一种无创血糖预测方法及装置与流程
本发明涉及医疗器械技术领域,特别是涉及一种无创血糖预测方法及装置。
背景技术:
无创血糖检测技术,能够帮助使用者连续、无痛苦、无感染隐患地检测血糖水平,具有重要的医学价值和经济价值,多年来始终是研究热点。其中光学传感器检测方案,因使用便捷,成本相对低廉等优势受到研究者较多关注。光电容积波(photoplethysmograph,ppg)传感器,是通过光电手段检测活体组织中血液容积变化的传感器。该传感器信号交变部分能够反映动脉血液的成份信息,同时信号波形细节能反映血粘稠度、心率变异性、血管壁状态等血液动力学信息,这些信息又与血糖水平具有相关性。因此ppg传感器较适合作为无创血糖仪的信号检测部件。近期一些无创血糖仪研发团队利用ppg传感器取得了较理想的研究进展。例如韩国釜庆大学的研究结果,在12名志愿者的实验中,血糖浓度预测相关系数平均值达到0.86,预测标准差达到6.16mg/dl。又如以色列spectrophon公司的无创血糖仪,在200名成人参与的实验中,血糖浓度预测相关系数平均值,餐前为0.8994,餐后为0.9382,平均百分比误差为7.40-7.54%。上述结果表明,ppg传感器具有实现实用化无创血糖仪的硬件潜力。
然而,无创血糖检测通常面临着一个主要技术瓶颈,即不同检测对象体质的多样性会导致检测信号与血糖水平的对应关系复杂化;同时对于相同个体,由于身体状况可能发生变化,同样使得原有模型无法长期适用。这一问题的直接结果是影响无创血糖仪的检测精度,无法通过行业标准;或者使得已通过标准验证实验的血糖仪在大范围临床应用中精确性严重下降,造成市场化失败,例如以色列integrityapplication公司的glucotrack(糖无忌)、美国的手表式血糖仪glucowatch等。无创血糖仪通常没有精确的解析模型可以依赖,而是采用机器学习技术建立检测信号与血糖水平间的预测模型。这种情况下,为增加血糖仪的检测精度以及通用性,制备大量的有标定样本,用以训练预测模型,显然无法避免。尽管一些研究者提出了各种削弱个体差异影响的方法,如动态光谱法、粒度计算方法等,但从统计学原理出发,训练样本集的充足程度仍是模型泛化能力的基本限制条件。一个有代表性的研究成果为北京大学研究团队近期公布的earlight无创血糖仪原型机,其训练集为来自89位志愿者的4012个ppg-血糖样本,研究者指出这样的样本集规模是他们检索范围内,光学无创血糖仪中规模最大的。大规模训练集使得他们的模型具有更强的泛化能力,同时也使得模型性能测试更加严苛并且更加贴近实际临床应用。虽然该团队采用模糊粒度计算方法降低了个体差异的影响程度,但模型预测精度仍未能满足血糖仪行业标准。研究者指出,受样本数量限制,无法进一步增加粒度分类器精细程度以提高模型性能,并猜测更大样本集能使性能进一步提升。
然而现阶段没有ppg-血糖标定样本集的共享资源,此类样本涉及到有创人体检测,经济、时间、伦理审批等因素明显限制样本集的规模扩充,使得样本的成本激增。如前所述的北大团队,在与大型医疗机构合作的前提下,仍用时一个半月才收集到89人的超过4000个样本。而为克服个体差异影响,需要收集尽可能多不同个体的样本,而不是总人数较少但来自同一人的样本较多的情况,这无疑进一步增加了收集成本。
技术实现要素:
本发明所要解决的技术问题是提供一种无创血糖预测方法及装置,能够降低数据集收集过程的经济和时间成本。
本发明解决其技术问题所采用的技术方案是:提供一种无创血糖预测方法,包括以下步骤:
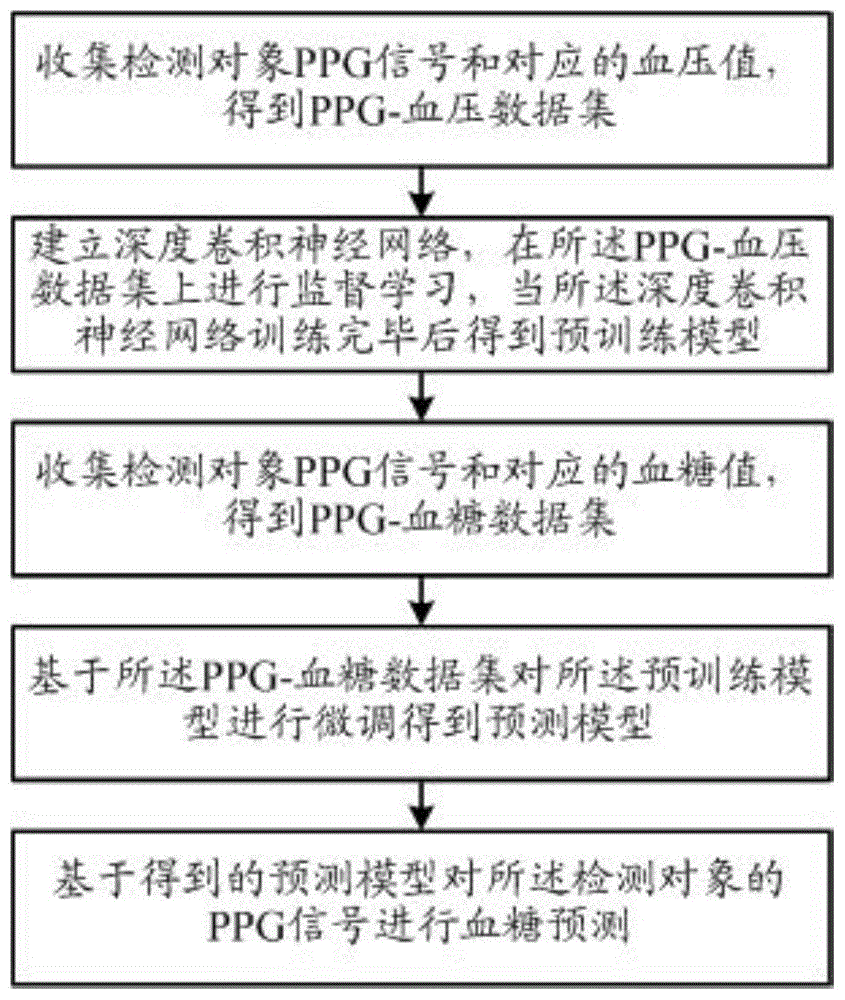
(1)收集检测对象ppg信号和对应的血压值,得到ppg-血压数据集;
(2)建立深度卷积神经网络,在所述ppg-血压数据集上进行监督学习,当所述深度卷积神经网络训练完毕后得到预训练模型;
(3)收集检测对象ppg信号和对应的血糖值,得到ppg-血糖数据集;
(4)基于所述ppg-血糖数据集对所述预训练模型进行微调得到预测模型;
(5)基于得到的预测模型对所述检测对象的ppg信号进行血糖预测。
所述步骤(2)中建立的深度卷积神经网络为一维卷积神经网络,所述一维卷积神经网络包括三组卷积层部分,每组卷积层部分包括两个卷积层和一个最大池化层,所述一维卷积神经网络的输出部分包括两个全连接层。
所述步骤(4)中基于所述ppg-血糖数据集对所述预训练模型进行微调是指:保留所述预训练模型的卷积层,冻结保留的卷积层的参数,通过重新设计全连接层或增加新的卷积层的方式调整所述预训练模型,并采用所述ppg-血糖数据集对调整后的所述预测模型进行训练。
所述步骤(4)和步骤(5)之间还包括解除保留卷积层参数的冻结状态,采用所述ppg-血糖数据集对所述预测模型进行进一步训练得到最终预测模型的步骤。
所述进一步训练时通过逐层设置不同的学习率的方式来优化网络性能。
本发明解决其技术问题所采用的技术方案是:还提供一种无创血糖预测装置,包括:第一收集模块,用于收集检测对象ppg信号和对应的血压值,得到ppg-血压数据集;第一建模模块,用于建立深度卷积神经网络,在所述ppg-血压数据集上进行监督学习,当所述深度卷积神经网络训练完毕后得到预训练模型;第二收集模块,用于收集检测对象ppg信号和对应的血糖值,得到ppg-血糖数据集;第二建模模块,用于基于所述ppg-血糖数据集对所述预训练模型进行微调得到预测模型;预测模块,用于基于得到的预测模型对所述检测对象的ppg信号进行血糖预测。
所述第一建模模块建立的深度卷积神经网络为一维卷积神经网络,所述一维卷积神经网络包括三组卷积层部分,每组卷积层部分包括两个卷积层和一个最大池化层,所述一维卷积神经网络的输出部分包括两个全连接层。
所述第二建模模块在基于所述ppg-血糖数据集对所述预训练模型进行微调是指:保留所述预训练模型的卷积层,冻结保留的卷积层的参数,通过重新设计全连接层或增加新的卷积层的方式调整所述预训练模型,并采用所述ppg-血糖数据集对调整后的所述预测模型进行训练。
所述第二建模模块和预测模块之间还包括第三建模模块,所述第三建模模块用于解除保留卷积层参数的冻结状态,采用所述ppg-血糖数据集对所述预测模型进行进一步训练得到最终预测模型。
所述第三建模模块在进一步训练时通过逐层设置不同的学习率来优化网络性能。
有益效果
由于采用了上述的技术方案,本发明与现有技术相比,具有以下的优点和积极效果:本发明以ppg信号的血压标定样本集为源域,将训练获得的知识表征学习结果,迁移至ppg信号与血糖标定值的目标域,以此获得降低数据集收集过程的经济和时间成本的效果。
附图说明
图1是本发明第一实施方式的流程图;
图2是本发明第二实施方式的结构图;
图3是本发明对比实验中使用传统方法在数据集上的预测结果散点图;
图4是本发明对比实验中使用发明方法在数据集上的预测结果散点图;
图5是使用发明方法得到的预测模型十折交叉检验克拉克误差网格图。
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
本发明的第一实施方式涉及一种无创血糖预测方法,如图1所示,包括以下步骤:
(1)收集检测对象ppg信号和对应的血压值,得到ppg-血压数据集;值得一提的是,本步骤中的样本来源可以为公共数据集(例如mimic数据库),也可以是专门收集工作的成果。
样本中的ppg信号是连续的时间片,信号长度为3000个采样点。例如当采样频率为125赫兹时,时间片长度为24秒;采样频率为100赫兹时,时间片长度为30秒。作为目标值的血压值可以来自有创动脉压(abp)或临床中普遍应用的高精度无创血压检测仪器,只是在整个数据集中目标值的来源需要一致,不能混杂。这是因为ppg-血压数据集中目标值的作用为通过监督学习完成预训练网络中各卷积层的训练,进而通过迁移学习过程传递给ppg-血糖模型,并充当该模型中的特征提取部分。因此目标值并不局限于有创或无创检测获得方式(通常检测对象的有创动脉压数值不同于无创血压数值),只要是有意义的实际血压数值,就能在有监督表示学习过程中,驱使预训练网络中各卷积层的滤波器收敛到有效提取ppg信号特征的取值。其中有创动脉压为时间片内的连续信号,因此可提取一个时间片内的极大值和极小值,并滤除粗大误差后取众数作为收缩压和舒张压。确定目标值获取方式后,取舒张压为最终的ppg-血压目标值。
(2)建立深度卷积神经网络,在所述ppg-血压数据集上进行监督学习。即不经过人为的特征工程,在监督学习过程中,直接对输入ppg信号进行特征提取和输出拟合。本步骤中采用的深度卷积神经网络可以为一维深度卷积神经网络,主要由一维卷积层和全连接层构成,在卷积层后适当搭配最大池化层进行下采样,池化层数量、尺寸和位置由具体问题中实验调整确定。所有卷积层的激活函数为线性整流函数(relu),全连接层最后一层无激活函数,其余层也采用relu激活函数。选用adam优化器,初始学习率设定为:lr=0.0001。损失函数为均方误差(mse)函数。选择平均绝对误差(mae)和决定系数两个指标作为训练过程的度量函数,优先确保mae处于最佳值的前提下,选择决定系数最高的超参数配置。当所述深度卷积神经网络训练完毕后得到预训练模型。
(3)收集检测对象ppg信号和对应的血糖值,得到ppg-血糖数据集;本步骤中的样本来自专门的收集工作。其中ppg信号是连续时间片,信号长度为3000个采样点。血糖目标值来自临床中普遍应用的高精度血糖检测设备。
(4)基于所述ppg-血糖数据集对所述预训练模型进行微调得到预测模型。具体地说,在对所述预训练模型进行微调时,可以保留预训练模型的卷积层,重新设计其全连接层,或视具体情况保留预训练网络的全部层的情况下,添加新的卷积层,或添加新的卷积层并重新设计全连接层。重新设计的各层除最后输出的全连接层外,均采用relu激活函数,最后输出层无激活函数。进而冻结预训练模型保留的卷积层参数,冻结卷积层参数是为了避免训练初始阶段损失函数过大,从而破坏了预训练模型中已经生成的特征提取滤波器参数。用ppg-血糖数据集,对重新设计的网络进行训练。选用adam优化器,初始学习率设定为:lr=0.0001。损失函数为均方误差(mse)函数。选择平均绝对误差(mae)和决定系数两个指标作为训练过程的度量函数,优先确保mae处于最佳值的前提下,选择决定系数最高的超参数配置。训练完成后,可作为ppg-血糖函数关系的预测模型,并进一步在测试集上计算平均百分比误差(mape),评估预测模型是否符合血糖仪行业标准。
(5)基于得到的预测模型对所述检测对象的ppg信号进行预测。
值得一提的是,本实施方式中如有进一步优化网络性能的需求,可以在步骤(4)训练完成后,解除保留卷积层参数的冻结状态,使用新的ppg-血糖数据或者原数据集,以上一步训练生成的各层权参数为初始值,进一步训练模型。这是因为在上一步训练后,模型具备了一定的拟合精度,继续训练过程不至于完全破坏已经生成的参数,而是能够进一步将各参数向优化网络性能的方向调整。在继续训练阶段,可考虑逐层设置不同的学习率以达到优化目的。
本发明的第二实施方式涉及一种无创血糖预测装置,如图2所示,包括:第一收集模块,用于收集检测对象ppg信号和对应的血压值,得到ppg-血压数据集;第一建模模块,用于建立深度卷积神经网络,在所述ppg-血压数据集上进行监督学习,当所述深度卷积神经网络训练完毕后得到预训练模型;第二收集模块,用于收集检测对象ppg信号和对应的血糖值,得到ppg-血糖数据集;第二建模模块,用于基于所述ppg-血糖数据集对所述预训练模型进行微调得到预测模型;预测模块,用于基于得到的预测模型对所述检测对象的ppg信号进行预测。
所述第一建模模块建立的深度卷积神经网络为一维卷积神经网络,所述一维卷积神经网络包括三组卷积层部分,每组卷积层部分包括两个卷积层和一个最大池化层,所述一维卷积神经网络的输出部分包括两个全连接层。
所述第二建模模块在基于所述ppg-血糖数据集对所述预训练模型进行微调是指:保留所述预训练模型的卷积层,冻结保留的卷积层的参数,通过重新设计全连接层或增加新的卷积层的方式调整所述预训练模型,并采用所述ppg-血糖数据集对调整后的所述预测模型进行训练。
所述第二建模模块和预测模块之间还包括第三建模模块,所述第三建模模块用于解除保留卷积层参数的冻结状态,采用所述ppg-血糖数据集对所述预测模型进行进一步训练得到最终预测模型。所述第三建模模块在进一步训练时通过逐层设置不同的学习率来优化网络性能。
下面通过一个对比实验进一步说明本发明。
为验证本发明的优越性,设计了小样本学习(few-shotlearning)实验,目的为观察在相同神经网络架构下,利用本发明的方法能否明显优化ppg-血糖预测模型的建模过程。具体步骤如下:
一.训练小样本ppg-血糖预测模型:
首先使用max30101集成传感器收集检测对象ppg信号,并使用强生稳豪便携式血糖仪采样对应的血糖值。参与者为三名成年男性,对实验过程事先完全知情,并同意参与实验,以及授权使用所收集的数据。收集样本数为65个,每个样本包括30秒ppg波形,由于传感器采样频率为100赫兹,所以总共3000个采样点。每个样本通道数为3,对应红光、近红外和绿光,因此所生成的ppg数据集为一个65×3000×3的张量,并有一个65维的向量存储血糖目标值。
使用python语言在keras框架下搭建和训练神经网络。所设计的网络为一维深度卷积网络,架构包括三组卷积层部分,每组卷积层部分由两个卷积层构成,并有一个最大池化层进行下采样。输出部分包括两个全连接层。各层参数如下:
第一层:为卷积层,通道数为3。滤波器个数为32,尺寸为15。激活函数为relu函数。
第二层:为卷积层,滤波器个数为32,尺寸为15。激活函数为relu函数。
第三层:为最大池化层,尺寸为3。
第四层:为卷积层,滤波器个数为32,尺寸为15。激活函数为relu函数。
第五层:为卷积层,滤波器个数为32,尺寸为15。激活函数为relu函数。
第六层:为最大池化层,尺寸为3。
第七层:为卷积层,滤波器个数为64,尺寸为15。激活函数为relu函数。
第八层:为卷积层,滤波器个数为64,尺寸为15。激活函数为relu函数。
第九层:为最大池化层,尺寸为3。
第十层:为全连接层,神经元个数为70。激活函数为relu函数。
第十一层:为全连接层,神经元个数为1。
将数据集按8:2比例划分为训练集和测试集。对该网络训练30轮,损失函数不再下降,重复训练过程若干次,并以不同的度量函数评价训练效果,涉及到的度量函数包括平均绝对误差(mae)、平均百分比误差(mape)、决定系数。由于多次训练,验证集上决定系数平均值为0.012,这说明网络很可能是在近似拟合目标值平均值,没有正确拟合函数关系。用网络模型对整个ppg-血糖数据集进行预测,预测值散点图如图3所示。
由图中结果可见,深度神经网络将ppg-血糖全数据集65个点映射为目标值的平均值,显然不是在拟合检测信号与血糖水平之间的关系。对深度卷积网络进行调整,尝试修正上述问题,包括添加或删减卷积层及全连接层、调整各卷积层滤波器数量和全连接层神经元数量、添加正则化手段、调换优化器、调整学习率、改变训练轮次(epoch)和样本批量(batch-size)、放大或删除数值性质较差的绿光通道等方法均无法使网络正常工作。上述结果表明,妨碍神经网络正常工作的可能原因主要有以下两点:
①光电容积波信号(ppg)与血糖水平之间没有直接的相关性,从而不适合作为血糖检测信号。
②ppg信号虽然能作为检测信号,但实验中的样本数过少,且含有基线漂移和运动噪声等干扰成份,使得网络无法提取出充分的特征,完成回归过程。
原因①与现有众多文献结论不符,因此初步判断为原因②,并在后续实验过程中进一步验证。
二、迁移学习血糖模型:
1.建立ppg-血压预训练网络
首先访问mimic-ⅲ波形数据库,从中提取同时含有光电容积波信号(pleth)和动脉血压信号(abp)的用户记录,时长24秒,共3000个数据点。总人数30人,总样本数为322个。提取abp信号极小值,滤除粗大误差后,取众数(mode)为舒张压数值。mimic-ⅲ数据库pleth信号为单通道,因此数据集为一个322×3000×1的张量,并有一个322维的向量存储血压目标值。
在相同框架下搭建深度卷积神经网络,包含3组卷积层,每组两个卷积层,以及一个最大池化层下采样。两个全连接层做输出拟合。
数据集随机划分为训练集和测试集,比例为8:2,训练轮次为150轮。以不同度量函数在测试集上评估网络,多次重复训练,平均绝对误差(mae)最佳情况为7.13mm汞柱;决定系数最佳情况为0.83。选取决定系数最高的训练结果保存模型,作为ppg-血压预训练网络。
2.验证血糖模型失效原因
从上述322个样本中随机选取65个,组成一个与血糖样本集数量相当的子集,用来训练相同架构的神经网络,结果出现了与血糖拟合过程类似的情况,即网络不再拟合ppg信号与血压间的函数关系,而是始终输出目标血压值的平均值。这进一步说明血糖建模过程失败是由于样本数量不充分造成的。
3.微调(fine-tune)预训练网络
将预训练网络最后二个全连接层取代为ppg-血糖模型的两个全连接层,如此情况下,各层参数如下:
第一层:为卷积层,通道数为1。滤波器个数为32,尺寸为15。激活函数为relu函数。
第二层:为卷积层,滤波器个数为32,尺寸为15。激活函数为relu函数。
第三层:为最大池化层,尺寸为3。
第四层:为卷积层,滤波器个数为32,尺寸为15。激活函数为relu函数。
第五层:为卷积层,滤波器个数为32,尺寸为15。激活函数为relu函数。
第六层:为最大池化层,尺寸为3。
第七层:为卷积层,滤波器个数为64,尺寸为15。激活函数为relu函数。
第八层:为卷积层,滤波器个数为64,尺寸为15。激活函数为relu函数。
第九层:为最大池化层,尺寸为3。
第十层:为全连接层,神经元个数为70。激活函数为relu函数。
第十一层:为全连接层,神经元个数为1。
这样可以不改变预训练网络架构,仅冻结卷积层权值,利用ppg-血糖数据集训练网络(实际是训练两个全连接层),取红光和近红外通道数值相加作为网络输入,65个样本随机按8:2比例分为训练集和测试集,训练轮次为30。分别以决定系数和平均绝对百分比误差(mape)作为度量函数。决定系数值达到了0.76(无迁移学习过程时近似为0),mape值为12.22%。保存模型,并对整个ppg-血糖数据集进行预测,结果如图4所示。
可见模型克服了预测输出收敛到目标平均值现象,网络为正常拟合状态。为进一步观察模型性能,在ppg-血糖数据集上进行十折交叉检验,将各次检验的预测结果全部绘制于克拉克误差网格图内,如图5所示。图中位于a区域的点占78.5%,b区域点为21.5%,其它区域没有分布。上述结果说明,利用公共数据集训练获得的卷积滤波器参数,能有效提取实际ppg信号特征,且通过该特征集合能拟合出ppg-血糖水平间的函数关系。利用迁移学习技术优化的预测模型,已经具有一定精确性。随着源域和目标域的样本集进一步扩充,精确性和可靠性有望进一步提高。
综上所述利用ppg-血压数据集,通过深度迁移学习技术可以有效优化ppg信号与血糖值之间的建模过程,减少基于ppg信号的光学无创血糖仪研发成本和研发周期。
- 还没有人留言评论。精彩留言会获得点赞!