一种数据驱动的从电子病历中提取信息的方法与流程
1.本发明涉及电子病历信息提取技术领域,特别涉及一种数据驱动的从电子病历中提取信息的方法。
背景技术:
2.电子病历(electronic medical records,emrs)中记录着许多有用信息,比如,关于疾病的描述、检查结果、具体的治疗方案和疗效等,这些信息将有助于医学专家们更清楚得地了解疾病的发展进程,从而找到更有效的治疗方法或者发掘某些医学需求的不足,然后从非结构化的电子病历文本中自动提取这些有用信息是相当错综复杂的过程,电子病历中的描述都是医师在对病人诊疗过程中记录下来的,因此具有简洁和个性化的特点,尽管病历记录有相应的实用书写标准,但由于医师们书写习惯或者先验知识的不同,记录的形式也会显著不同有时甚至可能发生错误记录。
3.此外,中文相对英文在语言复杂性上是显著增加的,而中国的医师们还经历过传统中医(tcm)的训练,书写习惯甚至可能更接近古文,想从中文电子病历中有效地提取信息,将面临更大的挑战,因此,现有的用于从新闻或者一般文学作品中提取信息的常用方法都不适用于从中文电子病历中提取信息,用大量经人工注释的中文电子病历去训练一个新的模型用来识别的确是一个可行的办法,但是这需要具有专业知识的人员花大量的时间去注释才能实现,显然是不易操作和推广的,故提出一种数据驱动的从电子病历中提取信息的方法。
技术实现要素:
4.本发明针对现有技术中存在的技术问题,提供一种数据驱动的从电子病历中提取信息的方法,该数据驱动的从电子病历中提取信息的方法可自动从非结构化的电子病历中识别有用信息并且将这些自由文本转换为包含时间
‑
事件
‑
描述三元组的结构化文本。
5.本发明解决上述技术问题的技术方案如下:一种数据驱动的从电子病历中提取信息的方法,包括以下步骤:
6.s1、对收集的核心词汇库进行有效扩充,构建一个全面的跨领域的词汇库;
7.s2、利用词汇库去电子病历中提取包含时间
‑
医学事件
‑
描述这个三元组的结构化信息。
8.在上述技术方案的基础上,本发明还做了如下改进。
9.进一步,构建的词汇库由核心词汇库及其扩充部分组成,其包含六种类型的医学事件:疾病、症状、药物、身体部位名称、疗程信息以及临床检测信息。
10.进一步,对核心词汇库进行扩充的方法包括识别模式迭代法、动态术语组合法和方向型或者扩展型前缀法。
11.进一步,所述识别模式迭代法包括以下步骤:
12.1)从核心词汇库开始,在每一次的非监督迭代过程中,首先对整个电子病历主体
进行扫描并鉴别出当前词汇库中还未被识别或者未包含被的词汇,然后选出其中比较可信的添加到当前词汇库中;
13.2)用这些词汇构建一系列候选的新识别模式,最后再从中筛选出较为可靠的模式用于下一次迭代中新词汇的搜索,如此循环直到没有新词汇被鉴别到为止。
14.进一步,所述动态术语组合法识别的不是一个个单独的词汇,而是词汇的组合,组合中每个独立的词汇可能都已经被包含在核心词汇库里了,但是它们组合后的词汇组往往没有被核心词汇库收录,这样的词汇组很多都以身体的某个部位作为前缀。
15.进一步,所述方向型或者扩展型前缀法为对于词汇库中的一个已知术语,如果它前面三个字符是方向性或者扩展性的词汇,则将这个新的组合也添加到词汇库中并以该已知术语作为其标签。
16.进一步,利用词汇库去电子病历中提取结构化的三元组信息中,信息提取的过程为如下步骤:
17.1)首先用一种医学事件标记算法和一系列时间识别规则从电子病历文本中鉴别出医学术语和时间词汇;
18.2)剩下的文本则被视为关于这些医学术语的候选描述,首先按照如下规则将其中明显不属于医学事件描述的句子去掉:
19.a、如果句子中包含着前面提到的非医学事件的术语,比如“非恶寒”等;
20.b、如果句子中包含病历中的一些常见用语,比如“入院”、“出院”、“住院”、“就诊”和“治疗”等;
21.3)然后建立所有可能的“时间
‑
医学事件
‑
描述”三元组,再用一种二元的支持向量机(svm)模型将这些三元组分类为真或假组合,标记为真的组合就应该是某时间节点发生的医学事件在病历中的实际描述,反之,该三元组中的描述并非该事件的描述。
22.进一步,所述医学事件标记算法为对于输入的每一个句子,先标记这个句子中所有可能的代表某医学事件的短语,从最长到最短,然后用一个布尔阵列去记录那些这些被标记的短语,对每一个被标记的短语,首先看它的第一个和最后一个字符是否被标记了,如果它们中没有一个被标记,那么这个短语不需要被记录,于是布尔返回值为假,因为它的一部分或者全部很可能被包含在一个更长短语中,否则,检查该短语是否为词汇库中的收录,如果是,布尔返回值为真即要将它加入到被识别的医学事件里表中,同时将表示否定或者将来行动的词或者短语作为前缀的医学事件从识别列表中去除。
23.进一步,时间信息为九个组成部分,分别为:前置近似词、后置近似词、数字、单位、时间单位、前置词、某个确定的时间、一天中某个确定的时间段和一天中某个确定的时间点等,代表时间的术语可以用以下两个正则表达式来表述:
24.a、前置近似词?数字(单位)?(时间单位)(后置近似词)?前置词;
25.b、(某个确定的时间)(一天中某个确定的时间段)?((前置近似词)?(一天中某个确定的时间点)(后置近似词)?)?;
26.此外,在中文里六个惯用的词语并不属于以上两个正则表达式的格式,也被添加到时间术语列表里,它们是“昨晚”,“昨夜”,“今夜”,“今晚”,“今早”和“今晨”,时间的术语的覆盖范围遵守如下的规定:
27.a、如果在一个陈述句中只包含一个时间术语,那么它代表整个陈述中事件的发生
时间;
28.b、如果一个陈述句中存在多个时间术语,那么每一个时间术语管辖的范围从公司术语起直到下一个时间术语出现之前;
29.c、如果一个陈述句是指在病历中用句号隔开的句子,在某个时间术语覆盖范围内的医学事件,都默认为是在该时间发生的事件。
30.进一步,所述svm分类模型引入了以下8种特征:
31.a、被识别出的医学事件前后三个字符;
32.b、每个候选描述前后三个字符;
33.c、一个候选描述是否包含数字;
34.d、计算一个医学事件x和一个候选描述y之间的归一化谷歌距离(ngd),计算公式如下:
[0035][0036]
其中m是一种搜索引引擎编制索引的网页总数,f(x)和f(y)是分别搜索x和y返回的搜索结果的数量,而f(x,y)是同时包含x和y的网页总数;
[0037]
e、两个医学事件之间被识别出的术语的数量;
[0038]
f、两个医学事件之间候选描述的数量;
[0039]
g、两个医学事件之间逗号的数量;
[0040]
h、被识别出的医学事件类型。
[0041]
与现有技术相比,本技术的技术方案具有以下有益技术效果:
[0042]
1、该数据驱动的从电子病历中提取信息的方法,通过模式构建
‑‑
新词汇识别
‑‑
再构建新模式这样迭代的方式,以及用身体部位前缀、方向型或者扩展型前缀这些特征性的识别规则,从给定的电子病历中自动搜索口语化、简化或者当地习惯用语等新词汇以扩充系统中原有的核心词汇库,利用该扩展后的词汇库去识别真实电子病历中的医学术语(事件),与同时期最常用的其它方法相比,其识别能力(用f1分数代表)略胜一筹,甚至显著高于带有精确匹配的方法,此外,该扩充方案不需要手动注释,更易操作和实现搜索规模化。
[0043]
2、该数据驱动的从电子病历中提取信息的方法,通过一系列规则以及带有特征的支持向量机(svm)模型去捕获识别到的医学事件相应的发生时间和相关描述,与其它几种可行的或者常用的方法相比,其正确关联医学事件与其相关描述的能力(用f1分数代表)也明显优于其它几种方案,这里值得一提的是,该方法将跨领域的归一化谷歌距离(ngd)引入svm模型作为特征之一去匹配医学事件与其相应描述,这样的创新对于在以自然语言甚至口语化语言记录的电子病历中匹配相关信息提供了极大的便利。
附图说明
[0044]
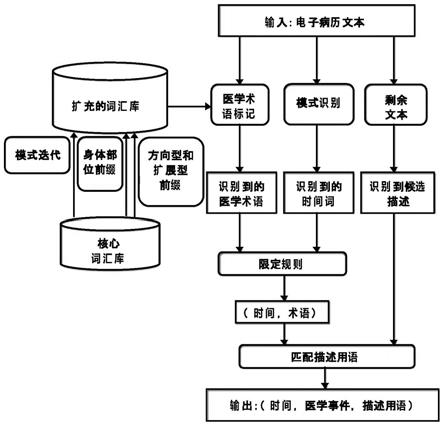
图1为本发明数据驱动的从电子病历中提取信息的方法的系统工作框架图;
[0045]
图2为本发明数据驱动的从电子病历中提取信息的方法中用身体部位前缀的动态术语扩充词汇库的流程图。
具体实施方式
[0046]
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定发明的范围。
[0047]
请参阅图1,本实施例中的一种数据驱动的从电子病历中提取信息的方法,首先通过识别模式迭代,采用动态术语组合以及方向型或者扩展型前缀的方法对收集的核心词汇库进行有效扩充,从而构建一个全面的跨领域的词汇库用于在中文电子病历中识别临床命名实体或医学事件,然后再用统计模型将医学事件与其在同一电子病历中对应的描述信息进行关联,具体流程如下:
[0048]
s1、对收集的核心词汇库进行有效扩充,构建一个全面的跨领域的词汇库;
[0049]
s2、利用词汇库去电子病历中提取结构化的三元组信息。
[0050]
需要说明的是,中文电子病历是一种使用自然语言的复杂系统,非现有的自然语言处理方法能直接识别,所以解析这样的文本系统就需要先进行医学术语识别,然而电子病历中涉及的医学术语不一定都是正规命名也会被记录为简称或者其他变体的形式,现有的医学词汇库很难全面覆盖这些信息,因此,必须首先构建一个大型的覆盖全面的中文医学词汇库。
[0051]
所以,构建的词汇库由核心词汇库及其扩充部分组成,它包含了六种类型的医学事件:疾病、症状、药物、身体部位名称、疗程信息以及临床检测信息。
[0052]
其中,核心词汇库里的收录都来自线下和线上的可靠信息资源,正规词汇来自中文版的《医学系统命名法
‑
临床术语》(snomed
‑
ct)以及中国药典,同时还包括万方医学网、百度百科以及互动百科这些开放型医学或者百科全书式网站里的相应词汇,以及搜狗中文输入法里的词典,而核心词汇库里的非正规词汇则是正规医学术语的变体,它们没有被包含在任何正式的词典里但很可能会出现在电子病历里。
[0053]
为对核心词汇库进行扩充需用到了如下三种词汇扩充的方法:
[0054]
i、识别模式迭代法:
[0055]
它是一种数据驱动迭代搜寻方法,从核心词汇库开始,在每一次的非监督迭代过程中,它首先对整个电子病历主体进行扫描并鉴别出当前词汇库中还未被识别或者未包含被的词汇,然后选出其中比较可信的添加到当前词汇库中,并用这些词汇构建一系列候选的新识别模式,最后再从中筛选出较为可靠的模式用于下一次迭代中新词汇的搜索,如此循环直到没有新词汇被鉴别到为止,这里构建候选模式的方法相对简单,就是以鉴别到的词汇为中心向其左边或者右边或者同时两边分别增加一到三个字符(包括标点符号)而形成的一系列识别模式的组合,比如在句子“,给予头孢呋抗感染”中药物头孢呋被鉴别出来,所以围绕这个药物产生的一系列候选模式如下所示:
[0056]
这样的构建方式势必产生大量的候选模式,为了尽可能多的鉴别有效词汇同时又不引入太多噪音就需要对候选模式进行筛选,保留质量高的,这里引入了两个参数对模式质量进行评价,它们分别是模式选择性(ps)和精确度(pp),定义如下:
[0057]
模式选择性由该模式识别出的特异且正确的医学事件的数量
[0058]
模式精确度
[0059]
其中,正确的医学事件是指已经存在于当前词汇库的中的医学事件,只有当ps和pp都大于某一阈值(分别被称为pst和ppt)的时候,该模式才被视为可靠的高质量的识别模式用于下一次迭代中鉴别新词汇,而对于鉴别到的有新益词效汇果,也引入了一个参数对其准确性进行评价,它是术语频率(tf),其定义如下:
[0060]
术语频率(tf)=鉴别出该术语的识别模式的数量
[0061]
同样,只有当tf大于某一阈值(tft)的时候,该新词汇才会被视为有效的新词汇而加入到现有词汇库中,根据反复测试的经验,tft一般设为1比较合适,而pst和ppt的值就需要在实际操作中用调试集去寻找最佳组合,一般用pst从3到10(步长为1)和ppt从0.3到0.9(步长为0.05)的不同组合去测试,会得到让术语或者医学事件识别效果的f1分数达到最高的最佳阈值组合;
[0062]
ii、动态术语组合法:
[0063]
不同于识别模式迭代法,用它去识别的不是一个个单独的词汇,而是词汇的组合,组合中每个独立的词汇可能都已经被包含在核心词汇库里了,但是它们组合后的词汇组往往没有被核心词汇库收录,这样的词汇组很多都以身体的某个部位作为前缀,因此称之为身体部位为前缀的动态术语组合,它们出现的形式一般分为两种:一种是b1,...,b
n
,d,另一种是b,d1,...,d
n
,其中b代表身体的某个部位,而d则代表了一种医学事件,比如,疾病、症状、疗程、临床检测等,第一种形式可被解析为b1d,...,b
n
d;第二种形式可被解析为bd1,...,bd
n
,但是这样的简单解析会引入不必要的错误术语,所以要计算b和d中词汇各种组合在训练集中出现的概率,也就是要建立b和d词汇之间的统计相关性,只有当它们之间的某个组合出现概率大于某个阈值时,该组合才会被视为新的有效词汇组合而被加入到词汇库中,具体操作流程如图2所示;
[0064]
iii、方向型或者扩展型前缀法:
[0065]
很多时候,一个医学术语是以方向性或者扩展性的词语开始的,比如,左侧输尿管结石,右下肺感染等等,带有这种描述性的术语一般也不会出现在核心词汇库里,所以对于词汇库中的一个已知术语,如果它前面三个字符是方向性或者扩展性的词汇,则将这个新的组合也添加到词汇库中并以该已知术语作为其标签。
[0066]
词汇库建好以后,就要利用它去电子病历中提取结构化的三元组信息了,信息提取的过程可以分为两步:第一步,首先用一种医学事件标记算法和一系列时间识别规则从电子病历文本中鉴别出医学术语和时间词汇,剩下的文本则被视为关于这些医学术语的候选描述;第二步,将每一个代表一种医学事件的术语与其发生的时间和存在的相关描述关联起来。
[0067]
其中,采用了一种简单的递归算法去标记每个句子里最长的代表某医学事件的术语,具体算法如下所示:
[0068][0069]
具体的,对于输入的每一个句子,先标记这个句子中所有可能的代表某医学事件的短语,从最长到最短,然后用一个布尔阵列去记录那些这些被标记的短语(真或假代表该短语应该或者不必加入到识别到的医学事件列表里),对每一个被标记的短语,首先看它的第一个和最后一个字符是否被标记了,如果它们中没有一个被标记,那么这个短语不需要被记录,于是布尔返回值为假,因为它的一部分或者全部很可能被包含在一个更长短语中;否则,检查该短语是否为词汇库中的收录,如果是,布尔返回值为真即要将它加入到被识别的医学事件里表中。
[0070]
一般而言,病历中记录的是患者已经经历过的事件,但也有例外,比如,“无恶寒”,“拟行前列腺电切术”等,这些事件是未发现的或者将要进行的,所以为了避免错误记录,该算法还将那些有表示否定或者将来行动的词或者短语作为前缀的医学事件从识别列表中去除,这些词包括,不是/没有/无、拒绝、未见、计划/拟/将、建议等等。
[0071]
医学事件的发生时间是一个重要描述信息,在病历中记录的时间信息可以多达九个组成部分,分别为:前置近似词,比如“约”;后置近似词,比如“左右”;数字;单位,比如“个”;时间单位,比如“年”;前置词,比如“前”;某个确定的时间,比如“昨天”;一天中某个确定的时间段,比如“下午”;或者一天中某个确定的时间点,比如“下午3点”等,这些代表时间的术语可以用以下两个正则表达式来表述:
[0072]
前置近似词?数字(单位)?(时间单位)(后置近似词)?前置词;
[0073]
(某个确定的时间)(一天中某个确定的时间段)?((前置近似词)?(一天中某个确定的时间点)(后置近似词)?)?。
[0074]
此外,在中文里六个惯用的词语并不属于以上两个正则表达式的格式,也被添加到时间术语列表里,它们是“昨晚”,“昨夜”,“今夜”,“今晚”,“今早”和“今晨”。
[0075]
时间的术语的覆盖范围遵守如下的规定:
[0076]
如果在一个陈述句中只包含一个时间术语,那么它代表整个陈述中事件的发生时间;
[0077]
如果一个陈述句中存在多个时间术语,那么每一个时间术语管辖的范围从公司术
语起直到下一个时间术语出现之前;
[0078]
如果一个陈述句是指在病历中用句号隔开的句子,在某个时间术语覆盖范围内的医学事件,都默认为是在该时间发生的事件。
[0079]
从电子病历中识别出医学事件及对应的时间后,剩下的文本包含着关于这些医学事件的候选描述,首先按照如下规则将其中明显不属于医学事件描述的句子去掉:
[0080]
如果句子中包含着前面提到的非医学事件的术语,比如“非恶寒”等;
[0081]
如果句子中包含病历中的一些常见用语,比如“入院”、“出院”、“住院”,“就诊”和“治疗”等。
[0082]
清理完毕后,接下来要在剩下的候选描述中,建立所有可能的“时间
‑
医学事件
‑
描述”三元组,再用一种二元的支持向量机(svm)模型将这些三元组分类为真或假组合,顾名思义,标记为真的组合就应该是某时间节点发生的医学事件在病历中的实际描述,反之,该三元组中的描述并非该事件的描述,一种描述可能针对好几种医学事件,而多种描述也可能只针对同一种医学事件。
[0083]
为了正确的将某种描述与其对应的医学事件相关联,该svm分类模型引入了以下8种特征:
[0084]
被识别出的医学事件前后三个字符;
[0085]
每个候选描述前后三个字符;
[0086]
一个候选描述是否包含数字;
[0087]
计算一个医学事件x和一个候选描述y之间的归一化谷歌距离(ngd),计算公式如下:
[0088][0089]
其中,m是一种搜索引引擎编制索引的网页总数,f(x)和f(y)是分别搜索x和y返回的搜索结果的数量,而f(x,y)是同时包含x和y的网页总数;
[0090]
两个医学事件之间被识别出的术语的数量;
[0091]
两个医学事件之间候选描述的数量;
[0092]
两个医学事件之间逗号的数量;
[0093]
被识别出的医学事件类型。
[0094]
上述八种特种,其中前三项属于局部文本背景特征,后面五项属于语义特征,找到所有标记为真的“时间
‑
医学事件
‑
描述”三元组输出为结构化的结果文件,在整个方案操作流程中,只在这个分类环节用到了少量的人工标记。
[0095]
实验例:
[0096]
用一个包含24817份真实电子病历的数据集去验证该方法的实际操作效果,其中24317份病历被用作该方法的训练集,另外400份作为抽出型测试集(gd
‑
400),剩下的100份作为调试集,这里用三个常见指标召回率、精确度和f1分数去评价和比较不同方案识别和匹配效果。
[0097]
用到的核心词汇库包含了31493个疾病相关术语,3723个症状相关,36725个药物相关,6666个身体部位相关,5758个疗程相关以及1019个临床检测相关术语,如果单用该核心词汇库去测试集gd
‑
400中识别医学术语,识别效果如下表所示:
[0098][0099]
结果显示,单用核心词汇进行识别,效果十分有限,特别是对疾病相关术语,身体部位和疗程相关术语的识别效果非常不理想。
[0100]
当用该方法中的富集方案之一—识别模式迭代法去扩充核心词汇,用得到的新词汇库在gd
‑
400中重复一次术语识别,得到的结果如下表所示:
[0101] 召回率(%)精确度(%)f1分数(%)疾病79.476.277.8药物87.591.989.8身体部位71.034.246.1疗程51.360.055.3症状87.589.588.5临床检测88.991.290.0综合84.879.081.8
[0102]
尽管综合识别能力提升不大,但疾病和药物相关术语的识别能力都有显著提高。
[0103]
在识别模式迭代法扩充的基础上再加上以身体部位前缀、方向型或者扩展型前缀这些特征性识别规则进一步扩充核心词汇库,得到涵盖范围更全面的新词汇库,它一共包含了33803个疾病相关术语,6306个症状相关,36792个药物相关,9551个身体部位相关,6092个疗程相关以及1386个临床检测相关术语,其识别效果如下表所示:
[0104][0105]
综合识别效果有显著提升(f1分数可达0.9),各类术语的识别能力都有不同程度的提高,特别是在对疾病和症状相关术语的识别上。
[0106]
此外,将这种扩充词汇库以识别医学术语的方案去和2014年发表在美国医学信息学会杂志上的一个条件随机场(crf)方案(同期最为流行的方案)相比较,结果如下表所示:
[0107][0108][0109]
*上面的值代表f1分数(召回率/精确度)(%)*
[0110]
总体来说,该方法与非精确匹配的crf方法在识别效果上相当,但是其识别能力显著优于精确匹配的crf方法。
[0111]
除了较全面和精确地鉴别出医学事件,该方法还在gd
‑
400测试集中检测到1338个时间术语,98.5%被鉴别出来的医学事件都被和它对应的时间正确关联起来,识别时间术
语的召回率和精确度分别是0.967和1.0。
[0112]
接下来就要将剩下文本中的候选描述与其对应的医学事件关联起来以形成“时间
‑
医学事件
‑
描述”三元组存入结果文件输出,该方法用以归一化谷歌距离(ngd)为特征之一的支持向量机(svm)模型去关联医学事件及其对应的描述(只是谷歌在中国国内不可用,所以在计算方式不变的情况下,用微软必应(bing)代替谷歌作为搜索引擎),与其它几种可行的模型相比,该方案的匹配效果几乎在各个指标上都高于其它几种方案,特别是在f1分数上(如下表所示,该方案的f1分数最高),其召回率,精确度和f1分数分别达到0.892,0.856和0.874,值得注意的是,与没有采用ngd特征的svm模型相比,该模型f1分数有较大提高,可见,创新采用这种跨领域的方法是十分合理的。
[0113][0114]
最后输出三元组结构化的信息,并得到该方案在端对端操作中,从测试集gd
‑
400中提取三元组结构化信息的效果分别为,召回率达到0.838,精确度为0.854而用于综合性评价的f1分数达到了0.846。
[0115]
有意效果:该方法采用数据驱动的富集模式有效扩充了用于自动识别的词汇库,使其在相关医学术语的识别上显著优于同时期最流行的监督学习模型(f1分数分别为0.896 vs 0.886),同时,该方法采用用归一化谷歌距离(ngd)为特征的支持向量机(svm)作为匹配模型,在事件及其相应描述的关联上,它同样比其它可行的方案都要优越(f1分数分别为0.874vs0.838),此外,该方法几乎不需要手动注释,容易实现规模化提取,并且在处理大量数据面对增加的变异和噪音时,也具有很好的稳定性。
[0116]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1