用于解释宿主噬菌体反应的机器学习系统的制作方法
1.本公开涉及用于解释宿主噬菌体反应数据的基于机器学习的方法。
背景技术:
2.在以下的讨论中,出于背景和介绍的目的将描述某些文章和方法。本文包含的任何内容都不应被理解为“承认”现有技术。申请人明确保留在适当情况下证明此处引用的文章和方法不构成适用法律规定下的现有技术的权利。
3.多重耐药(mdr)细菌正以惊人的速度出现。目前,据估计在美国每年至少有200万感染是由mdr生物体引起的,导致大约23,000人死亡。此外,据信基因工程和合成生物学也可能导致生成额外的高毒性微生物。
4.例如,金黄色葡萄球菌是革兰氏阳性菌,其能够导致皮肤和软组织感染(ssti)、肺炎、坏死性筋膜炎和血流感染。耐甲氧西林金黄色葡萄球菌(“mrsa”)是临床环境中非常关注的mdr生物体,因为mrsa造成了超过80,000例侵入性感染,接近12,000例相关死亡,并且是医院获得性感染的主要原因。此外,世界卫生组织(who)已将mrsa鉴定为国际关注的生物体。
5.鉴于快速发生和传播的毒性微生物和抗微生物剂抗性的潜在威胁,正在开发针对细菌感染的替代临床处置。一种治疗mdr感染的潜在方法涉及使用噬菌体。细菌噬菌体(“噬菌体”)是病毒的多样性集合,它们在特定的细菌宿主内复制并且能够杀死特定的细菌宿主。在20世纪早期对噬菌体进行初步分离后,研究了利用噬菌体作为抗菌药的可能性,并且在一些国家已经将噬菌体作为抗菌剂在临床上使用,并且取得了一些成功。尽管如此,在发现青霉素之后,噬菌体疗法在美国基本上被放弃了,直到最近才重新引起了对噬菌体诊疗的兴趣。
6.噬菌体的成功诊疗性应用取决于施用能够杀死或抑制与感染相关的细菌分离物生长的噬菌体菌株的能力。已经开发了经验实验室技术来筛选细菌菌株的噬菌体易感性(即抑制细菌生长的功效)。然而,这些技术是耗时并且主观的,并且涉及在测试噬菌体存在的情况下尝试使细菌菌株生长。数小时后,通过人工目测检查来评估噬菌体裂解(杀死)或抑制细菌生长的能力(宿主噬菌体反应)。
7.一种这样的测试是噬斑测定,这是一种半固体培养基测定,其测量由放置测试噬菌体和细菌感染引起的细菌菌苔中透明带的形成。尽管噬斑测定很简单,但噬斑的形态和大小能够随着实验者、培养基和其他条件而变化。最近,使用omnilog
tm
系统(biolog,inc)开发了一种自动化高通量间接液体裂解测定系统来评估噬菌体生长。omnilog
tm
系统是与相机和计算机联结的自动化的基于板的培养箱系统,计算机利用氧化还原化学将细胞呼吸作为通用报告器。板中的每个孔都含有生长培养基、四唑鎓染料、(宿主)细菌菌株和噬菌体(以及对照/校准孔)。在细菌的活跃生长期间,细胞呼吸还原四唑鎓染料并且产生颜色变化。成功的噬菌体感染和随后噬菌体在其宿主细菌中的生长导致细菌生长和呼吸减少,并且伴随颜色减弱。相机在多个时间点收集图像,并且分析图像中的每个孔以生成颜色测量。这能够
被称为初始颜色或参考颜色,从而收集颜色随时间变化的时间序列数据集(即比色测定)。对每个孔(即宿主噬菌体组合)的时间序列数据集作图,然后用户(主观地)审查这些图表中的每个图表(例如96孔板的96个图表)。用户使用他/她的经验、直觉和隐含的知识来解释图表并且估计宿主噬菌体反应。这导致可变性或品质增加,因为解释是主观的,并且依赖于用户在特定时间审查图表的技能水平和/或注意力。
8.因此,需要开发用于分析/解释宿主噬菌体反应数据的改进的自动化方法,例如减少基于人的解释的可变性,或至少提供现有方法的有用替代方法。此外,自动化方案将减少基于人类解释的可变性。
技术实现要素:
9.根据第一方面,提供了一种训练用于解释宿主噬菌体反应数据的机器学习模型的计算机实施的方法,该方法包括:
10.由计算系统接收或上传宿主噬菌体反应数据集和标记,其中宿主噬菌体反应数据集包括多种宿主噬菌体组合中每一种组合的时间序列数据集,在多种宿主噬菌体组合中宿主细菌在存在噬菌体的情况下生长,并且与宿主噬菌体组合相关联的时间序列数据集中的每个数据点包括指示在特定时间在相应噬菌体存在的情况下相应宿主细菌生长的参数的测量值,并且每个时间序列数据集具有指示噬菌体抑制宿主细菌生长的功效的相关联标记;
11.针对每个时间序列数据集,在第一时间窗上拟合至少一个函数;
12.为每次拟合生成概括参数的集合,该概括参数包括一个或多个模型系数、拟合优度、r2、误差、残差或残差的概括统计;以及
13.根据训练数据集来训练机器学习模型,训练数据集包括对时间序列数据集之一的每次拟合的概括参数的集合,以及所拟合的时间序列数据集的相关联标记;
14.以电子格式导出或保存机器学习模型以供后续使用,从而使用由使用测试噬菌体和测试细菌获得的宿主噬菌体反应时间序列数据集来估计测试噬菌体抑制测试细菌生长的功效。
15.在一种形式中,对于每个时间序列数据集,在第一时间窗上拟合至少一个函数包括在第一时间窗上拟合单个函数。在另一种形式中,对于每个时间序列数据集,在第一时间窗上拟合至少一个函数包括在第一时间窗上拟合至少两个函数,其中这些函数中每个函数具有不同的函数形式。在另一种形式的拟合中,对于每个时间序列数据集,第一时间窗上的至少一个函数包括执行多次拟合,其中每次拟合包括在时间区间上拟合函数,其中第一时间窗由最早时间区间的起点和最晚时间区间的终点来定义,并且每个时间区间比第一时间窗更短。时间区间可以是连续的或非连续的时间区间。在一种形式中,时间区间的数量至少是三个。在一种形式中,第一时段的终点是24小时或更少。在一种形式中,至少一个函数是线性函数或多项式泛函中的一个或多个。
16.在一种形式中,机器学习模型是生成二元结论的二元分类器,其指示测试噬菌体对抑制测试细菌的生长是否有效果。在另一种形式中,机器学习模型是概率分类器,其估计测试噬菌体对抑制测试细菌生长有效果的概率。
17.根据第二方面,提供了用于解释宿主噬菌体反应数据的计算机实施的方法,该方
法包括:
18.由计算机系统加载经训练的机器学习模型,经训练的机器学习模型以电子格式存储并且被配置成对宿主反应数据集进行分类;
19.接收和/或上传测试噬菌体的宿主反应数据集,其中宿主反应数据集包括时间序列数据集,其中时间序列数据集中的每个数据点包括指示在特定时间存在测试噬菌体的情况下宿主细菌生长的参数的测量值;
20.在第一时间窗上拟合至少一个函数;
21.为拟合生成概括参数的集合;
22.通过向经训练的机器学习模型提供该概括参数的集合来获得测试噬菌体抑制宿主细菌生长的功效的估计;
23.报告测试噬菌体功效的估计。
24.在一种形式中,该方法可以进一步包括接收包含附加数据点的更新的宿主反应数据集,并且重复拟合、生成、获得和报告步骤,其中报告估计包括测试噬菌体有效果的概率的估计。
25.在一种形式中,可以对多个宿主反应数据集重复该方法,并且该方法还包括:
26.获得被估计对测试细菌有效果的至少两种测试噬菌体的集合;
27.获得对该集合中每种测试噬菌体的一种或多种作用机制的估计;
28.基于每种测试噬菌体的估计作用机制来获得该集合中每对测试噬菌体的多样性度量;
29.基于所获得的多样性度量来选择至少两种噬菌体用于诊疗性噬菌体制剂。
30.在优选的实施例中,通过对测试噬菌体进行测序来确定每种测试噬菌体的作用机制。
31.上述方法可以在非暂时性的计算机程序产品中实现,该计算机程序产品包括在计算设备中实施上述方法中任何方法的指令。上述方法也可以在计算设备中实施,该计算设备包括被配置为实施上述方法的至少一个存储器和至少一个处理器。
32.根据第三方面,提供了一种非暂时性的计算机程序产品,其包括计算机可执行指令,计算机可执行指令训练用于解释宿主噬菌体反应数据的机器学习模型,指令包括:
33.接收宿主噬菌体反应数据集和标记,其中宿主噬菌体反应数据集包括多种宿主噬菌体组合中每一种组合的时间序列数据集,在宿主噬菌体组合中,宿主细菌在存在噬菌体的情况下生长,并且与宿主噬菌体组合相关联的时间序列数据集中的每个数据点包括指示在特定时间存在相应噬菌体的情况下相应细菌生长的参数的测量值,并且每个时间序列数据集具有指示噬菌体抑制宿主细菌生长的功效的相关联标记;
34.对于每个时间序列数据集,在第一时间窗上拟合至少一个函数;
35.为每次拟合生成概括参数的集合,该概括参数包括一个或多个模型系数、拟合优度、r2、误差、残差或残差的概括统计;以及
36.根据训练数据集来训练机器学习模型,训练数据集包括对时间序列数据集之一的每次拟合的概括参数的集合,以及时间序列数据集的相关联标记;
37.以电子格式导出机器学习模型。
38.根据第四方面,提供了一种非暂时性的计算机程序产品,包括用于解释宿主噬菌
体反应数据的计算机可执行指令,该指令可由计算机执行以:
39.加载被配置成对宿主反应数据集进行分类的经训练的机器学习模型;
40.接收测试噬菌体的宿主反应数据集,其中宿主反应数据集包括时间序列数据集,其中时间序列数据集中的每个数据点包括指示在特定时间存在测试噬菌体的情况下宿主细菌生长的参数的测量值;
41.在第一时间窗上拟合至少一个函数;
42.为拟合生成概括参数的集合;
43.通过向经训练的机器学习模型提供该概括参数的集合来获得测试噬菌体抑制宿主细菌生长的功效的估计;
44.报告对试验噬菌体功效的估计。
45.根据第五方面,提供了一种计算设备,包括:
46.至少一个存储器,以及
47.至少一个处理器,其中存储器包括指令,指令用于将处理器配置为:
48.接收宿主噬菌体反应数据集和标记,其中宿主噬菌体数据集包括多种宿主噬菌体组合中每一种组合的时间序列数据集,其中宿主细菌在存在噬菌体的情况下生长,并且与宿主噬菌体组合相关联的时间序列数据集中的每个数据点包括指示在特定时间存在相应噬菌体的情况下相应细菌生长的参数的测量值,并且每个时间序列数据集具有指示噬菌体抑制宿主细菌生长的功效的相关联标记;
49.对于每个时间序列数据集,在第一时间窗上拟合至少一个函数;
50.为每次拟合生成概括参数的集合,该概括参数包括一个或多个模型系数、拟合优度、r2、误差、残差或残差的概括统计;以及
51.根据训练数据集来训练机器学习模型,训练数据集包括对时间序列数据集之一的每次拟合的概括参数的集合,以及所拟合的时间序列数据集的相关联标记;
52.以电子格式导出或保存机器学习模型,其中在使用中,经训练的机器学习模型用于使用由使用测试噬菌体和测试细菌获得的宿主噬菌体反应时间序列数据集来估计测试噬菌体抑制测试细菌生长的功效。
53.根据第六方面,提供了一种计算设备,包括:
54.至少一个存储器,以及
55.至少一个处理器,其中存储器包括指令以配置处理器来:
56.加载被配置为对宿主反应数据集进行分类的经训练的机器学习模型;
57.接收测试噬菌体的宿主反应数据集,其中宿主反应数据集包括时间序列数据集,其中时间序列数据集中的每个数据点包括指示在特定时间存在测试噬菌体存的情况下宿主细菌生长的参数的测量值;
58.在第一时间窗上拟合至少一个函数;
59.为拟合生成概括参数的集合;
60.通过向经训练的机器学习模型提供该概括参数的集合来获得测试噬菌体抑制宿主细菌生长的功效的估计;
61.报告对试验噬菌体功效的估计。
62.根据第六个方面,提供了包括至少两种噬菌体的诊疗性噬菌体制剂,其中至少两
种噬菌体通过以下方式选择:
63.通过使用被配置为解释多种宿主噬菌体组合的宿主噬菌体反应数据的经训练的机器学习模型来获得被估计为对测试细菌有效果的至少两种测试噬菌体的集合,在宿主噬菌体组合中宿主细菌在存在噬菌体的情况下生长;
64.获得对该集合中每种测试噬菌体的一种或多种作用机制的估计;
65.基于每种测试噬菌体的估计作用机制来获得该集合中每对测试噬菌体的多样性度量;
66.基于所获得的多样性度量来选择至少两种噬菌体以用于诊疗性噬菌体制剂。
67.在优选的实施例中,通过对测试噬菌体进行测序来确定每种测试噬菌体的作用机制。
附图说明
68.将参照附图讨论本公开的实施例,其中:
69.图1是根据一个实施例,训练用于解释宿主噬菌体反应数据的机器学习模型的方法的流程图;
70.图2是根据一个实施例的多个宿主噬菌体反应数据集的曲线图;
71.图3是根据一个实施例的计算设备的示意图;
72.图4是根据一个实施例的关于其中噬菌体不抑制细菌宿主生长(没有效果/无效)的第一宿主噬菌体时间序列数据集与其中噬菌体抑制细菌宿主生长(有效果/有效)的第二宿主噬菌体时间序列数据集上的几个曲线拟合的比较;以及
73.图5是示出根据一个实施例的机器学习模型对宿主噬菌体时间序列数据集的功效正确分类所花费的时间的曲线图集合;
74.在以下描述中,贯穿所有附图中相同的附图标记表示相同或相对应的部件。
具体实施方式
75.如在说明书和权利要求中所使用的,单数形式“一(a)”、“一个(an)”和“该(the)”包括复数参考,除非上下文另有明确规定。例如,术语“细胞”包括多个细胞,包括它们的混合物。术语“核酸分子”包括多个核酸分子。“噬菌体制剂”能够指至少一种噬菌体制剂,以及多种噬菌体制剂,即多于一种噬菌体制剂。如本领域技术人员所理解的,术语“噬菌体”能够用于指单个噬菌体或多于一种噬菌体。
76.本发明能够“包括”(开放式的)本发明的组分以及本文所描述的其它成分或元素或“基本上由”本发明的组分以及本文所描述的其它成分或元素组成。如这里所使用的,“包括”意味着所列举的元素,或者它们在结构或功能上的等同物,加上没有列举的任何其他一种或多种元素。术语“具有”和“包括”也应理解为开放式的,除非上下文另有暗示。本文所用的“基本上由
……
组成”是指除了权利要求中列举的那些成分之外,本发明还可以包括其它成分,但前提是这些附加成分不会实质性地改变所要求保护的发明的基本特征和新颖特性。
77.如本文所用,“受试者”是脊椎动物,优选哺乳动物,更优选人类。哺乳动物包括,但不限于,鼠类、猿类、人类、农场动物、运动动物和宠物。在其它优选的实施例中,“受试者”是
啮齿动物(例如,豚鼠、仓鼠、大鼠、小鼠)、鼠类(例如,小鼠)、犬科动物(例如,狗)、猫科动物(例如,猫)、马科动物(例如,马)、灵长类动物、猿类动物(例如,猴或猿)、猴(例如,狨猴、狒狒)或猿(例如,大猩猩、黑猩猩、红毛猩猩、长臂猿)。在其他实施例中,可以使用非人哺乳动物,特别是通常用作证明在人类中的治疗功效的模型的哺乳动物(例如,鼠类、灵长类、猪、犬或兔动物)。优选地,“受试者”涵盖任何生物体,例如任何动物或人,其可能患有细菌感染,特别是由多重耐药性细菌引起的感染。
78.如本文所理解的,“有此需要的受试者”包括患有细菌感染的任何人或动物,包括但不限于多重耐药性细菌感染、微生物感染或多种微生物感染。事实上,尽管本文设想到这些方法可用于靶向特定的病原物种,但该方法也能够用于对抗基本上所有的人和/或动物细菌病原体,包括但不限于多重耐药性细菌病原体。因此,在一个具体的实施例中,通过采用本发明的方法,本领域的技术人员能够设计和创建针对许多不同的临床相关细菌病原体的个性化噬菌体制剂,包括多重耐药性(mdr)细菌病原体。
79.如本文所理解的,药物组合物的“有效量”是指适合在受试者中引发诊疗上有益的反应,例如根除受试者中的细菌病原体的组合物的量。这种反应可以包括例如预防、改善、治疗、抑制和/或减少与细菌感染相关联的一种或多种病理状况。
80.术语“大约”或“近似”是指在由本领域普通技术人员确定的特定值的可接受范围内,这部分取决于如何测量或确定该值,例如测量系统的限制。例如,“大约”能够表示给定值的至多20%,优选地至多10%,更优选地至多5%,并且还更优选地至多1%的范围。可替代地,特别是相对于生物系统或过程而言,该术语能够表示在一个数量级内,优选地在一个值的5倍内,更优选地在2倍内。除非另有说明,术语“大约”是指特定值在可接受的误差范围内,诸如
±
1-20%,优选地
±
1-10%,更优选地
±
1-5%。在更进一步的实施例中,“大约”应该理解为+/-5%。
81.在提供值范围的情况下,应该理解的是,在该范围的上限与下限之间的每个中间值以及在该陈述范围内的任何其它陈述值或中间值都包含在本发明内。这些较小范围的上限和下限可以独立地包括在较小范围内,并且也包含在本发明内,服从在所叙述范围内的任何具体排除的限制。当所述范围包括一个或两个极限时,排除这些包括极限的范围也包括在本发明中。
82.本文列举的所有范围包括端点,包括列举两个值“之间”的范围的端点。诸如“大约”、“大体上”、“基本上”、“近似地”等术语被理解为修饰术语或值,使得它不是绝对的,但是不在现有技术中读取。这些术语将由环境和它们修饰的术语来定义,因为这些术语被本领域技术人员所理解。这至少包括用于测量值的给定技术的预期实验误差、技术误差和仪器误差的程度。
83.本文使用的术语“和/或”当用于两个或多个项目的列表中时,意味着能够存在列出的特性中的任何一个,或者能够存在列出的特性中两个或多个特性的任意组合。例如,如果组合物被描述为包含特性a、b和/或c,则该组合物单独地能够仅包含特征a;仅包含特征b;仅包含特征c;a与b的组合;a与c的组合;b与c的组合;或者a、b和c的组合。
84.术语“噬菌体敏感的”或“敏感性谱”是指对感染和/或由噬菌体杀死和/或生长抑制敏感的细菌菌株。即,噬菌体在抑制该细菌菌株生长方面是有效果的或有效的。
85.术语“噬菌体不敏感”或“抗噬菌体性”或“噬菌体抗性”或“抗性谱”被理解为是指
对感染和/或噬菌体杀死和/或生长抑制不敏感,并且优选地高度不敏感的细菌菌株。也就是说,噬菌体在抑制细菌菌株生长方面是没有效果或无效的。
86.本文所用的“诊疗性噬菌体制剂”、“诊疗有效的噬菌体制剂”、“噬菌体制剂”或类似术语应理解为是指包含一种或多种噬菌体的组合物,当施用给有需要的受试者时,能够为细菌感染提供临床有益的治疗。
87.本文使用的术语“组合物”包括本文公开的“噬菌体制剂”,其包括但不限于包含一种或多种纯化噬菌体的药物组合物。“药物组合物”为本领域技术人员所熟知,并且通常包括与选自各种常规药学上可接受的赋形剂、载体、缓冲剂和/或稀释剂的非活性成分组合配制的活性药物成分。术语“药学上可接受的”用于指与生物系统(诸如细胞、细胞培养物、组织或生物体)相容的无毒材料。药学上可接受的赋形剂、载体、缓冲剂和/或稀释剂的示例为本领域技术人员所熟悉,并且能够在例如remington’s pharmaceutical sciences(最新版),mack publishing company,easton,pa中找到。例如,药学上可接受的赋形剂包括但不限于润湿剂或乳化剂、ph缓冲物质、粘合剂、稳定剂、防腐剂、填充剂、吸附剂、消毒剂、洗涤剂、糖醇、胶凝或粘度增强添加剂、调味剂和着色剂。药学上可接受的载体包括大分子,诸如蛋白质、多糖、聚乳酸、聚乙醇酸、聚合氨基酸、氨基酸共聚物、海藻糖、脂质聚集体(诸如油滴或脂质体)和无活性的病毒粒子。药学上可接受的稀释剂包括但不限于水、盐水和甘油。
88.如本文所使用的,术语“估计”涵盖各种各样的动作。例如,“估计”可以包括计算、运算、处理、确定、推导、调查、查找(例如,在表格、数据库或另一数据结构中查找)、查明等。此外,“估计”可以包括接收(例如,接收信息)、访问(例如,访问存储器中的数据)等。此外,“估计”可以包括解析、选择、挑选、建立等。
89.现在将描述训练用于解释宿主噬菌体反应的机器学习模型的计算机实施的方法和系统的实施例,以及用于解释宿主噬菌体反应的机器学习模型的后续使用。
90.图1a是根据一个实施例的训练用于解释宿主噬菌体反应数据的机器学习模型的方法100的流程图,图1b是使用经训练的机器学习模型解释宿主噬菌体反应数据的方法200的流程图。
91.参考图1a,训练用于解释宿主噬菌体反应数据的机器学习模型的方法100包括接收宿主噬菌体反应数据集和标记110。数据集包括多种宿主噬菌体组合中每一种组合的时间序列数据集。与宿主噬菌体组合相关联的时间序列数据集中的每个数据点包括在特定时间在存在相应噬菌体的情况下指示相应细菌生长的参数测量值。此外,为了训练的目的,每个时间序列数据集都有一个相关联的标记,其指示噬菌体抑制细菌生长的功效。为了清楚起见,生长的指标包括指示缺乏生长,诸如测试噬菌体裂解细菌的指标。这通常是二元标志或值,诸如“1”或“真”代表有效果(即抑制或裂解细菌),而“0”或“假”代表没有效果/无效。在一些实施例中,该值可以是概率估计,并且可以确定或改变阈值来对时间序列数据集进行分类。
92.图2是根据一个实施例的多个宿主噬菌体反应数据集10的曲线图1。这些曲线图描绘了作为时间函数的任意单位的生长指标。生长指标可以是染料颜色或细菌生长或呼吸的其他指标的度量,以及生长缺乏的度量,诸如细菌裂解的度量,包括比色和非比色度量。随着时间的推移,数据集分成两组数据集。宿主噬菌体反应的第一集合20对应于其中噬菌体没有效果的反应,即噬菌体无效并且具有s形生长曲线(即sigmoidal),该s形生长曲线起点
于最初的迟滞阶段(或时段)11,随后是其中细菌在存在噬菌体的情况下继续生长的生长阶段(或时段)12,以及其中细菌生长稳定的稳定阶段(或时段)13,例如,当它已经完全定殖在孔中或达到一些生长极限时。宿主噬菌体反应的第二集合30对应于其中噬菌体有效果(即噬菌体有效抑制细菌生长)的反应,并且生长曲线是线性的并且相当平坦或随时间略微上升。
93.不是直接根据每个孔的图像(即宿主噬菌体反应)或每个孔的时间序列数据集来训练机器学习模型,而是首先在第一时间窗内将一个或多个函数拟合到每个宿主噬菌体组合(即每个孔)的时间序列数据集。第一时间窗可以是时间序列数据集所跨越的时间的子集。例如,数据集可以跨越0到36小时,并且第一时间窗可以是0到24小时、1-24小时、2-30小时或0-36小时。例如,在一个实施例中,等式1中所示形式的三阶多项式被拟合到每个孔的时间序列数据:
94.y=a0+a1x+a2x2+a3x3等式1
95.其中x,自变量,是时间;y,因变量,是细菌的相对呼吸指数并且由颜色变化指示。拟合系数a0、a1、a2和a3,也称为回归系数,是拟合(或回归)的概括参数,然后这些概括参数被提供作为用于训练机器学习模型的训练数据集的输入特征。从拟合方法返回的附加概括参数(或概括统计),诸如(多个)误差项、相关系数、确定系数、anova等,也可以作为概括参数的一部分提供。在训练期间,输入特征提供有指示宿主噬菌体反应的标记(例如,1=良好/有效果,0=不良/无效)并且被用于训练机器学习模型。
96.拟合函数提供了一种概括数据集性质从而有助于分类的方法。提供一系列原始图像或甚至完整的时间序列数据集可能会导致过度拟合或提供太多的参数以至于无法实现高效分类。通过拟合函数,能够概括数据集的性质,从而实现更高效和更准确的分类。因此,在上述实施例中,拟合了三阶多项式。选择这一点是因为它提供了若干概括了机器学习模型的数据集(实现了数据缩减)的拟合参数(例如4个),并且三阶多项式能够捕获无效噬菌体的s形噬菌体-宿主反应数据的曲率,以及有效果的噬菌体的近似线性(非)生长曲线,因为高阶系数a2和a3可能接近于零。这种函数也将拾取部分有效的噬菌体。即未抑制生长与完全受抑制生长的极端情况之间的曲线。然而,应当理解,可以使用一系列其他拟合函数,包括线性函数、二次或更高阶多项式,以及非多项式函数,其包括对数、指数、幂、三角、b样条、sigmoidal、非线性函数、回归模型及其组合。通常,(多个)拟合函数将由若干能够作为输入提供给机器学习模型的参数来参数化。可以使用回归/曲线拟合方法来拟合函数,回归/曲线拟合方法试图最小化关于拟合函数的残差的一些参数或损失函数,包括基于最小二乘法的方法,并且可以使用迭代、加权和/或稳健回归方法。
97.参考图2,还应注意,未抑制生长与完全抑制生长的两个极端是截然不同的函数形式,即未抑制生长的近似“s”形曲线(即sigmoidal)(或等效的斜坡或倾斜阶跃函数),与抑制生长的近似线性曲线相比。因此,在一个实施例中,拟合函数可以被选择为具有模拟期望曲线/情况(噬菌体功效)之一的形式,因为注意到对于另一种情况,残差将是大的或异方差的,因为拟合函数不是数据集实际形状的良好估计器/概括。因此,残差或误差将会较大,或者呈现结构/不遵循零均值正态分布。因此,作为补充或替代,这些残差/误差、或基于残差/误差的概括参数可以被提供作为训练模型的参数。残差/误差可以是相关系数r、确定系数(r2)、回归系数ε或误差矩阵ε,或者残差的概括参数/统计,诸如标准差、四分位数间距、五
数概括(最小值、下四分位数、中位数、上四分位数、最大值)、残差分布的若干预定义分位数(例如10%&90%)。此外,拟合优度测试可应用于残差,并且拟合优度测试的输出用作机器学习模型的输入。
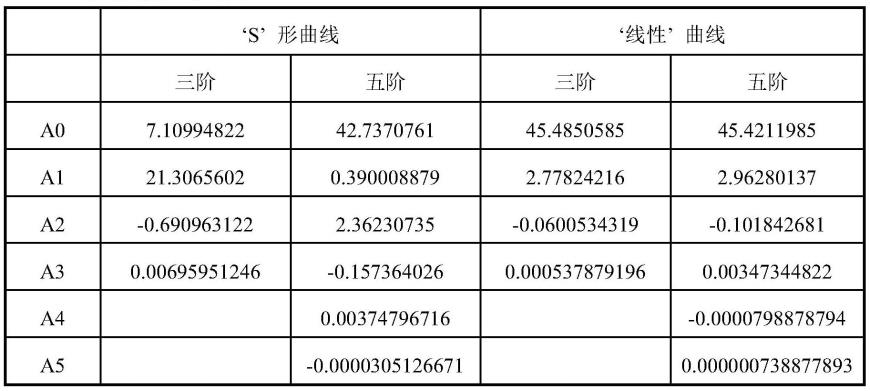
98.这在图4中进一步说明,图4是根据一个实施例,关于其中噬菌体不抑制细菌宿主生长(没有效果/无效)的第一宿主噬菌体时间序列数据集41与其中噬菌体抑制细菌宿主生长(有效果/有效)的第二宿主噬菌体时间序列数据集42的若干曲线拟合的比较。将三阶多项式43、五阶多项式45和线性拟合47各自拟合到第一宿主噬菌体时间序列数据集41。类似地,将三阶多项式44、五阶多项式46和线性拟合48各自拟合到第二宿主噬菌体时间序列数据集42。表1列出了拟合的模型参数。
99.表1拟合模型参数
[0100][0101]
从图4可以看出,三阶和五阶多项式提供了相似的拟合性能,特别是在第二数据集的情况下,其中曲线是线性的(线性曲线),因此高阶系数(a2、a3、a4、a5)实际上为零。最值得注意的是,第一数据集上的线性拟合47由于生长引起的曲率而非常差,生成了0.467的r2值,而线性拟合很好地对第二数据集建模并且具有0.865的r2值。因此,除了提供模型估计之外,提供拟合优度(例如r2)的度量或残差的一些参数化(诸如标准差、残差的四分位数间距)向机器学习模型提供了附加的信息以帮助分开宿主噬菌体反应数据集。在一些实施例中,可以在相同的时间区间内拟合若干函数。例如,线性函数和三阶多项式都可以在相同的0-24小时时段内拟合。在这些实施例中,概括参数包括来自两个拟合函数的拟合参数(例如系数和/或误差)。
[0102]
此外,从图2和图4中可以明显看出,曲线10示出了不同的阶段——即迟缓阶段11、(潜在)生长阶段12和稳定阶段13。因此,在一个实施例中,不是在第一时段(例如,从0到20小时)内拟合单个函数,而是执行多次拟合,其中每次拟合是在比第一时间窗更短的时间区间内进行的。例如,在上述情况下,我们能够在迟缓阶段进行第一次拟合,在生长阶段进行第二次拟合,并且在稳定阶段进行第三次拟合。在该实施例中,第一时间窗由最早时间区间的起点和最晚时间区间的终点来定义。这些拟合可以是逐段或区间拟合/回归,其中时间区间是跨越时间窗的连续区间(即,因此每个函数在不同的时间窗上拟合)。例如,第一函数可以在诸如0至7小时的第一拟合时间区间上拟合,第二函数可以在诸如7至14小时的第二时间区间上拟合,第三函数可以在14至20小时的第三时间区间上拟合,以限定0-20小时的第
一时段。这些时间区间(或拟合时段或时间部分)可以连续地跨越第一时段(即逐段拟合),或者在一些实施例中,这些时间区间可以不连续地跨越第一时间窗,使得在一个时间区间的终点与另一个时间区间的起点之间存在时间间隙(例如,3至7小时、9至13小时、17至20小时)。此外,时间区间可以是部分重叠的时段,使得一个时间区间的终点的一部分可以与另一个时间区间的起点的一部分重叠(例如,0至10小时、5至15小时、10至20小时)。在一个实施例中,时间区间可以是固定宽度并且时间区间是滑动时间区间。相同类型的拟合函数(例如,具有相同的函数形式,诸如线性、三阶多项式等)可以被拟合到每个时间区间(即,单个函数被拟合到每个不同的时间区间),或者具有不同类型或形式的多个函数可以被拟合到每个时间区间。例如,在一个实施例中,在至少3个时间区间中执行逐段线性拟合,并且将每个时间区间的r2值作为输入参数之一提供给机器学习模型。在拟合时间区间中的每一个中,r2接近1指示好的噬菌体。在不同的函数形式/类型拟合到每个区间的情况下,这些不需要被限制为在边界上是连续的。
[0103]
因此,鉴于以上所述,我们能够将拟合步骤(图1a中的步骤120)概括为对于每个时间序列数据集,在第一时间窗上拟合至少一个函数。如所讨论的,这可以是在单个时间窗上的单个函数、在同一单个时间窗上的多个函数、或者在一个时间区间上拟合多个函数,其中第一时间窗由最早时间区间的起点和最晚时间区间的终点来定义,并且每个时间区间比第一时间窗更短。时间区间可以各自是不同的时间并且可以连续地或不连续地跨越第一时间窗。然后,我们执行概括步骤130,在该步骤中,拟合步骤的结果用于为每次拟合生成概括参数的集合,其用于训练机器学习模型(即,作为机器学习模型的输入提供),并且随后用作训练模型的输入以对测试宿主噬菌体反应数据集进行分类。该概括参数包括一个或多个模型系数/拟合参数、拟合优度、r2、误差、残差或残差的概括统计。
[0104]
一旦确定(或估计)了每个数据集集合的概括参数的集合,这能够用于创建用作训练机器学习模型的输入的训练数据集(和验证数据集)。在步骤140处,我们接着根据训练数据集来训练机器学习模型,该训练数据集包括用于拟合宿主噬菌体组合的时间序列数据集的概括参数的集合,以及时间序列数据集的相关联标记。输入数据集可以被格式化为矩阵,其中每行表示宿主噬菌体组合(或者更确切地说,在孔中存在噬菌体的情况下宿主生长观察的时间序列数据集),并且列表示拟合系数。然而,应该理解,数据集可以以其他格式存储或表示在包括联网存储装置和/或数据库的一个或多个存储装置上。然后,能够将标记分配给每一行(例如,作为额外的列添加)以用于机器学习模型的训练和验证评估。
[0105]
在这些实施例中,机器学习算法是监督分类法,其一旦被训练能够用于从宿主噬菌体反应数据集估计(分类)测试噬菌体对测试宿主细菌的功效。可以使用一系列机器学习分类器,诸如提升树分类器、随机森林分类器、决策树分类器、支持向量机(svm)分类器、逻辑分类器等。在一些实施例中,分类器是概率分类器。也就是说,分类器输出类别概率,而不仅仅是发布二元分类(例如,有效果或无效果)。概率分类器包括朴素贝叶斯、二项式回归模型、离散选择模型、决策树和基于boosting的分类器。
[0106]
机器学习训练包括将完整的数据集分成第一训练数据集和第二验证数据集。训练数据集优选地为总数据集的60-80%左右。机器学习模型使用该训练数据集来创建分类器模型以准确识别有效果的噬菌体。第二集合是验证数据集,其通常至少占数据集的10%并且更优选地占20-40%:该数据集用于验证使用训练数据集创建的模型的准确率。数据可以
随机地分派给训练数据集和验证数据集。在一些实施例中,可以对训练数据集和验证数据集进行检查以确保每个数据集内存在相似比例的好/坏噬菌体。
[0107]
在一些实施例中,执行多个训练验证循环(交叉验证)。在每个训练验证循环中,数据集被随机地分派给训练和验证数据集并且被用于训练模型。这被重复许多次,并且可以鉴定所选择的最佳模型或来自不同循环的多个性能良好的模型,以及使用集成投票法来组合结果。例如,每个模型可以投票决定它是否预测噬菌体是否有效果,并且使用多数决定规则来输出分类。这种方法还能够提供粗略的置信度估计,例如基于多数的大小。
[0108]
在使用交叉验证的一些实施例中,数据集可以被分派给三个数据集,即训练数据集、验证数据集和留出或测试数据集。第三个留出或测试数据集通常占总数据集的10-20%左右并且不用于训练机器学习分类器或交叉验证。该留出数据集提供了对机器学习分类器模型的准确率的无偏估计。
[0109]
一旦训练了机器学习模型,然后我们在步骤150处以电子格式导出或保存机器学习模型,供计算系统(相同或不同的计算系统)随后使用,以使用由使用测试噬菌体和测试细菌获得的宿主噬菌体反应时间序列数据集来估计测试噬菌体抑制测试细菌生长的功效。能够使用机器学习代码/api的适当功能将该模型导出或保存到电子模型文件中,以加载到被配置为执行该模型以对新的宿主噬菌体反应数据进行分类的另一个计算机装置上。在一些实施例中,保存机器学习模型供以后在用于训练机器学习模型的同一计算装置上使用。电子模型文件可以是由机器学习代码/库生成的具有定义格式的电子文件,该电子文件能够使用作为机器学习代码/api的一部分提供的标准函数(例如,exportmodel()和loadmodel())导出,然后读回(重新加载)。文件格式可以是二进制格式,包括机器可读格式或文本格式,并且可以是序列化表示。可以使用json、yaml或类似的数据传输协议将电子文件发送到另一个计算系统或保存到存储位置,包括网络存储位置。在一些实施例中,附加的模型元数据可以被导出/保存,并且与模型参数诸如模型准确率、训练数据集描述等一起发送,模型准确率、训练数据集描述等可以进一步表征该模型,或者以其他方式帮助在另一计算装置/服务器上构建另一模型。
[0110]
在步骤160处,然后通过计算系统或设备使用机器学习模型,使用由使用测试噬菌体和测试细菌获得的宿主噬菌体反应时间序列数据集来估计测试噬菌体抑制测试细菌生长的功效。这在流程图1b中进一步说明,图1b是用于解释宿主噬菌体反应数据200的方法的流程图。这能够使用经过训练的机器学习模型在相同的计算机系统或设备或者另一个计算机系统或设备上执行。
[0111]
在步骤210处,我们将被配置为将宿主反应数据集分类的经训练的机器学习模型加载到计算系统中。这可以包括接收在步骤150中导出的描述经训练的机器学习模型的电子文件,并且(由计算系统)读取该电子文件以在存储器中重建经训练的机器学习模型,用于由(多个)处理器执行。为了清楚起见,这不需要训练数据而只需要描述或表征从训练数据中学习的分类器的配置。在步骤220处,我们接收测试噬菌体的宿主反应数据集。这可以经由门户网站上传到计算系统,或者由与生成宿主反应数据集的设备相关联的计算设备作为电子文件发送,或者与生成宿主反应数据集的设备相关联的计算设备可以将宿主反应数据集作为电子文件存储在存储位置(例如网络存储),并且计算系统可以向存储位置周期性地轮询在存储位置中新接收的文件。如在训练数据集的情况下,数据集包括时间序列数据
集,其中时间序列数据集中的每个数据点包括指示在特定时间存在测试噬菌体的情况下宿主细菌生长的参数的测量值。在步骤230处,然后我们在第一时间窗上拟合至少一个函数,然后在步骤240处,我们为拟合生成概括参数的集合(例如,模型参数和/或误差/残差估计)。步骤230和240等同于步骤120和130,使得输入到经训练的机器学习模型的数据已经以与训练数据相同的方式生成。请注意,当传递概括参数的集合时,执行拟合(或多次拟合)的时间窗不需要与用于训练的时间窗相同。然而,优选的是时间窗相同或相似,或者至少足以使拟合获得拟合参数的可靠估计器。类似地,在训练机器学习模型期间使用的相同拟合过程应该被用于生成用于由机器学习模型分类的等效概括参数。例如,是否在第一时间窗上拟合单个函数、在第一时间窗上拟合多个函数、或者在作为第一时间窗的一部分的时段上各自拟合多个函数,是基于如何训练机器学习模型使得能够生成等效的概括参数来确定的。在步骤250处,然后通过向机器学习模型提供该概括参数的集合来获得测试噬菌体抑制宿主/测试细菌生长的功效的估计,即经训练的机器学习模型对输入数据集进行分类。在步骤260处,报告了测试噬菌体功效的估计。该报告可以是二元输出,诸如噬菌体是有效果的还是无效果的(即无效)。在一些实施例中,机器学习模型也可以输出分类的置信度估计。该报告可以是诸如pdf文件的电子记录,或者可以是经由计算系统的用户接口提供的电子报告。例如,用于上传宿主反应数据集的网络接口也可以用于发布报告,例如使用自动化报告生成器模块(例如微软报告服务),其使用存储的模板来生成报告,该模板在执行时纳入了功效的估计。此外,该系统可以被配置成允许用户上传多个宿主反应数据集并且在单个报告中报告所有结果。
[0112]
表2示出了在包括1000行的数据集上测试的各种机器学习模型的验证结果。该数据集被分成包含80%数据的训练集和包含剩余20%数据的测试集。
[0113]
表2机器学习模型验证结果
[0114]
ml模型验证准确率提升树分类器0.94444随机森林分类器0.96296决策树分类器0.96296svm分类器0.92593逻辑分类器0.96296
[0115]
随机森林分类器、决策树分类器和逻辑分类器是该数据集的表现最好的分类器。然而,提升树分类器甚至svm分类器的性能仅略低于这三个模型。此外,考虑到准确率预期会因测试运行而异,这表明上述机器学习模型中任一个都可能是可接受的。在一个实施例中,机器学习模型是随机森林分类器、决策树分类器或逻辑分类器。
[0116]
从图4能够看出,在迟缓阶段(即大约6至7小时)之后,两条曲线起点发散。因此,为了检验该模型能够多快地区分表现不佳的噬菌体,进行了一项计算机模拟实验以观察机器学习模型可以多快地可靠地对测试宿主噬菌体反应数据集进行分类。在该实验中,将机器学习模型拟合到每个宿主噬菌体反应的完整数据集,然后对数据集进行一系列测试拟合,其中每次拟合使用15分钟的间隔在逐渐增加的时间窗内进行。也就是说,在时间窗(0,t)上执行测试拟合,其中对于每个后续的测试拟合,t的增量是15分钟,然后将拟合的参数提供给经训练的机器学习模型。如上所指出的,经训练的机器学习模型仅需要概括参数的集合,
并且拟合数据集的时间窗不需要与用于训练模型的时间窗相同。
[0117]
图5是48个曲线图集合,示出了根据一个实施例的机器学习模型对宿主噬菌体时间序列数据集的功效正确分类所花费的时间。每一个曲线图示出了测试拟合上的分类是否与从机器学习模型获得的完整数据集上的分类一致,其中,在15分钟间隔中的每一个间隔上,“1”表示一致,“0”表示不一致。因此,每个曲线图示出了机器学习算法生成正确/稳定的估计需要多长时间。
[0118]
毫不奇怪,这些曲线图在最初的几个小时内波动很大,但往往在10至20小时之间确定在正确的估计上。值得注意的是,a3、c3和h3是噬菌体有效抑制生长的情况,并且这些都需要大约20小时(时间点51)用于机器学习模型来进行可靠的估计。这与a1、a4和c2形成对比,在a1、a4和c2中,噬菌体无效,并且这些在10小时后(时间点54)实现稳定的估计。然而,一些具有无效噬菌体的细胞诸如b5和d5需要更长的时间来稳定(时间点55)。
[0119]
这些结果表明,机器学习模型在10小时后在快速预测差的噬菌体方面相当准确,但需要更长时间来鉴定有效噬菌体(在这种情况下大约20小时)。这表明该时段应该跨越20小时,尽管测试可以在10小时后进行以选出明显无效的噬菌体。然而,所需的最短时段将在某种程度上取决于所用的拟合函数、进行拟合的时间窗(例如单次或逐段拟合)以及用于宿主噬菌体反应测试的孔的生长培养基。
[0120]
在一个实施例中,拟合步骤可以在宿主噬菌体实验过程中重复进行。也就是说,随着实验的进行,并且更多的图像和数据变得可用,用附加的数据点(即附加的时间)来更新数据集并且在更新的数据集上对拟合函数进行重新拟合和分类。这相当于在每次新的拟合中逐渐增加时间窗。在另一个实施例中,拟合时间窗的宽度可以是固定的,使得随着更多数据变得可用,拟合过程有效地使用滑动时间窗。在这些实施例中,概率分类器可以用于输出分类概率。可替代地,可以用每个新的时间点/拟合来估计分类预期。分类预期是对分类结果正确的概率(或可能性)的估计,其条件是使用包含与当前时间的当前状态匹配的点的历史数据的分布确定的当前状态。也就是说,在测定中给定时间处给定参数集合,可以生成作为给定噬菌体分类结论的置信度(即当前分类结果是预期结果)的度量。例如,可以每15分钟获得新数据,并且可以为每个时间点保存分类器决策。为了获得每个点的分类预期,提取具有匹配的当前状态的历史数据集的子集。在第一实施例中,这可以是在当前时间点具有相同分类结论的数据集。获得该子集后,然后确定分类结果的当前估计与最终分类结果(例如,测定完成后的分类)相同的子集的百分比,并且返回该百分比(或基于该百分比的数字)。随着时间的推移,预计这将稳定在最终值上。也就是说,对于在24小时内进行的测定,我们可能在4小时内得到50%概率的分类结果(即不稳定的估计)。到12小时,概率可能是75%(很可能是准确的),到20小时,概率可能是99%(很大可能是准确的)。在另一个实施例中,数据集可以是在当前时间点具有相同分类结论并且在当前时间具有在观察到的生长度量(即时间序列值)的某个预定义范围内的生长度量(即时间序列值)的数据集。这可以通过将生长值(图2中的y轴值)划分成间隔(interval)或堆栈(bin)的集合(例如0到0.1、0.1到0.2、0.3到0.4等)来实现。然后,鉴定观察到的生长度量属于哪个间隔/堆栈,并且选择在相同的时间在相同的间隔/堆栈中观察到具有相同的当前分类结果的生长度量的历史数据的子集。获得该子集后,接着确定当前分类结果与最终分类结果相同(即,当前分类结果是预期分类结果)的子集的百分比。在替代实施例中,数据集可以是如上所述的在当前时间具有
在观察到的生长度量的某个范围内的生长度量的数据集(即,数据集的选择忽略当前分类结果)。然后,我们返回最终分类结果与当前分类结果相匹配的子集的最终分类结果的百分比。因此,通过利用历史数据集中可用的较长时间序列(和结论),分类预期能够提供当前分类结果的置信度或稳定性的早期度量。
[0121]
上述实施例能够用于鉴定对宿主细菌有效果的一种或多种噬菌体。例如,在图5中,鉴定了3种有效果的噬菌体(a3,c3和h3)。当针对同一宿主细菌测试多种噬菌体时,能够生成用于治疗的最有效的(多种)噬菌体的诊疗性噬菌体制剂。可以通过有效果噬菌体的多样性度量来选择要包含哪一种或多种噬菌体。在一个实施例中,多样性度量指示了噬菌体之间不同的作用机制。这种多样性度量可以通过对噬菌体测序并且使用生物信息学方法或数据集来估计功能效应/关联进行估计,并且这些可以用于分配一种或多种作用机制标记(这些可以选自受控的本体,诸如基因本体数据库或生物网络数据库)。因此,能够基于具有不同作用机制的噬菌体来选择噬菌体组合,或者当噬菌体被分配多种可能的作用机制集合时,可以基于具有最不相似集合(即可能的作用机制的最小重叠)的两个噬菌体来选择噬菌体。可以基于共享生物网络或路径、或基因本体论(go)术语(或go术语的下游)、或go-cam模型来定义重叠的动作方法。例如,每对噬菌体可以基于两个列表不共有的作用机制的数量来分配分数。最大的分数将指示最具多样性(非重叠)的列表。在另一个示例中,分数可以是加权分数。例如,可以将先前的分数除以两个列表大小的总和以对列表大小进行加权。可以使用其他加权或评分函数,诸如应用考虑了与序列相关联的作用机制的证据的加权。基于生物信息学数据挖掘或生物网络/途径分析,也可以使用评估可能作用机制多样性的其他方法。这种方案提供了对抗适应单个噬菌体作用机制的细菌的鲁棒性,就好像第二噬菌体具有不同的作用机制,那么它可能仍然有效。
[0122]
因此,本文描述的实施例有利地提供了用于分析/解释宿主噬菌体反应数据的自动化方法。通过使用拟合一个或多个函数的方案并且生成概括参数作为训练机器学习模型的输入,机器学习模型能够被高效地训练为分类器。使用概括数据的方法在很大程度上与部署时的数据大小和采样频率无关,即,如果每分钟或每15分钟采样一次数据,则训练和后续部署仍会减少到所计算的概括参数。该方案能够用于鉴定包括在噬菌体制剂中的噬菌体,以用于治疗患有细菌感染,特别是多重耐药性感染的患者。方法还能够用于鉴定能够用于清理细菌污染的区域,诸如用于清理工业场地的噬菌体。这些噬菌体制剂可以包括两种或多种具有上述不同作用机制的噬菌体。
[0123]
也能够对上述方法进行变化。在一个实施例中,当在测定期间(即,在整个测定时段之前的某个时间点)执行时,历史数据集用于改进分类。在该实施例中,在当前时段(例如,0至6小时)内执行拟合(或多次拟合)。然后获得历史数据集中每个宿主噬菌体谱在相同时段内的拟合结果,并且基于拟合结果与当前宿主噬菌体组合(在当前时段内)的拟合结果相似来选择历史数据集的子集。也就是说,鉴定到这个时间点(或在到这个时间点的一些时间范围内)为止具有与观察到的噬菌体宿主曲线相似的噬菌体宿主曲线的历史数据集的子集。确定相似的噬菌体宿主曲线可以使用相关性度量(例如,交叉相关性或相似的相似性度量)来进行。然后,我们提供历史数据集中的附加数据作为分类器的进一步输入(不仅仅是拟合值)。在一个实施例中,这可能是最终有效果的历史数据集的该子集的百分比。
[0124]
在一个实施例中,可以使用深度学习方法来生成模型,其中大量的宿主噬菌体反
应训练数据是可用的。在深度学习方法中,通常包括具有分类层的多层卷积神经网的神经网络通过优化模型的参数或权重来训练,以最小化任务相关的“损失函数”。例如,如果我们考虑二元宿主噬菌体反应分类问题,即,将宿主噬菌体反应时间序列集合准确地分成两类,拟合的函数参数通过模型运行,该模型计算二元输出标记(例如0或1)以代表感兴趣的两类。然后将预测的输出与真实值标记进行比较,并且计算损失(或误差)。在二元分类示例中,二元交叉熵损失函数是最常用的损失函数。使用从该函数获得的损失值,我们能够计算网络中每一层相对于输入的误差梯度。这个过程被称为反向传播。直观地,这些梯度通知网络如何修改(或优化)权重以获得对这些图像中每个图像的更准确的预测。
[0125]
然而,在实践中,在训练的单个迭代或“轮”中计算网络更新可能是困难的、不可取的或者甚至是不可能的。这通常是因为网络需要大量数据并且包含大量能够被修改的参数。为了解决这个问题,通常使用小批量数据来代替完整的数据集。这些批量中的每一个都是从数据集中随机抽取的,并且选择足够大的批量大小来近似整个数据集的统计数据。然后在小批量上应用优化,直到满足停止条件为止(即,直到收敛为止,或者根据预定义的量度实现满意的结果)。这个过程被称为随机梯度下降(sgd)并且是优化神经网络的标准过程。通常,优化器会运行几十万到几百万次迭代。此外,神经网络优化是非凸的,在损失函数定义的参数空间中往往存在许多局部极小值。直观地说,这意味着由于网络和数据中权重之间的复杂交互作用,存在许多几乎同等有效的权重组合,从而导致几乎相同的输出。深度学习模型或包含多层卷积神经网的神经网络架构通常使用图形处理单元(gpu)进行训练。与中央处理器(cpu)相比,gpu在计算线性代数方面极为高效。
[0126]
像机器学习训练一样,训练神经网包括执行多个训练验证循环。在每个训练验证循环中,总可用数据集的每个随机化被分成至少3个数据集。如之前所述,第一数据集是训练数据集,优选地约为总数据集的70-80%:该数据集用于创建分类器模型以基于标记的训练数据来准确地鉴定有效果的噬菌体。第二集合是验证数据集,其通常至少占数据集的10%。该数据集用于验证或测试使用训练数据集创建的模型的准确率。尽管此数据集独立于用于创建模型的训练数据集,但验证数据集在准确率方面仍具有较小的正偏差,因为它用于监视和优化模型训练的进度。因此,训练倾向于以最大化该特定验证数据集的准确率的模型为目标,当更普遍地应用于其他数据集时,该模型不一定是最佳模型。因此,通常优选(但不是必须)具有被称为盲验证数据集的第三数据集,它通常占数据集的10-20%左右。这种验证发生在建模和验证过程的最后,当最终模型已被创建和选择时,并且用于对最终模型进行最终的无偏准确率评估以及解决验证数据集的任何正偏差。由于上文所讨论的原因,验证数据集的准确率可能会高于盲验证数据集,然而,盲验证数据集的结果是模型准确率的更可靠的度量。
[0127]
根据数据集使用多个训练验证循环来训练机器学习模型。为了便于理解,能够将数据集格式化为矩阵,其中每行代表宿主噬菌体实验(时间序列)并且列代表拟合的系数。然而,将会理解,数据集可以以其他格式或表示存储在包括联网存储装置在内的一个或多个存储装置上。训练验证循环遵循以下框架。
[0128]
训练数据被分成几批。每批中的行数(时间序列)是自由模型参数,但是控制算法学习的速度和稳定性。在每一批之后,调整网络的权重,并且评估到目前为止的运行总准确率。当所有行都被评估时,我们说已经执行了一轮。然后,训练集被重新随机化,并且对于下
一轮,训练再次从顶部起点。在训练期间,可以运行多轮,其数量取决于数据集的大小、数据集的复杂性和被训练模型的复杂性。在一些实施例中,轮的数量可以是从100到1000或更多。在每一轮之后,在没有任何训练发生的情况下在验证集上运行模型,以提供模型有多准确的进度感。这可以用于指导用户或系统是否应该运行更多轮,或者更多轮是否会导致过度训练。验证集指导总体模型参数(超参数)的选择,因此不是真正的盲集。一旦模型被训练,盲验证数据集被用于评估最终的准确率。
[0129]
在深度学习中,一系列自由参数被用于优化验证集上的模型训练。其中一个关键参数是学习率,它决定了每一批之后基础神经元权重的调整幅度。通常,在训练模型时,我们会尽量避免过度训练或过度拟合数据。当模型包含太多参数而无法拟合时,就会发生这种情况,并且本质上是“记忆”数据,在训练集或验证集上用泛化能力换取准确率。能够通过各种策略来改善过度训练的可能性,包括减慢或衰减的学习率(例如,每n轮将学习率减半)、张量初始化、预训练(使用先前训练的模型作为起始点)、以及添加噪声,诸如暂退层或批归一化,这迫使模型更真实地泛化。通过引入在整流器的接收范围内将所有进入权重设置为零的随机机会,暂退正则化有效地简化了网络。通过引入噪声,它有效地确保其余整流器正确地拟合数据的表示,而不依赖于过度特化。这允许神经网更有效地泛化并且变得对网络权重的特定值不太敏感。类似地,通过将输入权重转移到零均值和单位方差作为整流阶段的前兆,批归一化能够允许更快的学习和泛化。
[0130]
在执行深度学习时,改变神经元权重以实现可接受的分类的方法包括需要规定优化协议。也就是说,对于“准确率”或“损失”的给定定义(以下讨论),确切地应该调整多少权重,以及应该如何使用学习率的值,有许多需要规定的技术。合适的优化技术包括具有动量的随机梯度下降(sgd)(和/或nesterov加速梯度)、具有增量的自适应梯度(adadelta)、自适应矩估计(adam)、均方根传播(rmsprop)和有限记忆broyden-fletcher-gold farb-shanno(l-mbfgs)算法。除了这些方法之外,还可以包括不均匀的学习率。也就是说,卷积层的学习率能够被规定为比分类器的学习率大得多或小得多。这在预训练模型的情况下是有用的,其中对分类器下面的过滤器的改变应该保持更加“冻结”,并且分类器被再训练,使得预训练不会被附加的重新训练撤销。
[0131]
尽管优化器规定了如何在给定特定损失或准确率度量的情况下更新权重,但是在一些实施例中,损失函数被修改以纳入分布效应。这些可能包括交叉熵损失、推断分布或自定义损失函数。
[0132]
交叉熵损失(cross entropy loss)是一种常用的损失函数,它具有优于真实值与预测值之间的简单均方差的趋势。如果网络的结果通过softmax层传递,则交叉熵的分布导致更好的准确率。这是因为通过不对远处的异常点进行过重的加权,自然地最大化了对输入数据进行正确分类的可能性。对于输入阵列(input array),批量(batch)代表一批宿主噬菌体时间序列,并且类(class)代表功效(即噬菌体在抑制细菌生长方面是好还是差),交叉熵损失(loss)被定义为:
[0133][0134]
如果数据包含类偏差(class bias),即比好的噬菌体样例更差(或反之亦然),损失函数应该成比例地加权(weight),使得对数目较少类的元素的错误分类受到更重的惩
罚。这是通过将等式(2)的右侧预乘以因子:weight[class]=1/n[class]来实现的,其中n[class]是每个类的数据集总数。如果需要,也可以手动地将权重偏向好的噬菌体以便与假阳性相比减少假阴性的数量。
[0135]
在一些实施例中,可以使用推断分布。虽然在噬菌体分类中寻求高水平的准确率是重要的,但在模型中寻求高水平的可迁移性也是重要的。也就是说,理解分数的分布通常是有益的,并且尽管寻求高准确率是一个重要的目标,但是使用确定性的裕度来确信地分离有效果的(好的)和无效果的(差的)噬菌体是一种该模型将很好地泛化到留出测试集的指标。由于测试集的准确率能够用于基准测试,诸如比较熟练的分析人员对相同噬菌体宿主图表进行分类的准确率,确保泛化能力也应被纳入每一轮对模型成功的逐批评估中。
[0136]
图3描绘了被配置成执行本文描述的计算机实现方法中的任何一种方法的示例性计算系统。该计算系统可以包括操作性地连接到一个或多个存储器的一个或多个处理器,该一个或多个存储器存储指令以配置处理器来执行该方法的实施例。在这种情况下,计算系统可以包括例如一个或多个处理器、存储器、存储装置和输入/输出装置(例如,监视器、键盘、磁盘驱动器、网络接口、互联网连接等)。然而,计算系统可以包括用于执行过程的一些或所有方面的电路系统或其他专用硬件。计算系统可以是计算设备,诸如单体计算机、台式计算机、膝上型计算机、平板或移动计算设备以及任何相关联的外围装置。计算机系统可以是分布式系统,包括基于服务器的系统和基于云的计算系统。在一些操作设置中,计算系统可以被配置为包括一个或多个单元的系统,每个单元被配置为以软件、硬件或其某种组合来执行过程的一些方面。例如,用户接口可以在台式计算机或平板计算机上提供,而机器学习模型的训练和经训练的机器学习模型的执行可以在包括基于云的服务器系统的基于服务器的系统上执行,并且用户接口被配置成与这样的服务器通信。用户接口可以被提供为网络门户,允许一台计算机上的用户上传数据集,该数据集可以在远程计算设备或系统(例如服务器或云系统)上被处理,并且将结果(即报告)提供回用户或其他计算设备上的其他用户。
[0137]
结合本文公开的实施例描述的方法或算法的步骤可以直接体现在硬件、由处理器执行的软件模块或两者的组合中。对于硬件实施方式,处理可以在一个或多个专用集成电路(asic)、数字信号处理器(dsp)、数字信号处理装置(dspd)、可编程逻辑装置(pld)、现场可编程门阵列(fpga)、处理器、控制器、微控制器、微处理器、被设计成执行本文描述的功能的其他电子单元或其组合中实施。软件模块,也称为计算机程序、计算机代码或指令,可以包含许多源代码或目标代码段或指令,并且可以驻留在任何计算机可读介质中,诸如ram存储器、闪存、rom存储器、eprom存储器、寄存器、硬盘、可移动磁盘、cd-rom、dvd-rom、蓝光光盘或任何其他形式的计算机可读介质。在一些方面,计算机可读介质可以包括非暂时性计算机可读介质(例如,有形介质)。在另一方面,计算机可读介质可以与处理器是一体的。处理器和计算机可读介质可以驻留在asic或相关装置中。软件代码可以存储在存储器单元中并且处理器可以被配置为执行它们。存储器单元可以在处理器内部或处理器外部实施,在这种情况下,它能够经由本领域中已知的各种手段可通信地耦合到处理器。
[0138]
具体而言,图3描绘了具有可用于执行本文描述的过程的多个组件的计算系统(300)。例如,输入/输出(“i/o”)接口330、一个或多个中央处理单元(“cpu”)(340)和存储器部分(350)。i/o接口(330)连接到输入和输出装置,诸如显示器(320)、键盘(310)、盘存储单
元(390)和介质驱动单元(360)。介质驱动单元(360)能够读/写计算机可读介质(370),计算机可读介质(370)能够包含程序(380)和/或数据。i/o接口可以包括网络接口和/或通信模块,用于使用预定义的通信协议(例如,蓝牙、zigbee、ieee 802.15、ieee 802.11、tcp/ip、udp等)与另一装置中的等效通信模块进行通信。这可以是单个计算设备,或分布式计算设备或包括基于云的计算系统的分布式计算系统。
[0139]
在一个实施例中,使用turi create(apple.github.io/turicreate)生成机器学习模型,turi create是由苹果(以及更早的turi)开发的基于python的机器学习库,用于构建基于ai/基于机器学习的应用。然而,在其他实施例中,可以使用类似的机器学习库/包,诸如scikit-learn、tensorflow和pytorch。这些通常实施多个不同的分类器,诸如提升树分类器、随机森林分类器、决策树分类器、支持向量机(svm)分类器、逻辑分类器等。这些都能够各自进行测试,并且选择表现最好的分类器。计算机程序可以例如用通用编程语言(例如pascal、c、c++、java、python、json等)编写或用一些专门的应用特定语言编写来提供用户接口,调用机器学习库,并且导出结果。
[0140]
还能够生成包括用于执行本文描述的方法中任何方法的计算机可执行指令的非暂时性计算机程序产品或存储介质。非暂时性计算机可读介质能够用于存储(例如,有形地体现)一个或多个计算机程序,用于通过计算机执行上述过程中的任何一个过程。还提供了一种计算机系统,包括一个或多个处理器、存储器和一个或多个程序,其中一个或多个程序存储在存储器中并且被配置为由一个或多个处理器执行,一个或多个程序包括用于执行本文描述的方法中的任何方法的指令。
[0141]
本领域的技术人员将理解,可以使用多种技术和方法中的任何一种来表示信息和信号。例如,数据、指令、命令、信息、信号、比特、符号和芯片可以在整个上述描述中被引用,可以由电压、电流、电磁波、磁场或粒子、光场或粒子或其任意组合来代表。
[0142]
所属领域的技术人员将进一步了解,结合本文所公开的实施例描述的各种说明性逻辑块、模块、电路和算法步骤可实施为电子硬件、计算机软件或指令或两者的组合。为了清楚地说明硬件和软件的这种可互换性,各种说明性的组件、块、模块、电路和步骤已经在上面根据它们的功能进行了一般描述。这种功能性被实施为硬件还是软件取决于特定的应用和对整个系统的设计约束。熟练的技术人员可以针对每个特定的应用以不同的方式实施所描述的功能,但是这样的实施方式决定不应该被解释为导致脱离本发明的范围。
[0143]
在整个说明书和所附的权利要求书中,除非上下文另有要求,否则词语“包括”和“包含”以及诸如“具有”和“含有”之类的变体将被理解为暗示包括所陈述的整数或整数组,但不排除任何其他整数或整数组。
[0144]
本说明书中对任何现有技术的引用不是也不应该被认为是对这种现有技术构成公知常识的一部分的任何形式的建议的认可。
[0145]
本领域的技术人员将会理解,本公开的使用不限于所描述的一个或多个特定应用。关于这里描述或描绘的特定元件和/或特征,本公开也不限于其优选实施例。应当理解,本公开不限于所公开的一个或多个实施例,而是能够在不脱离由所附权利要求阐述和限定的范围的情况下进行多种重新布置、修改和替换。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1