缺氧诱导脂滴相关蛋白(HILPDA)在预防或治疗高血脂相关疾病中的应用
缺氧诱导脂滴相关蛋白(hilpda)在预防或治疗高血脂相关疾病中的应用
技术领域
1.本发明属于生物医药领域,具体而言,涉及缺氧诱导脂滴相关蛋白在制备用于预防或治疗高血脂相关疾病的药物中的用途。
背景技术:
2.高血脂是现代社会一种非常常见的代谢疾病,其主要临床表现为患者血液中的胆固醇、甘油三酯及载脂蛋白等含量异常增加。据调查,在我国超过60岁以上的人群中,超过13%的男性与超过23%的女性存在高血脂现象。长期高血脂易引起动脉粥样硬化,并引起相关心血管疾病、高血压、高血糖、高尿酸血症等并发症。
3.目前临床上常用的降血脂药物主要是他汀类药物,其主要作用机理是通过抑制细胞内胆固醇合成相关的关键生物酶,降低释放到血液中的胆固醇含量,从而起到降低血脂的作用。虽然他汀类药物在临床上被广泛使用,但其也有明显的不足,包括对甘油三酯及载脂蛋白的降低作用有限,以及较易引起肝脏损伤、肌痛等副作用。因此寻求能够特异性降低甘油三酯及载脂蛋白的降血脂药物有着重要的临床意义。
4.缺氧诱导脂滴相关蛋白(hypoxia-induced,lipid droplet-associated protein,hilpda)是一种受低氧诱导因子1/2(hif1/2)或过氧化物酶体增殖物激活受体(ppar)调节的靶蛋白(由hilpda基因编码),在细胞内主要定位于脂滴(lipid droplets),促进脂质的富集。hilpda在人类中由63个氨基酸组成,在小鼠中由64个氨基酸组成。
5.之前已有少量证据表明hilpda作为一个小型分泌蛋白,高表达于肾透明细胞癌患者血液中,但此结论随后被另外一个研究团队所否定,故其是否作为分泌蛋白尚存争议。
6.有相关研究发现在缺失载脂蛋白apoe的小鼠模型中敲除hilpda可以减少由积累过量脂质的巨噬细胞衍生而来的泡沫细胞(foam cells,动脉粥样硬化症发生的一种特征性细胞)的形成,缓解动脉粥样硬化病程的发展。这些发现揭示了在特定的apoe缺失型小鼠模型中,hilpda促进动脉粥样硬化病程的发展。目前的研究均是基于hilpda与其原来已知的胞内蛋白相互作用引发的生物学功能。
7.目前尚无hilpda降低血液中的载脂蛋白与脂质含量的报道。
技术实现要素:
8.本发明人通过研究发现,缺氧诱导脂滴相关蛋白(hilpda)确实可以作为分泌蛋白有效促进血清中的载脂蛋白与脂质颗粒,例如apolipoprotein e(apoe)脂质颗粒,被体外培养的多种细胞所清除,从而降低血液中的载脂蛋白(包括但不限于apoe)与脂质颗粒含量。
9.因此,一方面,本发明提供了缺氧诱导脂滴相关蛋白(hilpda)在制备用于降低血液中的载脂蛋白与脂质含量的药物中的用途。
10.另一方面,本发明提供了缺氧诱导脂滴相关蛋白(hilpda)在制备用于预防或治疗
高血脂相关疾病的药物中的用途。
11.本发明中,所述高血脂相关疾病是指高血脂及其并发症,即空腹静脉血清中总胆固醇含量过高,等于或超过6.2mmol/l;或/及血清甘油三酯含量过高,等于或超过2.3mmol/l;或/及低密度脂蛋白胆固醇(ldl-胆固醇)含量过高,等于或超过4.1mmol/l;或/及血清高密度脂蛋白-胆固醇(hdl-胆固醇)含量降低,低于1.0mmol/l,及其衍生的病理症状,包括但不限于高血脂,长期高血脂引起的动脉粥样硬化,以及长期高血脂引起的心血管疾病、高血压、高血糖、高尿酸血症等并发症。
12.在一个实施方式中,hilpda可以是来自人(homo sapiens)、黑猩猩(pan troglodytes)或大猩猩(gorilla)的hilpda,其氨基酸序列如seq id no:1(mkhvlnlyllgvvltllsifvrvmeslegllespspgtswttrsqlanteptkglpdhpsrsm)所示。
13.在另一个实施方式中,hilpda可以是鼠(mus musculus)的hilpda,其氨基酸序列如seq id no:2(mkfmlnlyvlgimltllsifvrvmeslggllesplpgsswitrgqlantqppkglpdhpsrgvq)所示。
14.在另一个实施方式中,hilpda可以是来自绿猴(chlorocebus sabaeus)的hilpda,其氨基酸序列如seq id no:3(mkhmlnlyllgvvltllsifvrvmeslegllenpspgtswttrsqlanteptkglpdhpsrsi)所示。
15.在另一个实施方式中,hilpda可以是来自秦岭金丝猴(rhinopithecus roxellana)的hilpda,其氨基酸序列如seq id no:4(mkhvlnlyllgvvltllsifvrvmeslegllenplpgtswttrsqltnteptkglpdhpsrsm)所示。
16.在另一个实施方式中,hilpda可以是来自食蟹猕猴(macaca fascicularis)的hilpda,其氨基酸序列如seq id no:5(mkhmlnlyllgvvltllsifvrvmeslegllenpspgtswttrsqlanteptkglpdhpsrsm)所示。
17.在另一个实施方式中,hilpda可以是来自家猪(sus scrofa)的hilpda,其氨基酸序列如seq id no:6(mkqvlqlyllgvvltllsvfvrlmetlggllespspgsfwttrgqlanteakslpehpsrgv)所示。
18.在另一个实施方式中,hilpda可以是来自狗(canis familiaris)的hilpda,其氨基酸序列如seq id no:7(mkpmlnlyllgvvltllsifvrlmeslggilespllgsswttrghtasaepprafqtihpercdktslhql)所示。
19.在另一个实施方式中,hilpda可以是来自山羊(capra hircus)的hilpda,其氨基酸序列如seq id no:8(mkhvlnlyllggvltllsifvrlmeslegllespspgsswatrgqlantepprafqtihpegcdktslhrl)所示。
20.在另一个实施方式中,hilpda可以是来自马(equus caballus)的hilpda,其氨基酸序列如seq id no:9(mkhilnlyllgvvltllsifvrlmeslegllespspgsswttrsqlvstr ppra fq tihp egcdktsvhrl)所示。
21.在另一个实施方式中,hilpda可以是来自牛(bos taurus)的hilpda,其氨基酸序列如seq id no:10(mkhmlnlyllggvmtllsifiglmesleacwracllgapgppevslptqspqgssrpsiqrgvirppstvynlgtvskipptlpvpgqasstsvlsen)所示。
22.在另一个实施方式中,hilpda可以是来自穴兔(oryctolagus cuniculus)的hilpda,其氨基酸序列如seq id no:11(mkhvlnlyvlgvvlallsifvrvmesleslvespsagnswst
rgqlagaeppkglpdppsrgmr)所示。
23.在一个实施方式中,所述药物用于治疗人类或者其他哺乳动物。其他哺乳动物指的是人类以外的哺乳动物,例如猿、猴、猪、狗、牛、羊、马、驴、兔等。
24.在一些实施方式中,来自人的hilpda可以用于治疗人或其他哺乳动物。
25.在一些实施方式中,来自其他哺乳动物的hilpda可以优选用于治疗相应哺乳动物的近亲种属(如无生殖隔离)的家养宠物等。例如,来自狗的hilpda可以用于治疗狗或狼。
26.本发明中,优选地,构成hilpda的氨基酸中的一个或多个氨基酸可为d-形式的氨基酸。
27.本发明中,优选地,hilpda可以进一步被修饰。
28.本发明中,hilpda可以采用本领域公知的各种技术手段进行修饰,只要这种修饰不产生显著劣化hilpda的有效促进血清中的载脂蛋白与脂质颗粒吸收的功能即可。多肽修饰种类繁多,根据修饰位点不同可分为n端修饰、c端修饰、侧链修饰、氨基酸修饰、骨架修饰等。多肽修饰可有效改变肽类化合物的理化性质、增加水溶性、延长体内作用时间、改变其生物分布状况、消除免疫原性、降低毒副作用等。
29.例如,修饰方法包括但不限于,末端(例如,n末端)连接硬脂酸来修饰,氨基化修饰、乙酰化修饰、生物素化修饰、荧光标记修饰、聚乙二醇修饰、异戊二烯化修饰、豆蔻酰化和棕榈酰化修饰、磷酸化修饰、糖基化修饰、多肽缀合物修饰、特殊氨基酸修饰等。
30.本发明人已通过研究发现了缺氧诱导脂滴相关蛋白(hilpda)的新用途。由于这种天然存在的小蛋白或多肽源于人体自身,在施加到病人身上之后理应具有较低的毒性并缺乏免疫原性,适于临床转化和推广应用,故hilpda将是一个非常具有医学和商业价值的多肽类药物。
附图说明
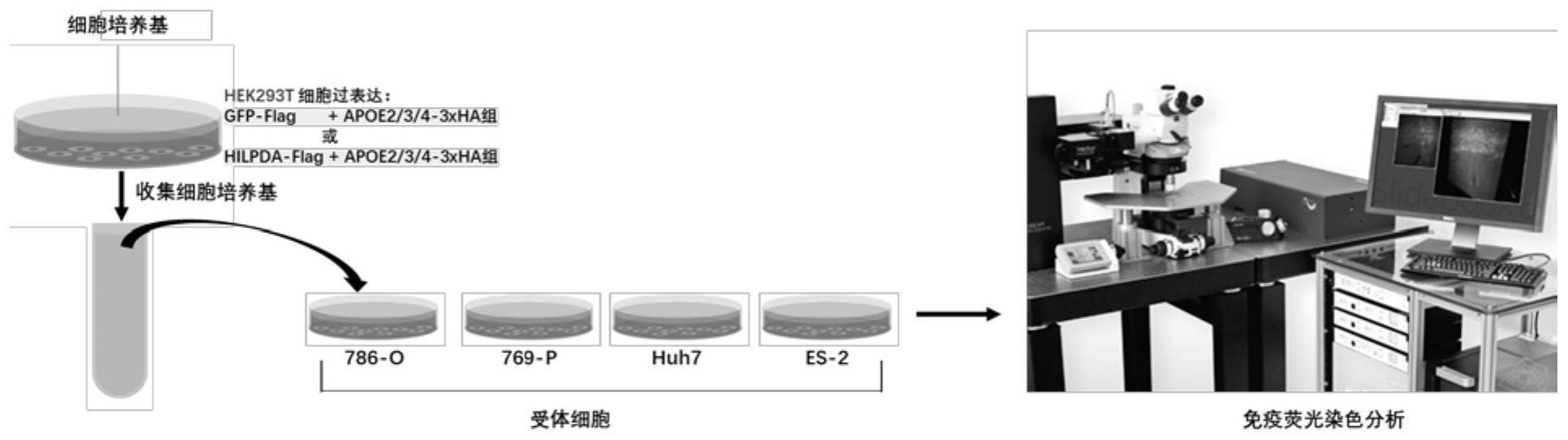
31.图1为评估hilpda是否促进apoe形成的载脂颗粒的吸收策略的图。
32.图2a-2d为显示hilpda存在与否条件下,细胞培养基中apoe被受体细胞吸收的情况的图。其中,2a:786-o;2b:769-p;2c:huh7;2d:es-2。
具体实施方式
33.以下具体实施方式本质上仅是例示性,且并不欲限制本发明及其用途。此外,本文并不受前述现有技术或发明内容或以下具体实施方式或实施例中所描述的任何理论的限制。
34.实施例
35.下述实施例所使用的实验方法如无特殊说明,均为常规方法。
36.下述实施例所用的材料、试剂等,如无特殊说明,均可从商业途径得到。
37.实施例1:表达hilpda-flag融合蛋白的真核表达质粒的构建
38.1)在genewiz(金唯智)直接合成表达人源hilpda-flag融合蛋白对应的dna序列
39.atgaagcatgtgttgaacctctacctgttaggtgtggtactgaccctactctccatcttcgttagagtgatggagtccctagagggcttactagagagcccatcgcctgggacctcctggaccaccagaagccaactagccaacacagagcccaccaagggccttccagaccatccatccagaagcatggattacaaggatgacgacgataagtga(注:
hilpda;flag;stop codon)(seq id no:12)。
40.2)设计对应的引物(正向:atagaagattctagaatgaagcatgtgttgaacctctac(seq id no:13);反向:cgcggccgcggatcctcacttatcgtcgtcatccttgtaatc(seq id no:14)),利用上述合成的dna序列作为模板进行pcr扩增,获得目的片段。(划线部分表示载体同源臂)
41.3)利用限制性内切酶xbai(货号:r0145l,neb)和bamhi(货号:r3136l,neb)双酶切真核表达载体pcdh-cmv-mcs-ef1-puro(货号:vt1480,优宝生物)获得线性载体。
42.4)利用exonuclease iii(货号:2170a,takara)介导的同源重组方法连接目的片段与已酶切的线性载体,并将连接产物在e.coli dh5α中转化,并在氨苄西林(ampicillin)抗性lb固体培养基平板上获得阳性菌落克隆。
43.5)扩增阳性菌落克隆并利用质粒纯化试剂盒抽提质粒。
44.6)测序验证,获得正确的hilpda融合蛋白表达质粒。
45.实施例2:gfp-flag融合蛋白表达质粒的构建
46.1)gfp基因序列来源于载体pcdh-cmv-mcs-ef1-gfp+puro(货号:vt8070,优宝生物),具体序列如下:
47.atggtgagcaagggcgaggagctgttcaccggggtggtgcccatcctggtcgagctggacggcgacgtaaacggccacaagttcagcgtgtccggcgagggcgagggcgatgccacctacggcaagctgaccctgaagttcatctgcaccaccggcaagctgcccgtgccctggcccaccctcgtgaccaccctgacctacggcgtgcagtgcttcagccgctaccccgaccacatgaagcagcacgacttcttcaagtccgccatgcccgaaggctacgtccaggagcgcaccatcttcttcaaggacgacggcaactacaagacccgcgccgaggtgaagttcgagggcgacaccctggtgaaccgcatcgagctgaagggcatcgacttcaaggaggacggcaacatcctggggcacaagctggagtacaactacaacagccacaacgtctatatcatggccgacaagcagaagaacggcatcaaggtgaacttcaagatccgccacaacatcgaggacggcagcgtgcagctcgccgaccactaccagcagaacacccccatcggcgacggccccgtgctgctgcccgacaaccactacctgagcacccagtccgccctgagcaaagaccccaacgagaagcgcgatcacatggtcctgctggagttcgtgaccgccgccgggatcactctcggcatggacgagctgtacaagtaa(小写字母表示终止密码子)(seq id no:15)。
48.2)设计对应的引物(正向:atagaagattctagaatggtgagcaagggcgagga(seq id no:16);反向:反向:),利用上述gfp的dna序列作为模板进行pcr扩增,获得目的片段gfp-flag序列。(划线部分表示载体同源臂,加粗表示flag序列)。
49.3)利用限制性内切酶xbai(货号:r0145l,neb)和bamhi(货号:r3136l,neb)双酶切真核表达载体pcdh-cmv-mcs-ef1-puro(货号:vt1480,优宝生物)获得线性载体。
50.4)利用exonuclease iii(货号:2170a,takara)介导的同源重组方法连接目的片段与已酶切的线性载体,并将连接产物在e.coli dh5α中转化,并在氨苄西林(ampicillin)抗性lb固体培养基平板上获得阳性菌落克隆。
51.5)扩增阳性菌落克隆并利用质粒纯化试剂盒抽提质粒。
52.6)测序验证,获得正确的gfp-flag融合蛋白表达质粒。
53.实施例3:apoe2/3/4-3xha三个不同等位基因对应融合蛋白表达质粒的构建
54.1)apoe3基因序列来源于载体pdonr223-apoe(货号:g118334,优宝生物)。具体序列如下:
55.atgaaggttctgtgggctgcgttgctggtcacattcctggcaggatgccaggccaaggtggagcaagcggtggagacagagccggagcccgagctgcgccagcagaccgagtggcagagcggccagcgctgggaactggcactgggtcgcttttgggattacctgcgctgggtgcagacactgtctgagcaggtgcaggaggagctgctcagctcccaggtcacccaggaactgagggcgctgatggacgagaccatgaaggagttgaaggcctacaaatcggaactggaggaacaactgaccccggtggcggaggagacgcgggcacggctgtccaaggagctgcaggcggcgcaggcccggctgggcgcggacatggaggacgtgtgcggccgcctggtgcagtaccgcggcgaggtgcaggccatgctcggccagagcaccgaggagctgcgggtgcgcctcgcctcccacctgcgcaagctgcgtaagcggctcctccgcgatgccgatgacctgcagaagcgcctggcagtgtaccaggccggggcccgcgagggcgccgagcgcggcctcagcgccatccgcgagcgcctggggcccctggtggaacagggccgcgtgcgggccgccactgtgggctccctggccggccagccgctacaggagcgggcccaggcctggggcgagcggctgcgcgcgcggatggaggagatgggcagccggacccgcgaccgcctggacgaggtgaaggagcaggtggcggaggtgcgcgccaagctggaggagcaggcccagcagatacgcctgcaggccgaggccttccaggcccgcctcaagagctggttcgagcccctggtggaagacatgcagcgccagtgggccgggctggtggagaaggtgcaggctgccgtgggcaccagcgccgcccctgtgcccagcgacaatcactga(小写字母为终止密码子,划线部分代表apoe不同等位基因的区分位点,此序列中特指apoe3)(seq id no:18)。
56.2)设计对应的apoe3引物(正向:atagaagattctagaatgaaggttctgtgggctgcg(seq id no:19),反向:cttccatggctcgaggtgattgtcgctgggcacag(seq id no:20)),利用上述apoe3的dna序列作为模板进行pcr扩增,获得目的片段apoe3序列。(划线部分表示载体同源臂)。
57.3)apoe2和apoe4的基因序列都是基于apoe3基因序列进行点突变而获得。
58.(1)设计点突变引物
59.apoe2,正向:atgccgatgacctgcagaagtgcctggcagtgtaccaggc(seq id no:21),
60.反向:gcctggtacactgccaggcacttctgcaggtcatcggcat(seq id no:22);
61.apoe4,正向:gcgcggacatggaggacgtgcgcggccgcctggtgcagta(seq id no:23),
62.反向:tactgcaccaggcggccgcgcacgtcctccatgtccgcgc(seq id no:24)
63.(2)利用apoe3正向引物+apoe2反向引物以apoe3基因序列作为模板进行pcr扩增出片段1;同时利用apoe2正向引物+apoe3反向引物以apoe3基因序列作为模板进行pcr扩增出片段2。最后通过apoe3正向引物+apoe3反向引物以片段1+片段2的混合物作为模板进行pcr扩增,获得目的片段apoe2的序列。apoe2具体序列如下:
64.atgaaggttctgtgggctgcgttgctggtcacattcctggcaggatgccaggccaaggtggagcaagcggtggagacagagccggagcccgagctgcgccagcagaccgagtggcagagcggccagcgctgggaactggcactgggtcgcttttgggattacctgcgctgggtgcagacactgtctgagcaggtgcaggaggagctgctcagctcccaggtcacccaggaactgagggcgctgatggacgagaccatgaaggagttgaaggcctacaaatcggaactggaggaacaactgaccccggtggcggaggagacgcgggcacggctgtccaaggagctgcaggcggcgcaggcccggctgggcgcggacatggaggacgtgtgcggccgcctggtgcagtaccgcggcgaggtgcaggccatgctcggccagagcaccgaggagctgcgggtgcgcctcgcctcccacctgcgcaagctgcgtaagcggctcctccgcgatgccgatgacctgcagaagtgcctggcagtgtaccaggccggggcccgcgagggcgccgagcgcggcctcagcgccatccgcgagcgcctggggcccctggtggaacagggccgcgtgcgggccgccactgtgggctccctggccggccagccgctacaggagcgggcccaggcctggggcgagcggctgcgcgcgcggatggaggagatgggcagccggacccgcgaccgcctggacgaggtgaaggagcaggtggcggaggtgcgcgccaagctggaggagcaggcccagcagatacgcctgcaggccgaggccttccag
gcccgcctcaagagctggttcgagcccctggtggaagacatgcagcgccagtgggccgggctggtggagaaggtgcaggctgccgtgggcaccagcgccgcccctgtgcccagcgacaatcactga(小写字母为终止密码子,划线部分代表apoe不同等位基因的区分位点,此序列中特指apoe2)(seq id no:25)。
65.(3)利用apoe3正向引物+apoe4反向引物以apoe3基因序列作为模板进行pcr扩增出片段1;同时利用apoe4正向引物+apoe3反向引物以apoe3基因序列作为模板进行pcr扩增出片段2。最后通过apoe3正向引物+apoe3反向引物以片段1+片段2的混合物作为模板进行pcr扩增,获得目的片段apoe4的序列。
66.apoe4具体序列如下:
67.atgaaggttctgtgggctgcgttgctggtcacattcctggcaggatgccaggccaaggtggagcaagcggtggagacagagccggagcccgagctgcgccagcagaccgagtggcagagcggccagcgctgggaactggcactgggtcgcttttgggattacctgcgctgggtgcagacactgtctgagcaggtgcaggaggagctgctcagctcccaggtcacccaggaactgagggcgctgatggacgagaccatgaaggagttgaaggcctacaaatcggaactggaggaacaactgaccccggtggcggaggagacgcgggcacggctgtccaaggagctgcaggcggcgcaggcccggctgggcgcggacatggaggacgtgcgcggccgcctggtgcagtaccgcggcgaggtgcaggccatgctcggccagagcaccgaggagctgcgggtgcgcctcgcctcccacctgcgcaagctgcgtaagcggctcctccgcgatgccgatgacctgcagaagcgcctggcagtgtaccaggccggggcccgcgagggcgccgagcgcggcctcagcgccatccgcgagcgcctggggcccctggtggaacagggccgcgtgcgggccgccactgtgggctccctggccggccagccgctacaggagcgggcccaggcctggggcgagcggctgcgcgcgcggatggaggagatgggcagccggacccgcgaccgcctggacgaggtgaaggagcaggtggcggaggtgcgcgccaagctggaggagcaggcccagcagatacgcctgcaggccgaggccttccaggcccgcctcaagagctggttcgagcccctggtggaagacatgcagcgccagtgggccgggctggtggagaaggtgcaggctgccgtgggcaccagcgccgcccctgtgcccagcgacaatcactga(小写字母为终止密码子,划线部分代表apoe不同等位基因的区分位点,此序列中特指apoe4)(seq id no:26)。
68.4)利用限制性内切酶xbai(货号:r0145l,neb)和xhoi(货号:r0146l,neb)双酶切真核表达载体pcdh-cmv-mcs-ef1-3xha-puro(在上述pcdh-cmv-mcs-ef1-puro载体上自建而成,方法如下)获得线性载体。载体pcdh-cmv-mcs-ef1-3xha-puro的构建如下:首先利用xhoi(货号:r0145l,neb)和noti(货号:r3189l,neb)双酶切载体pcdh-cmv-mcs-ef1-puro获得线性载体,然后将3xha序列(tacccttatgacgtacctgactatgctggcgcctacccttatgacgtacctgactatgctggatacccttatgacgtacctgactatgcttaa(seq id no:27))与线性载体pcdh-cmv-mcs-ef1-puro连接而形成羧基端带有3xha标签的载体,即pcdh-cmv-mcs-ef1-3xha-puro。
69.5)利用exonuclease iii(货号:2170a,takara)介导的同源重组方法连接目的片段apoe2/apoe3/apoe4与已酶切的线性载体pcdh-cmv-mcs-ef1-3xha-puro,并将连接产物在e.coli dh5α中转化,并在氨苄西林(ampicillin)抗性lb固体培养基平板上获得阳性菌落克隆。
70.6)扩增阳性菌落克隆并利用质粒纯化试剂盒抽提质粒。
71.7)测序验证,获得正确的apoe2-3xha/apoe3-3xha/apoe4-3xha融合蛋白表达质粒。
72.实施例4:分泌型的hilpda促进血清中载脂蛋白与载脂颗粒的清除
73.1)在10cm细胞培养皿中用dmem培养基培养hek293t细胞。
74.2)在上述细胞中分别共转染表达gfp-flag的质粒或表达hilpda-flag的质粒和表
达apoe2/3/4-3xha三个不同等位基因的质粒。
75.3)12小时后,用新鲜的dmem细胞培养基置换1)中的旧培养基。
76.4)再培养48小时后,分别收集上述3)中培养细胞的培养基,并用此培养基直接培养已用含0.25%edta胰酶预先消化好的受体细胞,如786-o(货号:细胞库tchu186,中国科学院典型培养物保藏委员会细胞库/中国科学院上海生命科学研究院细胞资源中心),769-p(货号:细胞库tchu215,中国科学院典型培养物保藏委员会细胞库/中国科学院上海生命科学研究院细胞资源中心),huh7(货号:tchu182,中国科学院典型培养物保藏委员会细胞库/中国科学院上海生命科学研究院细胞资源中心),es-2(货号:tchu111,中国科学院典型培养物保藏委员会细胞库/中国科学院上海生命科学研究院细胞资源中心)野生型细胞。
77.5)培养24小时后,用抗-flag(货号:f1804,sigma;用于检测gfp-flag或hilpda-flag融合蛋白)和抗-ha抗体(货号:ab9110,abcam;用于检测apoe2/3/4-3xha三个不同等位基因表达的融合蛋白)执行免疫荧光染色实验。
78.6)利用激光共聚焦显微镜观察apoe-3xha和hilpda-flag的定位情况(如图2a-2d所示)。
79.图1显示了评估hilpda是否促进apoe形成的载脂颗粒的吸收策略。图2a-2d显示了hilpda存在与否条件下,细胞培养基中apoe被受体细胞吸收的情况。
80.实验结果显示:相对于用培养共表达gfp-flag和apoe2/3/4-3xha蛋白的hek293t细胞的培养基培养的受体细胞如786-o,769-p,huh7,es-2,用培养共表达hilpda-flag和apoe2/3/4-3xha蛋白的hek293t细胞的培养基培养的受体细胞中出现了更多更强的荧光信号,表明在hilpda存在下受体细胞吸收了更多的载脂蛋白apoe2/3/4(抗ha抗体组示意),也暗示hilpda促进培养基中或血清中载脂蛋白及其所形成的载脂颗粒的清除。
81.不局限于任何理论,本发明人推测分泌型的hilpda的作用机理是通过一系列胞外和胞内的信号转导通路促进人体细胞对血液中的载脂颗粒的吸收,进而对高血脂与动脉粥样硬化及相关并发疾病会起到预防或治疗作用。由于这种天然存在的小蛋白或多肽源于人体自身,在施加到病人身上之后理应具有较低的毒性,适于临床转化和推广应用,故hilpda将是一个非常具有医学和商业价值的多肽类药物。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1