一种基于多轮问诊的标准症状抽取方法与流程
文档序号:28434655发布日期:2022-01-12 01:42阅读:170来源:国知局
导航: X技术> 最新专利>医药医疗技术的改进;医疗器械制造及应用技术
1.本发明属于医疗自然语言处理技术领域,具体是指一种基于多轮问诊的标准症状抽取方法。
背景技术:
2.在线问诊是指医生通过在线对话和患者进行病情交流并且提供相关的医疗建议。随着“互联网+医疗”迅速发展,在线问诊需求增长迅速,然而医生资源是稀缺的,因此,自动化医疗问诊技术便显得尤为重要。自动化医疗问诊可以实现人机对话来辅助问诊过程,标准症状抽取是其中重要的模块。通过从未结构化的对话文本中抽取结构化的标准症状信息,能够帮助医生迅速了解病人信息,进而给出相关诊断。
3.目前,对问诊对话文本进行标准症状抽取的方法通常是由实体识别模型识别出文本中所包含的症状信息,再经由人工整理的医学标准化对照词典对症状进行标准化。但是,上述方法默认在文本中提及的症状皆是患者当前所患症状,这一前提导致通过上述方法所抽取得到的标准症状信息存在大量与当前诊断无关的信息,影响在线问诊效果。同时,依靠医学专业人员使用人工的方式整理医学标准化对照词典,工作量大并且覆盖率低。
技术实现要素:
4.为了解决现有标准症状抽取方法覆盖率欠佳和抽取结果噪声过大的问题,本发明提供了一种基于多轮问诊的标准症状抽取方法。
5.本发明采用的技术方案包括如下步骤:
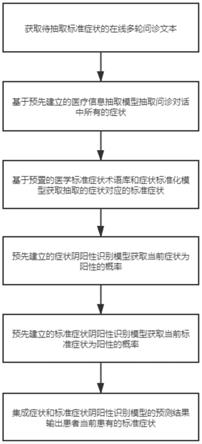
6.步骤1)获取待抽取标准症状的在线多轮问诊文本,并对多轮问诊文本数据进行数据清洗,得到初始文本;所述数据清洗包括统一化大小写、去除停用词、去除特殊符号(表情包和html标签)、去除冗余数据等;
7.步骤2)采用基于bert模型的医疗信息抽取模型对步骤1)得到的初始文本中的每段问诊文本进行症状信息抽取,获取初始文本中提及的所有症状;
8.步骤3)基于bert模型的症状标准化模型对通过步骤2)从每段问诊文本抽取的每个症状进行标准化,从而获取每个症状对应的标准症状;
9.步骤4)将步骤2)中每个抽取的症状及其所在的问诊文本段落输入基于bert模型的症状阴阳性识别模型,判断此症状是否为患者当前所患有;
10.步骤5)对于步骤2)中获取的每个症状,将所有属于同一个标准症状的症状所在的问诊文本以分号作为分隔符拼接成新文本,记作标准症状所在的拼接后的问诊文本;
11.步骤6)将每个步骤5)获取的标准症状所在的拼接后的问诊文本及对应的标准症状输入基于bert模型的标准症状阴阳性识别模型,判断输入的标准症状是否为患者当前患有;
12.步骤7)综合步骤4)和步骤6)的症状阴阳性识别概率,判断患者是否患有在线多轮问诊中抽取的标准症状。
13.所述步骤2)具体包括以下步骤:
14.2.1)将每段问诊文本输入医疗信息抽取模型,并将输入组织成下述bert形式;
15.token的输入为:[cls]问诊文本[sep];
[0016]
如:问诊文本“细菌性感染,需要用抗生素类药物”被组织为“[cls]细菌性感染,需要用抗生素类药物[sep]”;
[0017]
segment的输入为:问诊文本中每个字符对应的编码为1,[cls]、[sep]对应的编码均为1;
[0018]
position的输入为:将问诊文本中的每个字符按阿拉伯数字顺序进行位置编码,起始编码为0;[cls]、[sep]的位置编码均为0;
[0019]
如:输入“[cls]细菌性感染,需要用抗生素类药物[sep]”,则“[cls]”的位置编码为0,“细”为0,“菌”的位置编码为1,“[sep]”的位置编码为0;
[0020]
2.2)采用bert对步骤2.1)输入的问诊文本进行文本语义编码,获取问诊文本中各字符对应的融合全文语义信息后的语义特征向量;
[0021]
2.3)将步骤2.2)中获取的语义特征向量乘以分类参数矩阵,再加上一个偏置参数,从而每个字符生成与预设的字符类型标签数量相等维度的分类向量;
[0022]
预设的字符类型标签由实体类型标签、“b
‑”
和“i
‑”
构成,实体类型标签包括症状(symptom)、疾病(disease)、检查(exam)、药品(drug)、药品类型(drug category)和身体部位(body parts)等,本发明中预设的字符类型标签包括b-symptom、i-symptom、b-disease、i-disease、b-exam、i-exam、b-drug、i-drug、b-drug_category、i-drug_category、b-body_parts和i-body_parts等。
[0023]
2.4)通过softmax函数将步骤2.3)中生成的分类向量转化为概率输出;选取概率最大的分类向量对应的字符类型标签作为每个字符的预测结果;
[0024]
如:“细菌性感染,需要用抗生素类药物”的预测标签为“b-symptom i-symptom i-symptom i-symptom i-symptom o o o o b-drug_category i-drug_category i-drug_category o o o”;
[0025]
其中,“b-symptom”表示该字符是某一实体症状的起始,“i-symptom”表示该字符是构成某一实体症状的字符但并非起始,“b-drug_category”表示该字符是某一实体药品类别的起始,“i-drug_category”表示该字符是构成某一实体药品类别的字符但并非起始,“o”表示该位置的字符不参与构成实体;
[0026]
2.5)将问诊文本中实体类型标签同类的连续字符进行组合获得一种或多种医疗实体,并记录医疗实体对应的实体类型标签;
[0027]
医疗实体包括症状、疾病、检查、药品、药品类别和身体部位等;
[0028]
2.6)对初始文本中每段问诊文本采用步骤2.1)~2.5)的操作,获取每段问诊文本的医疗实体和其对应的实体类型标签;
[0029]
2.7)过滤每段问诊文本中实体类型标签不为症状的医疗实体,过滤后的医疗实体即为每段问诊文本中包含的所有症状。
[0030]
如:“细菌性感染,需要用抗生素类药物”抽取医疗实体并过滤后的结果为“细菌性感染”。
[0031]
其中,所述医疗信息抽取模型是在预训练bert的基础上基于带有标注信息的医疗
文本数据训练得到。
[0032]
所述步骤3)具体包括以下步骤:
[0033]
3.1)获取预置的医学标准症状术语库,将步骤2)抽取的每个症状与医学标准症状术语库中的一个医学标准症状术语输入症状标准化模型,输入组织成下述bert形式:
[0034]
其中,医学标准症状术语库包括但不限于:icd-10、医学知识图谱、标准化医疗术语集等;
[0035]
token的输入为:[cls]抽取的症状[sep]医学标准症状术语库中的医学标准症状[sep];
[0036]
抽取的症状为通过步骤2)从每段问诊文中获得的症状;
[0037]
如:“[cls]细菌性感染[sep]细菌感染[sep]”或“[cls]细菌性感染[sep]咳嗽[sep]”;
[0038]
segment的输入为:抽取的症状对应编码为0,医学标准症状术语库中的医学标准症状对应编码为1,符号[cls]和第一个[sep]对应编码为0,第二个[sep]对应的编码为1;
[0039]
position的输入为:将抽取的症状和医学标准症状术语库中的医学标准症状分别按阿拉伯数字顺序进行位置编码,每个症状的起始编码为0,[cls]、[sep]对应的编码均为0;
[0040]
如:对“[cls]细菌性感染[sep]细菌感染[sep]”的位置编码中“[cls]”和“[sep]”为0,“细菌性感染”分别为“0 1 2 3 4”,“细菌感染”分别为“0 1 2 3”;
[0041]
3.2)采用bert对步骤3.1)的输入文本进行文本语义编码,获取输入的各字符对应的融合全文语义信息后的向量,所述向量为包含抽取症状和医学标准症状之间相似度的语义特征向量;
[0042]
3.3)将步骤3.2)中获取的[cls]对应的语义特征向量输入单层全连接层,并采用sigmoid函数激活后得到抽取的症状和医学标准症状之间的相似度,相似度位于0-1之间;
[0043]
3.4)对于每段问诊文本中每个抽取的症状,将抽取的症状与医学标准症状术语库中每个医学标准症状进行步骤3.1)~步骤3.3)的操作,获取抽取的症状与医学标准症状术语库中所有医学标准症状之间的语义相似度;取与抽取症状语义相似度最高的医学标准症状作为标准化的结果,即每个抽取症状对应的标准症状;
[0044]
如:“细菌性感染”与“细菌感染”相似度最高,则“细菌性感染”标准化结果为“细菌感染”;
[0045]
3.5)对步骤2)抽取的所有症状采用步骤3.4)的操作,获取每个抽取症状对应的标准症状。
[0046]
所述步骤4)具体包括以下步骤:
[0047]
4.1)将问诊文本的输入者信息融入症状所在的问诊文本:若问诊文本的输入者为患者,则在问诊文本前拼接“患者:”;若文本的输入者为医生,则在问诊文本前拼接“医生:”;
[0048]
如:若“细菌性感染,需要用抗生素类药物”是医生输入的文字,则其应被处理成“医生:细菌性感染,需要用抗生素类药物”,否则应被处理成“患者:细菌性感染,需要用抗生素类药物”;
[0049]
4.2)将模型的输入信息组织成下述bert形式:
[0050]
token的输入为:[cls]症状[sep]症状所在的问诊文本[sep];
[0051]
如:问诊文本“医生:细菌性感染,需要用抗生素类药物”被组织为“[cls]细菌性感染[sep]医生:细菌性感染,需要用抗生素类药物[sep]”;
[0052]
segment的输入为:症状对应编码为0,症状所在的问诊文本对应编码为1;
[0053]
position的输入为:症状和症状所在的问诊文本中的每个字符分别按阿拉伯数字顺序进行位置编码,起始编码为0;
[0054]
4.3)采用bert对输入信息进行文本语义编码,获取输入的每个字符对应的融合全文语义信息后的向量,所述向量为包含症状是否为阳性的语义特征向量
[0055]
4.4)将步骤4.3)中获取的[cls]对应的语义特征向量输入单层全连接层,并采用sigmoid函数激活后得到通过语义判断症状为阳性的概率;当症状阴阳性识别模型预测症状为阳性的概率大于或等于0.5时,判断当前症状为阳性,反之为阴性。
[0056]
其中,阳性表示患者当前患有该症状,阴性表示患者当前不患有该症状。如问诊文本“患者:昨天和室友点外卖,现在都出现了腹泻的情况,室友更严重,一直呕吐”中“腹泻”为阳性,“呕吐”为阴性;
[0057]
症状阴阳性识别模型是在预训练bert的基础上基于带有阴阳性标注信息的医疗文本数据训练得到。
[0058]
所述步骤5)具体包括以下步骤:
[0059]
5.1)对于步骤2)中获取的症状,将文本输入者信息融入症状所在的问诊文本,获得融入文本输入者信息的问诊文本:若文本的输入者为患者,则在问诊文本前拼接“患者:”;若文本的输入者为医生,则在问诊文本前拼接“医生:”;
[0060]
5.2)将属于同一个标准症状的症状所在的融入文本输入者信息的问诊文本以分号作为分隔符拼接成新文本作为该标准症状的上下文信息,记为标准症状所在的拼接后的问诊文本。
[0061]
如:“患者:她前面查血是细菌导致的感染”中的“细菌导致的感染”和“医生:细菌性感染,需要用抗生素类药物”中的“细菌性感染”都可被标准化为“细菌感染”,则可将文本组织为“患者:她前面查血是细菌导致的感染;医生:细菌性感染,需要用抗生素类药物”。
[0062]
所述步骤6)具体包括以下步骤:
[0063]
6.1)将输入标准症状阴阳性识别模型的信息组成下述bert形式,并加入文本输入者信息type:
[0064]
token的输入为:[cls]标准症状[sep]标准症状所在的问诊文本[sep];
[0065]
如图5所示:步骤5.2)中的标准症状和标准症状所在的问诊文本应被组织为“[cls]细菌感染[sep]患者:她前面查血是细菌导致的感染;医生:细菌性感染,需要用抗生素类药物[sep]”;
[0066]
segment的输入为:标准症状对应编码为0,标准症状所在的拼接后的问诊文本对应编码为1;
[0067]
position的输入为:标准症状中的所有字符按阿拉伯数字顺序进行位置编码,起始编码为0;标准症状所在的拼接后的问诊文本中的所有字符以未拼接前文本为编码单位(包含分号和[sep]),每个编码单位内以0作为起始编码按阿拉伯数字顺序进行位置编码;
[0068]
如:“[cls]细菌感染[sep]患者:她前面查血是细菌导致的感染;医生:细菌性感
染,需要用抗生素类药物[sep]”的位置编码中,“细菌感染”为“0 1 2 3”,“患”为0,“医”为0,[cls]和[sep]皆为0;
[0069]
type的输入为:标准症状对应编码为0;标准症状所在的拼接后的问诊文本中输入者为医生的文本对应编码为1,输入者为患者的文本对应编码为2,[cls]和[sep]对应编码为0;
[0070]
如:“[cls]细菌感染[sep]患者:她前面查血是细菌导致的感染;医生:细菌性感染,需要用抗生素类药物[sep]”的type编码中,“细菌感染”皆编码为0,“患者:她前面查血是细菌导致的感染;”皆编码为2,“医生:细菌性感染,需要用抗生素类药物”皆编码为1,[cls]和[sep]皆为0;
[0071]
6.2)采用bert对token的输入、segment的输入和position的输入进行文本语义编码,获取输入的各字符对应的融合全文语义信息后的向量,所述向量为包含标准症状是否为阳性的语义特征向量;
[0072]
6.3)type的输入通过type嵌入层映射到type向量;所述type嵌入层为可训练的参数矩阵,可通过模型根据损失函数自学习得到;
[0073]
6.4)将步骤6.2)中获取的语义特征向量与步骤6.3)获取的type向量进行拼接,拼接后的向量通过一个激活函数为relu函数的全连接层获取融入type信息的语义特征向量;
[0074]
6.5)将[cls]对应的融入type信息的语义特征向量输入全连接层,并通过sigmoid函数激活后得到标准症状为阳性的概率。
[0075]
其中,所述标准症状阴阳性识别模型是在预训练bert的基础上基于步骤5.2)处理后的带有阴阳性标注信息的医疗文本数据训练得到。
[0076]
所述步骤7)具体包括以下步骤:对于每个标准症状:
[0077]
7.1)若步骤6)中判断标准症状是阳性的概率大于或等于所设定的阈值,则判断当前标准症状为患者当前所患有;
[0078]
7.2)若步骤6)中判断标准症状是阳性的概率小于设定的阈值:则统计当前标准症状对应的抽取症状在步骤4)中被症状阴阳性识别模型预测为阳性的个数,若被预测为阳性的个数超过或等于所有预测次数的中位数,则判断当前标准症状为患者当前所患有,否则判断当前标准症状非患者当前所患有。
[0079]
本发明的有益效果:
[0080]
1)本发明与通常的多轮问诊的标准症状抽取方法相比,增加症状阴阳性识别任务,防止阴性症状对标准症状抽取的结果造成影响,加强了抽取结果的可靠性。同时,针对多轮问诊这一特殊场景下的症状阴阳性识别,根据症状和标准症状分别构建模型进行症状阴阳性识别,集成局部和全局信息预测最终的阴阳性结果,增强了识别准确率。
[0081]
2)本发明基于预训练深度语言学习模型将标准化任务建模成文本相似度任务,通过将待标准症状与预置的医学标准症状术语库中的标准症状进行相似对比,从而获取症状所对应的标准化术语名,有效地减少了标准化任务对于人工标注的依赖,提高了标准化的覆盖率和泛化性。
附图说明
[0082]
图1为本发明的流程图;
[0083]
图2为本发明提供的医疗信息抽取模型的基本结构示意图;
[0084]
图3为本发明提供的症状标准化模型的基本结构示意图;
[0085]
图4为本发明提供的症状阴阳性识别模型的基本结构示意图;
[0086]
图5为本发明提供的标准症状阴阳性识别模型的基本结构示意图。
具体实施方式
[0087]
下面结合附图及具体实施例对本发明作进一步详细说明。
[0088]
如图1所示,本发明是一种基于多轮问诊的标准症状抽取方法,包括如下步骤:
[0089]
步骤1):获取待抽取标准症状的在线多轮问诊文本,并对所述问诊文本数据进行数据清洗,得到初始文本;
[0090]
其中,数据清洗包括但不限于:统一化大小写、去除停用词、去除特殊符号、去除冗余数据;
[0091]
步骤2):基于如图2所示的预先建立的基于bert模型的医疗信息抽取模型对步骤1)所述的初始文本中的每段问诊文本进行症状信息抽取,获取文本中提及的所有症状,具体包括以下步骤:
[0092]
2.1)将输入组织成如图2所示的bert形式;
[0093]
其中token的输入为:[cls]问诊文本[sep];
[0094]
如:问诊文本“细菌性感染,需要用抗生素类药物”被组织为“[cls]细菌性感染,需要用抗生素类药物[sep]”;
[0095]
segment的输入为:问诊文本对应编码为1;
[0096]
position的输入为:将问诊文本中的每个字符按阿拉伯数字顺序进行位置编码,起始编码为0;如:输入“[cls]细菌性感染,需要用抗生素类药物[sep]”,则“[cls]”的位置编码为0,“细”为0,“菌”的位置编码为1,“[sep]”的位置编码为0;
[0097]
2.2)采用bert模型对输入文本进行文本语义编码,获取输入各字符对应的融合全文语义信息后的语义特征向量;
[0098]
2.3)将步骤2.2)中获取的语义特征向量乘以分类参数矩阵,再加上一个偏置参数,每个字符生成与预设的字符类型标签数量相等维度的分类向量;
[0099]
2.4)通过softmax函数将步骤2.3)中生成的分类向量转化为概率输出;
[0100]
2.5)每个字符选取概率最大的字符类型标签作为预测结果,将问诊文本中实体类型标签同类的的连续字符进行组合获得医疗实体和其对应的实体类型标签。
[0101]
如:“细菌性感染,需要用抗生素类药物”的预测标签为“b-symptom i-symptom i-symptom i-symptom i-symptom o o o o b-drug_category i-drug_category i-drug_category o o o”;
[0102]
其中“b-symptom”表示该字符是某一实体症状的起始,“i-symptom”表示该字符是构成某一实体症状的字符但并非起始,“b-drug_category”表示该字符是某一实体药品类别的起始,“i-drug_category”表示该字符是构成某一实体药品类别的字符但并非起始,“o”表示该位置的字符不参与构成实体;
[0103]
2.6)对初始文本中每段问诊文本采用步骤2.1)~2.5)的操作,获取每段问诊文本的医疗实体和其对应的实体类型标签;
[0104]
2.7)过滤每段问诊文本中实体类型标签不为症状的医疗实体,获取每段问诊文本中包含的所有症状;
[0105]
如:“细菌性感染,需要用抗生素类药物”抽取实体并过滤后的结果为“细菌性感染”;
[0106]
步骤3)基于如图3所示的预先建立的基于bert模型的症状标准化模型对每段问诊文本所获取的每个症状进行标准化,获取每个症状对应的标准症状,具体包括以下步骤:
[0107]
3.1)获取预置的医学标准症状术语库;
[0108]
其中,医学标准症状术语库包括但不限于:icd-10、医学知识图谱、标准化医疗术语集等;
[0109]
3.2)将每个症状与医学标准症状术语库中的每个标准症状术语输入组织成如图3所示的bert形式;
[0110]
其中token的输入为:[cls]抽取的症状[sep]医学标准症状术语库中的标准症状[sep];
[0111]
抽取的症状为步骤2)获得的症状
[0112]
如:“[cls]细菌性感染[sep]细菌感染[sep]”和“[cls]细菌性感染[sep]咳嗽[sep]”;
[0113]
segment的输入为:抽取的症状对应编码为0,医学标准症状术语库中的标准症状对应编码为1,符号[cls]、第一个[sep]对应编码为0,第二个[sep]对应的编码为1;
[0114]
position的输入为:将抽取的症状和医学标准症状术语库中的标准症状分别按阿拉伯数字顺序进行位置编码,每个字符的起始编码为0;
[0115]
如:对“[cls]细菌性感染[sep]细菌感染[sep]”的位置编码中“[cls]”和“[sep]”为0,“细菌性感染”分别为“0 1 2 3 4”,“细菌感染”分别为“0 1 2 3”;
[0116]
3.3)bert对输入文本进行文本语义编码,获取输入各字符对应的融合全文语义信息后的向量表示;
[0117]
3.4)将步骤3.3)中获取[cls]对应的语义特征向量输入单层全连接层,并通过采用sigmoid函数激活后得到抽取的症状和医学标准症状术语库中的标准症状之间的相似度,相似度位于0-1之间;
[0118]
3.5)对每个抽取的症状和医学标准症状术语库中的每个标准症状进行上述操作,获取两者之间的语义相似度;
[0119]
3.6)取与所述症状语义相似度最高的医学标准症状术语作为标准化的结果,即得每个抽取的症状对应的标准症状;
[0120]
如:“细菌性感染”与“细菌感染”相似度最高,则“细菌性感染”标准化结果为“细菌感染”。
[0121]
步骤4)将步骤2)中所获取的每个症状和其所在文本输入至如图4所示的预先建立的基于bert模型的症状阴阳性识别模型,判断该症状是否为患者当前所患有,具体包括以下步骤:
[0122]
4.1)将问诊文本输入者信息融入症状所在的问诊文本:若文本的输入者为患者,则在问诊文本前拼接“患者:”;若文本的输入者为医生,则在问诊文本前拼接“医生:”;
[0123]
如:若“细菌性感染,需要用抗生素类药物”是医生输入的文字,则其应被处理成“医生:细菌性感染,需要用抗生素类药物”,否则应被处理成“患者:细菌性感染,需要用抗生素类药物”;
[0124]
4.2)将输入组织成如图4所示的bert形式;
[0125]
其中token的输入为:[cls]症状[sep]症状所在的问诊文本[sep];
[0126]
如:问诊文本“医生:细菌性感染,需要用抗生素类药物”被组织为“[cls]细菌性感染[sep]医生:细菌性感染,需要用抗生素类药物[sep]”;
[0127]
segment的输入为:症状对应编码为0,症状所在的问诊文本对应编码为1;
[0128]
position的输入为:症状和症状所在的问诊文本中的每个字符分别按阿拉伯数字顺序进行位置编码,每个字符的起始编码为0;
[0129]
4.3)bert对输入文本进行文本语义编码,获取输入各字符对应的融合全文语义信息后的向量表示;
[0130]
4.4)将步骤4.3)中获取[cls]对应的语义特征向量输入单层全连接层,并通过采用sigmoid函数激活后得到通过语义判断症状为阳性的概率;
[0131]
步骤5)对于步骤2)中的所有症状,将属于同一个标准症状的症状所在的问诊文本以分号作为分隔符拼接成新文本,作为该标准症状的上下文信息,具体包括以下步骤:
[0132]
5.1)将文本输入者信息融入症状所在的问诊文本,获得融入文本输入者信息的问诊文本:若文本的输入者为患者,则在文本前拼接“患者:”;若文本的输入者为医生,则在文本前拼接“医生:”;
[0133]
5.2)将属于同一个标准症状的症状所在的融入文本输入者信息的问诊文本以分号作为分隔符拼接成新文本作为该标准症状的上下文信息,记为标准症状所在的拼接后的问诊文本;
[0134]
如:“患者:她前面查血是细菌导致的感染”中的“细菌导致的感染”和“医生:细菌性感染,需要用抗生素类药物”中的“细菌性感染”都可被标准化为“细菌感染”,则可将文本组织为“患者:她前面查血是细菌导致的感染;医生:细菌性感染,需要用抗生素类药物”;
[0135]
步骤6)根据步骤5)中所获取的标准症状所在的拼接后的问诊文本和该文本所对应的标准症状采用预先建立的标准症状阴阳性识别模型进行识别,判断该标准症状是否为患者当前所患有,具体包括以下步骤:
[0136]
6.1)将输入组织成如图5所示的bert形式,并加入文本输入者信息type;
[0137]
其中token的输入为:[cls]标准症状[sep]标准症状所在的问诊文本[sep];
[0138]
如图5所示:步骤5.2)中的标准症状和标准症状所在的问诊文本应被组织为“[cls]细菌感染[sep]患者:她前面查血是细菌导致的感染;医生:细菌性感染,需要用抗生素类药物[sep]”[0139]
segment的输入为:标准症状对应编码为0,标准症状所在的问诊文本对应编码为1;
[0140]
position的输入为:标准症状中的字符按阿拉伯数字顺序进行位置编码,起始编码为0;标准症状所在的拼接后的问诊文本中的所有字符以未拼接前文本为编码单位,每个编码单位内以0作为起始编码按阿拉伯数字顺序进行位置编码;
[0141]
如:“[cls]细菌感染[sep]患者:她前面查血是细菌导致的感染;医生:细菌性感染,需要用抗生素类药物[sep]”的位置编码中,“细菌感染”为“0 1 2 3”,“患”为0,“医”为
0,[cls]和[sep]皆为0;
[0142]
type的输入为:标准症状对应编码为0,标准症状所在的拼接后的问诊文本中输入者为医生的文本对应编码为1,输入者为患者的文本对应编码为2;
[0143]
如:“[cls]细菌感染[sep]患者:她前面查血是细菌导致的感染;医生:细菌性感染,需要用抗生素类药物[sep]”的type编码中,“细菌感染”皆编码为0,“患者:她前面查血是细菌导致的感染;”皆编码为2,“医生:细菌性感染,需要用抗生素类药物”皆编码为1,[cls]和[sep]皆为0;
[0144]
6.2)bert对输入文本进行文本语义编码,获取输入各字符对应的融合全文语义信息后的向量表示;
[0145]
6.3)type的输入通过type嵌入层映射到type向量;
[0146]
其中type嵌入层为可训练的参数矩阵,可通过模型根据损失函数自学习得到;
[0147]
6.4)将6.2)中获取的语义特征向量与type向量进行拼接,拼接后的向量通过一个激活函数为relu函数的全连接层获取融入type信息的语义特征向量表示;
[0148]
6.5)获取[cls]对应的融入type信息的语义特征向量输入全连接层,并通过采用sigmoid函数激活后得到该标准症状为阳性的概率;
[0149]
步骤7)综合步骤4)和步骤6)所获取的症状信息,输出当前问诊患者所患有的标准症状,具体包括以下步骤:
[0150]
7.1)若步骤6)中标准症状阴阳性识别模型判断该标准症状是阳性的概率大于或等于所设定的阈值,则判断该标准症状为患者当前所患有;
[0151]
7.2)若步骤6)中标准症状阴阳性识别模型判断该标准症状是阳性的概率小于所设定的阈值,则统计步骤4)中属于该标准症状的抽取症状被症状阴阳性识别模型预测为阳性的个数。若被预测为阳性个数超过或等于中位数,则判断该标准症状为患者当前所患有,否则判断该标准症状非患者当前所患有。
- 该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。
- 技术研发人员:王翔;宋震亚;王贵宣;谢钟乐;夏彬彬
- 技术所有人:杭州祺鲸科技有限公司
- 我是此专利的发明人
- 该领域下的技术专家
- 如您需求助技术专家,请点此查看客服电话进行咨询。
- 1、司老师:1.制浆造纸 2.植物资源精细化工与化学 3.生物质精炼 4.天然产物化学
- 2、薛老师:1.CRISPR-Cas系统 2.基因编辑 3.基因修复 4.天然产物合成 5.单分子技术开发与应用
- 3、戴老师:1.天然药物(中药)合成生物学研究 2.酵母生物学与工程化研究
- 4、孟老师:1. 基于糖类的抗肿瘤药物的合成和活性评价及糖类疫苗的研制 2.功能糖类的化学酶法合成及构效关系研究 3.多糖及仿生材料功能的开发及应用
- 5、满老师:1.天然产品的提取分离与活性研究 2.天然产物活性与安全性评价 3.中药组方配伍机制研究
- 如您是高校老师,可以点此联系我们加入专家库。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
精彩留言,会给你点赞!
专利分类正在加载中....