一种基于深度学习卷积神经网络的新冠病毒识别预测模型
1.本发明涉及深度学习、拉曼光谱、数据处理、机器学习算法领域,特别涉及一种基于深度学习卷积神经网络的新冠病毒识别预测模型。
背景技术:
2.新型冠状病毒的出现给全球经济、公共安全等方面带来严重损失,快速且准确的诊断新型冠状病毒对控制疫情的爆发尤为重要。拉曼光谱技术已被广泛应用于生物医学、化学检测、矿物质分析等多个领域。深度学习和机器学习以其强大的学习以及适应能力,在某些方面具有远超于人类的决策能力,因此深度学习已被广泛应用于图像处理、语音识别、不同物质分类识别等领域。本发明提出将拉曼光谱技术与深度学习结合,对确诊新冠和健康人员的血清拉曼光谱数据进行模型构建。证明拉曼光谱技术结合深度学习用于诊断病情的可能性,为生物医学检测新冠病毒提供一种新的方法。
技术实现要素:
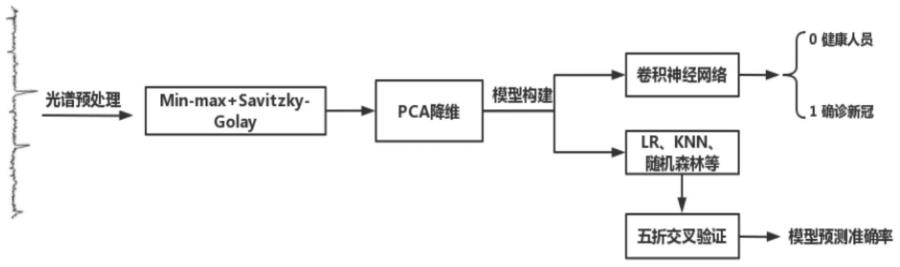
3.为了克服现有技术中的不足,本发明提供一种基于深度学习卷积神经网络的新冠病毒识别预测模型,针对确诊新冠和健康对照人员的血清拉曼光谱数据,使用卷积神经网络训练,使用卷积神经网络模型识别预测新冠病毒。
4.为了达到上述发明目的,解决其技术问题所采用的技术方案如下:
5.一种基于深度学习卷积神经网络的新冠病毒识别预测模型,包括以下步骤:
6.步骤1:对选取的确诊新冠和健康对照组的血清拉曼光谱数据作预处理操作;
7.步骤2:构建卷积神经网络模型;
8.步骤3:使用机器学习中的多种算法分别构建新冠病毒的识别预测模型,以作对比;
9.步骤4:对比利用卷积神经网络、机器学习中的几种算法构建的模型结果,得到对新冠病毒识别预测准确率最高的模型。
10.进一步的,步骤1包括以下内容:
11.步骤1.1:使用savitzky-golay方法对光谱数据平滑滤波处理,使生成的光谱图像更加平滑;
12.步骤1.2:使用min-max方法对样本数据进行归一化,使数据值分布在0~1之间;
13.步骤1.3:使用主成分分析方法pca对实验数据进行降维,因实验样本的特征数较多,故使用pca方法对样本数据进行主成分提取;
14.步骤1.4:对样本数据集进行扩充,提高后期构建模型的泛化能力,向拉曼光谱数据中随机添加高斯噪音,对样本数据集进行扩充,将总样本数据扩充至600个,其中新冠患者以及健康对照人员各300个,以便于卷积神经网络模型得到充分训练,提高模型的泛化能力;
15.步骤1.5:将所有的光谱数据按7:3的比例划分为训练集和测试集,以便于模型的
训练。
16.进一步的,步骤2包括以下内容:
17.步骤2.1:模型主要包括卷积层、批标准化层、激活层、池化层、舍弃层,卷积层对输入数据进行特征提取,批标准化层使神经网络每层的输入都调整成均值为0,方差为1的标准正态分布,激活层使用relu和softmax函数防止模型训练过程中神经元死亡和梯度消失问题的出现,池化层用于减小模型训练中产生的参数矩阵的尺寸,舍弃层将训练过程中的神经元按照一定比例舍弃,加快模型训练的速度;
18.步骤2.2:使用adam优化器优化网络模型参数,使参数能够对输入的光谱数据作非线性变换拟合输出,使得损失函数最小化。
19.进一步的,步骤3包括以下内容:
20.步骤3.1:分别使用k近邻、随机森林、逻辑回归、决策树算法构建识别模型;
21.步骤3.2:使用k折交叉验证方法对基于机器学习算法的模型进行评估,k折交叉验证将数据集分成训练集和测试集,在样本数据不充足的情况下,为了充分利用数据集对算法效果进行测试,将数据集随机分为k份,每次将其中一份作为测试集,其余k-1份作为训练集进行训练。
22.优选的,步骤3.2中的k折交叉验证方法使用5折交叉验证获得每个模型的最终准确率。
23.本发明由于采用以上技术方案,使之与现有技术相比,具有以下的优点和积极效果:
24.本发明一种基于深度学习卷积神经网络的新冠病毒识别预测模型,选取确诊新冠与健康人员的血清拉曼光谱作为样本,首先将样本光谱数据使用min-max方法归一化、使用savitzky-golay方法对光谱进行平滑去噪、使用主成分分析方法对光谱数据降维处理后,利用卷积神经网络构建新冠病毒的识别预测模型,并使用adam优化算法对模型参数进行优化,以提高模型的预测准确率。最后,为证明卷积神经网络的优越性,选取机器学习中的随机森林、逻辑回归、决策树、k近邻等算法进行模型构建,对比不同模型的预测结果,得出基于卷积神经网络的模型对新冠病毒具有最高的识别准确率,为生物医学检测新冠病毒提供一种无损辅助的方法。
附图说明
25.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单的介绍。显而易见,下面描述中的附图仅仅是本发明的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。附图中:
26.图1为本发明实施例的流程示意图;
27.图2为本发明实施例的样本原始光谱图;
28.图3为本发明实施例的经min-max标准化和savitzky-golay平滑滤波处理后的光谱图;
29.图4为本发明实施例的经pca降维处理后的部分样本在二维空间的分布图;
30.图5为本发明实施例提供的卷积神经网络模型的原理图;
31.图6为本发明实施例提供的使用卷积神经网络模型的预测结果和损失图;
32.图7为本发明实施例提供的对传统机器学习算法使用5折交叉验证的原理图。
具体实施方式
33.下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
34.如图1所示,本实施例公开了一种基于深度学习卷积神经网络的新冠病毒识别预测模型,包括以下步骤:
35.步骤1:对选取的确诊新冠和健康对照组的血清拉曼光谱数据作预处理操作;
36.具体的,步骤1包括以下内容:
37.步骤1.1:使用savitzky-golay方法对光谱数据平滑滤波处理,使生成的光谱图像更加平滑;
38.步骤1.2:使用min-max方法对样本数据进行归一化,使数据值分布在0~1之间;
39.步骤1.3:使用主成分分析方法pca对实验数据进行降维,因实验样本的特征数较多,故使用pca方法对样本数据进行主成分提取;
40.步骤1.4:对样本数据集进行扩充,提高后期构建模型的泛化能力,向拉曼光谱数据中随机添加高斯噪音,对样本数据集进行扩充,将总样本数据扩充至600个,其中新冠患者以及健康对照人员各300个,以便于卷积神经网络模型得到充分训练,提高模型的泛化能力;
41.步骤1.5:将所有的光谱数据按7:3的比例划分为训练集和测试集,以便于模型的训练。
42.步骤2:构建卷积神经网络模型;
43.具体的,步骤2包括以下内容:
44.步骤2.1:模型主要包括卷积层、批标准化层、激活层、池化层、舍弃层,卷积层对输入数据进行特征提取,批标准化层使神经网络每层的输入都调整成均值为0,方差为1的标准正态分布,激活层使用relu和softmax函数防止模型训练过程中神经元死亡和梯度消失问题的出现,池化层用于减小模型训练中产生的参数矩阵的尺寸,舍弃层将训练过程中的神经元按照一定比例舍弃,加快模型训练的速度。
45.1.卷积层
46.卷积核用于特征提取,使用多个卷积核可以实现对同一输入特征的多次特征提取,卷积核的个数决定输出层的通道数,本实施例中采用6个卷积核大小为5*5的卷积核,滑动步长strides取值为2,为使输入光谱特征与输出特征的矩阵尺寸大小一致,使用全零填充。
47.2.批标准化层
48.批标准化(batch normalization,bn)中的batch是批数据,对送入激活函数之前的数据重新调整数据分布,将光谱数据分为部分小批数据进行训练,可以加快梯度下降的求解速度。因新冠病毒的光谱数据具有高维度的特征,使用bn层使神经网络每层的输入都调整成均值为0,方差为1的标准正态分布。
49.3.激活层
50.常用激活函数有sigmoid函数、tanh函数、relu函数、leaky relu函数,使用激活函数可以解决神经元死亡和梯度消失问题,relu函数的收敛速度快于sigmoid、tanh函数。softmax函数对神经网络的全连接层输出进行变换,使输出结果服从概率分布,便于更好的观察分类结果。故本实施例中使用relu和softmax两种激活函数。
51.4.池化层
52.池化操作用于减少特征数据量,在相邻的卷积层之间加入一个池化层,可以有效缩小参数矩阵的尺寸,本实施例中选取最大池化,池化核为2*2,池化步长为2。使用flatten将经过卷积计算的数据拉直,并送入一个具有128个神经网络的全连接层,使用relu激活函数,由于该试验数据样本标签有0健康对照组和1新冠病毒患者两类,属于二分类,故最终还要经过一个具有2个神经元的全连接层。
53.5.舍弃层
54.子神经网络训练时,神经元个数较多,所以添加舍弃层将一部分神经元按照一定概率从神经网络中暂时舍弃,以加快模型的训练速度,在神经网络使用时,被舍弃的神经元恢复连接。最后使用softmax激活函数,使输出的结果以概率分布输出。
55.步骤2.2:使用adam优化器优化网络模型参数,使参数能够对输入的光谱数据作非线性变换拟合输出,使得损失函数(计算测试集中的目标值y的真实值和预测值之间的偏差程度)最小化。
56.本实施例中,使用adam优化算法对卷积神经网络模型进行优化,以代替传统随机梯度下降过程的一阶优化算法,模型中epoch迭代次数取值为30,每个batch取值为20,使用优化后的模型对测试集进行预测。
57.步骤3:为证明卷积神经网络具有更好的识别预测能力,使用机器学习中的多种算法分别构建新冠病毒的识别预测模型,以作对比;
58.具体的,步骤3包括以下内容:
59.步骤3.1:分别使用k近邻、随机森林、逻辑回归、决策树算法构建识别模型;对每一种算法参数调优后,结果表明不同算法对样本数据的预测结果具有明显差异。
60.步骤3.2:使用k折交叉验证方法对基于机器学习算法的模型进行评估,k折交叉验证将数据集分成训练集(training set)和测试集(test set),在样本数据不充足的情况下,为了充分利用数据集对算法效果进行测试,将数据集随机分为k份,每次将其中一份作为测试集,其余k-1份作为训练集进行训练。
61.优选的,步骤3.2中的k折交叉验证方法使用5折交叉验证获得每个模型的最终准确率。
62.步骤4:对比利用卷积神经网络、机器学习中的几种算法构建的模型结果,得到对新冠病毒识别预测准确率最高的模型。
63.图2是选取的确诊新冠和健康人员的血清对应的原始拉曼光谱,选取拉曼偏移范围为400至2000cm-1之间,样本光谱特征数共900个,其原始拉曼光谱图像如图2所示:其中横轴代表拉曼偏移(raman shift/cm-1),纵轴代表拉曼强度(intensity),黑色曲线代表健康人员,红色曲线代表新冠病毒患者。
64.图3是经过min-max归一化和savitzky-golay方法平滑去噪后的光谱图像,由于样
本光谱数据的拉曼偏移和对应的拉曼强度之间差距较大,故使用min-max标准化方法对原始数据进行线性变换,使数据落在[0,1]之间。另外,初采集的光谱图像会存在许多毛刺和噪声,需使用一些方法对光谱平滑处理,本实施例使用savitzky-golay方法。
[0065]
图4是经主成分分析方法对光谱降维,提取主成分后的样本在二维空间的分布图。
[0066]
图5表示的是使用卷积神经网络模型训练光谱数据的过程,光谱数据经以上预处理操作后,送入卷积神经网络模型进行训练,经卷积神经网络模型预测后能得出最终的结果。
[0067]
图6是使用优化后的网络模型对测试集和训练集进行预测,其训练集和测试集的预测准确率和损失图,其中training accuracy/loss指训练集准确率/损失,validation accuracy/loss指的是测试集准确率/损失。
[0068]
图7是使用k折交叉验证的原理图,为提高模型的泛化性能和鲁棒性,本实施例使用k折交叉验证的方法优化模型,获得最终的模型准确率。k折交叉验证将数据集分成训练集(training set)和测试集(test set),在样本数据不充足的情况下,为了充分利用数据集对算法效果进行测试,将数据集随机分为k份,每次将其中一份作为测试集,其余k-1份作为训练集进行训练。以上几种模型均使用5折交叉验证获得其最终准确率。
[0069]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1