基于半导体测序的降低无创产前检测假阳性假阴性的方法与流程
1.本发明涉及产前诊断分子遗传学检测技术领域,特别涉及一种基于半导体测序的降低无创产前检测假阳性假阴性的方法。
背景技术:
2.无创产前基因检测(non
‑
invasive prenatal testing,简称nipt)是通过分离孕妇外周血中游离的dna(cellfree dna,简称cf dna),利用大规模平行测序技术(massivelyparallel sequencing,mps)获得胎儿染色体信息,分析胎儿染色体是否存在非整倍体异常风险的技术。目前临床上染色体数目异常的产前诊断方法仍然是创伤性的,穿刺取样会造成一定比例的流产。nipt这种无创性采样方式(只需抽取5ml外周血)更容易被众多孕妇受检者接受。近年来nipt在产前诊断中大规模应用。
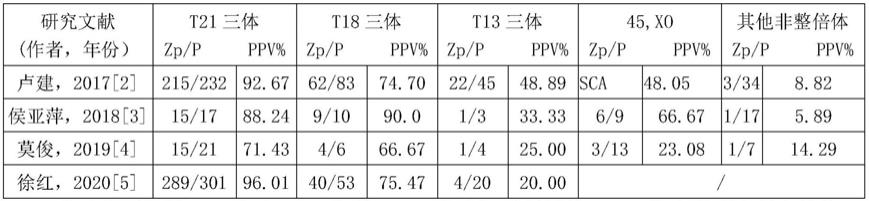
3.越来越多孕妇优先选择nipt的同时,无创产前检测假阳性假阴性样本的问题越发突出。据行业内专家报道,nipt的回顾性分析数据显示,部分染色体异常类型存在着比较低的阳性预测值,如下表:
[0004][0005]
(zp:代表诊断阳性;p:代表nipt阳性;ppv:代表阳性预测值;sca:代表类型为所有性染色体异常汇总)
[0006]
母体外周血中游离dna的来源与含量变化等生物因素会影响nipt检测准确性。对于所检测目标疾病,会产生nipt检测出的胎儿染色体结果与有创诊断结果不一致,即出现 nipt假阴性或假阳性结果。一般导致nipt假阳性假阴性的常见原因有以下3种:1.胎儿游离dna含量过低:早孕期双胎,一胎消亡变单胎;异卵双胎妊娠;辅助生殖妊娠;孕妇肥胖。2.胎儿和胎盘不一致:局限性胎盘嵌合;胎儿异常,胎盘细胞的染色体正常。3.母体自身原因造成染色体异常:母体拷贝数异常;母体为嵌合体异常;母体肿瘤携带;外源性输血或外源性淋巴细胞治疗。
[0007]
如何减少无创产前检测假阳性假阴性样本的误判越来越受重视,目前行内降低假阳性假阴性普遍有如下方法:
[0008]
1.加入母体测试样本,增加母体背景对照,去除母体异常引起的假阳性假阴性。但这种方法增加一定的运营成本,并不是所有实验室都能接受的,只是当发现异常样本时才会对个别增加母体测试环节,另外该环节且会导致报告周期延迟,不能广泛推广。
[0009]
2.实验流程中加入片筛环节来提高胎儿浓度,实践证明该方法在一定概率下提高胎儿浓度,阳性预测值得到了提高。但在实际检测中,因个体差异,如试管婴儿(或有减胎),孕妇的年龄,孕妇的体重指数(bmi),妊娠期并发症等因素影响,部分样本在实验过程即使
已加入磁珠片筛,却依然不能很好地提高胎儿浓度。
技术实现要素:
[0010]
本发明要解决的技术问题是针对上述现有技术的不足,提供一种基于半导体测序的降低无创产前检测假阳性假阴性的方法,既无需增加实验环节,也无需增加成本,只通过短片段富集减半数据量来进行分析和剔除母源cnv影响进行分析,使在已片筛优化实验方法的前提下胎儿浓度再度提高,通过对高胎儿浓度及剔除母源cnv影响的z值和低胎儿浓度的z值进行比较,从而识别假阳性假阳性样本。
[0011]
为解决上述技术问题,本发明的技术方案是:一种基于半导体测序的降低无创产前检测假阳性假阴性的方法,包括实验环节和测序数据分析环节,所述实验环节采用磁珠片筛试剂盒,包括如下步骤,样本取样—分离—提取—建库—定量—上机—获得后台数据,所述样本为母体外周血;所述测序数据分析环节,包括如下步骤,测序数据获取
‑
序列比对和过滤
‑
gc校正
‑
统计每个分辨率窗口的序列数值并归一化
‑
对分辨率窗口的比例(r)值进行 run内校正
‑
计算分辨率窗口的z
‑
score值
‑
胎儿dna浓度(fc)预测
‑
得出z值、zlength值和z
s
值
‑
结果汇总分析。
[0012]
作为本发明的进一步阐述,
[0013]
优选地,所述步骤测序数据获取,包括基于获取的母体外周血游离dna,利用高通量测序平台对待测样品进行全基因组测序以获得待测样本的染色体测序数据以及来自背景库样本的染色体测序数据的过程。
[0014]
优选地,所述步骤序列比对和过滤,包括选择比对软件将半导体测序仪获得原始序列数据与人类基因组参考序列进行序列比对,然后过滤无比对(ummaped)、低比对质量 (mapq<10)和多重复比对等对系统变异系数影响较大的序列,获得有效测序数据的过程。
[0015]
优选地,所述步骤gc校正,包括首先统计每0.1%gc范围内的所有20kb窗口的序列数值(ur)并利用loess算法计算获得urloess,再通过所有20kb窗口获得期望的序列数值ure的过程,最后校正后的序列数值urcorrected经如下公式计算得到:urcorrected=ur
‑
(urloess
‑
ure)。
[0016]
优选地,所述步骤统计每个分辨率窗口的序列数值并归一化,包括对gc校正的窗口进行合并得到合适的分辨率窗口,对每个分辨率窗口,利用每个gc校正的窗口中经校正后的序列数值,统计出比对到该分辨率窗口的序列数值(reads number,rn),然后对分辨率窗口的序列数值进行归一化处理得到每个分辨率窗口区段的比例(r)值的过程,所述比例(r)值经如下公式计算得到:公式中的n表示基因组的n个分辨率的窗口。
[0017]
优选地,所述步骤对分辨率窗口的比例(r)值进行run内校正,包括对每个分辨率窗口区段的比例值(r),利用同批次上机样本的同一染色体区段的比例值集合,进行校正得到每个区段的run内校正后相对比例(cr)值的过程,所述校正后相对比例(cr)值经如下公
式计算得到:公式中的k表示同批次上机样本中剔除异常值后的有效r值数。
[0018]
优选地,所述步骤计算分辨率窗口窗口的z
‑
score值,包括定义该区域在普通人群样本中cr值的均值与标准差,进一步计算当前样本在该区域的z
‑
score值的过程,所述 z
‑
score值经如下公式计算得到:
[0019]
优选地,所述步骤胎儿dna浓度(fc)预测,使用的模型包括y染色体比例的线性回归模型、基于游离dna长度分布信息的线性回归模型、基于测序的片段分布的多元线性回归模型和基于人群多态性位点杂合频率的线性回归模型等方法计算得到。
[0020]
优选地,所述步骤得出z值、zlength值和z
s
值,包括通过所有测序数据重复上述1 至7步骤计算获得各个目标染色体的z值;从测序数据获取短片段部分的一半数据重复上述1至7步骤计算zlength值;通过对染色体的每个1mb的窗口重复上述1至7步骤计算得到每个窗口的z
‑
score,取中值与染色体窗口数的开平方根相乘计算得到z
s
值的过程。
[0021]
上述z值、zlength值和z
s
值的计算方法如下:
[0022]
z=(r
i
‑
mean
i
)/sd
i
,z为当前待测样本的某个染色体的检测值,ri为当前待测样本获得的该染色体比例值,mean
i
为该染色体的整倍体检测值的参考比例值,sd
i
为该染色体的整倍体检测值的参考比例值的标准差。
[0023]
zlength=(hr
i
‑
mean
i
)/sd
i
,zlength为当前待测样本的所有测序数据中选取一半的短片段数据计算得到某个染色体的检测值,hri为当前待测样本的所有测序数据中选取一半的短片段数据获得的该染色体比例值,mean
i
为该染色体的整倍体检测值的参考比例值,sd
i
为该染色体的整倍体检测值的参考比例值的标准差。
[0024]
z
s
=med(z
i
)*sqrt(n),z
s
为使用中值法计算当前待测样本的某个染色体的检测值, med(z
i
)为该染色体所有分辨率窗口计算得到的z
i
值的中值,n为该染色体的划分的所有分辨率窗口的数量,sqrt(n)指对窗口数值n进行开方。
[0025]
优选地,所述步骤结果汇总分析,包括输出z值、zlength值和z
s
值的结果进行比较分析,判断待测样本是否阳性或者阴性的过程,所述zlength值和z
s
值提供有效的辨别依据,有效降低基于半导体测序的无创产前检测假阳性假阴性的概率。
[0026]
本发明的有益效果是:
[0027]
1、本发明无需改变实验方案、无需增加测序量和检测成本的前提下,通过短片段富集减半数据量的方法,可有效将胎儿浓度提高20%
‑
50%,把胎儿浓度提高后算出来的z值 (zlength),与实验优化后的z值进行对比,zlength可明显增加对假阳性假阴性的识别。
[0028]
2、本发明剔除母源cnv影响是通过取每条染色体的ratio值的中位数进行分析后算出 z值(z
s
),该方法能有效地剔除由于母源cnv导致z值假阳性假阴性的影响。
附图说明
[0029]
图1为实施例1
‑
1的nipt结果图之一;
[0030]
图2为实施例1
‑
1的nipt结果图之二;
[0031]
图3为实施例1
‑
1的nipt结果图之三;
[0032]
图4为实施例1
‑
1的诊断结果图之一;
[0033]
图5为实施例1
‑
1的诊断结果图之二;
[0034]
图6为实施例1
‑
2的nipt结果图;
[0035]
图7为实施例1
‑
2的诊断结果图;
[0036]
图8为实施例2的nipt结果图之一;
[0037]
图9为实施例2的nipt结果图之二;
[0038]
图10为实施例3的nipt结果图之一;
[0039]
图11为实施例3的nipt结果图之二;
[0040]
图12为实施例3的nipt结果图之三。
具体实施方式
[0041]
下面通过具体实施方式对本发明作进一步详细说明。
[0042]
本发明公开一种基于半导体测序的降低无创产前检测假阳性假阴性的方法,包括实验环节和测序数据分析环节,所述实验环节采用磁珠片筛试剂盒,包括如下步骤,样本取样—分离—提取—建库—定量—上机—获得后台数据,所述样本为母体外周血;所述测序数据分析环节,包括如下步骤,测序数据获取
‑
序列比对和过滤
‑
gc校正
‑
统计每个分辨率窗口的序列数值并归一化
‑
对分辨率窗口的比例(r)值进行run内校正
‑
计算分辨率窗口窗口的z
‑
score值
‑
胎儿dna浓度(fc)预测
‑
得出z值、zlength值和z
s
值
‑
结果汇总分析。
[0043]
进一步地,所述步骤测序数据获取,包括基于获取的母体外周血游离dna,利用高通量测序平台对待测样品进行全基因组测序以获得待测样本的染色体测序数据以及来自背景库样本的染色体测序数据的过程。
[0044]
进一步地,所述步骤序列比对和过滤,包括选择比对软件将测序获得半导体测序仪获得原始序列数据与人类基因组参考序列进行序列比对,然后过滤无比对(ummaped)、低比对质量(mapq<10)和多重复比对等对系统变异系数影响较大的序列,获得有效测序数据的过程。
[0045]
进一步地,所述步骤gc校正,包括首先统计每0.1%gc范围内的所有20kb窗口的序列数值(ur)并利用loess算法计算获得urloess,再通过所有20kb窗口获得期望的序列数值ure的过程,最后校正后的序列数值urcorrected经如下公式计算得到:urcorrected=ur
‑
(urloess
‑
ure)。
[0046]
进一步地,所述步骤统计每个分辨率窗口的序列数值并归一化,包括对gc校正的窗口进行合并得到合适的分辨率窗口,对每个分辨率窗口,利用每个gc校正的窗口中经校正后的序列数值,统计出比对到该分辨率窗口的序列数值(reads number,rn),然后对分辨率窗口的序列数值进行归一化处理得到每个分辨率窗口区段的比例(r)值的过程,所述比
例(r)值经如下公式计算得到:公式中的n表示基因组的n个分辨率的窗口。
[0047]
进一步地,所述步骤对分辨率窗口的比例(r)值进行run内校正,包括对每个分辨率窗口区段的比例值(r),利用同批次上机样本的同一染色体区段的比例值集合,进行校正得到每个区段的run内校正后相对比例(cr)值的过程,所述校正后相对比例(cr)值经如下公式计算得到:公式中的k表示同批次上机样本中剔除异常值后的有效r值数。
[0048]
进一步地,所述步骤计算分辨率窗口窗口的z
‑
score值,包括定义该区域在普通人群样本中cr值的均值与标准差,进一步计算当前样本在该区域的z
‑
score值的过程,所述 z
‑
score值经如下公式计算得到:
[0049]
进一步地,所述步骤胎儿dna浓度(fc)预测,使用的模型包括y染色体比例的线性回归模型、基于游离dna长度分布信息的线性回归模型、基于测序的片段分布的多元线性回归模型和基于人群多态性位点杂合频率的线性回归模型等方法计算得到。
[0050]
进一步地,所述步骤得出z值、zlength值和z
s
值,包括通过所有测序数据重复上述 1至7步骤计算获得各个目标染色体的z值;从测序数据获取短片段部分的一半数据重复上述1至7步骤计算zlength值;通过对染色体的每个1mb的窗口重复上述1至7步骤计算得到每个窗口的z
‑
score,取中值与染色体窗口数的开平方根相乘计算得到z
s
值的过程。
[0051]
上述z值、zlength值和z
s
值的计算方法如下:
[0052]
z=(r
i
‑
mean
i
)/sd
i
,z为当前待测样本的某个染色体的检测值,ri为当前待测样本获得的该染色体比例值,mean
i
为该染色体的整倍体检测值的参考比例值,sd
i
为该染色体的整倍体检测值的参考比例值的标准差。
[0053]
zlength=(hr
i
‑
mean
i
)/sd
i
,zlength为当前待测样本的所有测序数据中选取一半的短片段数据计算得到某个染色体的检测值,hri为当前待测样本的所有测序数据中选取一半的短片段数据获得的该染色体比例值,mean
i
为该染色体的整倍体检测值的参考比例值,sd
i
为该染色体的整倍体检测值的参考比例值的标准差。
[0054]
z
s
=med(z
i
)*sqrt(n),z
s
为使用中值法计算当前待测样本的某个染色体的检测值,med(z
i
)为该染色体所有分辨率窗口计算得到的z
i
值的中值,n为该染色体的划分的所有分辨率窗口的数量,sqrt(n)指对窗口数值n进行开方。
[0055]
进一步地,所述步骤结果汇总分析,包括输出z值、zlength值和z
s
值的结果进行比较分析,判断待测样本是否阳性或者阴性的过程,所述zlength值和z
s
值提供有效的辨别依据,有效降低基于半导体测序的无创产前检测假阳性假阴性的概率。
[0056]
结果汇总,基于上述3种算法输出z值、zlength值和z
s
值的结果进行比较分析,能全面地判断待测样本是否阳性或者阴性,实践证明zlength值和z
s
值对于特殊情况的样本 (比如z值在灰色区临界、z值阳性值不大、母源cnv影响等)提供有效的判别依据,可有效降低基于半导体测序的无创产前检测假阳性假阴性的概率。
[0057]
以下本发明非整倍体异常判读方案(备注:fc>4%,z
l
=zlength
‑
z)
[0058][0059]
注:当样本存在其他临床指标异常时,应严格一级判断。
[0060]
使用本发明方法后阳性预测值得到了有效提高:t21,t18,t13的ppv分别提高5%,4%,15%;xo的ppv提高很明显(15%),总体综合ppv提高10%。
[0061][0062]
以下以实际实施例来具体说明本发明方案:
[0063]
实施例1:假阳性识别
[0064]
实施例1
‑
1:母体t21:ej034720:z值异常高,无法去除母体背景影响均一化,s方法即z
s
值还是高的,但是可以通过z
lengthl
,与z值进行比较得出z
l
=
‑
7.77,符合chr21阴性的判断方案:c,z>50&z
l
<
‑
5。即随着胎儿浓度的提高,检测值反而降低,图形看到红线明显往回走,识别该样本为假阳性样本,穿刺结果胎儿正常得以证实。
[0065]
胎儿浓度18.7孕周22周+4天年龄32试管婴儿/输血/移植/肿瘤/nt/z73.438z
s
75.926z
length
65.648z
l
‑
7.77本方法nipt结果阴性诊断结果无异常
[0066]
nipt结果如图1、图2和图3所示。
[0067]
诊断结果如图4、图5所示,未见明显异常。
[0068]
实施例1
‑
2:本案例检测值z>3,结合z
length,
z
s
b,比较分析,符合chr21阴性的判断方案:b, 2≤z<3&(z
s
<3 or z
l
<3),即识别该样本为假阳性样本,穿刺结果胎儿正常得以证实。
[0069][0070][0071]
nipt结果如图6所示。
[0072]
诊断结果如图7所示。
[0073]
实施例2:假阴性的识别
[0074]
该案例其他机构检测t21假阴;采用本发明方法检测结果z=3.9.zlength=6.8,
通过分析方法富集胎儿浓度后的zlength值明显大于z值,符合chr21阳性的判读方案b,3<z ≤5&z
l
>1。可见能明显识别为t21阳性样本,能避免假阴性的发生。
[0075]
胎儿浓度17.3孕周/年龄/试管婴儿/输血/移植/肿瘤/nt/z3.927z
s
/z
length
6.845z
l
2.918本方法nipt结果t21诊断结果t21
[0076]
nipt结果如图8和图9所示。
[0077]
实施例3:去除母体异常背景
[0078]
e0347样本21的z值临界,经过剔除母源污染后的z
s
值降到正常值,符合chr21阴性的判读方案:d,z>3&z
s
<3&(21存在cnv),综合判断可出阴性。如没z
s
值协助判断,这样本需要重新实验,这样即增加了成本,报告也要至少延迟4天;甚至重做后也不一定能出阴性报告,导致假阳性的发生。
[0079]
该样本在z
s
协助判断下,发明人出具了阴性报告,经随访胎儿已出生,一切正常。可见该方法能有效避免假阳性的发生。
[0080]
胎儿浓度13.2孕周17+4年龄24试管婴儿/输血/移植/肿瘤/nt/z4.03z
s
0.045本方法nipt结果阴性随访结果胎儿已出生,一切正常
[0081]
nipt结果如图10、图11和图12所示。
[0082]
本发明无需改变实验方案、无需增加测序量和检测成本的前提下,通过短片段富集减半数据量的方法,可有效将胎儿浓度提高20%
‑
50%,把胎儿浓度提高后算出来的z值 (zlength),与实验优化后的z值进行对比,zlength可明显增加对假阳性假阴性的识别。真阳性样本的z值会随着胎儿浓度的提高而提高,如果没有提高反而降低的,则判断为假阳性的可能性。同时,如果数值落在灰区的临界样本,zlength随着胎儿浓度的提高而明显提高,即说明真阳性的风险大,相反的zlength随着胎儿浓度的提高而下降即说明真阳性的风险
小,从而有效识别假阳性假阴性。
[0083]
因为母体外周血浆中胎儿游离dna含量大概占全部游离dna的3~13%,其余大量来源于母体背景的游离dna,同时母源染色体如果存在cnv,母源cnv区域波动会很大,导致检测的z值偏高或者偏低(正常范围
‑
3~3),进而影响对胎儿是否携带的判断,容易导致对结果判断失准,出现假阳性或假阴性,同时也导致z值偏离正常范围,无法正常发放报告。本发明剔除母源cnv影响是通过取每条染色体的ratio值的中位数进行分析后算出z值 (z
s
),该方法能有效地剔除由于母源cnv导致z值假阳性假阴性的影响。
[0084]
使用本发明能有效降低无创产前基因检测(nipt)的假阳性假阴性率。本发明开发了纯生物信息分析的方法,无需改变实验方案、无需增加测序量和检测成本的前提下,通过短片段富集减半数据量的提高胎儿浓度算出来的z值和利用中值ratio值剔除母源干扰后算出来的z值,与优化前的z值进行比较,从而识别假阳性假阴性样本。对nipt准确性的提高,本发明具有重要的价值。
[0085]
以上所述,仅是本发明较佳实施方式,凡是依据本发明的技术方案对以上的实施方式所作的任何细微修改、等同变化与修饰,均属于本发明技术方案的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1