边缘计算网络中基于对比学习的皮肤病智能分类方法
1.本发明涉及物联网技术领域,具体的说是涉及一种边缘计算网络中基于对比学习的智能皮肤病分类方法。
背景技术:
2.皮肤病是人类最普遍的疾病之一,影响几乎所有群体中各个年龄段30%到70%的人。恶性皮肤病,如黑色素瘤,具有恶化速度快、死亡率高的特点。而早期诊断可使该病的生存率从14%提高到99%。由于此类疾病的发生往往伴随着皮肤颜色的变化,因此容易引起患者的注意和警觉,也带来了巨大的诊断需求。一些皮肤病如雀斑和黄褐斑是常见的,而其他一些皮肤病如黑素瘤和鲍文氏病的发病率相对较低。因此,这类罕见疾病的临床病例很少,所以不同类型的皮损往往分布不平衡。此外,皮肤病的病变外观具有类间方差,类内方差大的特点,这导致人工检查的误诊率高。研究表明,全科医生的诊断正确率为24%~70%,专业皮肤科医生的诊断正确率为77%~96%。因此在计算机辅助诊断(cad)的帮助下,可以显著提高诊断的准确性和效率。
3.随着cad技术的快速发展,由于深度学习方法在诊断精度和服务效率方面具有优势,将深度学习应用于皮肤病变诊断是一种日益发展的趋势。目前,现有的基于深度神经网络的医学图像分类诊断方案大致可以分为以下三类:
4.第一类方案采用单一cnn模型研究病变诊断问题。虽然该类别在一些皮肤病数据集上取得了显著的性能提升,但上述研究受到单一学习模型设计的特征挖掘和分类决策能力的限制。
5.为了克服第一类的不足,第二类方案结合多个cnn模型研究分类诊断问题。虽然这类方案提高了分类识别准确率,但数据集的类别不平衡和标注数据数量不足仍然是阻碍识别准确率从根本上提高的主要问题。
6.针对第二类存在的问题,第三类方案提出了高效的数据增强策略和方法,进一步提高了网络的分类和分割性能。针对训练数据集缺乏的问题,研究了生成对抗网络(gan)综合现有训练数据的方法。尽管这类方案为克服皮肤病诊断中训练样本不足的问题提供了一种更加先进的解决方案,但它大大增加了实现的难度,其中低质量的合成数据还会显著恶化网络性能。在以上方法中,并未考虑到使用大量的未标记数据来有效地提高网络的诊断性能。
技术实现要素:
7.为了解决上述问题,本发明提供了一种边缘计算网络中基于对比学习的皮肤病智能分类方法,该方法构建一种基于边缘计算的皮肤病智能诊断网络,为临近用户提供方便快捷的在线诊断服务;同时设计一种基于对比学习的双编码器网络,通过充分利用无标签样本来提高模型性能,克服训练样本缺乏的问题;随后,设计一个基于最大均值差异(mmd)的监督对比损失函数,它可以高效地学习样本中复杂的类内、类间差异。
8.为了达到上述目的,本发明是通过以下技术方案实现的:
9.本发明是一种边缘计算网络中基于对比学习的皮肤病智能分类方法,包括如下步骤:
10.步骤1:构建基于边缘计算的皮肤病智能诊断网络,该网络由用户、边缘节点和数据基站组成;
11.步骤2:构建基于对比学习的智能皮肤病诊断网络,该智能皮肤病诊断网络为由两个特征提取网络和一个分类器组成的双编码器网络,所述双编码器网络集成了自监督和监督式对比学习,以生成更多的分类判别特征,同时,可以在不同类别之间获得更均衡的分类精度,充分利用未标记样本;
12.步骤3:构建基于最大均值差异(mmd)的监督式对比损失函数,它将每一类数据集表示为特定概率分布的采样,并把不同类别之间的差异表示为这些分布的距离。
13.本发明的进一步改进在于:所述步骤2具体包括如下内容:
14.在边缘计算环境下,本发明设计了一个基于对比学习的智能皮肤病诊断网络。为了充分利用标签数据、无标签数据或两者兼有的数据形式,将传统的监督网络扩展为由两个特征提取网络和一个分类器组成的双编码器网络。
15.编码器和分类器的训练细节如下。去除resnet-50的全连接层和softmax输出层,并将其作为我们框架中的编码器。根据效用和训练方法的不同,将网络中的编码器定义为sup-encoder(supenc(
·
))和self-encoder(selfenc(
·
)),它们是用不同的数据集和损失函数分别进行训练。具体而言,将有标签数据集{x
l
,y
l
},和无标签数据集{xu}划分为两个训练集:监督训练集{x
l
,y
l
}和自监督训练集{x
l+u
}。
16.自监督对比训练(self-encoder):在训练阶段,对每幅图像进行多次增强和使用增强。输入图像经编码器编码为2048维表示向量,并归一化为单位球。使用sup-encoder作为一个实例。
17.wi=supenc(xi),
[0018][0019]
其中xi是第i个输入图像。自监督损失使用标准化后的特征进行计算,
[0020][0021]
其中p(i)表示第i个原始样本的增广样本。这种损失称为信息噪声对比估计(infonce)。
[0022]
在训练过程中,self-encoder学习从相同原始图像的不同增强中提取相似特征,以及从不同原始图像的不同增强中提取不同特征。
[0023]
监督对比学习(sup-encoder):在这种情况下,对训练集进行了增强操作,与自监督情况不同,在监督情况下,将归一化的特征向量按其标签进行分组,对于特征集中的每一组,将其定义为正分布p的样本,并将其他所有组合合并为负分布q,准确地说,对于每一批由n个样本组成,样本i的损失形式如下。
[0024]
[0025]
其中p(i)表示与样本i同组的样本集合,n(i)是与样本i不同组的样本集合。dist(
·
,
·
)是两个特征向量的距离函数。关于监督对比损失的更多细节将在第二小节中显示。在框架中,可以并行训练sup-encoder和self-encoder。
[0026]
分类器训练:在编码器训练后,使用标记数据集进行分类器训练。在框架中,标记数据被转发到两个编码器,输出特征向量被连接到医学图像的全局表示(4096维),然后,分类器通过交叉熵损失评价表征
[0027][0028]
其中是样本i的标签,是分类器的预测,在梯度传播过程中,编码器的参数被固定,梯度只传递给分类器本身。
[0029]
在实际应用中,使用数据基站中的标签数据和未标签数据训练编码器和分类器。在服务运行期间,边缘节点对请求图像进行编码并进行分类。然后,根据分类结果的确定性,将这些图像存储在数据基站的不同数据集中,为了提高服务效果和性能,边缘节点定期从数据基站下载新的训练数据,对诊断网络进行训练。
[0030]
本发明的有益效果:
[0031]
本发明提出了一种基于边缘计算网络的皮肤病诊断系统,为附近用户提供方便快捷的在线诊断服务;
[0032]
本发明设计了一种基于对比学习的双编码器网络,通过充分利用无标签样本来提高模型性能,克服训练样本不足的问题;
[0033]
本发明设计了一个基于最大均值差异(mmd)基于mmd的监督对比损失函数,有效地探索各种皮肤病的类内和类间差别。
[0034]
通过仿真结果表明,与现有的方法进行了比较,表明本文提出的方法是可行的,可以显著提高诊断的准确性,缓解无标记数据的失衡性能。
附图说明
[0035]
图1是本发明基于边缘计算的皮肤病智能诊断模型图。
[0036]
图2是本发明皮肤病变诊断的培训与实施程序图。
[0037]
图3为cl-isld无sup-encoder、cl-isld无self-encoder和(c)cl-isld的混淆矩阵三种混淆矩阵。
具体实施方式
[0038]
以下将以图式揭露本发明的实施方式,为明确说明起见,许多实务上的细节将在以下叙述中一并说明。然而,应了解到,这些实务上的细节不应用以限制本发明。也就是说,在本发明的部分实施方式中,这些实务上的细节是非必要的。
[0039]
本发明是一种边缘计算网络中基于对比学习的皮肤病智能分类方法,方法包括如下步骤:
[0040]
步骤1:构建基于边缘计算的皮肤病智能诊断网络,该网络由用户、边缘节点和数据基站组成。简单来说,用户从边缘节点获取服务,数据基站为边缘节点提供训练数据和数据存储,模型的三个组成部分如图1所示。
[0041]
用户:不同类型的用户获取皮肤病诊断服务的目的是不同的。具体来说,个人用户通过蜂窝网络或无线局域网(wlan)将手机拍摄的皮肤照片上传至边缘节点发送诊断请求;此外,专业用户通过专业计算机传输皮肤镜图像来获取辅助诊断信息,专业用户主要是全科医生或皮肤科医生。
[0042]
边缘节点:在我们的模型中,诊断网络部署在边缘节点上,边缘节点具有网络训练和诊断服务两个功能。对于网络训练,边缘节点从数据基础设施中获取初始训练样本,并在提供服务前执行训练操作。在服务时,在边缘端使用训练好的网络顺序处理用户的诊断请求。为了保证诊断服务的有效性,将识别结果按照置信度进行过滤,并将诊断输出响应给客户端。由于边缘节点完成了自动诊断,所有的诊断样本都被传送到数据基站。具有高度可信分类结果的样本存储在标记数据库中,而难分样本则存储在未标记数据库中。为了维护和提高服务性能,边缘节点定期从数据基站下载标签和未标签数据,对神经网络作提升训练。
[0043]
数据基站:我们设置数据基站来存储训练数据,它保存两种类型的数据集:无标签数据集和有标签数据集。一般来说,数据集中的数据来自两个主要的数据源。一是医疗机构的皮肤镜图像,另一个则是客户端上传用于诊断的数据。医疗机构的皮肤科医生则定期处理未标记数据库中难以识别的请求数据,并将这些样本添加到已标记数据库中。
[0044]
步骤2:在边缘计算环境下,本发明设计了一个基于对比学习的智能皮肤病诊断网络。为了充分利用标签数据、无标签数据或两者兼有的数据形式,本发明将传统的监督网络扩展为由两个特征提取网络和一个分类器组成的双编码器网络。在边缘计算环境下,设计了一个基于对比学习的智能皮肤病诊断网络。为了充分利用标签数据、无标签数据或两者兼有的数据形式,将传统的监督网络扩展为由两个特征提取网络和一个分类器组成的双编码器网络。
[0045]
编码器和分类器的训练细节如下。去除resnet-50的全连接层和softmax输出层,并将其作为框架中的编码器。根据效用和训练方法的不同,将网络中的编码器定义为sup-encoder(supenc(
·
))和self-encoder(selfenc(
·
)),它们是用不同的数据集和损失函数分别进行训练。具体而言,将有标签数据集{x
l
,y
l
},和无标签数据集{xu}划分为两个训练集:监督训练集{x
l
,y
l
}和自监督训练集{x
l+u
}。
[0046]
自监督对比训练(self-encoder):在训练阶段,对每幅图像进行多次增强和使用增强,输入图像经编码器编码为2048维表示向量,并归一化为单位球。
[0047]
使用sup-encoder作为一个实例
[0048]
wi=supenc(xi),
ꢀꢀꢀ
(1)
[0049][0050]
其中xi是第i个输入图像。自监督损失使用标准化后的特征进行计算,
[0051][0052]
其中p(i)表示第i个原始样本的增广样本。这种损失称为信息噪声对比估计(infonce)。
[0053]
在训练过程中,self-encoder学习从相同原始图像的不同增强中提取相似特征,
以及从不同原始图像的不同增强中提取不同特征。
[0054]
监督对比学习(sup-encoder):在这种情况下,对训练集进行了增强操作。与自监督情况不同,在监督情况下,将归一化的特征向量按其标签进行分组。对于特征集中的每一组,将其定义为正分布p的样本,并将其他所有组合合并为负分布q。准确地说,对于每一批由n个样本组成,样本i的损失形式如下。
[0055][0056]
其中p(i)表示与样本i同组的样本集合,n(i)是与样本i不同组的样本集合。dist(
·
,
·
)是两个特征向量的距离函数。关于监督对比损失的更多细节将在第二小节中显示。在我们的框架中,可以并行训练sup-encoder和self-encoder。
[0057]
分类器训练:在编码器训练后,使用标记数据集进行分类器训练。在框架中,标记数据被转发到两个编码器,输出特征向量被连接到医学图像的全局表示即4096维。然后,分类器通过交叉熵损失评价表征。
[0058][0059]
其中是样本i的标签,是分类器的预测。在梯度传播过程中,编码器的参数被固定,梯度只传递给分类器本身。
[0060]
在实际应用中,使用数据基站中的标签数据和未标签数据训练编码器和分类器。在服务运行期间,边缘节点对请求图像进行编码并进行分类。然后,根据分类结果的确定性,将这些图像存储在数据基站的不同数据集中。为了提高服务效果和性能,边缘节点定期从数据基站下载新的训练数据,对诊断网络进行训练。
[0061]
步骤3:构建基于最大均值差异(mmd)的监督式对比损失函数,它将每一类数据集表示为特定概率分布的采样,并把不同类别之间的差异表示为这些分布的距离。
[0062]
最常用的监督对比损失函数是(3)中infonce的修改,它鼓励编码器对来自同一类的所有条目呈现类似的表示。但是(3)中内积对复杂特征的学习能力是有限的,这些损失函数集中于每个样本的个体表示,而不是把每一类图像看作是一个整体的数据分布。
[0063]
提出一个更有效的对比损失函数来探索样本之间的类内和类间方差。具体地说,将每一类数据看作来自一个典型概率分布的样本,并使用积分概率度量(ipm)来度量不同分布的距离。通过ipm,p和q两个分布之间的距离可以表示为:
[0064]
δ(p,q)=sup
f∈fex~p
[f(x)]-e
z~q
[f(z)],
ꢀꢀꢀ
(6)
[0065]
其中函数f可以被改变为几个距离,如wasserstein,total variation和mmd。在本技术中设计了一种mmd的变体来代替(6)中函数f用于医学图像分析。
[0066]
mmd作为两种分布之间的有效距离度量,已广泛应用于深度学习领域,特别是迁移学习和神经网络。定义p和q两个分布的mmd距离的平方为:
[0067][0068]
在μ
p
和μq是核希尔伯特空间(rkhs)中p和q的平均嵌入,从概率的角度来看,式(7)可以写成
[0069]
[0070]
其中x和y是p和q的随机变量,f是一个将样本映射到rkhs的函数。
[0071]
在机器学习中,我们使用核函数将样本映射到无限维空间。因此,mmd距离可以表示为
[0072][0073]
其中xi和xj是p的两个随机样本,yi和yj是q的两个随机样本,k(
·
,
·
)是核函数,如高斯径向基函数(rbf),计算两个样本的相似性。
[0074]
在mmd对比损失中,分解mmd这三个不同部分,并抛弃第三项。距离方程(9)的松弛公式定义如下:
[0075]
mc(p,q)=e
p
[k(x,x
′
)]-2e
p,q
[k(x,y)],
ꢀꢀꢀ
(10)
[0076]
其中p是正分布,q是负分布。
[0077]
根据式(4)、(10),定义mmd对比损失函数如下。
[0078][0079]
其中系数λ和μ为控制两项尺度的超参数。通过最小化式(11),编码器学会减少类内差距,增加类间差距。
[0080]
在mmd中,主要使用rbf内核作为内核函数,rbf的扩展形式如下。
[0081][0082]
其中2范数项可展开为式(13),其中在单位球面上a
·
a、b
·
b等于1。
[0083][0084]
为简单起见,设η=σ2且x=a
·
b,则(12)式可表示为:
[0085][0086]
根据上式,可以很容易地得到输入特征向量的2范数梯度,如下所示
[0087][0088]
此外,在单位球面上,x的值以区间[-1,1]为界。相应地,梯度取范围:
[0089][0090]
式(16)显现了两个问题,第一个问题是负样本比正样本贡献的梯度信息更少。第二个问题是当各正样本在特征空间中非常接近时,其梯度仍旧保持最大值。这两个缺点会导致训练不稳定,并导致特征分散程度不够,容易产生过拟合。
[0091]
为解决这两个问题,重新定义了损耗函数公式和引入铰链损失函数。
[0092][0093]
如式(17)所示,gb(x)和fb(x)的梯度表示如下:
[0094]
[0095][0096]
其中参数ω和减轻了损失函数的收敛要求。
[0097]
利用式(18)和式(19)的控制机制,式(17)的梯度在训练期间动态变化。具体来说,随着训练的进行,过滤表现良好的样本,使其并不贡献梯度信息,这一特性有助于特征分散和复杂特征提取。另一方面,(18)和(19)中的铰链项可以有效地稳定训练。
[0098]
步骤4:在ham10000数据集上对所提出的cl-isld方案进行了训练和评估。该数据集包含七种互斥的类别:黑色素瘤(melanoma,mel)、黑素细胞痣(melanocytic nevus,nv)、基底细胞癌(basal cell carcinoma,bcc)、光化性角化病(actinic keratoses,akiec)、良性角化病(benign keratosis,bkl)、皮肤纤维瘤(dermatofibroma,df)和血管病变(vascular lesions,vasc)。为了评估方案的特征提取能力,本发明在不进行数据集预处理的情况下,对诊断网络进行1000epoch的训练。在自我监督对比训练中,本发明将损失函数(3)的参数τ设为0.07,使用无标记数据进行训练。对于监督对比训练损失(17),我们设置参数元组为(1,3,0.2,0.8)。
[0099]
本发明将cl-isld的结果与文献相比较,这些文件使用了相同的实验数据集ham10000,包括pnsnet for skin lesion classification(pnsn-slc),combination of resnet-50和gcforest for disease classification(rnf-dc),mobilenet based skin lesion classification(mn-slc)和bayesian densenet-169 based risk-aware diagnosis(bdn-rd)。此外,本发明将基于infonce的自监督对比学习的cl-isld即无sup-encoder的cl-isld的实验结果与基于mmd的监督对比学习的cl-isld即无self-encoder的cl-isld)的实验结果进行了比较。
[0100]
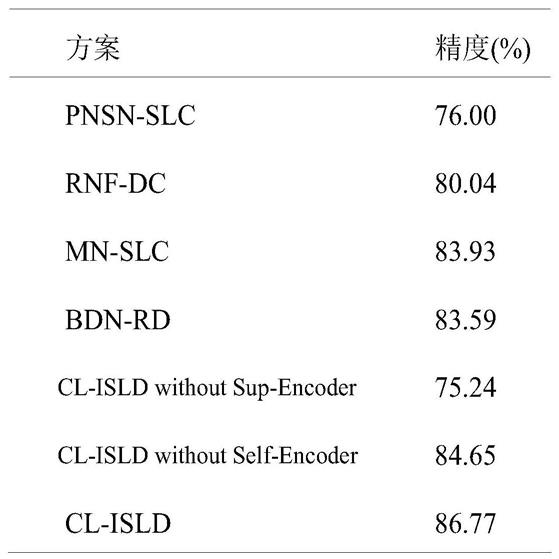
表1分类诊断结果
[0101]
[0102]
在ham10000上的分类诊断结果如表1所示,列出了所提出方案和对比文献的诊断准确率。在本表中,cl-isld法的准确率最高,为86.77%,其他方法的准确率为76.00%~83.59%。表1中pnsn-skc(76.00%)和cl-isld without sup-encoder(75.24%)低于其他方法。这说明在皮肤病诊断应用中,自监督方法与预训练微调方法相比,在特征提取方面存在局限性。另一方面,在无自监督编码器的情况下,cl-isld的诊断准确率为84.65%,而在有监督学习模型下,cl-isld的诊断准确率为86.77%,高于bdn-rd的83.59%。上述结果反映了我们设计的基于mmd的对比损失在复杂特征提取方面的优势,以及双编码器网络设计能够在此基础上进一步提高精度的特点。
[0103]
为了进一步评价在单独类别上的诊断精度,本发明分析了图3中不同方案的混淆矩阵。这些矩阵汇总结了ham10000中所有类的测试结果,矩阵的纵轴表示样本的真标签,横轴表示样本的预测标签,每个小数为预测标签占真标签的比例。
[0104]
图3(a)为没有sup-encoder的cl-isld混淆矩阵,mel、akiec、bkl和df类的正确分类比例均在60%以下,而vasc类的正确率为91%。图3(b)显示了混淆矩阵没有self-encoder的cl-isld。与不使用sup-encoder的cl-isld相比,该方法将mel类、akiec类、bkl类和df类的准确率分别提高到61%、61%、63%和57%。最高的等级(如vasc)的准确率高达100%。从这两幅图中可以看出,与公式(3)所示infonce损耗相比,提出的基于mmd的对比损耗(即式(17))更适合在皮肤病诊断应用中进行类内和类间对比特征挖掘。
[0105]
图3(c)给出了cl-isld的诊断结果,与上述两种方案相比,大部分病变类别的准确率都有提高,尤其是mel、bkl和df。而且,使用cl-isld后,各个类别的分类性能相对更加平衡。主要原因是类间对比信息和图像间对比信息的结合,增强了对复杂特征的辨别能力,尽管标注的数据不够充分和不平衡。在服务时间上,这一特性保证了cl-isld无论有无标记数据的增加,都能不断提高诊断准确性,也进一步减轻了人工标记的负担。
[0106]
以上所述仅为本发明的实施方式而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原理的内所作的任何修改、等同替换、改进等,均应包括在本发明的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1