生成对抗网络交替训练及医疗图像分类方法、装置、介质
1.本发明涉及人工智能领域,特别是一种生成对抗网络交替训练及医疗图像分类方法、装置、介质。
背景技术:
2.图像生成模型是近年来深度学习的一个热门研究领域
1.。生成模型通过从数据集中学习样本的数据分布,在生成样本时从数据分布中进行随机抽样,生成不同于数据集中原始样本的新样本。由于对样本的数据分布建模时在连续的特征空间中进行,从数据分布进行随机采样时,取到训练集样本对应点的概率很小。因此,生成的样本相对于原始训练集样本,有新的特征,起到了丰富数据集的作用。常见的图像生成模型包含自编码器
2.和生成对抗网络
3.。生成对抗网络相较于自编码器模型有独特的优势。自编码器通过图像重建损失函数度量生成样本与真实样本的分布差异,以显式度量的方式衡量生成样本的好坏,通过训练使得解码器生成的样本接近真实样本。生成对抗网络包含生成器和判别器。生成对抗网络通过判别器对生成样本的真假进行判断,让判别器网络区分生成样本和真实样本,以隐式度量的方式衡量生成样本的好坏,通过训练使得生成器生成的样本接近真实样本,生成对抗网络具有生成高清晰度图片的优势。
3.生成器和判别器的训练次数影响了生成对抗网络的收敛性。在现有的各种生成对抗网络中,都遵循生成器和判别器交替训练的方式。生成器和判别器交替训练,生成器和判别器的训练次数比例成为一个重要的超参数。在不同的生成对抗网络中,训练次数比有不同的取值。训练次数比决定了生成器和判别器的训练程度,对生成对抗网络的最终收敛有较大影响。但现有生成对抗网络将训练次数比设置为固定的值,具有较强的主观性,并且可能依赖于所使用的数据集。因此,在生成对抗网络中,如何打破传统的生成器和判别器交替训练方式,构建一种基于自适应交替训练策略的生成对抗网络,不再设置训练次数比的超参数,从而提高生成对抗网络的收敛性,是亟待解决的问题。
4.生成对抗网络在图像合成
[5-6]
、图像超分辨率
[7-8]
、图像数据增强
[9]
、图像风格迁移
[10]
等领域有广泛的应用。在图像合成领域,huang等人
[11]
构建tpgan模型,根据人的侧脸数据合成前向的人脸图像,为提高人脸识别模型的精度带来了帮助。生成对抗网络在图像合成有着广泛的应用
[12-13]
。在图像超分辨率领域,ledig等人
[14]
提出的超分辨率生成对抗网络srgan,生成器对低分辨率图像进行上采样,生成高分辨率图像,使用感知损失函数对模型优化。在图像数据增强领域,生成对抗网络通过对训练样本进行学习,生成更多数量的图像来扩充数据集,从而辅助鉴别模型的构建。在图像风格迁移领域,有许多有趣的应用。zhu等人
[15]
提出的cyclegan,可以实现两种不同风格的图像进行转换。
[0005]
尽管生成对抗网络在不同领域取得了研究成果,生成样本的清晰度也比其他生成模型更好,但是不可否认的是生成对抗网络仍然存在训练过程较难收敛、模式崩溃
[16]
等问题。生成对抗网络得益于博弈论的思想,其生成器和判别器具有不同的损失函数,以类似博弈的过程分开训练,这使得生成对抗网络的训练过程相比于传统的单个损失函数的神经网
络更难训练
[17]
。生成对抗网络的生成器和判别器,其优化目标不一致。因此,在训练生成对抗网络时,为生成器和判别器分别设置不同的损失函数,分开训练,当优化时都向着各自的目标进行权重调整,直到达到纳什均衡点
[18]
。这决定了生成对抗网络的生成器和判别器的交替训练方式。由于生成器和判别器同时达到均衡是相对困难的,并且生成器或者判别器其中一个网络过早收敛对另一个网络不利,因此生成对抗网络的训练过程相对困难,较多研究者致力于提高生成对抗网络的收敛性,但生成对抗网络的收敛性较难保证。研究者通常在大量样本下构建生成对抗网络,因为在小样本数据下生成对抗网络的收敛更加困难。
[0006]
综上,现有技术存在以下缺陷:(1)传统生成对抗网络收敛慢,生成器和判别器同时达到均衡非常困难;(2)传统生成对抗网络的生成器和判别器的收敛程度难以度量;(3)现有生成对抗网络将训练次数比设置为固定的值,具有较强的主观性,并且可能依赖于所使用的数据集。
技术实现要素:
[0007]
本发明所要解决的技术问题是,针对现有技术不足,提供一种生成对抗网络交替训练及医疗图像分类方法、装置、介质,使得生成器和判别器同时达到均衡。
[0008]
为解决上述技术问题,本发明所采用的技术方案是:一种自适应生成对抗网络交替训练方法,包括以下步骤:s1、从训练集中随机抽取一组图片集,从正态分布中随机抽样m个噪声向量;m为图片集中图片的数量;根据生成器生成的生成样本和训练样本x,计算得到和;s2、判断以下条件是否均满足,若是,则利用所述图片集训练生成器,否则利用所述图片集训练判别器。当训练生成器时,需要冻结判别器的权重(即保持判别器权重不变),反之,训练判别器时,需要冻结生成器的权重;;;其中,和是预先设置的超参数;s3、重复步骤s1和s2,当自适应生成对抗网络生成的图像视觉效果或预设的评价指标达到设定要求时,保存adagan模型。
[0009]
生成对抗网络基于博弈论的思想,寻找生成器g和判别器d的均衡点,各自朝着不同的目标进行优化。在一定程度上,g和d的优化目标是相悖的。g和d为了不同的目标进行优化,从而决定了g和d的交替训练方式。g和d在训练过程中,彼此是依赖的,互相提供了网络权重优化所需的梯度。在判别器的损失函数中,利用到了生成器的权重以及生成器前向传播的结果。如果生成器是收敛程度相对判别器过高,判别器的学习就会变得困难。在wgan中,使用wasserstein距离改进gan的损失函数,仍然交替训练,每训练5次判别器,再训练1次生成器。生成器和判别器的训练次数比作为一个超参数进行人为设置,这具有很强的主观性。因此,本发明提出基于自适应交替训练策略的自适应生成对抗网络adagan,根据生成器的收敛性度量指标convg和判别器的收敛性度量指标convd,设计生成对抗网络的自适应交替训练策略。由于训练时是通过自适应的方式选择训练生成器还是判别器,这样就不会
陷入一个网络比另一个网络收敛程度高很多的情况,提升了训练的稳定性。
[0010]
本发明的优势在于提升了生成对抗网络训练的稳定性,且不需要人为事先花费大量时间通过试错去设置生成器和判别器的固定训练轮次比,而且固定的训练轮次比不一定合适,在不同的数据集上不一定需要相同训练轮次比。即使在同一个数据集上,随着训练时间的推移,事先设置好的训练轮次比也不一定最适合目前的情况。产生优势的原因在于本方案始终对生成器和判别器的收敛程度进行度量,并根据此时的收敛程度和自适应交替训练策略去选择下一次训练哪一个网络更合理。
[0011]
;;是判别器函数,为生成器函数。
[0012]
本发明首次提出了生成器和判别器的收敛性度量准则,量化了训练生成对抗网络时生成器和判别器的收敛程度,为自适应交替训练策略奠定了基础。
[0013]
本发明还提供了一种医疗图像分类方法,包括以下步骤:a1、对于每一类疾病图像,初始化对应的自适应生成对抗网络,构建有标签训练集和有标签测试集;其中,, 其中,为类别k的有标签训练数据集,样本数量为,;k个类别构建的有标签测试集为;为类别k构成的测试数据集,样本数量为,,其中表示类别k构成的有标签测试数据集中的第1个样本;表示类别k构成的有标签测试数据集中的第个样本;a2、对于每一类疾病图像,使用有标签训练集训练,直到收敛后,保存模型;a3、对于每一类疾病图像,使用的生成器和随机生成的p个随机向量,得到k个类别,每个类别数量包括p个生成样本,记为,;a4、使用训练图像分类模型,即每次以随机的顺序从中抽取样本训练分类模型,直至图像分类模型收敛,保存收敛后的分类模型;其中,根据本发明自适应生成对抗网络交替训练方法训练获得。
[0014]
本发明可以仅凭借小样本医疗图像数据就能达到较好的医疗疾病图像分类准确率,这是现有方法所难以达到的。原因在于使用adagan利用原有的小样本医疗图像生成了大量的可靠医疗图像,再利用这些图像去训练分类模型,所以得到了更高的分类准确率。
[0015]
所述图像分类模型为resnet50模型。
[0016]
resnet50为广为使用的一种分类模型,是在分类准确率和时间复杂度上的一个平衡,具有较高的效率。
[0017]
本发明还提供了一种计算机装置,包括存储器、处理器及存储在存储器上的计算机程序;所述处理器执行所述计算机程序,以实现本发明方法的步骤。
[0018]
本发明还提供了一种计算机程序产品,包括计算机程序/指令;该计算机程序/指令被处理器执行时实现本发明方法的步骤。
[0019]
本发明还提供了一种计算机可读存储介质,其上存储有计算机程序/指令;所述计算机程序/指令被处理器执行时实现本发明方法的步骤。
[0020]
与现有技术相比,本发明所具有的有益效果为:本发明通过对生成器和判别器的
收敛程度进行度量,能够量化生成器和判别器的训练收敛程度;通过制定自适应交替训练策略,能够根据当前生成器和判别器的收敛程度,自适应地确定下一次是训练生成器还是判别器;通过基于自适应生成对抗网络对医疗影像进行疾病分类,能够提高分类准确率和识别效果,辅助医护人员对疾病进行诊断。本发明基于自适应交替训练策略的生成对抗网络,不依赖具体的数据集,由网络自适应决定生成器和判别器的训练进程,提高了生成对抗网络的收敛能力。
附图说明
[0021]
图1为本发明实施例方法流程图;图2(a)和图2(b)为本发明实施例5000次迭代时wgan和adagan的生成图片效果;图2(a)为毛囊虫图片;图2(b)为角化不全的图片;图3为本发明实施例自适应生成对抗网络学习疾病分类效果对比。
具体实施方式
[0022]
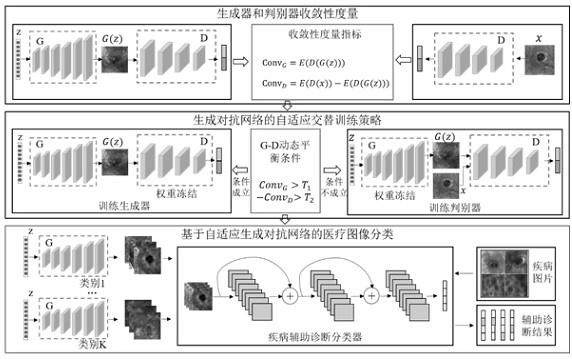
如图1所示,本发明实施例基于自适应策略的生成对抗网络训练方法主要分成四个部分。首先,生成器和判别器收敛性度量准则,对生成器和判别器的收敛程度进行度量,为后续的自适应训练策略平衡条件奠定基础。其次,使用自适应交替训练策略,设计g-d(生成器-判别器)动态平衡条件,根据生成器和判别器的收敛程度来确定下一次训练生成器还是判别器。再者,本发明通过将自适应交替训练策略与wgan进行融合,提出了一种新的网络结构——adagan(adaptivegan,自适应生成对抗网络)。最后,设计基于自适应生成对抗网络的医疗影像智能识别系统,扩充医疗影像数据集,提升医疗影像疾病分类性能,辅助医护人员决策。
[0023]
本发明采用的收敛性度量算法,为了衡量生成器和判别器收敛性,量化生成器和判别器的收敛程度,提出量化指标对生成器和判别器收敛性进行度量。wgan等方法在进行生成器和判别器的交替训练时,将生成器和判别器的训练次数比作为一个超参数,具有较强的主观性,并且训练次数比对结果可能有较大的影响,因此,本发明将针对这一问题,首先进行生成器和判别器的收敛性度量,然后设计自适应交替训练策略,构建具有自适应训练能力的生成对抗网络,使得生成器和判别器的训练更加均衡,提高模型的整体训练稳定性和收敛能力。由于wgan的损失函数能够反映数据的真实分布和生成分布之间的差异,因此,生成器和判别器的收敛性可以使用损失函数的值进行预估。将生成器的收敛程度(convergence)记为convg,将判别器的收敛程度记为convd。根据判别器对训练样本的预测概率和对生成样本的预测概率计算生成器的收敛性度量指标convg和判别器的收敛性度量指标convd。
[0024]
(1)(2)其中,e为数学期望。收敛性度量指标值越小,表明收敛程度更高。对于生成器的收敛性度量指标,越小,即生成器的生成样本让判别器给出的预测概率越小,表明判别器倾向于预测生成样本为真实样本,从而越小表明生成器的收敛程度更高。对于判别器的收敛性度量指标,越大,或者越小,即d对生成样本输出的预
测概率越大,d对真实样本输出的预测概率越小,表明判别器可以较好地区分真实样本和生成样本,从而越小表明判别器的收敛程度更高。
[0025]
本发明提出的自适应交替训练策略,将包含n张样本的某种疾病数据集记为。构建生成对抗网络,判别器使用函数表示,生成器使用函数表示。判别器的权重为,初始权重为。生成器的权重为,初始权重为。训练时的批大小(batchsize)为m,则每次权重迭代时从训练数据集随机抽样m个样本,组成一个batch数据。自适应生成对抗网络的交替训练算法如自适应生成对抗网络的交替训练算法所示。学习率为lr,批大小为m,最大的迭代次数为。
[0026]
自适应生成对抗网络的交替训练算法:第一步:首先从训练集中随机抽取一个batch的图片集,从正态分布中随机抽样m个噪声向量;第二步:根据生成器生成的生成样本和训练样本x在判别器预测概率输出结果的均值计算和。
[0027]
第三步:定义生成器和判别器的动态平衡条件,同时满足公式(3)和公式(4)两个条件则称生成器和判别器处于g-d动态平衡状态,或者说adagan满足g-d动态平衡条件。如果adagan满足g-d动态平衡条件,则接着训练生成器(指对生成器进行梯度更新),否则训练判别器。其中,和是两个超参数,d(g(z))通常比d(x)大,因此,和均为正数。由于判别器对输入图片预测的值越小表示此图片认为是真实图片的概率越大,因此,e(d(g(z)))越大,越能反映判别器将生成图片判为假图片,说明判别器已经足够好;e(d(x))越小,反映了判别器越能够将真实图片判为真实图片,也说明判别器已经足够好。所以,当adagan满足g-d动态平衡条件时,应该训练生成器,否则训练判别器。
[0028]
(3)(4)第四步:重复第一步到第三步,自适应交替训练adagan,当adagan生成图像视觉效果或预设的评价指标达到理想要求时,保存adagan模型。
[0029]
adagan是针对传统gan的训练策略的改进,在wgan的基础上施加自适应交替训练策略,便构成了adagan。因此,算法1(即自适应生成对抗网络的交替训练算法)的时间复杂度与wgan等模型的复杂度近似,adagan的收敛性度量指标的计算以及g-d动态平衡条件的判断不需要耗费额外的时间。
[0030]
本发明提出一种基于自适应生成对抗网络的医疗影像智能识别系统,能够在原有的小样本医疗数据集上进行扩充,在扩充后的数据集上训练疾病分类模型。
[0031]
基于自适应生成对抗网络的医疗影像疾病分类算法步骤如下:第一步:对于每一类疾病图像,初始化对应的自适应生成对抗网络,构建有标签训练集和有标签测试集。其中,,其中,为类别k的训练数据集,样本数量为,。k个类别构建的测试集为。其中,为类别k构成的测试数据集,样本数量为,
。
[0032]
第二步:对于每一类疾病图像,使用有标签训练集自适应交替训练,直到收敛后,保存模型(这一步实则为算法1,为算法1中的,为算法1保存的adagan模型);第三步:对于每一类疾病图像,使用的生成器和随机生成的p个随机向量,得到k个类别p的生成样本,记为,其中;第四步:使用训练resnet50图像分类模型,直至resnet50收敛,保存分类模型resnet50。
[0033]
基于本发明提出的自适应生成对抗网络训练方法,我们选取某三甲医院的临床医疗影像数据集,实验以医疗影像数据毛囊虫和角化不全为例,数据集包含了605张毛囊虫医疗影像数据和589张角化不全症医疗影像数据。每张图像的原始尺寸为1000
×
1000。在进行小样本学习模型构建时,随机抽取20张样本作为自适应生成对抗网络的训练集,剩余数据作为计算机辅助诊断模型的测试集数据。实验在ubuntu系统上进行,在titan xp显卡上进行实验,显存为12gb。
[0034]
本发明设计了收敛性度量指标以及自适应交替训练策略,并在wgan的基础上引入生成器和判别器的收敛性度量指标,根据生成器判别器动态平衡条件进行训练,完成自适应生成对抗网络的训练。实验时,生成器判别器动态平衡条件的参数t_1设置为0.3,参数t_2设置为0.5。adagan的其余设置与wgan相同,在训练相同迭代次数时,比较模型的生成样本的生成差异。将数据集的605张毛囊虫疾病数据图像随机划分20张训练集图像和585张测试集图像,589张角化不全症疾病数据图像随机划分为20张训练集图像和569张测试集图像。每个类别的20张训练集图像用于训练生成对抗网络adagan和wgan,adagan和wgan生成的样本用于后续的辅助诊断模型构建,测试集图像用于后续辅助诊断模型的性能测试。
[0035]
对于毛囊虫和角化不全,每个疾病类别单独训练wgan和adagan。将生成器和判别器的训练次数之和称为生成对抗网络的迭代次数。为了比较相同迭代次数时wgan和adagan的生成样本效果,图2(a)和图2(b)展示了5000次迭代的生成图片效果。可以看到,adagan的训练过程收敛较快。在5000次迭代时,adagan的生成样本病灶特征明显,而wgan的生成图片相对模糊,adagan的生成样本比wgan的生成样本效果更好,验证了adagan的有效性。
[0036]
将20张毛囊虫图像和20张角化不全图像组成的训练集图像分别训练生成对抗网络adagan和wgan。生成对抗网络的迭代次数在从0到30000之间,每隔500次迭代保存一次模型,使用保存的adagan和wgan模型进行数据生成。在每次生成时,毛囊虫训练的adagan模型用于生成1000张毛囊虫样本,角化不全训练的adagan模型用于生成1000张角化不全样本;毛囊虫训练的wgan模型用于生成1000张毛囊虫样本,角化不全训练的wgan模型用于生成1000张角化不全样本。构建一个resnet-50网络,作为疾病辅助诊断的分类器。将adagan模型生成得到的1000张毛囊虫样本和1000张角化不全样本作为训练集,训练resnet-50模型,再使用585张毛囊虫真实图像和569张角化不全真实图像作为测试集,对训练resnet-50模型进行测试,得到的准确率即为基于adagan的小样本学习模型的准确率。将wgan作为对比模型,用wgan模型生成得到的1000张毛囊虫样本和1000张角化不全样本作为训练集,训练resnet-50模型,再使用585张毛囊虫真实图像和569张角化不全真实图像作为测试集,对训练resnet-50模型进行测试,得到的准确率即为基于wgan的小样本学习模型的准确率。基于
wgan的小样本学习和基于adagan的小样本学习分类效果对比如图3所示。从实验结果可以看到,基于adagan的小样本学习分类效果显著优于基于wgan的小样本学习分类效果。
[0037]
参考文献:[1]yix,waliae,babynp.generativeadversarialnetworkinmedicalimaging:areview.medicalimageanalysis,2019,58:101552[2]hanpy,jinatb,abasfs.neighbourhoodpreservingdiscriminantembeddinginfacerecognition.journalofvisualcommunicationandimagerepresentation,2009,20(8):532-542[3]goodfellowi,pougetj,mirzam,etal.generativeadversarialnets//advancesinneuralinformationprocessingsystems.2014:2672-2680[4]hoffmanmd,bleidm,wangc,etal.stochasticvariationalinference.journalofmachinelearningresearch,2013,14(5)[5]santanae,hotzg.learningadrivingsimulator.arxivpreprintarxiv:1608.01230,2016[6]zhuk,liux,yangh.asurveyofgenerativeadversarialnetworks//chineseautomationcongress.2018:2768-2773[7]zhangt,wangh,chengr,etal.super-resolutionreconstructionofimagebasedongenerativeadversarialnetworkwithattentionmodule//internationalconferenceonsignalimageprocessingandcommunication.2021,11848:1184805[8]zhux,guok,rens,etal.lightweightimagesuper-resolutionwithexpectation-maximizationattentionmechanism.ieeetransactionsoncircuitsandsystemsforvideotechnology,2021[9]antonioua,storkeya,edwardsh.dataaugmentationgenerativeadversarialnetworks.arxivpreprintarxiv:1711.04340,2017[10]mirzam,osinderos.conditionalgenerativeadversarialnets.arxivpreprintarxiv:1411.1784,2014[11]huangr,zhangs,lit,etal.beyondfacerotation:globalandlocalperceptionganforphotorealisticandidentitypreservingfrontalviewsynthesis//ieeeinternationalconferenceoncomputervision.2017[12]zhujy,philippk,shechtmane,etal.generativevisualmanipulationonthenaturalimagemanifold//proceedingsofeuropeanconferenceoncomputervision.2016[13]liy,lius,yangj,etal.generativefacecompletion//ieeeconferenceoncomputervisionandpatternrecognition.2017[14]ledigc,theisl,huszarf,etal.photo-realisticsingleimagesuper-resolutionusingagenerativeadversarialnetwork.ieeecomputersociety,2016[15]zhujy,parkt,isolap,etal.unpairedimage-to-image
translation using cycle-consistent adversarial networks//proceedings of ieee international conference on computer vision. 2017: 2242-2251。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1