基于液体活检的连锁区域甲基化评估方法和装置、终端设备及存储介质与流程
本发明涉及生物医学技术领域,尤其涉及一种基于液体活检的连锁区域甲基化评估方法和装置、终端设备及存储介质。
背景技术:
早筛、早诊、及时治疗是降低癌症死亡率的有效途径。欧洲医学肿瘤学会(esmo)指出:西方国家的癌症发病率和致死率在逐年降低,主要是归功于癌症的早期筛查,早期良性腺瘤切除以及癌症病灶的早期治疗。发现和利用肿瘤特异性生物标记物,凭借高精度的检测和分析方法,在肿瘤发生早期锁定其发生器官并实施治疗,是提升肿瘤治疗效果,延长患者寿命的关键因素。通过肿瘤的早期筛查和诊断,对于提高全民生活质量、降低全社会医疗成本均具有深远的社会和经济意义。
目前,典型的肿瘤早筛和早诊手段可以大致分为两类:第一类在现有临床检测平台基础上(例如病理切片、ct影像、肠镜、胃镜等)引入更灵敏的电子化数据分析手段,以提高检测的灵敏度,降低对人工判读的依赖性,减少人为误差,辅助临床决策;第二类从机理角度研究与肿瘤发生发展潜在相关的临床层面和分子层面的体细胞、遗传学、表观遗传学、或者代谢产物等种类的肿瘤标志物,并以这些筛查位点为基础开发新的检测平台和检测手段。
在第一类的研究方面,研究者成功将人工神经网络、多目标优化等机器学习算法运用到结肠造影ct片的判读,以更灵敏地检测结肠息肉,提早发现癌变可能。但是,对于较小结肠息肉(直径6-9mm)的影像识别能力还有待提高。基于类似的概念,一些机器学习算法也被成功用于自动判读肺部pet/ct影像,区分出良性和恶性的肺部结节,以实现对肺癌的早期诊断。代表性的算法包括支持向量机、随机森林、卷积神经网络或深度学习等。这些方法在肺癌的早期检测领域已经得到一定的应用。虽然对于低剂量pet影像的判断,基于机器学习的判读算法通常具有较高的特异性,但是灵敏性有待提高。在肝癌检测领域,机器学习算法也被用来从ct影像中区分并识别不同类别的肝损伤,包括肝囊肿、局部结节增生、肝血管瘤、慢性肝炎、肝硬化以及肝细胞癌等,及早并准确地从ct影像中识别出肝癌病变非常有利于治疗效果。类似的应用还包括对乳房x射线成像用于乳腺癌早筛,以及对前列腺组织的h&e染色活检切片进行判读来有效排除癌症阴性样本等。
在第二类的研究方面,目前临床上常用的肿瘤标志物,例如癌胚抗原(cea)、甲胎蛋白(afp)、癌抗原125(ca125)、糖类抗原19-9(ca19-9)、前列腺特异抗原(psa)等对肿瘤筛查均有一定的指导意义。但是其敏感性或特异性通常不能满足对临床诊断的需求。因此在实践上,临床医生们通常会一次同时测定多种标志物,并结合临床症状、影像学检查等其他手段综合考虑。所以单就肿瘤标志物本身而言,对健康人群的广泛筛查可推广性不高。
液体活检技术,特别是基于血浆中提取的游离dna(cfdna)的检测技术,近年来迅速成为一种重要的和最低限度侵入性肿瘤检测手段,并被广泛应用于肿瘤的诊断、病情追踪、疗效评估和预后预测工作当中。在最近的研究中,基于cfdna的基因变异检测的液体活检技术在癌症早期检测中表现出巨大的潜力,而其中的甲基化组学信号是一个重要的分支。
dna甲基化是最早发现的基因表观修饰方式之一,真核生物中的甲基化仅发生于胞嘧啶,即在dna甲基化转移酶(dnmts)的作用下使cpg岛中的5’-胞嘧啶转变为5’-甲基胞嘧啶。dna甲基化异常是肿瘤发生发展过程中的标志性事件之一。人类基因启动子区的cpg岛通常是非甲基化的状态,在癌症中cpg岛会发生明显的高甲基化现象,可能会导致一些重要的抑癌基因、dna修复基因的转录沉默,同时全基因通常呈现出去甲基化的状态,与基因组的稳定性有很大关联。这两种异常变化均与肿瘤的发生发展密切相关。dna甲基化在癌症组织和正常组织之间差异显著,在肿瘤发生过程中,dna甲基化是一个早期事件,在驱动突变发生前就已经发生。
现在已在一些研究中证明了甲基化组学优秀的区分效果,并利用机器学习模型,能同时达到癌症早筛及组织溯源的目的,补充现有影像学、痰细胞学检查和活检检查。但现有的基于甲基化组学的方法,一是在包括肺癌这种主要癌种上在早期的灵敏性还不足以满足需求;二是一些方法需要的检测成本过高操作复杂,不利于市场上普通人的推广,另外一些方法只能用于区分健康人和癌症患者,检测结果并不能满足需求。
技术实现要素:
针对上述问题,本发明提供了一种基于液体活检的连锁区域甲基化评估方法和装置、终端设备及存储介质,对待检测血浆样本的甲基化程度进行分析,提高检测灵敏度。
本发明提供的技术方案如下:
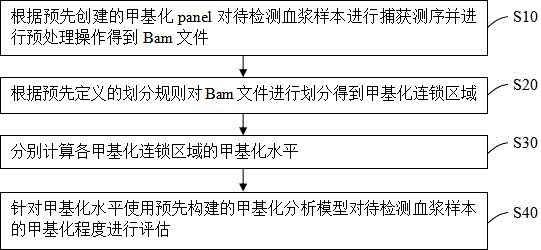
一方面,本发明提供了一种基于液体活检的连锁区域甲基化评估方法,包括:
根据预先创建的甲基化panel对待检测血浆样本进行捕获测序并进行预处理操作得到bam文件;
根据预先定义的划分规则对所述bam文件进行划分得到甲基化连锁区域,所述划分规则包括:同一甲基化连锁区域中任意相邻两个cpg位点之间的皮尔逊相关系数大于预设值,及同一甲基化连锁区域中cpg位点的数量大于预设数量;
分别计算各甲基化连锁区域的甲基化水平;
针对所述甲基化水平使用预先构建的甲基化分析模型对所述待检测血浆样本的甲基化程度进行评估。
进一步优选地,所述根据预先创建的甲基化panel对待检测血浆样本进行捕获测序并进行预处理操作得到bam文件之前,还包括创建甲基化panel的步骤,其中,针对一类型的癌种创建甲基化panel的步骤包括:
获取公共数据库中收录的泛癌队列肿瘤组织和正常组织甲基化修饰数据及公共数据集中收录的健康人外周血甲基化修饰数据,并从中选定健康人组织样本和癌组织样本;
筛选癌组织和癌旁组织之间的第一甲基化水平差异显著位点,及筛选癌组织和健康人血细胞之间的第二甲基化水平差异显著位点;
将所述第一甲基化水平差异显著位点和第二甲基化水平差异显著位点合并得到甲基化panel的核心位点,完成甲基化panel的创建。
进一步优选地,所述筛选癌组织和癌旁组织之间的第一甲基化水平差异显著位点,及筛选癌组织和健康人血细胞之间的第二甲基化水平差异显著位点之前,还包括筛选癌组织中cpg位点的步骤:
分次从随机选定的部分癌组织样本中筛选满足预设条件的cpg位点;
针对各次筛选得到的cpg位点进行进一步的筛选,将其交集作为最终选定的cpg位点;
在所述筛选癌组织和癌旁组织之间的第一甲基化水平差异显著位点中,基于所有癌组织样本和所述选定的cpg位点筛选癌组织和癌旁组织之间差异化最显著的第一数量的cpg位点,作为第一甲基化水平差异显著位点;
在所述筛选癌组织和健康人血细胞之间的第二甲基化水平差异显著位点中,基于所有癌组织样本和所述选定的cpg位点筛选癌组织和健康人血细胞之间差异化最显著的第二数量的cpg位点,作为第二甲基化水平差异显著位点。
进一步优选地,所述分次从随机选定的部分癌组织样本中筛选满足预设条件的cpg位点中,基于每个cpg位点的beta值,预设条件包括:
健康人样本和癌组织样本之间统计检验的错误发现率fdr小于第一预设阈值;
健康人血细胞的均值与标准差之和小于第二预设阈值;
过滤非cpg岛及相关区域的cpg位点;
癌组织中的均值不小于基于第三预设阈值;及
癌旁正常组织的均值与标准差之和小于第四预设阈值。
进一步优选地,在针对所述甲基化水平使用预先构建的甲基化分析模型对所述待检测血浆样本进行分类之前,还包括构建并训练甲基化分析模型的步骤,其中,针对一类型的癌种构建并训练甲基化分析模型的步骤包括:
选定健康人组织样本和癌组织样本;
根据预先定义的划分规则对所述癌组织样本的bam文件进行划分得到甲基化连锁区域,并分别计算各甲基化连锁区域的甲基化水平;
对各甲基化连锁区域的甲基化水平进行log2(x+1)变换,其中,x为甲基化连锁区域的甲基化水平;
对变换后的甲基化水平进行标准化处理,计算z-score值;
通过交叉验证递归式特征消除的方法进行特征筛选得到部分甲基化连锁区域作为最终特征;
基于筛选得到的甲基化连锁区域对构建的甲基化分析模型进行训练,得到最佳甲基化分析模型。
进一步优选地,所述对各甲基化连锁区域的甲基化水平进行log2(x+1)变换之前,还包括筛选甲基化连锁区域的步骤:
根据预先创建的甲基化panel分别对健康人组织样本和癌组织样本进行捕获测序;
分别通过方差分析、费希尔精确检验、卡方检验、wilcoxon秩和检验、曼-惠特尼检验及t检验6个指标计算癌症组织样本和健康人组织样本之间各甲基化连锁区域的差异程度;
根据计算结果对甲基化连锁区域进行筛选,当一甲基化连锁区域所述6个指标中至少4个的结果为癌症组织样本和健康人组织样本之间的p值小于预设值,保留该差异显著的甲基化连锁区域。
另一方面,本发明还提供了一种基于液体活检的连锁区域甲基化评估装置,包括:
待检测血浆样本处理模块,用于根据预先创建的甲基化panel对待检测血浆样本进行捕获测序并进行预处理操作得到bam文件;
连锁区域划分模块,用于根据预先定义的划分规则对所述bam文件进行划分得到甲基化连锁区域,所述划分规则包括:同一甲基化连锁区域中任意相邻两个cpg位点之间的皮尔逊相关系数大于预设值,及同一甲基化连锁区域中cpg位点的数量大于预设数量;
甲基化水平计算模块,用于分别计算各甲基化连锁区域的甲基化水平;
甲基化程度评估模块,用于针对所述甲基化水平使用预先构建的甲基化分析模型对所述待检测血浆样本的甲基化程度进行评估。
进一步优选地,所述连锁区域甲基化评估装置中还包括甲基化panel创建模块,包括:
样本选定单元,用于获取公共数据库中收录的泛癌队列肿瘤组织和正常组织甲基化修饰数据及公共数据集中收录的健康人外周血甲基化修饰数据,并从中选定健康人组织样本和癌组织样本;
差异显著位点筛选模块,用于筛选癌组织和癌旁组织之间的第一甲基化水平差异显著位点,及筛选癌组织和健康人血细胞之间的第二甲基化水平差异显著位点;
核心位点获取模块,用于将所述第一甲基化水平差异显著位点和第二甲基化水平差异显著位点合并得到甲基化panel的核心位点,完成甲基化panel的创建。
进一步优选地,所述连锁区域甲基化评估装置中还包括cpg位点筛选模块,用于分次从选定的部分样本中筛选满足预设条件的cpg位点,及针对各次筛选得到的cpg位点进行进一步的筛选,将其交集作为最终选定的cpg位点;
在所述差异显著位点筛选模块中,基于所有癌组织样本和所述选定的cpg位点筛选癌组织和癌旁组织之间差异化最显著的第一数量的cpg位点,作为第一甲基化水平差异显著位点;及基于所有癌组织样本和所述选定的cpg位点筛选癌组织和健康人血细胞之间差异化最显著的第二数量的cpg位点,作为第二甲基化水平差异显著位点。
进一步优选地,在所述cpg位点筛选模块中,基于每个cpg位点的beta值,预设条件包括:
健康人样本和癌组织样本之间统计检验的错误发现率fdr小于第一预设阈值;
健康人血细胞的均值与标准差之和小于第二预设阈值;
过滤非cpg岛及相关区域的cpg位点;
癌组织中的均值不小于基于第三预设阈值;及
癌旁正常组织的均值与标准差之和小于第四预设阈值。
进一步优选地,所述连锁区域甲基化评估装置中还包括甲基化分析模型构建及训练模块,包括:
样本选定单元,用于选定健康人组织样本和癌组织样本;
甲基化水平计算单元,用于根据预先定义的划分规则对所述癌组织样本的bam文件进行划分得到甲基化连锁区域,并分别计算各甲基化连锁区域的甲基化水平;
甲基化水平变换单元,用于对各甲基化连锁区域的甲基化水平进行log2(x+1)变换,其中,x为甲基化连锁区域的甲基化水平;
标准化单元,用于对变换后的甲基化水平进行标准化处理,计算z-score值;
特征筛选单元,用于通过交叉验证递归式特征消除的装置进行特征筛选得到部分甲基化连锁区域作为最终特征;
模型训练单元,用于基于筛选得到的甲基化连锁区域对构建的甲基化分析模型进行训练,得到最佳甲基化分析模型。
进一步优选地,所述连锁区域甲基化评估装置中还包括甲基化连锁区域筛选模块,包括:
预处理单元,用于根据预先创建的甲基化panel分别对健康人组织样本和癌组织样本进行捕获测序;
指标计算单元,用于分别通过方差分析、费希尔精确检验、卡方检验、wilcoxon秩和检验、曼-惠特尼检验及t检验6个指标计算癌症组织样本和健康人组织样本之间各甲基化连锁区域的差异程度;
筛选单元,用于根据所述指标计算单元的计算结果对甲基化连锁区域进行筛选,当一甲基化连锁区域所述6个指标中至少4个的结果为癌症组织样本和健康人组织样本之间的p值小于预设值,保留该差异显著的甲基化连锁区域。
另一方面,本发明还提供了一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时实现上述循环无细胞核小体活性区域的甲基化评估方法的步骤。
另一方面,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上述循环无细胞核小体活性区域的甲基化评估方法的步骤。
本发明提供的基于液体活检的连锁区域甲基化评估方法和装置、终端设备及存储介质,通过设计甲基化panel及划分甲基化连锁区域将基因组分成多个内部相关联的区间,使用机器学习的方法筛选特征并建模,以此降低单个cpg位点出现假阳性降低检测灵敏度的问题。相比单个肿瘤标志蛋白cea和临床常规pet-ct筛查结果,该连锁区域甲基化评估方法及装置能够大大提高样本甲基化程度分析的灵敏度和特异性,为后续区分待检测血浆样本是否来源于癌症组织提供依据,尤其能够提高某些良性结节、早期癌症患者的检测灵敏度,从而有效辅助癌症的早期诊断以及癌症的早期筛查,提高筛查效率和精度。
附图说明
下面将以明确易懂的方式,结合附图说明优选实施方式,对上述特性、技术特征、优点及其实现方式予以进一步说明。
图1为本发明基于液体活检的连锁区域甲基化评估方法一种实施例流程示意图;
图2为一实例中cfdna甲基化roc曲线;
图3为本发明基于液体活检的连锁区域甲基化评估装置一种实施例结构示意图;
图4为本发明中终端设备结构示意图。
附图标记:
100-连锁区域甲基化评估装置,110-待检测血浆样本处理模块,120-连锁区域划分模块,130-甲基化水平计算模块,140-甲基化程度评估模块。
具体实施方式
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
本发明的第一种实施例,一种基于液体活检的连锁区域甲基化评估方法,如图1所示,包括:s10根据预先创建的甲基化panel对待检测血浆样本进行捕获测序并进行预处理操作得到bam文件;s20根据预先定义的划分规则对bam文件进行划分得到甲基化连锁区域,划分规则包括:同一甲基化连锁区域中任意相邻两个cpg位点之间的皮尔逊相关系数大于预设值,及同一甲基化连锁区域中cpg位点的数量大于预设数量;s30分别计算各甲基化连锁区域的甲基化水平;s40针对甲基化水平使用预先构建的甲基化分析模型对待检测血浆样本的甲基化程度进行评估。
在本实施例中,捕获测序得到fastq文件之后随即对其进行预处理操作,包括比对去重、过滤、排序、建立索引等。在一实例中,首先,调用trimmomatic将每一对fastq文件都作为成对(paired)reads进行去除接头和低质量碱基处理,生成去接头后的fastq文件。具体,在切除接头序列后,切去剩余部分开头和结尾处碱基质量低于20的碱基,从reads的5’端开始,以大小为5的窗口进行划窗计算平均质量,如果窗口内平均碱基质量低于20,则切除该窗口,并要求切除后剩余碱基数量超过75。之后,调用bismark(一种比对方法软件,用于查找测序序列在基因参考序列中的位置,可输出bam格式结果文件)将每一对fastq文件作为成对reads与hg19人类参考基因组序列进行比对去重,生成初始bam文件和比对报告。之后,调用samtools对初始bam文件按照染色体位置进行排序;接着,为了更准确的计算甲基化水平,调用bamutil去除成对reads之间的重叠区间。之后,调用samtools中的view命令对去除了重叠区域的bam文件进行筛选,对比对质量(用于量化比对到错误位置的可能性,值越高表示可能性越低)进行过滤,要求比对质量超过20,生成最终的bam文件;使用内部脚本过滤每个read上非cpg的c-t转化率低于95%的reads(考虑实验转化率对结果的影响,增加对每条read的转化率的过滤)。最后,调用samtools中的index模块对最终生成的bam文件建立索引,生成与标记重复后的bam文件配对的bai文件。
预处理完成之后,进入甲基化连锁区域(methylation-correlatedblock,mcb)划分的步骤,使得同一mcb中任意相邻两个cpg位点之间的皮尔逊相关系数大于预设值及同一mcb中cpg位点的数量大于预设数量,且将mcb中包含的所有cpg位点beta值的均值作为该mcb的甲基化水平。最后针对甲基化水平使用预先构建的甲基化分析模型(logistic模型、svm模型等)对待检测血浆样本的甲基化程度进行评估,若判断待检测血浆样本甲基化程度高,表示其可能来源于癌症血浆样本;若判断待检测血浆样本甲基化程度低,表示其可能来源于健康人血浆样本,甲基化程度高/低由训练后的甲基化分析模型判定。在此基础上,在后续诊断过程中可以辅助医生进行综合判断,为诊断结果提供部分依据,辅助癌症筛查工作,尤其是早期癌症的诊断和筛查。对于甲基化分析模型的输出结果,还可以为甲基化分析模型对于待检测血浆样本属性的预测及其预测概率,如预测待检测血浆样本患有恶性结节的可能性、患有良性结节的可能性等,为后续医生进行诊断提供部分依据。对于皮尔逊相关系数的预设值和同一mcb中cpg位点的预设数量均可以根据实际应用进行设定,如,皮尔逊相关系数的预设值可以根据实际应用设定为0.7、0.75、0.8、0.85、0.9、0.95等;同一mcb中cpg位点的预设数量可以根据实际应用设定为3个、4个、5个、6个等。在一实例中,皮尔逊相关系数的预设值为0.9;同一mcb中cpg位点的预设数量为3个。
在本实施例中,通过联合基因组物理位置相近的cpg位点成为检测区域(mcb),以检测区域的整体甲基化修饰水平作为早筛检测的定量结果,可以避免单点检测噪音对实际信号的影响。
对上述实施例进行改进,在步骤s10根据预先创建的甲基化panel对待检测血浆样本进行捕获测序并进行预处理操作得到bam文件之前,还包括创建甲基化panel的步骤,其中,针对一类型的癌种创建甲基化panel的步骤包括:s01获取公共数据库(tgga)中收录的泛癌队列肿瘤组织和正常组织甲基化修饰数据,及公共数据集(gse40279)中收录的健康人外周血甲基化修饰数据,并从中选定健康人组织样本和癌组织样本;s02筛选癌组织和癌旁组织之间的第一甲基化水平差异显著位点,及筛选癌组织和健康人血细胞之间的第二甲基化水平差异显著位点;s03将第一甲基化水平差异显著位点和第二甲基化水平差异显著位点合并得到甲基化panel的核心位点,完成甲基化panel的创建。
在本实施例中,由于健康人血浆中cfdna主要来源于血细胞,而癌症病人血浆中还包含癌组织释放的ctdna,是以除了筛选癌组织和癌旁组织之间的第一甲基化水平差异显著位点(dmp)之外,进一步筛选癌组织和健康人血细胞之间的第二甲基化水平差异显著位点,进而合并两个甲基化水平差异显著位点得到差异区间dmr,作为甲基化panel的核心位点,最大化甲基化panel在癌症患者与健康人之间的差异。在其他实施例中,为了方便panel的设计,还可以对合并得到的差异区间dmr进行进一步合并,如将间隔不超过250bp(可根据实际情况进行设定,还可以限定为200bp、300bp等甚至更大)的两个dmp可以合并在一个dmr上等。
为了进一步提高检测效率,在筛选癌组织和癌旁组织之间的第一甲基化水平差异显著位点,及筛选癌组织和健康人血细胞之间的第二甲基化水平差异显著位点之前,还包括筛选癌组织中cpg位点的步骤,具体:分次(如5次、10次、15次甚至更多)从随机选定的部分癌组织样本(如1/2样本、2/3样本、3/4样本等)中筛选满足预设条件的cpg位点;针对各次筛选得到的cpg位点进行进一步的筛选,将其交集作为最终选定的cpg位点。以此,基于所有癌组织样本和选定的cpg位点筛选癌组织和癌旁组织之间差异化最显著的第一数量(如400、500、600等甚至更多)的cpg位点,作为第一甲基化水平差异显著位点;基于所有癌组织样本和选定的cpg位点筛选癌组织和健康人血细胞之间差异化最显著的第二数量(如4500、5000、5500等甚至更多)的cpg位点,作为第二甲基化水平差异显著位点,最后合并两部分选择到的甲基化水平差异显著位点为甲基化panel的核心位点。
在本实施例筛选满足预设条件的cpg位点中,针对同一次甲基化panel创建,每次选定的癌组织样本数量相同,如分5次依次从随机选定的2/3癌组织样本中筛选满足预设条件的cpg位点等。具体,筛选cpg位点的预设条件包括:健康人样本和癌组织样本之间统计检验的错误发现率fdr小于第一预设阈值(如0.001、0.005、0.01、0.05、0.1、0.2等);健康人血细胞的均值与标准差之和小于第二预设阈值(如0.05、0.1、0.2、0.5等);过滤非cpg岛及相关区域的cpg位点(如过滤opensea区域等);癌组织中的均值不小于基于第三预设阈值(如0.1、0.2、0.3、0.5等);及癌旁正常组织(应尽量选择与癌种对应的正常组织)的均值与标准差之和小于第四预设阈值(如0.05、0.1、0.2、0.5等)。应当清楚,在实际应用中,对于cpg位点的筛选条件可以根据实际情况进行设定,甚至从上述条件中选定部分作为筛选依据。
在一实例中,对于一个类型的癌种,每次选择该癌种全部样本的2/3筛选满足条件的cpg点,重复10次,选定10次中都被选中的cpg点作为最终cpg点。之后使用全部样本,计算选定的最终cpg点中癌组织和癌旁组织中差异最显著的500个点作为第一甲基化水平差异显著位点,对于癌组织和健康人血细胞中差异最显著的5000个点作为第二甲基化水平差异显著位点,最后合并得到该癌种甲基化panel的核心位点。在实际应用中,往往需要对多癌种的甲基化panel进行创建,以此在本实例中,基于获取的公共数据库(tgga)和公共数据集(gse40279),多癌种的第一甲基化水平差异显著位点取并集获得5434个cpg位点,第二甲基化水平差异显著位点取并集获得15880个cpg位点,合并两部分位点得到覆盖1590035bp长度的区域。
在本实施例中,同时筛选出对泛癌种具有较高普适性以及对单一癌种具有较高特异性的cpg位点并进行合并,在保证检测具有较高灵敏性和特异性的前提下,精简检测位点,从而降低检测成本、提高检测效率,对癌种的判断也具有一定参考价值。在实验技术方面,保证技术实现稳定性的同时,保留允许检测panel升级的灵活性。
在另一实施例,在步骤s40针对甲基化水平使用预先构建的甲基化分析模型对待检测血浆样本进行分类之前,还包括构建并训练甲基化分析模型的步骤,其中,针对一类型的癌种构建并训练甲基化分析模型的步骤包括:s04选定健康人组织样本和癌组织样本;s05根据预先定义的划分规则对所述癌组织样本的bam文件进行划分得到甲基化连锁区域,并分别计算各甲基化连锁区域的甲基化水平;s06对各甲基化连锁区域的甲基化水平进行log2(x+1)变换,其中,x为甲基化连锁区域的甲基化水平;s07对变换后的甲基化水平进行标准化处理,计算z-score值;s08通过交叉验证递归式特征消除的方法进行特征筛选得到部分甲基化连锁区域作为最终特征;s09基于筛选得到的甲基化连锁区域对构建的甲基化分析模型进行训练,得到最佳甲基化分析模型。
在本实施例中,在构建并训练甲基化分析模型之前,先对各甲基化连锁区域的甲基化水平进行log2(x+1)变换,对于缺失数据,使用同一组别对应甲基化连锁区域的中位值填充,其中,x表示甲基化连锁区域的甲基化水平;之后根据式z=(x–mean(x))/std(x)进行标准化处理计算z-score值,其中,x表示同一样本组别对应mcb的甲基化水平。
之后,使用交叉验证递归式特征消除的方法(recursivefeatureeliminationwithcross-validation,简称rfecv)对甲基化连锁区域进一步进行特征筛选以最佳化模型的效果。在一实例中,从20%的测试集和80%的训练集开始拆分数据,同时使用线性支持向量机(linearsupportvectorregression,简称linearsvr)和xgboost回归做重复迭代次数为10的交叉验证对特征进行排序,每次测试集增加1%的大小剩余的作为训练集,直到40%的测试集、60%的训练集结束,共20个比例的拆分组合。最终选择n(任意整数)个甲基化连锁区域作为最终的特征。基于此,基于13-fold交叉验证,使用线性内核svm训练甲基化分析模型表现。在每个fold中,随机选择60%的样本作为训练集,40%作为测试集,通过交叉验证穷举网格搜索(gridexhaustivesearch)最优化超参数(hyper-parameter),得到最佳的甲基化分析模型。最后使用独立的样本集作为验证集,对训练得到的甲基化分析模块进行验证。应当清楚,这里仅示例性的给出一种甲基化分析模型的结构及其训练方法,在其他实例中,甲基化分析模型结构及其训练参数均可根据实际情况进行调整,这里不做具体限定,只要能够实现本实施例的目的均包括在其范围内。
为了进一步提升检测精度,在对各甲基化连锁区域的甲基化水平进行log2(x+1)变换之前,还包括筛选甲基化连锁区域的步骤,包括:s31根据预先创建的甲基化panel分别对癌症组织样本和健康人组织样本进行捕获测序;s32针对一类型的癌种,分别通过方差分析(anova)、费希尔精确检验(fisher’sexacttest)、卡方检验(chi-squaretest)、wilcoxon秩和检验(wilcoxonranksumtest)、曼-惠特尼检验(mann-whitneytest)及t检验(student’st-test)6个指标计算癌症组织样本和健康人组织样本之间各甲基化连锁区域的差异程度;s33根据计算结果对甲基化连锁区域进行筛选,当一甲基化连锁区域6个指标中至少4个的结果为癌症组织样本和健康人组织样本之间的p值小于预设值(可根据实际情况进行设定,如设定为0.1等),保留该差异显著的甲基化连锁区域。之后基于保留的甲基化连锁区域对甲基化分析模型进行训练。对于选定的用于计算癌症组织样本和健康人组织样本之间各甲基化连锁区域差异程度的检验方法,在其他实施例中还可以根据实际应用进行调整,如还以采用基于二项分布和泊松分布的检验方法等,只要能够实现发明目的即可。
以下通过一实例对上述基于液体活检的连锁区域甲基化评估方法及其有益效果进行说明:
一、实验流程:
1.血浆cfdna提取
使用游离dna提取试剂盒(thermocat#a29319)提取待检测血浆样本的cfdna。提取后使用labchip质检是否存在大量基因组污染(>600bp占比小于30%)。对产量大于10ng且无基因组污染的cfdna进行后续建库。
2.cfdna甲基化建库
使用甲基化文库构建试剂盒(swiftcat#30096)对提取的cfdna进行甲基化建库。使用qubit高灵敏试剂(thermocat#q32854)对文库进行定量,文库产量大于400ng进行后续实验。
3.文库捕获
将文库混合到一个1.5ml离心管中,加入封闭试剂,放入真空离心浓缩仪中蒸干。样本完全蒸干后,每个捕获中加入2×杂交缓冲液(vial5)和杂交组分a(vial6)(rochecat#5634253001),置于95℃变性10min。加入预先创建的甲基化肺癌探针,47℃杂交60-72h,使用杂交纯化试剂(rochecat#5634253001)和纯化磁珠(cat#6977952001)纯化并扩增捕获样本。使用qubit高灵敏试剂(thermocat#q32854)对文库进行定量。
4.捕获后上机
将捕获后的样本用illumina平台进行上机。
二、数据分析流程:
2.1比对并去重:调用bismark将每一对fastq文件都作为成对reads比对到hg19人类参考基因组序列,生成初始bam文件;调用bismark去除初始bam文件中的重复序列;
2.2排序:调用samtools,对去除重复序列的初始bam文件按照染色体位置进行排序;
2.3去除成对reads之间的重叠区间:调用bamutil去除成对reads之间的重叠区间;
2.4过滤:调用samtools中的view指令对上述bam文件进行筛选,过滤低比对质量的reads,要求比对质量超过20,生成最终的bam文件。使用内部脚本过滤每个read上非cpg的c-t转化率低于95%的reads;
2.5建立索引:调用samtools的index模块对最终生成的bam文件建立索引,生成与标记重复后的bam文件配对的bai文件。
计算每个mcb的甲基化水平
2.6.1计算单点的beta值(单点的甲基化水平):调用bissnp得到每个cpg位点的beta值;
2.6.2统计每个mcb上包含的cpg点的平均甲基化水平,作为各mcb的甲基化水平。
三、机器学习建模
3.1选两组样本,一组癌症患者(n=70),一组良性结节的病人(n=70),分别经过数据预处理、特征筛选和模型训练步骤,得到最终的甲基化分析模型。
3.2取独立验证集,包含已知的癌症患者(n=30)和良性结节患者(n=30),对构建的甲基化分析模型进行验证并统计结果。如图2所示,最终roc曲线下的面积auc=0.9。可见构建的甲基化分析模型具有较好的甲基化分析效果,能够较好的辅助医生区分样本的良恶性(癌症患者或是良性结节患者)。
本发明的另一实施例,一种基于液体活检的连锁区域甲基化评估装置100,如图3所示,包括:待检测血浆样本处理模块110,用于根据预先创建的甲基化panel对待检测血浆样本进行捕获测序并进行预处理操作得到bam文件;连锁区域划分模块120,用于根据预先定义的划分规则对bam文件进行划分得到甲基化连锁区域,划分规则包括:同一甲基化连锁区域中任意相邻两个cpg位点之间的皮尔逊相关系数大于预设值,及同一甲基化连锁区域中cpg位点的数量大于预设数量;甲基化水平计算模块130,用于分别计算各甲基化连锁区域的甲基化水平;甲基化程度评估模块140,用于针对甲基化水平使用预先构建的甲基化分析模型对待检测血浆样本的甲基化程度进行评估。
在本实施例中,待检测血浆样本处理模块110捕获测序得到fastq文件之后随即对其进行预处理操作,包括比对去重、过滤、排序、建立索引等。在一实例中,首先,调用trimmomatic将每一对fastq文件都作为成对(paired)reads进行去除接头和低质量碱基处理,生成去接头后的fastq文件。具体,在切除接头序列后,切去剩余部分开头和结尾处碱基质量低于20的碱基,从reads的5’端开始,以大小为5的窗口进行划窗计算平均质量,如果窗口内平均碱基质量低于20,则切除该窗口,并要求切除后剩余碱基数量超过75。之后,调用bismark将每一对fastq文件作为成对reads与hg19人类参考基因组序列进行比对去重,生成初始bam文件和比对报告。之后,调用samtools对初始bam文件按照染色体位置进行排序;接着,为了更准确的计算甲基化水平,调用bamutil去除成对reads之间的重叠区间。之后,调用samtools中的view命令对去除了重叠区域的bam文件进行筛选,对比对质量(用于量化比对到错误位置的可能性,值越高表示可能性越低)进行过滤,要求比对质量超过20,生成最终的bam文件;使用内部脚本过滤每个read上非cpg的c-t转化率低于95%的reads(考虑实验转化率对结果的影响,增加对每条read的转化率的过滤)。最后,调用samtools中的index模块对最终生成的bam文件建立索引,生成与标记重复后的bam文件配对的bai文件。
预处理完成之后,连锁区域划分模块120开始对甲基化连锁区域(mcb)进行划分,使得同一mcb中任意相邻两个cpg位点之间的皮尔逊相关系数大于预设值及同一mcb中cpg位点的数量大于预设数量,且甲基化水平计算模块130计算得到各cpg位点的beta值(实例中可调用bissnp进行计算)之后,将mcb中包含的所有cpg位点beta值的均值作为该mcb的甲基化水平。最后甲基化程度评估模块140针对甲基化水平使用预先构建的甲基化分析模型(logistic模型、svm模型等)对待检测血浆样本的甲基化程度进行评估,若判断待检测血浆样本甲基化程度高,表示其可能来源于癌症血浆样本;若判断待检测血浆样本甲基化程度低,表示其可能来源于健康人血浆样本,甲基化程度高/低由训练后的甲基化分析模型判定。在此基础上,在后续诊断过程中可以辅助医生进行综合判断,为诊断结果提供部分依据,辅助癌症筛查工作,尤其是早期癌症的诊断和筛查。。对于甲基化分析模型的输出结果,还可以为甲基化分析模型对于待检测血浆样本属性的预测及其预测概率,如预测待检测血浆样本患有恶性结节的可能性、患有良性结节的可能性等,为后续医生进行诊断提供部分依据。对于皮尔逊相关系数的预设值和同一mcb中cpg位点的预设数量均可以根据实际应用进行设定,如,皮尔逊相关系数的预设值可以根据实际应用设定为0.7、0.75、0.8、0.85、0.9、0.95等;同一mcb中cpg位点的预设数量可以根据实际应用设定为3个、4个、5个、6个等。
对上述实施例进行改进,上述连锁区域甲基化评估装置100中还包括甲基化panel创建模块,包括:样本选定单元,用于获取公共数据库中收录的泛癌队列肿瘤组织和正常组织甲基化修饰数据及公共数据集中收录的健康人外周血甲基化修饰数据,并从中选定健康人组织样本和癌组织样本;差异显著位点筛选模块,用于筛选癌组织和癌旁组织之间的第一甲基化水平差异显著位点,及筛选癌组织和健康人血细胞之间的第二甲基化水平差异显著位点;核心位点获取模块,用于将所述第一甲基化水平差异显著位点和第二甲基化水平差异显著位点合并得到甲基化panel的核心位点,完成甲基化panel的创建。
在本实施例中,由于健康人血浆中cfdna主要来源于血细胞,而癌症病人血浆中还包含癌组织释放的ctdna,是以除了筛选癌组织和癌旁组织之间的第一甲基化水平差异显著位点(dmp)之外,进一步筛选癌组织和健康人血细胞之间的第二甲基化水平差异显著位点,进而合并两个甲基化水平差异显著位点得到差异区间dmr,作为甲基化panel的核心位点,最大化甲基化panel在癌症患者与健康人之间的差异。在其他实施例中,为了方便panel的设计,还可以对合并得到的差异区间dmr进行进一步合并,如将间隔不超过250bp的两个dmp可以合并在一个dmr上等。
为了进一步提高检测效率,连锁区域甲基化评估装置100中还包括cpg位点筛选模块,具体:分次(如5次、10次、15次甚至更多)从随机选定的部分癌组织样本(如1/2样本、2/3样本、3/4样本等)中筛选满足预设条件的cpg位点;针对各次筛选得到的cpg位点进行进一步的筛选,将其交集作为最终选定的cpg位点。以此,差异显著位点筛选模块基于所有癌组织样本和选定的cpg位点筛选癌组织和癌旁组织之间差异化最显著的第一数量(如400、500、600等甚至更多)的cpg位点,作为第一甲基化水平差异显著位点;基于所有癌组织样本和选定的cpg位点筛选癌组织和健康人血细胞之间差异化最显著的第二数量(如4500、5000、5500等甚至更多)的cpg位点,作为第二甲基化水平差异显著位点,最后合并两部分选择到的甲基化水平差异显著位点为甲基化panel的核心位点。
在本实施例筛选满足预设条件的cpg位点中,针对同一次甲基化panel创建,每次选定的癌组织样本数量相同,如分5次依次从随机选定的2/3癌组织样本中筛选满足预设条件的cpg位点等。具体,筛选cpg位点的预设条件包括:健康人样本和癌组织样本之间统计检验的错误发现率fdr小于第一预设阈值(如0.001、0.005、0.01、0.05、0.1、0.2等);健康人血细胞的均值与标准差之和小于第二预设阈值(如0.05、0.1、0.2、0.5等);过滤非cpg岛及相关区域的cpg位点(如过滤opensea区域等);癌组织中的均值不小于基于第三预设阈值(如0.1、0.2、0.3、0.5等);及癌旁正常组织(应尽量选择与癌种对应的正常组织)的均值与标准差之和小于第四预设阈值(如0.05、0.1、0.2、0.5等)。
在另一实施例中,上述连锁区域甲基化评估装置100中还包括甲基化分析模型构建及训练模块,包括:样本选定单元,用于选定健康人组织样本和癌组织样本;甲基化水平计算单元,用于根据预先定义的划分规则对所述癌组织样本的bam文件进行划分得到甲基化连锁区域,并分别计算各甲基化连锁区域的甲基化水平;甲基化水平变换单元,用于对各甲基化连锁区域的甲基化水平进行log2(x+1)变换,其中,x为甲基化连锁区域的甲基化水平;标准化单元,用于对变换后的甲基化水平进行标准化处理,计算z-score值;特征筛选单元,用于通过交叉验证递归式特征消除的装置100进行特征筛选得到部分甲基化连锁区域作为最终特征;模型训练单元,用于基于筛选得到的甲基化连锁区域对构建的甲基化分析模型进行训练,得到最佳甲基化分析模型。
在本实施例中,在构建并训练甲基化分析模型之前,先对各甲基化连锁区域的甲基化水平进行log2(x+1)变换,对于缺失数据,使用同一组别对应甲基化连锁区域的中位值填充,其中,x表示甲基化连锁区域的甲基化水平;之后根据式z=(x–mean(x))/std(x)进行标准化处理计算z-score值,其中,x表示同一组别对应mcb的甲基化水平。
之后,使用交叉验证递归式特征消除的方法对甲基化连锁区域进一步进行特征筛选以最佳化模型的效果。在一实例中,从20%的测试集和80%的训练集开始拆分数据,同时使用线性支持向量机和xgboost回归做重复迭代次数为10的交叉验证对特征进行排序,每次测试集增加1%的大小剩余的作为训练集,直到40%的测试集、60%的训练集结束,共20个比例的拆分组合。最终选择n(任意整数)个甲基化连锁区域作为最终的特征。基于此,基于13-fold交叉验证,使用线性内核svm训练模型表现。在每个fold中,随机选择60%的样本作为训练集,40%作为测试集,通过交叉验证穷举网格搜索(gridexhaustivesearch)最优化超参数(hyper-parameter),得到最佳的甲基化分析模型。最后使用独立的样本集作为验证集,对训练得到的甲基化分析模块进行验证。应当清楚,这里仅示例性的给出一种甲基化分析模型的结构及其训练方法,在其他实例中,甲基化分析模型结构及其训练参数均可根据实际情况进行调整,这里不做具体限定,只要能够实现本实施例的目的均包括在其范围内。
为了进一步提升检测精度,上述连锁区域甲基化评估装置100中还包括甲基化连锁区域筛选模块,包括:预处理单元,用于根据预先创建的甲基化panel分别对健康人组织样本和癌组织样本进行捕获测序;指标计算单元,用于分别通过方差分析(anova)、费希尔精确检验(fisher’sexacttest)、卡方检验(chi-squaretest)、wilcoxon秩和检验(wilcoxonranksumtest)、曼-惠特尼检验(mann-whitneytest)及t检验(student’st-test)6个指标计算癌症组织样本和健康人组织样本之间各甲基化连锁区域的差异程度;筛选单元,用于根据所述指标计算单元的计算结果对甲基化连锁区域进行筛选,当一甲基化连锁区域所述6个指标中至少4个的结果为癌症组织样本和健康人组织样本之间的p值小于预设值,保留该差异显著的甲基化连锁区域。
预处理单元,用于根据预先创建的甲基化panel分别对癌症组织样本和健康人组织样本进行捕获测序;指标计算单元,用于针对一类型的癌种,分别通过方差分析(anova)、费希尔精确检验(fisher’sexacttest)、卡方检验(chi-squaretest)、wilcoxon秩和检验(wilcoxonranksumtest)、曼-惠特尼检验(mann-whitneytest)及t检验(student’st-test);筛选单元,用于根据指标计算单元的计算结果对甲基化连锁区域进行筛选,当一甲基化连锁区域6个指标中至少4个的结果为癌症组织样本和健康人组织样本之间的p值小于预设值(可根据实际情况进行设定,如设定为0.1等),保留该差异显著的甲基化连锁区域。之后基于保留的甲基化连锁区域对甲基化分析模型进行训练。
所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,仅以上述各程序模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的程序模块完成,即将装置的内部结构划分成不同的程序单元或模块,以完成以上描述的全部或者部分功能。实施例中的各程序模块可以集成在一个处理单元中,也可是各个单元单独物理存在,也可以两个或两个以上单元集成在一个处理单元中,上述集成的单元既可以采用硬件的形式实现,也可以采用软件程序单元的形式实现。另外,各程序模块的具体名称也只是为了便于相互区分,并不用于限制本申请的保护范围。
图4是本发明一个实施例中提供的终端设备的结构示意图,如所示,该终端设备200包括:处理器220、存储器210以及存储在存储器210中并可在处理器220上运行的计算机程序211,例如:循环无细胞核小体活性区域的甲基化评估方法关联程序。处理器220执行计算机程序211时实现上述各个循环无细胞核小体活性区域的甲基化评估方法实施例中的步骤,或者,处理器220执行计算机程序211时实现上述循环无细胞核小体活性区域的甲基化分析装置实施例中各模块的功能。
终端设备200可以为笔记本、掌上电脑、平板型计算机、手机等设备。终端设备200可包括,但不仅限于处理器220、存储器210。本领域技术人员可以理解,图4仅仅是终端设备200的示例,并不构成对终端设备200的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件,例如:终端设备200还可以包括输入输出设备、显示设备、网络接入设备、总线等。
处理器220可以是中央处理单元(centralprocessingunit,cpu),还可以是其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现场可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器220可以是微处理器或者该处理器也可以是任何常规的处理器等。
存储器210可以是终端设备200的内部存储单元,例如:终端设备200的硬盘或内存。存储器210也可以是终端设备200的外部存储设备,例如:终端设备200上配备的插接式硬盘,智能tf存储卡(smartmediacard,smc),安全数字(securedigital,sd)卡,闪存卡(flashcard)等。进一步地,存储器210还可以既包括终端设备200的内部存储单元也包括外部存储设备。存储器210用于存储计算机程序211以及终端设备200所需要的其他程序和数据。存储器210还可以用于暂时地存储已经输出或者将要输出的数据。
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详细描述或记载的部分,可以参见其他实施例的相关描述。
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
在本申请所提供的实施例中,应该理解到,所揭露的装置/终端设备和方法,可以通过其他的方式实现。例如,以上所描述的装置/终端设备实施例仅仅是示意性的,例如,模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如,多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通讯连接可以是通过一些接口,装置或单元的间接耦合或通讯连接,可以是电性、机械或其他的形式。
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本申请各个实施例中的各功能单元可能集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
集成的模块/单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读存储介质中。基于这样的理解,本发明实现上述实施例方法中的全部或部分流程,也可以通过计算机程序211发送指令给相关的硬件完成,的计算机程序211可存储于一计算机可读存储介质中,该计算机程序211在被处理器220执行时,可实现上述各个方法实施例的步骤。其中,计算机程序211包括:计算机程序代码,计算机程序代码可以为源代码形式、对象代码形式、可执行文件或某些中间形式等。计算机可读存储介质可以包括:能够携带计算机程序211代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、电载波信号、电信信号以及软件分发介质等。需要说明的是,计算机可读存储介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如:在某些司法管辖区,根据立法和专利实践,计算机可读介质不包括电载波信号和电信信号。
应当说明的是,上述实施例均可根据需要自由组合。以上仅是本发明的优选实施方式,应当指出,对于本技术领域的普通相关人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!