用于设计期望有机分子的有机合成途径的系统和方法与流程
用于设计期望有机分子的有机合成途径的系统和方法
1.相关案例的交叉引用
2.本技术要求于2019年10月1日提交的标题为“systems and method for designing organic synthesis pathways for desired organic molecules”的美国临时专利申请第62/909,160号的优先权,所述临时专利申请以其整体并入本文。
技术领域
3.所要求保护的主题总体上涉及化学合成领域,并且更具体地涉及用于使化学合成途径的确定和显示自动化的方法。
背景技术:
4.通常,对于上市的每种药物,需要在实验室中制备多达20,000个药物样分子并进行测试。制备分子的过程被称为化学合成。逆合成的任务是寻找反应生成目标分子的底物。确定如何合成分子效率很低且容易出错。这涉及化学师人工审查数十篇或数百篇科学论文。化学合成是药物发现中被忽略的瓶颈。
5.因此,需要加快或甚至自动化确定合同途径的方法和系统。
附图说明
6.实施方案是在附图的图中以实例而不是限制的方式来说明,在附图中,类似的附图标记指示相似的元件,并且其中:
7.图1是用于拟定合成途径的方法的实施方案的流程图;
8.图2是用于拟定合成途径的方法的元件的实施方案中的步骤的流程图;
9.图3是用于拟定合成途径的方法300的实施方案的流程图;
10.图4是用于拟定合成途径的方法的实施方案的步骤的流程图;
11.图5是用于拟定合成途径的方法的实施方案的步骤的流程图;
12.图6是例示用于提取反应模板的方法的实施方案的步骤的图;
13.图7是用于拟定反应的方法的实施方案中步骤的流程图;
14.图8是用于过滤掉可能不正确的反应的方法的实施方案中的步骤的流程图;
15.图9是用于创建阴性反应的方法的实施方案中步骤的流程图;
16.图10是例示用于表示反应的方法的实施方案的图;
17.图11是用于训练用于拟定合成途径的模型的方法的实施方案中步骤的流程图;
18.图12是来自用户界面的实施方案的屏幕截图,该用户界面显示出途径视图的实施方案;
19.图13是来自用户界面的实施方案的屏幕截图,该用户界面显示出来自合成途径的反应的详细视图;
20.图14是来自用户界面的实施方案的屏幕截图,该用户界面显示出目标化合物输入屏幕;
21.图15是来自用户界面的实施方案的屏幕截图,该用户界面显示出用户输入搜索参数的屏幕的实施方案;
22.图16是来自用户界面的实施方案的屏幕截图,该用户界面显示出正在生成结果时显示的屏幕的实施方案;
23.图17是来自用户界面的实施方案的屏幕截图,该用户界面显示出显示部分搜索结果的详细视图的屏幕的实施方案;
24.图18是来自用户界面的实施方案的屏幕截图,该用户界面显示出显示部分搜索结果的详细视图的屏幕的实施方案;
25.图19是来自用户界面的实施方案的屏幕截图,该用户界面显示出显示完成的搜索结果的详细视图的屏幕的实施方案;
26.图20是来自用户界面的实施方案的屏幕截图,该用户界面显示出图19中显示的结果的完整合成途径的屏幕的实施方案;
27.图21是来自用户界面的实施方案的屏幕截图,该用户界面显示出与图19和图20的反应相似的反应的屏幕的实施方案;
28.图22是由实施方案生成的拟定合成途径的实例;
29.图23是替代化合物的实例;
30.图24是由使用替代化合物的实施方案生成的拟定合成途径的实例;
31.图25是来自用户界面的实施方案的屏幕截图,该用户界面显示出已分组的反应的屏幕的实施方案;
32.图26是示出用户界面的实施方案的绘图,该用户界面显示了例示支持信息的屏幕的实施方案;
33.图27是阳性反应和阴性反应的实施方案的图解;
34.图28是用于生成阳性反应和阴性反应的方法的实施方案的图解;
35.图29是示出合成可及性得分的实施方案和已知评分方法之间的相关性的图表;
36.图30是示出针对具有不同数量的反应的途径对合成可及性得分实施方案与已知评分方法进行比较的结果的图表;
37.图31是示出用于拟定合成途径的方法的实施方案的架构的流程图;
38.图32是示出用户界面的实施方案的绘图,该用户界面显示了用于拟定合成途径的方法的搜索树的实施方案;
39.图33是示出用户界面的实施方案的绘图,该用户界面显示了搜索树的实施方案和搜索树的特征;
40.图34是示出用户界面的实施方案的绘图,该用户界面显示了搜索树的实施方案和搜索树的特征;
41.图35是示出用户界面的实施方案的绘图,该用户界面显示了搜索树的实施方案和搜索树的特征;
42.图36是示出用户界面的实施方案的绘图,该用户界面显示了搜索树的实施方案和搜索树的特征;
43.图37是用于拟定合成途径的方法的实施方案的方面的图解;
44.图38是用于拟定合成途径的方法的实施方案的方面的图解;
45.图39是描绘用于实现本公开的方法的实施方案的系统的实施方案的示例性框图;以及
46.图40是描绘计算设备的示例性框图。
具体实施方式
47.实施方案的概述
48.在用于拟定目标分子的合成途径的方法的实施方案中,所述实施方案借助人工智能在数秒内而不是在数小时或数天内设计化学合成。在实施方案中,任何合成途径内的一些中间反应可能完全是新的——从中间反应是该方法创建的,而不是从可访问数据库内的反应过滤掉的意义上来讲。
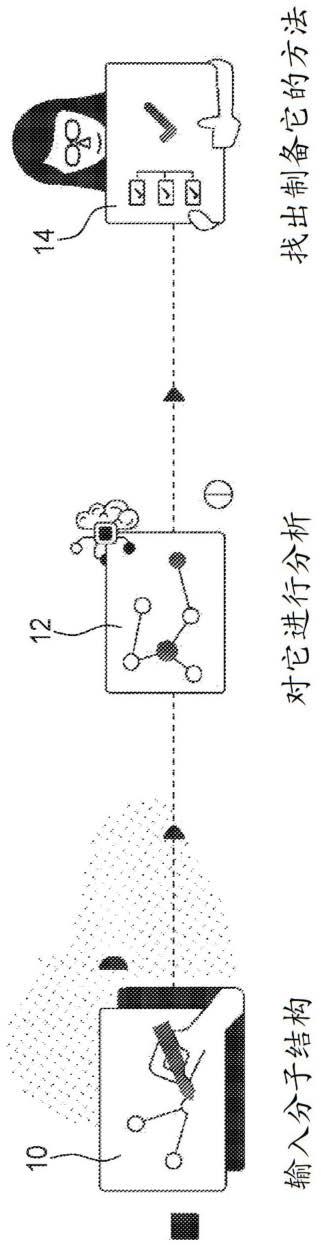
49.图1例示了用于拟定合成途径的方法的实施方案。在第一步骤10中,化学师(该方法的原型用户)将作为合成的目标的分子的结构以及任选的额外标准输入到系统中。在步骤12中,用户启动系统,其分析目标分子并拟定合成途径,这些将在该步骤内详细地描述。一般地,在步骤12中,该系统确定用于从可商购获得的的分子合成目标分子的途径。最后,在步骤14中,任选地根据用户定义的标准对所确定的途径进行排名并呈现给用户。在实施方案中,拟定的途径可能附有显示例如反应可行性的支持性的经实验室测试的证据。
50.图2例示了分析步骤12的元件的实施方案。在图2中,该分析运用生成器20来生成拟定的合成途径。生成器20可为基于模板的或基于神经网络的。在生成拟定的途径之后,鉴别器22确定所生成的反应的概率或可行性。
51.在实施方案的示例性使用中,用户可输入目标分子。例如,奥西替尼的结构。然后,用户可选择适合于后期药物发现的合成标准:介质数量、起始材料的短运输时间。然后,可以启动系统。虽然可能会在几秒钟内获得第一个结果,但完整的结果可能需要数分钟的计算。在实施方案中,该系统采用深度学习——利用有关先前实验的信息找出不同分子之间哪些种类的转化是可行的。然后,该系统能够拟定得到以前未见过的分子的新合成步骤。然后,这些合成步骤被装配成包括从底物到目标分子的所有拟定反应的搜索树。从搜索树中提取从起始材料到产物的途径并进行排名。途径排名可能会考虑并顾及反映实际客户情形的用户选择的标准。完成搜索后,最具有前景的结果在gui(例如,图12)中被示于用户。在屏幕的左侧,用户看到他们的目标分子。借助不同的颜色,用户可以将单个原子或目标分子的结构部分追溯回可商购获得的的分子。因此,使用实施方案,可在数分钟内执行以前需要化学师数小时时间的过程——需要迭代数千次才能开发出仅一种药物的过程。
52.系统功能性的顶层描述
53.在实施方案中,系统和软件设计期望有机分子的有机合成途径,用户在所述系统和软件中输入他们想要制造的一种或多种分子的一个或多个结构。
54.在实施方案中,途径由起始材料(底物)和一个或多个从起始材料得到期望产物(目标分子)的反应的集合组成。
55.在实施方案中,软件利用多种类型的信息,包括先前执行的反应(已知或“参考”反应)的数据库、可商购获得的的起始材料以及用户引入的参数。在实施方案中,软件可允许用户将此信息输入到系统中;然而,该信息的输入不是系统运行所必需的,因为绝对必要的数据是随系统提供的。
56.在实施方案中,软件可能会拟定新化学反应。因此,这些“新”反应未被引入到系统中。相反,它们是软件“动态(on-the-fly)”生成的。系统具有在本文中讨论的反应可行性估计的模块。关于如前面使用的“新”,它意指:由系统创建,并且不是由系统从数据库中检索。因此,新反应可能与系统所访问的数据库内的任何反应或以其他方式提供给系统的任何反应不同。换句话说,新反应未被编程到数据库中,而是由算法生成的。简单来说,从反应数据库提取“哪种类型的反应是可能的”的规则,并且然后它们应用于到任何化学化合物,甚至未见过的化学化合物。这将在后面的“反应拟定”部分中描述。因此,已知反应可被并入结果中,但实施方案的特征是能够从头生成反应。
57.在实施方案中,软件将拟定的反应装配成多反应合成途径并对这些途径进行排名。将针对搜索树对此进行进一步讨论。首先将反应装配成搜索树结构,然后从该结构提取途径。简而言之,搜索树包括所有可能被用于合成目标分子的不同反应。这些反应被纳入作为搜索树的例如不同分枝、主干、枝干、枝条或树叶。在实施方案中,化合物可用化合物节点表示,并且反应可用反应节点表示。在实施方案中,为指示反应,定向链路可将化合物节点联接到反应节点上,并且定向链路可将反应节点联接到产物化合物或节点上。在实施方案中,单一化合物节点可为一个或多个“上游”反应的产物和单一“下游”反应的底物二者,其中“上游”和“下游”由定向链路确定。在实施方案中,单一化合物可被链路到多个下游反应和多个上游反应二者。也就是说,反应拟定方法的实施方案可确定多个合成特定化合物(其可以是,例如,用户的目标化合物,或者拟定用于合成用户的目标化合物的反应中的底物)的方式。反应拟定机构(mechanism)也可确定在后续反应中使用同一化合物作为底物的几种方式。因此,搜索树的实施方案是互相关联的一组从底物产生用户的目标分子的反应。
58.在实施方案中,反应拟定机构可能会还给用户拟定替代的最终目标分子,该目标分子由搜索树中的这样的合成底物产生,该合成底物具有与该合成底物略微不同的可商购获得的底物。在该实施方案中,修正了发生改变的底物的下游反应以反映该改变,并且经修正过的反应变为搜索树的不同分枝,其产生替代的最终目标分子。然后,用户可决定是否合成该替代目标分子以作为对用户的原目标分子的补充或作为对用户的原目标分子的替代。
59.在实施方案中,排名是通过包括统计和启发法在内的多种方法进行。排名意在呈现途径执行的总估计成本,包括起始材料的成本和合成失败的风险。考虑并顾及了用户偏好。例如,虽然总估计成本可能是最终标准,但如下面针对成本函数所描述的,总估计成本可能取决于用户偏好。
60.在实施方案中,软件根据系统内的信息和由用户引入的信息提供了每个反应和化合物的详细视图,包括支持信息,诸如反应执行条件、价格和起始材料可获得性。支持信息还充当系统决策的基础,在此背景下系统决策包括:整个系统的推理:拟定哪些反应,它们的可行性如何,如何估计它们的成本,将哪些合成路径展示给用户等。
61.在实施方案中,gui允许用户查看拟定的途径并与它们交互。用户可能对规划过程的走向有大的影响。例如,使用gui,用户可挑选出搜索结果中应当被更全面地分析的化合物,并且用户还可以改变搜索策略的行为,如以下所描述。
62.在实施方案中,用户可以以不同格式导出搜索结果和由系统提供的所有信息。它们还可以保存查询和搜索结果供以后使用。
63.在实施方案中,用户可能引入的输入和约束可能会对所拟定的反应产生深远的影
响。例如,用户输入约束可包括:所期望的目标化合物的量、对设备和试剂可获得性的限制(包括,例如,基于每种底物的供应链的约束)、关于合成途径中可能使用的反应的类别的约束,以及关于目标分子详细信息的约束(例如,在合成途径期间目标分子中不得断裂的键)。典型的软件只允许指定与用例不太相关的参数,诸如合成计划中的反应的最大数量、每一数量的起始材料的最大价格、评分功能类型a或b,等等。
64.存在两个主要用例。在第一用例中,用户定义需合成什么终产物。在第二用例中,系统基于用户限定的约束生成类似化合物库,并拟定该库中每种化合物的合成途径。在第二用例中,一次合成多种类似化合物可能比单独合成每种化合物要便宜的多。这是因为人们可以重复使用每种终产物的合成计划共有的中间化合物和起始材料(有点像“规模经济”)。对于第二用例和类似化合物库(例如,基于用户约束,或者基于与用户选择的目标终产物的相似性),该系统可能会为一种类似化合物拟定与拟定用于不同类似化合物的反应途径没有共同中间体或起始底物或者与用户拟定的目标化合物没有共同中间体或起始底物的反应途径。
65.图3是用于拟定合成途径的方法300的实施方案的流程图。在步骤302中,向软件模块提供第一分子结构。分子结构通常将由用户通过gui提供。在步骤304中,软件模块将拟定用于合成第一分子结构的第一多个反应,其中第一多个反应中的至少一个是由计算机模块创建并且不预先存在于该计算机模块可访问的任何位置。在该拟定步骤中,软件模块将使用所述第一分子结构和由利用已知反应进行的机器学习生成的模型。在步骤306中,软件模块将从所述第一多个反应中提取至少一个产生所述第一分子结构的第一反应途径。在步骤308中,软件模块将确定每个经提取的第一反应途径的成本。在步骤310中,软件模块将根据所确定的成本对每个经提取的第一反应途径进行排名。并且在步骤312中,软件模块将提供包括呈根据所述排名确定的顺序的每个第一反应途径的列表。
66.用统计模型协助逆合成
67.在实施方案中,所述软件的主要特征是能够拟定产生目标化合物的化学反应。这是借助机器学习模型进行的,该机器学习模型使用关于以前执行的成功反应(在本文中被称为阳性反应或“参考反应”)的信息。在实施方案中,也可使用阳性反应和阴性反应来训练模型,其中所述阴性反应包括关于已知不成功反应的信息或关于被指定为“不可行”的所拟定的反应的信息,或者关于已知不成功的反应和所拟定的不可行的反应二者的信息。
68.拟定目标化合物的候选反应
69.在典型的逆合成方法中,响应于用户输入化学化合物,系统输出许多产生所述化学化合物分子的候选反应。候选反应的数量可能极大,因此在实施方案中,该数量可能是有限的。在典型的逆合成方法中,这是由反应生成器完成的,所述反应生成器可使用若干种技术中的任何一种。1)反应可通过将模板应用于所述目标化合物而生成。单步逆合成的反应模板是将目标化合物重写为底物的规则。在合成规划软件的背景下,反应模板通常是被自动地从反应数据中提取出来的。它们还可以被手动精选,并且包括一组能够应用该模板的条件。统计模型可在参考反应的数据集上进行训练。它可以以很多方式实现。一个实例是一对神经网络,其中所述第一网络预测目标化合物中发生反应的位点,并且所述第二网络基于所述目标和所述反应位点生成完全反应。2)系统可以搜索其中产物类似于所述目标化合物的参考反应。为度量化合物之间的相似性,可以使用充分确立的技术,诸如分子指纹。在
实施方案中,使用其中反应位点与目标化合物匹配的一些最类似的参考反应,并应用它们以获得候选反应。
70.单独地,前者的方法可能是用于逆合成的已知方法。然而,在实施方案中,我们的系统可能以新的方式组合这些方法。统计模型可以被用来帮助在参考反应的数据库中进行搜索。这些方法可在两个方向获益:相关的参考反应可以增强统计模型,并且统计模型可以改善参考数据库中的搜索。
71.可以对统计模型进行训练,使得搜索在参考反应的数据集上最有效,即对于来自参考反应的产物,尽可能经常地拟定相应的参考反应。这可以按若干种方式中的任何一种进行。1)训练学习化合物之间的相似性函数(similarity function)的模型。这可被用来使相似性量度与反合成任务更相关。2)训练预测期望参考反应(例如,反应的类型)的一些性质的模型。然后,可将参考反应仅限于符合一些预测标准且可能与用户更相关的那些反应。
72.输入界面描述
73.在实施方案中,输入界面是允许通过以下一种或多种形式输入期望分子的一种或多种结构的工具:机器可读的格式,如smiles、化学表格文件;插入式外部分子编辑器;在已与软件整合的外部数据源中搜索该结构;通过api自动进行;或者内置分子编辑器。
74.在实施方案中,输入界面是允许用户引入途径设计过程中使用的数据和偏好的工具。例如,该界面可被用于:插入外部数据源;以及/或者直接通过该界面引入关于起始材料、排名偏好、反应条件和其它影响搜索的因素的信息。
75.搜索树
76.在实施方案中,搜索树是可被系统用来装配合成途径的基本数据结构。
77.在实施方案中,搜索树可以是由反应节点和化学化合物节点构成的有向图。在搜索开始时,搜索树可由代表产物的单一化学化合物节点-树的根组成。树的结构是下面描述的迭代(“展开”)的直接结果。
78.搜索树在结构上类似于合成途径。合成途径和搜索树之间的主要差异是在搜索树中,可能存在多个产生给定化学化合物的反应。在概念上,搜索树代表可能由我们在搜索过程中拟定的反应装配而成的所有可能合成途径的集合。
79.在实施方案中,途径装配算法通过迭代地“展开”搜索树,然后从中提取合成途径来工作。提取合成途径可能在任何次数的迭代后进行,因此它允许系统甚至在搜索完成之前向用户显示部分搜索结果。
80.在实施方案中,从搜索树提取所有合成途径和/或若干种最佳合成途径和/或符合某些约束的途径亚组/
……
可使用标准动态编程方法完成。
81.图4是例示用于展开搜索树节点的方法400的实施方案的步骤的流程图。方法400描述了搜索树节点的展开的迭代,其中很多此类迭代可在任何搜索树上执行。在步骤402中,选择化学化合物节点来“展开”。该节点可根据搜索策略或用户动作来进行选择。例如,如果用户请求系统投入更多时间来分析某种化合物,则搜索策略可能受该请求约束。作为响应,它将从属于代表用户选择的化合物的节点子树的节点亚组选择节点。通常,在此类情况下,将存在利用此类约束执行的多次迭代。在步骤404中,查询反应拟定机构以生成产物与所选择的节点代表的化学化合物相同的反应。在步骤406中,将其中任何底物与从所选择的节点到根(终产物)的路径上的任何化合物相同的反应从该集合中删除。进行这种删除是
为了避免含有循环(“由b制备a,然后由a制备b”)的合成。在步骤408中,对于每个反应,向搜索树中添加新反应节点。在步骤410中,对于每个新反应节点,从它向所选择的节点添加边。在步骤412中,对于前面创建的每个反应节点:为此类节点代表的反应的每种底物创建化学化合物节点。并且在步骤414中,对于每个新化学化合物节点,从它到相关反应节点添加边。
82.作为该过程的结果,每种化学化合物和每个化学反应在搜索树中可以多次表示为节点。那些节点中的每一个均具有从它到根的不同路径,其代表在合成工艺中利用给定反应或化合物的不同方式。
83.对于搜索树中的每个节点,可能会有额外的数据和/或统计数字存储在内存中,并在每次扩展后更新,以提高算法的性能或允许搜索策略/评分算法的运作(function)。
84.成本函数和合成途径的总估计成本的估计
85.在实施方案中,成本函数被用于计算合成途径的总估计成本以及用于搜索策略目的。成本函数有多种变型。用于计算合成途径的总估计成本的示例性成本函数描述如下。
86.对合成途径中的每个反应节点和化合物节点计算成本函数。终产物的成本函数的值是合成途径的总估计成本。
87.作为起始材料(搜索树中的叶)的化合物节点的成本函数等于化合物节点代表的化合物的价格。它依赖于许多搜索参数。例如:如果用户请求每种起始材料可从多个供应商(这是有用的,因为供应商可能是不可靠的),算法从给定化学化合物的第n最便宜的供应商(其中n=用户希望提供起始物料的供应商的数量)而不是最便宜供应商挑选价格。一般而言,可能有许多方式将起始材料供应商冗余度的要求并入到起始材料的计算价格中。起始材料的价格可能受合成所需的量影响。该量是基于用户想要合成的以参数传入的最终产物的量以及从起始材料节点至终产物的路径上的每个反应的估计收率和化学计量过量的量计算的。(每个反应因非100%收率而发生一些损失,因此需要使用较大量的底物)。用户可以驳回或选择优选的供应商(在实施方案中,用户可以从搜索参数屏幕中的列表中挑选供应商)。可以丢弃运输时间大于用户所请求时间的化合物出价,或者通过在延迟的每一天贴上价格标签来将起始物料的估计运输时间并入到起始物料的价格中(可用化合物的数据库包含运输时间的估计值)。第二个方法允许实施方案顾及这样的事实,即如果合成路径本身较短,则长运输时间可能是可接受的。实施方案可以利用可供用户使用的用户提供的化学化合物数据库或用户的采购数据。
88.合成途径中的其他化合物节点可能是合成途径中一些反应的产物。这些化合物节点中每个节点的成本函数等于相应反应的成本函数。
89.反应节点的成本函数是执行给定反应的估计成本,包括底物的成本、化学师劳动的成本等。在实施方案中,成本函数=(每个底物节点的成本函数总和+线性因子*底物的量+恒定因子)*1/成功概率。
90.成功概率可使用其他部分中描述的反应可行性预测模型得出。(1/成功概率)因子允许实施方案顾及这样的事实,即在失败的情况下,必须再次创建该化合物,可能以完全不同的方式来创建。
91.线性因子可能代表执行化学反应的成本,其随着需要被带入到反应中的底物的量近似线性增长,并且包括催化剂的成本、溶剂的成本等。在实施方案中,最简单的实现方案(implementation)假定每个所拟定反应的线性因子的值相同。它的值可以通过考虑化学合
成中使用的溶剂和催化剂的平均价格来估算(例如,非常常见的溶剂是thf,成本为100美元/升,并且通常对于每摩尔底物,反应需要1l溶剂等)。有了关于过去执行的反应的更精确的数据,实施方案将能够找到用于所拟定反应的最适当的溶剂以及催化剂和条件,并以更精确的方式估计该值。
92.恒定因子代表化学家实际执行化学合成所需的劳动成本,并且它的值可以直接或间接地从搜索参数中推导出来(用户可以直接输入成本或实施方案可以假设一些恒定值,如针对同线性因子所做的)。
93.如前面所描述的,底物的量是基于用户希望合成的终产物的量计算的。
94.参数如何影响向用户呈现哪个途径的实例之一是在请求少量终产物时的情况。在该情况下,执行反应的成本(恒定因子)比起始材料的成本占优势,并导致较短的路径被呈现给用户作为最佳路径,即使如果起始材料是相对昂贵的。相反,对于大量的终产物,更经济合理的是使用少量非常便宜的起始材料,即使需要执行更多个反应。该行为(大量导致长合成,少量导致短合成)与用户的期望匹配,并且是紧急的行为(emergent behavior),即在系统中没有被明确编码的行为。
95.因此,在实施方案中,所提取的途径的成本计算旨在提供执行途径合成的实际成本,而不是合成复杂度的抽象度量。
96.搜索策略(管理设计策略的算法)
97.在实施方案中,搜索策略负责挑选将在搜索过程中展开的节点。在实施方案中,搜索策略可以利用下面描述的成本函数变体
‑“
搜索策略成本函数”。对于搜索树中的每个未展开节点,计算含有指定节点的最便宜的(从搜索策略成本函数来看)合成途径的成本——该成本越低越好。然后,选择一个或几个最佳节点展开。出于搜索策略的目的,那些合成途径不需要具有可商购获得的起始材料。
98.在实施方案中,如果用户想对一些化合物进行更全面地分析,实施方案将从搜索树选择的节点集合限制于那些属于代表给定化合物的节点子树的节点。
99.在实施方案中,搜索策略成本函数和前面描述的成本函数之间的主要差异是出于搜索策略的目的,实施方案未使用起始材料的价格,而是它的估计值,如下面所描述的。价格估计与a*算法(这是技术人员已知用于寻找图中最短路线的算法)中的评价函数的作用一样,并且整个搜索算法可被视为a*算法的经重度修饰的变体,在这里,我们寻找搜索树的最便宜子树(即,最便宜的合成途径),而不是搜索图形中的最短路线。
100.图5是例示用于成本估计的方法500的实施方案中的步骤的流程图。在步骤502中,该实施方案假定每种起始材料是从一些未知反应获得的。在步骤504中,该实施方案假定该起始材料的价格和未知反应的底物的价格可表示为那些化合物的尺寸或复杂度(例如,许多非氢原子)的一些容易计算的量度的数学函数。在步骤506中,该实施方案假定该未知反应的底物的一种或多种尺寸是起始材料的尺寸的一小部分。在步骤508中,该实施方案使用在合成途径的总估计成本计算中使用的反应的成本函数的一些简化形式来表示未知反应的底物成本与起始材料成本之间的关系。在步骤510中,该实施方案求解了描述该关系的方程式,从而获得起始材料成本与其尺寸的显式函数。在该实施方案中,假定:(1)起始材料或未知反应底物的成本与该化合物的量成比例,(2)该反应需要相同尺寸的两种底物,以及(3)该反应的成本的恒定因子可忽略不计。因此,该实施方案得出下面的方程式:
101.f(x)=(r+f(kx)
·
2/y)
·
1/p
ꢀꢀ
方程式1
102.其中:
[0103]-x=起始材料的尺寸,f(x)=起始材料的价格
[0104]-k=底物与产物尺寸之比,kx=未知反应的底物尺寸
[0105]-y=未知反应的收率
[0106]-r=反应成本的线性因子
[0107]-p=未知反应成功的概率。
[0108]
通过指定边界条件:f(x0)=f0,该实施方案可以求解上面方程式1,并且得到:
[0109]
f(x)=(q+f0)(x/x0)
in(y
·
p/2)/ln(k)
_q
ꢀꢀ
方程式2
[0110]
其中q=r
·
y/(2-p
·
y)。此方程式可被系统直接用于由起始材料的尺寸计算估计的价格。因此,该实施方案可以计算合成途径的成本,甚至当起始材料无法获得时也可计算。
[0111]
在实施方案中,如有可能,选择常数r、p、y、k的值以匹配用于计算合成途径总估计成本的成本函数中的常数。
[0112]
不可能的情况的实例是成功的概率,因为它是使用机器学习模型基于每个反应计算的。因此,出于价格估计的目的,在实施方案中,一些乐观值是基于模型输出的概率分布手动选择的。这确保了价格估计值是乐观的,并且使算法有很高的机会找到最优解——就像a*算法中的可容许的启发法(即不高估目标成本的启发法)一样,从而确保找到最优路线。
[0113]
在实施方案中,边界条件值(x0,f0)目前是手动选择的,以匹配有机合成中通常使用的起始材料的平均尺寸,以及大多数化学师认为合理的起始材料的成本。
[0114]
在实施方案中,一项改进是更加微调的尺寸计算:不是计算许多非氢原子,而是将权重分配给分子中的每个非氢原子。加和这些权重从而得到分子的尺寸,以便估计价格。权重可以下面的方式计算。首先,离线生成一组图(搜索开始前),并且给每个图分配因子。为计算搜索期间化合物中原子的权重,系统从这图组中寻找含有令人关注的原子的所有子图。该权重是分配给那些图的所有因子的乘积。
[0115]
在实施方案中,手动挑选子图及其因子是通过考虑分子中使分子的合成更困难(被分配的因子大于1)或更容易(被分配的因子小于1)的频繁存在的片段来完成的。该过程可通过如下方式来自动化:通过算法寻找可商购获得的化合物数据集中的可获得的分子中最频繁存在的子图的集合,然后借助于统计回归分配这些子图的因子以使得使用基于这些因子的尺寸计算出的估计的价格与系统已经由可商购获得的化合物的数据库访问的实际价格相匹配。用同样的方法,可以拟合估计的价格的方程式的常数。
[0116]
在实施方案中,上述搜索参数策略可以通过使用此搜索策略和其他策略(随机或加权随机、bfs、具有不同的——更加乐观或不太乐观的——参数集的搜索策略等)以及使用诸如对通过搜索策略选择的节点运行迭代加深启动等技术并行地选择扩展节点来与其他方法混合。
[0117]
反应拟定
[0118]
在实施方案中,反应拟定方法基于一组由先前执行的反应的数据库生成的模板。
[0119]
在实施方案中,每个模板均可从反应通过算法来生成。模板编码关于以下的信息:
1)作为反应的结果而发生的底物的图结构的改变,以及2)属于该图中发生改变的部分的原子的邻域。
[0120]
在实施方案中,多个反应可能会产生相同模板。例如,图27中的所有反应都产生相同模板。在数据集可能含有错误的情况下,数据集中产生特定模板的反应的数量被用作过滤反应的粗略方法,因为错误的反应趋于产生非常罕见的模板。
[0121]
在实施方案中,模板生成算法需要以下形式的输入:1)底物的图,2)产物的图,以及3)关于映射的信息,即关于产物中什么原子对应于其中一种底物中的什么原子的信息。
[0122]
在实施方案中,生成模板的算法不要求底物或产物被完全映射(即并非底物中的每个原子都需要具有对应的产物原子,反之亦然),并且该算法被设计用于修复映射中的不一致。
[0123]
在实施方案中,底物和产物中的元素并非必须平衡(即,它们不遵守来自wikipedia的引文:“质量守恒定律规定每种元素的量不会在化学反应中发生改变。因此,化学方程式的每一侧必须代表相同数量的任何特定元素”),因此该算法可容忍其中一些底物被省略(例如,在酯水解的情况下,很明显水分子需要以某种形式包含在反应方程式的底物中)或副产物被省略的反应。
[0124]
在实施方案中,映射信息不得重复,也就是说,不应存在具有多于一个对应产物原子的底物原子,反之亦然。备注:此类重复的映射有时可能由某些映射算法生成以指出这样的事实,即有些底物在反应中被使用“多于一次”——化学计量不同于1:1,其中多个分子a与一个分子b反应。
[0125]
图6是例示用于构建反应模板72的方法的实施方案的简图。在图6中,已发生改变的原子或键是由箭头74指示。单键是由线76指示。被去除的“令人厌烦的(boring)”键是由交叉阴影线78指示。特殊映射边由虚线80指示。特殊“缺失键”边由点划线82指示。通配符星号84指示。并且被去除的介于非通配符原子之间的映射边由交叉阴影虚线86指示。在图6中,从反应生成产物66的底物62、64之间的反应60来看,初始图68是子图(即底物子图62、64和产物子图66)的总和。
[0126]
在实施方案中,并且参考图6,模板构建方法在概念上可分成以下阶段:1)注释:对于底物62、64和产物66二者,对于每个原子和原子键,实施方案可确定它们的特征(例如,给定原子或键是否为某个环的一部分或特定尺寸的环、该原子或键是否属于某个特定子图等的信息),并且给键和原子标注这些特征,例如指示器74至86中的一个或多个。每个原子可被额外标记有关于它是否为底物之一或产物的一部分的信息。2)合并:实施方案可创建图68,其是底物62a、64a和产物66a图的简单加和(图6)。因此,在图68中,根据作为输入添加的映射数据,模板生成过程的实施方案可为每一对相应的底物62a、64a和产物66a原子添加特殊“映射”图边80。因此,对于其中键不在底物中而是在产物中被发现的底物原子间的每个键边76,实施方案可在例如底物62a的氮和64a的碳之间添加特殊“缺失键”边82。3)提取反应核心:实施方案可通过选择“令人厌烦的”(解释如下)键78将图68修饰为图70。由此类键连接的每个原子被标记为通配符84,并且去除了令人厌烦的键78。通过以下方式将图70修饰为反应模板72。去除非通配符原子之间的映射边78。重新计算“缺失键”边(它们被去除并根据与前描述的规则相同的规则再次添加)。如下重新计算缺失键边84:由于映射边被去除,因此产物中的氮原子在底物中不再有相应的原子,因此该键不再被视为缺失。丢弃了图
70中不具有任何通配符原子的连接组分(不适用于图70)。因此,保留了底物62b、64b和产物66b。丢弃了该图中不具有任何具有相应原子且在反应过程中发生改变的原子的连接组分。“发生改变(的)”意指其电荷发生改变,或者其被反应过程中发生改变的键连接。因此,丢弃了图70的每一侧上外部两个特殊映射边80。出于统一相同类型的映射反应的不同方式的目的(其益处可根据方程式3进行解释),将映射边86从非通配符原子(n)中去除。在方程式3中,对于如绘制的酯化反应,存在6种不同方式将底物中的氧原子映射到产物中的氧原子上,尽管辨别与生成新酯化反应的目的无关。因此,如前描述的模板生成方法将产生单一模板。
[0127][0128]
在实施方案中,“令人厌烦的”边是不令人关注的边。所有“映射”和“缺失键”边都是令人关注的。不具有相应的边,或者其相应的产物键边是令人关注的,或者其相应的键是不同的(即,相应的键在反应过程中被修饰)的所有键边都是令人关注的。
[0129]
有必要将那些键视为令人关注的(因此在提取模板的过程中不会去除它们),以编码反应过程中发生的底物的图结构的改变。
[0130]
在实施方案中,其他边被视为令人关注的,因此定性上不同的反应类型将产生不同的模板,诸如区分:“由酰卤和醇形成酯”或“williamson酯合成”。这也有助于统一映射相同类型的反应的不同方式。实施方案中其他可以被认为令人关注的键包括:1)所有并非芳族环的一部分的双键和三键;2)所有未将中性碳原子与中性碳原子连接且不是芳族环的一部分的键;以及3)所有未将中性碳原子与中性碳原子连接且连接至少一个发生改变的原子(发生改变的原子在“反应核心的提取”部分中被定义)的键。
[0131]
图7是例示拟定合成途径的方法的步骤的流程图。在实施方案中,为了基于特定模板拟定产生所请求产物的反应,可以使用以下方法。在步骤702中,模板图被分成两个子图:产物模板图和底物模板图。在步骤704中,实施方案然后可以搜索与所请求产物的产物模板图匹配的子图。在步骤706中,对于每个匹配,实施方案可以通过去除产物中匹配的原子和键并添加底物的模板图原子和键来生成拟定的底物集合。在步骤708中,每个连接至匹配的产物原子的键然后可以被与相应的底物原子连接的相同顺序的键替换。在步骤710中,此过程可产生不是有效化学化合物(例如,一些原子可能没有有效的化合价)的底物集合的候选物,并且实施方案然后可以将它们过滤掉。在步骤712中,每一对(其中对包括拟定的底物和产物的集合)均被看作反应。在步骤714中,对于每个反应,实施方案可从其中提取模板。在步骤716中,实施方案可过滤掉所提取模板与用于生成此反应的模板不同的反应。该等同性检查是基于检查图同构以及模板创建过程中生成的注释来完成的。
[0132]
在实施方案中,该过程也可被用来根据所请求底物,通过反转底物模板图和产物模板图的角色来生成可能的产物。备注:上面的描述中使用的作为一对(底物集合的图,产物的图)的反应的表示与机器学习模型所使用的反应的表示相关,因为它不需要元素达到平衡,也不需要反应被完全映射,但在其他方面不同。
[0133]
关于反应拟定方法的实施方案,用于合成具有平均复杂度的示例性目标分子的第一多个反应可能导致系统执行大约三分钟的计算,并且导致拟定例如17,000个反应。从这
个反应集合中,被提取的途径包括以最低成本的顺序排名的满足任何用户提供的约束的那些途径。
[0134]
反应可行性估计
[0135]
在实施方案中,使用机器学习的系统的另一个特征是反应可行性估计。反应可行性估计值可被直接提供给用户,并且可以被用作用于对逆合成步骤中拟定的候选反应进行排名的方法。与对候选反应的拟定相似,实施方案可以使用参考反应的数据集来估计候选反应的可行性。1)实施方案可使用相似性量度(例如使用反应指纹)来寻找与候选反应最相似的参考反应,并且将反应可行性估计为与“最接近的”参考反应的距离的倒数。反应指纹是技术人员已知的,并且可以被用来将反应表示为固定长度的位向量。存在可用于度量反应(例如,候选反应和参考反应)之间的距离的已知指标,诸如euclidean距离或jaccard指数。2)实施方案可利用统计方法估计反应可行性:此类方法涉及基于化学反应的数据集构建(学习)统计模型(利用机器学习,或者更具体地,深度学习技术)。参考反应是数据的主要来源。在统计模型中,实施方案可使用呈无向图的形式的自定义反应表示,这将在下文针对“化学反应表示”进行描述。实施方案可将参考反应看作“阳性”反应,即现实中发生的反应,并且使用自定义启发法生成“阴性”(不可行)反应。存在两个版本的统计模型,如下文在反应可行性估计部分中描述的。
[0136]
在实施方案中,关于反应可行性估计,可引入两项新颖之处:1)构建能够鉴别由系统生成但由于与参考反应数据集的低相似性而被认为在化学上不可能的化学反应的统计模型。该方法的主要优点是构建具有由我们的系统生成但被认为不可行的反应组成的数据集的很大一部分的数据集(其用于训练模型)。该模型有两个使用不同类型的生成的“阴性”(不可行)反应进行训练的版本,如下文在“反应可行性估计的统计模型”中所述的。两种生成这些阴性反应的方法描述于“反应可行性估计的统计模型”部分内。在这些方法中,出于训练机器学习模型的目的,每个标记为“阴性”的反应都被视为不可行。由系统生成的反应事实上不可行的原因是启发式的,这在一些“阴性”反应的情况下实际上可能是不正确的。2)这些统计模型使用呈无向多重图形式的自定义反应表示,其中原子表示为图节点,并且不同类型的边表示反应底物和产物中的化学键,如下面针对“化学反应表示”所讨论的。
[0137]
反应可行性估计的统计模型
[0138]
实施方案可引入两种机器学习方法来使用参考反应数据集估计反应可行性:第一种模拟给定化学反应发生的概率;而第二种鉴别由系统生成的与由参考反应表示的数据分布不匹配的化学反应。在实施方案中,根据以下讨论开发的反应可行性估计值的量度被称为合成可及性得分(sas),其也将通过参考图29、图30c、图37和图38进行进一步讨论。
[0139]
基于实验,使用这两种方法进行训练得到了用于估计反应可行性的最强效的统计模型。
[0140]
1.模拟给定化学反应发生的概率
[0141]
这类模型可被用来通过将反应按其概率进行排名或者过滤掉不可能的反应来辅助逆合成。然而,典型的模型没有专门针对逆向合成设置进行调整,或者根本没有解决逆向合成设置。
[0142]
图8是用于构建用来对用于提供化学反应发生的概率的模型进行训练的数据集的方法800的实施方案中步骤的流程图。在实施方案中,用于训练该模型的反应的数据集构建
如下。在步骤802中,实施方案可以将参考反应看作“阳性”反应,即现实中发生的反应。在步骤804中,对于每个反应,实施方案可为其分配描述该反应的重要细节(特别是哪些键发生改变)的唯一模板。在步骤806中,基于模板出现频率,实施方案从数据集中去除不常见的反应。这种去除可防止无效反应最终出现在数据集中。
[0143]
训练该模型也可使用“阴性”数据,即被确定为实际发生概率很小的反应。此类阴性数据是合成的,并且可以如下构建。首先,对于每个参考反应,实施方案使用其模板生成具有相同底物但不同产物的合成反应。这是正向反应或下游反应,因为流程是从底物到产物。这种合成反应是相同类型的反应,其进行方式与原始反应不同(例如,在底物的不同位点中),并产生替代产物。然后,将获得的反应标记为“阴性”反应,并且在此情况下标记为“正向阴性”反应。
[0144]
该模型可由构造块构建,所述构造块是机器学习模型的充分确立的元件。该实施方案可使用在图输入上工作的图卷积神经网络。然而,该实施方案可能是首次将这种模型用于将反应直接表示为单个图。该模型通过迭代地调适其内部参数来学习基于阳性和阴性数据预测反应可行性。
[0145]
2.鉴别由系统生成的与由参考反应表示的数据分布不匹配的化学反应。
[0146]
这类模型架构和训练方法与以前的模型没有很大不同,但这种模型因以下原因可能是新颖的。首先,它由于在其数据集构建过程中发生了以下概念转变而直接适合于逆合成问题:替代仅使用在参考反应中发现的模板来产生人为的不可行的反应,该实施方案也利用由该实施方案本身生成的反应来构建此类阴性样本。其次,与以前的模型相比,这个模型使用以下额外的统计方法:实施方案使用该实施方案的反应生成器生成反应,并将与参考反应的某些统计数字不匹配的反应添加到阴性反应数据集中。计算这些统计数字的细节下文针对“数据集构建”进行了描述。从生成器的角度来看,目的是使基本事实反应(ground truth reaction)的得分与其它可针对同一产物拟定但未在基本事实数据集中报告的反应相比最大化。
[0147]
数据集构建:实施方案可以使用先前描述的阳性和阴性数据作为基础。
[0148]
图9是用于创建阴性反应的方法的实施方案中步骤的流程图,所述阴性反应在流程是从产物行进到底物的意义上讲是反向的或上游的。在实施方案中,关键想法是添加用下面的程序(其与逆合成过程中反应生成运行的程序相似)创建的额外阴性合成反应。在步骤902中,选择随机参考反应亚集合。在步骤904中,丢弃了每个反应中的底物,仅留下产物。在步骤906中,对于每种产物,执行一个逆合成反应生成步骤,从而生成许多导致该产物的合成的化学反应。在步骤908中,从那些反应中仅选择出那些不符合在相似类型的参考反应中观察到的统计特性的反应。在步骤910中,将所选择的反应标记为阴性反应并添加到基础数据集中。在步骤912中,重复该生成过程直到生成的阴性反应数目超过某个设定的百分比。该百分比是通过手动估计生成的反应的多大部分通常是不可行的来确定的。在实施方案中,用于训练该模型的阴性反应数目处于与阳性(“参考”)反应数目相同的数量级,所述数量级在实施方案中大约为1百万个阳性反应。因此,在实施方案中,该模型可使用大约2百万个总反应进行训练。
[0149]
此类反向阴性实例代表产生给定化合物的替代的(不同于基本事实的)反应。它们在训练机器模型中的使用对于化学师来说并不直观,因为化合物具有许多产生它们的可能
反应,因此反向阴性实例必须含有一些假阳性。
[0150]
模型构建:按照第一模型中进行。第一模型和第二模型之间的差异源自学习过程中使用的不同数据集,而非源自不同的模型结构。
[0151]
化学反应表示
[0152]
上面讨论并被用于估计反应可行性的两种模型都是图神经网络(常用机器学习模型)的类型。然而,实施方案可以使用在图10中例示的作为训练统计模型时使用的输入的呈图形式的化学反应的以下表示。
[0153]
图10是例示用于编码从底物1002开始并产生产物1004的反应的方法1000的实施方案的图。在方法1000中,该反应被表示为包括底物图1006和产物图1008的无向多重图1005。在代表用于机器学习的反应的图1005中,产物1004中并非所有原子都在底物1002中被发现。例如,元素o、n、o 1024在底物1002中未被发现,但如所示地被表示在图1006中,因为它们在产物1004中被发现(n 1036、o 1038、o 1040)。元素o、n、o 1026描绘于产物图1008中。另外,实施方案可能会丢弃一些简单化合物,诸如水,因为它们在底物列表中的存在可以被不言自明地推导出来。因此,多重图1005是完整的,并且假设是氮原子和氧原子来自一些其他化合物,例如no2。在多重图1005中,每个节点(即,顶行1016、1020中的每个原子,它们与第一列1022中的每个原子相同)代表反应中的唯一原子。在底物和产物二者中都存在的原子被表示为单节点。仅出现在底物中或仅出现在产物中的原子也被表示为单节点。换句话说,在实施方案中,每个原子都被表示为单节点,并且如果某个原子既在底物中又在产物中,则它不会被复制并被表示为两个节点,而是被表示为单节点。原子之间存在两类边:一类代表底物中的化学键,另一类代表产物中的化学键。这两类边被分别用两个单独子图1006、1008的邻接矩阵1010和1012表示。矩阵中的每个条目均含有代表一对原子之间的键(以符号示出为单键(-)或双键(=))的化学类型的数值。行和列的顺序对应于提供给反应1004中的原子并被镜像到图1005的列1022中的标签。该顺序由列1022示出并示出在每行1016、1020上方,但该顺序的列表是任选的(尽管有助于举例说明的目的)。图1005描述了反应之前(子图1006)和反应之后(子图1008)原子之间的关系。模型可学习检查底物子图1006和产物子图1008之间的差异以评估反应可行性。为明确起见,多重图1005可用于表示可提供给根据一个或多个实施方案可作为训练输入的统计模型的反应。
[0154]
在图10中所示的实例中,底物子图1006由反应中示出的每个原子的行和列构成。因此,子图1006包括该反应的底物侧中未示出的原子1024。原子可被任意布置,但行1016和1020及其列顺序必须相似。这种布置导致由“自身”指示的身份(identities)的对角线行,其中“自身”线任一侧的信息是另一侧的镜像。因此,在实施方案中,每个矩阵1010、1012可被限制到矩阵的唯一一半。
[0155]
生成完整合成途径
[0156]
前面的段落描述了如何可以为单个目标产物拟定反应的实施方案(“单步”逆合成)。然而,实施方案可为用户提供一个或多个由市场上可获取的简单化学化合物生成目标产物的完整路径(“多步”逆合成)。在实施方案中,存在两种处理多步逆合成的基本方法:在第一种方法中,多步逆合成可通过递归地拟定得到已针对目标分子拟定的化合物的反应,并根据途径的价值的一些启发而选择最有希望的路径来解决。在第二种方法中,多步逆合成任务可使用学习拟定最有前景的反应从而使参考数据集的性能最大化的统计模型来解
决。
[0157]
图11是用于训练用于拟定合成途径的模型的方法1100的实施方案中步骤的流程图。在步骤1102中,该模型使用前面描述的生成器之一生成目标化合物的候选反应。在步骤1104中,该模型选择产生目标化合物的单个最有前景的反应。在步骤1106中,该模型对候选反应中的每个底物重复此过程。在步骤1108中,该模型重复此过程,直到所有最终底物是可在市场上或在某个最大数量的步骤后获取的分子。在步骤1110中,这个第二模型会因为未达到符合最终标准的底物而受到惩罚(punished),并且会因为以最小可能数量的中间反应达到适当底物的路径而受到奖励(rewarded)。
[0158]
我们生成完整合成路径的模型的实施方案至少因为其综合利用内部模块而是新颖的。1)使用模板和/或深度神经网络的生成器。2)与参考数据集的相似性搜索(通过分子指纹或经训练的模型)。3)反应可行性估计器。该生成器可用于拟定许多可能有用的反应,而反应可行性估计器与参考数据集相似性联合用于选择目标化合物的最可能反应。
[0159]
总体途径/途径视图
[0160]
图12是图形用户界面1200的实施方案的屏幕截图,该用户界面显示出从搜索树提取的多步反应途径1210的实施方案。在图12中例示的实施方案中,目标分子1228的途径1210呈现为化合物1212、1214、1216、1218、1226、1230、1232、1234及代表化学反应的方向箭头(链路)1203、1207、1209、1213、1217的集合体。每个箭头均表示一种反应,并从一个或多个反应底物行进至反应产物。因此,许多化合物既是底物又是反应产物。在图12中,用户被提供了从搜索树提取的呈按照许多已提取反应途径的评分(也称为“排名”)确定的顺序的拟定合成途径1210。该得分是如“成本函数和合成途径的总估计成本的估计”部分中确定的合成途径的成本。此外,搜索策略(管理设计策略的算法)部分描述了也可以使用的成本函数的不同变体。对于合成途径中的每种化合物,用户可决定他们是否想以不同方式合成该化合物,或者他们是否想要系统在这个分析部分上花费更多时间。用户可选择化合物,例如1226,并且系统将重新设计该合成途径,即反应1213以及可能的1217的相关上游部分。在图12中,gui 1200包括化合物选项卡1202、反应搜索选项卡1204(其被选中并且可以被命名为“合成计划”)、已保存的反应选项卡1206和评分工具选项卡1208。反应搜索选项选项卡1204显示一种或多种提取的反应途径(例如,途径1210)或反应搜索的状态。为了帮助用户从目标分子1228跟踪结构或官能团到结构或官能团来源,gui 1200可以对目标分子1228的部分进行颜色编码,并将颜色编码传播到所编码部分的来源。例如,目标分子1228具有颜色编码的部分1220a、1222a、1224a。这些部分中的每一个均在原始底物的上游反应中经受了颜色编码。即部分1222a在分子1230中显示为部分1222b,所述部分1222b是部分1220a的源底物。对于1220a部分,该部分存在于分子1232、1223、1226、1214中,并且最终在初始底物1218中作为部分1220f存在。用户可使用此类源信息进一步告知选择,例如有关哪个反应具有反应拟定机构重新设计的选择。在gui 1200的实施方案中,按钮可显示在每个化合物附近,或者用户能够直接点击该化合物。当按钮或化合物被选中时,系统可被请求执行有关该化合物的动作,例如重新设计到达该化合物或从该化合物引出的途径。(参见,例如,图33和图35)一些不太重要的反应可能被隐藏(注:在图12中,没有反应被隐藏)。
[0161]
来自结果的反应的详细视图
[0162]
图13是来自gui 1200的实施方案的屏幕截图,该用户界面显示出来自合成途径的
反应1300的详细视图。在图13中,来自合成途径的反应1300、1330被显示给用户。gui 1200具有状态指示器1314,其指示搜索是否完成。gui 1200包括选项1310和1312按钮,用户可选择这些按钮来重新运行反应拟定搜索1310或显示完整合成途径1312。使用按钮1316、1318,用户可以在经排名(1316较好,1318较差)的从搜索树提取的反应合成途径之间导航,以查看产生相同产物的其他反应。为查看产生当前查看的反应的底物的反应,用户可点击该底物本身。例如,点击底物1324显示产生该底物的反应1330(其仅被部分示出(1332))。在默认情况下,产生相同产物的反应根据其所在的完整合成途径的排名或评分(即,该排名对于途径中的任何特定步骤都不是局部的,而是全局的——适用于整个提取的反应合成途径——其目的是优化整个过程,而不是单个步骤)来显示。用户可以选择使用如由相似性量度确定的按钮1320来查看与反应1300相似的反应,该按钮随后将显示与反应1300相似的相似反应。用户可通过在界面中添加适当的输入或作出选择来影响排名或过滤掉某些反应(图15)。反应可使用相似性量度来分组,以便用户更容易浏览它们。用户可能会影响组的形成方式。在实施方案中,相似性量度是由分组机构使用,该分组机构将修饰该目标分子的相同一部分或多部分的反应分组在一起。在其他实施方案中,分组机构可基于反应类型(如“去保护反应”、“保护反应”、“碳-碳键形成反应”、“官能团相互转化”...)或化学师所熟知且对化学师有意义的其他类别分组。为了阐明,相似的反应是作为所讨论的反应的参考提供的反应(因此点击1320产生显示1300的参考的屏幕);而分组反应是出于更容易浏览而不是查看参考的目的进行的。在gui 1200中,可对反应进行颜色编码,以便用户可以在视觉上跟踪类似的元素、官能团或结构。在反应1300中,在产物1322和底物1324二者中,n元素1326可具有相同的颜色。类似地,cl元素1328可具有不同于n 1326的相同颜色。在反应1330中,n元素1326可以像在反应1300中一样在产物1332和衬底1336、1338中被着色。
[0163]
图25是来自用户界面的实施方案的屏幕截图,该用户界面显示出显示已分组的反应的屏幕的实施方案。每条红线(2506、2508、2510、2512、2514、2516)均标记在每次反应过程中由相应基团形成的键。每个组内的反应都形成了共同的键。
[0164]
图26是例示有关化合物2604的信息2608的显示的用户界面1200的屏幕截图。对于经设计的合成途径中出现的每种可商购获得的化合物,支持信息,例如可帮助确定是购买该化合物还是自行制备该化合物最具成本效益的信息被提供给用户。(也可参见图17至图19、图34、图36和图37)。该信息可能有助于在实验室中更有效地执行合成。在图26中,信息2608指示来自反应合成途径1210的化合物2604可从三个不同的供应商以不同的价格和量获取。供应商是根据它们所属层级进行排名。信息2610与enamine bb供应商有关。enamine bb被列为3级供应商,其在实施方案中意指该化合物有库存。相比之下,4级及更高层级意指该化合物没有库存。因此,用户可使用信息2608作为对拟定的合成反应途径的约束——用户可要求拟定合成途径,以要求可商购获得的化学品能够商购获得且有存货(3级或更低层级)。此外,用户添加的约束可为所要求的数量的具有特定底物库存的供应商。因此,如果在反应拟定机构将化合物2604拟定为待购买底物之前用户要求两家或更多家供应商具有该化合物库存,则化合物2604将不符合该标准。因此,在实施方案中,反应拟定机构将拟定从符合标准或需要他们自行合成的底物产生化合物2604的合成途径。可以从化合物2602和2606获取相似的信息。在实施方案中,对于每家供应商,gui 1200可提供转到供应商/采购地点的能力。对于每个拟定且提取的反应,gui 1200可显示可在系统有权访问的数据中被
发现的最相似反应的参考。实施方案可能能够在外部数据源或用户提供的数据中搜索此类参考。
[0165]
图14是来自用户界面的实施方案的屏幕截图,该用户界面显示出目标化合物输入屏幕。在图14中,gui 1200在化合物选项卡1202内提供了用户输入目标分子1228的能力。在实施方案中,化合物可为从外部源导入的已知化合物(例如,奥西替尼),或者可使用内置的分子编辑器创建。在实施方案中,可对目标分子1228进行颜色编码以帮助用户跟踪某些部分的合成。例如,部分1220a、1222a和1224a可各自具有不同的颜色。类似地,元素1414、1416可以具有相似的颜色,并且元素1418、1420可以具有相似的颜色。颜色编码可帮助用户直接在分子结构上限定搜索约束。
[0166]
图15是来自用户界面的实施方案的屏幕截图,该用户界面显示出用户输入搜索参数的屏幕的实施方案。在图15中,在合成计划选项卡1204内,用户被提供了进度指示器1520以及关于搜索参数的选项。例如,选项1506可规定在反应拟定机构中使用机器学习。选项1508可规定将拟定的反应限制于单步途径。选项1510可规定要求可从一定数量的供应商处获取可商购获得的化合物。选项1512可能涉及合成规模。选项1514可能进一步涉及供应商以及他们运货的能力或时间安排。选项1516可提供标准搜索参数的重写,诸如,例如对被排名以供显示的所提取反应途径的数量的标准限制。在该屏幕内,合成按钮1518的搜索允许用户启动该系统以搜索和拟定反应途径(例如,途径1210)。
[0167]
图16是正在生成结果时的用户界面的实施方案的屏幕截图。在图16中,gui 1200包括计时器1602,其提供自开始搜索目标分子1228的反应合成途径起的时间。反应结果部分1604发生改变从而反映了搜索进度。
[0168]
图17是来自用户界面的实施方案的屏幕截图,该用户界面显示出部分搜索结果的详细视图。在图17中,gui 1200指示搜索已进入主动运行阶段1702。反应结果部分1604已变为显示拟定的反应1203,其中目标分子1228是底物1232和1230之间的反应的产物。价格指示器1710指示底物1230可商购获得以及处于什么价格。底物1232缺乏类似的价格指示器可能指示底物1232不可商购获得。排名的结果指示器1316、1318显示反应1704是计算中此时拟定的39条反应途径中最好的。底物1232缺乏类似的价格指示器也可能是因为该系统能够创建并显示其中一些起始材料不可商购获得的反应途径。也就是说,当用户点击它时,可以显示产生底物1232的反应。
[0169]
图18是来自用户界面的实施方案的屏幕截图,该用户界面显示出部分搜索结果的详细视图。在图18中,gui 1200指示结果(包括途径1704在内的39个反应途径)正在更新1802。
[0170]
图19是来自用户界面的实施方案的屏幕截图,该用户界面显示出完成的搜索结果的详细视图。在图19中,gui 1200指示反应合成已完成1314。因此,用户被提供了重新运行合成1310(可能在改变一个或多个输入参数之后),或显示完整反应合成途径1312的选项。
[0171]
图20是来自用户界面的实施方案的屏幕截图,该用户界面显示出图19中显示的结果的完整合成途径。在图20中,在用户选择显示合成按钮1312之后,gui 1200显示用于合成目标分子1228的完整合成途径1704。在图20中,底物附近的购物车符号指示该底物可商购获得,并且如果被选中,该购物车符号将提供有关化合物的信息。由于还为化合物2008显示出购物车符号,并且拟定了用于合成化合物2008的反应,因此该显示指示系统已经确定合
成化合物2008比购买化合物2008更经济。虚线封闭部分2002指示颜色相似的元素,其可帮助用户跟踪反应产物1228和底物1216、1218、1230、1232、2002、2004、2006、2008及2010之间的途径的方面。虽然未在图20中示出,但目标分子1228的其他部分也可以被着色并通过如图12中所示的反应途径1704跟踪。
[0172]
图21是来自用户界面的实施方案的屏幕截图,该用户界面显示出与图19和图20的反应1203相似的反应,以帮助用户在实验室中执行反应。在图21中,gui 1200显示出目标分子2102,它是底物2104和2106之间的反应2103的产物。在实施方案中,该系统确定目标2102与目标分子1228类似,并且反应2103与反应1203类似。因此,它提供了反应2103以及反应2103的作为反应1203的支持信息的描述。显示反应2103可帮助用户执行反应1203,因为由于相似性确定,用于执行反应2103的反应条件也很可能允许用户执行反应1203。
[0173]
规划多种化合物的合成
[0174]
目前,根据实施方案,反应拟定机构生成搜索树,并从搜索树提取用于合成用户输入的目标分子的反应途径。在实施方案中,用户可以选择单一底物,例如反应途径中的起始底物或中间化合物,并且系统可以通过将所选择的化合物替换为系统从一组候选化合物中所选择的取代化合物(substitute compound)来产生额外的一组反应(位于所选底物的下游)。在实施方案中,候选化合物可以全部是如由系统搜索一个或多个已知化合物的数据库确定的可商购获得的化合物。如果所选择的化合物是中间体(而不是起始材料),则产生的途径会被截断(truncated)——限于下游反应——因为不再需要产生取代产物的上游反应。在实施方案中,用户可以选择取代化合物。在任一情况下,系统都会拟定取代化合物的下游反应。
[0175]
在实施方案中,来自反应途径的中间化合物可以用于第二目标分子的合成。因此,可以拟定两种或更多种合成途径,每种途径均在合成途径中的某个点处发现的共同底物处发散。在实施方案中,拟定的第二目标分子可以是被确定为与如由前面所述的相似性量度确定的用户的目标分子尽可能相似的分子。
[0176]
图22是由实施方案生成并从底物2204、2206和2208产生用户所选择的目标分子2202的拟定的合成途径2200的实例。在实施方案中,用户可以选择底物2204,并且请求系统生成替代化合物的库。从所生成的库中,用户或系统或二者可以选择底物2302(图23)。基于新的底物2302,系统随后修正化合物2204下游的反应以反映化合物2302对化合物2204的取代。图24例示了系统使用化合物2302修正反应的结果。新反应产物2402反映了取代化合物2302的使用。在实施方案中,化合物2402的部分2404a可被着色并通过上游反应追踪为2404b和2404c,以显示部分2404a的起源。类似地,与化合物2302相关的结构可被类似地着色以显示其起源。图22至图24示出了实施方案的两个方面。首先,用一种底物取代另一种底物可能产生不同的目标分子2402与2202。其次,单一底物2206可与两种不同底物2204、2302反应从而产生两种不同的目标分子2202、2402。在显示第一目标分子和第二目标分子及其相关合成途径的gui 1200的实施方案中,用户可以看到合成中间化合物2206和使用化合物2206合成用户的目标分子2202及第二目标分子2402的优势。换句话说,用户可能会看到通过执行三个反应而不是四个反应来合成化合物2202和2402的优势,因为从化合物2208到化合物2206的反应对于这两种途径是相同的。在实施方案中,该系统可以提供被拟定作为替代品并且可以被用户购买来合成库的可商购获得的化合物的列表。
[0177]
在实施方案中,原始底物的替代品可以包括这样的底物,该底物的使用没有使修正的合成途径中的下游反应与原始途径中的反应相比发生实质性改变。也就是说,经修正的合成途径除直接归因于原始底物和被取代的底物之间的结构差异的改变之外与原始途径相同,并且经修正的合成途径不包括下游反应中反应类型或类别的改变。
[0178]
在实施方案中,替代目标分子可按由替代目标分子与原始目标分子的接近程度所确定的排名拟定。在实施方案中,对于来自替代底物的库的每个替代底物,该系统可以生成替代目标化合物。如果第二合成途径中的反应被证明是不可行的,则该系统可能无法生成替代的目标化合物。对于每种替代目标化合物,系统然后执行在替代目标化合物和原始目标化合物之间的比较,并生成相似性得分。系统然后根据相似性得分对替代目标化合物进行排名,并向用户提供最相似的替代目标化合物和相关合成途径,或者经排名的替代目标化合物和合成途径的列表。
[0179]
在实施方案中,在拟定产生替代目标化合物的经修正的合成途径时,反应拟定模块采用了用于拟定原始目标分子至底物的逆合成途径的相同模板。因此,实施方案使用已经被评价并被确定产生可行结果的模板,但在新背景下对它们进行重新评价。换句话说,同一模板可能产生可行反应和不可行反应。统计模型的作用是确定给定反应的可行性。
[0180]
参考图22,规划多种化合物的合成的实施方案可参考其中存在一种用于替换的候选物(化合物2204)、仅一种替换化合物(化合物2302)以及仅一个待修饰的反应(产生2202,如22中所示)的合成途径来描述。在第一系列的步骤(如参考图6所讨论)中,系统从反应中提取反应模板(产生2202,如图22中所示),并将这个反应模板在正向、下游方向上应用于其中一个底物被替换(2206和2302)的底物集合中。结果可能会产生多个反应。
[0181]
如果对于原始反应中的任何未发生改变的底物,在新生成反应过程中发生改变的原子亚集合与原始反应中发生改变的原子亚集合不同,则丢弃新生成的反应。这确保产生的反应修饰(或“发生在(takes place)”)与原始反应相同的底物区域。
[0182]
随后,丢弃根据系统使用的(以及前面所描述的)统计模型不可行的那些反应。通常,最多只剩下一个反应。将这个新生成的反应的产物添加到化合物的库中,该系统将该化合物的库作为可被合成的化合物返回给用户。
[0183]
在利用比图22的合成途径相对更长的合成途径,例如,图20的合成途径1704时,如果用于替换的候选化合物不是合成途径的最终反应(即图20的反应1203)中的底物,那么对从被替换化合物到目标化合物的每个反应重复前面描述的过程。例如,如果图20的化合物2006被替换,将需要对化合物2006和目标分子1228之间的每个反应重复以上步骤。
[0184]
对每个替换化合物重复该过程。由于可能存在数百万种此类化合物,因此可以利用各种优化。当前在系统中实现的一种这样的优化描述如下。在第一步中,系统检测被替换化合物中哪些官能团参与了原始反应。官能团是例如通过沿着“令人厌烦的边”分割被替换化合物的图(参见有关图6的讨论)并将每个所得的连接组分解释为官能团来生成。如果此种官能团的至少一个原子在原始反应期间被修饰,则它被解释为参与了原始反应,因此,替换化合物必须含有此种官能团。
[0185]
随后,不是对每个替换化合物执行上述步骤,而是仅选择出那些具有发生第一修饰反应所需的所有官能团的替换化合物。此过滤是用查找表实现的,其中索引是官能团,值是具有给定官能团的化合物列表。该过程是极快的,并且在绝大多数情况下,将要考虑的可
商购获得的化合物数量减少了至少一个数量级。
[0186]
在实施方案中,所生成的目标化合物的库可以按许多方式分类、过滤或排名。分类可基于替换化合物的商业可获得性,例如每克价格或某一供应商处的可获得性。分类可基于化合物的估计的admet性质,诸如由反应性官能团引起的毒性、溶解度、分配系数等(使用充分确立的方法)。分类可基于产生库中给定化合物的新生成反应的估计的可行性(使用前面描述的统计模型)。分类可基于生成的产物与使用例如充分确立的方法(例如ecfp)的原始合成途径的最终产物的相似性。
[0187]
图27是用于创建阴性反应的方法的实施方案的图解。在图27中,底物2702和2704之间的反应2700被示出为在苯环上具有用于使底物2704与底物2702的碳原子键合从而代替氯原子的四个可能的位置2706、2708、2710、2714。图27示出了“正向”或“下游”反应,因为箭头指示从底物至产物的方向。反应2706被视为阳性反应,因为它是已知的参考反应。在反应2706中,化合物2704在碳2714处被连接至化合物2702。碳2714的位置在化合物2708、2710和2712中也被指示出以供参考。为创建阴性反应2708、2710、2714,使化合物2704在碳位置处键合至分子2702,这未知是否可行,但属于同一反应类别。也就是说,这些是与其中与氯的键被与苯环碳的键替换的产生化合物2706的反应属于同一类别的三个可替代反应。
[0188]
图28例示了用于创建阴性反应的不同方法的实施方案。图28示出了“反向”或“上游”反应,因为箭头指示从产物到底物的方向。在图28中,已知产物化合物2802由底物2808之间的反应2804产生。在图28中,系统通过将模板(任何模板,不仅仅是刚提取的模板)应用于产物确定存在在两种已知反应数据库内未发现的分别具有底物2810a、2810b的组合的其他可能的反应2806a、2806b。反应2806a、2806b随后被指定为阴性反应。在图28中,示出了两个阴性反应,但阴性反应的数量未受限制。
[0189]
在实施方案中,系统使用阳性反应和阴性反应二者训练统计模型,以从反应生成器拟定的反应中鉴别出可行反应和不可行反应。
[0190]
图29是示出合成可及性得分的实施方案和已知评分方法之间的相关性的图表。上面公开了合成可行性得分(sas)的实施方案——合成途径的成本(如“成本函数和合成途径的总估计成本的估计”部分中所述)是sas的实施方案。在图29中,m1得分、快速m1得分、m1得分(分布)和快速m1得分(实验,分布)每个均是系统对每个已提取反应途径确定的合成可及性得分(sas)的实施方案。sas是执行已提取合成途径的难度的量度,其中途径越困难,得到的sas越高。sas基于该系统可用的信息,即已提取的反应,与每个可商购获得的底物相关的信息。注意,在图29中,sas的快速m1得分实施方案可被用于提供每小时数以万计化合物的sas,其指示系统需要处理以对所提取合成途径排名的反应数量。在实施方案中,由于sas度量了给定化合物的合成难度,但不依赖于单一途径——作为例子,具有多个可能途径可降低全部途径将失败的风险,从而降低合成难度。
[0191]
图30c是图表3000,其示出了使用合成可及性得分的实施方案对途径中具有不同步数的合成途径进行评分的结果。图30a和图30b分别是示出使用现有技术方法对图30c中评分的相同反应进行评分的结果的图表3004、3002。每个图表在x轴上列出了反应途径中的步骤数3014。来自sas图表3000反应的2步路径结果3010与来自sc得分3002的2步路径结果3012的比较显示结果3010被更紧密地分组。这甚至对于合成途径3006、3008中的0步骤(其指示该化合物是购买的)也适用。来自每个图表的一般结果的比较显示图表3000更清楚地
反映了不断增加的合成途径长度的影响。
[0192]
在实施方案中,sas与以前评估合成可及性的方式相比提供了优势,因为它基于已提取合成途径,并使用实际提取的途径估计它的执行价格,然后将该执行价格用于计算和输出得分。发现这比直接使用分子特征(诸如环中的原子数或立体中心数)从结构计算得分的方法更准确。
[0193]
由于sas具有访问已提取途径的权限,因此可顾及可用起始物料的集合。如果没有访问数据库的权限,则不可能通过算法确定仅仅知道其结构的任意化合物的商业可获得性。该知识很重要,因为合成途径中间体的商业可获得性可能会减少需要执行的反应数量,从而显著降低合成的复杂度。
[0194]
在sas中估计终产物的成本这一事实允许将起始材料的价格顺利并入到最终得分中(给定起始材料的成本在小规模合成的情况下可能可以忽略不计,但在多克规模合成中使用时过于昂贵)。通常,在自动逆合成的背景下,应用固定截止值(如“只有低于100美元/克的化合物是可接受的起始材料”)。这对于成本接近阈值的化合物的利用存在问题——略高于阈值的化合物被完全忽视,刚好低于阈值的化合物的显著成本被忽略。
[0195]
由于sas具有访问已提取途径的权限,因此它可以顾及必须执行的实际反应。有时,与期望产物明显不同的化合物可被用于快速合成它,反之亦然——与最终化合物几乎同一的化合物可能对最终化合物的合成无用。对于特定化合物,该情况可能随着新反应的发现而发生改变。也重要的是,由途径中的一种反应产生的化合物的修饰可以使不同反应的利用成为可能。因此,如果要精确估计合成的复杂度,那么实际访问合成途径(就像计算sas的方法一样)是非常有帮助的。
[0196]
图37例示了sas的这些优势。尽管笼结构3708(金刚烷基)被认为是复杂结构,但目标化合物3702可以很容易地在单一步骤中合成,因为a)存在含有该结构的廉价起始材料3706;以及b)利用该起始材料的反应是可行的。忽略那些因素中的任何因素可能会导致不正确的结果。
[0197]
sas的实际用例包括以下。sas得分可用于确定药物发现管道各个阶段设计的结构的优先级。优先顺序可被用于决定应该首先合成哪些化合物(或完全合成)。这对收集关于新结构活性的信息和尽快作出进一步决定非常重要。sas得分可被用于对由计算机模拟方法生成的结构进行多目标优化;训练模型以生成具有期望药理学特性且能够轻易合成的结构。
[0198]
图31是示出用于拟定合成途径的方法的实施方案的架构3100的流程图。在图31中,在步骤3102中,用户向系统提交提供目标化合物的合成途径的请求。在步骤3104中,postgres数据库接收来自api层的请求。在定期执行的步骤3106和3108的循环3130中,在步骤3106中,lambda层从postgres数据库读取该请求,该lambda层在步骤3108中创建ecs任务。在步骤3110中,ecs层通过ecs集群自动缩放旋转新例子,所述ecs集群自动缩放由自动缩放组层提供。在步骤3111中,执行循环,直到不存在待处理请求。循环3111包括步骤3112,其中请求是从postgres数据库中读取的,并被标记为“进行中”,如提供给rust层。在步骤3134中,循环3111中的循环使用步骤3114和3116构建搜索树。在构建搜索树时,在步骤3114中,在rust层中,从不完全搜索树中选择化合物,并且产生用于合成该化合物的反应。在步骤3116中,rust层从python层获取预测值(或“反应可行性估计值”)。在步骤3118中,python
层将预测值返回给rust层。在实施方案中,rust层和python层二者都是在ecs任务内运行的docker镜像。在步骤3120中,仍在循环3111内,rust层将结果插入到postres层中。在步骤3122中,用户请求结果。在步骤3124中,api将结果请求转发到postgres层。在步骤3126中,postgres层返回结果3126(经排名、提取的合成途径和其他如上所述并通过gui1200显示给用户的结果),该结果在步骤3128中由api层提供给用户。在图31中所示的架构中,postgres(rds)用于存储和处理队列;ec2自动缩放组被用于计算;api接受用户查询并将每个化合物插入队列中;lambda层监测队列并创建ecs任务;ec2自动缩放组根据ecs任务的数量缩放;任务从队列中拾取待处理的单独化合物;并且当队列为空时ecs任务关闭,此时ec2自动缩放组缩小。
[0199]
在拟定图31的合成途径的方法的实施方案中,数据在用户与系统交互之前被输入到系统中。关于输入系统中的反应数据,数据集中每个反应所需的信息最低水平是底物和主要产物列表。需要批量访问该反应数据。关于反应数据的处理。系统包括化学品信息工具包(chem-inf toolkit)(rust,图31)和python(图31)(pytorch,rdkit)。关于rust层的化学品信息工具包(图31),这执行了实施方案的以下功能或步骤:化合物的标准化和典型的smiles生成;用于训练统计分类模型的阴性数据生成;用户应用程序中的反应生成和树搜索。此外,经训练的ml模型可被嵌入到rust层中。关于python层,该层执行实施方案的以下功能或步骤:数据分割的指纹计算(rdkit);在训练和推理过程中作为ml模型的输入的反应图生成。在实施方案中,python层可以用嵌入到最终用户应用程序rust层中的ml模型替换。
[0200]
在实施方案中,反应拟定机构可以采用模板先验概念。如本公开中所讨论的,实施方案可拟定产生目标化合物的合成途径。系统中既指导搜索又参与最终反应可行性估计的组件之一是机器学习模型,该模型接受关于阳性反应和阴性反应(即根据“反应可行性估计的统计模型”生成的阳性(参考)和阴性(不可行)反应的数据集)的训练,以估计反应的可行性,如本中所述。该机器学习模型应用于特定反应r(表示为“m(r)”)的输出估计了r的可行性,并帮助系统选择最有前景的反应。它也是最终反应/途径得分的一部分。在每个搜索步骤中应用该模型是耗时的。开发了快速启发(“模板先验”)以在反应拟定(也称为“搜索”)阶段中替换该模型。快速启发“模板先验”的使用减少了模型的使用,因为模型的应用可能仅对所有反应的一小部分是必要的。
[0201]
在实施方案中,“模板先验”可以定义并创建如下。首先,对于具有模板t(r)的反应r,模板先验(t(r))计算如下:
[0202]
模板先验(t(r))=(具有模板t(r)的阳性反应和阴性反应的数据集中阳性反应的数量)/(具有模板t(r)的数据集中阳性反应和阴性反应二者的数量)。
[0203]
然后,计算模板先验(t(r))值并在搜索阶段中使用它来代替m(r),作为m(r)的更快速(尽管不太精确)的代理。最终结果的计算是使用m(r)完成的。
[0204]
在使用m(r)值和使用模板先验(t(r))值拟定目标化合物的反应途径之间的比较时,使用模板先验值导致测试搜索目标的参考集合的总搜索时间减少约9倍。对于使用模板先验的约95%的测试目标,系统能够找到与使用m(r)的原始未经修饰的搜索找到的最佳路径匹配的合成路径。
[0205]
图32是用户界面的实施方案的屏幕截图,该用户界面显示出用于拟定合成途径的方法的实施方案的方面。在图32中,gui 1200显示了合成途径1210,其中目标化合物3202是
一系列反应3203、3205、3207、3209的产物,其中起始材料为3210、3212、3214、3216,中间体为3204、3206、3208。每种化合物均被显示在点线3218指示的gui区域内。在实施方案中,对于每种化合物,可以选择区域3218,并且用户将被提供关于所选化合物的选项。
[0206]
图33描述了图32的反应。在图33中,用户已选择与化合物3204相关的区域3218。作为响应,gui 1200提供了选项3302。在实施方案中,选项3302包括:查看替代物3304,从此处进行新搜索,导出mdl,保存化合物,以及复制smiles。当用户选择查看替代物3304时,gui 1200为用户提供化合物3204的如由系统计算与化合物库的相似性量度来确定的替代物,并提供经排名的结果列表。在图34中,gui 1200响应于用户的选择,显示了包括3402、3404、3406的替代化合物视图3400。在实施方案中,视图3400包括关于每种化合物的额外信息,诸如来源3408和报价3410。有了此类信息,用户可以选择替代化合物来替换化合物3204。然后,用户可以指导系统修正途径1210的下游部分,以反映从化合物3204到例如化合物3406的改变。由于化合物3406是可商购获得的,因此途径1210的位于被替换化合物3204的上游的部分将被丢弃。然后,系统将修正反应3203,以反映化合物3406与化合物3206的反应,并相应地修正产物3202。通过这种方式,用户可以选择目标分子。可以保存新目标分子和途径。
[0207]
在图35中,用户已选择与化合物3214相关的区域3218。作为响应,gui 1200提供了选项3302。响应于用户选择视图替代物3304,图36中的gui 1200显示包括化合物3602、3604、3606的替代化合物视图3400。如果用户选择化合物3602、3604、3606中的任何一种来替换化合物3214,则这种改变在合成途径1210下游的传播将导致化合物3206和3218二者都发生改变。由于化合物3214是起始材料,因此没有与这种改变相关的上游反应要被丢弃。
[0208]
图37是用于计算合成可及性得分(sas,如根据“成本函数和合成途径的总估计成本的估计”部分计算)的方法的实施方案的方面的图解。影响sas的因素包括:合成途径中步骤的数量;每个步骤的确定性(如通过使用ai的方法所评估);起始材料的成本;合成途径的形状(例如收敛或线性);途径内单个反应的顺序(风险更高的反应最好位于途径的开始处,因此其失败的影响较小)。
[0209]
在sas实施方案的测试中,对供应商提供的一组目标分子(其中大多数被认为具有可行的合成途径)以及来自学术项目的一组目标分子(其中大多数预计没有可行的合成途径)制定了得分。该测试旨在确定供应商化合物的sas和学术项目化合物的sas是否将反映供应商化合物大部分是可行的并且学术化合物大部分是不可行的预期。在测试中,使用上述实施方案确定了每种分子的合成途径。对于这组供应商化合物,可以找出绝大多数化合物的合成途径,并且sas平均值约为3.5,分布相对较紧。只有相对较小百分比的供应商化合物收到接近10的sas(其指示反应是不可行的)。来自学术项目的可行化合物的平均sas约为4,分布几乎为两倍大。然而,绝大多数的学术化合物收到10的sas,表明它们是不可行的反应。因此,该测试与反应可行性的期望相关。
[0210]
在图37中,合成反应途径3700包括目标化合物3702,其为底物3704、3706间反应的产物。底物3706和化合物3702二者都包括看似复杂的金刚烷基部分3708。在实施方案中,可以计算化合物3702的sas,其中sas与现有技术的难度量度相比相对较低,因为sas收到关于整个合成途径3700的信息,包括关于底物3706的信息和它是可商购获得的事实。相比之下,现有技术量度通常基于反应产物,例如3702,并且不考虑底物的可获得性。因此,现有技术
的量度可以查看金刚烷基部分3708并计算出该分子的未必高的得分(指示它是难以合成的),因为现有技术的量度没有顾及到具有相同奇怪结构3708的起始底物的可获得性。
[0211]
图38是用于计算合成可及性得分(sas)的方法的实施方案的方面的图解。在图38中,化合物3802和3804除双键3806、3808、3810、3812的位置以及五元环中三个氮原子的排名之外都是相似的。对于这些化合物,现有技术的量度可能提供相对相似的合成得分,由于这些化合物明显的相似性。然而,相比之下,化合物3802的sas将显著高于化合物3804的sas,因为具有化合物3802的完整合成途径,该方法可以顾及如反映在与化合物3802相关的途径中的化合物3802的合成明显比化合物3804的合成更困难这一事实。
[0212]
图39是示例性框图,其描述了用于实现本公开的方法的实施方案(例如,如参考包括图31在内的此前的图所描述的方法的实施方案)的系统的实施方案。在图39中,计算机网络3900包括许多计算设备3910a-3910b以及一个或多个经由多个通信链路3930耦合到通信网络3960的服务器系统3920。通信网络3960提供了用于允许分布式网络3900的各个组件相互通信和交换信息的机构。
[0213]
通信网络3960本身由一个或多个互连的计算机系统和通信链路组成。通信链路3930可包括硬连线链路、光学链路、卫星或其他无线通信链路、波传播链路或任何其他信息通信机构。各种通信协议均可被用于促进图39中所示的各种系统之间的通信。这些通信协议可包括tcp/ip、udp、http协议、无线应用协议(wap)、bluetooth、zigbee、802.11、802.15、6lowpan、lifi、google weave、nfc、gsm、cdma、其他蜂窝数据通信协议、无线电话协议、互联网电话、ip电话、数字语音、宽带语音(vobb)、宽带电话、ip语音(voip)、供应商专用协议、定制协议及其他协议。而在一个实施方案中,通信网络3960是互联网,在其他实施方案中,通信网络3960可以是任何合适的通信网络,包括局域网(lan)、广域网(wan)、无线网络、蜂窝网络、个人区域网络、内联网、专用网络,近场通信(nfc)网络、公共网络、交换网络、点对点网络以及这些网络的组合等。
[0214]
在实施方案中,服务器3920不位于计算设备的用户附近,并通过网络进行通信。在不同的实施方案中,服务器3920是用户可以随身携带或可以在附近存放的设备。在实施方案中,服务器3920具有用于为长距离通信网络,诸如蜂窝网络或wi-fi供电的大型电池。服务器3920经由有线链路或经由低功率短程无线通信(诸如蓝牙(bluetooth))与系统的其他组件进行通信。在实施方案中,系统的其他组件之一发挥服务器(例如pc 3910b)的作用。
[0215]
图39中的分布式计算机网络3900仅仅例示了并入了所述实施方案的实施方案,并且不限制如权利要求中叙述的本发明的范围。本领域的普通技术人员将能识别出其他变化、修改和替代方案。例如,多于一个的服务器系统3920可以连接到通信网络3960。作为另一个实例,许多计算设备3910a-3910b可以经由接入提供商(未示出)或经由一些其他服务器系统耦合到通信网络3960。
[0216]
计算设备3910a-3910b通常从提供信息的服务器系统请求信息。根据定义,服务器系统通常比这些计算设备(其往往是便携式设备、移动通信设备或其他在客户端-服务器操作中扮演客户端角色的计算设备之类的设备)具有更大的计算和存储容量。但是,特定的计算设备可以充当客户端和服务器二者,其取决于计算设备是请求信息还是提供信息。实施方案的各个方面可以使用客户端-服务器环境或云-云计算环境来实施。
[0217]
服务器3920负责接收来自计算设备3910a-3910b的信息请求,执行满足请求所需
的处理,并将请求对应的结果转发回请求计算设备。满足请求所需的处理可以由服务器系统3920执行,或者可以替代地被委托给连接到通信网络3960或其他通信网络的其他服务器。服务器3920可以位于计算设备3910附近,或者可以远离计算设备3910。服务器3920可以是在物联网场景中控制物品的本地飞地(local enclave)的集线器。
[0218]
计算设备3910a-3910b使用户能够访问和查询服务器系统3920存储的信息或应用程序。一些示例性计算设备包括便携式电子设备(例如,移动通信设备),诸如:appleapplepalm pre
tm
或任何运行以下的计算设备:apple ios
tm
、android
tm
os、google chrome os、symbianwindows 10、windowsos、palm或palm web os
tm
,或各种用于物联网(iot)设备或汽车或其他车辆的操作系统或实时操作系统(rtos)(诸如riot os、用于iot的windows 10、windriver vxworks、google brillo、arm mbed os、嵌入式apple ios和os x、nucleus rtos、green hills integrity或contiki)中的任一种,或各种可编程逻辑控制器(plc)或可编程自动化控制器(pac)操作系统(诸如microware os-9、vxworks、qnx neutrino、freertos、micriumμc/os-ii、micriumμc/os-iii、windows ce、ti-rtos、rtems)中的任一种。可以使用其它操作系统。在具体的实施方案中,在计算设备上执行的“网络浏览器”应用程序使用户能够选择、访问、检索或查询服务器系统3920存储的信息和/或应用程序。网络浏览器的实例包括google提供的android浏览器、apple提供的浏览器、opera software提供的opera网络浏览器、research in motion提供的浏览器、microsoft corporation提供的internet和internet explorer移动浏览器、提供的和firefox for mobile浏览器,等等。
[0219]
图40是示例性框图,其描述了实施方案的计算设备4000。计算设备4000可为来自图39的计算设备3910中的任一个。计算设备4000可包括显示器、屏幕或监视器4005、壳体4010和输入设备4015。壳体4010容纳了熟悉的计算机组件(其中的一些组件未示出),诸如处理器4020、内存4025、电池4030、扬声器、收发器、天线4035、麦克风、端口、插孔、连接器、摄像头、输入/输出(i/o)控制器、显示适配器、网络接口、大容量存储设备4040、各种传感器等。
[0220]
输入设备4015还可包括触摸屏(例如电阻式、表面声波、电容传感、红外、光学成像、色散信号或声脉冲识别)、键盘(例如,电子键盘或物理键盘)、按钮、开关、触控笔或其组合。
[0221]
大容量存储设备4040可包括闪存和其它非易失性固态存储器或固态驱动器(ssd),诸如闪存驱动器、闪存或usb闪存驱动器。大容量存储器的其他实例包括大容量磁盘驱动器、软盘、磁盘、光盘、磁光盘、固定磁盘、硬盘、sd卡、cd-rom、可刻录cd、dvd、可刻录dvd(例如,dvd-r、dvd+r、dvd-rw、dvd+rw、hd-dvd或蓝光光盘)、电池供电的易失性存储器、磁带存储器、阅读器和其他类似介质以及其组合。
[0222]
实施方案也可以与具有不同配置(例如具有额外的或更少的子系统)的计算机系统一起使用。例如,计算机系统可以包括多于一个的处理器(即,可以允许并行处理信息的多处理器系统)或者系统可能包括高速缓存。图40中所示的计算机系统只是适合与实施方案一起使用的计算机系统的实例。其他适合与实施方案一起使用的子系统的配置对本领域
的普通技术人员将是显而易见的。例如,在具体实现方式中,计算设备是移动通信设备,诸如智能手机或平板电脑。智能手机的一些具体实例包括htc corporation提供的droid incredible和google nexus one、苹果提供的iphone或ipad,以及许多其他产品。计算设备可以是笔记本电脑或上网本。在另一个具体实现方式中,计算设备是非便携式计算设备,诸如台式计算机或工作站。
[0223]
可用于实践实施方案的程序指令的计算机实现的或计算机可执行的版本可使用计算机可读介质来实施、存储在计算机可读介质上或与计算机可读介质相关联。计算机可读介质可包括任何参与向一个或多个处理器提供指令以供执行的介质,诸如内存4025或大容量存储器4040。此类介质可采取许多形式,包括但不限于非易失性、易失性、传播、非印刷和印刷介质。非易失性介质包括例如闪存或光盘或磁盘。易失性介质包括静态或动态内存,诸如高速缓存或ram。传输介质包括同轴电缆、铜线、光纤线以及布置在总线中的电线。传输介质也可以采取电磁波、射频波、声波或光波的形式,诸如在无线电波和红外数据通信过程中产生的那些。
[0224]
例如,可用于实践实施方案的软件的二进制、机器可执行版本可以存储或驻留在ram或高速缓存中,或存储或驻留在大容量存储设备4040上。该软件的源代码也可以存储或驻留在大容量存储设备4040(例如,闪存驱动器、硬盘、磁盘、磁带或cd-rom)上。作为进一步的实例,可用于实践实施方案的代码可通过电线、无线电波或通过网络(诸如互联网)传输。在另一个具体实施方案中,提供了用于实现实施方案的特征的计算机程序产品,包括各种软件程序代码。
[0225]
计算机软件产品可以用各种合适的编程语言诸如c、c++、c#、pascal、fortran、perl、matlab(来自mathworks,www.mathworks.com)、sas、spss、javascript、coffeescript、objective-c、swift、objective-j、ruby、rust、python、erlang、lisp、scala、clojure和java中的任一种来编写。计算机软件产品可以是具有数据输入和数据显示模块的独立应用程序。替代地,计算机软件产品可以是可以实例化为分布式对象的类。计算机软件产品也可以是组件软件,诸如java beans(来自oracle)或enterprise java beans(来自oracle的ejb)。
[0226]
该系统的操作系统可以是android操作系统、iphone os(即ios)、symbian、blackberry os、palm web os、bada、meego、maemo、limo或brew os。操作系统的其他实例包括microsoft windows系列操作系统(例如,windows 95、98、me、windows nt、windows 2000、windows xp、windows xp x64 edition、windows vista、windows 10或其他windows版本、windows ce、windows mobile、windows phone、windows 10mobile)、linux、hp-ux、unix、sun os、solaris、mac os x、alpha os、aix、irix32或irix64中的一种,或各种用于物联网(iot)设备或汽车或其他车辆的操作系统或实时操作系统(rtos)(诸如riot os、用于iot的windows 10、windriver vxworks、google brillo、arm mbed os、嵌入式apple ios和os x、nucleus rtos、green hills integrity或contiki)中的任一种,或各种可编程逻辑控制器(plc)或可编程自动化控制器(pac)操作系统(诸如microware os-9、vxworks、qnx neutrino、freertos、micriumμc/os-ii、micriumμc/os-iii、windows ce、ti-rtos、rtems)中的任一种。可以使用其它操作系统。
[0227]
此外,计算机可以连接到网络,并可以使用该网络与其他计算机交互。网络可以是
内联网、互联网或因特网等。网络可以是有线网络(例如,使用铜线)、电话网络、数据包网络、光纤网络(例如,使用光纤)或无线网络,或这些网络的任何组合。例如,可以采用诸如以下的协议使用无线网络在计算机和可用于实践所述实施方案的系统的组件(或步骤)之间传递数据和其他信息:wi-fi(ieee标准802.11、802.11a、802.11b、802.11e、802.11g、802.11i和802.11n,仅举几个例子),或者其他协议诸如bluetooth或nfc或802.15或蜂窝,或通信协议,该通信协议可包括tcp/ip、udp、http协议、无线应用协议(wap)、bluetooth、zigbee、802.11、802.15、6lowpan、lifi、google weave、nfc、gsm、cdma、其他蜂窝数据通信协议、无线电话协议等。例如,来自计算机的信号可以被至少部分地无线传输到组件或其他计算机。
[0228]
以下段落列举了枚举的实施方案。
[0229]
实施方案1是一种方法,其包括:
[0230]
由来自至少一个软件模块的模块接收第一分子结构;
[0231]
由来自所述至少一个软件模块的模块使用所述第一分子结构和由利用已知反应进行的机器学习生成的模型拟定用于合成所述第一分子结构的第一多个反应,所述第一多个反应中的至少一个是由所述模块创建的而不是从数据库中检索到的;
[0232]
由来自所述至少一个软件模块的模块从所述第一多个反应中提取至少一个产生所述第一分子结构的第一途径;
[0233]
由来自所述至少一个软件模块的模块预测每个提取的第一途径的成本;
[0234]
由来自所述至少一个软件模块的模块根据所预测的成本对每个提取的第一途径进行排名;以及
[0235]
由来自所述至少一个软件模块的模块提供包括呈根据所述排名确定的顺序的每个第一途径的列表。
[0236]
实施方案2是如实施方案1所述的方法,其进一步包括:
[0237]
除了所述第一分子结构之外,还由所述来自所述至少一个软件模块的模块接收对确定所述第一多个反应的约束,其中所述模块在确定所述第一多个反应时遵守所述约束。
[0238]
实施方案3是如实施方案2所述的方法,其中所述约束是针对所述第一分子结构限定的,其中所述模块在确定所述第一多个反应时遵守所述约束。
[0239]
实施方案4是如实施方案1所述的方法,其进一步包括:
[0240]
选择提取的第一途径;
[0241]
从所选择的第一途径中选择位于所述所选择的第一途径内的第一底物;
[0242]
由来自所述至少一个软件模块的模块将所述第一底物与可商购获得的化合物数据库内的化合物进行比较;
[0243]
基于所述比较,由所述模块从可商购获得的化合物数据库中选择第二底物;
[0244]
由来自所述至少一个软件模块的模块将所述所选择的第一途径内的所述第一底物取代为所述第二底物;
[0245]
由来自所述至少一个软件模块的模块修正所述所选择的第一途径内所述第二底物和所述第一分子结构之间的任何反应从而顾及了所述第二底物和所述第一底物之间的差异,所述修正产生第二途径和所述第一分子结构发生的改变,使得所述第二途径的结果是所述第二分子结构;以及
[0246]
由来自所述至少一个软件模块的模块将所述第二途径与所述所选择的第一途径相关联,其中所述提供包括呈根据所述排名确定的顺序的每个第一途径的列表包括将所述第二途径与相关的第一途径一起列出。
[0247]
实施方案5是实施方案4所述的方法,其中:
[0248]
选择提取的第一途径包括所述用户选择所述第一途径;并且
[0249]
从所选择的第一途径中选择由所述所选择的第一途径内的反应合成的第一底物包括来自所述至少一个软件模块的模块选择所述第一底物。
[0250]
实施方案6是如实施方案1所述的方法,其中:
[0251]
所述由所述模块使用所述第一分子结构和由利用已知反应进行的机器学习生成的模型拟定用于合成所述第一分子结构的第一多个反应包括:
[0252]
由所述模块创建具有定向链路的反应节点和化学化合物节点的集合,所述集合包括产生所述第一分子结构的多个途径;并且
[0253]
所述由所述模块从所述第一多个反应中提取至少一个产生所述第一分子结构的第一途径包括:
[0254]
由所述模块从所述反应节点和化合物节点的集合中提取所述至少一个第一途径。
[0255]
实施方案7是如实施方案6所述的方法,其中所述由所述模块创建具有定向链路的反应节点和化学化合物节点的集合包括从由所述集合中第一化学化合物节点代表的至少所述第一分子结构开始,并由所述模块通过执行至少一次展开迭代来创建展开的集合,其包括:
[0256]
从所述集合中选择待展开的化学化合物节点;
[0257]
由所述模块使用所述模型拟定至少一种产生由所选择的化学化合物节点表示的化学化合物的额外反应;
[0258]
由所述模块针对每个拟定的额外反应向所述集合中添加反应节点,并添加从所述反应节点到所述所选择的化合物节点的定向链路;以及
[0259]
由所述模块针对每个拟定的额外反应中的每个底物向所述集合中添加化学化合物节点,并添加从添加的化学化合物节点到代表所述额外反应的所述反应节点的定向链路。
[0260]
实施方案8是如实施方案7所述的方法,其中所述包括呈根据所述排名确定的顺序的每个第一途径的列表包括:
[0261]
由计算机显示器上的模块为每个第一途径显示从具有定向链路的反应节点和化学化合物节点的集合中提取的具有定向链路的反应节点和化学化合物节点的亚集合。
[0262]
实施方案8是如实施方案7所述的方法,其中,所述由所述模块从所述第一多个反应中提取至少一个产生所述第一分子结构的第一途径包括:
[0263]
由所述模块从所述展开的集合中提取所述至少一个第一途径。
[0264]
实施方案10是如实施方案6所述的方法,其中由所述模块预测每个提取的第一途径的成本包括:
[0265]
由所述模块通过使用借助已知反应数据和不可行反应数据被训练成预测反应可行性的统计模型评价提取的途径中的每个反应节点来确定所述每个反应节点的成功概率。
[0266]
实施方案11是如实施方案10所述的方法,其中所述不可行的反应数据包括由来自
所述至少一个软件模块的模块生成的反应:
[0267]
接收已知发生的反应的集合;
[0268]
丢弃底物以仅留下反应产物;
[0269]
使用所述第一分子结构和由利用已知反应进行的机器学习生成的模型针对所述反应产物中的每一种拟定作为所述反应产物逆合成中的第一步的反应;
[0270]
将所述生成的反应与所述已知发生的反应的集合进行比较,以确定不符合所述已知发生的反应的集合的性质的生成的反应的集合;以及
[0271]
添加不符合所述不可行反应数据的所述生成的反应的集合。
[0272]
实施方案12是如实施方案1所述的方法,其中由来自所述至少一个软件模块的模块使用所述第一分子结构和由利用已知反应进行的机器学习生成的模型拟定用于合成所述第一分子结构的第一多个反应包括:
[0273]
由所述模块搜索所述已知反应的模板图中与所述第一分子结构的产物子图匹配的产物子图;
[0274]
为每个匹配产物子图生成拟定的底物子图的集合;
[0275]
由所述模块从所述拟定的底物和相关产物子图的集合中去除无效的化学化合物;以及
[0276]
由所述模块从每个剩余的产物子图和生成的底物子图集合中提取模板,即反应模板。
[0277]
实施方案13是如实施方案1所述的方法,其中用于合成所述第一分子结构的所述第一多个反应中的至少一个反应是用于合成所述第一分子结构的初始单步途径,并且所述初始单步途径由来自所述至少一个软件模块的模块展开成多步途径:
[0278]
1)将来自所述初始单步途径的底物指定为目标分子结构;
[0279]
2)使用所述目标分子结构和所述模型拟定至少一个用于合成指定的目标分子结构的单步途径;以及
[0280]
3)将至少一个拟定的单步途径添加到所述第一多个反应中。
[0281]
实施方案14是如实施方案13所述的方法,其进一步包括对所述第一多个反应中的每个底物重复步骤1-3,直到所述软件模块确定在可商购获得的化合物数据库中找到所述底物,或者所述软件模块对所述底物执行最大次数的步骤1-3的迭代。
[0282]
实施方案15是如实施方案13所述的方法,其中提取的至少一个产生所述第一分子结构的第一途径是包括多个单步途径的多步途径。
[0283]
实施方案16是如实施方案13所述的方法,其进一步包括对所述第一多个反应的初始亚集合进行排名,其中所述初始单步途径是作为排名最高的反应从所述第一多个反应的初始亚集合中选择出的。
[0284]
实施方案17是如实施方案1所述的方法,其中所述第一多个反应的亚集合包括变成一个或多个所述提取的第一途径中的中间反应的反应。
[0285]
实施方案18是如实施方案1所述的方法,其中所述提供列表包括由来自计算机监视器上至少一个软件模块的模块提供交互显示呈根据所述排名确定的顺序的每个第一途径的列表。
[0286]
实施方案19是如实施方案1所述的方法,其进一步包括:
[0287]
由来自所述至少一个软件模块的模块为提取的第一途径提供根据所述提取的途径合成所述第一分子结构的难度的估计值,所述估计值至少部分地基于所述模块对所述提取的第一途径中每个反应的分析。
[0288]
实施方案20是如实施方案19所述的方法,其中所述估计值也基于所述提取的第一途径的成本。
[0289]
实施方案21是如实施方案1所述的方法,其中:
[0290]
所述由来自所述至少一个软件模块的模块使用所述第一分子结构和由利用已知反应进行的机器学习生成的模型拟定用于合成所述第一分子结构的第一多个反应包括由所述模块创建所述第一多个反应的途径中每个步骤的反应可行性的估计值;并且
[0291]
所述由来自所述至少一个软件模块的模块从所述第一多个反应中提取至少一个产生所述第一分子结构的第一途径包括由所述模块使用所述反应可行性的估计值来确定待提取的至少一个第一途径。
[0292]
实施方案22是如实施方案21所述的方法,其中所述由所述模块创建所述第一多个反应的途径中每个步骤的反应可行性的估计值包括:
[0293]
由所述模块使用所述模型为所述第一多个反应中的步骤的第一亚集合中的每个创建反应可行性的第一估计值;以及
[0294]
由所述模块通过如下方式为所述第一多个反应中的步骤的第二亚集合中的每个创建反应可行性的第二估计值:确定与所述步骤相关的反应模板,确定与这个反应模板相关的参考数据集中的可行反应的第一数量,确定与这个反应模板相关的参考数据集中的不可行反应的第二数量,将所述第一数量除以所述第一和第二数量的总和,所述除法的结果为反应可行性的第二估计值。
[0295]
实施方案23是如实施方案1所述的方法,其中:
[0296]
来自所述至少一个软件模块的第一模块执行:
[0297]
所述接收第一分子结构;以及
[0298]
所述提供包括呈根据所述排名确定的顺序的每个第一途径的列表;并且
[0299]
来自所述至少一个软件模块的第二模块执行:
[0300]
所述使用所述第一分子结构和由利用已知反应进行的机器学习生成的模型拟定用于合成所述第一分子结构的第一多个反应,所述第一多个反应中的至少一个是由所述模块创建的而不是从数据库中检索到的;
[0301]
所述从所述第一多个反应中提取至少一个产生所述第一分子结构的第一途径;
[0302]
所述预测每个提取的第一途径的成本;以及
[0303]
所述根据所预测的成本对每个提取的第一途径进行排名。
[0304]
一种系统,其包括至少一个处理器和内存,所述内存具有当被所述至少一个处理器执行时使所述系统根据实施方案1-23中的任何一项所述的方法执行动作的指令。
[0305]
一种系统,其包括至少一个处理器和内存,所述内存具有当被所述至少一个处理器执行时使所述系统执行包括以下的动作的指令:
[0306]
接收第一分子结构;
[0307]
使用所述第一分子结构和由利用已知反应进行的机器学习生成的模型拟定用于合成所述第一分子结构的第一多个反应,所述第一多个反应中的至少一个是由所述系统创
建并且不预先存在于所述系统可访问的任何位置;
[0308]
从所述第一多个反应中提取至少一个产生所述第一分子结构的第一途径;
[0309]
预测每个提取的第一途径的成本;
[0310]
根据预测的成本对每个提取的第一途径进行排名;以及
[0311]
提供包括呈根据所述排名确定的顺序的每个第一途径的列表。
[0312]
一种非暂时性计算机可读介质,其包括当被计算设备的处理器执行时导致所述计算设备根据实施方案1-23中任一项所述的方法执行动作的指令。
[0313]
一种非暂时性计算机可读介质,其包括当被计算设备的处理器执行时导致所述计算设备执行包括以下的动作的指令:
[0314]
接收第一分子结构;
[0315]
使用所述第一分子结构和由利用已知反应进行的机器学习生成的模型拟定用于合成所述第一分子结构的第一多个反应,所述第一多个反应中的至少一个是由所述系统创建并且不预先存在于所述系统可访问的任何位置;
[0316]
从所述第一多个反应中提取至少一个产生所述第一分子结构的第一途径;
[0317]
预测每个提取的第一途径的成本;
[0318]
根据预测的成本对每个提取的第一途径进行排名;以及
[0319]
提供包括呈根据所述排名确定的顺序的每个第一途径的列表。
[0320]
虽然已经针对特定的实施方案描述了实施方案,但应认识到可以在不背离本发明概念的情况下设计额外的改变。
[0321]
本文中使用的术语仅仅是出于描述具体实施方案的目的,并且并不意图限制所要求保护的主题。如本文所用,术语“和/或”包括相关的列出的项目中的一个或多个项目的任何和所有组合。如本文所用,单数形式“一个/种(a)”、“一个/种(an)”和“该/所述(the)”意欲包括复数形式以及单数形式,除非上下文另有明确指示。还应进一步理解,术语“包括/包含(comprises)”和/或“包括/包含(comprising)”在本专利说明书中使用时指定了所陈述的特征、步骤、操作、元件和/或组件的存在,但不排除一个或多个其它特征、步骤、操作、元件、组件和/或其组的存在或添加。
[0322]
除非另有定义,否则本文中使用的所有术语(包括技术和科学术语)具有与实施方案所属领域中普通技术人员通常所理解的含义相同的含义。应进一步理解,术语(诸如常用词典中定义的术语)应被解释为具有与其在相关领域和本公开的上下文中的含义一致的含义,并且不应以理想化或过于正式的含义来解释,除非在本文中被明确地如此定义。
[0323]
在描述实施方案时,应理解公开了许多元件、技术和步骤。这些元件、技术和步骤中的每一个都具有单独的益处,并且每一个也可与一个或多个,或在一些情况下,所有其他公开的元件或技术结合使用。阅读本专利说明书和权利要求书时应理解,此类组合完全落在实施方案和所要求保护的主题的范围内。
[0324]
在上面和通篇的描述中,阐述了许多具体细节以提供对本公开的实施方案的全面理解。然而,对于本领域的普通技术人员将显而易见的是,实施方案可以在没有这些具体细节的情况下实践。在其它例子中,为了便于解释,众所周知的结构和设备以框图形式被示出。优选实施方案的描述并未意图限制本文所附权利要求的范围。进一步地,在本文公开的方法中,公开了例示实施方案的一些功能的各个步骤。这些步骤仅仅为实例,并且未意图以
任何方式进行限制。可以在不背离本公开或实施方案的范围的情况下设想其他步骤和功能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1