0114]
图9至图11描绘了对象分类网络、对象位置预测器网络和掩模预测器网络的示例性网络架构。如图9和图10所示,分类和位置预测器网络都被实现为全连接(fc)mlp网络,其被配置为接收来自对象提案网络的特征向量。每个网络都包括fc mlp层902
1-4
、1002
1-4
的堆叠,每个层都被批量标准化层904
1-3
、1004
1-3
分隔开。这里,参数c表示全连接网络的每层中的神经元个数。
[0115]
图9的对象分类网络可以从对象提案网络接收特征集900,其中,每个特征集限定
3d锚点中的特征。在实施例中,特征集可以表示特征矩阵。如上所述,每个特征集可以包括固定数量的特征。基于特征集,对象分类网络可以确定分类的3d锚点906即,3d边界框,每个3d锚点都以3d网格的节点为中心。分类的3d锚点可以与指示3d锚点包括或不包括对象实例的概率的分数相关联。在实施例中,可以训练对象分类网络以执行二进制分类。在这种情况下,网络可以确定3d锚点是包括限定对象实例(例如牙齿)还是不包括限定对象实例(背景)的点。在另一个实施例中,对象分类网络可以被训练为确定不同类别的对象实例,例如,门牙和臼齿。
[0116]
图10的位置预测器网络可以从对象提案网络接收正分类的3d锚点(即,包括对象的3d锚点)的特征集900,并生成限定对象相对于3d锚点的节点的中心位置的偏移以及限定准确地包含对象的3d边界框的尺寸相对于3d锚点的尺寸的尺寸偏移(例如,缩放值)。因此,位置预测器网络可以确定3d锚点尺寸与对象的尺寸之间的差(delta)以及3d锚点的中心位置与对应对象的位置的中心之间的差。在另一个实施例中,位置预测器网络可以确定位置和尺寸的绝对值。
[0117]
图11描绘了根据本发明的实施例的掩模预测器网络的示意图。如参考图3所述,3d裁剪模块使用每个对象体积的位置和尺寸来从点云中裁剪出对象块,其中,每个对象块可以限定包括表示由对象检测器预测的(检测到的)对象的点的点集。3d裁剪模块可以使用m
×
k个对象体积中的每一个来从点云裁剪p个点,其中,每个点与特征向量相关联,导致m
×k×
p个特征向量(每个特征向量具有多个(例如,256个)特征元素)。
[0118]
如图所示,通过将值1分配给在检测到的边界框内的所有点并将0分配给框外的点而构建的m
×k×
q个掩模中的每一个被传递给掩模生成器。此外,将大小为n x 256的所有点的第一特征向量提供给掩模生成器。这里,q是检测到的对象(即,牙齿)的数量。掩模生成器的输出是每个边界框内的点的二进制分类。因此,可以将m
×k×
p
×
3个点1100和m
×k×
p
×
256个相关联的特征向量1101中的每一个提供给网络的输入。掩模预测器网络可以包括基于mlp的网络。在实施例中,基于mlp的网络可以具有pointcnn网络架构(例如,参考图5和图6所描述的)。或者,基于mlp的网络可以基于能够处理点云的其他神经网络,包括(但不限于)pointnet、pointgrid、mccnet、pointcnn、pointnet++、spidercnn等。如图11所示,基于mlp的网络模型1102可以包括χ-conv层1104
1-3
的(小)堆叠,其中,每个χ-conv层可以被配置为在由卷积算子进行处理之前对输入点及其对应的特征进行加权和置换。
[0119]
掩模预测器网络可以对每个对象块内的点进行分类。在实施例中,它可以执行将对象块的点分类成两个类别的二进制分类。例如,在ios数据的情况下,二进制分类可以将点分类成第一点(例如,可能属于牙齿实例的前景点)和第二点(例如,可能属于其他牙齿或牙龈的背景点)。
[0120]
因此,如上面参考图1至图11所述的用于点云的对象检测和实例分割的深度学习系统可以提供用于分割点云的准确且高性能的系统,而无需体素化。在高层次处,深度学习系统可以被视为用于基于2d像素的图像的实例分割的公知的掩模r-cnn系统的3d点云模拟,如shaoqing he,k.等人的文章中所描述的:“mask r-cnn”,proceedings of the ieee international conference on computer vision(ieee计算机视觉国际会议论文集),第2961-2969页(2017年)。因此,根据本发明的深度学习系统可以称为mask mcnet,其具有作为骨干网络的特征提取网络、作为区域提议网络(rpn)的对象提案网络和用于分类、回归和
掩模生成的三个预测器网络。
[0121]
参考图1至图11描述的深度学习系统的训练可以使用端到端训练方案(例如,梯度下降和adam学习适应技术)来执行。例如,可以使用批(batch)大小为32的1000个代(epoch)(在正锚点与负锚点之间均衡)。输入的预处理可以包括点云的标准化以获得零均值和单位方差。
[0122]
训练集可以包括标记的点云样本集。例如,在ios数据的情况下,训练集可以包括牙列的光学扫描,例如来自不同成年受试者的牙列的数百次光学扫描或更多,每个扫描包含一个上颌扫描和一个下颌扫描(例如如图3所描绘的)。可以使用3d扫描仪(例如,3shape d500光学扫描仪(3shape as,哥本哈根,丹麦))记录ios数据,该ios数据平均包括180k个点(在[100k,310k]的范围区间内变化)。数据集可能包括来自健康牙列的在受试者之间具有各种异常情况的扫描。
[0123]
在实施例中,光学扫描可以被手动分割,并且其相应的点可以由牙科专业人员进行标记并根据fdi标准分类成32个类别之一,并由一名牙科专家(dam)进行审查和调整。光学扫描的分割可能平均花费45分钟,这表明点云的分割对人类来说是艰巨的任务。
[0124]
损失函数可用于训练本技术中描述的实施例的网络。mask-mcnet的损失函数可以包括来自mask-mcnet的不同网络的损失贡献。在实施例中,损失贡献可以包括与对象分类网络的输出相关联的第一损失贡献、与对象位置预测器网络相关联的第二损失贡献和与掩模预测器网络相关联的第三损失贡献。在实施例中,损失贡献可以类似于由shaoqing he,k.等人(上面所引用的)用于mask r-cnn的损失函数,其中使用了三个损失贡献,其中三个损失贡献中的每一个的贡献相等。
[0125]
在实施例中,第一损失贡献(分类损失)可以限定分类分支(对象分类网络)在其输出层(例如,softmax层等)上的交叉熵损失值。在实施例中,第一损失贡献可以如下计算:
[0126][0127]
其中,pi可以限定3d网格的节点是具有对象(具有高iou)的3d锚点的中心的概率,以及p
i*
是从集合{0,1}中选择的其地面真值。参数na限定3d网格的节点数。
[0128]
在实施例中,第二损失贡献(回归损失)可以限定回归分支(对象位置预测器网络)的输出层(优选地,线性输出层)处的均方误差。在实施例中,可以如下计算第二损失贡献:
[0129][0130]
其中,ti可以限定三个元素的向量,这三个元素表示3d锚点的中心位置或尺寸的delta值,以及ti*是其地面真值。参数n
p
可以限定输入的ios中正锚点的数量。
[0131]
在实施例中,第三损失贡献(掩模损失)可以限定用于掩模分支(掩模预测器网络)的输出层处的正锚点(优选地,每个正锚点)中的点(优选地,所有点)的分类的二进制交叉熵损失。只有当3d锚点被标记为正时,才可以考虑回归损失和掩模损失。可以根据以下表达式计算掩模损失:
[0132][0133]
其中,pi是点属于被3d锚点包围的对应的对象的概率。这里,pi*是来自集合{0,1}
的地面真值的值。参数nm可以限定第i个3d锚点内的点的数量。在训练过程中,回归损失和质量损失可以分别用于改变目标位置预测器网络的权重和掩模预测器网络的权重。
[0134]
在系统的训练过程的示例性实施例中,如果3d锚点与标记的点云块中的任何牙齿实例的重叠高于第一阈值,则该3d锚点可以被标记为正。在实施例中,第一阈值可以是0.4iou,其中,iou限定平均雅卡尔(jaccard)指数。在另一个实施例中,如果3d锚点与标记的点云块中的任何牙齿实例的重叠低于第二阈值,则它可以被标记为负。
[0135]
在实施例中,第二阈值可以是0.2。由于正负3d锚点的数量高度不平衡,每个训练批次的大约50%可以从正3d锚点中选择,每个训练批次的大约25%从负3d锚点中选择。训练批次中其余的25%采样3d锚点可以从边缘3d锚点(例如,(0.2《iou《0.4),其也被认为是负样本)中选择。
[0136]
此外,在实施例中,在训练阶段,mask-mcnet的输入可以是点云的随机裁剪的块。每个裁剪的块可以包括多个对象实例,例如,2至4个牙齿实例。在实施例中,可以构建均匀网格域。在另一个实施例中,可以通过滤掉在每个尺寸中具有0.04(下限)空间分辨率的密集规则网格的节点来构建非均匀网格域。网格分辨率的上限可以设置为等于0.12。为了在3d锚点与小对象和大对象两者(例如,分别为门牙和臼齿)之间产生足够的重叠,可以使用不同尺寸的3d锚点。例如,在实施例中,可以采用两种类型(k=2)的3d锚点框(尺寸为[0.3,0.3,0.2]和[0.15,0.2,0.2])。
[0137]
图12a和图12b描绘了根据本发明的各个实施例的训练深度学习系统的流程图。图12a描绘了训练深度神经网络系统以用于点云中的对象检测的流程图。深度神经网络可以包括根据本技术中描述的任何实施例的特征提取网络、对象提案网络和对象分类网络。如图所示,在第一步骤(步骤1202)中,可以将包括一个或多个标记的对象实例的训练点云样本提供给深度神经网络系统的输入。深度神经网络系统可以至少包括被配置为用于点云中的对象检测的特征提取网络、对象提案网络和对象分类网络。进一步的步骤(步骤1204)可以包括由对象提案网络基于由特征提取网络确定的点云特征来计算对象提案。这里,对象提案可以限定3d边界框,该3d边界框可以包括限定对象的点。这样的3d边界框可以被称为3d锚点。训练过程还可以包括确定3d锚点与训练点云样本中的标记的对象实例的3d边界框之间的重叠(步骤1206)。如果重叠高于预定阈值,则可以将3d锚点标记为正,如果重叠低于预定阈值,则可以将3d锚点标记为负。接下来,可以使用3d锚点中的特征来确定对象分类网络对3d锚点的对象预测(步骤1208)。
[0138]
因此,正标记的3d锚点和负标记的3d锚点两者均用于对象分类网络的训练。对象分类网络可以预测3d锚点应该被标记为正(包含对象)还是负(不包含对象)。在训练期间,在这两种情况下,第一损失函数都用于确定贡献(即,如果预测正确,则损失的值为0(没有校正),但如果预测错误(虽然是正的但是为负预测,或者相反),那么损失值将是正的(并且将对网络进行校正))。对象预测和损失函数可用于获得损失值。最后,损失值可用于使用反向传播方法训练特征提取网络、对象提案网络和对象分类网络。
[0139]
图12b描绘了根据本发明的实施例的训练深度神经网络系统以用于点云的实例分割的流程图。在步骤1222中,可以将包括一个或多个标记的对象实例的训练点云样本提供给深度神经网络系统的输入。这里,深度神经网络系统可以被配置为用于点云的实例分割。这种网络可以至少包括特征提取网络、对象提案网络、对象分类网络、对象位置预测器网络
和掩模预测器网络。
[0140]
训练过程可以包括由对象提案网络基于由特征提取网络确定的点云特征来计算对象提案(步骤1224),其中,对象提案可以限定3d边界框,该3d边界框可以包括限定对象的点。这种3d边界框可以限定3d锚点。在进一步的步骤(步骤1226)中,可以确定3d锚点与训练点云样本中的标记的对象实例的3d边界框之间的重叠,其中,如果重叠高于预定阈值,则3d锚点可以被标记为正,而如果重叠低于预定阈值,则3d锚点可以被标记为负。
[0141]
对象分类网络可以基于3d锚点中的特征来为正标记的3d锚点或负标记的3d锚点确定对象预测(步骤1228)。对象分类网络预测3d锚点应该被标记为正(包含对象)还是负(不包含(完整)对象)。在训练期间,在这两种情况下,第一损失函数用于确定贡献(即,如果预测正确,则损失的值为0(没有校正),但如果预测错误(虽然是正的,但是为负预测,或者相反),则损失值将是正的(并且将进行网络的校正)。这样,对象预测与地面真值(标记对象)之间的差异可用于基于第一损失函数确定第一损失贡献。
[0142]
对象体积的位置和尺寸预测可以由对象位置预测器网络基于3d锚点中的特征来确定(步骤1230)。这里,对象体积可以是3d边界框,其中心应该与正分类的3d锚点的中心重合,并且该3d边界框具有应该紧密匹配对象实例的尺寸的尺寸。预测的位置和大小与地面真值(标记的位置和大小)之间的差异可用于基于第二损失函数确定第二损失贡献。差异越大,损失贡献越大。
[0143]
分类的点可以由掩模预测器网络基于对象体积中的第一点云特征来预测,该分类的点可以包括属于对象实例的第一分类点和不属于对象实例的第二分类点。预测的点分类与地面真值(标记的分类点)之间的差异可用于基于第三函数确定第三损失贡献(步骤1234)。第一损失贡献、第二损失贡献和第三损失贡献可用于使用反向传播方法训练特征提取网络、对象提案网络、对象分类网络、对象位置预测器网络和掩模预测器网络(步骤1234)。
[0144]
对新点云(例如,新的ios数据集)的推断可以通过在若干个裁剪的重叠的块上应用mask-mcnet来执行。给出3d块并应用具有最高限定分辨率(例如0.04)的节点的均匀3d网格,分类分支将定位在3d网格的节点上的3d锚点分类为对象/无对象。正分类的3d锚点(即,检测到的对象)的尺寸和(中心)位置根据由回归分支(即,对象位置预测器网络)估计的值进行更新。图13描绘了由mask-mcnet确定的正分类的3d锚点1302
1,2
和表示地面真值的3d边界框1302
1,2
的可视化。如图所示,两个3d锚点具有不同的尺度和中心位置。正分类的3d锚点与地面真值3d边界框的重叠高于第一阈值(以iou为单位),该第一阈值用于将3d锚点标记为正(即,包含对象(的部分))。
[0145]
与faster-rcnn类似,对于每个对象,可以检测到多个3d锚点,其中,每个3d锚点与高于第一阈值的概率分数相关联。因此,可以根据最高的客观分数(objectiveness score)(来自分类概率)采用非极大值抑制算法。因此,基于该算法,可以确定具有最高概率分数的3d锚点。非极大值抑制还通过将输入的块重叠来处理重复点。在预测所有牙齿实例的边界框之后,从掩模生成分支取得边界框内所有点的掩模非常简单。
[0146]
在图14a至图14h中可视化了mask-mcnet进行的ios实例分割的示例。这里,图14a和图14b描绘了正常牙列的分割。图14c描绘了包括具有缺失数据的经分割的牙齿的分割牙列。图14d至图14f描绘了包括具有异常和伪影的经分割的牙齿的分割牙列。图14g和图14h
示出了分割失败的两个示例。
[0147]
与最先进的分类网络相比,mask-mcnet的性能通过五重交叉验证进行评估。平均jaccard指数(也称为iou)用作分割指标。除了iou之外,还通过将每个类别单独(one-versus-all,一对多)视为二元问题来报告多类分割问题的精确度和召回率(recall)。此外,还报告了平均分数。mask-mcnet的性能如表1所示。如表1所示,提出的mask-mcnet在性能上明显优于能够分割点云数据的最新网络。
[0148][0149]
*
nvidia titan-x gpu
[0150]
表1
[0151]
图15描绘了根据本发明的实施例的对经分割的点云后处理的流程图。出于临床目的和牙齿标记分配的一致性,后处理方法可用于将由mask-mcnet预测的实例标签(经由查找表)转换成fdi标准标签。通过测量训练数据内fdi标签的平均中心位置和大小,组合搜索算法可以确定最可能的标签分配,它满足在约束满足问题(csp)的背景下的预定约束(对训练数据的先前测量)。有限域上的约束满足问题通常使用搜索形式来解决。用于这种搜索的技术可以是回溯、约束传播或局部搜索的变型。
[0152]
图16是示出可以在本公开中描述的实施例中使用的示例性数据处理系统的框图。数据处理系统1600可以包括通过系统总线1606耦接到存储器元件1604的至少一个处理器1602。这样,数据处理系统可以将程序代码存储在存储器元件1604内。此外,处理器1602可以执行经由系统总线1606从存储器元件1604访问的程序代码。在一方面,数据处理系统可以被实现为适合于存储和/或执行程序代码的计算机。然而,应当理解,数据处理系统1600可以以包括能够执行本说明书内描述的功能的处理器和存储器的任何系统的形式来实现。
[0153]
存储器元件1604可以包括一个或多个物理存储器装置,诸如例如本地存储器1608和一个或更多个大容量存储装置1610。本地存储器可以是指随机存取存储器或在程序代码的实际执行期间通常使用的其他非持久性存储器装置。大容量存储装置可以被实现为硬盘驱动器或其他持久性数据存储装置。处理系统1300还可以包括一个或更多个高速缓冲存储器(未示出),其提供至少一些程序代码的临时存储,以便减少在执行期间必须从大容量存储装置1610中取回程序代码的次数。
[0154]
描绘为输入装置1612和输出装置1614的输入/输出(i/o)装置可以可选地耦接到数据处理系统。输入装置的示例可以包括但不限于例如键盘、诸如鼠标的定点装置等。输出装置的示例可以包括但不限于例如监视器或显示器、扬声器等。输入装置和/或输出装置可以直接或通过中间i/o控制器耦接到数据处理系统。网络适配器1616也可以耦接到数据处理系统,以使其能够通过中间专用或公共网络耦接到其他系统、计算机系统、远程网络装置和/或远程存储装置。网络适配器可以包括:数据接收器,用于接收由所述系统、装置和/或
网络传输到所述数据的数据;以及数据发送器,用于将数据传输到所述系统、装置和/或网络。调制解调器、电缆调制解调器和以太网卡是可以与数据处理系统1650一起使用的不同类型的网络适配器的示例。
[0155]
如图16所示,存储器元件1604可以存储应用程序1618。应当理解,数据处理系统1600还可以执行可以促进应用程序的执行的操作系统(未示出)。以可执行程序代码的形式实现的应用程序可以由数据处理系统1300执行,例如由处理器1302执行。响应于执行应用程序,数据处理系统可以被配置为执行本文将进一步详细描述的一个或更多个操作。
[0156]
在一方面,例如,数据处理系统1600可以表示客户端数据处理系统。在这种情况下,应用程序1618可以表示客户端应用程序,所述客户端应用程序在被执行时配置数据处理系统1600以执行本文中参照“客户端”描述的各种功能。客户端的示例可以包括但不限于个人计算机、便携式计算机、移动电话等。在另一方面,数据处理系统可以表示服务器。例如,数据处理系统可以表示服务器、云服务器或(云)服务器的系统。
[0157]
本文所使用的术语仅出于描述特定实施例的目的,而不意图限制本发明。如本文所使用的,单数形式“一”、“一个(种)”和“该”也意图包括复数形式,除非上下文另外明确指出。将进一步理解的是,当在本说明书中使用术语“包括”和/或“包含”时,指明存在所述的特征、整体、步骤、操作、元件和/或组件,但并不排除存在或附加一个或更多个其他特征、整体、步骤、操作、元件、组件和/或其组。
[0158]
以下权利要求中的所有部件或步骤加上功能元件的对应结构、材料、作用和等同物旨在包括用于与具体要求保护的其他要求保护的元件组合地执行功能的任何结构、材料或作用。已经出于说明和描述的目的给出了本发明的描述,但并不意图是穷举的或将本发明限制为所公开的形式。在不脱离本发明的范围和精神的情况下,许多修改和变化对于本领域普通技术人员而言将是明显的。选择并描述实施例是为了最好地解释本发明的原理和实际应用,并使本领域的其他普通技术人员能够理解具有适合于预期的特定用途的各种修改的本发明的各个实施例。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1