信号处理方法及装置
本发明涉及数据处理领域,尤其涉及一种信号处理方法及装置。
背景技术:
本部分旨在为权利要求书中陈述的本发明实施例提供背景或上下文。此处的描述不因为包括在本部分中就承认是现有技术。
睡眠呼吸暂停低通气综合征(osahs)是一种常见病,其主要表现为睡眠时打鼾并伴有呼吸暂停和呼吸表浅,夜间反复发生低氧血症、高碳酸血症和睡眠结构紊乱,导致白天嗜睡、心脑肺血管并发症乃至多脏器损害,严重影响患者生活质量和寿命。睡眠呼吸暂停低通气指数(ahi)是评判osahs患者患病严重程度的一个重要指标,它指的是患者在整晚睡眠阶段单位时间(例如,每小时)平均出现呼吸事件的次数。此处的呼吸事件包括:阻塞型睡眠呼吸暂停、中枢性睡眠呼吸暂停、混合性睡眠呼吸暂停。
根据美国睡眠学会(aasm)的标准,呼吸暂停的定义是呼吸流量减少超过90%,持续10秒或更长时间。低通气的定义为患者血氧饱和度降低超过4%的情况下,呼吸流量减少超过30%,整个过程持续超过10秒。依据患者的ahi值区分患者患病的严重程度,例如,ahi<5表明患病程度为正常;5≤ahi<15表明患病程度为轻度;15≤ahi<30表明患病程度为中度;ahi≥30表明患病程度为重度。一些研究估计,在30~60岁的成年人中,患有osahs的患者人数接近10亿,其中4.25亿可能患有中度至重度osahs。
目前,现有技术采用的osahs检测方法是基于多导睡眠图(psg)的监测,这需要患者在专业的睡眠实验室接受整夜的psg监测,操作繁琐,且需要由受过专业培训的技师对产生的医学数据进行标注,一个熟练的技师一天仅能标注3个患者的信息。这种极高的诊疗成本很大程度上限制了osahs的大规模筛查,因而,如何研发一套切实可行且快速的呼吸事件检测方法,以辅助osahs的筛查,是亟待解决的技术问题。
技术实现要素:
本发明实施例提供一种信号处理方法,用以基于采集的音频信号快速检测出信号事件,该方法包括:采集待处理信号;按照预设时间间隔,对采集的待处理信号进行切割,得到多个信号片段,其中,每个信号片段的持续时长为预设时间间隔;将每个信号片段输入至预先训练好的信号事件检测模型中,输出每个信号片段的标记信息,其中,标记信息用于标记每个信号片段是否发生预设信号事件;根据待处理信号上各个信号片段的标记信息,统计待处理信号上发生预设信号事件的数量。
本发明实施例还提供一种信号处理装置,用以基于采集的音频信号快速检测出信号事件,该装置包括:信号采集模块,用于采集待处理信号;信号切割模块,用于按照预设时间间隔,对待处理信号进行切割,得到多个信号片段,其中,每个信号片段的持续时长为预设时间间隔;信号事件检测模块,用于将每个信号片段输入至预先训练好的信号事件检测模型中,输出每个信号片段的标记信息,其中,标记信息用于标记每个信号片段是否发生预设信号事件;信号事件统计模块,用于根据待处理信号上各个信号片段的标记信息,统计待处理信号上发生预设信号事件的数量。
本发明实施例还提供了一种计算机设备,用以基于采集的音频信号快速检测出信号事件,该计算机设备包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述信号处理方法。
本发明实施例还提供了一种计算机可读存储介质,用以基于采集的音频信号快速检测出信号事件,该计算机可读存储介质存储有执行上述信号处理方法的计算机程序。
本发明实施例中提供的一种信号处理方法、装置、计算机设备及计算机可读存储介质,在实时采集待处理信号的过程中或在采集完待处理信号后,按照预设时间间隔,对采集的待处理信号进行切割,得到多个信号片段,使得每个信号片段的持续时长为预设时间间隔,然后将每个信号片段输入至预先训练好的信号事件检测模型中,输出每个信号片段的标记信息,以标记每个信号片段是否发生预设信号事件,进而根据待处理信号上各个信号片段的标记信息,快速统计出待处理信号上发生预设信号事件的数量。通过本发明实施例,能够从采集的音频信号中,快速、自动地检测出信号事件,提高音频信号的处理效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。在附图中:
图1为本发明实施例中提供的一种信号处理方法流程图;
图2为本发明实施例中提供的一种可选的信号处理方法流程图;
图3为本发明实施例中提供的一种信号事件检测模型的训练流程图;
图4为本发明实施例中提供的一种信号处理装置示意图;
图5为本发明实施例中提供的一种计算机设备示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚明白,下面结合附图对本发明实施例做进一步详细说明。在此,本发明的示意性实施例及其说明用于解释本发明,但并不作为对本发明的限定。
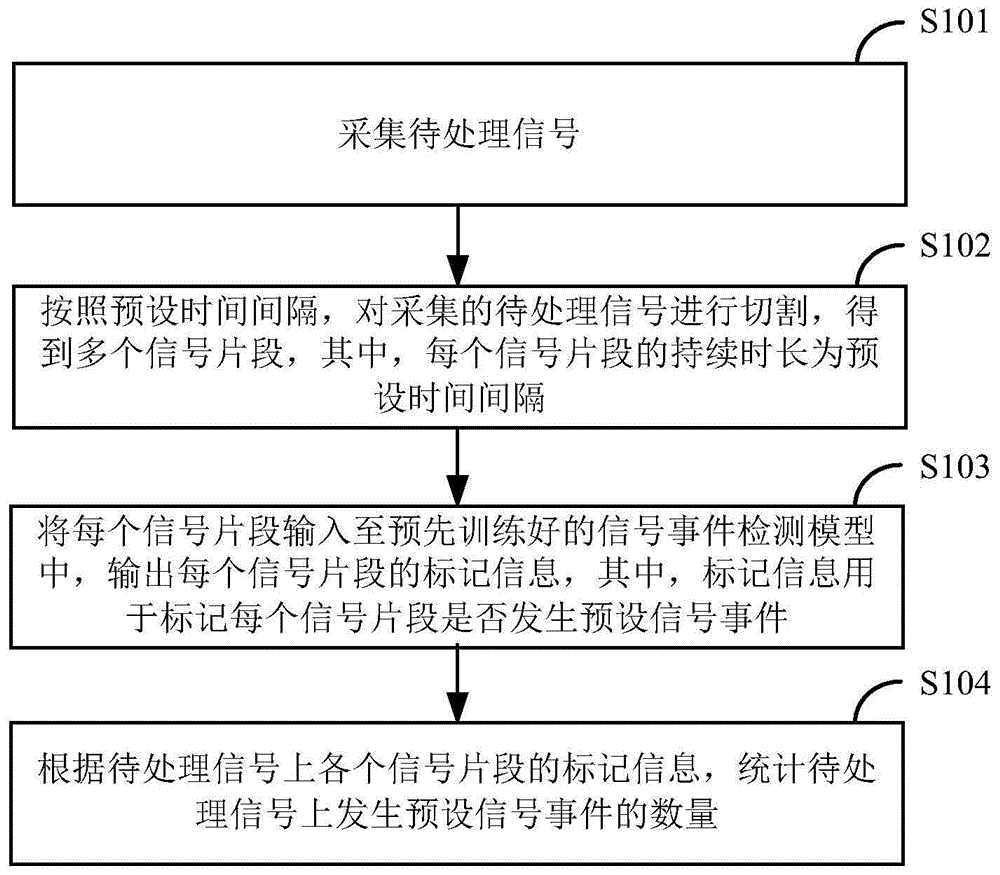
本发明实施例中提供了一种信号处理方法,图1为本发明实施例中提供的一种信号处理方法流程图,如图1所示,该方法包括如下步骤:
s101,采集待处理信号。
需要说明的是,本发明实施例中的待处理信号可以是任意一种待检测信号事件(即具有某个信号特征的事件)的信号,包括但不限于用户夜间呼吸音频信号、心电信号或脑电信号;本发明实施例中提供的信号处理方法可应用于夜间呼吸音频信号中鼾声检测、呼吸事件检测;心电信号中qrs波检测、心肌缺血检测、心肌梗死检测、心率失常检测;脑电信号中异常脑电波形检测等。
s102,按照预设时间间隔,对采集的待处理信号进行切割,得到多个信号片段,其中,每个信号片段的持续时长为预设时间间隔。
需要说明的是,上述s102中的预设时间间隔可以是预设一个时间段,根据检测的信号事件不同,可设定不同时长的时间间隔,例如,设置切割音频信号的时间间隔为5分钟。
需要注意的是,本发明实施例中通过s101采集的待处理信号可以是实时采集的,也可以是预先采集的。当s101中实时采集待处理信号的情况下,上述s102可以按照预设时间间隔,对实时采集的待处理信号进行持续切割,得到多个信号片段;当s101中采集的待处理信号为采集完的整个音频信号的情况下,上述s102可以按照预设时间间隔,将整个音频信号切割为多个信号片段。
s103,将每个信号片段输入至预先训练好的信号事件检测模型中,输出每个信号片段的标记信息,其中,标记信息用于标记每个信号片段是否发生预设信号事件。
需要说明的是,本发明实施例中的信号事件检测模型是指预先通过机器学习训练得到的一个检测音频信号上是否发生预设信号事件的模型;将待处理信号切割得到的每个信号片段输入至预先训练好的信号事件检测模型中,能够判断每个信号片段是否发生预设信号事件。
需要注意的是,本发明实施例中信号事件是指与音频信号幅值、频率等相关的事件,例如,某个时间段内音频信号幅值等于零或持续小于某个阈值的事件。在一个实施例中,当待处理信号为用户夜间睡眠音频信号的情况下,信号事件可以是用户呼吸暂停事件。
s104,根据待处理信号上各个信号片段的标记信息,统计待处理信号上发生预设信号事件的数量。
需要说明的是,由于本发明实施例中,通过信号事件检测模型对每个信号片段是否发生预设信号事件进行了检测,因而,根据根据待处理信号上所有信号片段的标记信息,能够统计出待处理信号上发生预设信号事件的数量。在将本发明实施例中提供的信号处理方法应用于用户夜间音频信号检测时,可根据用户夜间音频信号上发生预设信号事件的数量,反映出用户的健康状况以及是否患有睡眠呼吸暂停低通气综合征,根据预设信号事件的数量多少,还可反映用户患有睡眠呼吸暂停低通气综合征的严重程度。
在一个实施例中,如图2所示,在执行s101之后,本发明实施例中提供的信号处理方法还可包括如下步骤:
s201,采用如下任意一种方法对待处理信号进行信号增强预处理:谱减法、基于最小均方lms算法的自适应滤波法、维纳滤波法、基于统计模型的滤波法、基于子空间的信号增强法、基于小波变换的信号增强法和基于神经网络的信号增强法。
则上述s102中,可按照预设时间间隔,对信号增强后的信号进行切割,得到多个信号片段,其中,每个信号片段的持续时长为预设时间间隔。
在一个实施例中,当本发明实施例中提供的音频信号处理方法应用于用户呼吸事件检测的情况下,可通过如下步骤来实现音频信号的增强:利用频减法,对采集音频信号进行预处理;将频减法后的音频信号进行归一化处理;利用双门限法去掉时长超过预设时长(例如,5分钟)的静音部分。在具体实时时,在通过音频采集设备采集受试者夜间音频信号的时候,可将音频采样设备放置于被试者睡眠发生处一米之内。音频采样设备的采样率包括但不限于44100hz。
在将每个信号片段输入至预先训练好的信号事件检测模型中,输出每个信号片段的标记信息之前,一个实施例中,如图3所示,本发明实施例中提供的信号处理方法还可通过如下步骤来实现信号事件检测模型的训练:
s301,搭建一维信号目标检测网络,其中,一维信号目标检测网络包括:降维层、特征提取层和特征融合层,特征融合层采用特征金字塔结构;
s302,使用深度学习方法,利用预先获取的样本数据,对一维信号目标检测网络进行训练,得到一个用于检测信号片段是否发生预设信号事件的信号事件检测模型。
当本发明实施例中提供的信号处理方法应用于呼吸事件检测的情况下,本发明实施例中用于训练信号事件检测模型的样本数据可以是夜间音频数据及相应呼吸事件标签,其中夜间音频数据对应的呼吸事件标签可以是由对应的病人在佩戴psg设备监控整晚之后确定的,本发明对此不作限定。在具体实施时,可按照时间顺序,将采集的用户夜间音频信号切割成预设时长(例如,5分钟)的音频信号片段,根据psg监测生成的呼吸事件列表标注出这些音频信号片段上呼吸事件发生的开始时刻与结束时刻,开始时刻与结束时刻之间为呼吸事件的持续时长。在对模型进行训练时,可将音频信号片段的梅尔特征作为一维信号目标检测网络的输入,则训练得到的信号事件检测模型能够根据采集的音频信号的梅尔特征进行信号事件的检测。
在模型训练过程中,将样本数据按照预设比例划分为训练数据、验证数据和测试数据;利用训练数据对一维信号目标检测网络进行训练,获得信号事件检测模型;利用验证数据,对训练得到的信号事件检测模型进行验证,调整模型参数,直到模型精确率和召回率符合预设条件;利用测试数据,对符合预设条件的音频数据呼吸事件检测模型进行测试。
在将本发明实施例中提供的信号处理方法应用于用户夜间呼吸事件检测时,本发明实施例中提供的信号事件检测模型,能够判断出5分钟音频中呼吸事件发生与否以及其位置。
在搭建一维信号目标检测网络时,需要搭建降维层、特征提取层、特征融合层,并设置预设框,其中降维层是将二维的梅尔谱信号(在采集音频信号后,提取信号片段的梅尔谱特征,其维度为5168×64)转化为一维的特征向量,就是将原来的5168×64维的二维特征矩阵矩阵降维成5168×1维的一维特征向量,该特征向量在时序上与呼吸信号呈线性相关。其中特征提取层与二位卷积神经网络中的resnet基本一致,区别在于将resnet中二维卷积层与二维池化层变成了一维卷积层和一维池化层此处将原有的5168×1维的一维特征向量降维为323×1维的特征向量并作为特征层。特征融合层使用步距为2的卷积层对特征进行进一步提取,分别提取出161×1维、80×1维、40×1维的特征层。这些特征层维度越低,其层次越高,包含语义信息越多,位置信息少。相反,特征层如果维度越高,其层次越低,包含语音信息少,位置信息多。
通过特征金字塔对这些特征层进行进行融合,使每一层所包含的信息更加丰富,具体方法为将高层特征层进行反卷积操作,得到新的特征层与低层特征层相加,例如将40×1维的特征层进行反卷积为80×1维,再用这个结果与原有的80×1维的特征层相加,获得一个新的80×1维的特征层。神经网络为特征层上的每一个点输出2×8个偏置参数和2×8个置信参数,其具体作用将在下文介绍。
具体实施时,特征层上预设框的基长度根据特征层长度的不同而改变,需要说明的是,本模型中采用的特征层数取决于模型深度,如果特征层数为m,则需要设置m个不同的基长度。其中每一个特征层基长度的比例因子sk设置表示为:
其中smin的值为0.033,smax的值为0.133,m为特征层数,一维目标检测网络中最大的基长度为40秒,最小的基长度为10秒。
具体实施时,预设框的长宽比设置为a∈{1,1.25,1.5,2,2.25,2.5,3,3.5},代表每一个特征层上的特征点都有8个预设框,其长度分别为基长度与长宽比中的因子相乘。预设框的中心设置为
具体实施时,模型的训练思路源自ssd,但本发明实施例中提供的方法可适用于一维信号的目标识别,利用上述的预设框与训练数据中标记出来的真实框进行匹配,匹配方法就是计算其交并比是否大于某一阈值(例如,0.5)我们将这些预测框放入正样本集,然后再选择典型的负样本,即损失最高的预测框放入负样本集,保持负样本集中预测框的数量是正样本集中的3倍,使用
其中,lloc是位置损失,lconf是置信度损失,n是被匹配上的预设框的个数,如果n为0,则置信度损失为0;l是预测框,预测框的位置是预设框根据神经网络的两个偏置输出调整而来的;g是预设框;(ct)和(d)分别是预设框的两个偏置参数;x表示预测框与真实框的对应情况;α是权重因子,一般设置为1。
其中lloc的计算方法如下:
其中,pos是正样本集;
置信度损失是多个类别(c)置信度上的softmax损失:
其中,
其中,neg是负样本集;
模型根据预设框与真实框的位置差别以及置信度差别利用神经网络的反向传播对参数进行更新,以达到对该模型进行训练的效果。
为了避免信号事件被切割,在一个实施例中,上述s102可通过如下步骤来实现:当第一信号片段发生预设信号事件的情况下,获取预设信号事件的结束时刻;在预设信号事件结束时刻后,间隔预设时长切割第二信号片段,其中,第二信号片段为第一信号片段的下一个信号片段。
当待处理信号为用户夜间睡眠音频信号且信号事件为用户呼吸暂停事件的情况下,按照5分钟切割用户夜间睡眠音频信号,检测每个5分钟信号片段是否发生呼吸暂停事件,如果在某一个5分钟信号片段的3分钟50秒处检测到一个呼吸暂停事件(持续20秒),则在4分钟20秒(即呼吸事件结束时刻为4分钟10秒,再延长10秒),继续切割下一个5分钟信号片段,这样就不会导致呼吸暂停事件被切割。
在将本发明实施例中提供的信号处理方法应用于用户夜间呼吸事件检测时,具体实现流程如下:
①获取用户整晚的睡眠音频信号,切割前300秒的音频数据。可选地,通过谱减法对信号进行数据增强。
②将切割下来的音频输入音频数据呼吸事件检测模型,如果没有检测到事件或者呼吸事件结束时间在180秒之前,则切割位置选在该段音频180秒处。如果检测到呼吸事件,则切割位置选在时序上该段音频检测出的最后一个呼吸事件的结束位置后10秒。
③进行下一次切割,从切割位置开始切割出又一段5分钟音频,然后重复步骤②,直到整段音频被检测完全。
④输出整段音频中呼吸事件的个数及每个呼吸事件的位置生与否以及其位置。
由于呼吸事件持续时长不超过120秒,两次呼吸事件发生间隔不小于10秒。在具体实施时,切割位置的选取根据任务的不同而设定,因为本例中时间最长的呼吸事件是120秒,切片长是300秒,故如果没有呼吸事件发生或呼吸事件结束时间在180秒之前,则切割位置选在该段音频180秒处。因为两次呼吸事件发生的最小间隔为10秒,故如果检测到呼吸事件,则切割位置选在时序上该段音频检测出的最后一个呼吸事件的结束位置后10秒。这样就可以保证呼吸事件不被切割。
在具体实施时,为了不将原始音频信号暴露给基于一维信号目标检测的呼吸事件检测方法算法提供者,首先算法提供者将基于一维信号目标检测的呼吸事件检测方法张训练的模型的特征提取层和部分特征融合层的参数发送给受试者。受试者的终端通过利用特征提取层和部分特征融合层的参数与自己的夜间鼾声音频计算获得夜间鼾声数据的特征向量。受试者将不包含原始音频信息的特征向量发送给算法提供者。算法提供者根据特征向量预测进行呼吸事件检测,并把结果发送回受试者。
将本发明实施例中提供的信号处理方法应用于用户夜间呼吸事件检测,能够利用“边切边检”方法与上述模型对受试者整夜音频进行呼吸事件的定位,统计受试者夜间发生呼吸事件的次数,判断其患阻塞性睡眠呼吸暂停低通气综合征的严重程度。可选地,受试者的ahi可用整晚测得呼吸事件的个数与睡眠时间相除得到。
基于同一发明构思,本发明实施例中还提供了一种信号处理装置,如下面的实施例所述。由于该装置解决问题的原理与信号处理方法相似,因此该装置的实施可以参见信号处理方法的实施,重复之处不再赘述。
图4为本发明实施例中提供的一种信号处理装置示意图,如图4所示,该装置包括:信号采集模块41、信号切割模块42、信号事件检测模块43和信号事件统计模块44。
其中,信号采集模块41,用于采集待处理信号;信号切割模块42,用于按照预设时间间隔,对待处理信号进行切割,得到多个信号片段,其中,每个信号片段的持续时长为预设时间间隔;信号事件检测模块43,用于将每个信号片段输入至预先训练好的信号事件检测模型中,输出每个信号片段的标记信息,其中,标记信息用于标记每个信号片段是否发生预设信号事件;信号事件统计模块44,用于根据待处理信号上各个信号片段的标记信息,统计待处理信号上发生预设信号事件的数量。
在一个实施例中,如图4所示,本发明实施例中提供的信号处理装置还可包括:信号增强处理模块45,用于采用如下任意一种装置对待处理信号进行信号增强预处理:谱减法、基于最小均方lms算法的自适应滤波法、维纳滤波法、基于统计模型的滤波法、基于子空间的信号增强法、基于小波变换的信号增强法和基于神经网络的信号增强法。
在一个实施例中,如图4所示,本发明实施例中提供的信号处理装置还可包括:机器学习模块46,用于搭建一维信号目标检测网络,其中,所述一维信号目标检测网络包括:降维层、特征提取层和特征融合层,所述特征融合层采用特征金字塔结构,在一维信号目标检测网络中加入特征金字塔结构,得到待训练的机器学习模型,并使用深度学习方法,利用预先获取的样本数据,对一维信号目标检测网络进行训练,得到一个用于检测信号片段是否发生预设信号事件的信号事件检测模型。
在一个实施例中,本发明实施例中提供的信号处理装置中,信号切割模块42还可用于:当第一信号片段发生预设信号事件的情况下,获取预设信号事件的结束时刻;以及在预设信号事件结束时刻后,间隔预设时长切割第二信号片段,其中,第二信号片段为第一信号片段的下一个信号片段。
基于同一发明构思,本发明实施例还提供了一种计算机设备,用以基于采集的音频信号快速检测出信号事件,图5为本发明实施例中提供的一种计算机设备示意图,如图5所示,该计算机设备50包括存储器501、处理器502及存储在存储器501上并可在处理器502上运行的计算机程序,处理器502执行计算机程序时实现上述信号处理方法。
基于同一发明构思,本发明实施例还提供了一种计算机可读存储介质,用以基于采集的音频信号快速检测出信号事件,该计算机可读存储介质存储有执行上述信号处理方法的计算机程序。
综上所述,本发明实施例中提供的一种信号处理方法、装置、计算机设备及计算机可读存储介质,在实时采集待处理信号的过程中或在采集完待处理信号后,按照预设时间间隔,对采集的待处理信号进行切割,得到多个信号片段,使得每个信号片段的持续时长为预设时间间隔,然后将每个信号片段输入至预先训练好的信号事件检测模型中,输出每个信号片段的标记信息,以标记每个信号片段是否发生预设信号事件,进而根据待处理信号上各个信号片段的标记信息,快速统计出待处理信号上发生预设信号事件的数量。通过本发明实施例,能够从采集的音频信号中,快速、自动地检测出信号事件,提高音频信号的处理效率。将本发明实施例中提供的信号处理方法应用于呼吸事件检测,由于无需受试者穿戴各种psg设备,只需要整晚睡眠监测的音频信号,相比于人工通过口鼻气流判断呼吸事件而言更为高效,为osahs的大规模筛查提供了可能。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!