分布式列子集选择方法、系统及白血病基因信息挖掘方法
本发明属于大数据处理领域,具体涉及一种分布式列子集选择方法、系统及白血病基因信息挖掘方法。
背景技术:
随着物联网,机器学习,计算机视觉和自然语言处理等新兴计算机应用的涌现,人们经常会遇到具有海量样本数和特征数的高维数据。处理这些高维数据,需要更多的计算和存储资源,往往无法使用单机进行处理,而且这些数据中的大部分特征可能是无用和多余的。因此,从高维数据中选择具有代表性的特征并服务于计算机应用,就成为了亟待解决的问题。因此,作为一种能有效地从原始特征集中选择代表性特征的方法,特征选择技术成为了近年来研究的重点。同时,挖掘白血病人基因信息,得到基因特征和白血病关联性是治疗白血病的重要途径。然而,由于基因序列的规模巨大和结构复杂,含有海量冗杂的特征信息,传统的单机版特征选择算法无法有效挖掘蕴含着基因中的有效信息。
列子集选择(columnsubsetselection,css)问题是特征选择研究中的核心子问题,也是一个约束低秩近似问题。具体来讲,css旨在从矩阵a中找到一个含最多k个列(即特征)子矩阵s,使得子矩阵s尽可能多的包含矩阵a中的信息。研究中,一般使用重建错误率来衡量这种包含能力,特征与列是等价的。
不同于其他低秩近似问题,例如svd、pca等,css更加灵活,解释性更强,计算效率更高。然而,目前已有的针对css问题的求解算法,其实践性均不强,也不适应于大规模数据集。例如,在2019年,冯等人提出了pocss算法,取得了目前已知的最低重建错误率;然而,这种算法需要大量的迭代,非常耗时。再者,随着数据体积的爆炸式增长,研究分布式css算法变得尤为重要。
已有的分布式css算法属于两阶段的算法。具体来讲,在分布式算法中,目标变为从m个特征子集中选择出k个特征(m≥2),特征子集由原数据集划分得到;根据分布式两阶段css算法,在第一阶段中,根据算法从每个特征子集中选择出k个特征,然后在第二阶段中使用相同的算法从m*k个特征中选择k个特征作为最后的输出结果。
这种两阶段的分布式css算法有如下三个缺点:
1)由于划分后每个子集所含代表性特征数目不同,比如有的子集所包含的特征大部分都是冗余特征,从这些子集中选择到的特征可能对下一阶段的特征选择有不利影响,所以每个子集并不都值得从中选择k个特征;
2)对于数据集中k个最具代表性的特征(最优特征)会被划分到不同子集,每个子集含有的最优特征数必小于等于k,所以从每个子集中选择k个特征是多余的;
3)两阶段算法理论上达不到线性加速,所以在实践中这种算法计算非常耗时,实用性不强。
此外,两阶段算法假设所有子集具有相同的质量,这是造成以上不足的主要原因。实际上,子集之间的质量往往是不同的,忽略这种不同会导致时间和资源的浪费,甚至影响最后的特征选择的结果。因此,目前的面向列子集选择的分布式特征选择方法,依旧存在精确性不高、计算速度较慢和可靠性较差的问题。
技术实现要素:
本发明的目的之一在于提供一种分布式列子集选择方法,该方法通过在分布式特征选择框架中融入子集质量评估方法,避免了子集中选择到冗余特征,加速了特征选择,而且可扩展性好,计算速度较快,可靠性更好。
本发明的目的之二在于提供一种基于所述的分布式列子集选择方法的系统。
本发明的目的之三在于提供一种基于上述的分布式列子集选择方法和系统的白血病基因信息挖掘方法。
本发明公开的这种分布式列子集选择方法,包括如下步骤:
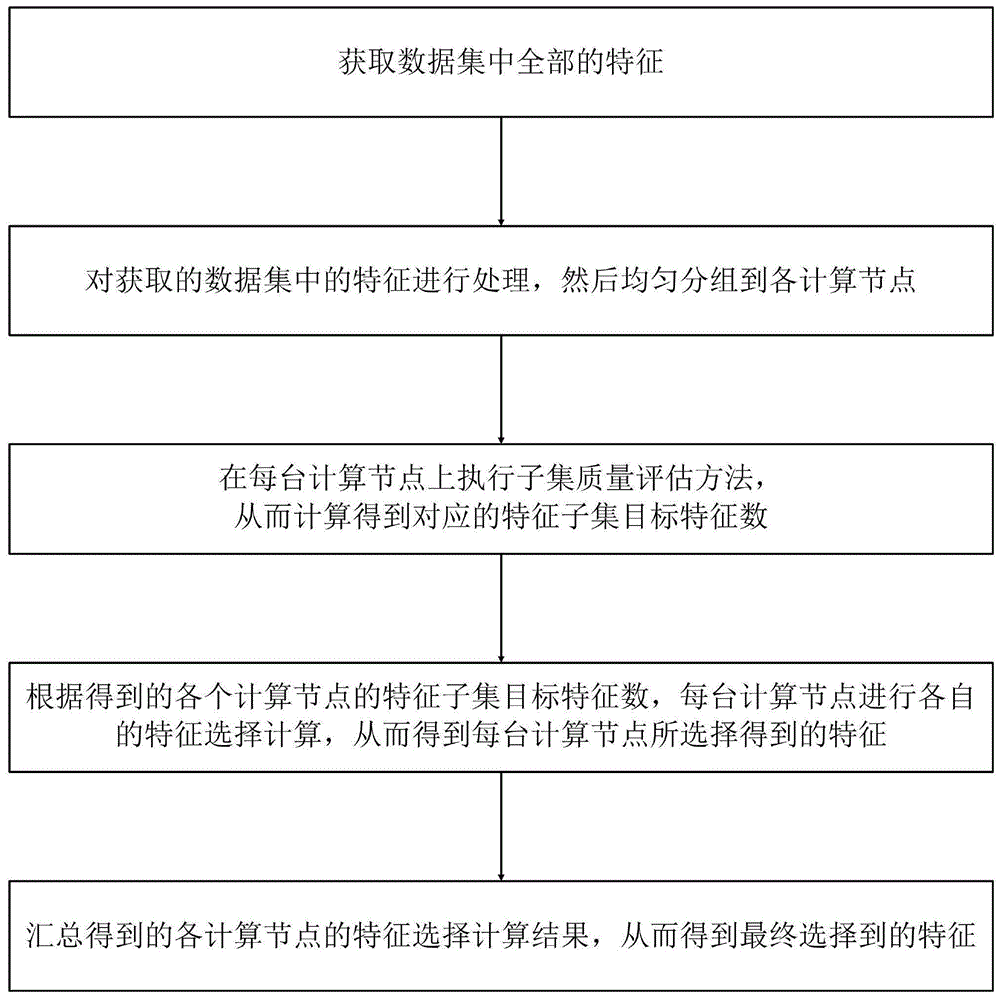
s1.获取数据集中全部的特征;
s2.对步骤s1获取的数据集中的特征进行处理,然后均匀分组到各计算节点;
s3.在每台计算节点上执行子集质量评估方法,从而计算得到对应的特征子集目标特征数;
s4.根据步骤s3得到的各个计算节点的特征子集目标特征数,每台计算节点进行各自的特征选择计算,从而得到每台计算节点所选择得到的特征;
s5.汇总步骤s4得到的各计算节点的特征选择计算结果,从而得到最终选择到的特征。
步骤s2包括:首先将数据集中数据转化为一个由特征和特征取值组成的二维矩阵,然后将特征取值全为空以及特征取值方差为0的特征删除,接着利用l2范数对剩余特征进行归一化处理,最后根据集群中的计算节点数量建立分组标签,为每一个特征随机分配标签,从而将每一个特征随机划分到不同的计算节点的特征子集。
对每个特征f的l2范数归一化的计算公式如下:
其中,fv1,fv2,…,fvn是特征f可能取得的特征值;||f||2表示特征f的l2范数。
步骤s3所述的子集质量评估方法,具体为使用信息熵衡量特征子集vi的子集质量sqi;特征信息熵h(f)用于衡量一个特征f所蕴含信息量的大小,信息熵h(f)越高表示该特征f蕴含的信息量越大,定义特征集合熵:
其中,ni为特征子集vi所含特征数目,fvt是特征fj所有可能取得的特征值,p(fvt)=pr(fj=fvt)是概率质量函数;子集质量sqi的值越大,表示特征子集vi含有的信息量越大,越多的最优特征分布在特征子集vi中,因此特征数目ki越大。
步骤s4所述的根据步骤s3得到的各个计算节点的特征子集目标特征数,每台计算节点进行各自的特征选择计算,具体为,质量越高,特征数目ki越大;为了保证质量更高的特征子集vi能分配到更大的特征数目ki,将各子集的子集质量sqi降序排列,计算降序排列的前m-1个子集的特征数目ki,m为集群中计算节点的数量;
其中,1≤i≤m-1,[·]表示向上取整,k为目标特征总数;
得到前m-1个子集的特征数目ki后,降序排列的最后一个子集的特征数目ki,记为
步骤s4所述的每台计算节点进行各自的特征选择计算,具体每台计算节点采用pocss算法进行各自的特征选择计算。
本发明还公开了一种基于上述分布式列子集选择方法的系统,包括获取模块、预处理模块、评估模块、选择模块和输出模块;获取模块、预处理模块、评估模块、选择模块和输出模块依次串联;获取模块用于获取数据集中全部的特征;预处理模块用于预处理原始数据集,并负责特征的清洗和归一化处理,根据集群中计算节点数量为处理后的特征集均匀随机分配分组标签,并为下一模块的计算做输入准备;评估模块用于为各特征子集进行子集质量评估,根据各子集质量为该子集找到目标特征数目;选择模块用于根据特征子集以及目标特征数目,采用pocss算法在各计算节点上计算,然后汇总各节点的计算结果得到最终选择到的特征;输出模块用于输出特征选择结果。
本发明还公开了一种基于上述分布式列子集选择方法和系统的白血病基因信息挖掘方法,包括如下步骤:
b1.给定一个总特征选择数目k;
b2.通过获取模块将基因数据集读入并转化为一个由样本和特征组成的二维矩阵a=(样本数量,特征数量);
b3.通过预处理模块将步骤b2得到矩阵进行特征清洗和归一化处理;
b4.将步骤b3清理后数据根据集群中节点数量,形成基因子集vi分发到各个节点;
b5.通过评估模块,各节点利用子集质量评估算法计算所分配基因子集的质量sqi;
b6.根据各子集的质量和总目标特征数计算出每个子集应选的特征数ki;
b7.根据ki执行pocss算法,在每个基因子集中选择出ki个特征;
b8.汇总各节点的选择结果,从而得到最终k个与白血病最具相关性的基因表达。
本发明提供的这种分布式列子集选择方法、系统及白血病基因信息挖掘方法,在分布式特征选择框架中融入子集质量评估方法,有效避免了在子集中选择到冗余特征,同时也加速了特征选择过程;再者,直接汇总各计算节点选择出的特征作为最终选择结果,使得在理论上该方法至少能达到线性加速;最后,本发明避免了子集中选择到冗余特征,加速了特征选择,而且可扩展性好,计算速度较快,可靠性更好,可以快速挖掘白血病基因信息的基因特征和白血病关联性。
附图说明
图1为本发明方法的流程示意图。
图2为本发明系统的结构示意图。
具体实施方式
两阶段算法假设所有子集具有相同的质量,是造成现有技术不足的主要原因。然而,实际上子集之间的质量往往是不同的,忽略这种不同会导致时间和资源的浪费,甚至影响最后特征选择的结果。在本申请中,用子集中含最优特征的数量来衡量子集质量的高低。具体来讲,对一数据集中一定存在着k个最具代表性的特征,称之为k个最优特征,定义一个子集所含最优特征数越多,该子集质量越高。对于css问题,定义最优解sopt为一个包含k个最优特征的集合,此k个特征的组合是全部特征组合中拟合原数据集能力最强的特征组合。
如图1为本发明方法的流程示意图:本发明提供的这种分布式列子集选择方法,包括如下步骤:
s1.获取数据集中全部的特征;
s2.对步骤s1获取的数据集中的特征进行处理,然后均匀分组到各计算节点;
在本实施例中,数据集从加州大学欧文分校提供的uci数据库中获取,该数据库包含了特征数目和样本数目规模不同的数据集。本步骤首先将数据集中数据转化为一个由特征和特征取值组成的二维矩阵,然后将特征取值全为空和取值方差为0的特征删除,接着利用l2范数对剩余特征进行归一化处理,最后根据集群中的计算节点数量建立分组标签,为每一个特征随机分配标签。
对每个特征f的l2范数归一化的计算公式如下:
其中,fv1,fv2,…,fvn是特征f可取得的特征值;||f||2表示特征f的l2范数。
上述步骤包括一种面向css问题分布式的特征选择框架,具体包括如下步骤:
a1.创建并初始化分布式软硬件运行环境,并预先加载该特征选择框架所依赖的资源,为框架的运行做好准备;
a2.获取步骤s1中的带分组标签的全部特征,按照分组标签对特征进行分组形成特征子集vi,其中1≤i≤m,m为集群中计算节点的数量,并将分组分发给对应计算节点;
a3.在每台计算节点上对步骤a2得到的特征子集vi运行子集质量评估方法,得到特征子集vi的子集质量sqi;
具体包括使用信息熵衡量特征子集vi的子集质量sqi,特征信息熵h(f)用于衡量一个特征f所蕴含信息量的大小,信息熵h(f)越高表示该特征f蕴含的信息量越大,定义特征集合熵:
其中,ni为特征子集vi所含特征数目,fvt是特征fj所有可取得的特征值,p(fvt)=pr(fj=fvt)是概率质量函数;子集质量sqi的值越大,表示特征子集vi含有的信息量越大,越多的最优特征分布在特征子集vi中,因此ki越大。
本步骤的优点在于两个方面,首先基于信息熵的子集质量评估方法计算效率高,是一种快速的评估方法;其次,该子集质量评估指标是灵活可插拔的,可以根据用户和应用的不同偏好来选择子集质量评估指标。
a4.汇总各计算节点分配到的特征子集的子集质量sqi,根据目标特征数目k,按照各特征子集vi的质量确定在该子集中应选的特征数目ki,并分发给对应计算节点;
按照各特征子集vi的质量确定在该子集中应选的特征数目ki,具体为,质量越高,特征数目ki越大;为了质量高的特征子集vi能分配到更大的特征数目ki,将各子集的子集质量sqi降序排列,计算降序排列的前m-1个子集的特征数目ki,m为集群中计算节点的数量;
其中,1≤i≤m-1,[·]表示向上取整;
得到前m-1个子集的特征数目ki后,降序排列的最后一个子集的特征数目ki,记为
本步骤的优点在于,由于在步骤s2中对特征进行随机分配分组标签,那么sopt所含最优特征会分散到各个子集中,也即ki往往小于k,所以相较两阶段的css算法从每个子集中选择k个特征,本发明方法仅需选择ki个特征,有效地缩短了算法的运行时间。
a5.各计算节点根据步骤a4中得到的特征数目ki,在本节点的特征子集vi上运行单机版css算法选择出ki个特征,组成一个特征集合si;
单机版css算法具体采用pocss算法,pocss算法是一种利用帕累托优化的思想来解决css问题的算法,pocss算法需要2ek2n次迭代得到的解s有保证,有保证为2ek2n次迭代得到的解s能优于一个下界(1-e-γ)·opt,这个下界是目前已知的最高下界,其中e为欧拉数,e≈2.71828;k为要选择的特征数目;n为数据集中特征总数,opt是指最优解的函数值,即f(sopt);γ为子模率;pocss算法相较目前其他css算法取得了最低的重建错误率。
本步骤的目的在于,通过子集质量评估方法为特征子集vi找到一个合理的目标特征数ki。现有技术中的分布式特征选择算法会直接从特征子集vi中选择k个特征,然而实际上每个特征子集vi中仅包含sopt中一部分最优特征。如果知道每个特征子集vi中所含sopt中最优特征的数量
改造后的分布式pocss算法相较于单机版pocss算法的加速效果如下:
对于css问题,在分布式场景下,把特征集根据集群中的计算节点数m平均划分为了{v1,v2,...,vm}子集共m组,目的为从这些特征子集中选择出k个特征得到一个解s,使得解s能最小化目标函数f(s)。在理想情况下,所有特征子集vi的质量相同,即sq1=sq2=…=sqm,根据子集质量评估算法,对任意的vi有ki=k/m。对于pocss算法,子集vi上的算法迭代次数为
a6.将步骤a5得到的特征集合si聚合,得到最终特征选择结果s,
本步骤的优点在于,直接汇总合并各子集的选择结果即为最终输出结果,简洁高效,区别于已有的两阶段css算法,还需要在汇总子集的选择结果上再次运行单机版css算法才能获得最终选择结果。
s3.在每台计算节点上执行子集质量评估方法,从而计算得到对应的特征子集目标特征数;
子集质量评估方法具体为使用信息熵衡量特征子集vi的子集质量sqi;特征信息熵h(f)用于衡量一个特征f所蕴含信息量的大小,信息熵h(f)越高表示该特征f蕴含的信息量越大,定义特征集合熵:
其中,ni为特征子集vi所含特征数目,fvt是特征fj所有可能取得的特征值,p(fvt)=pr(fj=fvt)是概率质量函数;子集质量sqi的值越大,表示特征子集vi含有的信息量越大,越多的最优特征分布在特征子集vi中,因此特征数目ki越大;
s4.根据步骤s3得到的各个计算节点的特征子集目标特征数,每台计算节点进行各自的特征选择计算,从而得到每台计算节点所选择得到的特征;
s5.汇总步骤s4得到的各计算节点的特征选择计算结果,从而得到最终选择到的特征
css问题是旨在由s拟合原矩阵a的约束性低秩近似问题,其中s是由从a中选择出的列(特征)组成的矩阵,s拟合能力的强弱由a与ss+a的方差来表示,方差越小,拟合能力越强。
css问题的数学定义为:给定一个矩阵
其中,|·|为矩阵s的列数,s+表示矩阵s的moore-penrose广义逆矩阵,||·||f为矩阵的frobenius范数。
本发明的基本思路在于,针对css问题,在分布式特征选择框架中融入子集质量评估方法以加速特征选择过程,一方面,利用启发式的子集质量评估方法确定在各个子集中应选的特征数目,有效避免了在子集中选择到冗余特征,同时也加速了特征选择过程;另一方面,经子集质量评估方法后再运行css算法,然后汇总从各个子集中选择出的特征直接得到最终选择结果,使得在理论上该方法至少能达到线性加速;最后一方面,依据使用者和应用的不同偏好,在单机版特征选择算法和子集质量评估指标的选择可做灵活改变,实现一种灵活可插拔的分布式特征选择框架。
在现有的实验中,通过将单机版pocss特征选择算法嵌入该分布式特征选择框架中,在小、中、大规模数据集上测试,本发现在全部数据集上的加速效果均有显著提升,最高加速比达到了3788,理想情况下理论加速比达到了m3,m为集群中计算节点的数量。其主要原因在于,根据子集质量评估方法确定的在各子集中选择的特征数量往往小于k,进而极大地降低了pocss算法所需的迭代次数,缩短了运行时间。
如图2为本发明系统的结构示意图,本发明提供了一种包括上述分布式列子集选择方法的系统,包括获取模块、预处理模块、评估模块、选择模块和输出模块;获取模块、预处理模块、评估模块、选择模块和输出模块依次串接;获取模块,获取数据集中全部的特征;预处理模块,用于预处理原始数据集,负责特征的清洗、归一化处理,根据集群中计算节点数量为处理后的特征集均匀随机分配分组标签,为下一模块的计算做输入准备;评估模块,用于为各特征子集进行子集质量评估,根据各子集质量为该子集找到合理的应选择的目标特征数目;选择模块,根据上游模块得到的特征子集以及应选择的目标特征数目,在本模块中选择一个单机版的css算法在各计算节点上计算,然后汇总各节点计算结果得到最终选择到的特征;输出模块,用于输出特征选择结果。
以下采用一个实施例,来说明本发明的优势。
在硬件方面采用8台计算节点,每一台配备了xeongold5118cpu和12g内存;软件方面,每台计算节点安装了centos7.7.1980系统,搭建了hadoop3.1.2和spark2.4.5分布式计算平台,使用python3.6.8编程实现本发明,以及对于css问题选择的目标特征数目为50,即k=50。
为了说明本发明方法的有效性以及对于加速效果的提升,在多个数据集上进行了测试,将应用本发明改造后的pocss算法运行时间与单机版pocss算法运行时间进行对比,计算公式如下:
其中,tf为本发明的特征选择运行时间,speedup为本发明相较单机版pocss算法运行时间的加速比,tpocss为单机版pocss算法特征选择运行时间。
加速比评估结果如下表:
表1
根据上表1的加速比实验结果,可以看出由于本发明在每个特征子集上仅选择出ki个特征,使得本发明应用到pocss算法上加速效果非常显著。而且随着数据集的规模不断扩大,特征总数的不断增长,加速效果越来越明显。可以看到在scene数据集中最高加速比为447,在semg数据集中最高加速比达到了3788。
应用本发明的加速效果极其显著的三个原因:首先是因为每个特征子集上选择较少的特征,在理论上改造后的pocss算法加速比在m和m3之间,在实际实验中,semg数据集经划分后各子集质量近似相同,所以能达到近m3倍的加速;其次是因为随计算节点数量增多,特征子集变得越来越小,其形成的二维矩阵也越来越小,在对该矩阵计算时的耗时也会相应减少;最后是由于各数据集的稀疏程度不同,稀疏矩阵的计算显然要比密集矩阵耗时要长,而semg属于稀疏矩阵。
本发明可广泛应用于生物信息挖掘和快速图像压缩等领域,下以生物信息挖掘为例。
本发明以公布的白血病数据集为例。该数据集包含与来自骨髓和外周血的急性淋巴细胞白血病(all)和急性髓细胞性白血病(aml)样本相对应的基因表达。数据集由72个样本组成:49个all样本;aml的23个样本。每个样本都测量了超过7,129个基因。
应用流程如下:
b1.获取数据集中全部的特征;给定一个总特征选择数目k;
b2.对步骤b1获取的数据集中的特征进行处理,然后均匀分组到各计算节点;通过获取模块将基因数据集读入并转化为一个由样本和特征组成的二维矩阵a=(样本数量,特征数量);
b3.通过预处理模块将步骤b2得到矩阵进行特征清洗和归一化处理;
b4.在每台计算节点上执行子集质量评估方法,从而计算得到对应的特征子集目标特征数;将步骤b3清理后数据根据集群中节点数量,形成基因子集vi分发到各个节点;
b5.通过评估模块,各节点利用子集质量评估算法计算所分配基因子集的质量sqi;
b6.根据各子集的质量和总目标特征数计算出每个子集应选的特征数ki;
b7.根据ki执行pocss算法,在每个基因子集中选择出ki个特征;
b8.汇总得到的各计算节点的特征选择计算结果,从而得到最终选择到的特征;具体为汇总各节点的选择结果,得到最终k个与白血病最具相关性的基因表达。
步骤b3包括:首先将数据集中数据转化为一个由特征和特征取值组成的二维矩阵,然后将特征取值全为空以及特征取值方差为0的特征删除,接着利用l2范数对剩余特征进行归一化处理,最后根据集群中的计算节点数量建立分组标签,为每一个特征随机分配标签,从而将每一个特征随机划分到不同的计算节点的特征子集。
对每个特征f的l2范数归一化的计算公式如下:
其中,fv1,fv2,…,fvn是特征f可能取得的特征值;||f||2表示特征f的l2范数。
步骤b5所述的子集质量评估方法,具体为使用信息熵衡量特征子集vi的子集质量sqi;特征信息熵h(f)用于衡量一个特征f所蕴含信息量的大小,信息熵h(f)越高表示该特征f蕴含的信息量越大,定义特征集合熵:
其中,ni为特征子集vi所含特征数目,fvt是特征fj所有可能取得的特征值,p(fvt)=pr(fj=fvt)是概率质量函数;子集质量sqi的值越大,表示特征子集vi含有的信息量越大,越多的最优特征分布在特征子集vi中,因此特征数目ki越大。
步骤b7,根据步骤b4得到的各个计算节点的特征子集目标特征数,每台计算节点进行各自的特征选择计算,具体为,质量越高,特征数目ki越大;为了保证质量更高的特征子集vi能分配到更大的特征数目ki,将各子集的子集质量sqi降序排列,计算降序排列的前m-1个子集的特征数目ki,m为集群中计算节点的数量;
其中,1≤i≤m-1,[·]表示向上取整,k为目标特征总数;
得到前m-1个子集的特征数目ki后,降序排列的最后一个子集的特征数目ki,记为
每台计算节点进行各自的特征选择计算,具体每台计算节点采用pocss算法进行各自的特征选择计算。
本发明还提供了一种基于所述的白血病基因信息挖掘方法的系统,该系统包括获取模块、预处理模块、评估模块、选择模块和输出模块;获取模块、预处理模块、评估模块、选择模块和输出模块依次串联;获取模块用于获取数据集中全部的特征;预处理模块用于预处理原始数据集,并负责特征的清洗和归一化处理,根据集群中计算节点数量为处理后的特征集均匀随机分配分组标签,并为下一模块的计算做输入准备;通过获取模块将基因数据集读入并转化为一个由样本和特征组成的二维矩阵a=(样本数量,特征数量);预处理模块形成基因子集vi分发到各个节点;评估模块用于为各特征子集进行子集质量评估,根据各子集质量为该子集找到目标特征数目,各节点利用子集质量评估算法计算所分配基因子集的质量sqi;选择模块用于根据特征子集以及目标特征数目,采用pocss算法在各计算节点上计算,然后汇总各节点的计算结果得到最终选择到的特征;输出模块用于输出特征选择结果,得到最终k个与白血病最具相关性的基因表达。
- 还没有人留言评论。精彩留言会获得点赞!