基于SHAP值构建可解释的XGBoost回归模型预测PCE的QSPR方法及其系统
基于shap值构建可解释的xgboost回归模型预测pce的qspr方法及其系统
技术领域
1.本发明涉及一种关于染料敏化太阳能电池(dsscs)中氮苝(n
‑
p)类有机敏化剂的功率转化效率(pce)的预测方法及系统,特别是基于shap值构建可解释的xgboost回归模型预测pce的定量结构关系(qspr)方法发现高效的氮苝类有机染料。
背景技术:
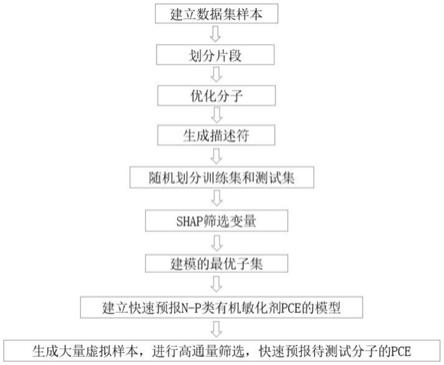
2.随着科学和社会的快速发展,缓解能源和污染问题迫在眉睫。自1991年o'regan和 michael发表突破性成果以来,染料敏化太阳能电池因其成本低、灵活性好、稳定性佳、室内效率高等优点而受到广泛关注。敏化剂作为dsscs的主要组成部分,在光捕获、电荷转移和电荷重组方面起着主导作用,这极大地影响了dsscs的关键参数—pce。其中,n
‑
p类纯有机染料具有优异的光学和物理性能,如高摩尔消光系数、高荧光量子效率和可调谐带隙等,在dsscs中作为光敏剂表现出相当高的光电转化效率。高效新型n
‑
p类敏化剂的发现将有效提高dsscs的pce,然而,可能的有机染料的化学空间非常巨大,实验的试错过程繁琐且昂贵。为了加快此类敏化剂的研发,有必要在实验前利用计算化学方法设计高效的潜在n
‑
p类敏化剂。
3.随着计算机软件和人工智能的不断发展,机器学习的应用也越来越广泛,发展出了一系列高性能的机器学习模型,例如,支持向量机、随机森林、深度学习等。xgboost是extreme gradient boosting的简称,是基于迭代累加的梯度提升决策树算法。xgboost是梯度增强回归树(gbrt)的改进与具体实现,由华盛顿大学的陈天奇最早于2014年提出。但这些机器学习模型内部原理难以理解。沙普利可加性模型(shap)方法将所有的特征都视为“贡献者”,对于每个预测样本,模型都产生一个预测值,shap值就是该样本中每个特征所分配到的数值。shap值最大的优势是反映每一个特征对目标特征的贡献,同时表现出其贡献的正负性。所以,利用shap嵌套xgboost选择特征并解释模型对研发高效n
‑
p类敏化剂很意义。
4.利用shap嵌套xgboost技术建立的定量构效关系(qspr)模型,用来分析分子结构与分子的某种性质之间的关系。模型中使用的候选描述符可以定量或定性的描述分子结构,分子组成(如氢键供体数、化学键数)、理化性质(如酯水分布系数)和分子形状等参数。近年来,qspr模型已被用于预测不同类型太阳能电池的pce值。毫无疑问,以上方法的模型为太阳能电池材料的设计提供了一些指导。但如何将xbgoost算法应用于预测n
‑
p类有机敏化剂的pce还需要进一步地探索和研究。
技术实现要素:
5.为了解决现有技术的问题,本发明的目的在于克服已有技术存在的不足,提供一种基于shap值构建可解释的xgboost回归模型预测pce的qspr方法及其系统,能加速发现高pce的n
‑
p类有机敏化剂,通过dragon计算得到n
‑
p类结构的描述符,利用shap嵌套xgboost
筛选特征,并借助xgboost算法建模,预测n
‑
p类有机敏化剂的pce,高通量筛选候选高pce的有机染料。该方法的成本低、简单高效、数据完整准确、无需实验、无需复杂的计算过程、无污染。
6.为达到上述发明创造目的,本发明采用如下技术方案:
7.一种基于shap值构建可解释的xgboost回归模型预测pce的qspr方法,包括以下步骤:
8.1)利用计算机系统查找文献,从文献中搜索n
‑
p类染料分子的结构、电解质条件及其对应的pce值;
9.2)将收集到的染料分子分成三个片段,前两个片段为ds(doner space)和dc(doner core),前两个片段为具有推电子基的供体,最后一个片段为a(accepter),具有吸电子基的受体,最后一个片段为后续解释片段作用和高通量筛选做准备;
10.3)用chemdraw画出染料分子的片段结构,在chem3d中通过mm2
‑
minimize energy优化分子,再用dragon软件生成描述符;
11.4)以pce值为目标变量,dragon生成的描述符为自变量,进行数据预处理,将预处理后的数据集样本作为后续建模的数据集样本;
12.5)对初步筛选的数据集,随机划分训练集和测试集,测试集的比例占整个数据集的15%,其中电解质条件在测试集和训练集中分布相同;
13.6)利用shap嵌套xgboost方法根据目标变量的“贡献值”筛选变量,xgboost建模的最优变量子集选择通过比较留一法交叉验证得到;
14.7)用xgboost回归建立n
‑
p类有机敏化剂pce的快速预报模型;
15.8)根据建立的n
‑
p类有机敏化剂pce的快速预报模型,预报待检测分子的功率转化效率pce;
16.9)根据shap值的正负影响进一步得到变量与目标变量的关系;
17.10)查阅文献,利用参考文献中对于特征的解释,结合在步骤9)中的根据shap值的正负影响进一步得到的变量,构建qspr模型;
18.11)查阅文献参考性能优异分子,通过编程自动生成大量的虚拟样本,将这些虚拟样本投入到构建好的qspr模型中,进行高通量筛选,快速预报出n
‑
p类有机敏化剂的功率转化效率pce值。
19.优选地,在所述步骤1)中,查找文献后,对得到的数据样本进行预处理,包括整理样本的分子结构、电解质条件和pce,确定样本数据个数。
20.优选地,在所述步骤6)和步骤7)中,对于某一个特征变量,利用treeshap计算出所有样本中对应该变量的shap值,将其平均值作为该特征变量的重要性值,从而得到全局解释;利用shap嵌套xgboost方法筛选变量,从一个初始朴素模型开始,基于样本集中观测值的误差,建立新模型进行拟合,并以加法形式添加至现有模型,反复迭代此过程形成集成模型。
21.优选地,在所述的步骤11)中,高通量筛选的方法包括以下步骤:
22.设计条件为:
23.选择文献中实验或理论研究pce>12.5%的分子,划分片段、优化分子和生成描述符的过程同上,利用python编程生成大量虚拟样本;
24.然后将生成的大量的虚拟样本投入到已构建完成的预测模型中,进行预报。
25.一种实施定量结构关系方法预测有机敏化剂的功率转化效率的系统,执行本发明基于shap值构建可解释的xgboost回归模型预测pce的qspr方法,包括:
26.输入模块:从公开发表的文献中查找n
‑
p类染料分子的结构、电解质条件及其对应的pce值,并作为输入数据;
27.数据分析模块:利用输入模块获得的数据,执行基于shap值构建可解释的xgboost回归模型预测pce的qspr方法,预测有机敏化剂的功率转化效率;
28.输出模块:将有机敏化剂的功率转化效率输出。
29.本发明与现有技术相比较,具有如下显而易见的突出实质性特点和显著优点:
30.1.本发明预测n
‑
p类有机敏化剂pce的过程简单、快捷、高效;利用chem3d
‑
mm2
‑
minimize energy优化后结合dragon软件将n
‑
p类染料分子片段生成描述符,仅需几秒就能得到所有样本的原子性质及结构参数;经过shap筛选特征与xgboost回归建模,可提前预判n
‑
p类有机敏化剂的pce,也能给染料敏化太阳能电池的研发人员提供参考,缩短研发时间,降低研发成本;
31.2.本发明对于每个预测样本,都产生一个预测值,shap值就是该样本中每个特征所分配到的数值;利用shap值与目标特征值之间的正负性关系结合领域知识解释特征,构建qspr模型,更深入理解分子结构、电解质条件和光电转化效率的关系,帮助解决大部分方法中特征无法解释的缺点,进而帮助建模人员深度理解并应用模型;
32.3.本发明的高通量筛选结果,对于片段的随机组合过程不涉及实验及化学品,不产生环境污染,符合绿色环保理念,多快好省地获得高性能的新型候选染料分子。
附图说明
33.图1为本发明实施流程图。
34.图2为本发明的部分染料分子(c261和c275)的片段划分范例图。
35.图3为本发明的shap嵌套xgboost特征筛选结果图。
36.图4为本发明预测n
‑
p类有机敏化剂pce的xgboost回归模型留一法交叉验证结果图。
37.图5为本发明预测n
‑
p类有机敏化剂pce的xgboost回归模型独立测试集结果图。
38.图6为本发明的shap嵌套xgboost筛选的特征对输出值的影响图。
具体实施方式
39.以下结合具体的实施例子对上述方案做进一步说明,本发明的优选实施例详述如下:
40.实施例一:
41.在本实施例中,参见图1,一种基于shap值构建可解释的xgboost回归模型预测pce的qspr方法,包括以下步骤:
42.1)利用计算机系统查找文献,从文献中搜索n
‑
p类染料分子的结构、电解质条件及其对应的pce值;
43.2)将收集到的染料分子分成三个片段,前两个片段为ds(doner space)和dc
(doner core),前两个片段为具有推电子基的供体,最后一个片段为a(accepter),具有吸电子基的受体,最后一个片段为后续解释片段作用和高通量筛选做准备;
44.3)用chemdraw画出染料分子的片段结构,在chem3d中通过mm2
‑
minimize energy优化分子,再用dragon软件生成描述符;在chem3d中通过mm2
‑
minimize energy优化分子并用dragon生成描述符,是一种快速且准确的方式描述分子结构;
45.4)以pce值为目标变量,dragon生成的描述符为自变量,进行数据预处理,将预处理后的数据集样本作为后续建模的数据集样本;
46.5)对初步筛选的数据集,随机划分训练集和测试集,测试集的比例占整个数据集的15%,其中电解质条件在测试集和训练集中分布相同;
47.6)利用shap嵌套xgboost方法根据目标变量的“贡献值”筛选变量,xgboost建模的最优变量子集选择通过比较留一法交叉验证得到;
48.7)用xgboost回归建立n
‑
p类有机敏化剂pce的快速预报模型;
49.8)根据建立的n
‑
p类有机敏化剂pce的快速预报模型,预报待检测分子的功率转化效率pce;
50.9)根据shap值的正负影响进一步得到变量与目标变量的关系;
51.10)查阅文献,利用参考文献中对于特征的解释,结合在步骤9)中的根据shap值的正负影响进一步得到的变量,构建qspr模型;
52.11)查阅文献参考性能优异分子,通过编程自动生成大量的虚拟样本,将这些虚拟样本投入到构建好的qspr模型中,进行高通量筛选,快速预报出n
‑
p类有机敏化剂的功率转化效率pce值。
53.本实施例基于shap值构建可解释的xgboost回归模型预测pce的qspr方法及其系统,能加速发现高pce的n
‑
p类有机敏化剂,通过dragon计算得到n
‑
p类结构的描述符,利用shap嵌套xgboost筛选特征,并借助xgboost算法建模,预测n
‑
p类有机敏化剂的pce,高通量筛选候选高pce的有机染料。该方法的成本低、简单高效、数据完整准确、无需实验、无需复杂的计算过程、无污染。
54.实施例二
55.本实施例与实施例一基本相同,特别之处在于:
56.在本实施例中,在所述步骤1)中,查找文献后,对得到的数据样本进行预处理,包括整理样本的分子结构、电解质条件和pce,确定样本数据个数。
57.在本实施例中,在所述步骤6)和步骤7)中,对于某一个特征变量,利用treeshap计算出所有样本中对应该变量的shap值,将其平均值作为该特征变量的重要性值,从而得到全局解释;利用shap嵌套xgboost方法筛选变量,从一个初始朴素模型开始,基于样本集中观测值的误差,建立新模型进行拟合,并以加法形式添加至现有模型,反复迭代此过程形成集成模型。
58.在本实施例中,利用shap方法结合xgboost筛选特征,选出建模的最优特征子集,由原来的984个特征筛选到6个特征;采用xgboost算法,建立快速预报n
‑
p类有机敏化剂pce的模型;根据筛选得到的6个特征,查阅文献结合shap对目标特征的“贡献”正负影响与分子结构相联系进行解释,构建qspr模型;
59.在本实施例中,在所述的步骤11)中,高通量筛选的方法包括以下步骤:
60.设计条件为:
61.选择文献中实验或理论研究pce>12.5%的分子,划分片段、优化分子和生成描述符的过程同上,利用python编程生成大量虚拟样本;
62.然后将生成的大量的虚拟样本投入到已构建完成的预测模型中,进行预报。
63.本实施例方法通过计算n
‑
p类敏化剂结构的描述符,利用shap结合xgboost方法筛选特征并建模,预测n
‑
p类敏化剂的pce值。这些方法几分钟就可得到结果,方便快捷,无需实验和繁杂的计算。同时,通过高通量筛选避免了仅凭经验盲目试凑而难以得到的高性能(pce>12.5%)的分子片段组合。本实施例基于shap值构建可解释的xgboost回归模型加速发现高pce的n
‑
p类有机敏化剂的qspr方法,建立数据集样本;切分分子片段;chem3d优化分子;生成描述符;随机划分训练集和测试集;利用shap嵌套xgboost筛选变量,选出xgboost建模的最优变量子集;用xgboost回归建立n
‑
p类有机敏化剂的快速预报模型;根据建立的模型,快速预报测试集染料分子的pce。根据shap反馈的对目标特征的影响和参考文献解释描述符,对应分子片段的结构,构建qspr模型;python生成大量虚拟样本,利用建好的xgboost模型进行预报。本实施例基于可靠的文献真实值和建模方法,所建的n
‑
p类有机敏化剂的xgboost预报模型具有方便快捷,无化学污染的优点。
64.实施例三
65.本实施例与上述实施例基本相同,特别之处在于:
66.在本实施例中,所述的步骤2)将收集到的染料分子根据吸电子和推电子能力的基团经验性规则分成三个片段,ds和dc片段为推电子的供体,a片段为吸电子的受体,为后续解释片段和高通量筛选做准备;其中片段的连接处用自由基代替,具体划分方式的举例参见图2,后续片段的实例以字母代替。
67.在本实施例中,所述的步骤3)中用chemdraw画出收集到的n
‑
p类染料分子的2d结构,后在chem3d
‑
calculations
‑
mm2
‑
minimize energy简单计算分子的最优结构,最后用dragon软件生成相应描述符。
68.在本实施例中,所述的步骤6)中shap嵌套的xgboost对特征进行降维,将特征先从984个筛选至10个,后将10个特征重新排序,特征参见图3,运用xgboost算法进行建模,通过比较留一法交叉验证的评价标准筛选得到最优特征子集,比较留一法交叉验证的评价标准包括相关系数r、决定系数r2和均方根误差rmse,图3中排名前6位。
69.在本实施例中,所述的步骤10)中查阅文献结合shap对目标特征的“贡献”正负影响与分子结构相联系对筛选得到的6个特征进行解释,构建qspr模型。
70.本实施例方法对数据进行预处理,对数据进行计算和排序,是一种低成本、简单高效、数据完整准确、无需实验、无需复杂的计算过程。
71.实施例四
72.本实施例与上述实施例基本相同,特别之处在于:
73.在本实施例中,
74.一种基于shap值构建可解释的xgboost回归模型预测pce的qspr方法,包括如下步骤:
75.1)通过调研文献,从文献中搜索n
‑
p类染料分子和pce值,作为后续建模的数据集样本。部分n
‑
p类染料分子的结构片段组合与pce值如表1所示;表1未标注为钴基电解质,片
段划分参见图2;
76.表1.n
‑
p类染料分子结构及pce值的部分数据样本集表
77.染料名称ds结构dc结构a结构pce(%)c261ds1dc1a18.8c261(碘基)ds1dc1a16.3c275ds15dc14a812.5nd04ds9dc9a47.0nps
‑
1ds2dc13a14.9c281ds5dc7a913.0cpd
‑
2ds6dc3a125.2c276ds5dc15a79.4
78.2)用dragon软件对chemdraw和chem3d优化后的n
‑
p类染料分子片段结构生成描述符,每个片段都生成了5271个描述符,部分描述符如表2所示;
79.表2.部分n
‑
p类染料分子部分描述符表
80.染料名称目标值(pce)elds
‑
mwdc
‑
ve1sign_ddc
‑
ic4a
‑
nr06c2618.8
‑
5.1368.590.60012224.830150c261(碘基)6.3
‑
4.6368.590.60012224.830150c27512.5
‑
5.1241.490.00249335.614262nd047.0
‑
5.1101.190.42481524.875082nps
‑
14.9
‑
5.1244.330.40068865.578120c28113.0
‑
5.1317.5905.268462cpd
‑
25.2
‑
5.1133.230.22854004.147161c2769.4
‑
5.1317.590.66342445.391112
81.3)去除皮尔逊相关系数>0.95的描述符,以防过拟合,初步筛选数据集获得974个描述符;随机划分训练集与测试集,比例为5:1,训练集与测试集的样本量分别为45个和9个;
82.4)以shap嵌套xgboost方法筛选描述符,首先选出影响最强的前10个描述符,参见图3,分别为dc
‑
spmin2_bh(s),el,dc
‑
mw,a
‑
p_vsa_s_6,a
‑
mats8e,ds
‑
gats1s,dc
‑
psi_i_a,ds
‑
gats5m,a
‑
jgi10,a
‑
cic4;再次使用shap嵌套的xgboost方法重新排序,对训练集n
‑
p类染料分子数据进行建模,根据留一法交叉验证的评价标准,评价标准包括r和rmse,获得最优子集,部分样本的6个最优描述符的数据如表3所示:
83.表3.部分染料的6个最优描述符的数据表
[0084][0085]
5)利用xgboost算法对训练集45个n
‑
p类染料分子数据样本进行回归建模,建立n
‑
p类有机敏化剂的xgboost快速预报模型。
[0086]
在本实施例中,基于45个样本建立的n
‑
p类有机敏化剂的快速预报xgboost回归模型的留一法交叉验证的结果,如图4所示。用6个特征建模的留一法交叉验证结果中,n
‑
p类染料分子的文献真实值与模型预报值最接近,其r为0.897,rmse为1.103。
[0087]
在本实施例中,基于shap筛选特征建立的n
‑
p类有机敏化剂的预报xgboost回归模型的独立测试集预报结果,如图5所示。对测试集中的9个样本进行预报,预报结果较好,文献真实值与预报值的r为0.880,rmse为1.098。
[0088]
本实施例方法通过来源于文献样本数据,建立了n
‑
p类有机敏化剂的shap筛选特征xgboost快速预报模型,具有低成本和绿色环保的优点,对数据建模方法的稳定性与可靠性做出评估,结果较好,同时也可以对实验实际操作起指导作用,避免盲目性。
[0089]
实施例五
[0090]
本实施例与上述实施例基本相同,特别之处在于:
[0091]
在本实施例中,参见图6,在本实施例中,利用shap嵌套xgboost方法,计算每个特征值对目标特征的正负性影响,进一步解释特征与目标特征之间的关系。红色表示特征值影响强,蓝色值表示特征影响弱。红色点出现在正影响中多,蓝色点出现在负影响中多,表示这一特征与目标特征为正相关;红色点出现在负影响中多,蓝色点出现在正影响中多,表示这一特征与目标特征为负相关。可见,dc
‑
spmin2_bh(s)特征与目标特征是正相关,el为负相关,dc
‑
mw是正相关,a
‑
p_vsa_s_6是正相关,a
‑
mats8e是负相关,ds
‑
gats1s正相关。
[0092]
在本实施例中,查阅有关6个特征的文献,解释其结构和电解质条件与pce的关系,建立qspr模型。dc
‑
spmin2_bh(s)特征表示dc片段的固有状态修正矩阵的最小状态绝对特征值
‑
n2/以相对固有状态的加权;el为电解质条件,表明钴基电解质相对于碘基电解质对于dssc的光电转化效率更好;dc
‑
mw是dc片段的分子质量,说明dc片段分子质量越大,pce越高;a
‑
p_vsa_s_6是a片段的分子范德华表面积,说明a片段分子范德华表面积越大,对pce越有优势;a
‑
mats8e是a片段的原子桑德森电负性加权的滞后8的莫兰自相关;ds
‑
gats1s是ds片段的用固有状态加权的滞后1的盖瑞自相关,解释了ds片段的内在状态,比如π和归队电子数越多,pce值越高,模型预测的更多地是具有较长半衰期的稳定分子。
[0093]
实施例六
[0094]
本实施例与上述实施例基本相同,特别之处在于:
[0095]
在本实施例中,基于shap值构建可解释的xgboost回归模型加速发现高pce的n
‑
p类有机敏化剂的qspr方法,在文献中选择高pce样本加入到原始数据集,将6个特征按照同上方法获得特征值,利用python生成的大量虚拟样本,进行高通量筛选,部分样本筛选结果如表4所示。
[0096]
表4.部分高通量筛选特征值与预测结果表
[0097][0098]
本实施例将生成的90719个虚拟样本投入建立好的模型,预报其对应pce,挑选出pce>12.8%的分子片段组合指导实验。
[0099]
实施例七
[0100]
本实施例与上述实施例基本相同,特别之处在于:
[0101]
在本实施例中,一种实施定量结构关系方法预测有机敏化剂的功率转化效率的系统,执行上述实施例基于shap值构建可解释的xgboost回归模型预测pce的qspr方法,包括:
[0102]
输入模块:从公开发表的文献中查找n
‑
p类染料分子的结构、电解质条件及其对应的pce值,并作为输入数据;
[0103]
数据分析模块:利用输入模块获得的数据,执行基于shap值构建可解释的xgboost回归模型预测pce的qspr方法,预测有机敏化剂的功率转化效率;
[0104]
输出模块:将有机敏化剂的功率转化效率输出。
[0105]
本实施例系统能对染料敏化太阳能电池(dsscs)中氮苝(n
‑
p)类有机敏化剂的功率转化效率(pce)进行快速预测,特别是基于shap值构建可解释的xgboost回归模型预测pce的定量结构关系(qspr),有助于低成本,高效率发现高效的氮苝类有机染料。
[0106]
综上所述,上述实施例基于shap值构建可解释的xgboost回归模型加速发现高pce的n
‑
p类有机敏化剂的qspr方法,包括以下步骤:(1)从文献中搜索n
‑
p类有机敏化剂的结构、电解质条件及其对应的pce值;(2)将收集到的染料分子根据一定的规则分成三个片段,ds和dc片段为供体,a片段为受体;(3)用chemdraw画出染料分子的片段结构,在chem3d中优化分子,再用dragon软件生成描述符;(4)以pce值为目标特征,dragon生成的描述符和电解质条件为特征,进行数据预处理,将预处理后的数据集样本作为后续建模的数据集样本;(5)将数据集随机划分训练集和测试集,比例为5:1(其中电解质条件在测试集和训练集中分布相同)(6)利用shap嵌套xgboost方法根据目标特征的“贡献值”筛选特征,通过比较留一法交叉验证得到xgboost建模的最优特征子集;(7)用xgboost建立n
‑
p类有机敏化剂pce的快速预报回归模型;(8)根据建立的n
‑
p类有机敏化剂pce的快速预报模型,预报测试集的pce;(9)查阅文献结合shap解释特征,进一步得到特征与目标特征的关系,构建qspr模型;
(10)查阅文献参考性能优异分子,通过python自动生成大量的虚拟样本,将这些虚拟样本投入到构建好qspr模型中,进行高通量筛选,快速预报出新组合的n
‑
p类染料分子的pce。上述实施例基于可靠的文献真实值和建模方法,所建的n
‑
p类有机敏化剂的预报模型具有方便快捷,无化学污染等优点。
[0107]
上述实施例方法避免了重复试验,不断试错的过程,利用chem3d优化分子,dragon软件生成结构描述符,经过shap嵌套xgboost方法特征筛选并建模,可提前预判n
‑
p类有机敏化剂的pce值,操作过程简单、成本低和无污染,仅需一人便可完成;上述实施例方法中利用shap和参考文献解释特征,构建qspr模型,更好地解释了染料分子结构、电解质条件和功能的关系,帮助解决大部分方法不能解释的缺点;上述实施例方法是用xgboost建立快速预报n
‑
p类有机敏化剂pce的qspr模型,通过python自动生成大量的虚拟样本,将这些样本投入到构建好的qspr模型中进行高通量筛选,快速预报出片段新组合的染料分子的pce,给dssc的研发人员提供参考,缩短研发时间,降低研发成本。
[0108]
上面对本发明实施例结合附图进行了说明,但本发明不限于上述实施例,还可以根据本发明的发明创造的目的做出多种变化,凡依据本发明技术方案的精神实质和原理下做的改变、修饰、替代、组合或简化,均应为等效的置换方式,只要符合本发明的发明目的,只要不背离本发明的技术原理和发明构思,都属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1