一种基于联邦元学习的罕见疾病分类方法
1.本发明涉及医疗领域和联邦学习技术领域,更具体的说是涉及一种基于联邦元学习的罕见疾病分类方法。
背景技术:
2.目前,申请号为202010843441.3的专利,该方法借助元学习技术可以发现未见过疾病类别的能力来进行疾病诊断;申请号为202011107453.6的专利,该发明根据获取数据不平衡问题对模型的影响,通过对概率分布分析来对标签识别准确度进行修正,根据异常数据问题对模型的影响,提出了加密数据共享,通过对异常数据处理对各参与方或计算结点的加权系数进行修改,保证联邦学习诊断的准确性;申请号为202011633747.2的专利,该申请通过元学习算法,仅需少量训练就能够快速收敛到其最优解,初始模型就能够保证在以后相似的任务上都能够快速收敛,得到对应的结果模型,节省了计算资源,有利于系统的良性运转;论文feature-context driven federated meta-learning for rare disease prediction虽然对元学习和联邦学习进行改进,然而其动态融合策略中以准确率作为主要参数,忽略了样本类别不均衡时对模型效果造成的负面影响,其次使用模型参数较大的transformer作为基模型,在元学习框架中进行二次梯度计算时需要巨大的显存空间,降低模型通信效率,另外其使用maml框架进行采用固定的学习率进行模型训练,预测效果较为有限。
3.上述专利虽然针对不同的问题进行了一定的改进,然而对联邦学习或元学习方法的改进仍有不足,没有很好的解决罕见疾病分类不准确以及模型通信效率低的问题。
4.因此,如何提供一种能够提高罕见疾病分类准确度以及模型间通信效率的分类方法是本领域技术人员亟需解决的问题。
技术实现要素:
5.有鉴于此,本发明提供了一种基于联邦元学习的罕见疾病分类方法,通过一种基于强化分类的元学习方法,提高疾病分类准确度,有助于提高罕见疾病的识别效果;本发明提出一种动态特征融合策略,即在每个医院仅上传比全局模型f分数高的元模型,并且融合不再仅以数据量为权重,而是对模型的f分数、准确率和数据量进行动态特征融合,以保证联邦学习检测的准确性。本发明将基于强化分类的元学习方法与动态融合策略的联邦学习方法应用于联邦元学习框架,提高了罕见疾病分类准确度,有助于提高模型对于罕见疾病的诊断精度以及模型间通信效率。
6.为了实现上述目的,本发明采用如下技术方案:
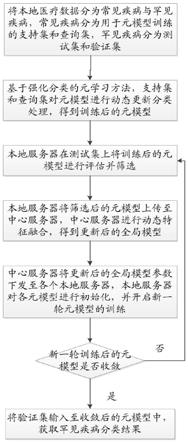
7.一种基于联邦元学习的罕见疾病分类方法,具体步骤如下:
8.s1、对本地医疗数据分为常见疾病与罕见疾病,常见疾病分为用于元模型训练的支持集和查询集,罕见疾病分为测试集和验证集;
9.s2、基于强化分类的元学习方法,支持集和查询集对元模型进行动态更新分类处
理,得到训练后的元模型;
10.s3、本地服务器在测试集上将训练后的元模型进行评估并筛选;
11.s4、本地服务器将筛选后的元模型上传至中心服务器,中心服务器进行动态特征融合,得到更新后的全局模型;
12.s5、中心服务器将更新后的全局模型参数下发至各个本地服务器,本地服务器对各元模型进行初始化,并开启新一轮元模型的训练;
13.s6、进行步骤s3-s5的迭代,直至本地服务器获取收敛后的元模型;
14.s7、将所述验证集输入至收敛后的元模型中,获取罕见疾病分类结果。
15.优选的,所述s1中,具体步骤如下:
16.s11、定义常见疾病与罕见疾病:根据医疗专家经验,将样本数量大的疾病类别作为常见疾病,剩余的疾病类别则为罕见疾病;
17.s12、对常见疾病进行任务划分,得到用于元模型训练的支持集:随机选取n类所述常见疾病的k个样本,构成一个任务,选取多个任务构成元模型训练的所述支持集;
18.s13、对常见疾病进行任务划分,得到用于元模型训练的查询集:选取与所述支持集相同的n类所述常见疾病,每类随机选择3k个样本构成一个任务,采用与所述支持集个数相同、分布相同的任务构成所述查询集;
19.s14、将罕见疾病划分为测试集和验证集:选择罕见疾病各类的一个样本作为测试集对训练后的元模型进行调整,然后将未参与训练的罕见疾病样本作为验证集进行分类诊断。
20.优选的,所述s2中,具体包括以下步骤:
21.s21、在进行元学习内循环中,基于损失函数计算所述支持集的损失,并根据所述损失及梯度信息确定内循环更新参数;
22.s22、在进行元学习外循环中,根据所述查询集和所述内循环更新参数对所述元模型参数进行外循环参数训练,得到外循环更新参数;根据所述外循环更新参数进行元模型训练。
23.优选的,所述s3中,具体包括以下步骤:
24.s31、本地服务器在测试集上对训练后的元模型评估分数;
25.s32、本地服务器选择f分数高于上一轮全局模型f分数的元模型进行上传。
26.优选的,所述s4中,具体包括以下步骤:
27.中心服务器以筛选后的元模型f分数、准确率和数据量计算权重,中心服务器对筛选后的元模型进行动态特征融合处理,得到更新后的全局模型;
28.所述动态特征融合过程包括:
29.筛选后的元模型分别以f分数、准确率和数据量计算权重,公式如下:
[0030][0031]
其中,w
rj
为第r轮所上传的第j个元模型的权重,i表示该轮一共有i个医院上传了
元模型,表示上传第j个元模型的f分数,代表对应准确率和数据量,softmax表示使各参数相加合为1;
[0032]
全局模型更新过程的公式如下:
[0033][0034]
f(θ,lr)为该轮更新所得的全局模型,θ为模型的初始化参数,lr表示学习率,fj(θ,lr)表示当前第j个医院上传的元模型。
[0035]
优选的,所述s21中,所述内循环强化分类条件,动态更新参数过程如下:
[0036]
在分类任务中,某类别概率p(x)可表示为:
[0037]
p(x)=softmax(《z,w》)
[0038]
其中z表示输入向量,w为对应的权重,《z,w》表示内积计算;
[0039]
假设:
[0040]
w=(w1,w2,...wn)
[0041]
则:
[0042]
p(x)=softmax(《z,w1》,《z,w2》,...,《z,wn》)
[0043]
若将z,wi(i=1,2...n)做l2范数归一化处理:
[0044][0045]
其中,ci表示经过l2范数处理后的乘积,使用交叉熵函数计算损失可得:
[0046][0047]
其中,t表示目标标签,由于模型在识别边缘样本时效果较差,因此通过强化分类条件来更新模型训练的每轮损失,公式如下:
[0048][0049]
其中v表示当前线性层的样本权值,在强化分类条件的基础上,对于边缘样本,v值较小,样本距离较大,分类条件应略微宽泛;对于中心样本,v值较大,类内距离较小,分类条件较为严格;
[0050]
本地服务器通过随机梯度下降方式更新模型参数,具体公式如下:
[0051][0052]
其中,表示在支持集上训练得到的基模型,α表示内循环中基模型的学习率,ti为第i个任务,θ为初始化参数,θc为所述基模型的参数,表示对θ求导数。
[0053]
优选的,所述s22中,在所述查询集中计算损失,并根据所述损失和所述内循环更新参数得到外循环更新参数,过程如下:
[0054]
本地服务器通过随机梯度下降方式更新模型参数,同时动态更新所述基模型参数
θc和所述基模型学习率α,具体公式如下:
[0055][0056]
其中,β代表模型外循环的学习率,θc′
为所述元模型的参数,p(t)代表任务的分布。
[0057]
经由上述的技术方案可知,与现有技术相比,本发明具有以下有益效果:
[0058]
(1)采用了一种基于强化分类的元学习方法,通过动态更新分类条件以提高模型对边缘样本的识别精度,提高疾病分类准确度,有助于提高罕见疾病的识别精度;
[0059]
(2)本发明为缓解联邦学习中模型平均融合对诊断准确率的负面影响,提出一种动态特征融合策略,即每个医院仅上传f分数比全局模型f分数高的元模型,并且融合不再仅以数据量为权重,而是综合考虑模型的f分数、准确率和数据量进行动态特征融合,以保证联邦学习分类的准确性;
[0060]
(3)本发明将基于强化分类的元学习方法与基于动态融合策略的联邦学习方法应用于联邦元学习框架,有助于提高模型对于罕见疾病的分类精度和模型间的通信效率。
附图说明
[0061]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0062]
图1附图为本发明的流程示意图。
[0063]
图2附图为本发明的基于强化分类的元模型结构示意图。
[0064]
图3附图为本发明的基于动态特征融合的联邦元学习原理示意图。
具体实施方式
[0065]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0066]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0067]
本发明实施例公开了一种基于联邦元学习的罕见疾病分类方法,此方法可以用于医院以及疾病研究所,能够为研究所以及医院提供大量罕见疾病的医疗数据以及将罕见疾病快速分类,有助于快速识别罕见疾病的类别,提升科研效率以及罕见疾病的识别速度。
[0068]
分类方法具体步骤如下:
[0069]
s1、将本地医疗数据分为常见疾病与罕见疾病,对常见疾病进行任务划分,得到用于元模型训练的支持集和查询集,将罕见疾病分为测试集和验证集;
[0070]
s2、本地服务器利用基于强化分类的元学习方法,结合支持集和查询集通过动态
更新分类条件对元模型进行训练,得到训练后的元模型;本发明能够提高模型对边缘样本的检测效率,还有助于提高各医院的元模型对罕见疾病的检测分类效果;
[0071]
s3、本发明的分类模型采用f分数,公式如下:
[0072]
其中,precision为准确率,recall为召回率,β是用于平衡precision与recall的权重;
[0073]
即本地服务器根据f分数对训练后的各元模型进行筛选并上传至中心服务器;本发明借助联邦学习方法,在保护医疗数据隐私的同时,使得各医院的元模型能够学习更多常见疾病的特征,通过模型筛选不但进一步提高罕见疾病诊断的效果,而且有助于提高模型间的通信效率;
[0074]
s4、中心服务器对筛选后的元模型进行动态特征融合,得到更新后的全局模型;本发明为缓解联邦学习中模型平均融合对诊断效果的负面影响,设计一种动态特征融合策略,再次有助于提高罕见疾病的诊断效果;
[0075]
s5、中心服务器将更新后的全局模型参数下发至本地服务器,本地服务器对各元模型进行初始化,并开启新一轮元模型的训练;
[0076]
s6、进行步骤s3-s5的迭代,直至本地服务器获取收敛后的元模型;
[0077]
s7、将验证集输入至收敛后的元模型中,获取罕见疾病的分类结果。
[0078]
在本实施例中,s1具体包括以下步骤:
[0079]
s11、定义常见疾病与罕见疾病:将样本数量大的疾病类别作为常见疾病,剩余的疾病类别则为罕见疾病;
[0080]
s12、对常见疾病进行划分,得到用于元模型训练的支持集:随机选取n类常见疾病的k个样本,构成一个任务,以p(t)的分布方式选取多个任务构成元模型训练的支持集;
[0081]
s13、对常见疾病进行划分,得到用于元模型训练的查询集:选取与s12中支持集相同的n类常见疾病,每类随机选择3k个样本构成一个任务,采用与支持集个数相同、分布相同的任务构成查询集;
[0082]
s14、将罕见疾病划分为测试集和验证集:选择罕见疾病各类的一个样本作为测试集对训练后的元模型进行调整,然后将未参与训练的罕见疾病样本作为验证集进行分类诊断。
[0083]
在本实施例中,为提高模型对罕见疾病的诊断准确率,设计基于强化分类的元学习方法,其模型结构示意图如图2所示;根据边缘样本和中心样本动态更新分类条件,以提高元模型对罕见疾病的分类效果,s2具体包括以下步骤:
[0084]
s21、在进行元学习内循环中,本地服务器基于损失函数计算支持集的损失,并根据损失及梯度信息确定内循环更新参数,具体如下;
[0085]
内循环强化分类条件,动态更新参数过程如下:
[0086]
在分类任务中,某类别概率p(x)可表示为:
[0087]
p(x)=softmax(《z,w》)
[0088]
其中z表示输入向量,w为对应的权重,《z,w》表示内积计算;
[0089]
假设:
[0090]
w=(w1,w2,...wn)
[0091]
则:
[0092]
p(x)=softmax(《z,w1》,《z,w2》,...,《z,wn》)
[0093]
若将z,wi(i=1,2...n)做l2范数归一化处理:
[0094][0095]
其中,ci表示经过l2范数处理后的乘积,使用交叉熵函数计算损失可得:
[0096][0097]
其中,t表示目标标签,由于模型在识别边缘样本时效果较差,因此通过强化分类条件来更新模型训练的每轮损失,公式如下:
[0098][0099]
其中v表示当前线性层的样本权值,在强化分类条件的基础上,对于边缘样本,v值较小,样本距离较大,分类条件应略微宽泛;对于中心样本,v值较大,类内距离较小,分类条件较为严格;
[0100]
本地服务器通过随机梯度下降方式更新模型参数,具体公式如下:
[0101][0102]
其中,表示在支持集上训练得到的基模型,α表示内循环中基模型的学习率,ti为第i个任务,θ为初始化参数,θc为所述基模型的参数,表示对θ求导数。
[0103]
s22、在进行元学习外循环中,本地服务器根据查询集和内循环更新参数对元模型参数进行外循环参数训练,得到外循环更新参数;根据外循环更新参数进行元模型训练,具体如下:
[0104]
本地服务器通过随机梯度下降方式更新模型参数,同时动态更新所述基模型参数θc和所述基模型学习率α,具体公式如下:
[0105][0106]
其中,β代表模型外循环的学习率,θc′
为所述元模型的参数,p(t)代表任务的分布。
[0107]
在模型特征提取过程中,采用融合空间注意力的卷积神经网络进行特征提取:针对医疗图像样本,一个空间注意力对应一个高
×
宽的矩阵,每个位置对原特征图对应位置的像素就是一个注意力分数。具体而言,基于通道对特征图进行最大池化和平均池化操作,然后将二者进行拼接并通过卷积将通道降为1维,最后将结果经过激活函数生成注意力分数,与特征图对应位置做乘法,通过为特征增加空间注意力,以提高卷积神经网络的特征提取能力。此外,在模型中使用adamw优化器,将学习率定义为0.0001,以进行罕见疾病诊断。
[0108]
在本实施例中,借助联邦学习方法,在保护医疗数据隐私的同时,增加常见疾病的类别,使s2步骤中各医院元模型能够学习更多种类常见疾病的特征,从而提高罕见疾病诊
断的准确率,s3具体包括以下步骤:
[0109]
s31、本地服务器在测试集上对训练后的元模型进行评估分数;
[0110]
s32、本地服务器选择f分数高于全局模型f分数的元模型进行上传至中心服务器。
[0111]
在本实施例中,为减弱s3步骤联邦学习中模型平均融合对诊断效果的负面影响,设计了一种动态特征融合策略,其原理如图3所示,进一步提高罕见疾病的诊断效果,s4具体包括以下步骤:
[0112]
中心服务器以筛选后的元模型准确率作为权重,中心服务器对筛选后的元模型进行动态特征融合处理,得到更新后的全局模型。
[0113]
动态特征融合过程如下:
[0114]
筛选后元模型分别以f分数、准确率和数据量计算权重,公式如下:
[0115][0116]
其中,w
rj
为第r轮所上传的第j个元模型的权重,i表示该轮一共有i个医院上传了元模型,表示上传第j个元模型的f分数,代表对应准确率和数据量,softmax表示使各参数相加合为1;
[0117]
全局模型更新过程的公式如下:
[0118][0119]
f(θ,lr)为该轮更新所得的全局模型,θ为模型的初始化参数,lr表示学习率,fj(θ,lr)表示当前第j个医院上传的元模型。
[0120]
本发明将基于强化分类的元学习方法与动态融合策略的联邦学习方法相结合,将联邦元学习框架用于罕见疾病分类,并对默认设置的联邦元学习框架进行了改进,各医院的诊断效果都有了显著的提升。
[0121]
在评估方法是否有效时,判断各元模型准确率是否比改进前各元模型效果有所提升,以此作为评估策略。此外,本发明以f分数、准确率同时作为评价指标,充分考虑了样本不均衡时,准确率难以有效评价模型效果的不足。本发明的改进方法使得每个医院元模型的诊断效果以及模型通信效率都比默认设置联邦元学习中各元模型有显著提升。
[0122]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0123]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1