免疫相关疾病分子分型和亚型分类器的分类方法、系统
1.本发明涉及精准医疗技术领域,具体地,涉及一种基于人工智能机器学习的免疫相关疾病分子分型和亚型分类器的分类方法、系统。
背景技术:
2.免疫相关疾病(immune related diseases)是指机体免疫调节失去平衡而引起的疾病。针对免疫相关疾病的治疗方法众多,尤其是单克隆抗体等生物制剂的使用日益广泛。然而临床可见不同免疫相关疾病的患者治疗预后情况不甚相同,这反映同种疾病不同病人的免疫状态存在广泛的异质性,难以根据临床表现来区分,亟需在分子层面对其免疫表征进行精准分型,以利临床预后和治疗。
3.以典型的免疫相关疾病溃疡性结肠炎(ulcerative colitis,uc)为例,溃疡性结肠炎以直肠到近端结肠的慢性炎症为疾病特征,给全球医疗带来了巨大负担。uc治疗药物包括5-氨基水杨酸类药物(5aminosalicylic acid,5-asa)、糖皮质激素、硫嘌呤、抗tnf药物、抗整合素和janus激酶抑制剂等。目前临床实践中,轻症病人以5-asa治疗为主,中-重度病人缓解治疗常以糖皮质激素和抗tnf治疗为主,但药物抵抗、药物不良反应、以及药物的昂贵价格,均制约患者预后。从治病机制来看,肠道稳态的破坏、肠道屏障的功能障碍和炎症反应,是uc患者的病理特征。uc肠道上皮中存在炎症负调节因子和促炎因子的平衡被破坏,中性粒细胞、淋巴细胞的激活和多种细胞因子参与了uc肠道炎症中,如细胞因子白细胞介素9(il-9)、il-13、il-23和il-36等。由此可知,肠道免疫稳态破坏是uc发病的本质,提示部分uc患者用药效果不良与病灶局部免疫浸润的异质性有关。
4.因缺乏uc分子分型,临床用药主要依据uc病理严重程度,专利文献cn110993099a公开了一种基于深度学习的溃疡性结肠炎严重程度评估方法及系统,利用溃疡性结肠炎严重程度评估模型输出mayo内镜下评分、血管分型、自发出血和糜烂溃疡特征的评分预测结果,再将血管分型、自发出血和糜烂溃疡特征的评分预测结果累加,得到溃疡性结肠炎内镜下活动指数评分。现有技术根据严重程度的评估结果,采取单用或联用方案,如激素和免疫生物制剂常被用于中-重度患者的缓解治疗,前者作用广谱但副反应大,而后者往往针对某一免疫靶点但作用局限且价格昂贵,故而造成精准性差且经济负担重。
5.除了溃疡性结肠炎以外,其他诸多免疫相关疾病都存在上述的临床问题,例如克罗恩病(crohn’s disease,cd)、系统性红斑狼疮、类风湿关节炎等。这类疾病的治疗有一个共同点,都需要用免疫抑制剂来抑制针对自身机体的免疫反应。最常用的是肾上腺皮质激素类制剂,如:强的松、氢化可的松、地塞米松等,简称“激素”。所有免疫抑制剂有个主要的共同的不良作用,它们会不同程度地影响机体的抗感染、抗肿瘤免疫功能。
6.因此,免疫相关疾病分子分型对于认识疾病的异质性,实现个性化治疗和避免过度医疗有极大意义。但是从现有报道来看,少有研究对免疫相关疾病进行精准且高质量的分子分型。本发明将以溃疡性结肠炎和克罗恩病两个实例来说明免疫相关疾病分子分型及亚型分类器的分类方法和分类系统。
技术实现要素:
7.针对现有技术中的缺陷,本发明的目的是提供一种免疫相关疾病分子分型和亚型分类器的分类方法、分类系统。
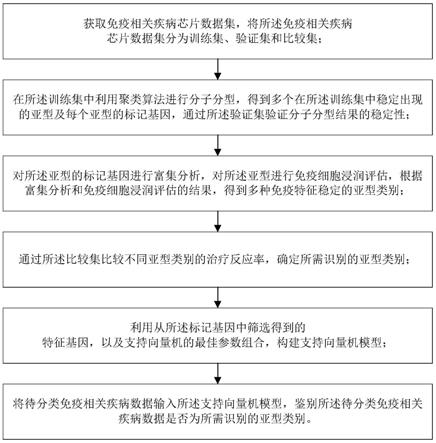
8.根据本发明提供的一种免疫相关疾病分子分型和亚型分类器的分类方法,包括:
9.数据获取步骤:获取免疫相关疾病芯片数据集,将所述免疫相关疾病芯片数据集分为训练集、验证集和比较集;
10.分子分型步骤:在所述训练集中利用聚类算法进行分子分型,得到多个在所述训练集中稳定出现的亚型及每个亚型的标记基因,通过所述验证集验证分子分型结果的稳定性;
11.分析评估步骤:对所述亚型的标记基因进行富集分析,对所述亚型进行免疫细胞浸润评估,根据富集分析和免疫细胞浸润评估的结果,得到多种免疫特征稳定的亚型类别;
12.比较步骤:通过所述比较集比较不同亚型类别的治疗反应率,确定所需识别的亚型类别;
13.分类器构建步骤:利用从所有所述标记基因中筛选得到的特征基因,以及支持向量机的最佳参数组合,构建支持向量机模型;
14.分类步骤:将待分类免疫相关疾病数据输入所述支持向量机模型,鉴别所述待分类免疫相关疾病数据是否为所需识别的亚型类别。
15.优选地,所述免疫相关疾病芯片数据集从geo数据库获取,所述免疫相关疾病芯片数据集包括溃疡性结肠炎芯片数据集或克罗恩病芯片数据集;
16.溃疡性结肠炎芯片数据集对应的所述训练集包括gse87466、gse107499和gse75214,所述验证集包括gse83687和gse126124,所述比较集包括gse114527、gse73661和gse16879;
17.所述克罗恩病芯片数据集对应的所述训练集包括gse112366、gse75214、gse179285和gse100833,所述验证集包括gse16879,所述比较集包括gse112366。
18.优选地,所述聚类算法包括crossicc算法,所述富集分析采用clusterprofiler包,所述免疫细胞浸润评估采用cibersort和单样本富集分析ssgsea;
19.多种亚型类别包括:免疫激活型和免疫稳态型;或者,固有免疫激活型、全免疫激活型和免疫稳态样型;或者,免疫稳态样型、固有免疫激活型和中间型;或者,免疫稳态型和免疫稳态型以外的其他类别。
20.优选地,筛选得到特征基因的方式包括:
21.对所有亚型的标记基因,先通过boruta包中的随机森林方法,设定最大运行次数、树的数目后,将筛选后留下的标记基因输入10折交叉验证的lasso回归中,留下参数不为0的标记基因作为所述特征基因。
22.优选地,还包括对构建的支持向量机模型在所述训练集和所述验证集中进行预测和评价,利用混淆矩阵评价分类的表现,其中:
23.准确度=分类正确的样本/总样本;
24.灵敏度=被正确分类的阳性样本数/总阳性样本数;
25.特异度=被正确分类的阴性样本数/总阴性样本数;
26.假阳性率=被判断为阳性的阴性样本/总阴性样本数;
27.假阴性率=被判断为阴性的阳性样本/总阳性样本数。
28.优选地,根据特征基因选择gamma值和cost值得到所述最佳参数组合。
29.根据本发明提供的一种免疫相关疾病分子分型和亚型分类器的分类系统,包括:
30.数据获取模块:获取免疫相关疾病芯片数据集,将所述免疫相关疾病芯片数据集分为训练集、验证集和比较集;
31.分子分型模块:在所述训练集中利用聚类算法进行分子分型,得到多个在所述训练集中稳定出现的亚型及每个亚型的标记基因,通过所述验证集验证分子分型结果的稳定性;
32.分析评估模块:对所述亚型的标记基因进行富集分析,对所述亚型进行免疫细胞浸润评估,根据富集分析和免疫细胞浸润评估的结果,得到多种免疫特征稳定的亚型类别;
33.比较模块:通过所述比较集比较不同亚型类别的治疗反应率,确定所需识别的亚型类别;
34.分类器构建模块:利用从所有所述标记基因中筛选得到的特征基因,以及支持向量机的最佳参数组合,构建支持向量机模型;
35.分类模块:将待分类免疫相关疾病数据输入所述支持向量机模型,鉴别所述待分类免疫相关疾病数据是否为所需识别的亚型类别。
36.优选地,所述免疫相关疾病芯片数据集从geo数据库获取,所述免疫相关疾病芯片数据集包括溃疡性结肠炎芯片数据集或克罗恩病芯片数据集;
37.溃疡性结肠炎芯片数据集对应的所述训练集包括gse87466、gse107499和gse75214,所述验证集包括gse83687和gse126124,所述比较集包括gse114527、gse73661和gse16879;
38.所述克罗恩病芯片数据集对应的所述训练集包括gse112366、gse75214、gse179285和gse100833,所述验证集包括gse16879,所述比较集包括gse112366。
39.优选地,所述聚类算法包括crossicc算法,所述富集分析采用clusterprofiler包,所述免疫细胞浸润评估采用cibersort和单样本富集分析ssgsea;
40.多种亚型类别包括:免疫激活型和免疫稳态型;或者,固有免疫激活型、全免疫激活型和免疫稳态样型;或者,免疫稳态样型、固有免疫激活型和中间型;或者,免疫稳态型和免疫稳态型以外的其他类别。
41.优选地,筛选得到特征基因的方式包括:
42.对所有亚型的标记基因,先通过boruta包中的随机森林方法,设定最大运行次数、树的数目后,将筛选后留下的标记基因输入10折交叉验证的lasso回归中,留下参数不为0的标记基因作为所述特征基因。
43.与现有技术相比,本发明具有如下的有益效果:
44.本发明的免疫相关疾病分子分型的通用流程是:在训练集用crossicc聚类,在验证集验证亚型,对亚型进行富集分析和免疫浸润评估以得到免疫亚型,在比较集比较各亚型的治疗反应率。该方案可适用于各免疫相关疾病的分子分型,并不局限于本发明所述的溃疡性结肠炎和克罗恩病两种疾病。
45.本发明通过大规模临床样本和机器学习的方法实现免疫相关疾病分子分型的分类,并在临床中准确鉴别出具有稳定特征的亚型,通过比较各亚型的治疗反应率,即可确定
不同治疗方式下治疗反应率最优、较优的亚型,以利于后续的精准药物选择、以及经济化治疗。
附图说明
46.通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
47.图1为本发明的流程图;
48.图2-图5为溃疡性结肠炎实例附图;
49.其中:
50.图2a、2b、2c为用三个训练集分别训练crossicc算法得到的分子亚型的示意图;
51.图2d、2e为用两个验证集分别验证crossicc算法得到的溃疡性结肠炎分子亚型的示意图;
52.图3a、3b、3c为对三种亚型的go富集分析结果的示意图;
53.图3d、3e、3f为对三种亚型的cibersort免疫浸润评估结果的示意图;
54.图3g为对亚型的ssgsea免疫浸润评估结果的示意图;
55.图4a为ihl-uc和其他类型的uc在疾病严重程度的差别的示意图;
56.图4b为亚型对糖皮质激素治疗反应的示意图;
57.图4c为不同亚型对英夫里昔单抗(ifx)或维多利住单抗(vdx)治疗反应的示意图;
58.图4d为gse73661中ifx/vdz治疗反应率和统计检验的示意图;
59.图4e为gse73661治疗靶点在亚型间比较的示意图;
60.图4f为不同亚型ifx治疗反应的示意图;
61.图4g为gse16879中ifx治疗反应率和统计检验的示意图;
62.图4h为gse16879治疗靶点在亚型间比较的示意图;
63.图5a为机器学习工作流程的示意图;
64.图5b为用混淆矩阵评价分类器的准确度的示意图;
65.图6-图9为克罗恩病示例附图;
66.其中:
67.图6a、6b、6c、6d为用四个训练集分别训练crossicc算法得到的克罗恩病分子亚型的示意图;
68.图6e为用验证集验证crossicc算法得到的分子亚型的示意图;
69.图7a、7b为对前两种主要亚型的go富集分析结果的示意图;
70.图7c、7d、7e为对三种亚型的cibersort免疫浸润评估结果的示意图;
71.图7f为对亚型的ssgsea免疫浸润评估结果的示意图;
72.图8a不同亚型克罗恩病对乌司奴单抗治疗反应的示意图;
73.图8b为gse112366中乌司奴单抗治疗反应率和统计检验的示意图;
74.图9为用混淆矩阵评价分类器的准确度的示意图。
具体实施方式
75.下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术
人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
76.如图1所示,本发明提供一种免疫相关疾病分子分型和亚型分类器的分类方法,包括:
77.数据获取步骤:获取免疫相关疾病芯片数据集,将所述免疫相关疾病芯片数据集分为训练集、验证集和比较集。
78.分子分型步骤:在所述训练集中利用聚类算法进行分子分型,得到多个在所述训练集中稳定出现的亚型及每个亚型的标记基因,通过所述验证集验证分子分型结果的稳定性。
79.分析评估步骤:对所述亚型的标记基因进行富集分析,对所述亚型进行免疫细胞浸润评估,根据富集分析和免疫细胞浸润评估的结果,得到多种免疫特征稳定的亚型类别。
80.比较步骤:通过所述比较集比较不同亚型类别的治疗反应率,确定所需识别的亚型类别。
81.分类器构建步骤:利用从所有所述标记基因中筛选得到的特征基因,以及支持向量机的最佳参数组合,构建支持向量机模型。
82.分类步骤:将待分类免疫相关疾病数据输入所述支持向量机模型,鉴别所述待分类免疫相关疾病数据是否为所需识别的亚型类别。
83.实施例1,溃疡性结肠炎(ulcerative colitis,uc)。
84.本实施例提供的一种uc分子分型和亚型分类器的分类方法,包括:
85.数据获取步骤:获取uc芯片数据集,将uc芯片数据集分为训练集、验证集和比较集。在本发明中,从geo数据库获取uc芯片数据集,gse87466(n=87)、gse107499(n=47)和gse75214(n=74)被用作训练集,gse83687(n=28)和gse126124(n=18)被用作分型验证集,gse114527(n=15)、gse73661(n=64)和gse16879(n=24)被用于比较治疗反应率。仅来自结肠的组织被纳入,仅活动性uc,受累的黏膜组织被纳入,另留置正常样本作对照组。总计208例黏膜组织被纳入训练集。数据都经过log2转化。治疗靶点通路基因集从gsea-msigdb(http://www.gsea-msigdb.org/gsea/msigdb/)下载。
86.分子分型步骤:在所述训练集中利用聚类算法进行分子分型,得到多个在训练集中稳定出现的亚型及每个亚型的标记基因,通过验证集验证分型训练结果的稳定性。本发明利用crossicc算法,利用训练集gse87466、gse107499和gse75214训练得到亚型及每个亚型的标记基因。将分型结果在验证集gse83687、gse126124上进行预测,观察分型结果是否稳定,如果不稳定则需对训练集重新进行数据集选择及质量控制。
87.分析评估步骤:对亚型的标记基因进行富集分析,对亚型进行免疫细胞浸润评估,根据富集分析和免疫细胞浸润评估的结果,将得到的亚型分为多种不同亚型类别。本发明利用clusterprofiler包对各亚型的标记基因进行富集分析,利用cibersort和单样本富集分析(ssgsea)对各亚型进行免疫细胞浸润评估。
88.比较步骤:通过比较集比较不同亚型类别的治疗反应率。gse114527、gse73661和gse16879中包括激素治疗、生物制剂治疗的反应数据被下载得到,仅使用药物前的黏膜表达谱数据被用于亚型鉴别。如不同亚型类别具有不同的药物治疗效果,则可说明本分子分
型的临床价值,并且提示建立可供临床使用的分类器的必要性。
89.分类器构建步骤:利用从所有标记基因中筛选得到特征基因,以及支持向量机的最佳参数组合,构建支持向量机模型。根据crossicc的结果,把样本分为二分类:免疫稳态样型与免疫稳态样型以外的其他亚型。基于所有亚型的标记基因,先通过boruta包中的随机森林方法,设定最大运行次数为100,树的数目为500,将筛选后的留下的特征输入10折交叉验证的lasso回归中。留下参数不为0的基因作为最终特征基因。支持向量机方法被用于亚型判断。每次执行支持向量机前,先将每个样本内的特征基因在基因之间进行标准化(scale),以避免过大标准差的特征基因对支持向量的影响。生成支持向量机模型后,在训练集和两个外部验证集中进行预测和评价。利用混淆矩阵评价分类的表现。其中:
90.准确度=分类正确的样本/总样本;
91.灵敏度=被正确分类的阳性样本数/总阳性样本数;
92.特异度=被正确分类的阴性样本数/总阴性样本数;
93.假阳性率=被判断为阳性的阴性样本/总阴性样本数;
94.假阴性率=被判断为阴性的阳性样本/总阳性样本数。
95.统计分析步骤:wilcoxon检验用于两组连续变量均值比较。kruskal-wallis检验用于多组连续型变量均值比较,分类变量使用卡方检验。所有的统计分析在r(4.0.3版本)中完成。
96.分类步骤:将待分类uc数据输入支持向量机模型,鉴别待分类uc数据是否为免疫稳态样型。
97.实验结果
98.(一)crossicc识别出三个稳定的uc分子亚型。
99.crossicc算法在gse87466、gse107499、gse75214三个数据集中都识别出了一系列亚型,其中第一簇cluster 1、第二簇cluster 2、第三簇cluster 3稳定出现于各数据集中(图2a-c)。每个亚型的标记基因均被获得。为了确认分型的稳定性,两个外部验证集,gse83687、gse126124被用于亚型验证,发现根据标记基因,在这两个数据集中也可以得到cluster 1、cluster 2、cluster 3亚型(图2d-e)。
100.(二)对亚型的富集分析和免疫浸润
101.对各亚型的标记基因进行go富集分析,发现cluster 1的标记基因富集于中性粒细胞活化的通路,cluster 2的基因富集于多种免疫活化的通路,但cluster 3的基因富集于代谢相关的通路(图3a-c)。将三个数据集去除批次效应合并成一个数据集,cibersort免疫浸润显示,cluster 1的中性粒细胞和肥大细胞比例较正常明显增多,cluster 2中,免疫细胞浸润比例与正常差异更显著,表现出了淋巴细胞如t细胞、b细胞的活化增强。但cluster 3中的免疫浸润和正常黏膜较为相似(图3d-f)。ssgsea评估免疫浸润显示免疫细胞在第三型中显示不高的免疫细胞丰度(图3g)。据此,将cluster 1命名为固有免疫激活型(innate immune activation,iia),将cluster 2命名为全免疫激活型(whole immune activation,wia),cluster 3命名为免疫稳态样型(immune homeostasis like,ihl)。
102.(三)亚型的严重程度和治疗反应性比较
103.从临床资料比较免疫稳态样型uc(ihl-uc)和其他亚型的疾病严重程度(病变extensive或limited),发现两组之间并无统计学差异(卡方检验p=0.3774)(图4a),说明
亚型在仅靠临床表现上难以区分。gse114527中比较亚型激素治疗反应性,发现各组无差异(图4b)。gse73661中比较亚型英夫里昔单抗(infliximab,ifx)或维多利珠单抗(vedolizumab,vdz)治疗反应性,发现wia型疗效最差(90%在初治无反应),ihl型治疗反应率最佳(卡方检验p=0.044)(图4c,4d)。gse16879中比较ifx治疗反应性,发现wia型疗效最差(100%无反应),ihl型治疗反应率最佳(卡方检验p=0.024)(图4f,4g)。ssgsea评估经典治疗靶点(包括白三烯、前列腺素、血栓素、血小板激活通路等)和新型治疗靶点(tnf,整合素、janus激酶通路等)可见,wia型各类治疗靶点丰度均较大,不同治病通路存在代偿可能是生物制剂无反应的原因(图4e,4h)。
104.(四)基于机器学习的分类器开发
105.以上结果提示,临床中准确鉴别出ihl-uc可针对性对其使用生物制剂保证较高反应率,而对其他亚型应尽可能避免使用生物制剂,以最大程度避免医疗资源的浪费。鉴于总共有460个标记基因,需要筛选出更少的特征基因来建立适合临床使用的panel。根据学习流程(图5a),随机森林共保留了108个特征基因,10折交叉验证的lasso回归后留下16个特征基因。10折交叉验证确定了支持向量机最佳参数组合gamma值=0.1,cost值=1,支持向量机模型建立后,在训练集上进行预测,得到准确度97.5%。外部验证集gse83687上,得到准确度89.3%,外部验证集gse126124上,准确度94.4%。该模型对ihl-uc和其他亚型的uc具有较好的区分能力(图5b)。图5b左侧:混淆矩阵,右侧:灵敏度、特异度、假阳性率、假阴性率表。
106.ihl型虽在临床表现上与其它亚型相似,但其病灶局部免疫细胞浸润谱接近正常黏膜。通过对临床研究患者行上述分子分型,并结合预后分析发现,针对抗肿瘤坏死因子(tumor necrosis factor,tnf)或抗整合素等免疫生物制剂治疗,ihl型uc患者反应率近50%,而wia型uc患者反应率不足10%,提示鉴别uc亚型有助于临床药物精准选择。因此,我们通过随机森林、正则化和支持向量机的机器学习流程,建立了基于免疫相关基因表达谱的ihl型uc分类器,在训练集和验证集中分别取得了97.5%和89.3~94.4%的准确度,实现ihl型uc精准、快速鉴别,助力uc精准治疗。
107.值得说明的是,在本实施例的分析评估步骤中,根据实际的分析结果,将得到的亚型分为三种亚型类别:固有免疫激活型、全免疫激活型和免疫稳态样型,而在治疗反应性比较时,发现对免疫稳态样型使用生物制剂时的反应率较高,因此在后续的支持向量机构建时,只是识别出反应率较高免疫稳态样型即可,以便于后续针对性使用生物制剂。而在使用其他治疗方式的时候,也会有其他类别的亚型出现较高的反应率,即只要识别出某治疗方式下反应率较高的亚型类别,即可在后续治疗过程中达到根据识别结果进行针对性治疗的目的。
108.有鉴于此,本领域技术人员有理由想到:在分析评估步骤中,可以只是将亚型分为免疫稳态样型和其他亚型类别即可,无需进行过多的分类。也可以是将亚型分为多种类别之后,通过支持向量机识别出治疗反应率高于目标值的一种或多种类别。因此,也可以将亚型分为免疫激活型(将前述的固有免疫激活型、全免疫激活型进行合并)和免疫稳态型;或者,分为免疫稳态样型和其他不限数量的类别。而本发明对于所要识别的具体的亚型类别不做限定,本领域技术人员可以根据治疗方式和治疗反应率确定相应的亚型类别。
109.实施例2,克罗恩病(crohn's disease,cd)。
110.一种克罗恩病分子分型和亚型分类器的分类方法,包括:
111.数据获取步骤:获取cd芯片数据集,将cd芯片数据集分为训练集、验证集和比较集。在本发明中,从geo数据库获取cd芯片数据集,gse112366(n=110)、gse75214(n=51)、gse179285(n=33)和gse100833(n=50)被用作训练集,gse16879(n=18)被用作分型验证集,gse112366(n=66)被用于比较治疗反应率。仅来自回肠末端的组织被纳入,仅活动性cd,受累的黏膜组织被纳入,另留置正常样本作对照组。总计244例黏膜组织被纳入训练集。数据都经过log2转化。
112.分子分型步骤:在所述训练集中利用聚类算法进行分子分型,得到多个在训练集中稳定出现的亚型及每个亚型的标记基因,通过验证集验证分型训练结果的稳定性。本发明利用crossicc算法,利用训练集gse112366、gse75214、gse179285和gse100833训练得到亚型及每个亚型的标记基因。将分型结果在验证集gse16879上进行预测,观察分型结果是否稳定,如不稳定则对训练集重新进行数据集选择及质量控制。
113.分析评估步骤:对亚型的标记基因进行富集分析,对亚型进行免疫细胞浸润评估,根据富集分析和免疫细胞浸润评估的结果,将得到的多个亚型分为免疫稳态样型、固有免疫激活型和中间型。本发明利用clusterprofiler包对各亚型的标记基因进行富集分析,利用cibersort和单样本富集分析(ssgsea)对各亚型进行免疫细胞浸润评估。
114.比较步骤:通过比较集比较不同亚型的治疗反应率。gse112366乌司奴单抗(il-12/il-23抑制剂)生物制剂治疗的反应数据被下载得到,仅使用药物前的黏膜表达谱数据被用于亚型鉴别。如不同亚型具有不同的药物治疗效果,则可说明本分子分型的临床价值,并且提示建立可供临床使用的分类器的必要性。
115.分类器构建步骤:利用从所有标记基因中筛选得到特征基因,以及支持向量机的最佳参数组合,构建支持向量机模型。根据crossicc的结果,把样本分为二分类:免疫稳态样型与其他亚型。基于所有亚型的标记基因,先通过boruta包中的随机森林方法,设定最大运行次数为1000,树的数目为500,将筛选后的留下的特征输入10折交叉验证的lasso回归中。留下参数不为0的基因作为最终特征基因。支持向量机方法被用于亚型判断。每次执行支持向量机前,先将每个样本内的特征基因在基因之间进行标准化(scale),以避免过大标准差的特征基因对支持向量的影响。生成支持向量机模型后,在训练集和两个外部验证集中进行预测和评价。利用混淆矩阵评价分类的表现。其中:
116.准确度=分类正确的样本/总样本;
117.灵敏度=被正确分类的阳性样本数/总阳性样本数;
118.特异度=被正确分类的阴性样本数/总阴性样本数;
119.假阳性率=被判断为阳性的阴性样本/总阴性样本数;
120.假阴性率=被判断为阴性的阳性样本/总阳性样本数。
121.统计分析步骤:wilcoxon检验用于两组连续变量均值比较。kruskal-wallis检验用于多组连续型变量均值比较,分类变量使用卡方检验或fisher’s精确检验。所有的统计分析在r(4.0.3版本)中完成。
122.分类步骤:将待分类cd数据输入支持向量机模型,鉴别待分类cd数据是否为免疫稳态样型。
123.实验结果
124.(一)crossicc识别出三个稳定的cd分子亚型。
125.crossicc算法在gse112366、gse75214、gse179285和gse100833三个数据集中识别出了一系列亚型,其中第一簇cluster 1、第二簇cluster 2稳定出现于各数据集中(图6a-d)。每个亚型的标记基因均被获得。为了确认分型的稳定性,两个外部验证集,gse16879被用于亚型验证,发现根据标记基因,在这两个数据集中也可以得到cluster 1、cluster 2亚型,cluster 3也为较为重要的亚型(图2e)。
126.(二)对亚型的富集分析和免疫浸润
127.对各亚型的标记基因进行go富集分析,发现cluster 1的标记基因富集于代谢相关的通路,cluster 2的基因富集于髓系、中性粒细胞活化的通路(图7a-b)。将四个数据集去除批次效应合并成一个数据集,cibersort免疫浸润显示,cluster 1的未见明显的免疫细胞激活,cluster 2中,中性粒细胞和m1巨噬细胞明显活化,cluster 3的免疫浸润介于cluster 1-2之间(图7c-e)。ssgsea评估免疫浸润显示免疫细胞在第一型中显示不高的免疫细胞丰度(图7f)。据此,将cluster 1命名为免疫稳态样型(immune homeostasis like,ihl),将cluster 2命名为固有免疫激活型(innate immune activation,iia),cluster 3为中间型。
128.(三)亚型的严重程度和治疗反应性比较
129.gse16879中比较亚型乌司奴单抗治疗反应性,发现ihl型治疗反应率最佳(卡方检验p=0.044)(图8a,8b)。
130.(四)基于机器学习的分类器开发
131.以上结果提示,临床中准确鉴别出ihl-cd可针对性对其使用生物制剂保证较高反应率,而对其他亚型应尽可能避免使用生物制剂,以最大程度避免医疗资源的浪费。鉴于总共有273个标记基因,需要筛选出更少的特征基因来建立适合临床使用的panel。根据学习流程,随机森林共保留了130个特征基因,10折交叉验证的lasso回归后留下24个特征基因。10折交叉验证确定了支持向量机最佳参数组合gamma值=0.01,cost值=1,支持向量机模型建立后,在训练集上进行预测,得到准确度98.8%。外部验证集gse16879上,得到准确度88.9%。该模型对ihl-cd和其他亚型的cd具有较好的区分能力(图9)。图9左侧:混淆矩阵,右侧:灵敏度、特异度、假阳性率、假阴性率表。
132.ihl型cd虽在临床表现上与其它亚型相似,但其病灶局部免疫细胞浸润谱接近正常黏膜。通过对临床研究患者行上述分子分型,并结合预后分析发现,免疫生物制剂治疗中ihl型cd患者反应率近70%,而其他亚型cd患者反应率较低,提示鉴别cd亚型有助于临床药物精准选择。因此,我们通过随机森林、正则化和支持向量机的机器学习流程,建立了基于免疫相关基因表达谱的ihl型cd分类器,在训练集和验证集中分别取得了88.9%-98.8%的准确度,实现ihl型cd精准、快速鉴别,助力cd精准治疗。
133.值得说明的是,在本实施例的分析评估步骤中,根据实际的分析结果,将得到的亚型分为三种亚型类别:固有免疫激活型、中间型和免疫稳态样型,而在治疗反应性比较时,发现对免疫稳态样型使用生物制剂时的反应率较高,因此在后续的支持向量机构建时,只是识别出反应率较高免疫稳态样型即可,以便于后续针对性使用生物制剂。而在使用其他治疗方式的时候,也会有其他类别的亚型出现较高的反应率,即只要识别出某治疗方式下反应率较高的亚型类别,即可在后续治疗过程中达到根据识别结果进行针对性治疗的目
的。
134.有鉴于此,本领域技术人员有理由想到:在分析评估步骤中,可以只是将亚型分为免疫稳态样型和其他亚型类别即可,无需进行过多的分类。也可以是将亚型分为多种类别之后,通过支持向量机识别出治疗反应率高于目标值的一种或多种类别。因此,也可以将亚型分为免疫稳态样型和其他不限数量的类别。而本发明对于所要识别的具体的亚型类别不做限定,本领域技术人员可以根据治疗方式和治疗反应率确定相应的亚型类别。
135.上述两个本实施例分别以溃疡性结肠炎(uc)和克罗恩病(cd)为例进行说明,但本领域技术人员知道,本方案可以适用于其他领域的免疫相关疾病分子分型中,本发明对此不做限制。
136.根据本发明提供的一种免疫相关疾病分子分型和亚型分类器的分类系统,包括:
137.数据获取模块:获取免疫相关疾病芯片数据集,将所述免疫相关疾病芯片数据集分为训练集、验证集和比较集。
138.分子分型模块:在所述训练集中利用聚类算法进行分子分型,得到多个在所述训练集中稳定出现的亚型及每个亚型的标记基因,通过所述验证集验证分子分型结果的稳定性。
139.分析评估模块:对所述亚型的标记基因进行富集分析,对所述亚型进行免疫细胞浸润评估,根据富集分析和免疫细胞浸润评估的结果,得到多种免疫特征稳定的亚型类别;
140.比较模块:通过所述比较集比较不同亚型类别的治疗反应率,确定所需识别的亚型类别。
141.分类器构建模块:利用从所有所述标记基因中筛选得到的特征基因,以及支持向量机的最佳参数组合,构建支持向量机模型。
142.分类模块:将待分类免疫相关疾病数据输入所述支持向量机模型,鉴别所述待分类免疫相关疾病数据是否为所需识别的亚型类别。
143.本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及其各个装置、模块、单元以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置、模块、单元以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装置、模块、单元可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置、模块、单元也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置、模块、单元视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
144.以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本技术的实施例和实施例中的特征可以任意相互组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1