一种基于深度学习算法的延迟CT图像生成方法
一种基于深度学习算法的延迟ct图像生成方法
技术领域
1.本发明属于医学图像技术领域,具体涉及一种基于深度学习算法的延迟ct图像生成方法。
背景技术:
2.正电子发射断层扫描/计算机断层扫描(pet/ct)系统为放射治疗计划提供关键信息,其可以用于在诊断肿瘤、预后和分期时辅助做出决策。pet是一种无创诊断工具,可提供有关代谢和功能的信息。ct是一种x射线断层扫描技术,可提供具有高空间分辨率病变的解剖结构。
3.在进行pet扫描前人体会被注入显像剂例如正电子放射性核素,然后被推进探测器环。注入人体的正电子放射性核素发生衰变产生正电子,正电子与组织中的电子发生湮灭,产生两个具有511千电子伏特、但向相反方向飞出的一对γ光子。封闭多环型探测器对这些反方向飞出的光子进行测量,形成投影线,经电子前端放大形成原始的sinogram数据,原始的sinogram数据传入到计算机系统,重建出pet图像。在pet成像中,由于γ光子在体内的吸收和能量的损失而导致无法检测到,这称为衰减。由于检测到的γ光子数量少于实际,因此导致图像质量下降。
4.γ射线通过人体组织的衰减会严重影响pet图像的准确性和质量,因此衰减校正是pet重建的重要组成部分。准确的pet图像需要ct图像或者从mr估计ct来校正湮灭光子的损失,而mr序列获取的时间较长。因此我们通过配准的方法生成ct图像来进行衰减校正。
5.延迟扫描是指在第一次pet/ct(t1pet/t1ct)扫描后的一定时间内,对选定的床位进行再次扫描,以便对疾病做出更准确的诊断。在延迟pet扫描(t2pet)期间,无需向患者注射显像剂,因此患者不会接受额外的辐射剂量。而延迟ct扫描(t2ct)会增加对患者的整体x射线辐射。精确的pet图像需要在重建过程中使用从ct图像中导出衰减校正图。
6.因此,设计一种充分利用现有的t2pet、t1pet和t1ct图像生成t2ct图像来降低患者经受的x射线辐射剂量以及解决在t2pet扫描中执行衰减校正的一种基于深度学习算法的延迟ct图像生成方法,就显得十分必要。
7.例如,申请号为cn202010125698.5的中国专利文献描述的一种用于pet图像衰减校正的ct图像生成方法,通过采集t1时刻的ct图像和pet图像以及t2时刻的pet图像,将其输入训练好的神经网络中,获得t2时刻的ct图像,该ct图像能用于pet图像的衰减校正,从而获得更精确的pet图片。虽然能减少整个图像采集阶段病人受到的x射线的剂量,减轻病人生理和心理上受到的压力,但不足之处在于,根据临床需要,存在获得的ct图像的准确性不足的问题。
技术实现要素:
8.本发明是为了克服现有技术中,在pet/ct延迟扫描中无法降低患者经受的x射线辐射,提供了一种能够在pet/ct延迟扫描中执行衰减校正,同时通过生成t2ct图像来降低
患者在t2ct过程中经受的x射线辐射剂量的一种基于深度学习算法的延迟ct图像生成方法。
9.为了达到上述发明目的,本发明采用以下技术方案:
10.一种基于深度学习算法的延迟ct图像生成方法,包括以下步骤:
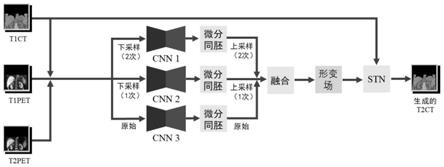
11.s1,采集患者的t2pet、t1pet和t1ct图像;
12.其中,t2pet图像指延迟pet扫描生成的图像,t1pet图像指第一次pet扫描生成的图像,t1ct图像指第一次ct扫描生成的图像;
13.s2,将采集的t2pet、t1pet和t1ct图像输入多分辨率配准卷积神经网络mrr
‑
cnn后,输出包含大、中、小形变量的三个形变场;
14.s3,将步骤s2中输出的包含大、中、小形变量的三个形变场融合为一个形变场;
15.s4,将所述形变场和输入的t1ct图像输入到空间转换网络stn中以生成t2ct图像;
16.其中,t2ct图像指延迟ct扫描图像。
17.作为优选,所述多分辨率配准卷积神经网络mrr
‑
cnn包括三个并行连接的卷积神经网络cnn1、cnn2和cnn3;所述cnn1、cnn2和cnn3分别输入低分辨率图像组、中分辨率图像组和原始分辨率图像组。
18.作为优选,步骤s2包括如下步骤:
19.s21,采用卷积神经网络cnn 1,对输入的图像t1pet、t2pet和t1ct进行两次下采样,使输入的图像的分辨率均变为原来的1/4,并输出包含大形变量的形变场并上采样到输入图像的原始分辨率;
20.s22,采用卷积神经网络cnn 2,对输入的图像t1pet、t2pet和t1ct进行一次下采样,使输入的图像的分辨率均变为原来的1/2,并输出包含中等形变量的形变场并上采样到输入图像的原始分辨率;
21.s23,采用卷积神经网络cnn 3,输入原始图像t1pet、t2pet和t1ct,并输出包含小形变量的形变场。
22.作为优选,所述卷积神经网络cnn1、cnn2和cnn3均包括编码器、解码器和若干个跳跃连接;所述编码器用于提取输入之间的特征,并在下采样过程中逐步将所述特征减半。
23.作为优选,所述编码器包括若干个堆叠的卷积层;每个卷积层的内核大小均为3
×3×
3,步幅均为2。
24.作为优选,所述解码器包括若干个反卷积层;每个反卷积层的内核大小均为3
×3×
3,步幅均为1。
25.作为优选,所述形变场用φ
t
表示,具体为:
[0026][0027]
其中,φ
(0)
=id是恒等变换,v
t
表示时间t∈[0,1]处的速度场v;使用时间步长t=7对单位时间内的速度场v进行积分,以生成最终的φ
(1)
,根据公式,φ
(1)
=exp(v)。
[0028]
作为优选,每个卷积层或反卷积层后均跟有归一化和激活函数。
[0029]
作为优选,所述多分辨率配准卷积神经网络mrr
‑
cnn包含三个卷积神经网络cnn,但不限于三个卷积神经网络cnn。
[0030]
本发明与现有技术相比,有益效果是:(1)本发明能够通过生成t2ct图像,而无需
额外的ct扫描来降低患者在t2ct扫描过程中经受的x射线辐射剂量;(2)本发明能够在延迟扫描中生成延迟ct(t2ct)图像,从而对t2pet执行衰减校正。
附图说明
[0031]
图1为本发明一种基于深度学习算法的延迟ct图像生成方法的一种流程图;
[0032]
图2为本发明中卷积神经网络cnn1、cnn2和cnn3的一种架构示意图。
具体实施方式
[0033]
为了更清楚地说明本发明实施例,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
[0034]
实施例1:
[0035]
如图1所示的一种基于深度学习算法的延迟ct图像生成方法,包括如下步骤:
[0036]
s1,采集患者的t2pet、t1pet和t1ct图像;
[0037]
其中,t2pet图像指延迟pet扫描生成的图像,t1pet图像指第一次pet扫描生成的图像,t1ct图像指第一次ct扫描生成的图像;
[0038]
s2,将采集的t2pet、t1pet和t1ct图像输入多分辨率配准卷积神经网络(multi
‑
resolution registration convolutional neural network,mrr
‑
cnn)后,输出包含大、中、小形变量的三个形变场;
[0039]
s3,将步骤s2中输出的包含大、中、小形变量的三个形变场融合为一个形变场;
[0040]
s4,将所述形变场和输入的t1ct图像输入到空间转换网络(spatial transform network,stn)中以生成t2ct图像;
[0041]
其中,t2ct图像指延迟ct扫描图像。
[0042]
进一步的,所述多分辨率配准卷积神经网络mrr
‑
cnn包括三个并行连接的卷积神经网络cnn 1、cnn 2和cnn 3;所述cnn 1、cnn 2和cnn 3分别被输入低分辨率图像组、中分辨率图像组和原始分辨率图像组。
[0043]
其中,包含大形变量的形变场是通过输入经过两次下采样的低分辨率图像而生成的,低分辨率图像组用于获取图像间的大的形变信息。包含中等形变量的形变场是通过输入经过一次下采样的中等分辨率图像而生成的,中分辨率图像组用于获取图像间的中等的形变信息。而包含小形变量的形变场是通过输入原始分辨率图像组而生成的,原始分辨率图像组用于获得图像间的小的形变信息。然后将包含大、中、小形变量的三个形变场融合为一个形变场,其形变量信息逐渐增加,获得包含多尺度形变量的形变场,用于准确地生成t2ct图像从而用于t2pet的衰减校正。每个图像集包含同一患者的t2pet、t1pet和t1ct图像。
[0044]
步骤s2包括如下步骤:
[0045]
s21,采用卷积神经网络cnn 1,对输入的图像t1pet、t2pet和t1ct进行两次下采样,使输入的图像的分辨率均变为原来的1/4,并输出包含大形变量的形变场并上采样到输入图像的原始分辨率;
[0046]
s22,采用卷积神经网络cnn 2,对输入的图像t1pet、t2pet和t1ct进行一次下采样,使输入的图像的分辨率均变为原来的1/2,并输出包含中等形变量的形变场并上采样到输入图像的原始分辨率;
[0047]
s23,采用卷积神经网络cnn 3,输入原始图像t1pet、t2pet和t1ct,并输出包含小形变量的形变场。
[0048]
步骤s21,旨在从低分辨率图像中计算出大的形变量;步骤s22,旨在从中等分辨率图像中计算出中等形变量;步骤s23,专注于从原始图像中计算出小的形变量。
[0049]
多分辨率配准卷积神经网络mrr
‑
cnn首先计算大的形变量,然后添加越来越多的形变量信息,其形变量信息逐渐增加,以获得包含多尺度形变量的形变场。然后把形变场和输入的t1ct图像输入到空间转换网络(stn)中以生成t2ct图像。
[0050]
进一步的,如图2所示,所述卷积神经网络cnn1、cnn2和cnn3均包括编码器、解码器和多个跳跃连接;所述编码器用于提取输入之间的特征,并在下采样过程中逐步将所述特征减半。
[0051]
进一步的,所述编码器包括多个堆叠的卷积层;每个卷积层的内核大小均为3
×3×
3,步幅均为2。
[0052]
进一步的,所述解码器包括多个反卷积层;每个反卷积层的内核大小均为3
×3×
3,步幅均为1。
[0053]
对于解码器中的前四个反卷积层,我们相应地添加了来自卷积层的跳跃连接,以增强输出的鲁棒性。在解码器中,通过对来自解码器和相应编码器的特征进行上采样来保留特征信息。在解码器的末尾,添加了三个额外的反卷积层以更好地保留特征信息。另外,每个卷积层或反卷积层后均跟有归一化和激活函数。
[0054]
此外,传统网络通常会忽略拓扑性和可逆映射等理想的微分同胚特性,从而导致形变场的折叠问题导致生成图像精度下降。为了实现微分同胚变形模型以提高配准精度,在网络中实现了微分同胚集成层。进一步的,所述形变场用φ
t
表示,具体为:
[0055][0056]
其中,φ
(0)
=id是恒等变换,v
t
表示时间t∈[0,1]处的速度场v;使用时间步长t=7对单位时间内的速度场v进行积分,以生成最终的φ
(1)
,根据公式,φ
(1)
=exp(v)。
[0057]
进一步的,本发明中的多分辨率配准卷积神经网络mrr
‑
cnn包含三个卷积神经网络cnn,但不限于三个卷积神经网络cnn,可以用两个也可以用四个。
[0058]
本发明提出了一种多分辨率配准卷积神经网络mrr
‑
cnn模型,充分利用现有的t2pet、t1pet和t1ct图像生成t2ct图像。本发明能够通过生成t2ct图像对t2pet执行衰减校正,同时来避免额外的ct扫描增加患者经受的x射线辐射剂量。
[0059]
以上所述仅是对本发明的优选实施例及原理进行了详细说明,对本领域的普通技术人员而言,依据本发明提供的思想,在具体实施方式上会有改变之处,而这些改变也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1