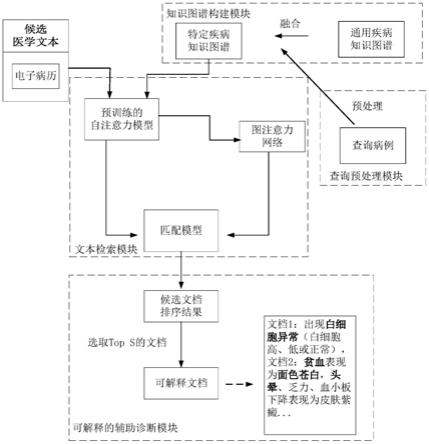
一种基于文本检索的可解释性智慧医疗辅助诊断系统的制作方法
1.本发明涉及文本检索的技术领域,尤其是指一种基于文本检索的可解释性智慧医疗辅助诊断系统。
背景技术:
2.随着计算机领域的飞速发展,各行业与计算机结合越来越深。借助计算机可以利用行业内的数据进行数据挖掘,数据分析。尤其是在医学领域,近年来计算机领域里的深度学习方法可以从海量数据中提取原始特征,然后发现这些原始特征背后的规律,从而解决复杂问题。随着技术的发展和计算能力的增强,深度学习在医疗领域的应用越来越广泛,智慧医疗已经在病例分析、疾病预测中获得初步成果,但深度学习模型属于黑盒子性质,即可解释性较差,不能给出哪些数据对于医疗诊断起了决定作用,因此医生对于医疗诊断结果不能完全相信,这样妨碍计算机技术用于生物医学领域。智慧医疗辅助诊断的可解释性模型就是提供疾病诊断结果的可解释性,即诊断疾病时,不仅仅是单纯给出诊断结果,还需要给出相关解释,例如诊断结果的由来,相关的案例等。
3.本专利运用文本检索技术,通过病例诊断结果或生物医学文献检索出相关的病例信息,从中找到以往的相似病例提供给医生。然而传统的检索方法,是对精准词的匹配,即使从生物医学知识库中加入词义相同的或者相关的词也不能很好解决,精准匹配带来的语义鸿沟问题。而最近深度学习技术应用于文本检索上,可以取得不错的效果,如将查询词或者拓展词与文档中的词通过神经网络映射到低维向量空间,从而更好比较两者的语义,找出具有相似语义但不完全匹配的词。除此之外,神经网络还可以通过深层的网络挖掘查询语句与文档整体语义匹配。然而大多数基于神经网络的检索模型并不能很好地解释检索结果,即只提供与查询相关的文章,而并不知道文档中哪些词或者哪些片段与查询语句有关,这还是会导致医生很难理解为什么得到这样的检索结果。此外,如果文档篇章过长,现有的神经网络不能很好地捕获文档中的语义信息,意味着不能很好地匹配文档与查询之间的语义关系。
4.文本检索可以提供病例诊断可解释性的结果,但可解释性的程度还不够,需要引入外部知识库以进一步解释检索结果。除此之外,最近比较流行的自注意模型也可以促进结果的可解释性。这种结构也可以用于解决文档过长所带来的长距离依赖的语义问题。
技术实现要素:
5.本发明的目的在于克服现有技术的缺点与不足,提出了一种基于文本检索的可解释性智慧医疗辅助诊断系统,可有效解决长文档长距离依赖的语义编码问题,以及将知识图谱很好地融入到查询词中,并通过知识图谱上和预训练的自注意力模型的权重值得到与查询词相关的实体信息或者文档片段,从而为智慧诊断提供更为精准的可解释性结果。
6.为实现上述目的,本发明所提供的技术方案为:一种基于文本检索的可解释性智慧医疗辅助诊断系统,包括:
7.查询预处理模块,用于对病人病历进行预处理,得到与患病信息相关的查询词;
8.知识图谱构建模块,用于与查询词结合形成一个新的关于特定疾病的知识图谱;
9.文本检索模块,用于通过查询词以及新的知识图谱来检索医学数据库中与查询词相关的以往的病例及治疗方案;
10.可解释的辅助诊断模块,用于解释检索出与病人病历相关的病例及治疗方案的原因。
11.进一步,所述查询预处理模块对病人病历进行的预处理包括分词、去标点符号、去停用词和拼写纠正,然后通过语法解析保留名词短语和动词短语,将其作为后续知识图谱融合的实体。
12.进一步,所述知识图谱构建模块通过从查询预处理模块中获得的名词短语和动词短语,从现有的生物医学领域知识图谱获得实体概念、语义解释和语义类型,通过知识融合,从现有的知识图谱中,抽取与查询词有关的子图,并融合形成新的特定疾病的知识图谱g,该知识图谱g定义为:
13.g={(h,r,t)|h,t∈ε,r∈r}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
14.式中,ε和r分别是集成图谱实体集合和关系集合;而三元组(h,r,t)表示这样的一条事实知识:头实体h与尾实体t之间存在着关系r。
15.进一步,所述文本检索模块包括词嵌入表示模块、图嵌入表示模块和文本匹配模块;
16.所述词嵌入表示模块利用预训练的自注意力模型来分别获得待检索病历与查询词的词嵌入表示;所述预训练的自注意力模型是一个12层的transformer的堆叠结构,其中第i层transformer的公式如(2)、(3)、(4)所示:
[0017][0018]
m
i
=ln(s
i
‑1+o
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0019][0020]
公式(2)中的q、k、v是查询词或者待检索的病历,是一个二维矩阵,分别是q、k、v的二维的权重矩阵,d
k
是的其中一维的大小,是缩放值,softmax是归一化操作,o
i
是通过词与词之间的相似度累加得到的序列向量;公式(3)中ln代表一个残差网络,s
i
‑1是第i
‑
1层的输入,在第一层指的是查询词或者待检索病历,m
i
是残差网络的输出;公式(4)是两层全连接层,其中w
1i
、是权重矩阵,是偏置,relu是激活函数,s
i
是一层transformer的输出,即新的词向量嵌入表示;
[0021]
所述图嵌入表示模块利用图注意力网络将特定疾病的知识图谱上查询词的词嵌入表示变为查询词的图嵌入表示,通过图注意力网络学习查询词在新的知识图谱的特征表示,其本质是图注意力网络通过对一个节点本身及在知识图谱上该节点的邻居给予不同的权重,学习得到一个新节点的特征表示;首先,知识图谱上所有节点的词向量嵌入表示h={h1,h2,...,h
o
},其中h
o
代表第o个节点的词向量嵌入,然后通过遮掩自注意力结构的方式将网络的关注点放在节点o的邻居节点集n
o
,其中邻居节点集包括本身,这里节点代表查询
词,具体公式如(5)所示:
[0022][0023]
式中,w、w
a
是权重矩阵,h
o
、h
j
、h
v
分别是第o、j、v个节点,leakyrelu给所有负值赋予一个非零的斜率,t是指对矩阵的转置,a
o,j
是节点o与节点j的相似度;最后通过对节点的邻居进行加权和得到节点在知识图谱上的图嵌入表示,公式如(6)所示:
[0024][0025]
式中,w
h
是权重矩阵;最后通过图注意力网络将所有的查询词嵌入转为图嵌入表示序列q=[q1,q2,...,q
o
],q
o
是第o个节点,即第o个查询词的图嵌入表示;
[0026]
所述文本匹配模块将查询词的图嵌入表示平均池化以及待查询病历的词嵌入表示卷积和最大池化后,通过余弦计算来两者的相似度,得出查询词与待查询病历的匹配分数;其中,查询词的图嵌入表示平均池化公式如(7)所示:
[0027][0028]
式中,mean
‑
pooling表示将q进行平均操作,是平均池化后的查询向量;待查询病历的卷积和最大池化公式如(8)、(9)、(10)所示
[0029][0030]
p=[p1,p2,...,p
m
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0031][0032]
其中,由词嵌入表示模块得到的待检索病历的词嵌入表示序列d={d1,d2,...,d
m
},d
m
为待检索病历中第m个词的词嵌入,d
m
‑
u:m+u
为待检索病历中的第m
‑
u到m+u的词,u是指卷积核的一半大小;公式(8)是卷积操作,b
l
是偏置,w
l
是卷积核,l为第l个卷积核,是点乘操作,p
m,l
是第l个卷积核得到的第m个标量;公式(9)是l个卷积核得到特征图p,p
m
是l个卷积核后得到的第m个向量;公式(10)max
‑
pooling是最大池化操作,对特征图的每一列取最大值,得到待检索病历向量
[0033]
所述文本匹配模块通过计算查询向量与待检索病历向量余弦值来得到两者的相似度分数score,公式如(11)所示:
[0034][0035]
进一步,所述可解释的辅助诊断模块将待检索病历与查询词匹配的分数进行排序,选取分数top s个文档,s为选取文档的个数,通过可视化图注意力网络得到知识图谱上各个路径的权重值以及预训练的自注意力模型中查询词与文档中词语的权重值,标注出知识图谱上基于知识感知的传播路径以及文档中最相关的片段作为病例诊断的可解释结果。
[0036]
本发明与现有技术相比,具有如下优点与有益效果:
[0037]
1、结合图注意力网络,通过知识图谱对查询词的表征进行建模。不同于现有技术简单地拼接拓展词,本发明根据拓展词重要性不同,将拓展词的语义信息按照不同的比例
编码进查询词的表征中,使得进行查询与文档匹配时更加精准。
[0038]
2、利用预训练的自注意力机制加上transformer结构对文档进行编码,这可以有效地解决了长文档所引起的长距离依赖的语义编码问题,同时这样的结构可以更好地匹配查询与文档之间的语义相似性。
[0039]
3、利用图注意力网络与transformer结构可以分别对知识图谱上的知识链路和查询的文档结果进行标注,得到最相关的信息片段,提供更加准确的可解释性结果。
附图说明
[0040]
图1是可解释性智慧医疗辅助诊断系统的架构图。
[0041]
图2是查询词与现有知识图谱的集成图。
[0042]
图3是预训练的自注意力模型的结构示意图。
[0043]
图4是图注意力网络的结构示意图。
具体实施方式
[0044]
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
[0045]
如图1所示,本实施例所提供的基于文本检索的可解释性智慧医疗辅助诊断系统,包括以下功能模块:
[0046]
查询预处理模块,用于对病人病历进行预处理,得到与患病信息相关的查询词;
[0047]
知识图谱构建模块,用于与查询词结合形成一个新的关于特定疾病的知识图谱;
[0048]
文本检索模块,用于通过查询词以及新的知识图谱来检索医学数据库中与查询词相关的以往的病例及治疗方案;
[0049]
可解释的辅助诊断模块,用于解释检索出与病人病历相关的病例及治疗方案的原因。
[0050]
所述查询预处理模块使用spacy工具对查询词进行预处理,分词,去标点符号,去停用词,拼写纠正,然后通过语法解析保留名词短语、动词短语等与病例诊断相关的关键词信息。
[0051]
查询词是和病人相关的信息,包括疾病名,基因名以及一些症状信息。预处理后如下所示:
[0052]
疾病:急性髓性白血病
[0053]
突变基因:arch
[0054]
症状:出现乏力,伴有高热,最高体温40度,咳嗽。
[0055]
所述知识图谱构建模块将上述预处理后的查询关键词与现有知识图谱,如umls、mesh、ncbi等,进行知识融合,然后形成一个新的关于特定疾病的知识图谱。从现有的知识图谱中,抽取与查询词有关的子图,并融合形成新的特定疾病的知识图谱g,该知识图谱g定义为:
[0056]
g={(h,r,t)|h,t∈ε,r∈r}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0057]
式中,ε和r分别是集成图谱实体集合和关系集合;而三元组(h,r,t)表示这样的一条事实知识:头实体h与尾实体t之间存在着关系r。
[0058]
具体过程使用metamap来提取每个查询词的umls概念。对于疾病方面的查询扩展可以借由lexigram工具进行知识集成,对于基因方面的查询扩展可以通过ncbi进行实体提取,这些提取的概念及其名称变体都将被用于与查询词进行知识融合,如图2所示。图2描述了急性髓性白血病的一些相关症状,突变基因,以及与之相关的其它疾病。
[0059]
所述文本检索模块包括词嵌入表示模块、图嵌入表示模块和文本匹配模块。
[0060]
所述词嵌入表示模块利用预训练的自注意力模型来分别获得待检索病历与查询词的词嵌入表示;所述预训练的自注意力模型是一个12层的transformer的堆叠结构。如图3所示,公式(2)对应图中的多头注意力机制,公式(3)对应图中的残差网络,公式(4)对应图中的两层全连接层。查询向量与文档向量分别按照格式“[cls]q[sep]”和“[cls]d[sep]”输入到transformer的公式中,
[0061][0062]
m
i
=ln(s
i
‑1+o
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0063][0064]
公式(2)中的q、k、v是查询词或者待检索的病历,是一个二维矩阵,分别是q、k、v的二维的权重矩阵,d
k
是的其中一维的大小,是缩放值,softmax是归一化操作,o
i
是通过词与词之间的相似度累加得到的序列向量;公式(3)中ln代表一个残差网络,s
i
‑1是第i
‑
1层的输入,在第一层指的是查询词或者待检索病历,m
i
是残差网络的输出;公式(4)是两层全连接层,其中w
1i
、是权重矩阵,是偏置,relu是激活函数,s
i
是一层transformer的输出,即新的词向量嵌入表示。
[0065]
输入查询词和待检索病历后分别得到h={h1,h2,...,h
n
}和d={d1,d2,...,d
m
},其中h
n
为第n个查询词的词嵌入,d
m
为待检索病历中第m个词的词嵌入。
[0066]
所述图嵌入表示模块利用图注意力网络将特定疾病的知识图谱上查询词的词嵌入表示变为查询词的图嵌入表示。通过图注意力网络学习查询词在新的知识图谱的特征表示,其本质是图注意网络通过对一个节点本身及在知识图谱上该节点的邻居给予不同的权重,学习得到一个新节点的特征表示。首先知识图谱上节点的词向量嵌入表示:h={h1,h2,...,h
o
},其中h
o
代表第o个节点的词向量嵌入。然后通过遮掩自注意力机制的方式将网络的关注点放在节点o的邻居节点集n
o
(邻居节点集包括本身),这里节点指查询词。图注意力网络结构如图4所示,节点o与节点j的相似度计算,具体公式如(5)所示:
[0067][0068]
式中,w、w
a
是权重矩阵,h
o
,h
j
,h
t
分别是第o,j,v个节点。leakyrelu给所有负值赋予一个非零的斜率,t是指对矩阵的转置,a
o,j
是节点o与节点j的相似度;最后通过对节点的邻居进行加权和得到节点在知识图谱上的图嵌入表示,公式如(6)所示:
[0069][0070]
式中,w
h
是权重矩阵,relu属于激活函数;最后通过图注意力网络将所有的查询词嵌入转为图嵌入表示序列q=[q1,q2,...,q
o
],q
o
是第o个节点,即第o个查询词的图嵌入表示。
[0071]
所述文本匹配模块将查询词的图嵌入表示平均池化以及待查询病历的词嵌入表示卷积和最大池化后,通过余弦计算来两者的相似度,得出查询词与待查询病历的匹配分数。其中,查询词的图嵌入表示平均池化公式如(7)所示:
[0072][0073]
式中,mean
‑
pooling表示将q进行平均操作,是平均池化后的查询向量;待查询病历的卷积和最大池化公式如(8),(9),(10)所示
[0074][0075]
p=[p1,p2,...,p
m
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0076][0077]
其中,由词嵌入表示模块得到的待检索病历的词嵌入表示序列d={d1,d2,...,d
m
},d
m
为待检索病历中第m个词,d
m
‑
u:m+u
为待检索病历中的第m
‑
u到m+u的词,u是指卷积核的一半大小;公式(8)是卷积操作,b
l
是偏置,w
r,l
是卷积核,l为第l个卷积核,relu为激活函数,是点乘操作,p
m,l
是第l个卷积核得到的第m个标量;公式(9)是l个卷积核得到特征图p,p
m
是l个卷积核后得到的第m个向量;公式(10)max
‑
pooling是最大池化操作,对特征图的每一列取最大值,得到待检索病历向量
[0078]
所述文本匹配模块通过计算查询向量与待检索病历向量余弦值来得到两者的相似度分数score。公式如(11)所示:
[0079][0080]
所述可解释的辅助诊断模块将待检索病历与查询词匹配的分数进行排序,选取top s个文档,s为选取文档的个数,通过可视化图注意力网络得到知识图谱上各个路径的权重值,标注出知识图谱上基于知识感知的传播路径,如图2所示,图注意力网络可以自适应地为知识图谱中各个连接路径分配不同的注意力权重得分a1,a1,...a
11
。每个查询词周围邻居的权重值越大,则表明越重要,即与检索的结果更相关。也可通过预训练的自注意力模型中查询词与文档中词语的权重值以及文档中最相关的片段作为智慧病例诊断的可解释结果,如图1中可解释结果中的加粗字段所示。
[0081]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1