用于提供生物样品的完整性指示的质谱系统和方法与流程
本发明涉及一种用于根据质谱数据提供生物样品的完整性指示的质谱系统和方法。
背景技术:
1、在实验室或临床环境中,最重要的是为了检索关于样品或关于个体的信息而被分析的这种样品的完整性不丢失或不损坏。换言之,能够可靠地评估样品的完整性至关重要。完整性被理解为与健全且完全的质量,即内部一致性有关,使得没有信息损坏。样品完整性也可视为样品质量的代替物。样品的完整性可能由于各种原因而损坏,该原因包括但不限于:
2、(a)样品来源不明或损坏
3、(b)丢失样品的身份
4、(c)样品的潜在污染
5、(d)样品加工中的问题
6、(e)样品的降解
7、关于完整性状态的信息通常被描述为“完整性数据”。技术人员容易地意识到完整性数据确保数据在其整个生命周期内的准确性和一致性。完整性数据被用作数据质量的代名词。任何完整性数据技术的总体意图都是相同的:确保数据完全按照预期记录(诸如数据库正确拒绝相互排斥的可能性)。此外,在稍后检索时,完整性数据确保生物样品的数据在加工生物样品和/或获取生物样品的数据之后仍然是相同的数据。简言之,数据完整性旨在防止信息的意外更改。
8、如果无法确认完整性,则所生成的数据可能损坏或无法分配给生物系统,并且无法生成可用的知识。本发明应用质谱系统来确认生物样品的完整性。
9、没有已知的方法能够同时验证如上所述的样品完整性的多个方面。用于验证例如样品完整性的已知方法包括施加至含有样品的贮器的物理条形码。例如,医生使用打印机将物理条形码施加至血液收集容器。条形码含有有关样品来源的信息,并且进而允许将样品重新分配给样品所获自的个体。容器中的血液可以是样品。条形码可用阅读器读取,并且可被分配给此个体。这允许将样品和来自这一样品的任何生成的数据与个体相匹配。此类物理条形码可用于鉴定样品及其来源。然而,已知的条形码不能用于检查样品的完整性。不能丢失的特定于样品的标识符只能从样品本身生成。
10、如果条形码标记丢失或样品被降解和/或污染,则从样品生成的数据和样品本身将变得无用或导致错误的结论。这些是样品完整性损坏的实例。
11、用于验证样品的部分完整性的其它已知方法包括dna或rna测序。dna或rna测序无法定量蛋白质,更不用说肽、翻译后修饰、代谢物、脂质和离子的离子了。在不含任何细胞或极少量细胞数的样品(诸如像尿液、脑脊液、血浆和血清的体液)中,基因组和转录组尤其难以分析。基于dna或rna的分析可有助于鉴定样品的来源,但无助于定量地确定被其它样品的污染或评估它的完整性。此外,测序技术无法检测通过样品采集或样品预加工引入的质量问题。
12、由于这些原因,需要一种可靠且准确的系统和一种方法来提供样品完整性的验证。
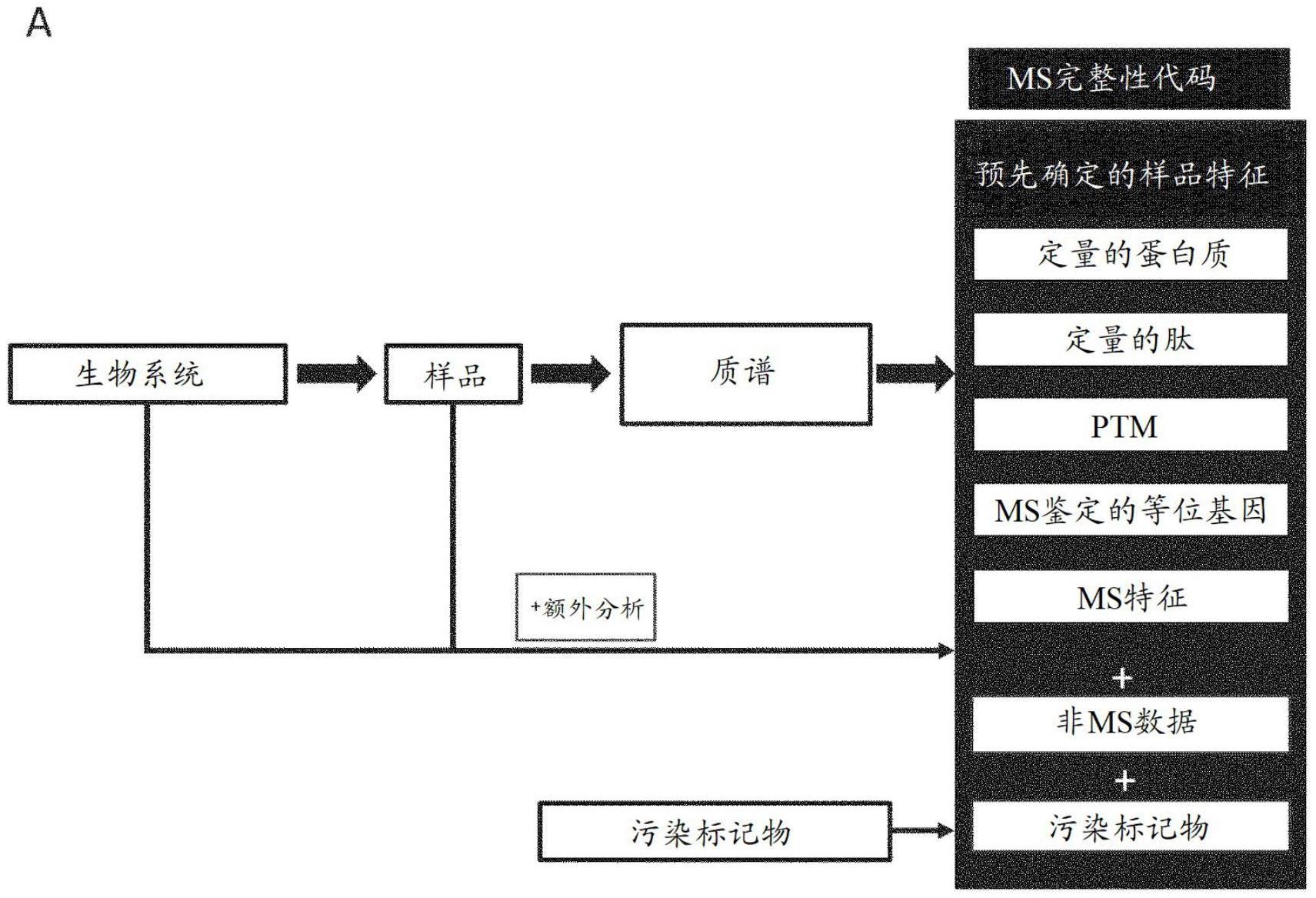
13、术语
14、质谱仪=各种各样的质谱仪
15、ms=质谱仪,质谱,质谱法
16、质谱数据=通过质谱系统生成的数据。这种未经加工和经进一步加工的数据。此种数据可以是质量,电荷,质荷比,碎片光谱,ms2碎片信息,离子迁移率,强度信息,保留时间,序列(在蛋白质/肽的情况下)或其它身份(在脂质/代谢物的情况),关于肽、蛋白质、翻译后修饰、等位基因、生物分子(如脂质)、小分子(如药物或代谢物)、碳水化合物,优选定量的生物分子的信息中的一者或多者。
17、预先确定的样品特征=是样品或其生物来源的特征。预先确定的样品特征可在用于确认样品完整性的质谱仪分析之前或之后限定或确定。
18、lc=液相色谱,各种各样的lc,也称为高效液相色谱或超高效液相色谱(hplc/uhplc);其它肽和/或蛋白质分离方法包括例如气相分离/分馏和毛细管电泳。
19、术语“组织”是指所有生物组织,包括人类来源的样品、人类遗骸或木乃伊,或非人类来源,诸如动物和/或保存的遗骸。它包括液体和固体组织以及用不同固定方法固定的组织。
20、活检物是从生物体中采集的样品。活检物可源自组织样品或体液。在后一种情况下,活检物通常被称为液体活检物,但也通常称为活检物。
21、生物系统=生物样品可以是任何生物来源的东西。例如,人类个体、动物、环境(如一块土壤)、更大生物系统的一部分(如人类个体的器官)。生物分子的存在、不存在、组成或浓度对于不同的生物系统可能是独特的,并且可从这种生物系统的样品中确定。
22、样品=有限数量的某物,其旨在类似于并代表更大量的生物系统。样品可以是活检物、组织样品、液体活检物如血液、血浆、尿液、脑脊液或生物系统的经加工部分或先前部分,诸如通过离心加工血液而获得的血浆或作为经加工的组织的ffpe组织。这样的生物样品将总是含有不同的分子,例如dna、rna、蛋白质、代谢物和/或脂质。
23、生物分子=存在于活生物体中的任何种类的分子,诸如蛋白质、肽、脂质、代谢物、碳水化合物、这些的修饰
24、反之亦然使用消化和裂解
25、反之亦然使用血液、血浆、血清及其所有相关基质
26、特征:在ms中测量的离子,与其标识无关(然而:优选与碎片信息相关)
27、元数据=所有可用数据;例如,临床化学分析、人体测量学、关于伦理起源的信息、基因组数据、转录组数据、蛋白质组数据
28、ptm=翻译后修饰,诸如磷酸化、糖基化、糖化、泛素化、s-亚硝基化、甲基化、n-乙酰化、苏素化(sumoylation)和/或脂化
29、m/z=质荷比
30、ms-完整性代码=质谱完整性代码。可由质谱系统分析的一种或多种预先确定的样品特征。ms完整性代码可包括质谱仪数据和/或其它预先确定的样品特征。
31、ai=人工智能、机器学习、深度学习
技术实现思路
1、根据本发明的第一方面,提供了一种质谱系统,所述质谱系统包括:质谱设备,所述质谱设备被配置为提供生物样品的质谱数据;和完整性模块,所述完整性模块被配置为:加工生物样品的质谱数据以确定所述生物样品的确定的样品特征作为所述生物样品的完整性数据,其中所述完整性数据包括关于样品的已知来源或损坏来源的信息、关于样品身份丢失的信息、关于样品加工中的问题的信息、关于样品降解的信息;以及输出所述生物样品的完整性数据。
2、完整性数据可包括关于样品的已知来源或损坏来源的信息、关于样品身份丢失的信息、关于样品加工中的问题的信息和/或关于样品降解的信息。
3、在此上下文中,完整性数据还可包括报告样品的身份和/或来源并且可通过质谱仪分析获取或确认的样品特征。样品特征可包括关于样品的身份和/或来源的信息。这样的完整性数据可允许在样品加工工作流程期间追踪样品和/或确定样品在物理量具(physical metrics)(例如96或384阵列和/或实验室器具或)中的布置。完整性数据可包括关于性别相关蛋白的数据,例如pzp和/或shbg。结合样品所获自的人的性别,完整性数据可用于确定不同样品是否源自具有不同性别的人的样品。评估样品的身份和/或来源的准确性可通过包括进一步完整性数据,诸如质谱法获取的信息,诸如源自变体肽的等位基因信息或特定于个体的蛋白质水平来提高。
4、在此上下文中,完整性数据还可包括样品特征,例如,确定的或预先确定的样品特征,其可报告样品的质量,所述样品的质量可能在样品收集期间受到损害,例如错误的离心力或血液样品加工时间。这样的质谱数据可报告:报告红细胞裂解的蛋白质水平,诸如碳酸酐酶的水平;或报告血小板污染物的蛋白质水平,诸如血小板碱性蛋白的水平。
5、在此上下文中,完整性模块可被配置为加工生物样品的质谱数据以确定生物样品的(预先)确定的样品特征作为所述生物样品的完整性数据并且输出所述生物样品的完整性数据。完整性模块可包括计算机系统。
6、完整性数据可包括确定的样品特征。完整性数据可包括预先确定的样品特征。确定的和/或预先确定的样品特征可通过质谱设备进行测量。完整性数据可包括确定的样品特征和预先确定的样品特征的相似性的指示。
7、完整性数据可包括确定的样品特征与预先确定的样品特征之间的关系的指示。
8、完整性数据可用于鉴定样品的来源、用于追踪过程中的样品、用于确定两个或更多个样品的相似性、用于确定两个或更多个个体的相似性、用于进行一个个体的样品之间和/或个体之间的相似性确定、用于排除两个或更多个样品的相似性、用于确定两个或更多个样品之间的相异性、用于确定两个或更多个个体的相异性,以及/或者用于确定两个样品是否来自同一组织来源,例如在血浆被分析两次而不是一次血浆和一次尿液的情况下。
9、完整性数据可包括关于定量的蛋白质和/或定量的肽和/或翻译后修饰和/或等位基因和/或变体肽的信息。
10、根据本发明的第二方面,提供了一种质谱系统,所述质谱系统包括:质谱设备,所述质谱设备被配置为提供生物样品的质谱数据;和计算机系统,所述计算机系统被配置为:加工生物样品的质谱数据以确定所述生物样品的确定的样品特征作为所述生物样品的完整性数据;以及输出所述生物样品的完整性数据。
11、通常,在此上下文中的表述“确定”应理解为意指获取定性和/或定量数据。表述“预先确定的样品特征”是样品或其生物来源的特征。预先确定的样品特征可在用于确认样品完整性的质谱分析之前或之后限定或确定。预先确定的样品特征是质谱系统的数据与之进行比较的信息。完整性数据可包括确定的样品特征。确定的样品特征可通过质谱设备进行测量。完整性数据可包括确定的样品特征和预先确定的样品特征的相似性的指示。
12、相似性通常可被定义为定量两个数据集之间的相似性的相似性量度,这意味着它们可对相似的数据集取大值,而对不相似的数据集取小值或负值。相似性可根据实际相似性(例如,皮尔逊相关性或余弦相似性)或距离度量的倒数(例如,曼哈顿或欧几里德距离)来定义。在此上下文中,我们将数据集定义为在超过固定的相似性阈值时重叠。此外,我们可将多个相似的测量值组合到单个参考中,在所述参考中比较各个数据集。所比较的数据集可含有预先确定的样品特征和/或质谱确定的样品特征。在此,可使用预先确定的样品特征来推断预期的质谱数据并提高相似性检查的灵敏度。
13、根据上文定义的相似性也可在分类数据与数值数据之间计算,例如在计算相似性之前将分类数据转换为数值数据并进行缩放时。在此,可使用参考值或参考测量值来转换或缩放数据。因此,当将等位基因转化为向量并计算距离时,可为等位基因的重叠分配相似性度量。例如,如果检测到高水平的妊娠带蛋白(pzp),则女性性别可表示为相似性。
14、完整性数据可包括确定的样品特征与预先确定的样品特征之间的关系的指示。
15、有利的是,质谱法可读出大量生物分子,从而提供大量的数据,这些数据描述了从中生成数据的样品。质谱系统甚至可通过单次测量提供数据,并且可通过多次测量提供甚至更高的生物分子覆盖率以提供生物样品的数据。所生成的生物分子数据可应用于通过将质谱法生成的数据与一个或多个预先确定的样品特征进行比较来评估生物样品的完整性。此数据可被视为反映样品完整性的代码,并且此代码可被质谱系统读取。因此,该代码被称为质谱完整性代码或ms完整性代码。质谱系统可进一步提供可从非质谱生成的数据评价预先定义的ms完整性代码的数据。这是可能的,因为可通过ms分析生成大量关于生物分子的信息。这种非ms数据包括但不限于有关性别、年龄、免疫测定测量值、其它实验室医学分析或个体基因组的数据。有利地,可针对样品来源通过质谱法来评估生物样品的完整性,例如以追踪样品、以将信息与样品进行匹配、以将一个或多个样品与不同的个体进行匹配、以将一个或多个样品彼此进行匹配、以将一个或多个样品与不同的临床参数进行匹配、以鉴定个体、以确定两个或更多个样品的相似性、以确认或排除两个或更多个样品的密切相似性、以确定两个或更多个样品是否来自同一类型的样品(例如血浆与尿液;肝脏与肌肉)、以检测由被另一个样品污染引起的样品完整性的改变、以检测由样品质量问题(例如由于样品加工或储存所致的问题)引起的样品完整性的改变、以检测由质谱系统的问题引起的样品完整性的改变。有利地,还可应用对一个或多个样品的样品完整性的分析来确定样品在诸如96或384阵列和/或实验室器具的物理量具中的布局和/或布置。
16、质谱系统还可包括用于质谱分析的样品制备方法、不与质谱仪耦合的预分离方法、与质谱仪耦合的预分离方法。ms完整性代码还可含有关于这些技术组件的性能的信息,诸如成功的样品制备、分离方法的正确功能或生物分子的正确电离。
17、计算机系统可包括以下单元中的一个或多个:用于基于预先确定的样品特征生成ms完整性代码的单元;用于从反映ms完整性代码的样品特征的质谱仪分析生成数据的单元;用于生成ms完整性代码中的预先确定的样品特征与质谱数据之间的相似性度量的单元;用于比较ms完整性代码和质谱数据以鉴定样品的单元;用于比较ms完整性代码和质谱数据以进行样品的质量评估的单元;用于比较ms完整性代码和质谱数据以检测样品污染的单元;用于比较ms完整性代码和质谱数据以控制样品采集和加工的单元;用于鉴定样品的单元;用于样品的质量评估的单元;用于样品加工的质量评估的单元。计算机系统被配置为加工质谱数据以直接和/或间接地鉴定生物样品的预先确定的特征作为生物样品的完整性数据。这是因为一些特征可直接测量,诸如蛋白质水平,而另一些特征(诸如性别)只能通过指示性别的蛋白质间接测量。诸如hdl水平的其它因素可与血浆中的蛋白质相关。
18、任选地,除了自下而上的蛋白质组学之外,还可应用自上而下的和天然蛋白质组学来检查样品完整性。自上而下/天然蛋白质组学的优点在于,在质谱分析之前无需将蛋白质消化成肽。
19、根据本发明的第三方面,提供了一种方法,优选计算机化方法,以用于根据质谱数据提供生物样品完整性的指示,所述计算机化方法包括:加工生物样品的质谱数据以确定所述生物样品的确定的样品特征作为所述生物样品的完整性数据;以及输出所述生物样品的完整性数据。
20、任选地,完整性数据包括确定的样品特征和/或生物样品的确定的样品特征与预先确定的样品特征的相似性的指示。完整性数据可包括确定的样品特征。另外或可替代地,完整性数据可包括生物样品的确定的样品特征与预先确定的样品特征的相似性的指示。
21、任选地,生物样品是人类生物样品,并且/或者生物样品包括血液、血浆、血清、尿液、脑脊液、唾液、泪液、粪便、胃液、组织、新鲜组织、经固定的组织(例如,福尔马林固定的石蜡包埋的组织)、经加工的组织、活检物、液体活检物、毛发和/或骨骼中的一者或多者。生物样品可以是人类生物样品。生物样品可包含人类生物样品。另外或可替代地,生物样品包括血液、血浆、血清、尿液、脑脊液、唾液、泪液、粪便、胃液、组织、新鲜组织、经固定的组织(例如,福尔马林固定的石蜡包埋的组织)、经加工的组织、活检物、液体活检物、毛发和/或骨骼中的一者或多者。优选地,生物样品包括血液、血浆、血清、尿液、脑脊液(csf)、唾液、泪液、粪便、胃液、经加工的液体样品(诸如从最高丰度蛋白质中耗竭的血浆或血清或在富集诸如低丰度蛋白质的亚群后的血浆)、组织(新鲜、冷冻、经包埋如ffpe)、经加工的组织、活检物、液体活检物、毛发和/或骨骼中的一者或多者。有利地,生物样品含有大量的生物分子,诸如蛋白质、肽、脂质、代谢物、药物、dna和rna,它们可通过质谱系统读出。任选地,可使用一种或多种样品。任选地,这些生物分子可与与其它样品特征(诸如人体测量数据、疾病状态或性别)相关并且/或者这些生物分子可被关联到其它样品特征(诸如人体测量数据、疾病状态或性别)。
22、任选地,预先确定的样品特征可以是具有选自质量、电荷、质荷比、碎片光谱、ms2碎片信息、离子迁移率、强度信息、保留时间、序列(在蛋白质/肽的情况下)或其它身份(在脂质/代谢物的情况下)中的一者或多者的特定特征的离子。任选地,预先确定的样品特征可以是多个离子或离子的组合。预先确定的样品特征也可以是序列或结构信息。任选地,可使用一种或多种样品特征。有利地,质量、电荷、质荷比、碎片信息、ms2碎片信息、离子迁移率、强度信息、保留时间、序列(在蛋白质/肽的情况下)或其它身份(在脂质/代谢物的情况下)可直接使用而无需先前的数据库搜索或数据的从头解释,并且可直接用于生成ms完整性代码以及用于样品完整性分析。
23、任选地,预先确定的样品特征是一种或多种肽或蛋白质,优选一种或多种定量的肽或蛋白质。有利地,定量的蛋白质提供可用于ms完整性代码中和可用于检查样品的完整性的数值。定量的肽或蛋白质的数值可经受使用定量数据的所有数学计算(诸如统计方法和人工智能方法),从而允许应用广泛的数据分析方法。这对于生成可计算的ms完整性代码以及将不同样品相互比较也是有利的。
24、任选地,被配置为加工质谱数据以增强质谱数据的计算机使用聚类算法来基于样品的相似性对样品进行分组。在此,许多距离度量可用作相似性的基础。例如,距离可被定义为所定义的蛋白质子集的定量差异。另外,在使用n维距离时可采用不同的距离范式。考虑在二维情况下使用曼哈顿距离或欧几里德距离的情况(例如,两个不同蛋白质子集的定量差异):当使用欧几里德距离时,与仅在一个子集上具有相同大小的距离进行比较时,两个蛋白质子集的偏差会比使用曼哈顿距离时产生更小的差异。额外的度量来自相关性,例如在计算两个向量之间的皮尔逊相关性时。在计算样品相似性之前,可对样品进行归一化、缩放和比对。可使用最先进的聚类算法(诸如层次聚类、基于密度的聚类和k均值聚类)对数据进行聚类。
25、任选地,蛋白质选自以下中的一者或多者:妊娠带蛋白(pzp)、性激素结合球蛋白(shbg)、载脂蛋白(a)(lpa)、其它载脂蛋白(apoa1、apob、apoa2、apoa4、apoc1、apoc3、apoc4、apoc2、apod、apoe)、免疫球蛋白链、血红蛋白亚基(hba1、hbb、hbd、hbg1、hbe、hbz)、碳酸酐酶(ca1、ca2)、过氧化物还原酶(prdx2、prdx6)、过氧化氢酶(cat)、带3阴离子转运蛋白(slc4a1)、血影蛋白链(spta1、sptb)、锚蛋白-1(ank1)、甘油醛-3-磷酸脱氢酶(gapdh)、超氧化物歧化酶(sod1)、二磷酸甘油酸变位酶(bpgm)、肌动蛋白(actb、actg1、acta1、actc1)、硒结合蛋白1(selenbp1)、蛋白4.1(epb41)、l-乳酸脱氢酶b链(ldhb)、西丝蛋白-a(flna)、踝蛋白-1(tln1)、肌球蛋白-9(myh9)、肌动蛋白(actb)、粘着斑蛋白(vcl)、α-辅肌动蛋白-1(actn1)、原肌球蛋白α-4链(tpm3)、血小板反应蛋白-1(thbs1)、血小板反应蛋白-4(thbs4)、微管蛋白(tubb1、tubb4b)、14-3-3蛋白ζ/δ(ywhaz)、凝溶胶蛋白(gsn)、微管蛋白α-1b链(tuba1b)、整联蛋白(itga2b)、凝血因子(f13a1、f2、f5、f7、f9、f10、f11、f12)、抑制蛋白-1(pfn1)、转胶蛋白-2(tagln2)、fermitin家族同源物3(fermt3)、ras相关蛋白(rap1b)、普列克底物蛋白(pleckstrin)(pleck)血小板碱性蛋白(ppbp)、纤维蛋白原链(fga、fgg、fgb)、抗凝血酶-iii(serpinc1)、凝血酶原(f2)、血小板糖蛋白ibα链(gp1ba)、血小板因子4(pf4、pf4v1)、细胞外基质蛋白1(ecm1)、簇集素(clu)、桥粒斑蛋白(dsp)、含wd重复蛋白1(wdr1)、引诱素(atrn)、血小板糖蛋白v(gp5)、血浆丝氨酸蛋白酶抑制剂(serpina5)、补体c1r亚组分样蛋白(c1rl)、甘露糖基-寡糖1,2-α-甘露糖苷酶ia(man1a1)、激肽原1(kng1)、胆碱酯酶(bche)、多聚免疫球蛋白受体(pigr)、角蛋白(krt1、krt10、krt17、krt2、krt28、krt9)、果糖-二磷酸醛缩酶(aldoa、aldob)、c-反应蛋白(crp)、血清淀粉样蛋白a蛋白(saa1、saa2、saa4)、对妊娠特异的妊娠特异性β-1-糖蛋白1(psg1)、妊娠特异性β-1-糖蛋白9(psg9)、肌动蛋白相关蛋白2(actr2)、前层蛋白(prelamin)a/c(lmna)、胞裂蛋白(septin)-9(septn9)、肽基-脯氨酰基顺式-反式异构酶(fkbp2)、v型质子atp酶亚基b、脑同种型(atp6v1b2)。任选地,蛋白质可以是蛋白质同种型。
26、优选地,蛋白质选自pzp、lpa、apoe、hba1、flna、fga、krt9、crp、psg1、actr2。这是因为pzp水平适合于区分女性和男性。lpa水平是高度特定于个体的。apoe存在于ldl颗粒中并且具有可分析的遗传组分。定量的hba1是红细胞裂解、样品收集和/或加工问题的标志物。定量的flna和tln1是血小板污染、样品收集和/或加工问题的标志物。定量的fga是部分凝血事件、样品收集和/或加工问题的指标,并且fga可进一步区分血浆和血清。高水平的krt9是人类操纵样品时对样品的污染的指标。crp水平可确定慢性炎症。psg1是在妊娠期间强烈增加的蛋白质。actr2是在从尿液样品中获得的细胞沉淀物中增加的蛋白质,从而允许检测尿液样品的污染。
27、任选地,预先确定的样品特征是定量的肽。有利地,生物肽是可通过ms分析的另外一类分子。此外,作为更直接的测量,可在不定量蛋白质的情况下分析从蛋白质产生的裂解肽。
28、任选地,预先确定的样品特征是翻译后修饰,优选地是定量的翻译后修饰。翻译后修饰可以是磷酸化、糖基化、糖化、泛素化、s-亚硝基化、甲基化、n-乙酰化、苏素化和/或脂化。有利地,翻译后修饰可报告各种生物学特征。糖基化可报告不同蛋白质的生物活性。糖化可报告糖尿病中存在的高血糖水平。磷酸化可报告蛋白质的活性,因为磷酸化是用于激活信号级联的主要蛋白质之一。
29、任选地,预先确定的样品特征是等位基因和/或变体肽。有利地,质谱法还可获取基因组信息。如果dna变体在氨基酸组成改变的蛋白质变体中被翻译,则等位基因可以反映在蛋白质水平上。此类蛋白质变体可用于鉴定不同个体的样品,并且因此用于检查生物样品的完整性。有利地,此类信息可能已经可从个体或样品的基因组学或转录组学数据中获得。在此类情况下,不需要先前的ms测量来生成ms完整性代码。肽变体分析的另外一个优点是可跨不同的样品类型应用完整性检查。可生成ms完整性代码,并且可将蛋白质的等位基因组合与任何其它含蛋白质的样品(诸如肌肉组织)进行比较。
30、任选地,等位基因选自用基因名称列出的以下基因中的一者或多者:lpa、pon1、gc、apob、apoe、agt、a1bg、a2m、abcc2、actb、actc1、acta1、acta2、actg2、adipoq、afm、afp、ahnak、ahsg、alb、aldh1a1、apoa4、apoh、apol1、c3、hel-s-62p、c4a、c7、cp、cpn2、f5、fgg、dkfzp779n0926、hba1、hbb、hbd、hp、lbp、pglyrp2、serpina1、serpinf1、serpinf2、f10、f11、f12、f13b、f2、f7、f9、serping1、tf、ttr、hel111、aldh1a3、aldoa、aldob、ambp、angptl3、anpep、apcs、apeh、apmap、apoa1、apoa2、apoc1、apoc3、apoc4、apoc4-apoc2、apoc2、apod、apof、apom、arhgap1、arsb、atp1a4、atp6v1a、atrn、atrnl1、azgp1、b2m、bche、blk、blvrb、btd、c15orf41、c1qa、c1qb、c1qc、c1r、c1rl、c1s、c2、c3、c4b、c4bpa、c4bpb、c5、c6、c8a、c8b、c8g、c9、ca1、ca2、cabin1、cald1、calm1、calm2、calm3、calr、card9、card11、cat、cd14、cd163、cd44、cd5l、cdh5、cdhr2、cep164、cfb、cfd、cfh、cfhr3、cfhr4、cfi、cfl1、chga、chi3l1、chit1、chrnb1、ckm、clec3b、cltc、cltcl1、clu、cndp1、cntn3、col18a1、col6a3、colec11、cope、cpb2、cpn1、cps1、crisp3、crp、crtac1、cryab、cryz、csh2、csh1、cst3、ctsa、ctsd、cubn、dbh、ecm1、eif4a1、eno1、erlin1、ern1、etfa、exoc1、fabp4、fah、fam153a、fam162a、fbln1、fcgbp、fcgr3a、fcn2、fcn3、fetub、fga、fgb、fgfr2、fgg、fgl1、fitm1、fkbp4、flii、flot2、fn1、gapdh、gba、gca、gdi2、ggh、glud1、glud2、gp1ba、gpc6、gpld1、gprc5c、gpx3、gsn、gstm4、habp2、hadh、hars、hbg2、hexa、hgfac、hist1h4a、hla-a、hla-h、hla-c、hpr、hpx、hrg、hsp90aa1、hsp90b1、hspa5、hspa8、hspg2、icam1、icam2、igfals、igfbp3、igfbp6、il1rap、ints4、itih1、itih2、itih3、itih4、kctd12、kiaa0319l、klkb1、kng1、kpnb1、krt24、lamb2、lcat、lcn2、lcp1、ldha、ldhb、lgals3bp、lilrb1、lilra1、loc93432、lrg1、lrp2、ltf、lum、lyve1、lyz、manba、marcks、masp1、masp2、mb、mbl2、mei1、mia3、mmp9、mmrn1、mpo、mst1、mst1l、muc4、myh11、myh14、myo1a、myo1b、myo1d、ncf4、nckipsd、neo1、nin、nrp2、orm1、orm2、pc、pcca、pcdha8、pcolce、pcyox1、pdia4、pebp1、pf4v1、pf4、pfn1、pi16、pigr、plcd1、plcg2、plec、plg、pls1、pltp、pon3、ppa1、ppbp、ppia、ppil1、prap1、prcc、prdx2、prg2、prg4、proc、procr、pros1、proz、prss2、psg1、psmb1、psmc6、psmd2、ptgds、ptprf、pus10、pzp、qsox1、rab21、ran、ranbp2、rbp1、rbp4、reck、reg1a、rnase4、rnf111、rpl10、s100a9、saa1、saa2、saa4、sdc1、sell、sepp1、serpina10、serpina3、serpina4、serpina5、serpina6、serpina7、serpinb6、serpinc1、serpind1、sftpb、shbg、slc12a3、slc3a2、snca、sod3、spp1、spta1、sptan1、sptb、srgn、stxbp5l、sumo2、sumo3、sumo4、tagln2、tcp1、tfrc、tgfbi、thbs1、timp1、tmsb10、tmsb4x、tnc、tnxb、tor3a、trhde、ttn、ttr、txn、ubc、ubb、rps27a、uba52、ubbp4、uchl3、ugt8、vasn、vcam1、vnn1、vsig4、vtn、vwf、ywhae、znf256、znf652,优选lpa、pon1、gc、apob、apoe、agt、a1bg、a2m、abcc2、actb、actc1、acta1、acta2、actg2、adipoq、afm、afp、ahnak、ahsg、alb、aldh1a1、apoa4、apoh、apol1、c3、hel-s-62p、c4a、c7、cp、cpn2、f5、fgg、dkfzp779n0926、hba1、hbb、hbd、hp、lbp、pglyrp2、serpina1、serpinf1、serpinf2、f10、f11、f12、f13b、f2、f7、f9、serping1、tf、ttr、hel111、aldh1a3、aldoa、aldob、ambp、angptl3、anpep、apcs、apeh、apmap、apoa1、apoa2,更优选lpa、pon1、gc、apob、apoe、agt、a1bg、a2m、adipoq、afm、alb、apoa4、apol1、c3、cp、cpn2、f5、fgg,更优选lpa、pon1、gc、apob、apoe、agt、a1bg、a2m、adipoq、afm。有利地,以上清单的基因名称涉及在血浆中高度丰富的蛋白质。由于这些蛋白质在血浆中高度丰富,因此随着血液流经我们所有的器官,这些蛋白质也是其它组织中的常见部分,并且通常可跨人类和动物样品分析使用。另外,可在血浆中发现所列基因的肽变体。
31、任选地,预先确定的样品特征包括生物分子诸如脂质,小分子诸如药物或代谢物,碳水化合物,优选定量的生物分子。有利的是,质谱法可鉴定和定量其它生物分子,并且这些生物分子具有供应正交水平的生物分子类别的优点,该生物分子类别可用于生成ms完整性代码并且可用于通过质谱系统评估样品的完整性。
32、任选地,预先确定的样品特征是未具体鉴定的离子,和/或未鉴定的离子和/或原始数据和/或其它质谱仪获取的数据。有利地,对于此类特征,不需要大量的预加工来生成可解释的数据以生成ms完整性代码和评估样品的完整性。
33、任选地,预先确定的样品特征包括人体测量数据,例如样品的来源的身高、体重、bmi。有利地,这样的数据常常对于个体是可用的并且可在没有ms测量的情况下生成ms完整性代码。可应用质谱分析来评估已经通过样品来源的人体测量特征预先建立的ms完整性代码。例如,不同的生物分子将与个人的bmi相关。可确认关于个体或样品的另一层参数并与质谱分析进行比较。
34、任选地,预先确定的样品特征包括医学相关信息,诸如临床分析,例如hdl,ldl,胆固醇,c-反应蛋白(crp),血红蛋白(hb),红细胞(rbc),白细胞(wbc)计数,淋巴细胞计数,嗜中性粒细胞计数,血小板计数(plt),平均血小板体积(mpv),血小板分布宽度(pdw),红细胞沉降率(esr),有关健康或疾病状态、遗传病症和/或药物治疗的信息。有利地,这样的数据常常对于个体是可用的并且可在没有ms测量的情况下生成ms完整性代码。可应用质谱分析来确认已经通过这样的样品特征预先建立的ms完整性代码。例如,诸如免疫测定的临床化学方法可分析生物分子,该生物分子也可通过质谱系统进行定量。另外,临床化学部门未直接测量的一些参数将与通过质谱系统定量的生物分子相关。
35、任选地,预先确定的样品特征包括关于性别、妊娠、种族的信息。有利地,这样的数据常常对于个体是可用的并且可在没有ms分析的情况下生成ms完整性代码。可应用质谱分析来确认已经通过这样的样品特征预先建立的ms完整性代码。例如,不同蛋白质(诸如psg1)的水平将指示妊娠,而其它蛋白质(诸如pzp)将指示性别。
36、任选地,预先确定的样品特征是关于个体的元数据的信息,诸如来自转录组学、基因组学或代谢组学分析的信息。有利地,这样的数据常常对于个体是可用的并且可在没有ms分析的情况下生成ms完整性代码。可应用质谱分析来确认已经通过这样的样品特征预先建立的ms完整性代码。
37、根据本发明的第四方面,提供了一种用于控制上述任何方法的计算机程序。
38、根据本发明的第五方面,提供了一种计算机可读介质,所述计算机可读介质包括用于控制上述任何方法的指令。
39、根据本发明的第六方面,提供了一种用于加工质谱数据的计算机系统,所述计算机系统被配置为加工所述质谱数据以确定生物样品的样品特征。用于加工质谱数据的计算机系统可生成通过质谱系统分析的样品与来自通过质谱分析的样品的预先确定的样品特征和/或另一非质谱生成的样品特征之间的相似性度量;并输出所述生物样品的完整性的指示。
40、根据本发明的第七方面,提供了质谱数据用于评估生物样品的完整性的用途。任选地,所述用途可包括以下用途中的一种或多种:追踪样品,确定样品的生物来源,检测由被另一样品污染引起的ms完整性代码的改变,检测由样品加工问题(例如红细胞裂解、样品储存问题、ms-工作流程中的问题)引起的ms完整性代码的改变,将信息与样品进行匹配,将一个或多个样品与不同的人进行匹配,将一个或多个样品彼此进行匹配,将一个或多个样品与不同的临床参数进行匹配,鉴定个体,确定两个或更多个样品的相似性,确定两个或多个个体的相似性,允许进行一个个体的样品之间以及个体之间的相似性确定,排除两个或更多个样品的相似性,确定两个或更多个样品之间的相异性,确定两个或更多个个体的相异性,和/或确定两个样品是否来自同一组织来源,例如如果分析两次血浆而不是一次血浆和一次尿液。
41、根据本发明的第八方面,提供了一种机器可读代码,诸如矩阵代码(例如,条形码和/或qr代码)。机器可读代码对预先确定的样品特征(诸如蛋白质水平、等位基因信息、样品污染指标、关于性别的信息)进行编码,并且是直接反映ms完整性代码的机器可读代码。优选地,机器可读代码是物理标记,例如用于附接至样品容器和/或管上的标签。任选地,机器可读代码用于鉴定样品和/或其来源。有利地,附接至样品容器的物理代码直接传送物理链接至样品的机器可读信息。质谱系统可生成完整性数据,可将所述完整性数据与物理代码中的样品特征进行比较。有利地,这允许确认可疑样品是否在带有标签的容器中。
42、根据本发明的第九方面,提供了预先确定的样品特征和被配置为提供质谱仪数据的质谱系统的用途,其中所述用途是用于密码术(cryptography)中。在ms完整性代码中使用预先确定的样品特征可被应用于提供信息的加密操纵,并且提供质谱仪数据的质谱系统可被应用于解密信息。有利地,用于解密信息的密钥从其预先确定的样品特征已被用于ms完整性代码的相同生物起源/个体的样品提供。有利地,这将允许特定于个体的密码术过程。有利地,这允许创建安全的样品分析平台,其中只有正确获取的样品数据才能用于基于ms完整性代码中的预先确定的样品特征正确地解密代码。此外,这样的设置不仅可直接应用于具有安全的样品分析平台,而且还可被应用作访问患者的健康相关信息的密钥。
43、任选地,所述用途可以是预先确定的样品特征用于加密数据以提供经加密数据和被配置为提供质谱仪数据的质谱系统用于解密所述经加密数据的用途。
44、任选地,可使用化学修饰来生成ms完整性代码的特定签名。有利地,可在质谱仪样品制备工作流程中将化学修饰添加至生物分子,从而允许生物分子的进一步变化。有利地,可添加可链接至特定额外信息的特定签名,例如实验室特定签名。
45、任选地,在密码术中使用ms完整性代码可被应用于加密医疗保健系统中的数据。
- 还没有人留言评论。精彩留言会获得点赞!