用于生成用于确定分析物值的软件实现的模块的方法和系统、计算机程序产品以及用于确定分析物值的方法和系统与流程
用于生成用于确定分析物值的软件实现的模块的方法和系统、计算机程序产品以及用于确定分析物值的方法和系统
1.本公开涉及一种用于生成用于确定分析物值的软件实现的模块的方法和系统以及计算机程序产品。此外,本公开涉及用于确定分析物值的方法和系统。
背景技术:
2.为了预测患者的葡萄糖水平,提出了要在预测过程中应用的不同模型。一方面,提出了所谓的生理(葡萄糖预测)模型。此外,还应用了机器学习(葡萄糖预测)模型,其也可以称为数据驱动(葡萄糖预测)模型。
3.据发现,建立完全数据驱动的葡萄糖预测模型(其对例如胰岛素或碳水化合物摄入灵敏)是一项艰巨的任务,特别是在用于模型训练的数据确实来自真实世界的用户数据的情况下。这些数据集只会反映单个患者的非常狭窄的治疗部位(大多数情况下,大多数患者都会很好地应对他们的治疗,而边缘例子很少见)。因此,任何机器学习算法都难以概括出对特定患者的正常治疗部位之外的胰岛素或碳水化合物的反应。另一方面,惯常治疗部位之外的情况正是葡萄糖预测算法会对患者最有用的例子,该算法要么针对错误进行警告,要么帮助寻找对危急情况的最佳响应。一个示例为关于以下的建议:在临界低葡萄糖值的情况下患者应该摄入多少碳水化合物以再次达到正常葡萄糖浓度范围。
4.为了克服纯数据驱动模型的此类缺点,提出了一种混合方法,其中由生理(第一原理)模型对碳水化合物或胰岛素的摄入所引起的葡萄糖动力学进行建模。这可以通过设计并提供机器学习模型来确保对此类摄入的灵敏度,该机器学习模型捕获生理模型所未很好地捕获的对葡萄糖动力学的残差影响。然而,这种方法的缺点是必须实现和维护生产中两种类型的模型,这浪费时间和金钱。
5.文献contreras et al.(2017),personalized blood glucose prediction:ahybrid approach using grammatical evolution and physiological models,plos one 12(11)涉及一种混合方法,其包括针对胰岛素和语法演变的生理模型,通过使用基于克拉克误差网格的惩罚适应度函数来考虑与目标血糖的偏离所引起的临床损害。
6.oviedo et al.(2017),a review of personalized blood glucose prediction strategies for t1dm patients,international journal for numerical methods in biomedical engineering 33(6)描述了用于预测血糖(bg)浓度、风险和bg事件的模型。对模型进行分类,并提供与用于拟合和测试每个模型的实验设置相关的最相关数据以及输入信号和性能度量。
7.文献us 2019/0252079a1公开了使用机器学习来确定患者的生理状态并向患者提供有关管理糖尿病等生理状况的指导。
8.hidalgo et al.,glucose forecasting combining markov chain based enrichment of data,random grammatical evolution and bagging,applied soft computing,88,2019公开了一种用于生成用于确定葡萄糖值的软件实现的模块的方法。在生成软件实现的模块的过程中,应用了机器学习过程。没有使用生理模型。在机器学习过程
之前应用了丰富的数据。
技术实现要素:
9.本公开的一个目的是提供一种用于生成用于确定分析物值的软件实现的模块的方法、系统和计算机程序产品。此外,将提供一种用于确定分析物值的方法和系统。
10.为解决该问题,提供了一种根据独立权利要求1的一种用于生成用于确定分析物值的软件实现的模块的方法。此外,提供了一种根据独立权利要求11的用于生成用于确定分析物值的软件实现的模块的系统。另外,提供了一种根据权利要求12的计算机程序产品。此外,提供了一种根据权利要求13的用于确定分析物值的方法。另外,提供了一种根据权利要求15的用于确定分析物值的系统。在从属权利要求和整个说明书中公开了另外的实施例。
11.根据一个方面,提供了一种用于生成用于确定分析物值的软件实现的模块的方法。该方法包括:在一个或多个数据处理器的布置中,提供指示针对多个输入参数所测量的第一值的第一输入数据集,该输入参数包括第一输入参数和第二输入参数;以及提供指示针对多个输入参数的第二值的第二输入数据集。第二值包括:针对来自多个输入参数的至少一个输入参数的增强值,该增强值与针对至少一个输入参数所测量的第一值不同并且通过增强该第一值来确定;以及针对来自多个输入参数的至少一个剩余的输入参数的第一值。该方法进一步包括:通过以生理模型处理第一输入数据集,确定指示分析物的第一多个分析物值的第一分析物数据;通过以生理模型处理第二输入数据集,确定指示分析物的第二多个分析物值的第二分析物数据;从第一分析物数据和第二分析物数据两者确定训练数据集;确定测试数据集,该测试数据集与训练数据集不同;提供软件实现的机器学习模型,其被配置成确定分析物的分析物值;通过训练数据集训练该软件实现的机器学习模型;以及通过测试数据集测试该软件实现的机器学习模型。
12.根据另一方面,提供了一种用于生成用于确定分析物值的软件实现的模块的系统,其包括一个或多个数据处理器的布置。一个或多个数据处理器被配置成:提供指示针对多个输入参数所测量的第一值的第一输入数据集,该输入参数包括第一输入参数和第二输入参数;以及提供指示针对多个输入参数的第二值的第二输入数据集。第二值包括:针对来自多个输入参数的至少一个输入参数的增强值,该增强值与针对至少一个输入参数所测量的第一值不同并且通过增强该第一值来确定;以及针对来自多个输入参数的至少一个剩余的输入参数的第一值。一个或多个数据处理器被进一步配置成:通过以生理模型处理第一输入数据集,确定指示分析物的第一多个分析物值的第一分析物数据;通过以生理模型处理第二输入数据集,确定指示分析物的第二多个分析物值的第二分析物数据;从第一分析物数据和第二分析物数据两者确定训练数据集;确定测试数据集,该测试数据集与训练数据集不同;提供软件实现的机器学习模型,其被配置成确定分析物的分析物值;通过训练数据集训练该软件实现的机器学习模型;以及通过测试数据集测试该软件实现的机器学习模型。
13.根据另一个方面,提供了一种用于生成用于确定分析物值的软件实现的模块的计算机程序产品。计算机程序产品包括指令,当程序在一个或多个数据处理器的布置上执行时,该指令使一个或多个数据处理器的布置执行或进行该方法。
14.根据又一个方面,一种用于确定分析物值的方法,该方法包括:在一个或多个数据处理器的布置中,提供在一个或多个数据处理器的布置中运行的软件实现的模块;提供当前输入数据,其指示针对包含分析物的液体的多个输入参数所测量的当前值;以及确定分析物值,包括:通过软件实现的模块分析当前输入数据。
15.根据另外的方面,提供了一种用于确定分析物值的系统,该系统具有一个或多个数据处理器的布置和在一个或多个数据处理器的布置中运行的软件实现的模块,其中一个或多个数据处理器被配置成:提供当前输入数据,该当前输入数据指示针对包含分析物的液体的多个输入参数所测量的当前值;以及确定分析物值,包括:通过软件实现的模块分析当前输入数据。
16.在一个实施例中,测量数据可指示体液中的分析物。
17.用于确定分析物值的系统可例如选自下组,该组由以下各项组成:智能电话、计算机、平板电脑、血糖仪或连续血糖监测装置的接收器、药物输送泵的遥控器和药物输送泵。
18.分析物可以是体液(诸如间质液或血液,特别是间质液)的样品中的葡萄糖。测得值(例如第一值)可以是(在时间上)连续测量的。
19.本身已知的不同生理模型可被应用于通过处理第一输入数据集来确定指示分析物的第一多个分析物值的第一分析物数据。类似地,本身已知的不同的数据驱动模型或机器学习模型可被应用于所公开的技术中。
20.第一输入参数和第二输入参数中的至少一者可以选自下组,该组由以下各项组成:通过连续葡萄糖测量进行测量的葡萄糖水平、胰岛素大剂量碳水化合物摄入、活动大剂量胰岛素、活动基础胰岛素、活动水平、胰岛素灵敏度系数、碳水化合物比率、压力水平和碳水化合物的升糖指数。
21.在生成之后,软件实现的模块可被应用于确定分析物(例如,包含分析物的样品)的分析物值。为一个或多个患者收集的测量数据可由软件实现的模块处理或分析,以确定分析物的分析物值。例如,来自连续葡萄糖监测(cgm)和/或血糖测量(bgm)的测量数据可以由软件实现的模块处理或分析。测量数据(任选地与附加数据相结合)为软件实现的模块提供输入。软件实现的模块可被应用于预测(确定未来值)分析物的分析物值,诸如患者的葡萄糖水平。
22.确定第一分析物数据可包括:通过以生理模型处理第一输入数据集,确定指示分析物的分析物值经预测时间段的第一时间依存过程(迹线)的第一预测性分析物数据。附加地或替代地,确定第二分析物数据可包括:通过以生理模型处理第二输入数据集,确定指示分析物的分析物值经预测时间段的第二时间依存过程的第二预测性分析物数据。
23.分析物的分析物值的第一时间依存过程和/或分析物的分析物值的第二时间依存过程可以是连续葡萄糖监测(cgm)迹线。预测时间段可以在截止时间开始。预测时间段可以具有24个时段或者12或36个时段的长度。每个时段可对应相同长度的同一时间间隔,例如15分钟、10分钟或5分钟。替代地,该长度可以是可变的。
24.分析物的分析物值经预测时间段的每个时间依存过程可以通过使用卡尔曼滤波器的卡尔曼预测来确定。卡尔曼滤波器可用于估计系统的初始状态。系统的初始状态可包括分析物值,优选为在时间t=0处的葡萄糖值x0(t)=y0(t)。系统的初始状态可指示在时间t=0处的系统的状态。其可表明系统在没有碳水化合物摄入或大剂量胰岛素注射的情况下
如何随时间演变。
25.替代地,可以使用自回归(ar)模型来估计系统的初始状态。
26.分析物的分析物值经预测时间段的每个时间依存过程可以通过卡尔曼预测来确定。
27.提供第一输入数据集可包括:提供指示经测量时间段针对多个输入参数所测量的第一值的第一输入数据集。附加地或替代地,提供第二输入数据集可包括:提供指示经测量时间段的针对多个输入参数的第二值的第二输入数据集。替代地,第一输入数据集或第二输入数据集是经测量时间段的部分或子时间段提供的。
28.预测时间段可被提供为测量时间段的延续部分。
29.替代地,预测时间段可至少部分地与测量时间段重叠。特别地,预测时间段可以在测量时间段内,优选在测量时间段的结束处。
30.可以接收指示针对至少一个输入参数的参数限制(参数界限)的限制数据。可优选地经由限制数据来限制对针对至少一个输入参数的第一值的增强。此外,可经由限制数据来限制对针对至少一个输入参数的第一值和/或第二值的增强。限制数据可指示分析物的生理限制和/或针对患者进行个性化。
31.限制数据可以包括第一值的上界和/或下界,特别是区间。该区间可以是碳水化合物摄入范围、大剂量胰岛素范围或cgm范围,例如[-600,1000]mg/dl。限制数据可包括多个区间。限制数据还可以包括用于界定值对的区域,例如,一个或多个灵敏度网格区域,优选为区域a、b、d和e。
[0032]
确定测试数据集可包括:仅从第一分析物数据确定测试数据集。替代地,确定测试数据集可包括:从第一分析物数据和第二分析物数据确定测试数据集。
[0033]
替代地,可以从附加测得数据以及第一分析物数据和第二分析物数据中的至少一者确定测试数据集。附加测得数据包含测得分析物数据。替代地,可以从第一分析物数据和其他测得数据以及任选的增强分析物数据确定测试数据集。可以例如经由连续葡萄糖监测(cgm)和/或血糖仪(bgm)来确定测得数据。
[0034]
确定训练数据集可包括:确定残差分析物数据;从第二分析物数据和残差分析物数据确定增强分析物数据;以及至少从增强分析物数据确定训练数据集。
[0035]
确定残差分析物数据可包括:从第一分析物数据和测得分析物数据确定残差分析物数据。可通过以下方法从第一分析物数据和测得分析物数据确定残差分析物数据的分析物值:例如,对于每个对应的时间值,从测得分析物数据的分析物值减去第一分析物数据的分析物值。可通过以下方法从第二分析物数据和残差分析物数据确定增强分析物数据的分析物值:对于每个对应的时间值,对第二分析物数据的分析物值和残差分析物数据的分析物值求和。可以规定,增强分析物数据的所确定的分析物值仅在其在预定范围内,特别是在有界区间内时被接受,否则被拒绝。该区间可以例如为[-600,1000]mg/dl。
[0036]
可以规定,在增强分析物数据的所确定的分析物值被拒绝的情况下,测得分析物数据的分析物值被存储为增强分析物数据的分析物值。可以规定,确定新的增强分析物数据,直到增强分析物数据的所确定的分析物值被接受。测得分析物数据可以包含在第一输入数据集或第一值中。测得分析物数据可以是随机提取的(数据)样品。
[0037]
在一个实施例中,增强分析物数据可表示增强的cgm(连续葡萄糖监测)迹线。cgm
迹线包括测得的cgm值。使用生理模型来确定生理模拟迹线。经模拟时间段进行模拟。可以计算cgm迹线中的实际cgm值与模拟迹线中的cgm值之间的差值并将其存储在残差cgm迹线(残差分析物数据)中。残差cgm迹线可以添加到增强的cgm迹线。
[0038]
所摄取的碳水化合物和/或大剂量胰岛素的值可以用人工(例如,随机)生成的碳水化合物量和/或大剂量胰岛素量替换。基于人工生成的值,使用生理模型来确定生理上预测的人工迹线。通过将存储的残差cgm迹线添加到生理上预测的人工迹线,确定增强的cgm迹线(增强分析物数据)。原始cgm迹线的特性(诸如凹凸)可以再次出现在增强的cgm迹线中。
[0039]
可以确定训练数据集,包括测得分析物数据。
[0040]
可以规定,通过增强分析物数据和非增强分析物数据的量的比率来调节软件实现的机器学习模型的灵敏度值。
[0041]
提供第一输入数据集可包括:提供指示针对多个输入参数连续地测量的第一值的第一连续输入数据集。
[0042]
附加地或替代地,提供第二输入数据集包括:提供指示针对多个输入参数连续地测量的第二值的第二连续输入数据集。
[0043]
该方法可进一步包括提供指示针对多个输入参数的第三值的第三输入数据集,该第三值包括:针对来自多个输入参数的至少一个另外的输入参数的增强值,该增强值与针对至少一个另外的输入参数所测量的第一值不同并且通过增强该第一值来确定;以及针对来自多个输入参数的至少一个剩余的输入参数的第一值。此外,该方法可包括:通过以生理模型处理第三输入数据集,确定指示分析物的第三多个分析物值的第三分析物数据;从第一分析物数据、第二分析物数据和第三分析物数据确定训练数据集。可以通过第三分析物数据附加地确定测试数据集。
[0044]
该方法可包括:提供各自指示多个输入参数的值的多个输入数据集。可以规定,对于每个输入数据集,相应值包括针对来自多个输入参数的至少一个相应的输入参数的增强值,并且该每个增强值与针对至少一个相应的输入参数所测量的第一值不同并且通过增强该第一值来确定。相应值可进一步包括针对来自多个输入参数的至少一个剩余的输入参数的第一值。可以规定,指示分析物的相应的多个分析物值的分析物数据是通过以生理模型处理相应的输入数据集来确定的。
[0045]
从多个相应的分析物数据,可以确定训练数据集。多个输入数据集的增强值可以涵盖由输入参数限制(特别是生理参数限制)限定的一个或多个输入参数的范围。可以通过相应的分析物数据附加地确定测试数据集。
[0046]
可以规定,生理模型不用作预测算法本身的一部分。相反,可以规定,生理模型用于扩展训练机器学习模型所用的训练数据。特别地,可以在训练数据中包括更多种类的生理上有意义的数据。例如,跨越整个生理谱的葡萄糖波动可以包括在训练数据中。在扩展训练数据上训练的模型能够更好地反映预期的生理反应,例如对碳水化合物或胰岛素摄入的反应。因此,这种模型可能更适合提供更具生理意义的葡萄糖预测,同时保持高的预测准确度。
[0047]
生理模型可以提供来自输入数据的反应。特别地,生理模型可以提供来自碳水化合物摄入和/或大剂量胰岛素注射的葡萄糖反应。过程模型可以通过方程y(t)=x0(t)+f
(u1,u2,t)来描述,其中f是传递函数,t表示时间,并且u1和u2分别为表示碳水化合物摄入和大剂量胰岛素注射的函数。
[0048]
生理模型也可以用方程y(s)=k1u1(s)/((1+t1s)2s)+k2u2(s)/((1+t2s)2s)或方程y(s)=k1u1(s)/(1+t1s)2+k2u2(s)/(1+t2s)2来描述,其中葡萄糖反应y是复频数s、碳水化合物摄入u1、大剂量胰岛素注射u2和常数k1、k2、t1和t2的函数。常数k1和k2可与餐食摄入和大剂量胰岛素注射后的葡萄糖波动的幅度有关。时间常数t1和t2可决定餐食摄入/胰岛素注射以变化的葡萄糖值将自身表现出来的时间。函数y可以是函数y的拉普拉斯变换。特别地,s在拉普拉斯域中的函数y,u1,u2可分别对应于时域中的函数y,u1,u2,其中变量为t。
[0049]
生理模型可以是患者特定的。可以通过使包括来自患者的测得数据的成本函数最小化来确定常数(模型参数)k1、k2、t1和t2。常数k1、k2、t1和t2可被进一步限制在生理上有意义的值范围内。
[0050]
第二输入数据集可以提供从第一输入数据集(通过增强)导出的人工/合成输入数据集。对值进行增强可包括:人工生成(例如,随机生成)另一值并且用另一值替换该值。随机生成可遵循预定的概率分布。人工生成的值可能会被限制在一个区间内。增强的值可以是碳水化合物摄入值或大剂量胰岛素值。
[0051]
软件实现的机器学习模型可以由递归神经网络,特别是编码器-解码器递归神经网络来表示。软件实现的机器学习模型也可以由其他类型的人工神经网络表示。
[0052]
可以通过确定针对机器学习模型的对大剂量胰岛素和/或碳水化合物的准确度值和/或灵敏度值来提供对软件实现的机器学习模型的测试。
[0053]
可以应用本身已知的不同生理模型。特别地,可以采用以下模型中的至少一个(例如,参见oviedo et al.(2017),international journal for numeric methods in biomedical engineering 33(6)):lehmann和deutsch葡萄糖吸收模型、改良的lehmann和deutsch葡萄糖吸收模型、berger血浆胰岛素浓度、dalla man葡萄糖吸收模型、dalla man胰岛素吸收模型、cobelli胰岛素模型、tarin血浆胰岛素浓度模型、lehmann葡萄糖显现率模型、dalla man餐食模型、verdonk血浆胰岛素模型、自回归外生(arx)模型、berger胰岛素动力学模型、hovorka餐食吸收模型、皮下胰岛素吸收动力学模型和时间序列模型。
[0054]
类似地,本身已知的不同的数据驱动模型或机器学习模型可被应用于所公开的技术中。例如,可以采用随机森林、梯度推进、自组织映射(som)和/或跳跃神经网络(jump nn)。
[0055]
对于用于确定分析物值的方法,该方法可进一步包括以下各项中的至少一项:通过输出装置向使用者输出分析物值;以及在分析物值低于最小阈值或高于最大阈值的情况下,向使用者输出警报。如果待确定的分析物值是体液中的葡萄糖水平,则警报可以指示低血糖和高血糖中的一者。输出装置可被配置成向使用者或患者输出音频数据和视频数据中的至少一者。
[0056]
如果分析物是葡萄糖并且分析物值是葡萄糖浓度,则最小阈值可以为70mg/dl,在一个实施例中为60mg/dl并且在另一个实施例中为50mg/dl。
[0057]
如果分析物是葡萄糖并且分析物值是葡萄糖浓度,则最大阈值可以为140mg/dl,在一个实施例中为160mg/dl并且在另一个实施例中为200mg/dl。
[0058]
输出装置可例如选自下组,该组由以下各项组成:智能电话、计算机、平板电脑、血
糖仪或连续血糖监测装置的接收器、药物输送泵的遥控器和药物输送泵。
具体实施方式
[0059]
接下来,参考附图描述进一步的实施例。在附图中示出:
[0060]
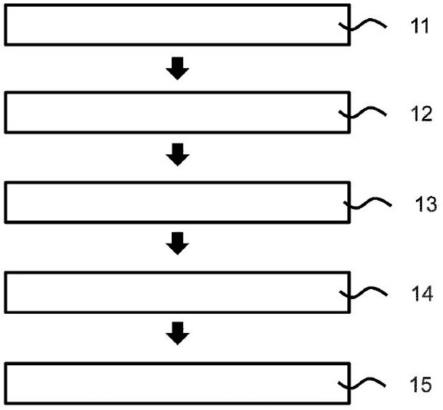
图1是用于生成用于确定分析物值的软件实现的模块的方法的图形表示;
[0061]
图2是用于将研究数据分配到时段的图形表示;
[0062]
图3是灵敏度网格的图形表示;
[0063]
图4用于生成增强的cgm迹线的图形表示;
[0064]
图5用于生成增强的cgm迹线的另一图形表示;
[0065]
图6是编码器-解码器递归神经网络的图形表示;
[0066]
图7是在一般场景和餐后场景中,准确度相对于时间的图形表示;并且
[0067]
图8是平均准确度相对于模型对胰岛素灵敏度的图形表示。
[0068]
图1示出了用于生成用于确定分析物值的软件实现的模块的方法的图形表示。
[0069]
在步骤11中,提供输入数据集,特别地至少提供第一输入数据集。输入数据指示针对多个输入参数测量或确定的值。输入数据集中的至少一个(例如第一输入数据集)包括原始数据,诸如临床研究数据。由原始数据制备(标准化)数据集(步骤12)。该步骤可包括:将数据集划分为训练数据集和测试数据集。
[0070]
输入参数可选自下组,该组由以下各项组成:通过连续葡萄糖测量或监测(cgm)针对患者所测量的葡萄糖水平、胰岛素大剂量碳水化合物摄入、活动大剂量胰岛素、活动基础胰岛素、活动水平、胰岛素灵敏度系数、碳水化合物比率、压力水平和碳水化合物的升糖指数。
[0071]
随后,对包括训练数据集和/或测试数据集的数据集进行预处理(步骤13)。该步骤可包括训练数据集的人工数据增强。替代地,也可以在预处理之后将数据集划分为训练数据集和测试数据集。在这种情况下,可以规定,识别非增强数据集并仅将非增强数据集分配给测试分区。
[0072]
在步骤14中,将预处理的训练数据集馈入建模算法,该建模算法建立用于预测分析物值(例如连续葡萄糖测量(cgm)值)的模型。在步骤15中,通过使用至少一个度量在测试数据集上评价建立的模型。
[0073]
数据集制备
[0074]
出于建模目的,对于输入数据集中的每一个,可以将原始数据映射到具有特定长度(时间长度)的各个时段的标准化时间网格上,从而产生标准化数据集。
[0075]
图2示出了将研究数据分配到沿着时间t轴的时段20的图形表示。对于每个时段20,该长度可以是相同的,例如15分钟、10分钟或5分钟。替代地,该长度可以是可变的。
[0076]
从中提取数据序列(例如,根据多对多序列建模的输入的需要)的时间范围由特征提取时间窗口(fetw)21表示。需注意,在图4和图5中,在截止时间之后的预测时间段内也存在测量数据。然而,可以规定,在截止时间之后的预测时间段内的测量数据不用于训练。此外,预测时间窗口(ptw)或预测时间段22表示所考虑的模型将在其上产生预测的时间范围。
[0077]
触发预测时数据可用的最后时段(截止时段)23由截止时间24定义。
[0078]
所生成的数据被拆分成不同的分区,用于训练(train)和测试(test)。即,对于固
定的fetw 21和ptw 22,截止时段被分配给train分区或test分区中的任一者。
[0079]
test分区中的截止被定义为没有ptw 22重叠。当机器学习模型(也称为预测模型)在test集上进行评价时,这允许对泛化误差进行无偏差的评估。对于train分区,没有这种要求。
[0080]
使用基于患者的train/test拆分,其中患者的所有截止时段被随机分配给train分区或test分区中的任一者。
[0081]
除了为模型的训练和测试定义数据拆分外,还使用预定义的截止标准(截止附近的特定要求)来定义不同的场景。标准carboydrates_all表示患者摄入的碳水化合物(以g为单位)。标准bolus_insulin表示胰岛素单位ui下的大剂量胰岛素。这些标准被应用于train分区和test分区两者中的数据集。
[0082]-一般场景:
[0083]-fetw长度=48个时段,ptw长度=24个时段,
[0084]-fetw 21和ptw 22中没有缺失的cgm值,并且
[0085]-在ptw中,carboydrates_all=0并且bolus_insulin=0。
[0086]-餐后场景:
[0087]-fetw长度=48个时段,ptw长度=24个时段,
[0088]-fetw 21和ptw 22中没有缺失的cgm值,
[0089]-对于所有最后的9个时段,carboydrates_all≤200并且bolus_insulin≤100,
[0090]-对于最后9个时段中的任一个,carboydrates_all≥10并且bolus_insulin≥0.1,并且
[0091]-在ptw中,carboydrates_all=0并且bolus_insulin=0。
[0092]
可以删除cgm值中的异常值。“没有缺失的cgm值”意指不存在其中不存在cgm值的时间间隙。这些场景旨在涵盖患者在一天中可能遇到的不同情况。在这些场景中评价各个模型可以更好地理解它们在特定情形中的表现。
[0093]
基于可用数据,获得场景截止到不同分区中的以下分布:
[0094]
场景分区截止数一般train1'210'727一般test15'630餐后train104'929餐后test2'744
[0095]
对于每个可用的时段,构建不同的特征。对于每个构建的特征,估算值,分三步完成:
[0096]
1.如果条目未丢失超过15分钟(对于5分钟的时段长度,这对应于3个时段),则对缺失值进行线性插值。
[0097]
2.用每位患者的中值、平均值等(如果有)替换剩余值。
[0098]
3.用队列中值、平均值等替换剩余值。
[0099]
对于每个场景和train/test分区,生成3维(标准化)数据集(样品*特征*时间)。
[0100]
每个数据集包括输入变量(针对train数据集的x
训练
、针对test数据集的x
测试
)和输出变量(针对train数据集的y
训练
、针对test数据集的y
测试
)。输入变量x
训练
和x
测试
中的每一个包
括以下特征:
[0101]-hba1c
[0102]-still_active_basal_insulin、
[0103]-bolus_insulin、
[0104]-bolus_insulin_still_active、
[0105]-basal_insulin、
[0106]-carbohydrates_all、
[0107]-cir_best_estimate__g_per_iu、
[0108]-isf_best_estimate__mg_per_dl_iu、
[0109]-cgm。
[0110]
hba1c表示糖化血红蛋白,still_active_basal_insulin表示根据过去的胰岛素注射量在特定时间点仍处于活动状态的分为基础胰岛素和大剂量胰岛素的胰岛素量,bolus_insulin表示大剂量胰岛素(以胰岛素单位iu表示),carbohydrates_all表示患者摄入的碳水化合物(以g为单位),cir_best_estimate_g_per_iu表示估计的碳水化合物与胰岛素比率,isf_best_estimate_mg_per_dl_iu表示估计的胰岛素灵敏度,并且cgm表示连续葡萄糖测量结果(mg/dl)。
[0111]
输入变量x
训练
和x
测试
可进一步包括fetw长度值(优选为48个时段)。
[0112]
输出变量y
训练
和y
测试
可包括用于后续建模/学习算法的目标变量(目标)cgm以及ptw长度值(优选为24个时段)。
[0113]
数据集预处理
[0114]
在“数据驱动与数据增强”(ddwda)方法中,train数据集被进一步预处理。在此,预处理被定义为对train数据集的任何重要修改,其预期提高数据驱动预测模型对单独评价(test)数据集的表现。
[0115]
特别地,迄今为止,用于葡萄糖预测的数据驱动序列模型对碳水化合物和/或大剂量胰岛素并不灵敏。数据预处理可有助于改善这种情况,而不受模型类型、架构和超参数选择的影响。
[0116]
任何数据驱动模型的质量都由基础的训练数据和测试数据决定。如果测试数据的分布与训练数据几乎没有重叠,则经训练的模型通常会对目标应用几乎没有任何用处。例如,高度受控的临床试验可能无法反映真实世界。数据增强的目标是通过修改训练集来提高模型表现(如例如通过预测准确度或均方根误差rmse来衡量)或对特定特征的灵敏度。
[0117]
数据增强方法可被描述为两个不同的数据预处理步骤的序列:
[0118]-对给定数据集进行过采样以及
[0119]-在(训练)数据集ds(合成数据生成)中修改样品或添加经修改的样品。
[0120]
过采样步骤并不是绝对必要的,因为由真实数据生成合成示例的任何引擎都足以满足数据增强的目的。
[0121]
通过使用生理模型(过程模型)来增强test数据集中的至少一个,该生理模型描述了分别在拉普拉斯域中的碳水化合物摄入u1或大剂量胰岛素注射u2之后,拉普拉斯域中的葡萄糖反应y(即,葡萄糖/cgm反应y的拉普拉斯变换)。附加地或替代地,可以通过使用生理模型来增强train数据集中的至少一个(参见下文的图4和图5)。
[0122]
可以采用两个生理模型pm1或pm2中的一者。针对葡萄糖反应y(碳水化合物摄入u1或大剂量胰岛素注射u2之后)的生理模型pm1可通过拉普拉斯域中的以下方程进行描述:
[0123][0124]
生理模型pm2可以用以下方程进行描述:
[0125][0126]
两种生理模型中均未考虑基础胰岛素注射。生理模型pm1和pm2是类似的。然而,pm1模型的两个传递函数均包括额外的积分项,其产生积分行为。而pm2模型在摄入的影响消失后总是返回到模型的稳定平衡点(基础葡萄糖状态),而pm1模型则不是这种情况,该模型没有平衡点。在pm1模型中,碳水化合物摄入和胰岛素摄入对葡萄糖水平具有持续影响,这特别是由积分项(s=0处的极点)引起的。
[0127]
两种模型结构均具有模型参数具有直接生理意义的优点。常数k1和k2与餐食摄入和大剂量胰岛素注射后的葡萄糖波动的幅度有关,而时间常数t1和t2决定餐食摄入/胰岛素注射以变化的葡萄糖值将自身表现出来的时间。对于pm1模型,表明模型参数是对患者和进餐时间特定的碳水化合物与胰岛素比率(cir)和胰岛素灵敏度系数(isf)的有用估计值,t1d患者使用这些参数来计算他们的大剂量胰岛素需求.在这种情况下,常数k2与系数isf具有相同的生理意义,而混合常数k2/k1的生理解释与cir的生理解释相同。
[0128]
患者特定的模型的识别对应于以下成本函数的最小化
[0129][0130]
其中
[0131][0131][0132][0133]
替代地,可以将函数f定义为针对yk的任意值。在成本函数中,yk对应于测得输出,即,cgm数据,而是模型输出。识别段中使用的每个数据段d(总数为d
总数
)均以起始索引k0和结束索引kn为特征。使用以下各项来计算模型输出模型参数θ=(k1,t1,k2,t2)以及初始状态的估计值初始状态估计值对应于识别段k0开始时的系统状态。例如,可以规定关于参数向量θ,对于患者的每个数据段,使用同一参数向量θ。替代地,针对每个段可以采用特定的参数向量θ。
[0134]
当针对每个段使用特定的参数向量θ时,有必要引入正则项以防止过度拟合。该正
则项对应于针对所有数据段d的参数向量θ的变异系数(标准偏差除以平均值)。该项的重要性由参数λ
正则
决定。利用该正则项,四个参数中的每一个均具有相同的权重,即,
[0135][0136]
相比之下,当使用同一参数向量来描述所有的识别数据段时,该正则项成为零。
[0137]
为了识别模型参数θ=(k1,t1,k2,t2),可以使成本函数j最小化,例如,经由matlab例程fmincon。为了不仅获得良好的预测结果,而且获得合理的模型参数,经由fmincon在优化中将k1,t1,k2和t2的值限制在生理上有意义的范围内。可以材料两种不同的设置:参数值的较宽范围和较窄范围。这些范围以及参数向量θ的初始猜测值总结如下。
[0138][0139][0140]
关于在识别数据段开始时系统的初始状态的估计值可以采用三种不同的方法:
[0141]
–
卡尔曼状态估计,
[0142]
–
无状态估计,或
[0143]
–
混合状态估计。
[0144]
对于卡尔曼状态估计,卡尔曼滤波器被用来使用模型输入和可用的cgm测量结果来估计系统的初始状态。滤波器从识别数据段开始前6小时开始进行其状态估计,并针对这些时间点中的每一个计算状态的估计值,直到识别段的开始。最后估计值(恰好在识别数据段的开始)对应于系统识别的初始状态。在优化的每个迭代步骤中使用模型参数θ的当前猜测值来更新卡尔曼滤波器内的模型(从具有参数θ的过程模型导出)。即,用于预测的过程模型和用于卡尔曼滤波的(同一)过程模型同时被优化。
[0145]
卡尔曼滤波器(其根据餐食碳水化合物和大剂量胰岛素以及测得cgm数据计算针对每个时间步的状态估计值)的微调决定了滤波器对用于估计状态的模型的信任程度以及对在每个时间步中可用的新cgm测量结果的重视程度。这是经由矩阵q和r完成的。如果q的值远大于r的值,则模型被认为不太可信,并且主要基于新的cgm数据来完成状态估计值的更新。但是,如果r的值远大于q的值,则不会过多重视cgm数据,并且更新几乎完全由模型决定。
[0146]
对角矩阵已用于q和r,分别具有对角元素q和r。q和r的值可以进行手动微调,也可以视为优化问题的自由度。在后一种情况下,除了模型参数外,还优化了q和r以使成本函数j最小化。
[0147]
在重点强调卡尔曼滤波器(r>>q)内的模型的情况下,初始状态下的经过滤输出与同一时间点的cgm数据之间可能会出现较大的偏差,这可能是不期望的。为了补偿这种影响,可以计算来自卡尔曼滤波器的与同一时间点的cgm测量结果之间的差值,然后以该差值偏移整个识别周期的模型输出
[0148]
针对卡尔曼状态估计采用以下设置:
[0149][0150]
优选地,采用设置c13。
[0151]
当替代地使用无状态估计时,假设系统在识别数据段开始时处于稳定的平衡状态。这对应于即,初始状态对模型输出没有影响。对于这种方法,生理模型pm1和pm2的输出对应于不进餐时的0mg/dl。因此,作为识别过程的一部分模拟的餐后轨迹总是从0mg/dl开始。为了仍然获得合理的模型输出和识别结果,假设系统在每个识别数据段开始时处于稳定的平衡状态。这是相当粗略的假设:可能在早餐时得到最好的满足,但在午餐和晚餐时对识别片段来说则不然。
[0152]
对于混合状态估计,假设针对过程模型,为0。这意味着初始状态对过程模型输出没有影响。初始状态的影响由自回归(ar)模型捕获。然后,该混合模型的预测葡萄糖输出对应于过程模型预测和ar模型的预测的总和。在该方法中,不需要假设系统在每个识别数据段开始时处于稳定的平衡状态,因为由于ar模型,组合模型输出直接从最后一次测量开始,而仅使用过程模型来描述餐食摄入和大剂量胰岛素摄入的额外影响。在这种情况下,系统识别不需要卡尔曼滤波器(针对过程模型,再次假设),但ar模型的微调当然会对识别结果和混合模型的预测表现产生影响。
[0153]
针对一天中的不同时间确定单独的模型参数,即,对于任何受分析的情况,总是会
生成三个模型:
[0154]
–
早餐模型:在系统识别中只考虑开始时间在5:30与10:30之间的识别数据段。
[0155]
–
午餐模型:在系统识别中只考虑开始时间在10:30与14:30之间的识别数据段。
[0156]
–
晚餐模型:在系统识别中只考虑开始时间在17:00与21:00之间的识别数据段。
[0157]
除了卡尔曼状态估计、无状态估计或混合状态估计之外,还可以采用贝叶斯方法进行系统识别。在这种情况下,方程3中的成本函数j包含附加项,其惩罚所识别的模型参数与预定义的先验之间的差值。在使用同一参数向量对所有识别数据段进行建模的情况下,经修改的成本函数采用以下形式:
[0158][0159]
其中函数f如在上文的方程4中定义。成本函数中的第二项惩罚所识别的参数向量与具有相对权重λ
先验
的先验之间的二次差值。在对每个数据段使用不同的参数向量的情况下,该项对应于所有参数向量的所有二次差值的总和(加上额外的正则项,参见方程3)。
[0160]
针对贝叶斯状态估计采用以下设置。优选地,采用窄约束(或者,宽约束)。
[0161][0162]
随着生理模型的建立,预测葡萄糖轨迹可以计算如下。可以研究用于预测的不同范围。数据具有采样时间ts=5分钟,并且执行范围为k=1(5分钟)到k=24(120分钟)的预测。总是对每个患者的完整数据集和所有不同的所识别的参数集(即早餐参数、午餐参数和晚餐参数)进行预测。如果识别出餐食特定的参数,则所有餐食的平均值被用于估计每个过程模型的状态以及通过基于该估计状态模拟过程模型来进行预测。
[0163]
可以采用两种不同的预测方法:
[0164]
–
卡尔曼预测(与卡尔曼状态估计和无状态估计一起使用)和
[0165]
–
混合预测(与混合状态估计一起使用)。
[0166]
在卡尔曼预测的情况下,过程模型的所识别的参数以及q和r的值被用于根据直到时间t的输入(u1,u2)(碳水化合物摄入u1和大剂量胰岛素注射u2)数据和输出(δy=y-gb)数据在每个时间t对过程模型进行状态估计gb表示患者经所有识别日的基础葡萄糖,即,由患者前28天的数据计算的cgm平均值。
[0167]
基于每个时间点t的估计状态的信号,将该状态用作以过程模型进行模拟的初始条件:x0=x(t)。对于模拟,所有未来输入(在当前时间t之后)都被删除(设置为0)并且输出y
模拟,k
(t)被模拟达k=0,...,24个步骤。这样,计算出对时间的预测t+k
·
ts,即,
[0168][0169]
在计算出来自卡尔曼滤波器的与同一时间点的cgm测量结果之间的差值并且以该差值偏移整个识别周期的模型输出的情况下,预测由下式给出
[0170][0171]
其中y(t)表示时间t处的实际cgm测量结果。
[0172]
在混合预测的情况下,预测由下式计算
[0173][0174]
其中表示利用全局ar模型进行的对时间的预测k
·
ts,给定直到时间t的信息。作为y
模拟,k
(t)的初始条件,假设x0=0。
[0175]
(二阶)全局ar模型采用以下形式
[0176][0177]
δy(t)=y(t)-gb,
[0178][0179]
其中gb是患者特定的基础葡萄糖(每位患者经前28天的平均cgm值)。使用最小二乘(ls)优化针对以下每个预测范围优化参数(ak,bk):∈{1,2,
…
,24}。对训练数据集中所有175个患者的前28天数据的组合识别全局ar模型。
[0180]
可以采用全局ar模型的不同变体:
[0181]
a)使用所有数据(训练数据集中所有175个患者的前28天数据的组合);
[0182]
b)使用所有数据而不考虑对非零输入进行预测的数据段;
[0183]
c)与b)相同,但不是使用预测误差而是使用普通最小二乘ls(即,),采用归一化误差
[0184][0185]
产生加权最小二乘(wls)问题;
[0186]
d)与c)相同,但仅为使用夜间(定义为23:00与5:30之间)的数据。
[0187]
作为ar模型的替代方案,通过保持最新的可用值恒定,即根据直到时间t的cgm数据y经由零阶保持(zoh)模型来计算时间t+k
·
ts处的预测
[0188]
使用生理模型和针对各个患者的补充数据(k1、t1、k2、t2等),采用以下知识驱动的数据增强算法来增强cgm迹线(cgm值的时间序列)。
[0189]
1.定义数据增强参数:
[0190][0191][0192]
2.根据数据增强参数提取待增强的随机样品。
[0193]
3.对于每个待增强的提取样品,
[0194]
a)在进餐时间窗口mtw中识别(输入特征carbohydrates_all或bolus_insulin中的任一者的)最后一个条目时段,
[0195]
b)计算实际cgm值与在进餐时间窗口mtw中的最后一个条目时段处计算的生理模型(优选为c13)的实际cgm值之间的差值并将其存储在残差cgm迹线cgm_delta中,
[0196]
c)在最后一个条目时段处,将carbohydrates_all和bolus_insulin替换为人工生成的碳水化合物量和大剂量胰岛素量,
[0197]
d)在最后输入时间使用修改的输入数据来触发对生理模型的预测,直到预测时间窗口结束(=cgm_phys),
[0198]
e)如果信号在界限内(参见上文的参数cgm范围[min_cgm,max_cgm]),则接受经修改的cgm迹线(cgm_augmented=cgm_phys+cgm_delta),否则拒绝并存储原始cgm迹线,以及
[0199]
f)重复进行。
[0200]
替代地或附加地,可以增强可以用生理模型预测的其他类型的值。例如,可以增强表示体育活动程度的值。
[0201]
图3示出了灵敏度网格的图形表示。灵敏度网格划分为区域a、c、d、e、f和g。此外,示出了对应于碳水化合物和大剂量胰岛素对的示例性数据点30。数据点30表示增强之后碳水化合物值和胰岛素值的分布的示例。
[0202]
并非所有数据点30都用于灵敏度计算。只有位于灵敏度网格区域a、c、d和e中的碳水化合物和大剂量胰岛素对可接受。距离对角线(未示出)较远的数据点30表示更极端的情况。
[0203]
图4和5示出了生成增强cgm迹线的图形表示。在截止时间40、50之前或之后的时段中缩放x轴。对应地,进餐时间窗口41、51的最后一个条目时段具有时段值0。cgm迹线42、52包括实际/测得的cgm值。基于每个进餐时间窗口41、51的最后一个条目时段,使用生理模型确定生理预测迹线43、53。预测发生在预测时间段22。计算cgm迹线42、52中的实际cgm值与预测迹线43、53中的cgm值之间的差值并将其存储在残差cgm迹线(未示出)中。
[0204]
在进餐时间窗口41、51的最后一个条目时段处,将摄取的碳水化合物和大剂量胰岛素的值替换为人工(例如,随机)生成的碳水化合物量44、54和大剂量胰岛素量45、55。基于人工生成的值44、45(分别为54、55,使用生理模型来确定生理上预测的人工迹线46、56。通过将存储的残差cgm迹线添加到人工迹线46、56,确定增强的cgm迹线47、57。原始cgm迹线42、52的某些特性(诸如凹凸48、58)可以在增强的cgm迹线47、57中再次出现(作为凹凸49、59)。
[0205]
基于所描述的数据增强方法,构建附加的(增强的)训练集并将其用于建模。对于所有数据增强方法,test分区的数据集未被进一步修改(即未被增强),以便评估模型对真实数据分布的表现。
[0206]
在仅比较数据驱动(dd)的方法中,train数据集未被进一步预处理,而是在训练模型时按原样使用。test数据集也未被预处理。
[0207]
在另外的比较混合(h)方法中,对(未增强的)train数据集和test数据集执行以下数据集预处理步骤。采用如上文所定义的生理模型,并且使用cgm残差而不是(非残差)cgm值作为用于建模的目标变量。cgm残差定义如下:
[0208]
cgm
残差,i
=cgm
预测_生理,i-cgm
实际,i
, (方程9)
[0209][0210]
其中cgm
残差,i
表示第i时间点处的残差,单位为mg/dl,cgm
预测_生理,i
表示由生理模型预测的第i cgm值,单位为mg/dl,并且cgm
实际,i
表示第i实际cgm值,单位为mg/dl。在评价模型并与其他模型进行比较时,cgm残差空间中的预测被转换回cgm空间。
[0211]
建模
[0212]
在预处理数据集ds之后,基于序列到序列建模架构训练(软件实现的)机器学习模
型。作为输入,机器学习模型需要使用数据增强(ddwda)方法、仅数据驱动(dd)方法或混合(h)方法建立的预处理数据集ds。
[0213]
对于建模,可以采用用于缩放数据集的缩放函数,例如,minmax。数据集的特征可以例如被缩放到区间[-1,1]。
[0214]
图6示出了利用其来训练机器学习模型的编码器-解码器递归神经网络(ed-rnn)60的图形表示。ed-rnn 60获取多个(序列)输入值61并产生多个(序列)输出值62。这对应于多对多架构。一定数量的编码器单元63(g各自获取一个输入值61)后面跟着多个解码器单元64(各自产生一个输出值62)。单元63、64被布置在链中并且单元63、64中的每一个(除了最后一个单元)产生状态65作为链中下一个单元的输入。编码器单元63属于第一阶段66并且解码器单元62属于第二阶段67。
[0215]
可以使用可变预测时间窗(ptw)和特征提取时间窗(fetw)。ed-rnn 60的特征在于可以对其进行优化的以下超参数:
[0216]-层数,表示网络的深度;
[0217]-节点数,表示特定层中的宽度;
[0218]-单元64、65的类型(长短期记忆(lstm)或门控递归单元(gru));
[0219]-学习速率(步长),每次迭代后权重被覆盖的速度;
[0220]-批量大小,一次迭代中使用的训练样品数;
[0221]-时期数,学习算法将在整个训练数据集ds中运行的次数;
[0222]-损失函数,用于计算误差(例如,均方误差)的成本的函数;
[0223]-优化器,算法所使用的优化算法(例如,adam);
[0224]-正则化器,用于避免过度拟合的技术类型;以及
[0225]-正则化器因子,与正则化器因子一起应用的系数因子。
[0226]
可以规定,在建模期间优化超参数中的至少一些。替代地,所有超参数都是固定的。例如,层数可以为128、256或512。批量大小可以为128、256或512。时期数可以为1与20之间的任何整数,优选为5或7。学习速率可以在10-4
与10-1
之间,优选为10-3
。
[0227]
除了ed-rnn,其他类型的人工神经网络也可以用于建模。
[0228]
评价和结果
[0229]
使用包括输入变量x
测试
和输出变量y
测试
的test数据集来评价建立的机器学习模型的预测表现。
[0230]
针对评价,未缩放预测值。在(非残差)cgm空间中评价预测表现。在混合方法的情况下,因此必须事先将目标变量值cgm
残差,i
转换回非残差cgm值。
[0231]
随后,通过使用度量来评价预测值。可采用以下度量来评价机器学习模型:
[0232]-准确度和
[0233]-对大剂量胰岛素和/或碳水化合物的灵敏度。
[0234]
准确度对应于在相应时间点处高于或等于100mg/dl(低于100mg/dl)的真cgm值的+/-15%(或15mg/dl)内的cgm预测值百分比。对大剂量胰岛素和/或碳水化合物的灵敏度对应于预测cgm的变化程度(以mg/dl每单位胰岛素为单位)。在截止处,胰岛素δi或碳水化合物δcarb的微小变化被添加到相应的值。在这之后,每次的cgm预测dcgm都会发生变化。因此,如果dcgm(t)=f(δi),则灵敏度=dcgm(t)/δi;并且如果dcgm(t)=f(δcarb),则灵
敏度=dcgm(t)/δcarb。
[0235]
这里的灵敏度意指t=90分钟时的平均灵敏度。
[0236]
针对每个预测时间点分别计算评价度量。聚合特定预测时间的所有样品,例如,通过使用中值。
[0237]
对于每种方法(dd、ddwda、h),选择在一般场景下经120分钟具有最高平均准确度的机器学习模型。结果汇总如下。
[0238][0239][0240]
图7示出了在一般场景和餐后场景中方法dd、ddwda和h的准确度(以%为单位)相
对于时间(以分钟为单位)的图形表示。
[0241]
第70、71和72行分别表示一般场景中方法dd、ddwda和h的准确度值,并且第73、74和75行分别表示餐后场景中方法dd、ddwda和h的准确度值,。所有准确度值都随时间单调递减。方法dd的准确度值在两种场景中都最高,而方法h的准确度值在大多数时间在两种场景中都最低。因此,通过添加人工数据,获得较高的灵敏度,但可能会降低表现。
[0242]
图8示出经120分钟平均准确度(以%为单位)相对于模型对胰岛素灵敏度(以(mg/dl)/iu为单位)的图形表示。示出了三种方法(dd一般80、dd餐后81、ddwda一般82、ddwda餐后83、h一般84、h餐后85)中的每一种的结果以及由数据增强模型驱动的进一步数据86。使用同一数据增强技术,但利用不同的参数和/或超参数来形成进一步数据86。第87和88行分别表示一般场景和餐后场景中ddwda数据点的线性拟合。
[0243]
由数据点82、83表示的ddwda模型构成一般场景中经120分钟在准确度方面最佳的ddwda模型。
[0244]
在本说明书、附图和/或权利要求书中公开的特征可以是用于实现各种实施例的材料,这些特征是单独地或以其各种组合来采用的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1