一种新型筛选压力性损伤危险因素的模型构建评价方法及其应用
1.本发明涉及医疗技术领域,尤其涉及一种新型筛选压力性损伤危险因素的模型构建评价方法及其应用。
背景技术:
2.压力性损伤(pressure injury,pi)曾被称为褥疮、压疮或压力性溃疡(pressure ulcer,pu),2016年美国压力性损伤委员会正式更名为压力性损伤,是指发生在皮肤和(或)皮下组织的局限性损伤,通常发生在骨隆突部位或皮肤与医疗器械接触的部位,可表现为完整的皮肤或开放性的溃疡,同时可伴有疼痛感,压力性损伤已被认为是严重的医院不良事件,其发生不但与许多不良结果相关,如感染、慢性炎症状态引起的系统性淀粉样变性、长期压力和缺血引起的横纹肌溶解等,还降低了患者生活质量、延长患者住院时长,增加医疗系统的费用负担。
3.医院获得性压力性损伤(hospital acquired pressure injury,hapi)是指在医院获得的压力性损伤。压力性损伤一直以来都是全球医疗卫生机构所面临的重大健康问题,全球压力性损伤患病率为12.8%,医院获得性压力性损伤患病率为8.4%,占压力性损伤的62%,北美地区医院获得性压力性损伤发生率为12.6%-14.5%,欧洲为12.6%-16.5%,澳大利亚为3%-50%,亚洲地区为2.1%-31.3%,我国住院患者压力性损伤现患率为1.67%,医院获得性压力性损伤现患率为0.68%,发病率为1.26%。压力性损伤的发生不仅增加患者痛苦,降低其生活质量,延长住院时间,还增加了护理人员额外的护理工作量,提高了医疗费用,增加了医疗卫生系统的负担。英国某研究显示,随着压力性损伤严重程度增加,治疗费用亦随着增加,第1期的压力性损伤约为1214英镑,第4期的费用为14108英镑。美国每年治疗医院获得性压力性损伤的费用十年前为110亿美元,现今预计约要268亿美元,3期和4期患者的治疗费用占全部费用的56%,每位患者治疗医院获得性压力性损伤的费用约为10708美元。
4.重症监护室(intensive care unit,icu)患者常因病情危重,长期卧床及处于镇静状态,营养状况较差,并可能伴有糖尿病、感染、心血管疾病等多种合并症,使其压力性损伤的发生率远高于其他科室的普通住院患者。chaboyer等对icu患者发生率和患病率进行meta分析,结果显示icu患者发生压力性损伤的患病率为10.0%-25.9%,发生率为16.9%-23.8%。coyer等利用二级数据分析发现,除压力性损伤第一阶段外,2012年至2014年,重症监护室患者的医院获得性压力性损伤患病率为11%,非重症监护患者为3%,重症监护室患者住院期间发生压力性损伤的概率是非重症监护患者的3.8倍。蒋琪霞等的一项多中心调查研究结果显示,内科病房的压力性损伤现患率为1.4%,外科病房的压力性损伤现患率为0.8%,老年科的压力性损伤现患率为3.3%,重症监护室患者压力性损伤的现患率(11.9%)在所有科室中最高。对患者进行压力性损伤发生的风险进行评估和预测,及时采取措施进行早期干预不仅可以预防压力性损伤的发生,从而减少患者的伤害,降低患者的
住院费用,减轻医疗系统费用负担,因为预防压力性损伤的费用比治疗压力性损伤的费用低。因此,使用压力性损伤预测工具至关重要。
5.目前国内外重症监护室患者广泛使用的压力性损伤风险评估工具为braden量表,由美国的braden博士和bergs博士于1987年研制,但是有研究者提出braden量表缺少了对icu患者特有的重要危险因素的评估内容,例如镇静镇痛药的使用、医疗器械的使用等,而使其用于icu患者时预测效能不足,准确性较低,并不适用于icu患者。也有研究者对braden量表进行修改、或者与其他量表联合使用以及研制icu患者压力性损伤风险评估量表等研究,但这些研究在我国只进行小样本研究,信效度有待进一步验证,仍需进行大样本检验,联合其他量表使用起来也较繁杂。随着科技的进步和发展,全球进入大数据时代,人工智能和数据挖掘技术在医学领域得到广泛应用,如预防、保健、诊疗、影像及手术机器人等。机器学习作为人工智能的一个重要分支,在医学领域也应用广泛,如图像识别、遗传学和基因组学、智能诊疗、预测预后等方面。利用机器学习技术构建的模型在医学领域的预测预后方面展现出强大的预测性能。google brain回顾性收集了128175张视网膜图像构建了深度卷积神经网络模型,然后将该模型用于识别新的图像,结果显示该模型在识别糖尿病视网膜病变具有90.3%的灵敏度和98.1%的特异度,roc曲线下面积为0.991。kim等利用构建的机器学习模型以区分外科肺活检样本中常见的间质性肺炎与其他间质性肺疾病,结果显示在48个样品的训练集中,模型的特异度为92%,灵敏度为82%,在36个样本的测试集中,模型的特异度为95%,敏感度为59%。数据挖掘和机器学习技术已经成为现代医学发展的方向之一,其在医学领域对提高疾病诊断的准确性和护理不良事件管理中具有重大作用。
6.识别压力性损伤的危险因素并进行早期风险评估已被广泛应用,对压力性损伤的预防至关重要,本技术将对重症监护室患者发生压力性损伤的相关因素研究进展进行归纳总结,旨在帮助临床医护人员进一步识别重症监护室患者发生压力性损伤的影响因素,以及为临床护理实践和压力性损伤预测模型的构建研究提供依据。
技术实现要素:
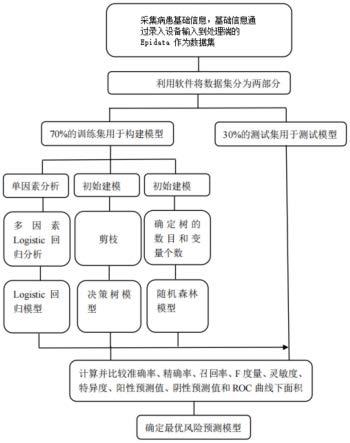
7.本发明的提供一种新型筛选压力性损伤危险因素的模型构建评价方法及其应用。
8.本发明的方案是:
9.一种新型筛选压力性损伤危险因素的模型构建评价方法,包括下列步骤:
10.1)收集资料,采集病患基础信息,病患基础信息包括自变量信息与因变量信息,将若干患者的基础信息通过录入设备输入到处理端的epidata作为数据集;
11.2)分类处理,处理端利用软件将数据集随机分为训练集与测试集,其中训练集占数据集资料的70%,剩余的为验证集;
12.3)构建模型,将所述训练集用于构建模型,处理端中的三个构建模块分别通过训练集构建logistic回归模型、决策树模型与随机森林模型;
13.4)比较检验,将测试集分别对构建logistic回归模型、决策树模型与随机森林模型进行性能比较测试;
14.5)评价比较,通过测试集将各模块进行评估,得到各模型的评价指标,然后将各模型的评价指标进行比较,提供比较后的各项优异评价指标数据。
15.所述步骤5)中评估模型的评价方法为交叉测试法,是指在一个数据集样本中,将
大部分的数据集样本用于构建模型,然后将建立好的模型用于剩余的小部分数据集样本进行预测,并求出小部分数据集样本的预报误差,记录它们的平方加和;交叉测试法的作用在于预防过拟合和欠拟合现象,得到可靠稳定的模型。常见的交叉测试法包括k-折交叉测试(k-fold cross validation,k-cv);k-折交叉测试法是指将初始数据集随机分成k个子数据集,某个单独的子数据集会被作为测试模型的数据集,其余k-1个数据集用来训练及构建模型;交叉测试重复k次,每个子数据集测试一次,最终计算这k个模型的平均评估指标。这个方法的优势在于同时重复运用随机产生的子数据集进行训练和测试,每次的结果可测试一次。k常用的取值为五和十,其中十折交叉测试是最为常用的交叉测试法。
16.所述步骤5)中的各模型的评价指标通过混淆矩阵直接获得;在二分类问题中,混淆矩阵存在以下4种结果:真正(true positive)、真负(true negative)、假正(false positive)、假负(false negative)。其中,真正表示真实类别为正,预测也是正类别;真负表示真实类别为负,预测也是负类别;假正表示真实类别为负,预测却是正类别;假负表示真实类别为正,预测却是负类别;
17.二分类问题中的混淆矩阵如下表(表1)所示:
[0018][0019][0020]
基于表1根据相应的公式可以计算出各指标的值。
[0021]
准确率(accuracy)是分类问题中最常用的度量,是预测正确的样本量与所有样本量的比值。准确率的取值在0-1之间,越大说明分类结果越好。一般来说,正确率越高,分类模型就越好。其计算公式如下:
[0022][0023]
准确率适用于多分类模型,但在非平衡集中评估效果较差。精确率(precision)是指被预测为正类别的样本中占真正的正类别样本的比例。精确率越高,说明判定为正类的样本中事实上为负类的样本越少。其计算公式如下:
[0024][0025]
召回率(recall),即灵敏度,是指实际为正类别的样本占预测也为正类别样本的比例。召回率越高,说明正类样本被错误分类的比例越小。其计算公式如下:
[0026][0027]
精确率和召回率都高是最好的,但是这两项指标是互斥的,故提出一种折衷的评价指标f度量(f-measure),又称f分数(f-score)。f度量是精确率和召回率的简单调和平均数,f度量越高,对正样本的分类效果越好,说明精确率和召回率都较好,算法的性能较好。精确率和召回率也适用于非平衡集,但不适用于多分类模型。f度量的取值范围在0到1之间,其值越高,分类模型就越有效。其公式计算如下:
[0028][0029]
其中p为精确率,r为召回率。
[0030]
受试者工作特征曲线(receiver operating characteristic curve,简称roc曲线),又称感受性曲线,用于二分类判别效果的分析与评价,是反映敏感性和特异性的综合指标,通过判断点(或临界值)的移动,获得多对灵敏度和误判率(1-特异度),以灵敏度为纵轴,以(1-特异度)为横轴,绘制成的曲线,在roc曲线上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。
[0031]
auc即roc曲线下面积,是模型优劣的评价指标,曲线下面积越大,表明准确性越高。auc的值在0~1之间,普遍认为auc越靠近1,模型的灵敏度和特异度越高,区分能力越好,模型的预测性能和准确度越高。评价标准:auc《o.5,模型无区分能力;0.5《auc《0.7,模型的预测准确度偏低;0.7《auc《0.9,模型的预测准确度中等;auc值在0.9以上表示模型的预测准确度较高。
[0032]
作为优选的技术方案,所述自变量信息为y,y为是否发生压力性损伤,将因变量的取值定为0与1,0代表否,1代表是;还包括m个自变量x,其中m≥1,所述自变量包括性别、糖尿病史、高血压史、脑卒中史、意识状态、机械通气、镇静药、镇痛药、血管升压药、年龄、braden量表评分、icu住院天数、血红蛋白、尿素氮、肌酐、乳酸与血清白蛋白,其中年龄、braden量表评分、icu住院天数、血红蛋白、尿素氮、肌酐、乳酸和血清白蛋白为连续型自变量;而性别中男=0,女=1;糖尿病史中否=0,是=1;高血压史中否=0,是=1;脑卒中史中否=0,是=1;意识状态中否=0,是=1;机械通气中否=0,是=1;镇静药中否=0,是=1;镇痛药中否=0,是=1;血管升压药中否=0,是=1。
[0033]
作为优选的技术方案,所述构建模块构建logistic回归模型为利用软件将经过单因素分析有统计学意义的自变量进行多因素logistic回归分析,再将多因素logistic回归分析结果有统计学意义的变量纳入logistic回归方程构建logistic回归模型,最后利用列线图将模型进行可视化;
[0034]
影响y取值的m个自变量分别为x1,x2,x3,
…
,xm,在m个自变量作用下y=1发生的条件概率p=p(y=1/x1,x2,x3,
…
,xm),则logistic回归方程式为:
[0035][0036]
in是logistic回归方程的符号,p是概率,θ0是常数项,θ1,θ2……
θm是回归系数。
[0037]
作为优选的技术方案,所述构建模块构建决策树模型为将全部自变量为输入,是否发生压力性损伤为输出,利用rpart程序包的rpar函数在训练集中构建决策树初始模型,后用prune函数将初始模型进行剪枝,从而得到一颗二叉决策树模型;
[0038]
决策树模型的构建主要包括建树和剪枝两个步骤,建树是指通过算法从某个数据集中学习获取规律,从而建立模型,决策树模型采用cart算法;而剪枝是指在树的主体上删除过多的或者一些不可靠的分支,从而提高决策树的预测性能。
[0039]
作为优选的技术方案,所述构建模块构建随机森林模型为将全部自变量为输入,是否发生压力性损伤为输出,利用randomforest程序包的randomforest函数在训集中构建随机森林初始模型,经过参数调优得到随机森林模型预测性能最好时的森林数目和变量选
择个数,然后利用varimpplot函数得到最佳随机森林模型变量的重要性排序;
[0040]
随机森林模型是一种包含多棵决策树的集成算法;集合多个分类器来提高模型的预测性能的方法由此产生,这就是集成学习算法,bagging和boosting是两种最常见的集成学习方法,这两者的区别在于bagging集成的方式是并行,boosting集成的方式是串行,随机森林算法是bagging集成方法里最具有代表性的一个算法。随机森林中的随机主要体现在数据的随机选择和特征的随机选取两个方面。数据的随机选择是指通过从训练的数据集中采取有放回的抽样构建数据子集并利用数据子集来构建子决策树,每个子决策树可得到一个结果,然后根据自助样本数据集组成k个分类树,形成一个组合(森林),算法的分类结果需要由组合里的每棵决策树投票决定,投票数最多的类别即为随机森林算法的预测结果。其本质是对决策树算法的改进,把多个决策树组合在了一起,每棵树的生长依靠的是独立随机选取的样本。特征在机器学习中即指变量,特征的随机选取是指随机森林中的决策子树的每一个分类过程并未用到所有的自变量,而是从所有的自变量中随机选取一定的自变量,之后再在随机选取的自变量中选取最优的自变量构建子决策树,这样能够使得随机森林中的子决策树都不同,从而提升模型的多样性,提高模型的预测性能。
[0041]
作为优选的技术方案,所述步骤5)中模拟信息包括准确率、精确率、召回率、f度量、灵敏度、特异度、阳性预测值、阴性预测值与roc曲线下面积。
[0042]
作为优选的技术方案,所述步骤1)中病患需要符合纳入标准,并且不违反排除排除标准。
[0043]
作为优选的技术方案,所述纳入标准包括年龄≥18周岁;入住icu时间>24h;所述排除标准为基础信息不完整;烧伤或者皮肤情况模糊不清,无法判定的患者;限制翻身的患者。
[0044]
本发明还公开了一种通过新型筛选压力性损伤危险因素的模型构建评价方法完善压力性损伤危险因素评估方法。
[0045]
本发明还公开了一种通过新型筛选压力性损伤危险因素的模型构建评价方法在压力性损伤预测软件开发应用。
[0046]
由于采用了上述技术方案,一种新型筛选压力性损伤危险因素的模型构建评价方法及其应用,1)收集资料,采集病患基础信息,病患基础信息包括自变量信息与因变量信息,将若干患者的基础信息通过录入设备输入到处理端的epidata作为数据集;2)分类处理,处理端利用软件将数据集随机分为训练集与测试集,其中训练集占数据集资料的70%,剩余的为验证集;3)构建模型,将所述训练集用于构建模型,处理端中的三个构建模块分别通过训练集构建logistic回归模型、决策树模型与随机森林模型;4)比较检验,将测试集分别对构建logistic回归模型、决策树模型与随机森林模型进行性能比较测试;5)评价比较,通过测试集将各模块进行评估,得到各模型的评价指标,然后将各模型的评价指标进行比较,提供比较后的各项优异评价指标数据。
[0047]
本发明的有益效果在于:
[0048]
本发明通过比较logistic回归、决策树和随机森林三种预测模型的预测性能,从而确定预测性能最优的预测模型,为之后重症监护室压力性损伤预测软件开发选择合适的模型提供依据,以提高临床预测重症监护室成人患者压力性损伤发生的准确性和便捷性,从而降低重症监护室成人患者的压力性损伤发生率,减轻患者痛苦和医疗负担;
[0049]
确认了icu住院天数是重症监护室患者压力性损伤发生的重要预测因子;为重症监护室压力性损伤预测软件开发确认了可选择随机森林模型作为预测模型。
附图说明
[0050]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0051]
图1:本发明实施例2中患者入院时的braden量表评分图;
[0052]
图2:本发明实施例2中logistic回归模型进行列线图;
[0053]
图3:本发明实施例2中决策树模型图;
[0054]
图4:本发明实施例2中森林树的数目图;
[0055]
图5:本发明实施例2中随机森林模型自变量重要性排序图;
[0056]
图6:本发明实施例2中logistic回归模型的roc曲线:图;
[0057]
图7:本发明实施例2中决策树模型的roc曲线图;
[0058]
图8:本发明实施例2中随机森林模型的roc曲线图;
[0059]
图9:本发明实施例2中logistic回归、决策树和随机森林模型的roc曲线比较图;
[0060]
图10:本发明的构建模型流程图。
具体实施方式
[0061]
为了弥补以上不足,本发明提供了一种新型筛选压力性损伤危险因素的模型构建评价方法及其应用以解决上述背景技术中的问题。
[0062]
在本发明当中
[0063]
apache为急性生理学与慢性健康状况评估;
[0064]
dt为决策树;
[0065]
fp为假正;
[0066]
fn为假负;
[0067]
hapi为医院获得性压力性损伤;
[0068]
icu为重症监护室;
[0069]
pi为压力性损伤;
[0070]
pu为压力性溃疡;
[0071]
rf为随机森林;
[0072]
tp为真正;
[0073]
tn为true negative。
[0074]
一种新型筛选压力性损伤危险因素的模型构建评价方法,包括下列步骤:
[0075]
1)收集资料,采集病患基础信息,病患基础信息包括自变量信息与因变量信息,将若干患者的基础信息通过录入设备输入到处理端的epidata作为数据集;
[0076]
2)分类处理,处理端利用软件将数据集随机分为训练集与测试集,其中训练集占数据集资料的70%,剩余的为验证集;
[0077]
3)构建模型,将所述训练集用于构建模型,处理端中的三个构建模块分别通过训练集构建logistic回归模型、决策树模型与随机森林模型;
[0078]
4)比较检验,将测试集分别对构建logistic回归模型、决策树模型与随机森林模型进行性能比较测试;
[0079]
5)评价比较,通过测试集将各模块进行评估,得到各模型的评价指标,然后将各模型的评价指标进行比较,提供比较后的各项优异评价指标数据。
[0080]
所述自变量信息为y,y为是否发生压力性损伤,将因变量的取值定为0与1,0代表否,1代表是;还包括m个自变量x,其中m≥1,所述自变量包括性别、糖尿病史、高血压史、脑卒中史、意识状态、机械通气、镇静药、镇痛药、血管升压药、年龄、braden量表评分、icu住院天数、血红蛋白、尿素氮、肌酐、乳酸与血清白蛋白,其中年龄、braden量表评分、icu住院天数、血红蛋白、尿素氮、肌酐、乳酸和血清白蛋白为连续型自变量。
[0081]
所述构建模块构建logistic回归模型为利用软件将经过单因素分析有统计学意义的自变量进行多因素logistic回归分析,再将多因素logistic回归分析结果有统计学意义的变量纳入logistic回归方程构建logistic回归模型,最后利用列线图将模型进行可视化。
[0082]
所述构建模块构建决策树模型为将全部自变量为输入,是否发生压力性损伤为输出,利用rpart程序包的rpar函数在训练集中构建决策树初始模型,后用prune函数将初始模型进行剪枝,从而得到一颗二叉决策树模型。
[0083]
所述构建模块构建随机森林模型为将全部自变量为输入,是否发生压力性损伤为输出,利用randomforest程序包的randomforest函数在训集中构建随机森林初始模型,经过参数调优得到随机森林模型预测性能最好时的森林数目和变量选择个数,然后利用varimpplot函数得到最佳随机森林模型变量的重要性排序。
[0084]
所述步骤5)中模拟信息包括准确率、精确率、召回率、f度量、灵敏度、特异度、阳性预测值、阴性预测值与roc曲线下面积。
[0085]
所述步骤1)中病患需要符合纳入标准,并且不违反排除排除标准。
[0086]
所述纳入标准包括年龄≥18周岁;入住icu时间>24h;所述排除标准为基础信息不完整;烧伤或者皮肤情况模糊不清,无法判定的患者;限制翻身的患者。
[0087]
本发明公开了一种通过新型筛选压力性损伤危险因素的模型构建评价方法完善压力性损伤危险因素评估方法。
[0088]
本发明公开了一种新型筛选压力性损伤危险因素的模型构建评价方法在压力性损伤预测软件开发应用。
[0089]
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施例,进一步阐述本发明。
[0090]
实施例1:
[0091]
1)收集资料,采集病患基础信息,病患基础信息包括自变量信息与因变量信息,将若干患者的基础信息通过录入设备输入到处理端的epidata作为数据集;
[0092]
2)分类处理,处理端利用软件将数据集随机分为训练集与测试集,其中训练集占数据集资料的70%,剩余的为验证集;
[0093]
3)构建模型,将所述训练集用于构建模型,处理端中的三个构建模块分别通过训
练集构建logistic回归模型、决策树模型与随机森林模型;
[0094]
4)比较检验,将测试集分别对构建logistic回归模型、决策树模型与随机森林模型进行性能比较测试;
[0095]
5)评价比较,通过测试集将各模块进行评估,得到各模型的评价指标,然后将各模型的评价指标进行比较,提供比较后的各项优异评价指标数据。
[0096]
所述自变量信息为y,y为是否发生压力性损伤,将因变量的取值定为0与1,0代表否,1代表是;还包括m个自变量x,其中m≥1,所述自变量包括性别、糖尿病史、高血压史、脑卒中史、意识状态、机械通气、镇静药、镇痛药、血管升压药、年龄、braden量表评分、icu住院天数、血红蛋白、尿素氮、肌酐、乳酸与血清白蛋白,其中年龄、braden量表评分、icu住院天数、血红蛋白、尿素氮、肌酐、乳酸和血清白蛋白为连续型自变量。
[0097]
所述构建模块构建logistic回归模型为利用软件将经过单因素分析有统计学意义的自变量进行多因素logistic回归分析,再将多因素logistic回归分析结果有统计学意义的变量纳入logistic回归方程构建logistic回归模型,最后利用列线图将模型进行可视化。
[0098]
所述构建模块构建决策树模型为将全部自变量为输入,是否发生压力性损伤为输出,利用rpart程序包的rpar函数在训练集中构建决策树初始模型,后用prune函数将初始模型进行剪枝,从而得到一颗二叉决策树模型。
[0099]
所述构建模块构建随机森林模型为将全部自变量为输入,是否发生压力性损伤为输出,利用randomforest程序包的randomforest函数在训集中构建随机森林初始模型,经过参数调优得到随机森林模型预测性能最好时的森林数目和变量选择个数,然后利用varimpplot函数得到最佳随机森林模型变量的重要性排序。
[0100]
所述步骤5)中模拟信息包括准确率、精确率、召回率、f度量、灵敏度、特异度、阳性预测值、阴性预测值与roc曲线下面积。
[0101]
所述步骤1)中病患需要符合纳入标准,并且不违反排除排除标准。
[0102]
所述纳入标准包括年龄≥18周岁;入住icu时间>24h;所述排除标准为基础信息不完整;烧伤或者皮肤情况模糊不清,无法判定的患者;限制翻身的患者。
[0103]
本发明公开了一种通过新型筛选压力性损伤危险因素的模型构建评价方法完善压力性损伤危险因素评估方法。
[0104]
压力性损伤危险因素评估方法为:
[0105]
第一部分:压力性损伤危险因素临床判定法根据患者情况直接评定为压力性损伤高风险人群
[0106]
口呼吸机辅助通气
[0107]
口昏迷或完全瘫痪
[0108]
口持续镇静
[0109]
口大便或小便失禁
[0110]
第二部分:当患者不符合第一部分任何条目时,则进入第二部分进行评估,满足两项,评为中风险人群,满足一项,评为低风险人群。
[0111]
口偏瘫或截瘫
[0112]
口术程≥90min的急诊手术
[0113]
口bmi<18.5
[0114]
口血清白蛋白<35g/l
[0115]
口血红蛋白<30g/l
[0116]
第三部分:当患者不符合上诉选项时,评为无压力性损伤风险人群。
[0117]
压力性损伤预防措施:
[0118]
口使用翻身计划表
[0119]
口保证翻身频率
[0120]
口使用床面或椅面减压设备
[0121]
口最大限度的活动
[0122]
口使用溃疡贴保护受压部位
[0123]
口保持皮肤清洁,使用护肤霜,维持皮肤弱碱性
[0124]
口保证患者营养。
[0125]
实施例2:
[0126]
1研究对象
[0127]
采用便利抽样法选取温州市某综合性三甲医院2017年1月至2019年12月在重症监护室住院的成人患者作为研究对象。
[0128]
1.1纳入标准与排除标准
[0129]
1.2(1)纳入标准:
①
年龄≥18周岁;
②
入住icu时间>24h。(2)排除标准:
①
院外带入的压力性损伤;
②
住院病历及临床资料不完整;
③
烧伤或者皮肤情况模糊不清,无法判定的患者;
④
限制翻身的患者。
[0130]
1.2样本量
[0131]
发明样本量为研究因素的10-15倍,本发明将样本量定为研究因素的10倍,本发明共收集17项压力性损伤相关因素,即发生pi的患者与未发生pi的患者各需170例,考虑到资料不全等可能造成的无效评估,增加20%的样本量,一共至少需要408例。本发明在实际收集过程中,共收集到符合纳入与排除标准的重症监护室成人患者639例,满足样本量需求。
[0132]
2研究工具
[0133]
通过文献回顾确定重症监护室患者发生压力性损伤的相关因素,自行设计重症监护室成人患者压力性损伤调查表作为调查工具,调查表内容包括患者的基本信息、治疗情况、实验室检查情况等:
[0134]
(1)基本信息:性别、年龄、民族、职业、婚姻情况、文化程度、宗教信仰、入院主要诊断、糖尿病史、高血压史、脑卒中史等情况;
[0135]
(2)治疗情况:患者意识状态、是否使用机械通气、镇静药、镇痛药及血管活性药物等情况;
[0136]
(3)实验室检查项目:血红蛋白、血清白蛋白、乳酸、肌酐、尿素氮;
[0137]
(4)患者入院时的braden量表评分(图1)。
[0138]
3研究方法
[0139]
3.1资料收集
[0140]
通过查阅温州市某综合性三甲医院电子病历系统,检索其2017年1月至2019年12月在重症监护室住院的成人患者,回顾性收集符合纳入与排除标准患者的相关病历资料,
填写调查表。pi患者的意识状态、药物使用和实验室检查项目等收集其发生压力性损伤当天的资料。根据以往研究[57]发现,icu患者发生压力性损伤的平均时间为11.7天,因此本研究将收集未发生pi患者入院14天内的相关资料。重复测量结果取平均值。相关指标收集判定如下:
[0141]
(1)压力性损伤:根据2016年美国压力性损伤咨询委员会[1]更新的压力性损伤定义及分期进行判定,对于无法判定是否为压力性损伤的患者,不予纳入。(2)意识状态:本研究将患者分为意识障碍和非意识障碍。意识障碍指生物个体对自身状态和周围环境的觉察和识别能力发生障碍,包括嗜睡、昏睡、昏迷、意识模糊、谵妄等,格拉斯哥昏迷评定量表(gcs)评分低于15分,确定患者具有不同程度的意识障碍。非意识障碍患者即清醒的患者,其格拉斯哥昏迷评定量表(gcs)评分等于15分。
[0142]
(3)机械通气:指患者是否经鼻、口气管插管行机械通气、气管切开行机械通气或使用无创呼吸机。
[0143]
(4)镇静药:指患者是否使用丙泊酚、咪唑安定、米达唑仑、盐酸右美托咪定等镇静药物。
[0144]
(5)镇痛药:指患者是否使用芬太尼、瑞芬太尼、布托菲诺等镇痛药物。
[0145]
(6)血管升压药:指患者是否使用肾上腺素、去甲肾上腺素、和多巴胺等血管升压药物。
[0146]
3.2数据整理与赋值将收集到的调查表资料采用统一的标准录入epidata建立数据集。
[0147]
如下表2变量赋值表
[0148]
[0149][0150]
3.3数据预处理
[0151]
利用r软件先将分类变量进行因子转换,再将数据集按7:3的比例分成训练集和测试集两部分。
[0152]
3.4模型的构建
[0153]
3.4.1 logistic回归模型
[0154]
利用r软件将经过单因素分析有统计学意义的自变量进行多因素logistic回归分析,再将多因素logistic回归分析结果有统计学意义的变量纳入logistic回归方程构建logistic回归模型,最后利用列线图将模型进行可视化。
[0155]
3.4.2决策树模型
[0156]
以全部自变量为输入,是否发生压力性损伤为输出,利用rpart程序包的rpart函数在训练集中构建决策树初始模型,后用prune函数将初始模型进行剪枝,从而得到一颗二叉决策树。
[0157]
3.4.3随机森林模型
[0158]
以全部自变量为输入,是否发生压力性损伤为输出,利用randomforest程序包的randomforest函数在训集中构建随机森林初始模型,经过参数调优得到随机森林模型预测性能最好时的森林数目和变量选择个数,然后利用varimpplot函数得到最佳随机森林模型变量的重要性排序。
[0159]
3.5模型评价
[0160]
分别计算logistic回归模型、决策树模型和随机森林模型在测试集的准确度、精确度、召回率、f度量、灵敏度、特异度、阳性预测值、阴性预测值和roc曲线下面积,评价和比较三个预测模型的预测性能。
[0161]
4统计学方法
[0162]
使用r(3.6.3)进行数据集划分、患者一般资料描述,进行单因素分析时,将连续型自变量进行正太分布和方差齐性检验,正太分布检验采用shapiro-wilktest,方差齐性检验采用levene’s test,正太分布且方差齐的连续型变量采用t检验,非正太分布或方差不齐的连续型变量采用非参数检验,分类变量采用卡方检验,检验水准α=0.05。多因素logistic回归分析,检验水准α=0.05。利用glm函数构建logistic回归模型;利用rpart程序包中的rpart函数在训练集中构建决策树初始模型,后用prune函数将初始模型进行剪枝后得到最终决策树模型;利用randomforest程序包的randomforest函数在训练集中构建随机森林初始模型,经过参数调优得到预测性能最佳的随机森林模型的数的数目和变量的个数,最后利用varimpplot函数得到随机森林模型变量的重要性排序。利用predict函数进行模型预测,及利用proc程序包进行roc曲线的绘制。
[0163]
结果
[0164]
1研究对象的一般资料
[0165]
共计639例重症监护室成人患者纳入本研究,其中发生pi的患者219例,未发生pi的患者420例,将患者按7:3的比例随机分为训练集和测试集,其中训练集有472例患者,测试集有167例患者,训练集和测试集患者的一般资料见表3;
[0166]
表3训练集和测试集患者的一般资料情况
[0167]
[0168][0169]
2模型的构建
[0170]
2.1 logistic回归模型的构建
[0171]
2.1.1单因素分析
[0172]
将收集到的性别、糖尿病史、高血压史、脑卒中史、意识状态、机械通气、镇静药、镇痛药、血管升压药、年龄、braden量表评分、icu住院天数、血红蛋白、尿素氮、肌酐、乳酸和血清白蛋白共17个自变量经单因素分析,结果显示:braden量表评分、icu住院天数、意识状态、机械通气、镇静药、尿素氮和乳酸与压力性损伤的发生有统计学意义(p《0.05);而性别、年龄、糖尿病史、高血压史、脑卒中史、镇痛药、血管升压药、血红蛋白、肌酐和血清白蛋白与压力性损伤的发生无统计学意义(p》0.05)。单因素分析结果见表4:
[0173]
表4单因素分析
[0174][0175][0176]
注:*表示p<0.05
[0177]
2.1.2多因素logistic回归分析
[0178]
将单因素分析结果具有统计学意义的7个自变量再进行多因素logistic回归分析,结果显示:icu住院天数、意识状态、镇静药这3个变量与压力性损伤的发生有统计学意义(p<0.05),是压力性损伤发生的独立风险因素,而机械通气、braden量表评分、尿素氮、
乳酸不是压力性损伤发生的独立风险因素,多因素logistic回归分析结果见表5;
[0179]
表5压力性损伤的多因素logistic回归分析
[0180][0181]
注:*表示p<0.05
[0182]
2.1.3 logistic回归模型
[0183]
经过单因素分析和多因素logistic回归分析得到3个压力性损伤独立影响因素及其回归系数,则建立的回归方程为:
[0184]
logit(p)=in(p/1-p)=-2.490+0.981x5+0.787x7+0.083x12
[0185]
预测压力性损伤发生的概率模型为:
[0186]
p=1/(1+exp(-2.490+0.981x5+0.787x7+0.083x12))。
[0187]
2.1.4绘制列线图
[0188]
将logistic回归模型进行列线图可视化(见图2),该列线图最上面的points对应于下方预测因子的取值,total points指每个预测因子的分数加起来的总和,total points对应的最下方的概率即为预测患者发生压力性损伤的概率。
[0189]
2.2决策树模型的构建
[0190]
以全部自变量为输入,是否发生压力性损伤为输出建立初始模型,后经过剪枝留下的自变量有:icu住院天数和意识状态。图3为决策树模型,最上面的方框为根节点,下面的方框为叶节点,每一次从根节点到叶节点的一条路径即为一条分类规则,从图3可以看出,当患者在icu的住院天数小于10天,则判断该患者不发生压力性损伤,或者当患者icu住院天数大于等于10天,但患者的意识状态为非意识障碍时,则判断该患者不发生压力性损伤,否则判定该患者会发生压力性损伤。
[0191]
2.3随机森林模型的构建
[0192]
以全部自变量为输入,是否发生压力性损伤为输出建立初始模型。随机森林模型中决定模型预测能力的两个重要参数分别是树节点预选的变量个数和随机森林中树的个
数,通过参数调优,结果显示当森林树的数目(见图4)设置为96,变量选择为5个时,所建立的随机森林模型的预测性能最好,此时该模型的自变量重要程度(见图5)由高到低依次为:icu住院天数、尿素氮、血清白蛋白、肌酐、乳酸。
[0193]
3模型的评估
[0194]
3.1 logistic回归模型
[0195]
3.1.1 logistic回归模型的分类结果logistic回归模型在测试集的分类结果见表6;
[0196]
表6 logistic回归模型在测试集的分类结果
[0197][0198]
根据表6,通过公式可计算得出logistic回归模型在测试集的准确率为71.26%,精确度为61.11%,召回率为39.92%,f度量为47.83%,灵敏度为39.29%,特异度为87.39%,阳性预测值为61.11%,阴性预测值为74.05%。3.1.2logistic回归模型的roc曲线利用plot函数绘制出logistic回归模型对测试集数据进行预测的roc曲线(图6),并得到roc曲线下面积为0.757。
[0199]
3.2决策树模型
[0200]
3.2.1决策树模型在测试集的分类结果
[0201]
决策树模型在测试集的分类结果见表7;
[0202]
表7决策树模型在测试集的分类结果
[0203][0204]
根据表7,通过公式可计算得出决策树模型在测试集上的准确率为74.85%,精确度为62.50%,召回率为62.50%,f度量为62.50%,灵敏度为62.50%,特异度为81.08%,阳性预测值为62.50%,阴性预测值为81.08%。
[0205]
3.2.2决策树模型的roc曲线
[0206]
利用plot函数绘制出决策树模型对测试集数据进行预测的roc曲线(图7),并得到roc曲线下面积为0.742.
[0207]
3.3随机森林模型
[0208]
3.3.1随机森林模型在测试集的分类结果
[0209]
随机森林模型在测试集的分类结果见表8。
[0210]
表8随机森林模型在测试集的分类结果
[0211][0212]
根据表8,通过公式可计算得出随机森林模型在测试集上的准确率为75.45%,精确度为65.96%,召回率为55.36%,f度量为60.20%,灵敏度为55.36%,特异度为85.59%,阳性预测值为65.96%,阴性预测值为79.17%。3.3.2随机森林模型的roc曲线利用plot函数绘制出随机森林模型对测试集数据进行预测的roc曲线(图8),并得到roc曲线下面积为0.816。
[0213]
4模型的比较
[0214]
4.1模型在测试集的评价指标比较
[0215]
从表9可以得出,在构建的三个模型中,logistic回归模型只有最高的特异度,决策树模型具有最高的召回率、f度量、灵敏度和阴性预测值,随机森林模型具有最高的准确率、精确率和阳性预测值。
[0216]
表9 logistic回归、决策树和随机森林模型在测试集的评价指标(%)
[0217][0218]
4.2模型的roc曲线比较
[0219]
将logistic回归模型、决策树模型和随机森林模型的roc曲线绘制在同一个图上(图9),从图中可以看出红色代表的随机森林模型的roc曲线下面积最大,可以得出随机森林模型的预测性能较logistic回归模型和决策树模型好。
[0220]
讨论
[0221]
1模型的特征选择
[0222]
特征也叫属性,也就是自变量,模型构建过程中会选择对模型有意义的特征或对模型贡献较大的特性进行模型构建。logistic回归模型主要是先通过单因素分析,再经过多因素logistic回归分析筛选有意义的变量进行建模。通过多因素logistic回归分析,研究结果显示,icu住院天数、意识状态和镇静药是压力性损伤发生的独立风险因素,因此将这些变量作为logistic回归模型的预测因子。icu住院天数与压力性损伤的发生有关,分析原因是因为患者在icu住院天数越长,卧床时间就越长,机体抵抗力下降,加之约束或镇静,患者活动力和移动力减少,局部长期受压而增加了压力性损伤风险;
[0223]
决策树模型是将数据根据某种属性进行分类的过程。在建树的过程中属性的选择很重要,在分类算法中有信息增益、信息增益比、基尼(gini)指数等重要的属性。决策树基
本算法有id3算法、c4.5算法和cart算法。id3算法是利用信息增益来进行建树过程中特征选择的,用信息增益最大的特征来确定决策树的节点。本发明采用的是cart算法,cart算法即分类与回归树算法,它既可以用于分类也可以用于回归。cart算法在对决策树进行构建时,通常采用二分递归技术,对树状结构进行设置。一般情况下,数据样本集会被cart算法分成两个子样本集,这两个子集会在其内部分别构建递归决策树,且每个非叶结点也分别包含两个分枝。决策树结构生成同时也是信息递归的过程,信息通过递归形成得到两个分枝的决策树,cart算法的基本原则是平均误差值最小,属性选择的标准是gini系数值。本研究构建的决策树模型以icu住院天数和意识状态两个属性作为分类规则。
[0224]
随机森林模型的特征重要性排序主要通过袋外数据(oob)得到,计算模型的预测错误率,即袋外数据误差。本研究构建的随机森林模型的变量重要性排序前5位分别是icu住院天数、尿素氮、血清白蛋白、肌酐和乳酸。
[0225]
logistic回归模型、决策树模型以及随机森林模型都将icu住院天数作为压力性损伤发生的预测因子,且在决策树模型中icu住院天数为主要分类规则,而在随机森林模型中,icu住院天数是该模型预测最重要的预测因子,由此得出icu住院天数是icu患者压力性损伤发生的重要预测因子。
[0226]
2模型的预测性能比较
[0227]
本发明结果显示,经测试集测试,三个预测模型的准确度、精确度、召回率、f度量、灵敏度、特异度、阳性预测值和阴性预测值各有优劣,logistic回归模型只具有最高的特异度,决策树模型具有最高的召回率、f度量、灵敏度和阴性预测值,随机森林模型具有最高的准确率、精确率和阳性预测值,且模型的预测性能综合评价指标roc曲线下面积显示随机森林模型的auc较logistic回归模型和决策树模型高,根据研究结果可得出随机森林模型的预测性能优于logistic回归模型和决策树模型,因此得到模型的预测能力随机森林>逻辑回归>多元线性回归>决策树的结论。
[0228]
随机森林的预测性能较logistic回归模型和决策树模型好的结论。
[0229]
结果显示随机森林模型的预测准确性和灵敏度最高。
[0230]
3模型的优缺点
[0231]
logistic回归模型优点是简单易理解,模型的可解释性好,从变量的回归系数可以看到不同的变量对最后结果的影响,结果可利用列线图可视化,也便于临床使用。缺点是不能解决非线性问题,对多重共线性数据较为敏感,形式较简单,类似线性模型,很难去拟合数据的真实分布。
[0232]
决策树模型的cart算法的优点是在属性选择时没有对数运算,计算量不大,因此效率高,可以对缺失的数据进行处理。cart算法是将数据进行二次分类,最终生成的决策树是一颗二叉树,其结构一目了然,易于寻找分类规则,相较于logistic回归模型和随机森林模型,决策树模型的决策过程非常直观,易于理解,符合人们的决策思维,有较好的可解释性。缺点是如果类别太多,错分几率就较大,对于较小样本的数据集预测结构不稳定。
[0233]
随机森林因它良好的分类性能受到了大家的广泛关注,随机森林和其它分类算法相比较有一定的算法优势,主要表现在分类精度高、泛化误差小,算法训练速度快而且容易并行化计算等几个方面。随机森林模型的一个重要特征就是结合了bagging思想,通过随机有放回的重复抽样得到多个样本数据集,大量随机选择子样本数据集的方法平衡了样本误
差的影响,由此产生的大量数据训练出的模型结果更为可靠。其优点能够处理高维度、分类不平衡的数据,能够处理缺失值,无论对于离散型数据还是连续型数据不做要求,数据适应性较强;在随机森林模型的估计过程中,可将特征进行重要性排序。bagging算法的引入使得模型的抗噪声能力较好,提高了模型预测能力和准确度,与单颗决策树相比,降低了模型过拟合的问题。
[0234]
4人工智能和本发明预测模型在护理领域的应用前景
[0235]
可以应用于人工智能在护理领域的应用;
[0236]
还可以应用到电子病历当中,电子病历是医疗机构医务人员对门诊、住院患者或保健对象临床诊疗和指导干预所使用的信息、系统生成的文字、符号、图标、数据以及影像等数字化的医疗服务工作记录。电子病历包含大量医疗信息数据,利于二次分析。基于电子病历数据的风险预测模型能更好地帮助护理人员提前做出决策,改善患者的不良转归。目前,许多医院都无法有效利用大数据分析电子病历以生成高质量的研究及其临床实践。利用电子病历数据,挖掘潜力巨大,目前临床上的使用越来越多,风险预测模型能更加科学、有效的指导护理工作,在护理领域方面,风险预测模型的开展运用仍具有很大空间。利用机器学习构建的模型不仅预测性能好,而且可在实际应用中便捷使用。
[0237]
结论
[0238]
1.icu住院天数是重症监护室患者压力性损伤发生的重要预测因子。
[0239]
2.之后重症监护室压力性损伤预测软件开发使用本发明中的构建模型。
[0240]
创新性
[0241]
(1)针对压力性损伤高发人群重症监护室患者进行预测模型比较。
[0242]
以上显示和描述了本发明的基本原理、主要特征及本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1